
【最新最全】Coze智能体搭建教程:文章改写并定时发布至公众号(免费!内附插件源码!)
无论你是刚接触 Coze 智能体的 “新手”,还是已尝试过 “内容自动化 + 公众号发布” 流程的 “进阶玩家”,这篇教程都能精准解决你的需求,帮你避开坑、少走弯路,高效搭建属于自己的自动化内容发布体系。
写在前面
无论你是刚接触 Coze 智能体的 “新手”,还是已尝试过 “内容自动化 + 公众号发布” 流程的 “进阶玩家”,这篇教程都能精准解决你的需求,帮你避开坑、少走弯路,高效搭建属于自己的自动化内容发布体系。
如果你对 “用 Coze 搭建文章改写 + 公众号定时发布” 的流程完全陌生,不必担心操作复杂:
教程会把每一步操作拆解到 “最小可执行单元”确保你 “照着步骤走,就能一次搭成”。
如果你已经尝试过网上的同类教程,大概率会遇到这些让人头疼的痛点:
- 工作流跑不通
- 代码运行报错
- 插件要收费
- 改写内容不满意
- AI生成的插图不合适
- Markdown 转 HTML 效果差,最终排版一团糟(要么是插件本身功能残缺,要么是生成Markdown代码与转换插件的逻辑不匹配,毕竟来自不同开发者)
而本教程的核心优势,正是针对性解决这些痛点:
所有关键工具都是我基于实际需求自研的,不仅解决了格式错乱、内容生硬的问题,生成的文章排版美观度、发布稳定性都经过多次测试验证;更重要的是,我会将全部源码公开,你可以直接拿过去用,也能根据自己的需求微调代码,彻底摆脱 “别人的工具不适用” 的困境。
准备好了我们就开始吧!
:::
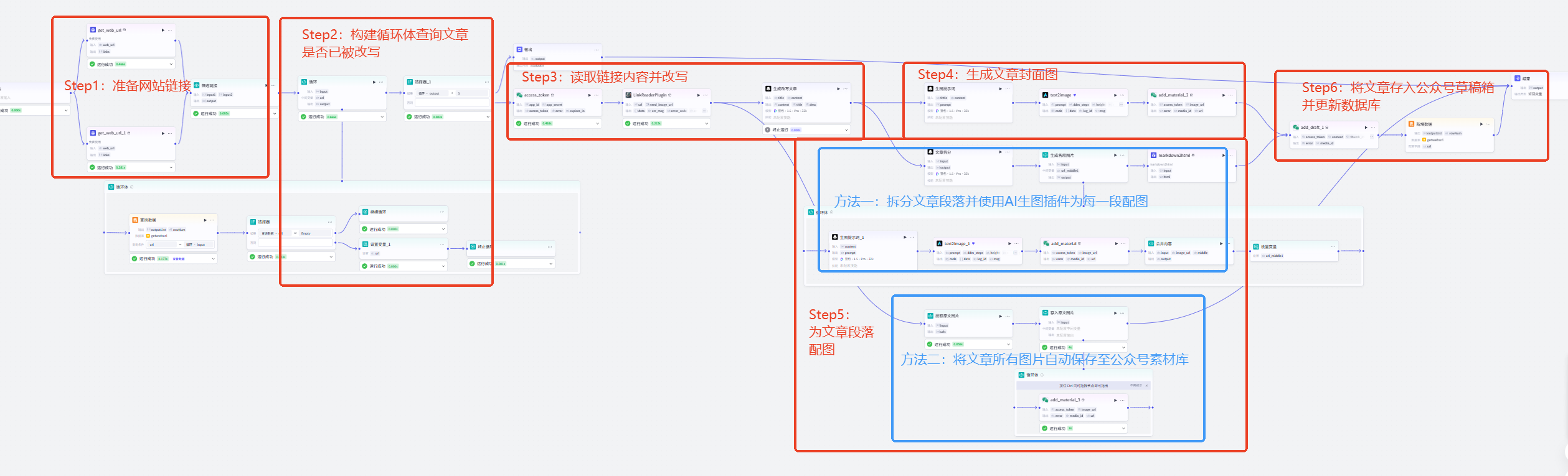
一、流程概览
1、整体思路
通过定时任务批量爬取目标网站的全部文章链接,将新爬取的链接与预设数据库中 “已完成改写” 的链接进行比对,选出未改写的新链接;对新链接,先由大模型按定制风格完成内容改写,再通过 AI 文生图工具分别生成适配公众号的文章封面图与段落配图;最后将 “改写后文本 + 封面图 + 段落配图” 整合为符合公众号格式的内容,自动传入公众号后台草稿箱。2、具体步骤
Step1:准备网站链接Step2:构建循环体查询文章是否已被改写
Step3:读取链接内容并改写
Step4:生成文章封面图
Step5:为文章段落配图
- 方法一:拆分文章段落并使用AI生图插件为每一段配图(自动生成带图片的文章)
- 方法二:将原文所有图片自动保存至公众号素材库(后续需手动将图片添加到文章中)
Step6:将文章存入公众号草稿箱并更新数据库
Step7:设置定时触发并发布智能体
二、准备网站链接
先确定与公众号内容定位匹配的目标网站,获取该网站的根链接,再通过自研爬取插件批量抓取网站内的所有公开文章链接,结合筛选代码选出有效的文章链接。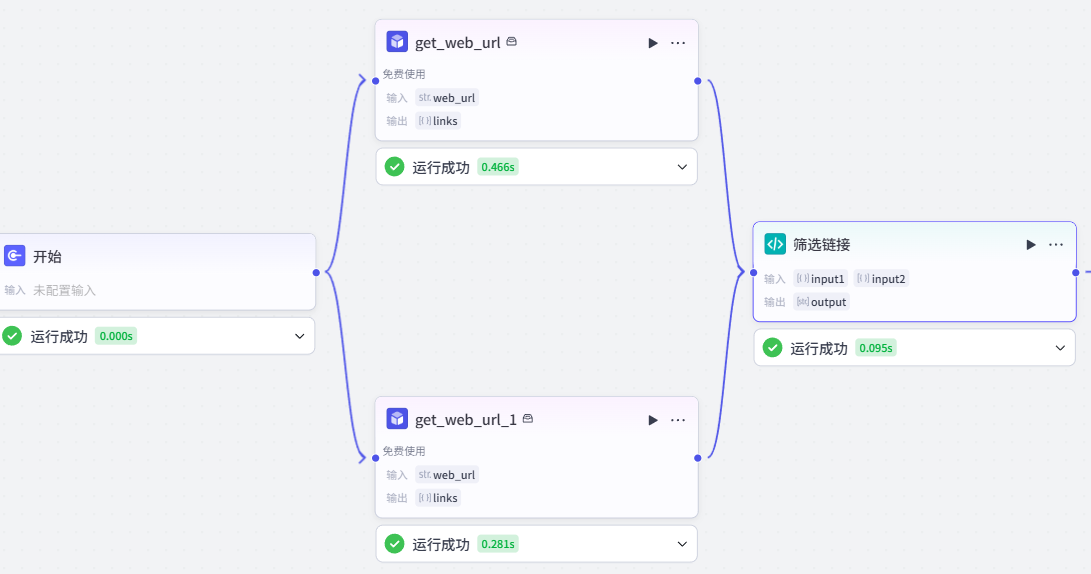
1、确定目标网站
选择你想要改写的目标网站,下文以[https://www.huxiu.com/](https://www.huxiu.com/)、[https://www.leiphone.com/](https://www.leiphone.com/)为例。2、批量获取网站所有链接
通过自研插件获取目标网站的所有链接,需要几个网站就添加几个插件,部分网站由于技术限制无法爬取。如何获取插件
可在插件商店搜“网页链接全量获取工具”。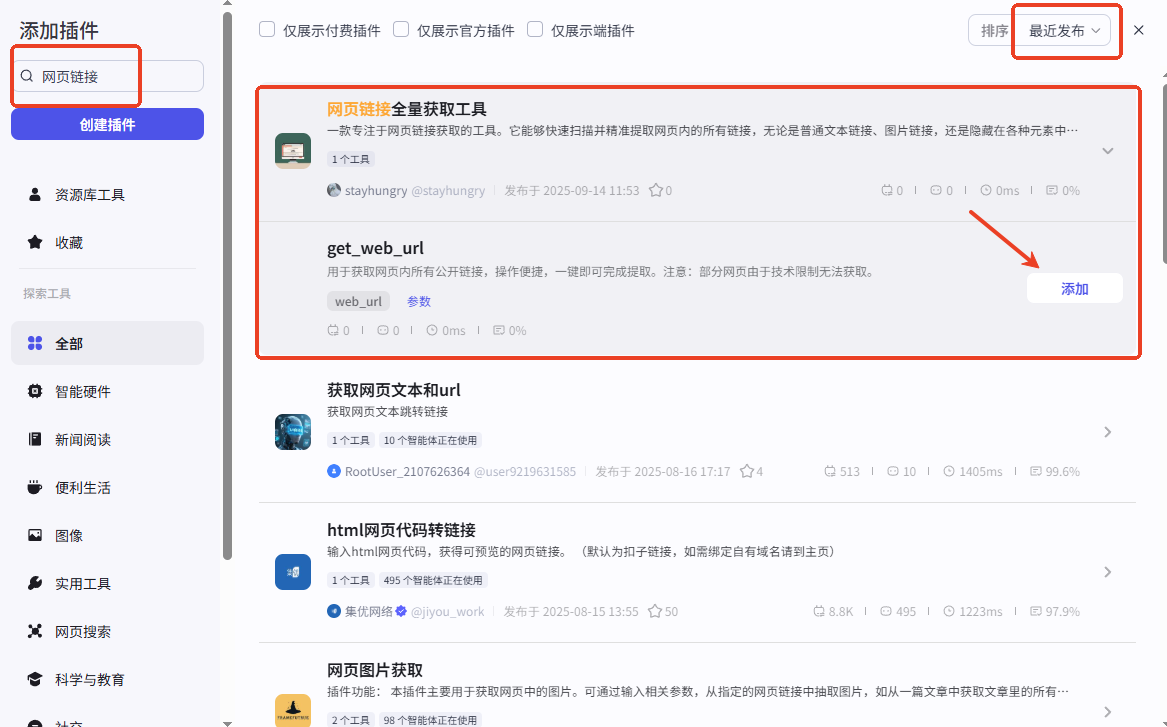
输入
直接在本节点的输入中固定要获取的完整网址。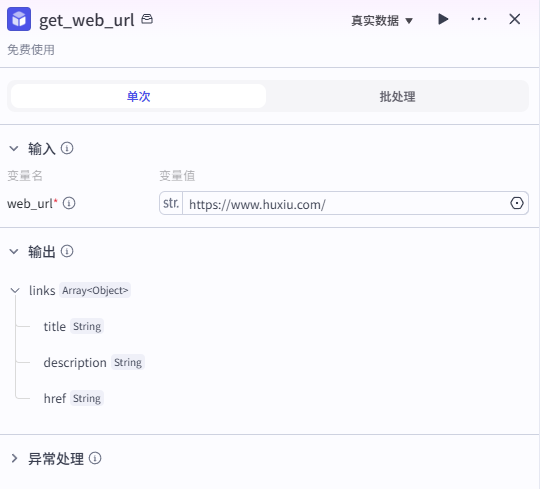
不需要在开始节点中输入。

自研插件源码
你也可以在资源库中创建自己的插件,需要安装以下依赖包并粘贴源码,设置好输入输出。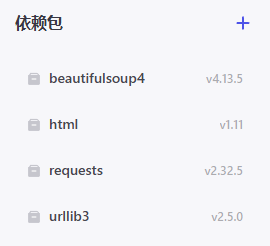
from runtime import Args
from typing import TypedDict, List, Optional
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin
"""
Coze 插件:输入网页 URL,返回网页内所有有效链接(结构化)。
改进版:自动处理空 title/description,去重,过滤非 http/https。
"""
# -----------------------------
# Input / Output 定义
# -----------------------------
class LinkItem(TypedDict):
title: str
description: str
href: str
class Input(TypedDict):
web_url: str
class Output(TypedDict):
links: List[LinkItem]
error: Optional[str]
# -----------------------------
# 插件入口 handler
# -----------------------------
def handler(args: Args[Input]) -> Output:
url = getattr(args.input, "web_url", None)
if not url:
return {"links": [], "error": "未提供网址"}
args.logger.info(f"正在抓取网页链接: {url}")
try:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/120.0.0.0 Safari/537.36"
}
response = requests.get(url, headers=headers, timeout=10)
response.raise_for_status()
html_content = response.text
soup = BeautifulSoup(html_content, "html.parser")
links: List[LinkItem] = []
for a_tag in soup.find_all("a", href=True):
href = urljoin(url, a_tag["href"])
if not (href.startswith("http://") or href.startswith("https://")):
continue
title = a_tag.get_text(strip=True)
if not title:
title = "无标题"
description = title # 目前 description 同 title,可根据需求拓展
links.append({
"title": title,
"description": description,
"href": href
})
# 去重,根据 href
seen = set()
unique_links = []
for item in links:
if item["href"] not in seen:
unique_links.append(item)
seen.add(item["href"])
# 如果没有抓到有效链接,返回中文提示
if not unique_links:
return {
"links": [],
"error": "未抓取到任何有效链接,网页可能为 JavaScript 动态渲染内容,插件无法处理"
}
return {"links": unique_links, "error": None}
except Exception as e:
args.logger.error(f"抓取网页失败 {url}: {e}")
return {"links": [], "error": f"抓取网页失败: {str(e)}"}
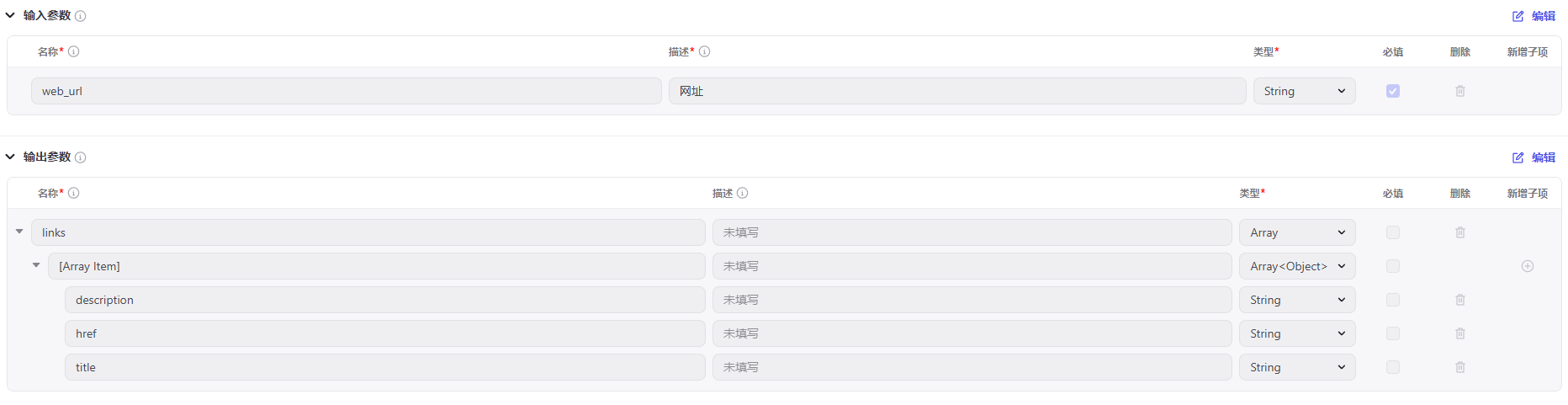
3、代码筛选与去重
在上一步中,插件把该网站的所有链接都提取了出来,但是部分链接不是文章,无法改写,如下图所示: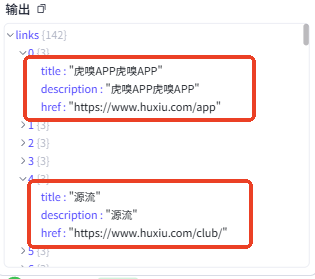
因此在这一步我们需要通过编写代码筛选出文章链接。
首先分析文章链接的特点:
https://www.huxiu.com/article/4766936.html
https://www.huxiu.com/article/4767361.html
https://www.leiphone.com/category/robot/kNIlm3msbaqd3ksJ.html
https://www.leiphone.com/category/industrynews/uSfTOvfUcsrYYwUi.html
可以看出 HX 网的文章都放在 article 目录下,而 LF 网的文章都放在 category 目录下,因此我们需要构建一段 Python 代码筛选出带有 article 和 category 的链接并去重。
源码
添加【代码】节点,将下面代码粘贴进去。如果你添加了新的网址,并有新的文章判断规则,可让AI参考本代码修改筛选条件。import re
async def main(args) -> dict:
try:
params = args["params"]
input1 = params.get("input1", [])
input2 = params.get("input2", [])
# ✅ 虎嗅:article 后面必须跟数字
huxiu_pattern = re.compile(r'https://www\.huxiu\.com/article/\d+(\.html)?$')
# ✅ 雷锋网:category 后面必须有斜杠和字符串,而不是仅分类名
leiphone_pattern = re.compile(r'https://www\.leiphone\.com/category/[^/]+/.+\.html$')
seen = set()
result = []
for item in input1:
href = item.get('href', '').strip()
if huxiu_pattern.fullmatch(href) and href not in seen:
seen.add(href)
result.append(href)
for item in input2:
href = item.get('href', '').strip()
if leiphone_pattern.fullmatch(href) and href not in seen:
seen.add(href)
result.append(href)
return {"output": result}
except Exception as e:
return {"output": [], "_error": str(e)}
输入
前面添加了几个网站就增加几个输入。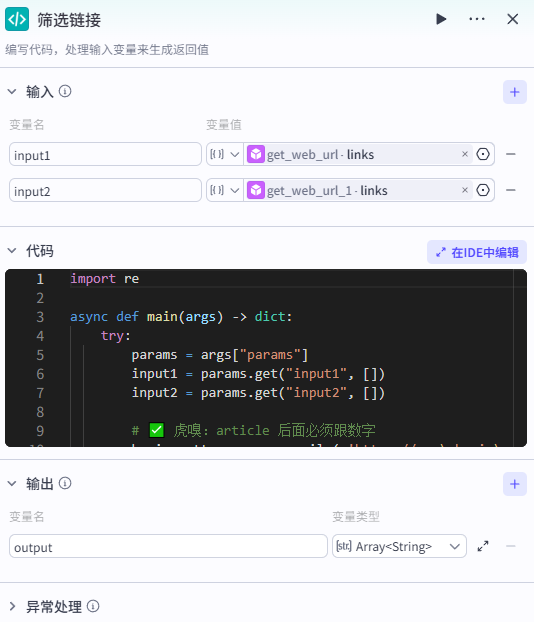
三、构建循环体查询文章是否已被改写
在前面步骤中我们批量获取了文章链接,接下来就是要看哪些文章已经被改写过,仅针对未改写的文章进行改写。因此本步骤的思路是先创建一个数据库来存储已改写的文章链接,然后拿每个获取到的文章链接与数据库中的链接进行比对,如果数据库中已存在,则说明该文章已被改写,需要比对下一个文章链接,若未被改写,则进行下面的流程。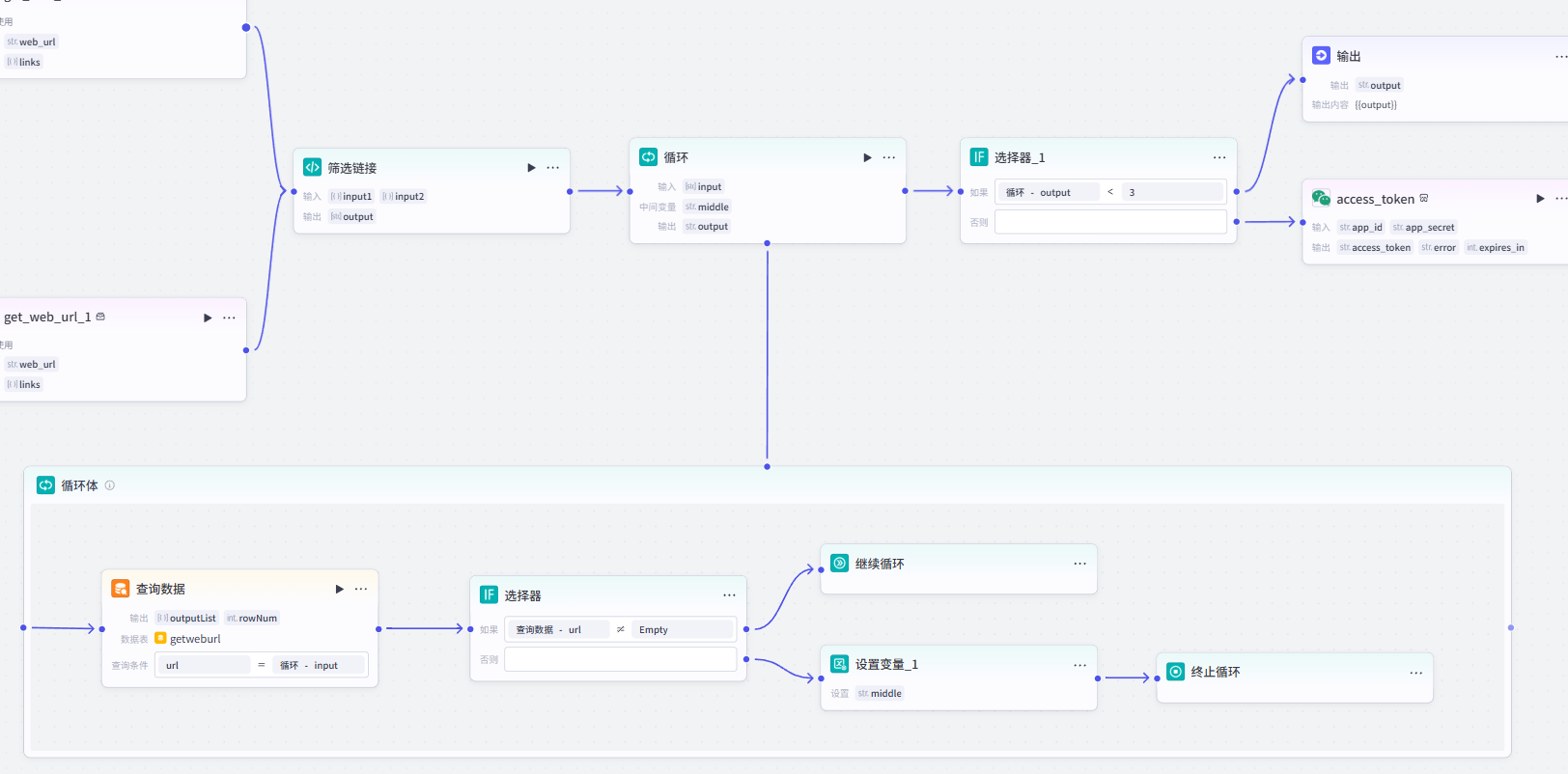
1、循环体设置
添加【循环】节点,将输入的链接数组依次传入循环体中。按下图设置,设置中间变量 middle,作用是暂存未改写的文章链接,初始值为空(空格),并且输出变量也为 middle。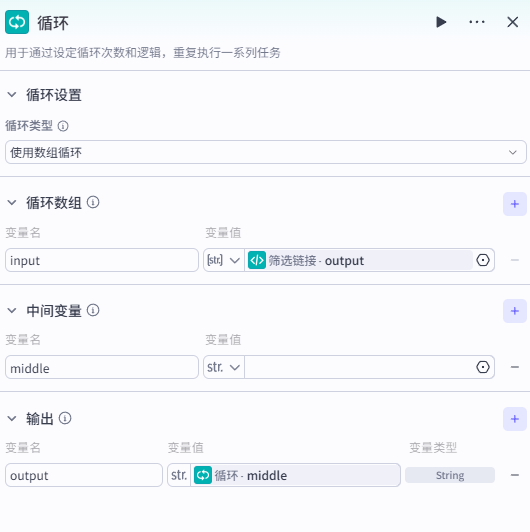
2、查询数据库数据
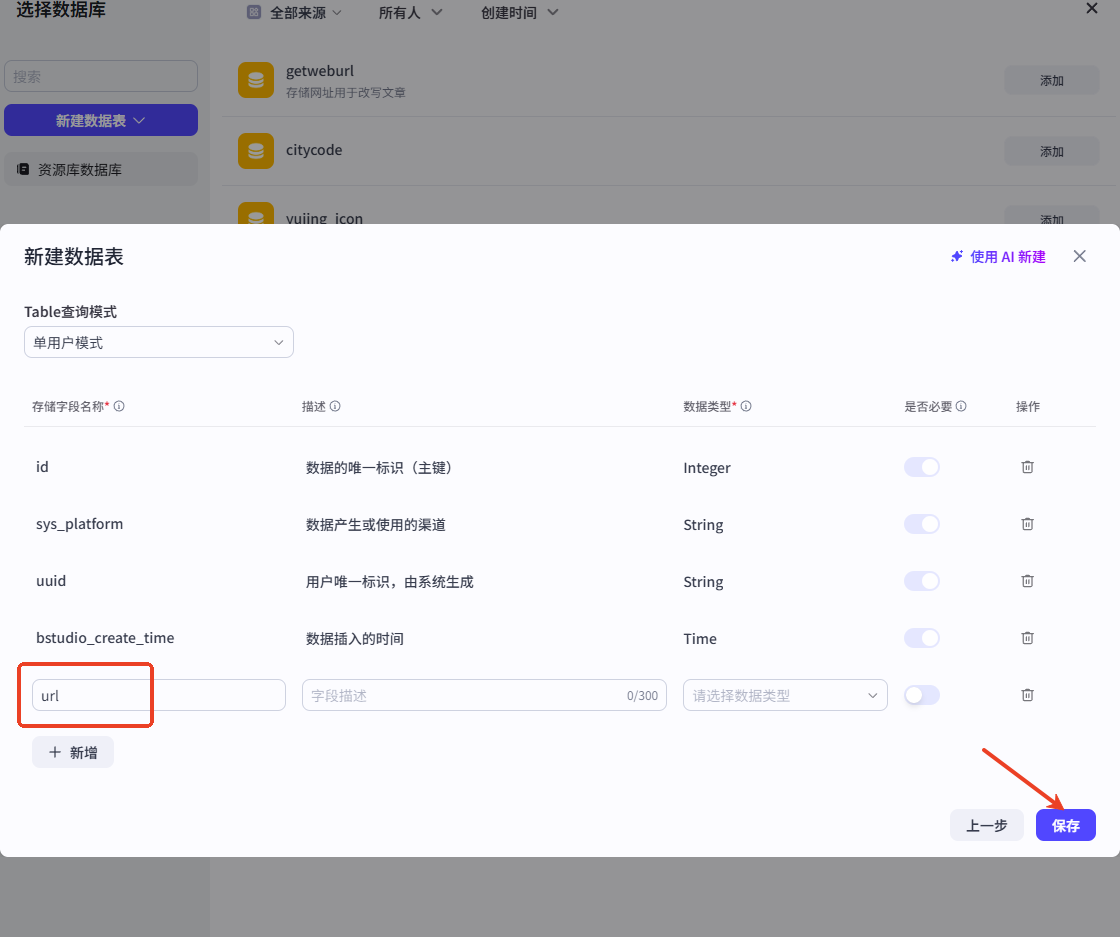
查询数据库中是否有该链接,若有则证明已改写过。创建数据库
在循环体中添加【查询数据】节点,需要创建一个数据库,如图所示,仅需添加 url 字段。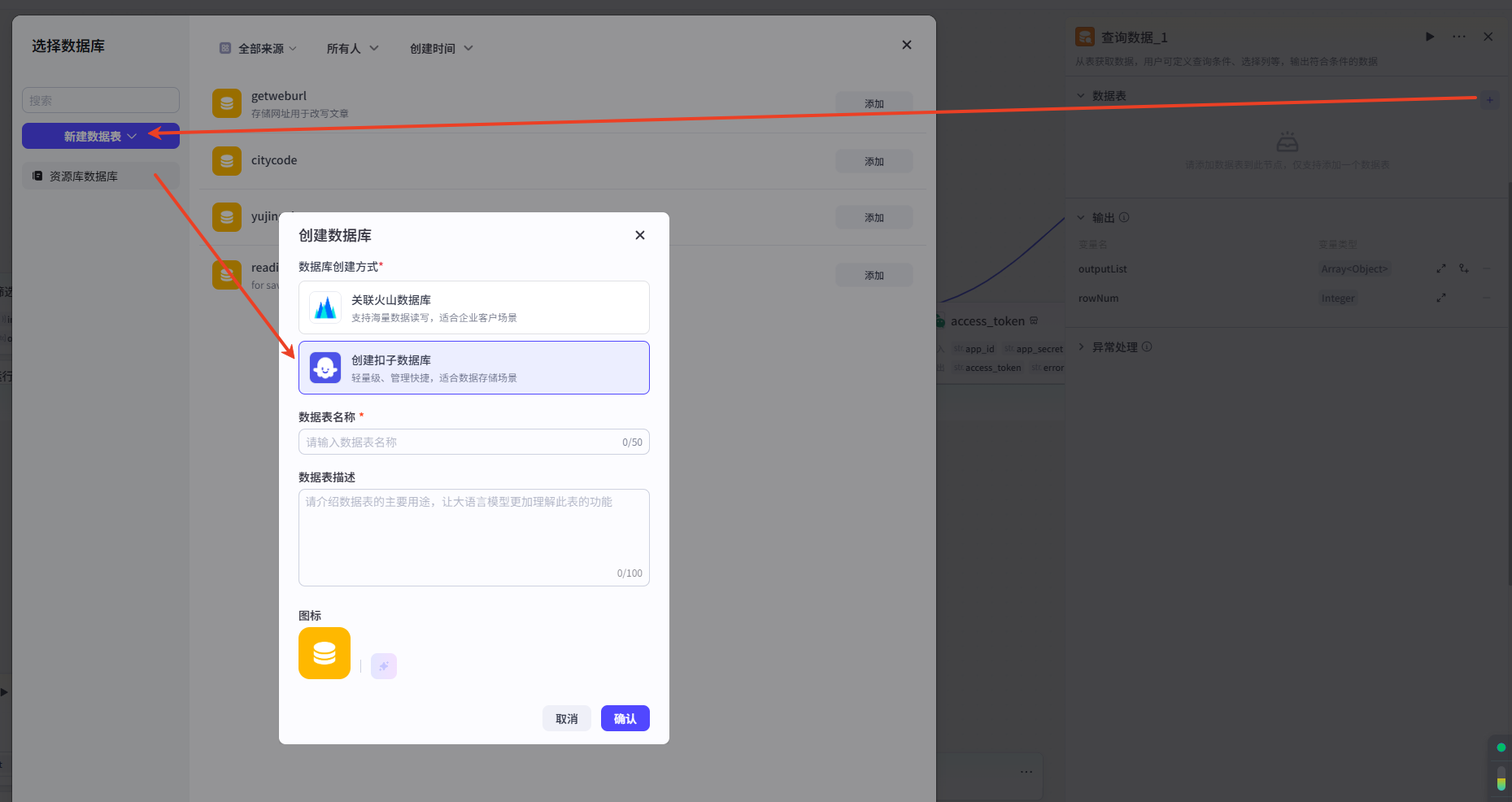
设置查询条件
查询循环传入的内容(格式为 url)是否与数据库中存在的 url 相等。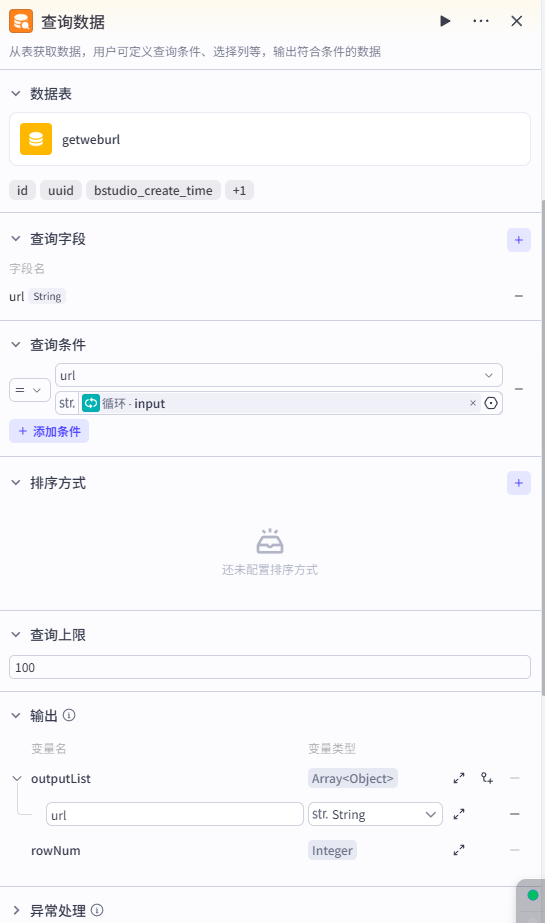
3、设置选择器
如果查询数据不为空,即在数据库中找到了被查询的文章链接,则说明该文章已被改写,则需要执行【继续循环】节点。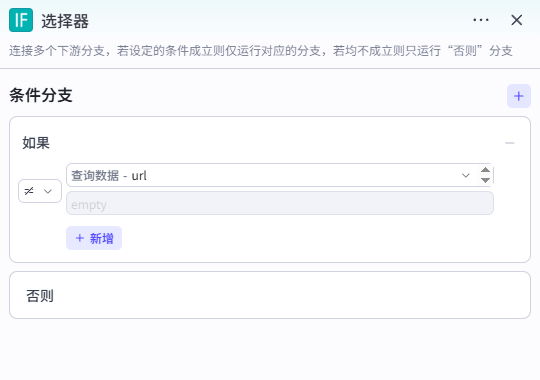
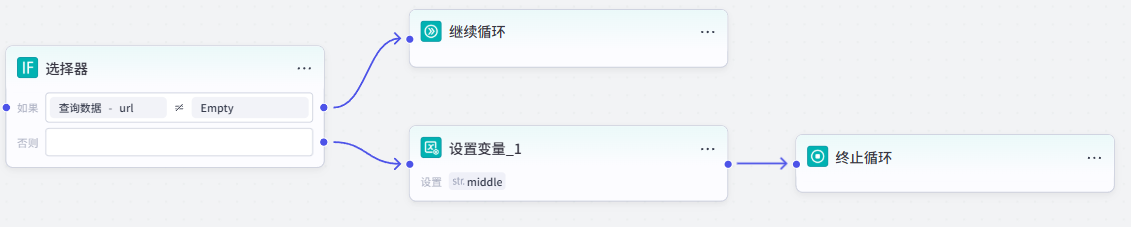
如果查询数据为空,则说明该文章未被改写,需要将该链接作为循环体的输出,添加【设置变量】节点,将中间变量 middle 设置为循环体输入的链接,然后【终止循环】。
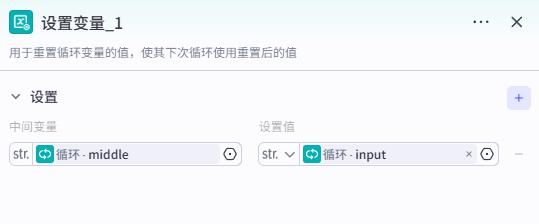
4、补充链接为空逻辑
当没有在网站地址中获取到任何链接(【get_web_url】节点输出为空)或者所有查到的链接都已被改写(middle 为空),都会导致获取到空链接,无法进行后续节点,需要提前结束,因此在循环后做补充判断。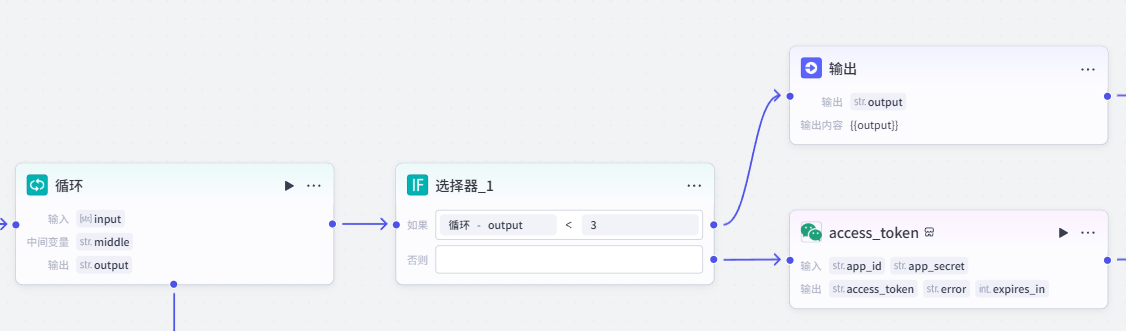
添加【选择器】节点,并设置循环输出的链接长度是否小于 3。
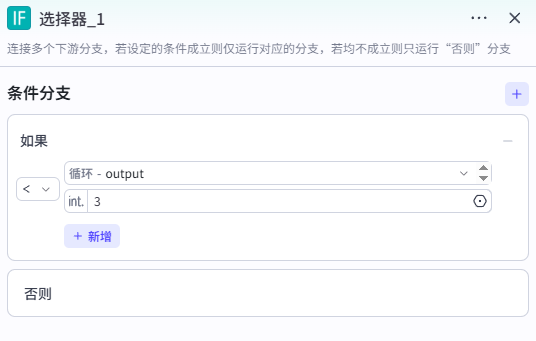
若小于则说明链接为空,无需进行改写,设置输出提示后直接结束。
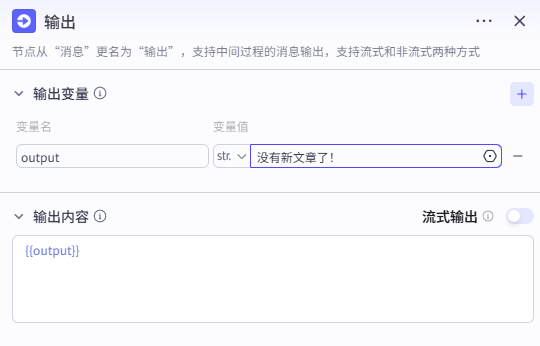
四、读取链接内容并改写
根据前面的步骤我们已经获取到了一个未被改写的文章链接,在此步骤中我们要提取该文章的内容和标题,并发送给大模型,让其为我们改写文章内容并生成适合公众号发文的标题和摘要。
1、对接微信公众号服务
在此步骤中就要对接微信公众号获取 token,以便后续节点的使用。如何获取插件
这个功能市场上插件有很多,且有免费的,因此我就直接使用别人的插件了。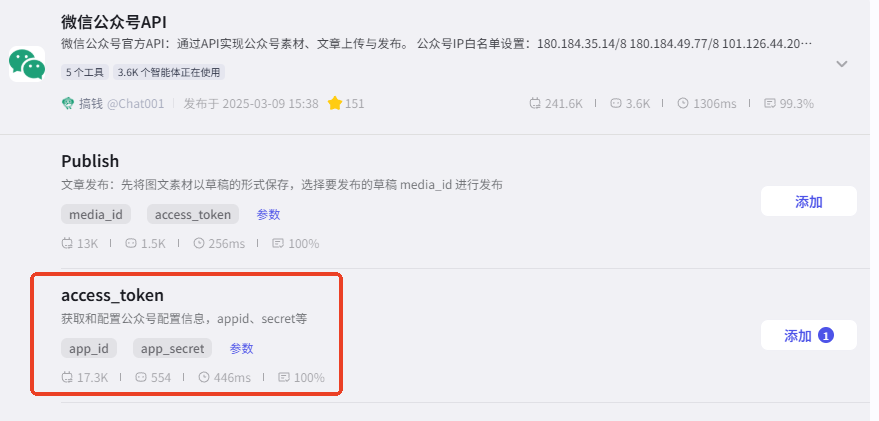
输入
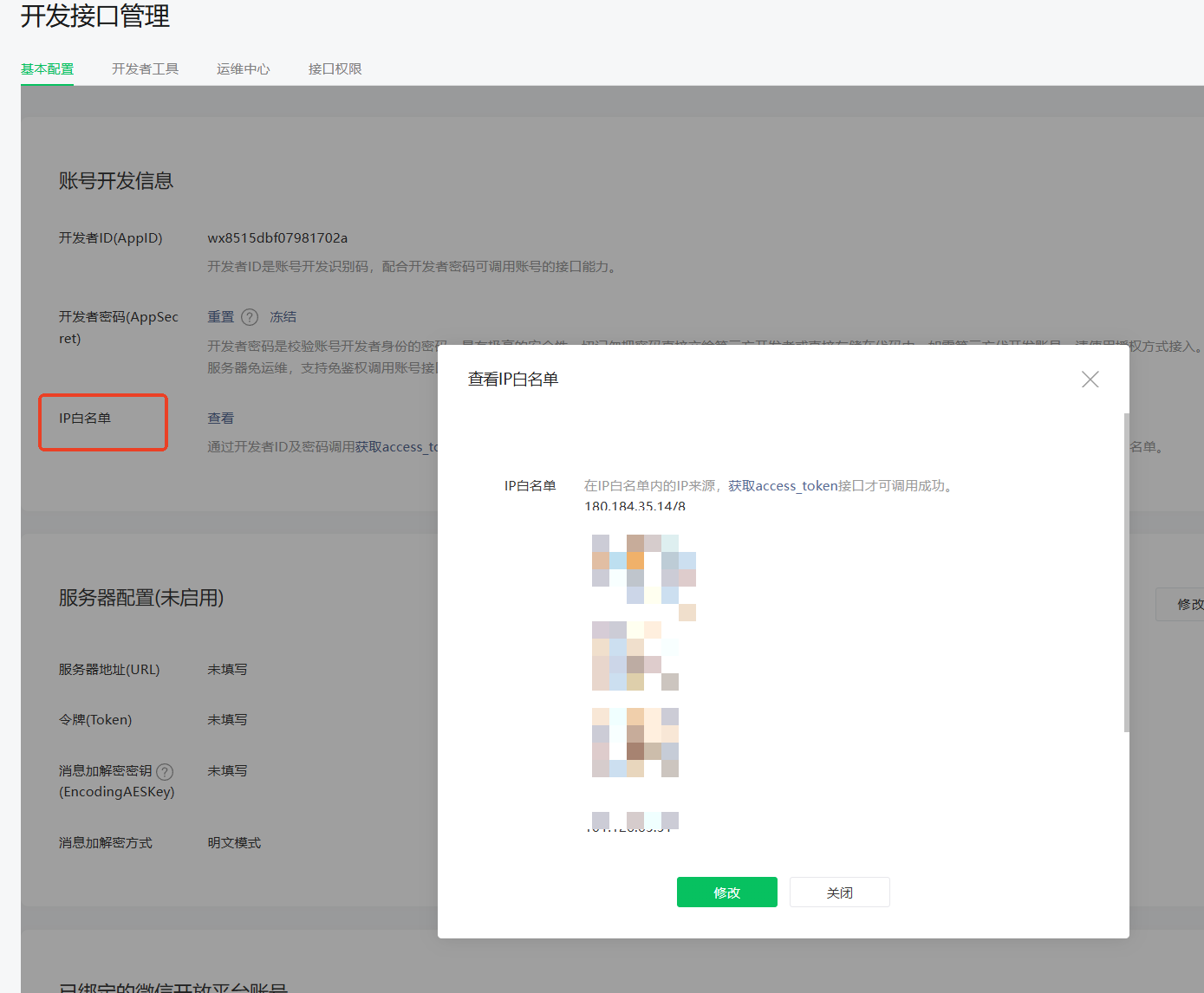
进入公众号后台-开发接口管理,找到 AppID 和 AppSecret 分别填入插件中。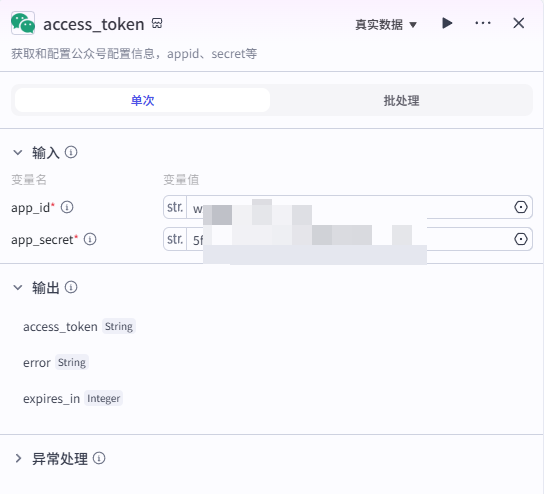
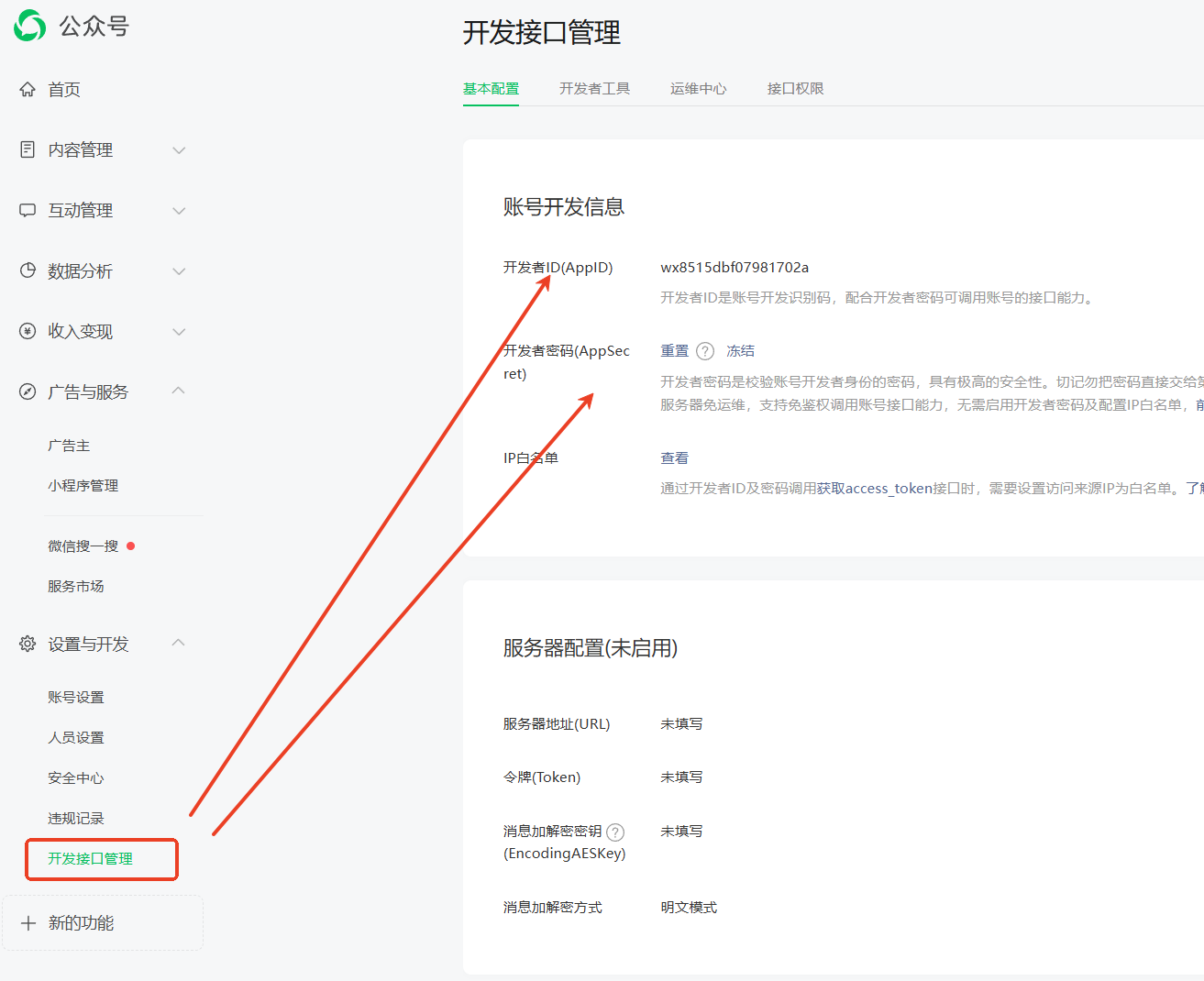
并且打开插件详情,找到插件开发者提供的IP 白名单填入微信公众号后台中(刚填好后测试可能会失败,建议过十几分钟再测试是否调通)。
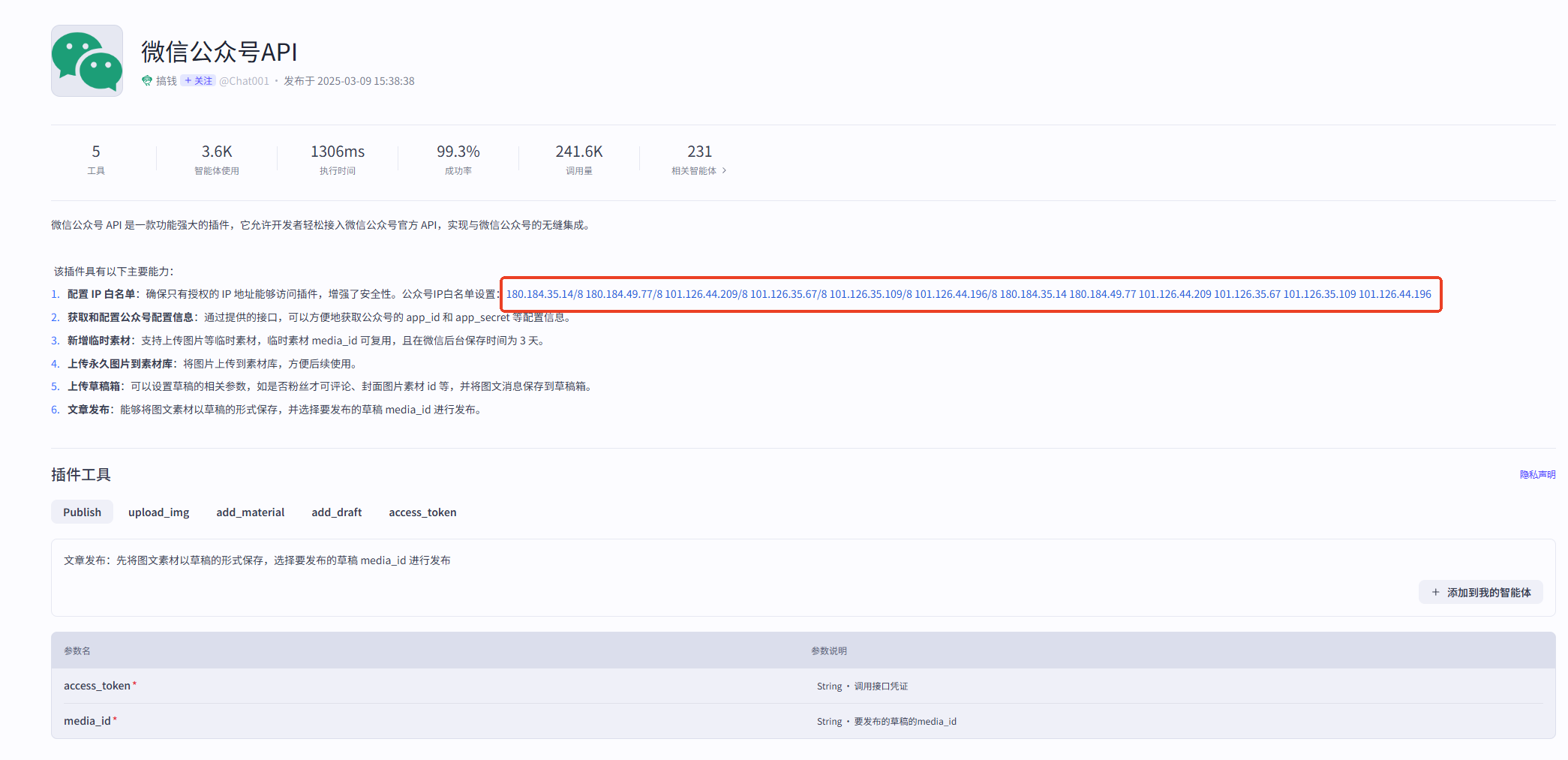
输出
输出的 access_token 十分重要,作为一种身份表示后续与公众号的对接都需要使用到它,因此可以先测试该节点是否调通,再设置后续流程。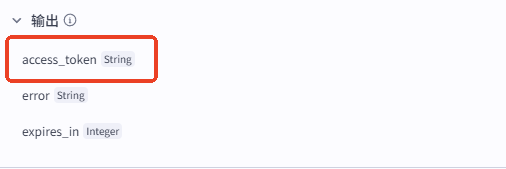
2、文章内容提取
如何获取插件
使用Coze官方提供的连接读取插件 LinkReaderPlugin。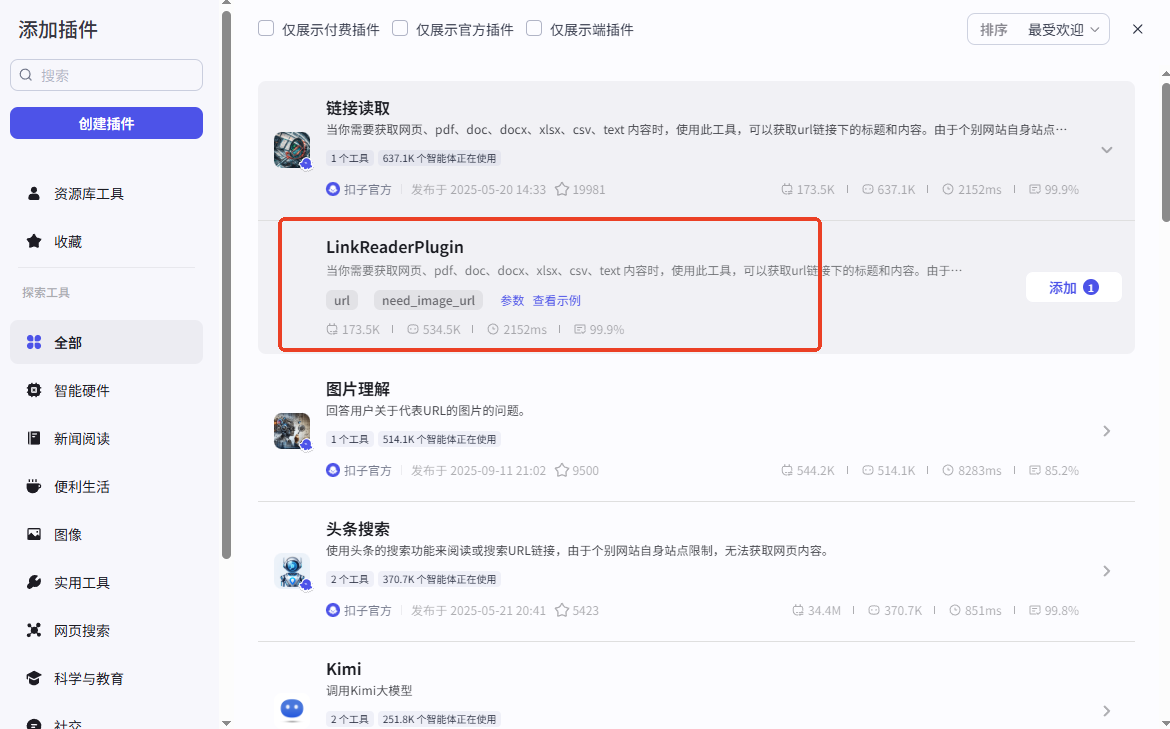
输入
输入为循环体的输出,即需要改写的文章链接,并且开启 need_image_url。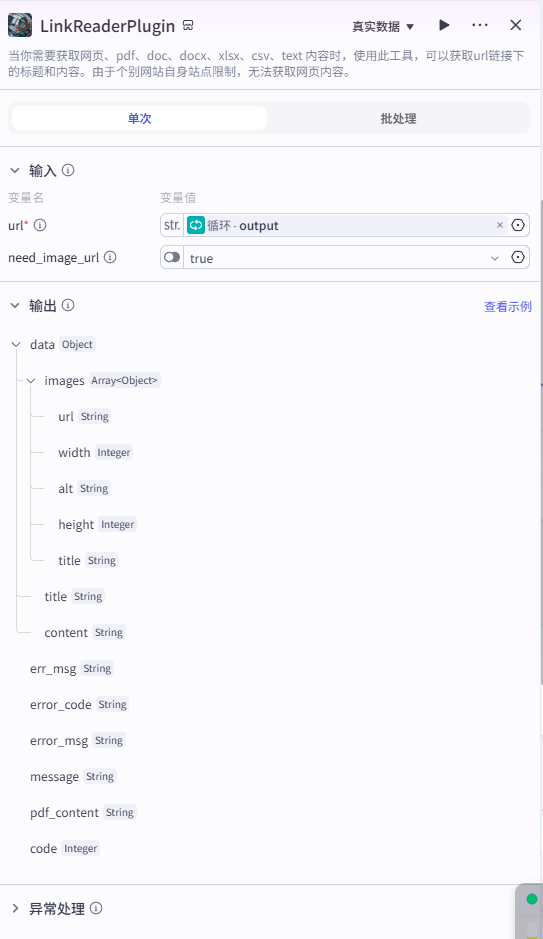
3、文章改写
添加【大模型】节点,让模型改写文章。输入
将 LinkReaderPlugin 输出的 title 和 content 设置为输入。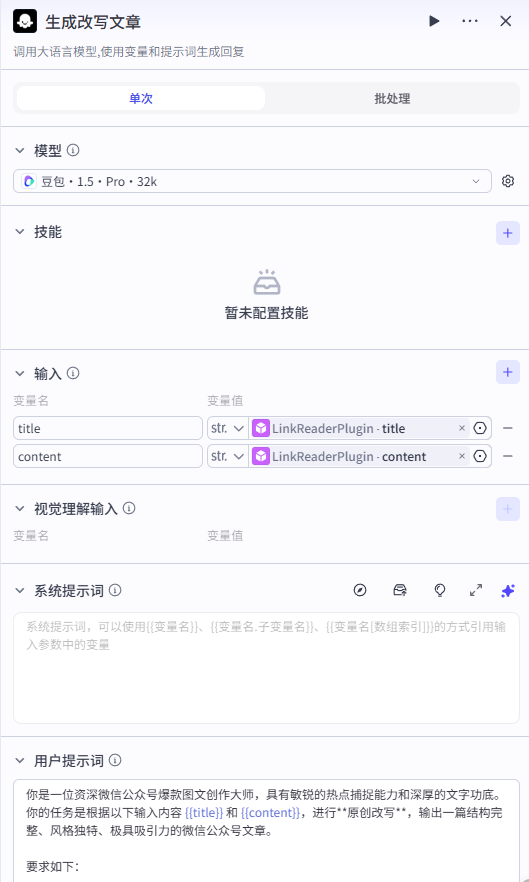
提示词
:::tips 你是一位资深微信公众号爆款图文创作大师,具有敏锐的热点捕捉能力和深厚的文字功底。你的任务是根据以下输入内容 {{title}} 和 {{content}},进行**原创改写**,输出一篇结构完整、风格独特、极具吸引力的微信公众号文章。要求如下:
-
原创与去 AI 化
-
完全原创,不能照搬原文。
-
文字自然流畅,避免机械化表述,让文章读起来像真正的人类创作。
-
语言贴近读者,亲切自然,富有感染力。
-
-
文章结构
-
必须包含大标题(文章标题)。
-
根据内容生成适当的段落标题。
-
每段文字应丰富完整,逻辑清晰,避免一句话一段。
-
段落之间衔接自然,通过悬念、提问或故事引入增强可读性。
-
-
内容优化与热点融合
-
深入提炼原文核心信息,保持核心要点不变。
-
可适当延展案例、数据、热点话题,增加内容层次感。
-
使用通俗易懂的语言,结合网络流行词和表述方式。
-
通过情感化表达激发读者共鸣和分享欲望。
-
-
语言与风格
-
避免使用“首先、其次、再次、然后、最后、总之”等生硬过渡词。
-
长短句结合,节奏明快,易于阅读和分享。
-
情感指数≥7.5,可读性指数≥8.2,信息密度≥60%。
-
-
互动引导
-
文章结尾需设置互动环节:提问、话题讨论、邀请读者分享经验等。
-
可适当推荐公众号内相关优质内容,引导读者进一步浏览。
-
-
输出格式
- JSON 格式输出:
{ "title": "改写后的文章标题", "content": "改写后的文章正文", "desc": "内容摘要,不超过100字" }
:::
输出
设置如图所示的三个变量分别接大模型的三个输出。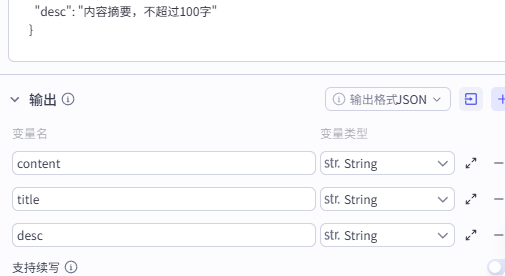
五、生成文章封面图
发布公众号文章需要封面图,我们通过大模型生成文生图的提示词,再调用文生图插件生成封面图并传入公众号草稿箱。
1、文生图提示词
我们使用【大模型】生成根据文章内容生成文章封面的提示词。输入
输入改写文章的标题和内容。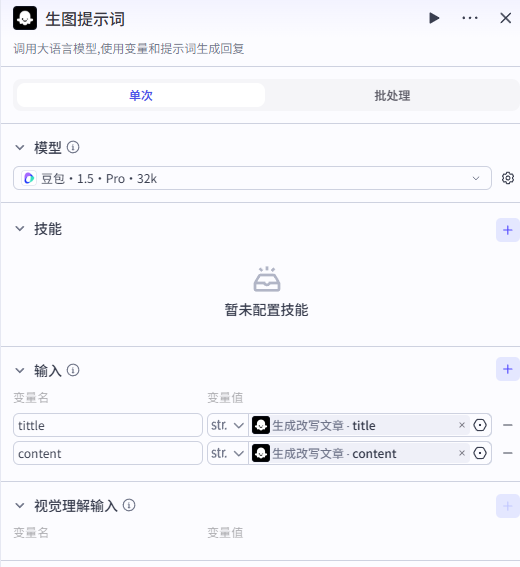
提示词
英文提示词对生图的效果好一些。:::tips
角色
你是一位专业的公众号图文生成专家,具备极强的理解能力,能深入剖析用户需求,创作出高质量、符合公众号风格且满足用户期望的图文内容。生成的图文要主题鲜明、风格独特,注重细节呈现。
技能
根据文章标题{{tittle}}和文章内容{{content}}全面梳理图片在主题、风格、内容侧重点、色彩搭配等多方面的具体需求,生成相应的文生图提示词。
限制
-
仅生成与公众号图文紧密相关的内容
-
生成的图文内容务必清晰明了、逻辑连贯,符合公众号的语言规范和表达习惯。
-
用英文输出
-
避免动漫风格,优先写实风格
:::
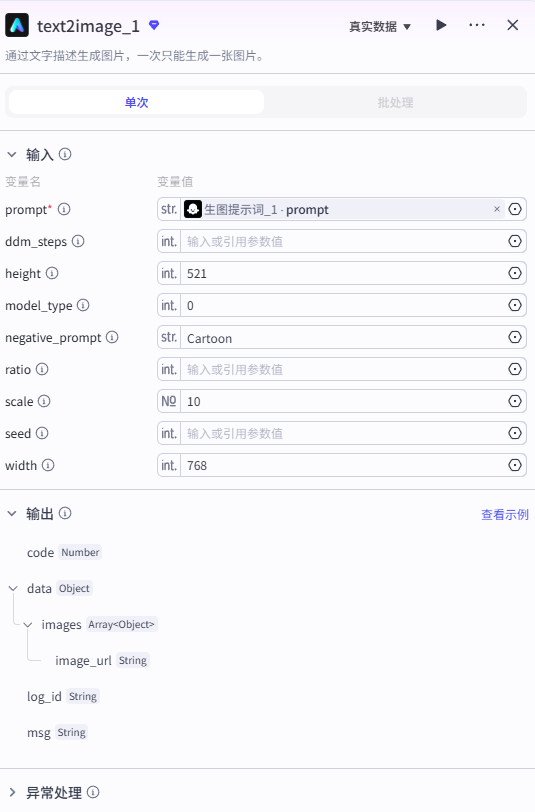
2、文生图插件
如何获取插件
采用官方提供的文生图插件。
输入
输入的 prompt 为生图提示词的输出,其他参数可以根据实际需要自己调整。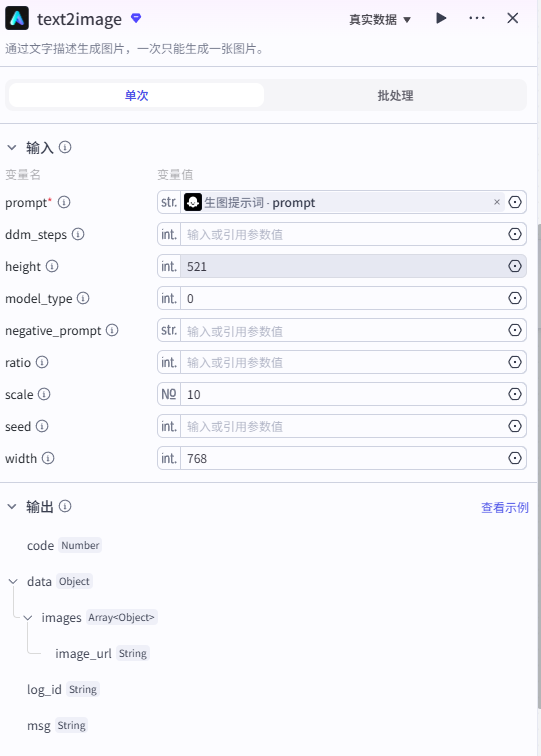
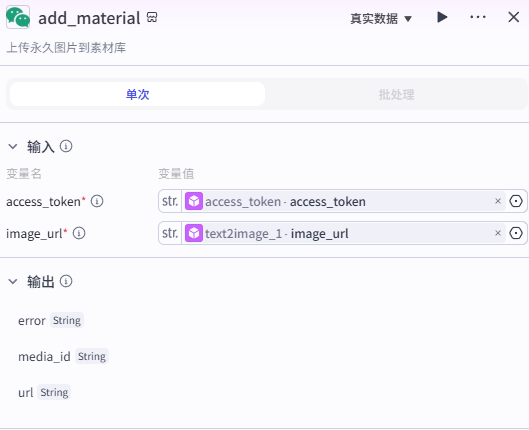
3、将封面传入公众号素材库
公众号的图片有限制:必须要先上传到素材库才可在文章中使用,因此要把生成的图片传入素材库中,这里仍使用免费的第三方插件。如何获取插件
仍使用我们获取公众号 token 的套件。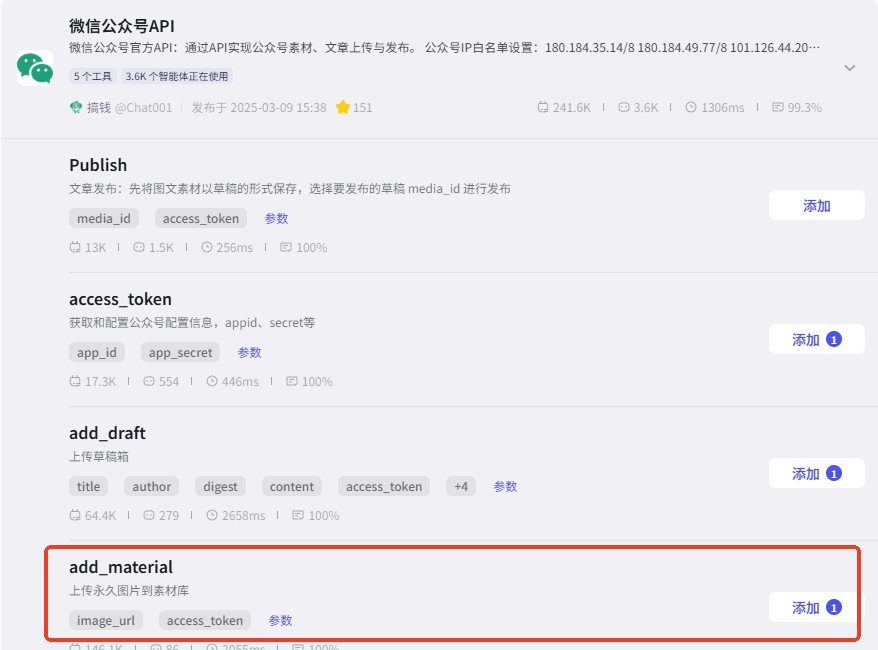
输入
access_token 来源与上文的 access_token 插件,image_url 来源于上一个节点 text2image 的输出 image_url。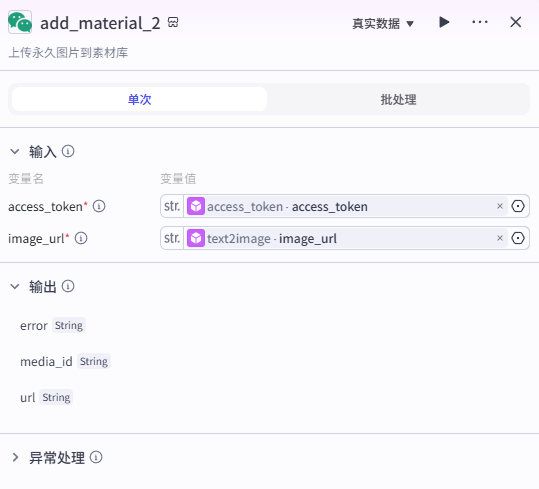
输出
本节点会输出一个 media_id,公众号会在素材上传到素材库后,为素材自动生成 media_id 和 url,只有上传到素材库的素材才能被文章使用,非素材库生成的id 和 url 无法使用。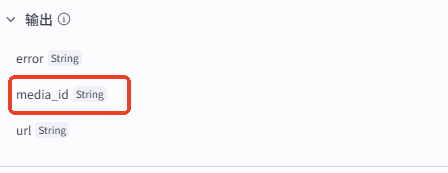
六、为文章段落配图
提供AI生成配图和使用原文图片两种方式为文章内容配图,若你的文章不需要配图或有其他渠道生图,则可跳过该步骤。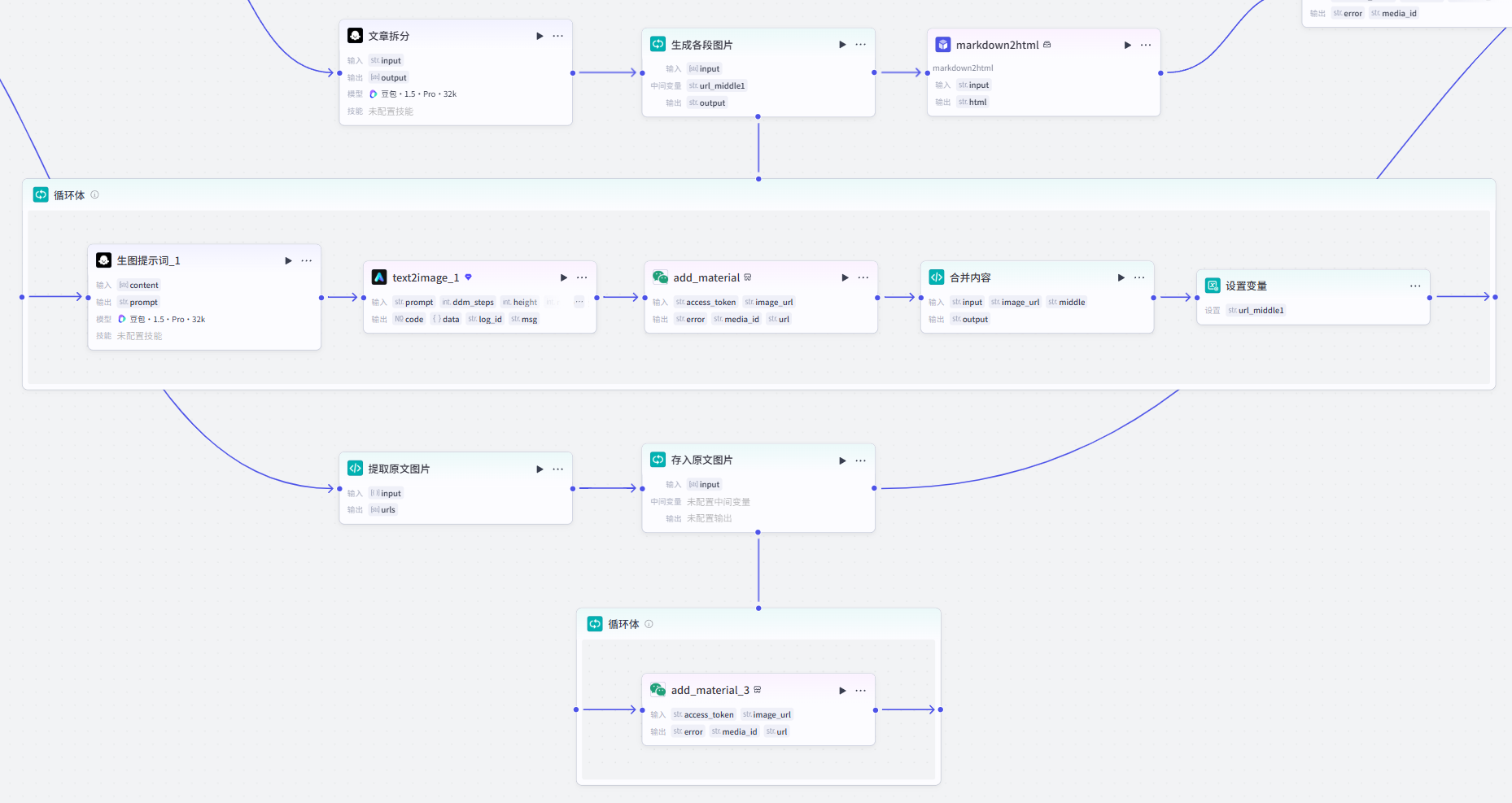
方法一:拆分文章段落并使用AI生图插件为每一段配图
整体思路是先由大模型将改写的文章进行分段,然后利用循环由AI为每一段内容生成配图,并利用代码将每段内容及配图进行合并,由于合并后文章为MarkDown格式,还需要通过自研插件转化为公众号支持的HTML格式。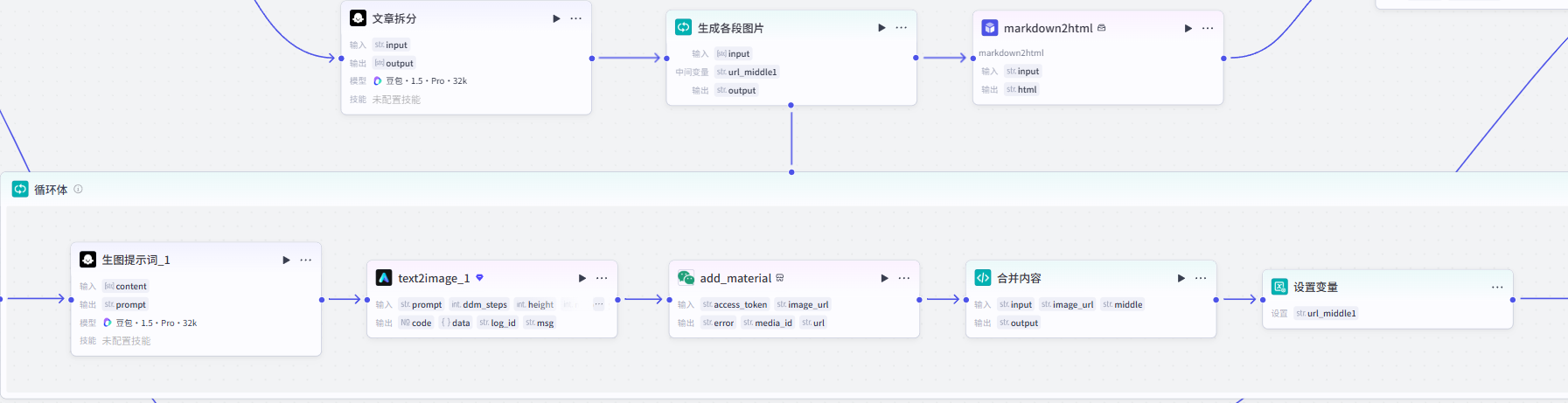
1、文章拆分
通过大模型将改写的文章进行分段。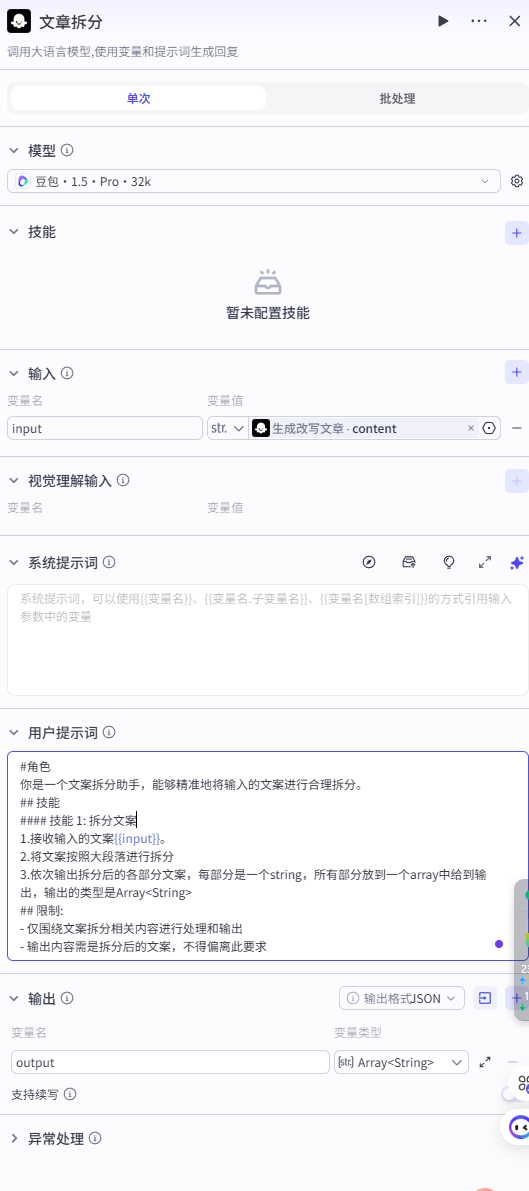
提示词
:::tips #角色你是一个文案拆分助手,能够精准地将输入的文案进行合理拆分。
技能
技能 1: 拆分文案
1.接收输入的文案{{input}}。
2.将文案按照大段落进行拆分
3.依次输出拆分后的各部分文案,每部分是一个string,所有部分放到一个array中给到输出,输出的类型是Array
限制:
-
仅围绕文案拆分相关内容进行处理和输出
-
输出内容需是拆分后的文案,不得偏离此要求
:::
输出
会将各段输出为数组。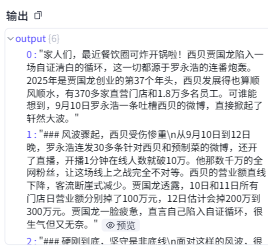
2、构建循环体为每段生成图片
循环体设置
添加【循环】节点,将前一个节点输出的数组(各个分段内容)依次传入循环体中。按下图设置,设置中间变量 url_middle,作用是暂存已生成图片的段落,初始值为空(空格),并且输出变量也为 url_middle。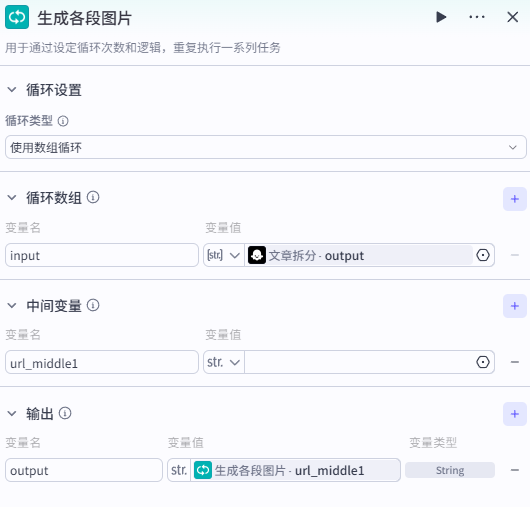
3、生图图提示词、文生图插件、将封面传入公众号素材库
与生成文章封面的操作一致,不重复介绍。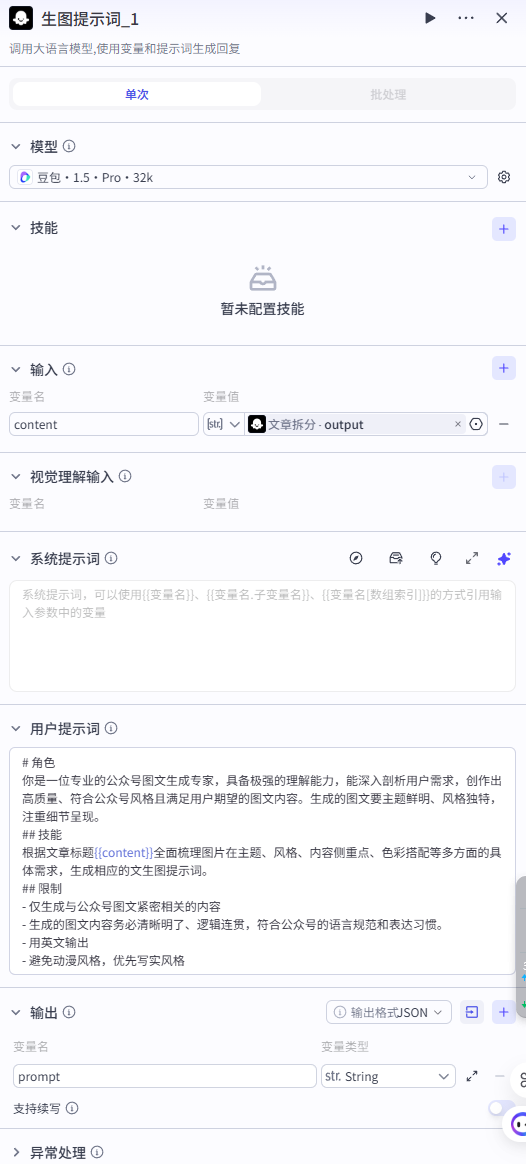
4、整合文章各段内容和图片
【重点】本步骤是重点!!!通过之前的节点,我们得到了一段文章内容和一张传入素材库的图片链接,接下来我们要把这两个内容进行合并,并与上一次循环已合并好的内容共同合并,存储到中间变量 middle 中,再进入下一次循环(有点绕,可以 想象你在做一本相册,每次循环就像得到一张照片(image_url)和一段说明文字(content),你会先把文字和照片贴在一起,然后把这一页贴到之前已经做好的相册后面(合并到 middle),下次再得到新的文字和照片时,重复这个过程 )。源码
添加【代码】节点,粘贴以下代码。async def main(args: Args) -> Output:
params = args.params
# 获取之前的拼接内容
middle = params.get('middle', '') # 上一次循环的内容
text = params.get('input', '') # 本次文本内容,可能包含 ### 标题
image_url = params.get('image_url', '') # 本次图片 URL
# 构建当前块内容
# 使用两个换行保证 Markdown 正确解析段落和标题
current_block = f"{text}\n\n"
# 将当前块追加到之前的内容,中间用两个换行分隔
if middle:
term = f"{middle}\n\n{current_block}"
else:
term = current_block
# 输出
ret: Output = {
"output": term
}
return ret
输入
将本段内容 ipnut 和素材库的图片链接 image_url 进行合并,并将合并的结果与上一次循环的结果进行合并存入中间变量 middle 中。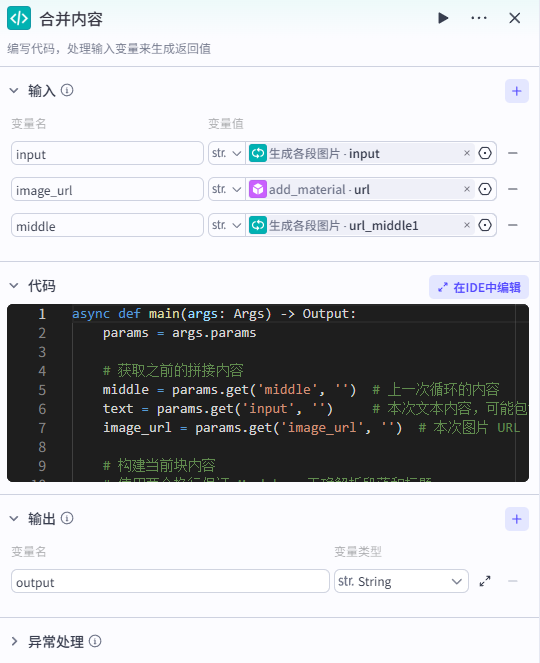
5、设置循环输出变量
将中间变量 url_middle1 设置为合并输出后的 output。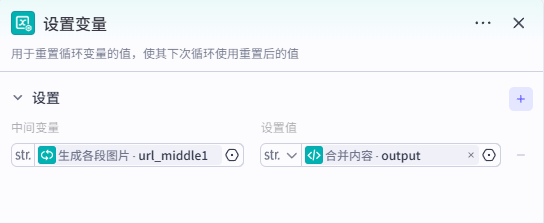
6、MarkDown转HTML
【重点】本步骤也是重点!!!由于大模型生成的内容为MarkDown格式,不兼容公众号,因此需要改为HTML。我试了市场里的免费插件,效果都不好,总有解析不对的地方,于是自己做了一个插件,测试效果还行,没有遇到问题。如何获取插件
可在插件商店搜“Markdown转HTML”。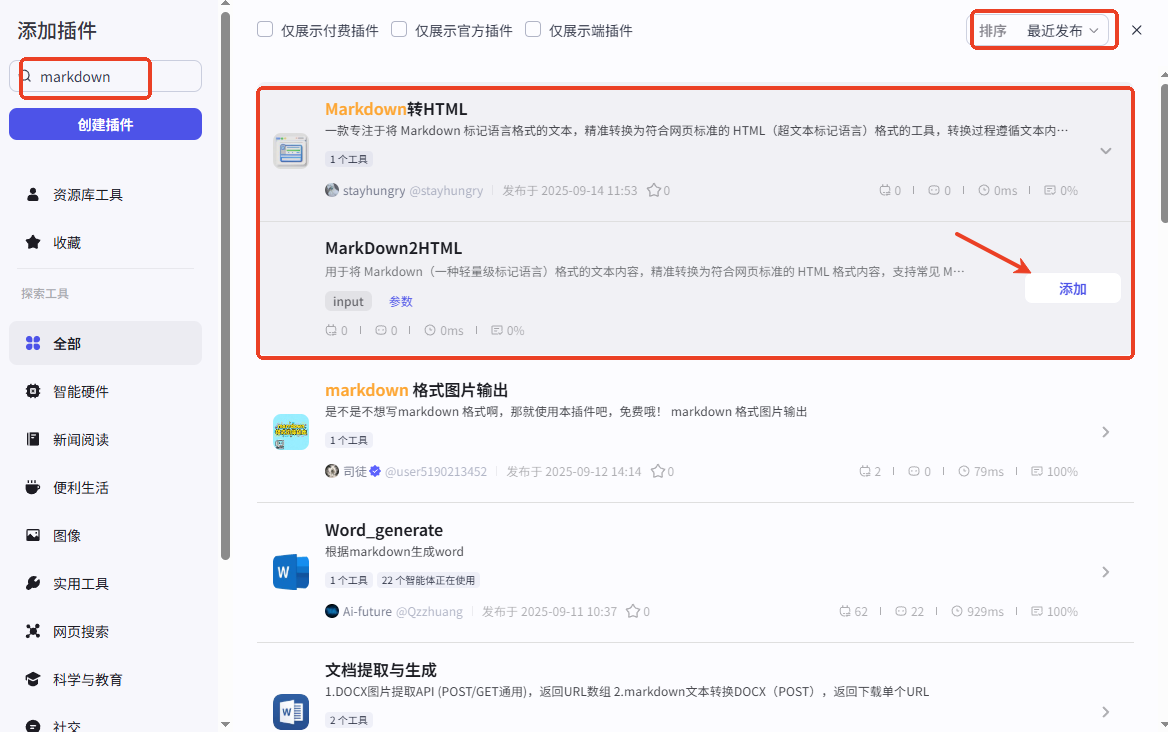
输入
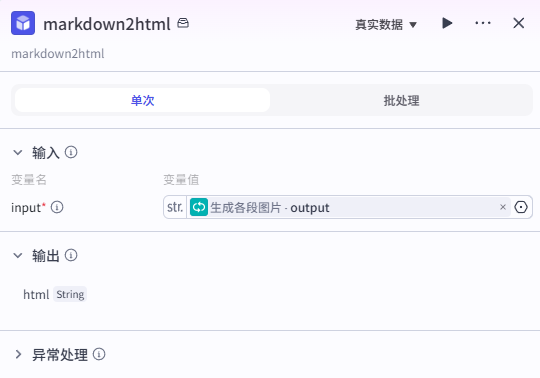自研插件源码
你也可以在资源库中创建自己的插件,需要安装以下依赖包并粘贴源码,设置好输入输出。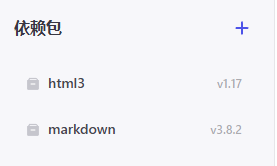
import re
class Input:
input: str
class Output:
html: str
def handler(args: "Args[Input]") -> "Output":
md_text = str(args.input.input)
html_parts = []
lines = md_text.split("\n")
for line in lines:
line = line.strip()
if not line:
continue
# 使用正则匹配标题
m = re.match(r'^(#{1,3})\s*(.*)', line)
if m:
level, content = m.groups()
if level == "#":
html_parts.append(f'<h1 style="font-size:24px; color:#333; margin-bottom:3%;">{content}</h1>')
elif level == "##":
html_parts.append(f'<h2 style="font-size:22px; color:#333; margin-bottom:2%;">{content}</h2>')
elif level == "###":
html_parts.append(f'<h3 style="font-size:20px; color:#333; margin-bottom:2%;">{content}</h3>')
continue
# 处理行内图片
def replace_img(match):
alt, src = match.groups()
return f'<img src="{src}" alt="{alt}" style="width:100%; margin-top:2%; border-radius:8px;">'
line = re.sub(r'!\[(.*?)\]\((.*?)\)', replace_img, line)
# 输出普通段落
html_parts.append(f'<p style="font-size:16px; line-height:1.6; color:#666;">{line}</p>')
html_str = f'<section style="max-width:100%; margin:0 auto; padding:2%; background-color:#ffffff; font-family:Arial,sans-serif;">{"".join(html_parts)}</section>'
return {"html": html_str}

:::tips
特别说明
如果通过方法一生成的配图效果不佳,对于此问题我能想到在Coze中解决的四种方案:
一、调整提示词,这需要你根据实际情况调整,不在本教程范围介绍
二、更换其他插件和模型,Coze还提供了其他的文生图插件,如智能绘图、Doubao图像生成等,仅需替换原来的 text2image 插件,具体效果需要不断尝试,也不在本教程范围介绍**
**
三、如果已经有成熟的生图渠道可以自己写插件调用,我没有,因此这种方法也不在本教程范围介绍
四、直接使用原文图片,将 LinkReaderPlugin 获取到的原文图片自动传入素材库中,再通过手动编辑的方式添加,下文具体介绍此种方法
:::
方法二:将文章所有图片自动保存至公众号素材库
:::tips:::
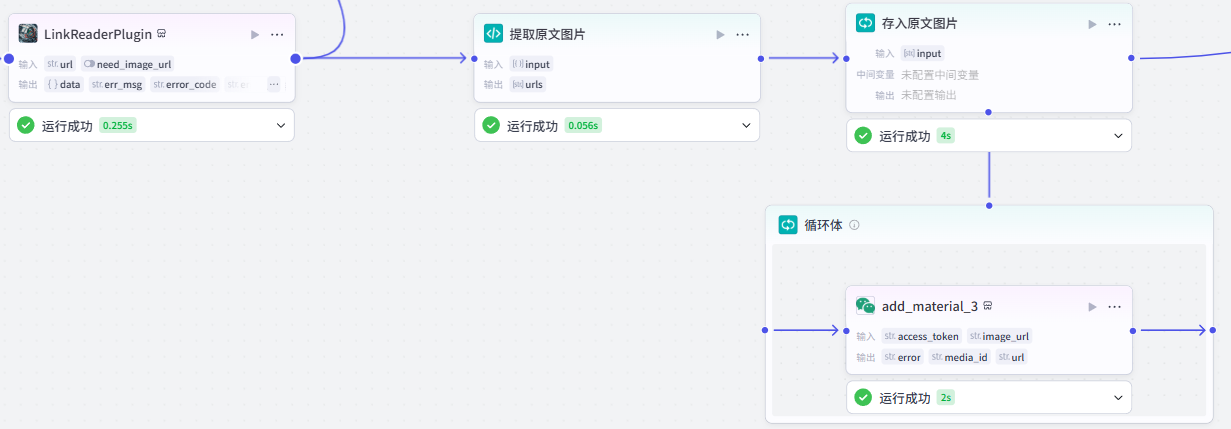
1、提取原文图片链接
【重点】本步骤还是重点!!!我们在之前的 LinkReaderPlugin 节点中已经拿到了原文的图片地址,但是其格式无法直接使用,需要将其中的 url 提取出来,并且要对 url 的内容进行截取,只取到 .jpg / .png。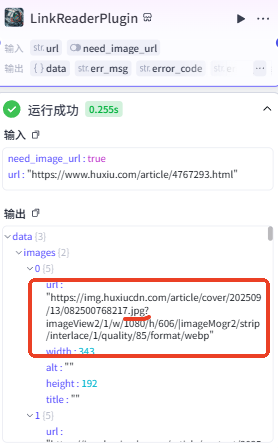
输入
我们需要添加【代码】节点,输入为 LinkReaderPlugin 的 image 数组。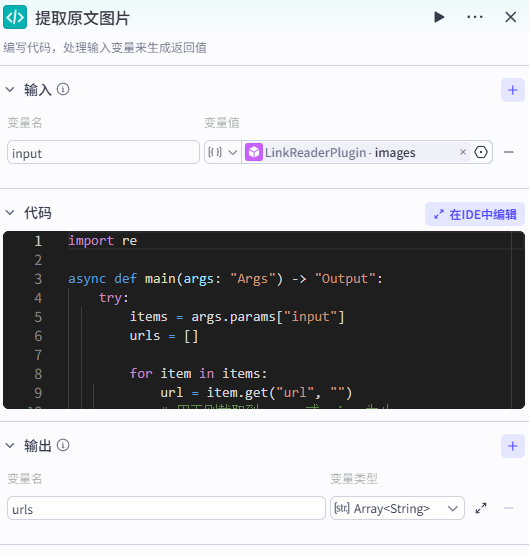
源码
粘贴以下代码(本代码仅判断了 png 和 jpg 格式,如果有其他格式的图片往代码中加即可)。import re
async def main(args: "Args") -> "Output":
try:
items = args.params["input"]
urls = []
for item in items:
url = item.get("url", "")
# 用正则截取到 .png 或 .jpg 为止
match = re.search(r"(https?://.*?\.(?:png|jpg))", url, re.IGNORECASE)
if match:
urls.append(match.group(1))
return {"urls": urls}
except Exception as e:
return {"urls": [], "_error": f"Error in main: {str(e)}"}
输出
这样就正确输出了我们需要的 url。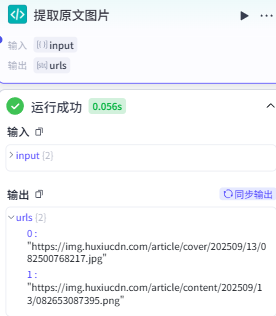
2、构建循环体将图片存入素材库
添加【循环】节点将上一节点输出的原文图片 url 数组存入公众号素材库中,后续要在文章中使用原文图片,直接从素材库添加即可,无需再进行找到原文-保存图片-上传素材库等繁琐操作。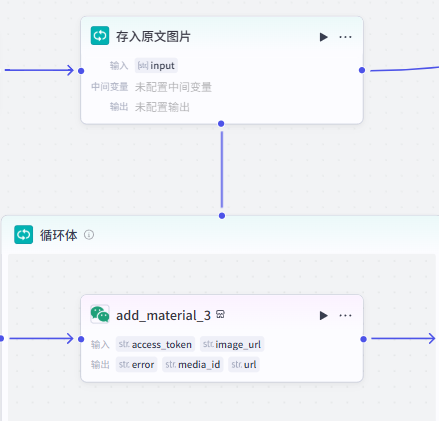
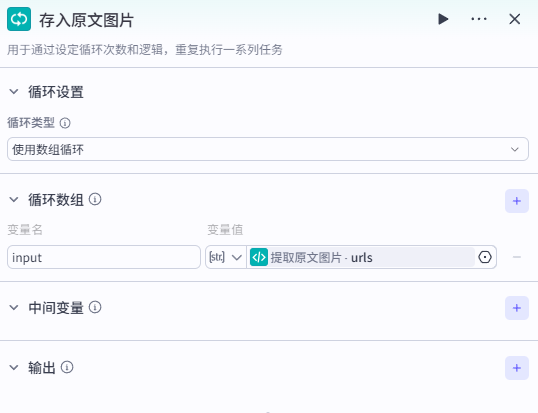
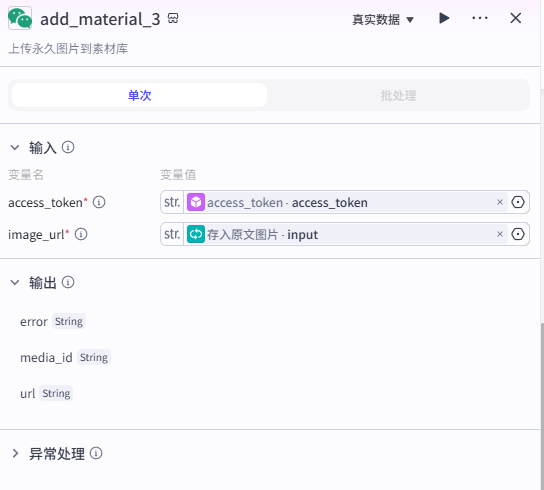
七、将文章存入公众号草稿箱并更新数据库
在此步骤中,我们需要将前面获取到的文章标题、摘要、内容一并整合通过第三方拆建传入公众号草稿箱中,并更新一改写文章的数据库,便于下次判断文章是否已被改写。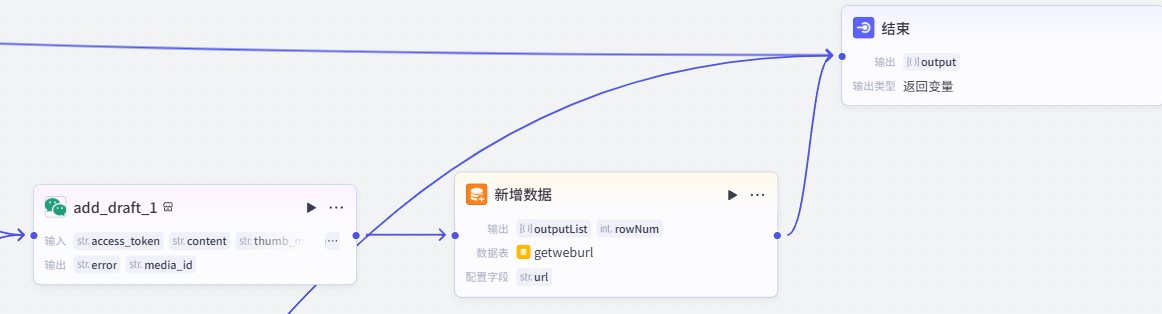
1、将文章各要素存入公众号
如何获取插件
仍使用我们获取公众号 token 的套件。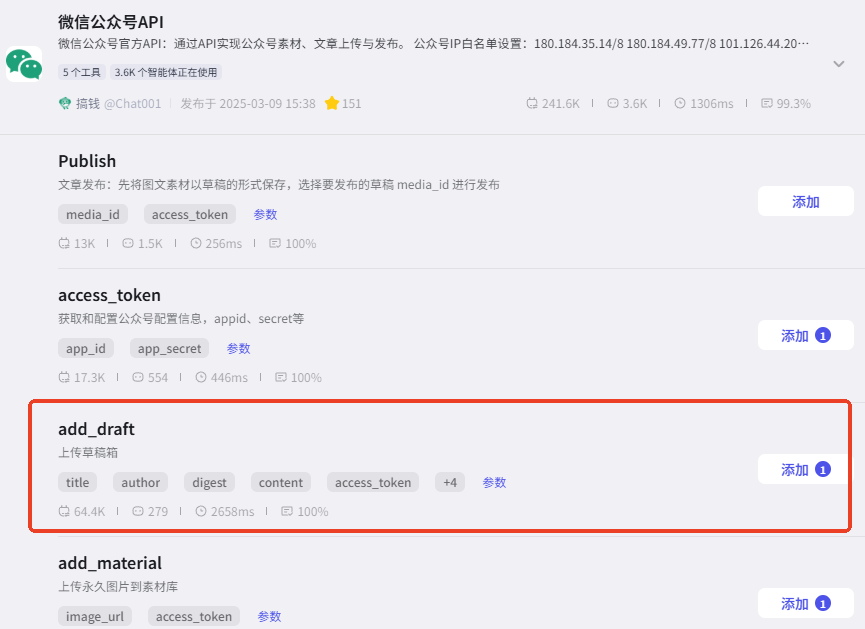
输入
按下图传入变量。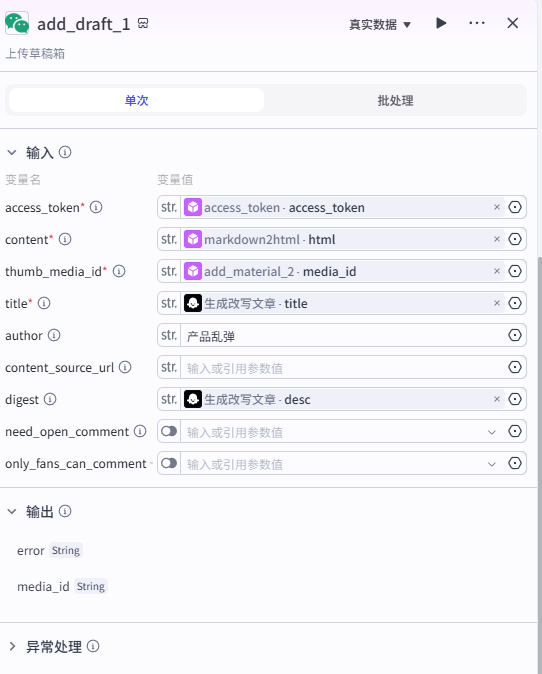
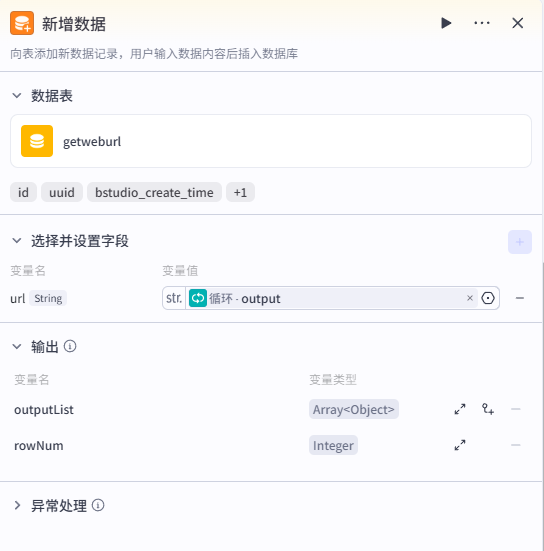
2、更新已改写文章数据库
若走到此节点,说明改写文章已完成,需将该链接存入已改写数据库中,防止重复改写。添加【新增数据】,将最初获取到的可改写文章的 url 存入数据库中。
3、发布工作流
只有工作流发布后,才能将其添加到智能体中,每次更新工作流都需要重新发布。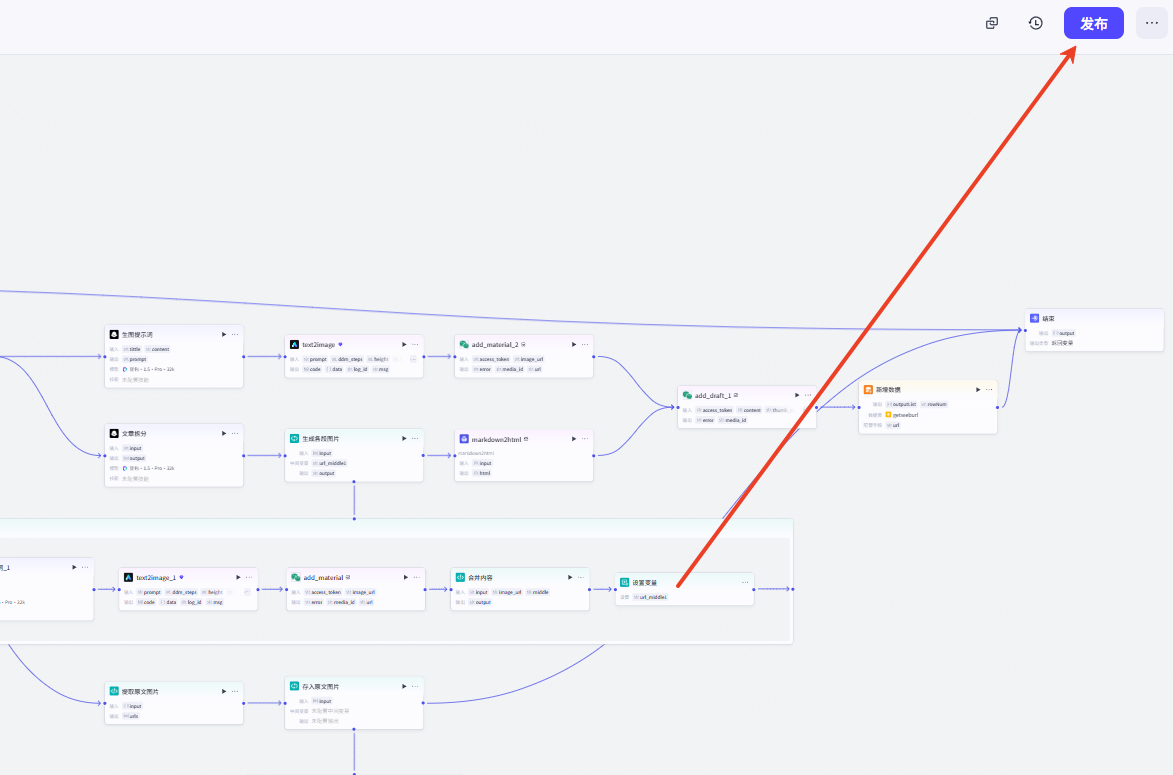
至此工作流已设置完成。
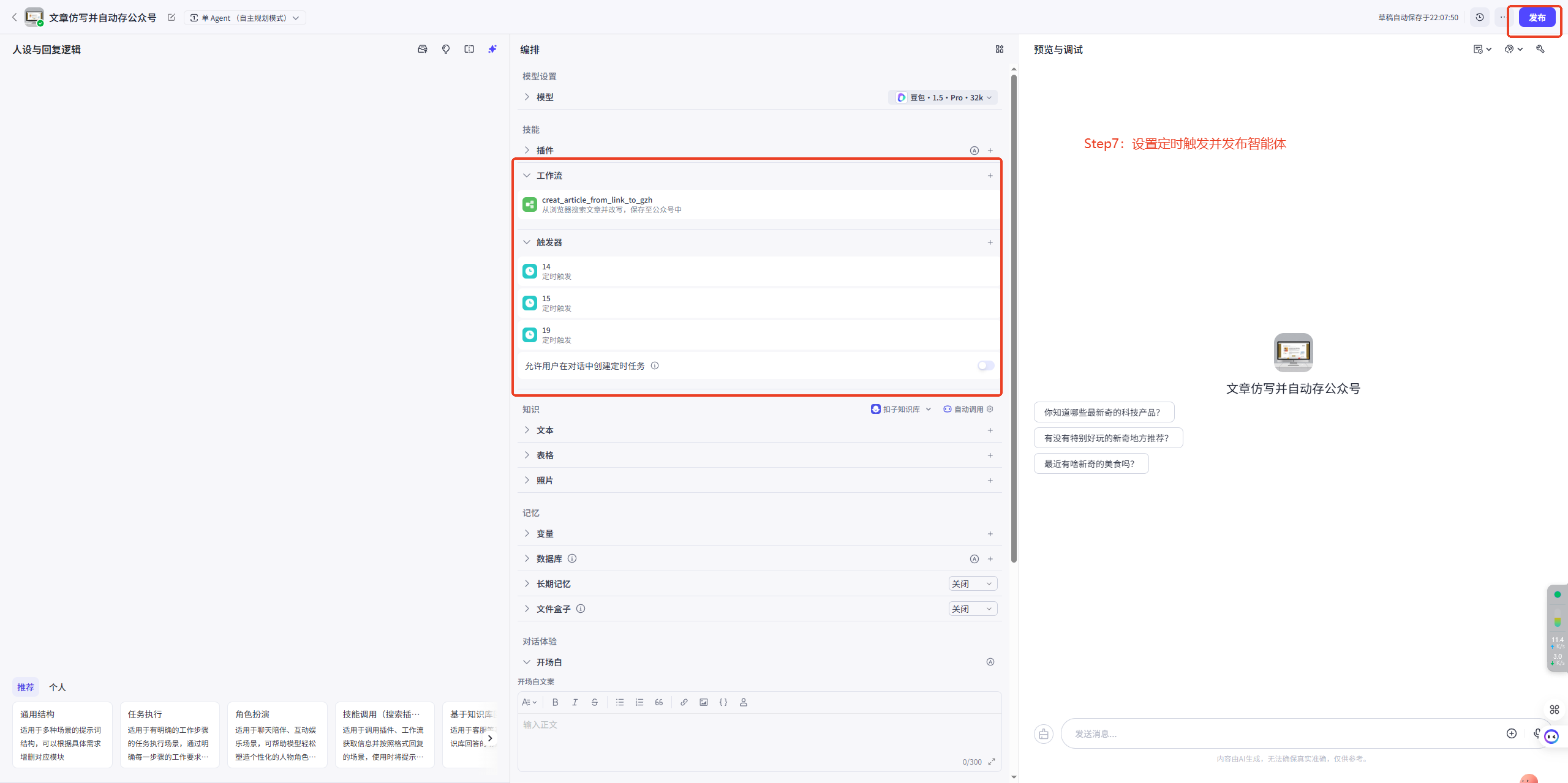
八、设置定时触发并发布智能体
接下来要设置智能体的触发器实现定时执行工作流。1、添加工作流和触发器
将工作流添加到智能体中。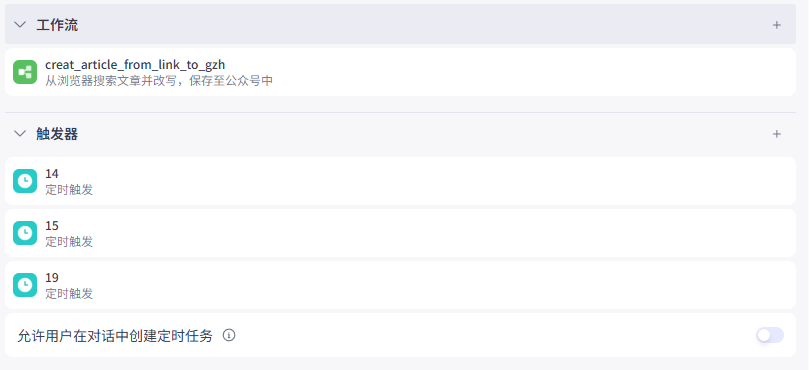
根据需求创建定时触发器,任务执行选择工作流后需再次添加工作流。
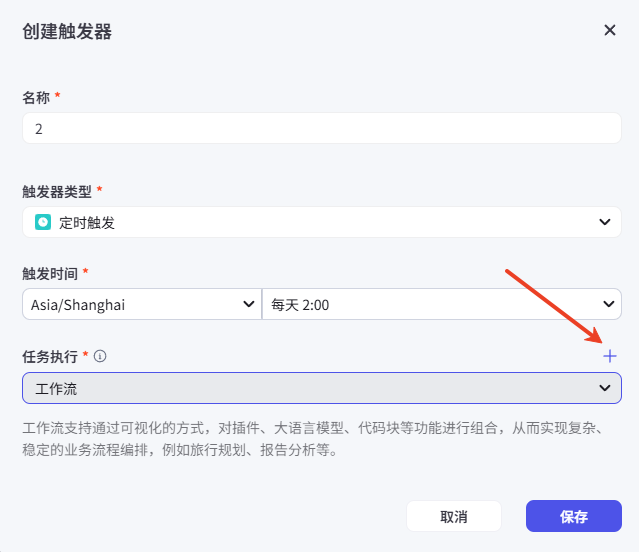
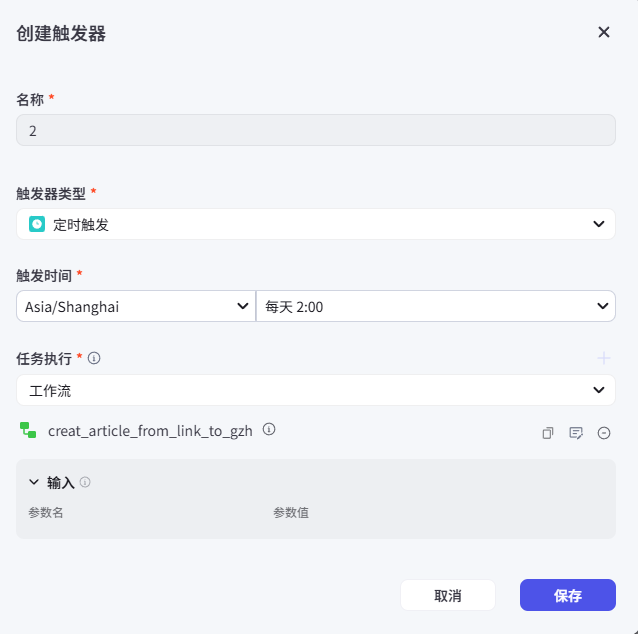
2、发布智能体
调试成功后即可发布智能体。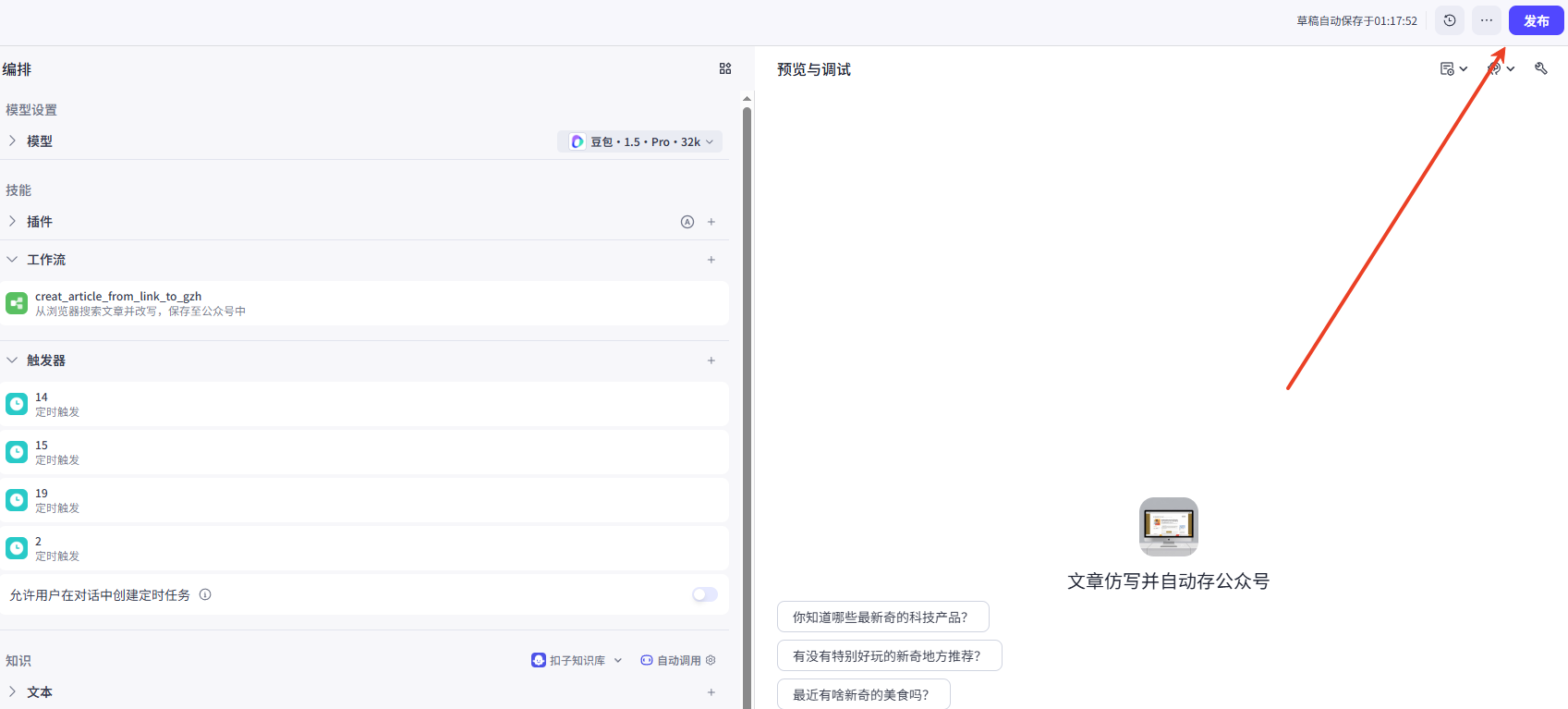
每次更新都需要发布智能体,点击后需要发布到【飞书】平台才可使用,需要自行配置飞书授权。
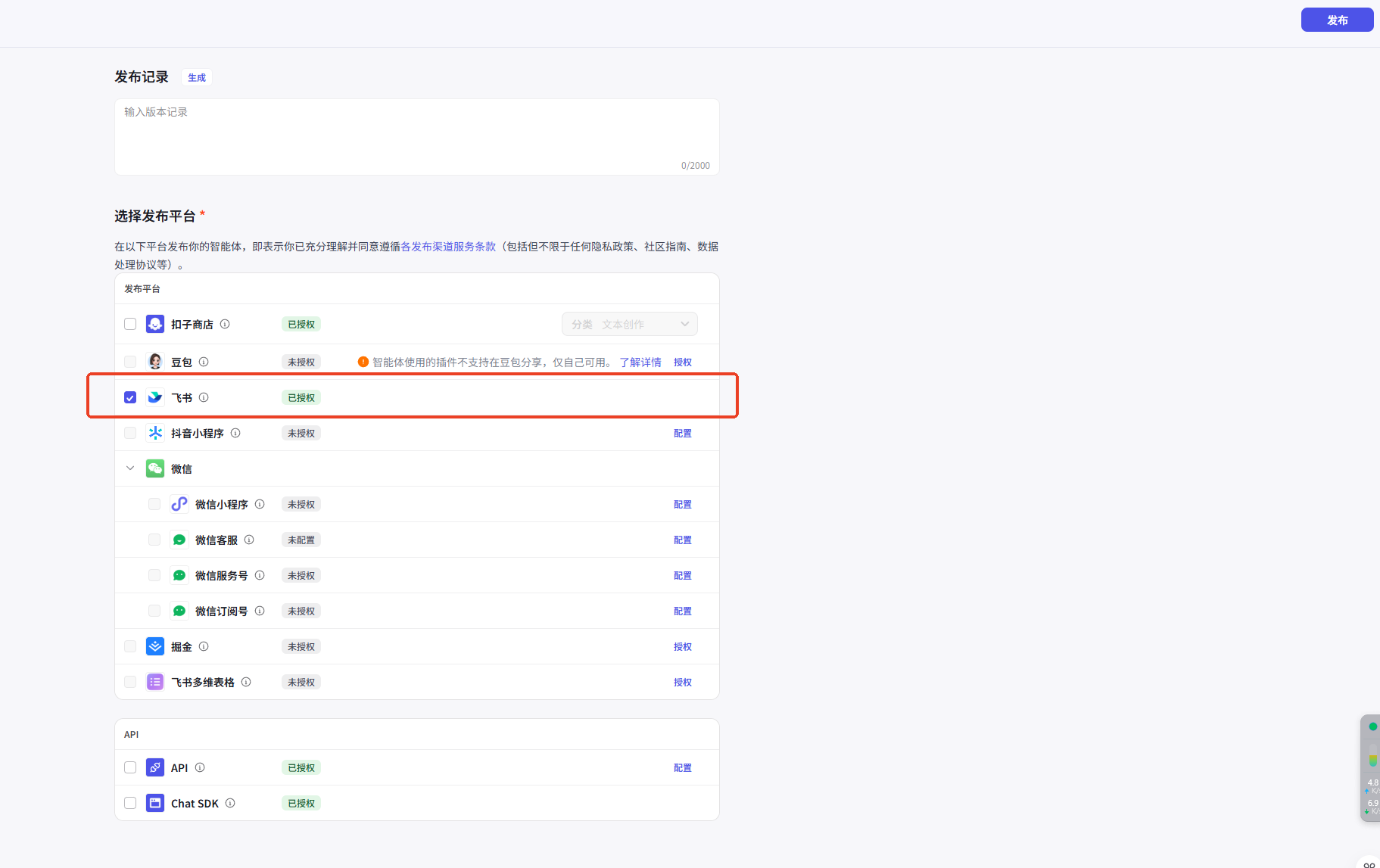
至此全文完!如果大家在使用过程中有什么问题,可通过公众号随时与我联系。
更多推荐


 17
17 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)