
大模型微调框架之LLaMA Factory
近年来,大语言模型(LLM)在自然语言处理(NLP)领域取得了突破性进展。然而,直接训练或微调这些模型往往需要昂贵的计算资源和复杂的工程实现,这使得许多研究者和开发者在落地应用时面临困难。为此,开源社区涌现出了一系列面向大模型的高效训练与推理框架,前面我们介绍了LangChain,vLLM,PEFT,TRL,今天我们来看一下 LLaMA Factory 。
📚大模型框架系列文章
知识管理与 RAG 框架全景:从 LlamaIndex 到多框架集成
近年来,大语言模型(LLM)在自然语言处理(NLP)领域取得了突破性进展。然而,直接训练或微调这些模型往往需要昂贵的计算资源和复杂的工程实现,这使得许多研究者和开发者在落地应用时面临困难。为此,开源社区涌现出了一系列面向大模型的高效训练与推理框架,前面我们介绍了LangChain,vLLM,PEFT,TRL,今天我们来看一下 LLaMA Factory 。
所有相关源码示例、流程图、模型配置与知识库构建技巧,我也将持续更新在Github:LLMHub,欢迎关注收藏!
大家可以带着下面三个问题阅读本文,我会在文章最后给出答案。
1.什么是LLaMA Factory?
2.LLaMA Factory的核心功能包括哪些?
3.LLaMA Factory和其他框架有什么核心区别?
一、LLaMA Factory 简介
LLaMA Factory 是一个开源的大模型微调与训练框架,主要围绕 Meta 发布的 LLaMA 系列模型 进行优化。它集成了多种高效参数高效微调(PEFT,Parameter-Efficient Fine-Tuning)技术,如 LoRA、QLoRA、Prefix Tuning 等,帮助用户在有限的算力资源下快速完成模型定制。

该框架的目标是让研究者和工程师能够 以最小的成本实现模型的领域适配和下游任务优化,并且尽量降低使用门槛。
二、框架原理
LLaMA Factory 的核心思想是 参数高效微调(PEFT)。传统的全量微调需要更新数十亿甚至上百亿参数,显存和计算开销极大。而在 PEFT 方法中,只需在原有模型中加入一些额外模块或矩阵,对其进行训练即可:
- 冻结预训练模型主干参数,保持原始知识和能力。
- 新增少量可训练参数(如 LoRA 的低秩矩阵、Prefix Tuning 的提示向量),专门学习任务相关信息。
- 组合输出:推理时,模型同时利用原始参数和新学到的参数进行预测。
这样做的好处是:
- 显存占用显著降低(因为大部分参数被冻结,不参与反向传播)。
- 训练效率大幅提升(更新的参数量大幅减少)。
- 灵活性增强(可以为不同任务训练不同的 LoRA 权重,而主模型保持不变)。
三、核心功能
- 多种 PEFT 方法支持
- LoRA / QLoRA:通过低秩分解降低训练参数量和显存占用。
- Prefix/Prompt Tuning:无需修改模型主体,仅优化提示向量。
- Adapter 模块:在主干网络中插入轻量级层实现高效调优。
- 高效数据处理与加载
- 内置多种格式的数据预处理工具,兼容 Hugging Face datasets。
- 支持指令微调、对话数据、文本分类、摘要生成等多样任务。
- 多 GPU 与混合精度训练
- 支持 DeepSpeed、Accelerate 等分布式训练方案。
- 原生支持 FP16、BF16、量化训练,显著降低显存开销。
- 模型推理与导出
- 支持一键部署,结合 Hugging Face Transformers 实现快速推理。
- 提供模型导出功能,方便在生产环境中落地。
四、LLaMA Factory 的架构设计
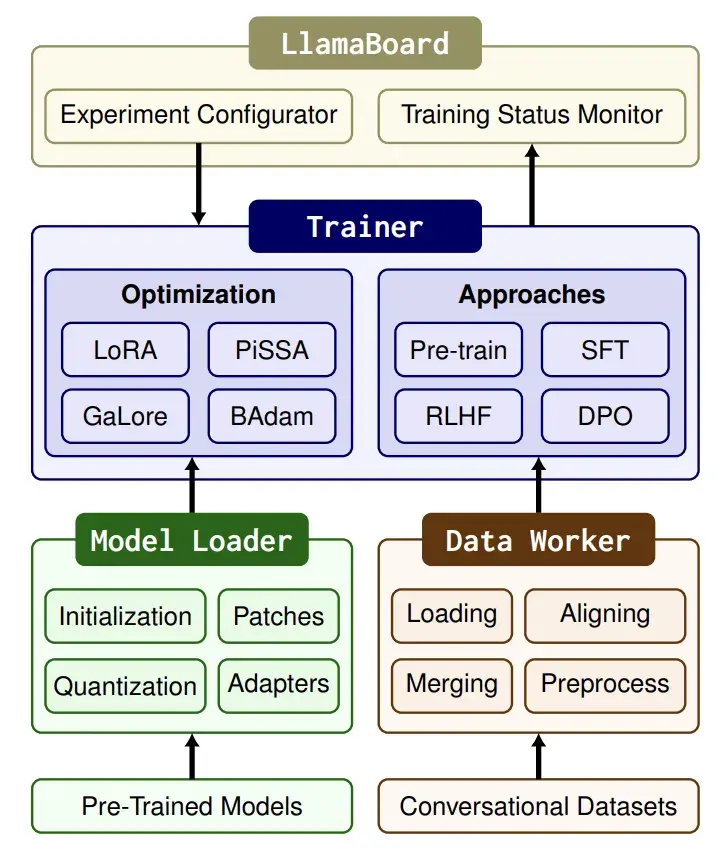
LLaMA Factory 的架构设计围绕 高效、灵活、可扩展 三个目标展开,整体可以分为以下几个核心模块:
- 模型层(Model Layer)
- 基于 Hugging Face Transformers 提供的预训练大模型(如 LLaMA、Baichuan、ChatGLM 等)。
- 通过 冻结主干参数 + 注入 PEFT 模块 的方式实现高效微调。
- 支持 LoRA、QLoRA、Adapter、Prefix/Prompt Tuning 等多种方案,用户可灵活切换。
- 数据层(Data Layer)
- 内置数据预处理与加载模块,兼容 Hugging Face datasets 和本地 JSON/CSV 格式。
- 提供统一的 指令微调模板(Instruction Templates),适配问答、对话、分类等任务场景。
- 支持多任务训练(Multi-task),便于构建综合能力模型。
- 训练层(Training Layer)
- 封装了训练调度逻辑,兼容 Accelerate 与 DeepSpeed,支持多 GPU 和分布式训练。
- 内置混合精度(FP16、BF16)和量化(4bit/8bit)方案,降低显存占用。
- 提供训练配置文件(YAML/JSON),用户可以快速复现和自定义实验。
- 推理与部署层(Inference & Deployment Layer)
- 内置推理脚本,支持单轮/多轮对话测试。
- 支持 LoRA 权重与原始模型合并,导出标准 Hugging Face 格式,便于后续部署。
- 可结合 API 服务快速上线,支持轻量化部署到边缘设备或云端。
- 工具与扩展层(Utils & Extensions)
- 提供日志监控(如 TensorBoard、WandB 集成)。
- 预留插件接口,方便扩展新的 PEFT 方法或自定义任务。
- 社区贡献模块活跃,不断加入新的功能与优化。
五、典型应用场景
- 垂直领域模型微调
- 金融、医疗、法律等专业领域的知识增强。
- 多轮对话系统构建
- 在现有大模型基础上微调,提升上下文理解能力。
- 轻量化部署
- 通过量化 + LoRA 训练后,将模型部署到低成本服务器或边缘设备。
- 个性化助手训练
- 利用私有数据快速定制符合个人或企业需求的智能助手。
六、快速上手示例
下面的部分展示如何用 LLaMA Factory + LoRA 在一个文本分类数据集上进行微调,大家可以亲手试一试,当然,手头要有一个显卡。
# 1. 克隆项目
git clone https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
# 2. 安装依赖
pip install -r requirements.txt
# 3. 启动微调任务(以LoRA为例)
CUDA_VISIBLE_DEVICES=0 python src/train.py \
--model_name_or_path meta-llama/Llama-2-7b-hf \ # 基础模型
--dataset_name ag_news \ # 数据集(也可换成本地数据)
--finetuning_type lora \ # 微调方式
--output_dir output/llama2_lora_agnews \ # 输出目录
--num_train_epochs 3 \
--per_device_train_batch_size 4 \
--learning_rate 2e-4 \
--fp16
微调完成后,可以直接用 推理脚本 来测试效果:
python src/inference.py \
--model_name_or_path output/llama2_lora_agnews \
--template default \
--max_new_tokens 128
这样,你就可以快速得到一个在新闻分类任务上优化过的 LLaMA 模型。
七、总结
LLaMA Factory 的出现,大大降低了大模型微调的门槛,让更多开发者能够参与到 LLM 的创新与应用中。它不仅提供了高效的训练方式,还在部署与应用环节提供了便利。如果你想在有限的算力资源下快速打造一个适合自己场景的大模型,LLaMA Factory 将是一个值得尝试的工具。
最后,我们来回答一下文章开头提出的三个问题:
1. 什么是 LLaMA Factory?
LLaMA Factory 是一个面向大语言模型(LLM)的开源微调与训练框架,特别针对** Meta 的 LLaMA 系列模型**进行了优化。它的核心目标是降低大模型定制的门槛,让研究者和开发者能够在有限算力条件下高效地完成模型微调和部署。框架内置了多种参数高效微调(PEFT)方法,例如 LoRA、QLoRA、Prefix Tuning 等,并且与 Hugging Face Transformers 无缝兼容,既适合科研实验,也适合工业落地。
2. LLaMA Factory 的核心功能包括哪些?
LLaMA Factory 的核心功能主要包括:支持多种 PEFT 方法(如 LoRA、QLoRA、Adapter、Prefix/Prompt Tuning),显著降低显存和训练成本;提供高效的数据预处理与加载工具,兼容 Hugging Face datasets;支持分布式与混合精度训练,结合 DeepSpeed 与 Accelerate 提升训练速度;同时支持一键推理与模型导出,方便在生产环境中快速部署。这些功能让用户能够在不同场景下灵活使用该框架。
3. LLaMA Factory 和其他框架有什么核心区别?
与其他大模型微调框架相比,LLaMA Factory 的核心区别在于它对** LLaMA 系列模型的深度优化和一站式支持**。相比通用的 Hugging Face PEFT,LLaMA Factory 提供了更加简洁的配置方式和开箱即用的脚本,用户只需少量命令即可完成训练;同时,它在 LoRA/QLoRA 等轻量化方案上表现更优,单张消费级显卡即可运行。此外,LLaMA Factory 社区活跃,功能迭代快,更贴近 LLaMA 模型的生态,因而在易用性与适配性上更具优势。
关于深度学习和大模型相关的知识和前沿技术更新,请关注公众号 coting!
以上内容部分参考了相关开源文档与社区资料。非常感谢,如有侵权请联系删除!
更多推荐

 9
9 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)