
从“不确定”到“高效”:Anthropic 官方实践指南,重塑你的智能体工具设计!
从“不确定”到“高效”:Anthropic 官方实践指南,重塑你的智能体工具设计!
在过去几十年里,软件开发的底层逻辑一直没变:函数是确定的,调用是可靠的,系统是可控的。
这种“稳定性”造成的效果就是:输入确定,输出唯一,行为透明。
但自从大模型(LLM)和智能体(AI Agent)登上舞台,这条铁律就被彻底打破了。
智能体更像是一个“拥有主观能动性”的协作者,它可能选择调用工具,也可能不调用;可能理解指令,也可能误解语境;甚至同样的输入,今天和明天都可能给出完全不同的结果。
那么,问题来了,如果智能体本身就是“不确定性的”,那我们该如何为它设计“确定性”的工具?
Anthropic 研究团队最近分享了一套系统方法论,今天这篇文章就从工程实践角度出发,深度拆解。
01|为什么智能体工具设计这么重要?
智能体强,就强在工具。
大模型本身的能力是很有限的,只能依赖训练数据概率输出。
比如它不能联网搜索实时信息、不能查询天气、不能发邮件。
这时候就需要给 AI 模型配备各种“工具”(Tools)。
举个例子,当你问一个配备了联网工具的智能体“今天需要带伞吗?”,它可能会:
-
先询问你在哪个城市
-
调用天气查询工具获取实时天气
-
根据自己的知识判断是否需要带伞
划重点:智能体(AI Agent)的能力上限,很大程度上取决于我们给它配备的工具质量。
工具设计得好,智能体就能高效完成任务;设计得不好,它可能会绕弯路,甚至直接罢工。
如果说传统软件是确定性系统之间的契约(比如输入 A 永远得到输出 B),那么工具就是确定性系统与非确定性智能体之间的契约。
这也意味着我们需要用完全不同的思路来为智能体设计工具。
02|Anthropic 的工具设计方法
核心流程:原型 -> 评估 -> 优化
Anthropic 分享的工具设计方法,和软件开发(尤其是 AI 时代的开发)非常类似。
第一步:快速搭建原型
先别想太多,快速实现一个能用的版本。
-
用 AI 编程工具(如 Claude Code、Codex)来写工具代码
-
通过 MCP 协议或 API 直接测试
-
测试真实使用场景,收集用户反馈
以现阶段 AI 的能力,给定相关的库、APIs、SDKs 文档,很快就能生成一个基础版本。
第二步:构建评估系统
这是整个方法的核心。
你需要运行评估来衡量这个工具的效果。
-
生成测试任务:创建几十个真实场景的任务
-
运行自动化测试:让智能体执行这些任务
-
收集关键指标:成功率、工具调用次数、Token 消耗等
高质量任务示例:
Schedule a meeting with Jane next week to discuss our latest Acme Corp project. Attach the notes from our last project planning meeting and reserve a conference room.
低质量任务示例(过于简单):
Schedule a meeting with jane@acme.corp next week.
主要差别在于:高质量任务更接近真实场景,需要多个工具配合,能测试出工具的真正表现。
第三步:让 AI 优化自己的工具
以彼之矛,攻彼之盾。
这是最有意思的部分,值得借鉴。
把评估结果,包括失败案例、智能体的思考过程,全部投喂给 AI 工具,让它来分析问题并优化工具。
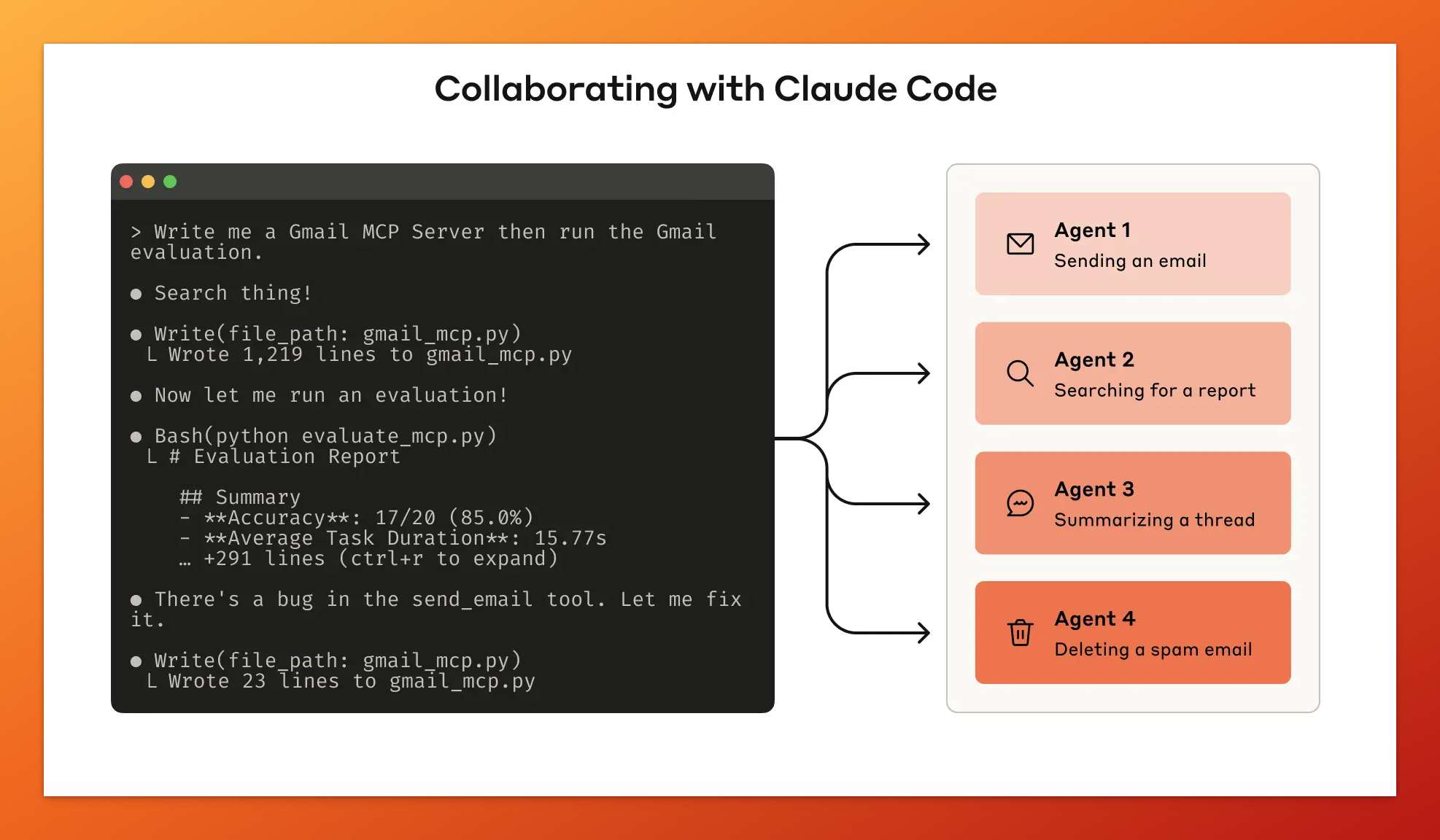
Claude Code 自动化评估流程:编写工具、运行测试、发现问题、即时优化
根据 Anthropic 的统计数据,经过 Claude Code 优化后的 Slack 工具性能提升了约 15%,Asana 工具提升了约 20%。还蛮可观的提升幅度。
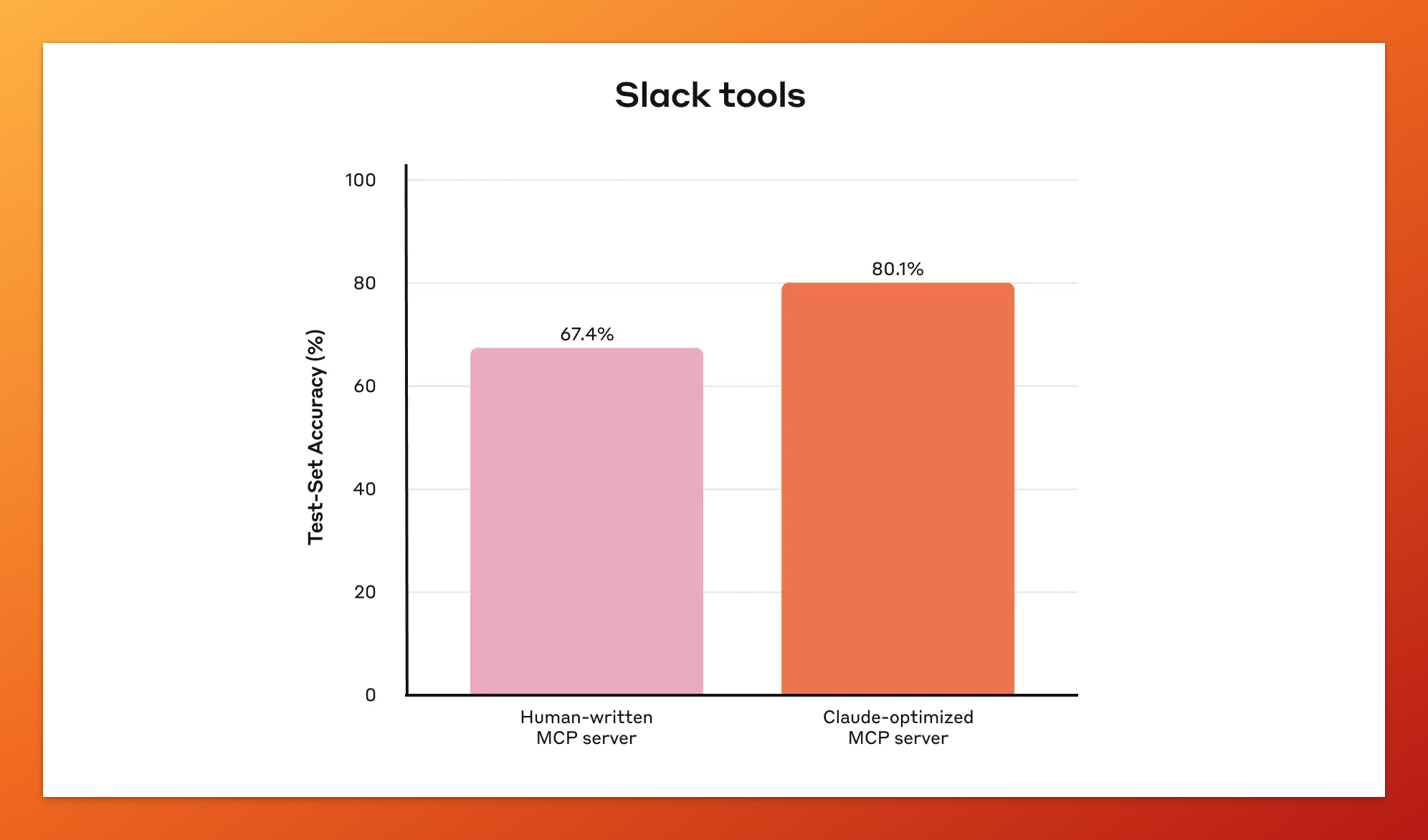
Slack 工具性能对比:Claude 优化后的版本将准确率从 67.4% 提升至 80.1%
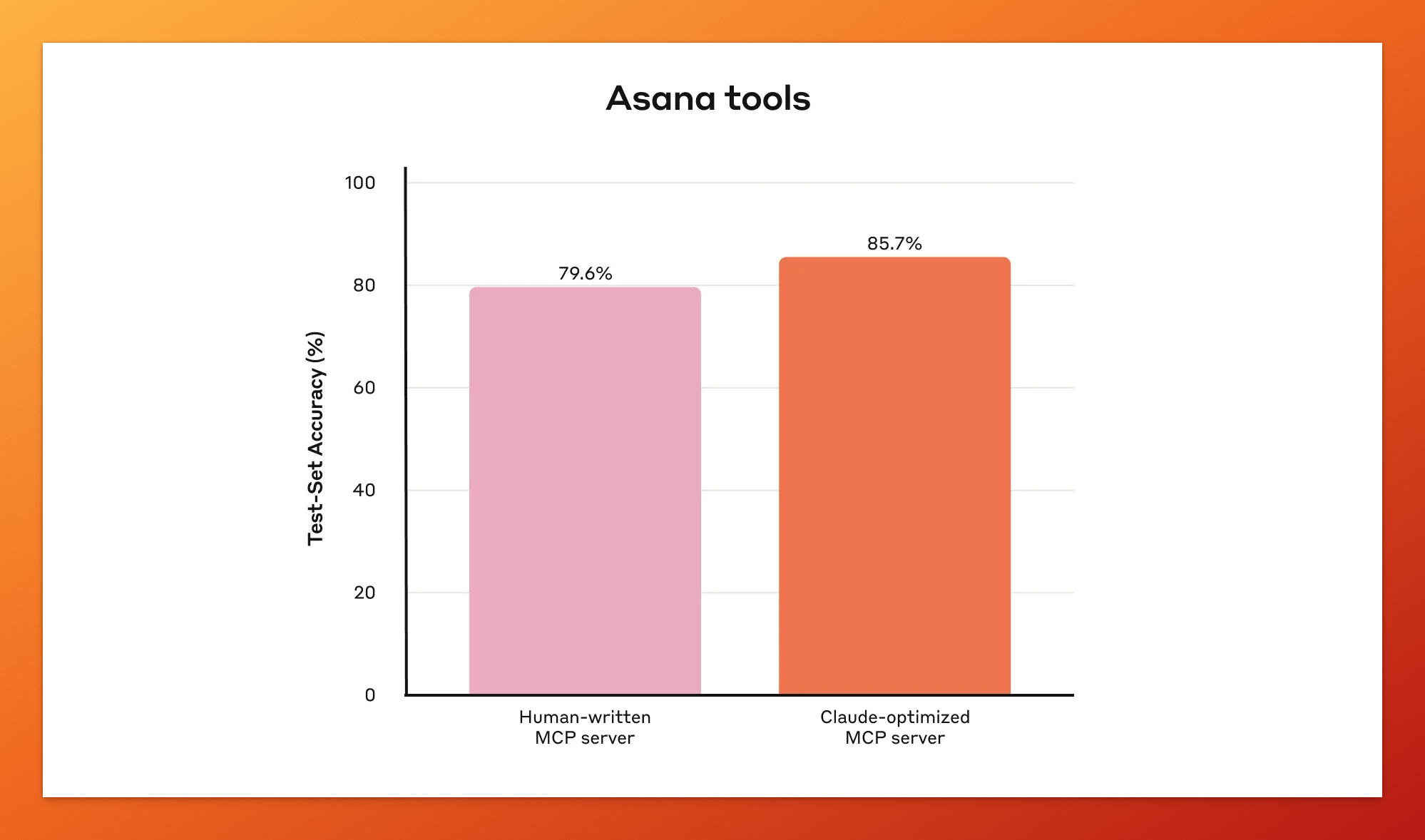
Asana 工具性能对比:通过 AI 自优化,准确率从 79.6% 提升至 85.7%
AI 时代,用 AI,来优化 AI。
03|智能体工具设计原则
接下来聊几个智能体工具设计原则。
1. 选择合适的工具
工具并不是越多越好。
而是,越合适越好。
以在通讯录中搜索联系人这一任务为例。
-
不好的设计:
list_all_contacts()返回所有联系人 -
好的设计:
search_contacts(name="张三")直接搜索
原因很简单,智能体的上下文长度有限,返回太多无关信息会浪费 Token,降低效率。
2. 工具命名空间
当工具多了之后,清晰的命名变得很重要。
asana_projects_search()
asana_users_search()
jira_projects_search()
jira_users_search()
这种工具命名方式能帮助智能体快速理解每个工具的用途和边界,降低调用出错的风险。
3. 返回内容优化
-
优先返回语义化的信息(如“张三”而不是 “user_1234”)
-
提供响应格式控制(简洁版 concise /详细版 detailed)
-
合理设置分页和截断
Anthropic 的测试显示,仅仅是把 UUID 改成更有意义的标识符,就能显著减少智能体的出错率。
4. Token 效率优化
智能体的上下文是有成本的,每个 Token 都是算力,都是钱。
所以,优化工具返回给智能体的信息量就变得很重要。
不是返回越多信息越好,而是返回“刚刚好”的信息,既满足需求,又不浪费上下文。
具体来说,可以这样操作。
-
设置响应上限:Claude Code 默认限制工具响应为 25,000 个 Token
-
智能分页:不要一次返回 1000 条记录,而是分批次返回
-
有效截断:截断时告诉智能体还有更多内容,引导它缩小搜索范围
5. 提示工程优化
据 Anthropic 表示,这是工具优化最有效的方法之一。
工具描述和规范就像是给新员工写的操作手册,会被默认带入上下文,引导智能体调用合适的工具。
-
明确说明输入输出格式
-
解释专业术语
-
提供使用示例
-
说明注意事项
04|实践建议
如果你也想尝试这套方法,建议从小处着手。
先针对一个具体使用场景设计工具,比如“自动整理会议纪要”或“批量处理客户工单”,不要一上来就想做个“大而全”的万能助手。
评估标准很重要。你需要建立起一套评估机制,像运行单元测试一样定期评估工具性能。
即使只有 10 个测试用例,也能帮你发现大部分问题。
更重要的是制定统一的工具设计规范,命名、传参、错误返回,小细节会直接影响智能体的整体表现。
结语
回到开头那个悖论,我们该如何为“不确定”的智能体,设计“确定”的工具?
Anthropic 的答案是 —— 既然无法消除不确定性,那就拥抱它。
让 AI 参与到工具的设计和优化中来,用智能体的视角,理解智能体的工作方式。
这有点像“套娃”,用工具来改进工具本身。
当然,这套方法也有局限性。
它更适合有明确任务边界的场景,对于开放的创造性任务可能效果有限。
但从更大的视角来看,它指向的,或许是一种新的开发范式,是一次思维方式的重塑。
参考链接
-
Writing effective tools for agents — with agents. Anthropic, 2025 年 9 月. 链接:https://www.anthropic.com/engineering/writing-tools-for-agents
我是木易,一个专注 AI 领域的技术产品经理,国内 Top2 本科 + 美国 Top10 CS 硕士。
相信 AI 是普通人的“外挂”,致力于分享 AI 全维度知识。这里有最新的 AI 科普、工具测评、效率秘籍与行业洞察。
欢迎关注“AI信息Gap”,用 AI 为你的未来加速。
精选推荐
更多推荐
 14
14 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)