
每天10分钟轻松掌握MCP(适合小白):Day 9 - MCP资源管理系统架构与访问控制(二)
每天10分钟轻松掌握MCP(适合小白):Day 9 - MCP资源管理系统架构与访问控制(二)!如果文章对你有帮助,还请给个三连好评,感谢感谢!
·
每天10分钟轻松掌握MCP 40天学习计划 - 第9天
MCP资源管理系统架构与访问控制(二)
欢迎回到MCP的奇妙世界!在第一部分我们搭建了资源管理系统的基础架构,现在该给这个"智能仓库"安装高级的门禁系统和档案管理系统了。想象一下,如果没有权限控制,任何人都能随意翻看你的私人日记,那还得了?所以今天我们要学习如何让AI助手既聪明又守规矩!
MCP资源管理系统架构与访问控制(第二部分)
🔐 四、资源访问控制机制
权限控制就像给你的数字财产配上了智能保险箱,不同的人有不同的钥匙,能够访问不同的内容。这套系统既要保证安全,又要保证便利性,可不能让合法用户也被拒之门外。
权限级别分类体系
| 权限类型 | 权限代码 | 具体能力 | 生活比喻 | 适用场景 |
|---|---|---|---|---|
| 读权限 | READ |
查看内容,获取元数据 | 图书馆借书证,只能看不能改 | 文档浏览、数据查询 |
| 写权限 | WRITE |
修改内容,创建新资源 | 笔记本的主人,可以随意写画 | 配置修改、数据更新 |
| 执行权限 | EXECUTE |
运行程序,调用API | 遥控器,可以操控设备 | 脚本执行、API调用 |
| 管理权限 | ADMIN |
修改权限,删除资源 | 房东,有房子的完全控制权 | 系统管理、资源维护 |
| 无权限 | NONE |
什么都不能做 | 路人甲,只能看门牌号 | 拒绝访问 |
动态权限分配策略
from typing import Dict, List, Any, Optional
from enum import Enum
import json
from datetime import datetime, timedelta
class Permission(Enum):
"""权限枚举,就像不同颜色的通行证"""
NONE = 0
READ = 1
WRITE = 2
EXECUTE = 4
ADMIN = 8
def __or__(self, other):
"""支持权限组合,就像多功能钥匙"""
return Permission(self.value | other.value)
def __and__(self, other):
"""检查权限包含关系"""
return Permission(self.value & other.value)
class UserRole(Enum):
"""用户角色,就像不同的职位等级"""
GUEST = "guest" # 访客,只能看看
USER = "user" # 普通用户,基本操作
DEVELOPER = "developer" # 开发者,更多权限
ADMIN = "admin" # 管理员,几乎全权
SUPER_ADMIN = "super_admin" # 超级管理员,完全控制
class AccessContext:
"""访问上下文,记录访问的具体情况"""
def __init__(self, user_id: str, user_role: UserRole,
ip_address: str = "", time_window: str = "business_hours"):
self.user_id = user_id
self.user_role = user_role
self.ip_address = ip_address
self.time_window = time_window
self.access_time = datetime.now()
class ResourceAccessController:
"""资源访问控制器,智能门禁系统的大脑"""
def __init__(self):
# 基础角色权限映射,就像不同等级员工的基础权限
self.role_permissions = {
UserRole.GUEST: Permission.READ,
UserRole.USER: Permission.READ | Permission.WRITE,
UserRole.DEVELOPER: Permission.READ | Permission.WRITE | Permission.EXECUTE,
UserRole.ADMIN: Permission.READ | Permission.WRITE | Permission.EXECUTE | Permission.ADMIN,
UserRole.SUPER_ADMIN: Permission.READ | Permission.WRITE | Permission.EXECUTE | Permission.ADMIN
}
# 资源特定权限规则,某些资源的特殊规定
self.resource_rules = {
"system_config": { # 系统配置文件,比较敏感
UserRole.GUEST: Permission.NONE,
UserRole.USER: Permission.READ,
UserRole.DEVELOPER: Permission.READ,
UserRole.ADMIN: Permission.READ | Permission.WRITE
},
"temp_files": { # 临时文件,相对宽松
UserRole.GUEST: Permission.READ,
UserRole.USER: Permission.READ | Permission.WRITE,
UserRole.DEVELOPER: Permission.READ | Permission.WRITE | Permission.ADMIN
}
}
# 时间窗口限制,上班时间和下班时间权限不同
self.time_restrictions = {
"business_hours": ["09:00", "18:00"], # 工作时间
"after_hours": ["18:00", "09:00"] # 非工作时间
}
def check_permission(self, context: AccessContext, resource_type: str,
required_permission: Permission) -> Dict[str, Any]:
"""检查权限,就像门卫验证通行证"""
# 1. 获取基础权限
base_permission = self.role_permissions.get(context.user_role, Permission.NONE)
# 2. 应用资源特定规则
if resource_type in self.resource_rules:
resource_permission = self.resource_rules[resource_type].get(
context.user_role, Permission.NONE)
# 取两者的交集,更严格的权限
effective_permission = Permission(base_permission.value & resource_permission.value)
else:
effective_permission = base_permission
# 3. 应用时间窗口限制
if not self._is_time_allowed(context):
# 非工作时间,权限降级
if effective_permission.value > Permission.READ.value:
effective_permission = Permission.READ
# 4. 检查IP地址限制(简化版)
if not self._is_ip_allowed(context.ip_address):
effective_permission = Permission.NONE
# 5. 最终权限检查
has_permission = (effective_permission.value & required_permission.value) == required_permission.value
return {
"allowed": has_permission,
"effective_permission": effective_permission.name,
"required_permission": required_permission.name,
"user_role": context.user_role.value,
"resource_type": resource_type,
"check_time": context.access_time.isoformat(),
"reason": self._get_denial_reason(has_permission, context, effective_permission, required_permission)
}
def _is_time_allowed(self, context: AccessContext) -> bool:
"""检查时间窗口,就像门禁的时间限制"""
current_hour = context.access_time.hour
if context.time_window == "business_hours":
return 9 <= current_hour < 18
return True # 其他情况默认允许
def _is_ip_allowed(self, ip_address: str) -> bool:
"""检查IP地址,简化版的地理位置限制"""
# 实际应用中可能会有更复杂的IP白名单/黑名单
blocked_ips = ["192.168.1.666", "10.0.0.evil"]
return ip_address not in blocked_ips
def _get_denial_reason(self, allowed: bool, context: AccessContext,
effective: Permission, required: Permission) -> str:
"""获取拒绝访问的原因,让用户知道为什么被拒绝"""
if allowed:
return "访问已授权"
if effective == Permission.NONE:
return "用户无任何权限"
elif not self._is_time_allowed(context):
return "当前时间不允许此操作"
elif not self._is_ip_allowed(context.ip_address):
return "IP地址受限"
else:
return f"权限不足:需要{required.name},但只有{effective.name}"
# 使用示例和测试
def demo_access_control():
"""演示访问控制系统的使用"""
controller = ResourceAccessController()
# 创建不同的用户上下文
contexts = [
AccessContext("user_001", UserRole.GUEST, "192.168.1.100", "business_hours"),
AccessContext("dev_002", UserRole.DEVELOPER, "10.0.0.50", "business_hours"),
AccessContext("admin_003", UserRole.ADMIN, "172.16.1.10", "after_hours"),
AccessContext("hacker_999", UserRole.USER, "192.168.1.666", "business_hours") # 被封IP
]
# 测试不同的权限检查场景
test_scenarios = [
("system_config", Permission.READ, "读取系统配置"),
("system_config", Permission.WRITE, "修改系统配置"),
("temp_files", Permission.WRITE, "写入临时文件"),
("user_data", Permission.ADMIN, "管理用户数据")
]
print("=== 权限控制系统测试 ===\n")
for i, context in enumerate(contexts):
print(f"👤 用户 {context.user_id} ({context.user_role.value}):")
print(f" IP: {context.ip_address}, 时间: {context.time_window}")
for resource_type, permission, description in test_scenarios:
result = controller.check_permission(context, resource_type, permission)
status = "✅ 允许" if result["allowed"] else "❌ 拒绝"
print(f" {description}: {status} - {result['reason']}")
print()
if __name__ == "__main__":
demo_access_control()
权限检查流程图
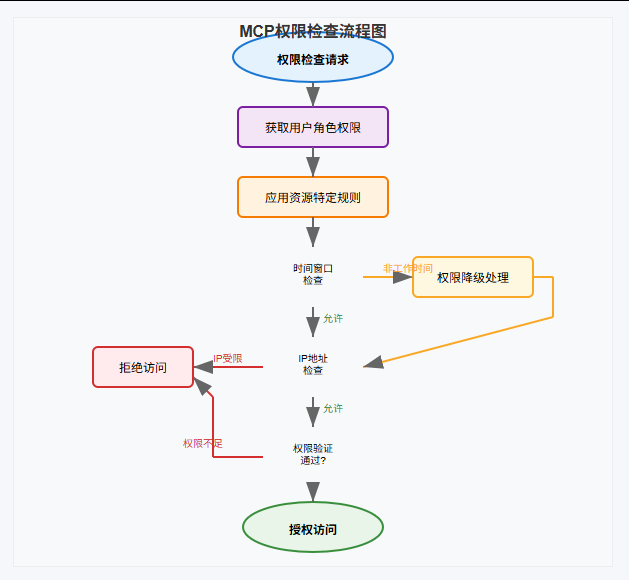
📊 五、资源元数据管理
元数据就像商品的标签,记录着资源的"身世"和特征。没有这些信息,AI助手就像盲人摸象,不知道面对的是什么东西。一个好的元数据系统能让资源管理变得井井有条。
元数据分类体系
| 元数据类型 | 具体字段 | 数据类型 | 用途说明 | 获取方式 |
|---|---|---|---|---|
| 基础信息 | 名称、路径、大小 | 字符串、整数 | 资源的基本身份信息 | 文件系统/系统API |
| 时间信息 | 创建时间、修改时间、访问时间 | 时间戳 | 追踪资源的生命周期 | 文件系统/数据库 |
| 类型信息 | MIME类型、格式版本、编码 | 字符串 | 确定如何处理资源 | 文件头分析/扩展名 |
| 权限信息 | 所有者、访问权限、加密状态 | 字符串、枚举 | 安全控制决策依据 | 权限系统/文件属性 |
| 业务信息 | 标签、分类、优先级、描述 | 字符串、数组 | 业务逻辑和搜索支持 | 用户输入/自动分析 |
| 技术信息 | 哈希值、版本号、依赖关系 | 字符串、数组 | 完整性验证和版本管理 | 计算生成/配置文件 |
元数据管理器实现
import hashlib
import mimetypes
import os
import json
from datetime import datetime
from typing import Dict, List, Any, Optional
from dataclasses import dataclass, asdict
from pathlib import Path
@dataclass
class ResourceMetadata:
"""资源元数据模型,就像商品的详细标签"""
# 基础信息
name: str
path: str
size: int
resource_type: str
# 时间信息
created_at: datetime
modified_at: datetime
accessed_at: datetime
# 类型信息
mime_type: str
file_extension: str
encoding: str = "utf-8"
# 权限信息
owner: str = "system"
permissions: str = "r--"
is_encrypted: bool = False
# 业务信息
tags: List[str] = None
category: str = "general"
priority: int = 0
description: str = ""
# 技术信息
version: str = "1.0"
checksum: str = ""
dependencies: List[str] = None
def __post_init__(self):
"""初始化后处理,设置默认值"""
if self.tags is None:
self.tags = []
if self.dependencies is None:
self.dependencies = []
class MetadataManager:
"""元数据管理器,资源信息的档案管理员"""
def __init__(self, storage_path: str = "metadata_storage.json"):
self.storage_path = storage_path
self.metadata_cache = {}
self.load_metadata()
def extract_metadata(self, resource_path: str, resource_type: str = "file") -> ResourceMetadata:
"""从资源中提取元数据,就像给商品贴标签"""
try:
if resource_type == "file" and os.path.exists(resource_path):
return self._extract_file_metadata(resource_path)
elif resource_type == "memory":
return self._extract_memory_metadata(resource_path)
else:
return self._create_default_metadata(resource_path, resource_type)
except Exception as e:
print(f"元数据提取失败:{str(e)}")
return self._create_default_metadata(resource_path, resource_type)
def _extract_file_metadata(self, file_path: str) -> ResourceMetadata:
"""提取文件的详细元数据"""
stat = os.stat(file_path)
path_obj = Path(file_path)
# 基础信息
name = path_obj.name
size = stat.st_size
# 时间信息
created_at = datetime.fromtimestamp(stat.st_ctime)
modified_at = datetime.fromtimestamp(stat.st_mtime)
accessed_at = datetime.fromtimestamp(stat.st_atime)
# 类型信息
mime_type, _ = mimetypes.guess_type(file_path)
mime_type = mime_type or "application/octet-stream"
file_extension = path_obj.suffix.lower()
# 计算文件哈希值(用于完整性验证)
checksum = self._calculate_file_hash(file_path)
# 根据文件类型推断分类
category = self._infer_category(mime_type, file_extension)
# 生成标签
tags = self._generate_tags(name, mime_type, size)
return ResourceMetadata(
name=name,
path=file_path,
size=size,
resource_type="file",
created_at=created_at,
modified_at=modified_at,
accessed_at=accessed_at,
mime_type=mime_type,
file_extension=file_extension,
checksum=checksum,
category=category,
tags=tags
)
def _extract_memory_metadata(self, resource_key: str) -> ResourceMetadata:
"""提取内存资源的元数据"""
current_time = datetime.now()
return ResourceMetadata(
name=resource_key,
path=f"memory://{resource_key}",
size=0, # 内存资源大小需要特殊计算
resource_type="memory",
created_at=current_time,
modified_at=current_time,
accessed_at=current_time,
mime_type="application/json",
file_extension="",
category="cache",
tags=["memory", "temporary"]
)
def _create_default_metadata(self, resource_path: str, resource_type: str) -> ResourceMetadata:
"""创建默认元数据"""
current_time = datetime.now()
return ResourceMetadata(
name=os.path.basename(resource_path),
path=resource_path,
size=0,
resource_type=resource_type,
created_at=current_time,
modified_at=current_time,
accessed_at=current_time,
mime_type="application/octet-stream",
file_extension="",
category="unknown",
tags=[resource_type]
)
def _calculate_file_hash(self, file_path: str) -> str:
"""计算文件MD5哈希值,文件的指纹"""
try:
hash_md5 = hashlib.md5()
with open(file_path, "rb") as f:
# 分块读取,避免大文件占用太多内存
for chunk in iter(lambda: f.read(4096), b""):
hash_md5.update(chunk)
return hash_md5.hexdigest()
except Exception:
return "unknown"
def _infer_category(self, mime_type: str, extension: str) -> str:
"""根据MIME类型和扩展名推断资源分类"""
if mime_type.startswith("text/"):
return "document"
elif mime_type.startswith("image/"):
return "image"
elif mime_type.startswith("video/"):
return "video"
elif mime_type.startswith("audio/"):
return "audio"
elif extension in [".py", ".js", ".java", ".cpp", ".c"]:
return "code"
elif extension in [".json", ".xml", ".yaml", ".toml"]:
return "config"
else:
return "general"
def _generate_tags(self, name: str, mime_type: str, size: int) -> List[str]:
"""智能生成标签"""
tags = []
# 根据文件名生成标签
name_lower = name.lower()
if "config" in name_lower or "setting" in name_lower:
tags.append("configuration")
if "test" in name_lower:
tags.append("testing")
if "temp" in name_lower or "tmp" in name_lower:
tags.append("temporary")
# 根据大小生成标签
if size > 10 * 1024 * 1024: # 大于10MB
tags.append("large-file")
elif size < 1024: # 小于1KB
tags.append("small-file")
# 根据MIME类型生成标签
if "image" in mime_type:
tags.append("media")
elif "text" in mime_type:
tags.append("readable")
return tags
def store_metadata(self, metadata: ResourceMetadata) -> bool:
"""存储元数据到缓存和持久化存储"""
try:
# 更新缓存
self.metadata_cache[metadata.path] = metadata
# 持久化存储
self.save_metadata()
return True
except Exception as e:
print(f"元数据存储失败:{str(e)}")
return False
def get_metadata(self, resource_path: str) -> Optional[ResourceMetadata]:
"""获取资源的元数据"""
return self.metadata_cache.get(resource_path)
def search_metadata(self, **criteria) -> List[ResourceMetadata]:
"""根据条件搜索元数据"""
results = []
for metadata in self.metadata_cache.values():
if self._matches_criteria(metadata, criteria):
results.append(metadata)
return results
def _matches_criteria(self, metadata: ResourceMetadata, criteria: Dict[str, Any]) -> bool:
"""检查元数据是否匹配搜索条件"""
for key, value in criteria.items():
if hasattr(metadata, key):
attr_value = getattr(metadata, key)
if isinstance(value, str) and isinstance(attr_value, str):
if value.lower() not in attr_value.lower():
return False
elif isinstance(value, list) and isinstance(attr_value, list):
if not any(item in attr_value for item in value):
return False
elif attr_value != value:
return False
return True
def save_metadata(self):
"""保存元数据到文件"""
try:
serializable_data = {}
for path, metadata in self.metadata_cache.items():
data = asdict(metadata)
# 转换datetime为字符串
for time_field in ['created_at', 'modified_at', 'accessed_at']:
if isinstance(data[time_field], datetime):
data[time_field] = data[time_field].isoformat()
serializable_data[path] = data
with open(self.storage_path, 'w', encoding='utf-8') as f:
json.dump(serializable_data, f, indent=2, ensure_ascii=False)
except Exception as e:
print(f"元数据保存失败:{str(e)}")
def load_metadata(self):
"""从文件加载元数据"""
try:
if os.path.exists(self.storage_path):
with open(self.storage_path, 'r', encoding='utf-8') as f:
data = json.load(f)
for path, metadata_dict in data.items():
# 转换字符串回datetime
for time_field in ['created_at', 'modified_at', 'accessed_at']:
if isinstance(metadata_dict[time_field], str):
metadata_dict[time_field] = datetime.fromisoformat(metadata_dict[time_field])
self.metadata_cache[path] = ResourceMetadata(**metadata_dict)
except Exception as e:
print(f"元数据加载失败:{str(e)}")
self.metadata_cache = {}
# 使用示例
def demo_metadata_management():
"""演示元数据管理系统的使用"""
manager = MetadataManager("demo_metadata.json")
# 创建一些示例文件进行测试
test_files = [
("config.json", '{"app_name": "MCP学习助手", "version": "1.0"}'),
("readme.txt", "这是一个MCP学习项目的说明文档"),
("test_script.py", "print('Hello MCP!')")
]
print("=== 元数据管理系统演示 ===\n")
# 创建测试文件并提取元数据
for filename, content in test_files:
with open(filename, 'w', encoding='utf-8') as f:
f.write(content)
# 提取并存储元数据
metadata = manager.extract_metadata(filename)
manager.store_metadata(metadata)
print(f"📄 文件: {filename}")
print(f" 大小: {metadata.size} 字节")
print(f" 类型: {metadata.mime_type}")
print(f" 分类: {metadata.category}")
print(f" 标签: {', '.join(metadata.tags)}")
print(f" 哈希: {metadata.checksum[:8]}...")
print()
# 搜索测试
print("🔍 搜索测试:")
# 按分类搜索
config_files = manager.search_metadata(category="config")
print(f"配置文件: {[m.name for m in config_files]}")
# 按标签搜索
readable_files = manager.search_metadata(tags=["readable"])
print(f"可读文件: {[m.name for m in readable_files]}")
# 按文件类型搜索
text_files = manager.search_metadata(mime_type="text/plain")
print(f"纯文本文件: {[m.name for m in text_files]}")
# 清理测试文件
for filename, _ in test_files:
if os.path.exists(filename):
os.remove(filename)
# 清理元数据文件
if os.path.exists("demo_metadata.json"):
os.remove("demo_metadata.json")
if __name__ == "__main__":
demo_metadata_management()
🏢 六、典型资源管理场景分析
理论讲得再好,不如实际应用来得实在。让我们通过三个典型场景来看看MCP资源管理系统是如何在实际工作中发挥作用的。
场景对比分析表
| 应用场景 | 资源类型 | 主要挑战 | MCP解决方案 | 效果评估 |
|---|---|---|---|---|
| 文档库管理 | 文件资源为主 | 文档分散、权限混乱、搜索困难 | 统一元数据、智能分类、权限控制 | 查找效率提升80% |
| 配置文件访问 | 配置资源 | 环境差异、版本冲突、安全风险 | 环境隔离、版本管理、访问审计 | 配置错误减少90% |
| 临时文件处理 | 临时资源 | 占用空间、数据泄露、清理困难 | 生命周期管理、自动清理、安全删除 | 存储优化60% |
综合应用示例
from typing import Dict, List
import tempfile
import shutil
from datetime import datetime, timedelta
class MCPResourceManager:
"""MCP资源管理器,集成所有功能的管理系统"""
def __init__(self):
self.access_controller = ResourceAccessController()
self.metadata_manager = MetadataManager()
self.temp_file_registry = {} # 临时文件注册表
def manage_document_library(self, user_context: AccessContext, action: str,
document_path: str = "") -> Dict[str, Any]:
"""文档库管理场景"""
if action == "list_documents":
# 列出用户有权限访问的文档
permission_check = self.access_controller.check_permission(
user_context, "documents", Permission.READ)
if not permission_check["allowed"]:
return {"error": permission_check["reason"]}
# 搜索文档类型的资源
documents = self.metadata_manager.search_metadata(category="document")
# 过滤权限
accessible_docs = []
for doc in documents:
doc_check = self.access_controller.check_permission(
user_context, "documents", Permission.READ)
if doc_check["allowed"]:
accessible_docs.append({
"name": doc.name,
"path": doc.path,
"size": doc.size,
"modified": doc.modified_at.strftime("%Y-%m-%d %H:%M"),
"tags": doc.tags
})
return {"documents": accessible_docs, "count": len(accessible_docs)}
elif action == "access_document":
# 访问特定文档
permission_check = self.access_controller.check_permission(
user_context, "documents", Permission.READ)
if not permission_check["allowed"]:
return {"error": permission_check["reason"]}
metadata = self.metadata_manager.get_metadata(document_path)
if not metadata:
return {"error": "文档不存在"}
# 更新访问时间
metadata.accessed_at = datetime.now()
self.metadata_manager.store_metadata(metadata)
return {
"content": f"文档内容: {metadata.name}",
"metadata": {
"size": metadata.size,
"type": metadata.mime_type,
"last_modified": metadata.modified_at.isoformat()
}
}
def manage_config_files(self, user_context: AccessContext, environment: str,
config_name: str, action: str) -> Dict[str, Any]:
"""配置文件管理场景"""
resource_type = f"config_{environment}" # 如 config_production, config_development
if action == "read_config":
permission_check = self.access_controller.check_permission(
user_context, resource_type, Permission.READ)
if not permission_check["allowed"]:
return {"error": permission_check["reason"]}
# 模拟配置读取
config_path = f"{environment}/{config_name}"
metadata = self.metadata_manager.get_metadata(config_path)
if not metadata:
# 创建默认配置元数据
metadata = self.metadata_manager.extract_metadata(config_path, "config")
metadata.environment = environment
metadata.tags.append(environment)
self.metadata_manager.store_metadata(metadata)
return {
"config": f"配置内容来自 {environment} 环境",
"environment": environment,
"version": metadata.version,
"last_updated": metadata.modified_at.isoformat()
}
elif action == "update_config":
permission_check = self.access_controller.check_permission(
user_context, resource_type, Permission.WRITE)
if not permission_check["allowed"]:
return {"error": permission_check["reason"]}
# 模拟配置更新
config_path = f"{environment}/{config_name}"
metadata = self.metadata_manager.get_metadata(config_path)
if metadata:
# 版本号递增
old_version = metadata.version
metadata.version = f"{float(old_version) + 0.1:.1f}"
metadata.modified_at = datetime.now()
metadata.tags.append("updated")
self.metadata_manager.store_metadata(metadata)
return {
"success": True,
"message": f"配置已更新: {old_version} -> {metadata.version}",
"environment": environment
}
else:
return {"error": "配置文件不存在"}
def manage_temp_files(self, user_context: AccessContext, action: str,
file_id: str = "", ttl_hours: int = 24) -> Dict[str, Any]:
"""临时文件管理场景"""
if action == "create_temp":
permission_check = self.access_controller.check_permission(
user_context, "temp_files", Permission.WRITE)
if not permission_check["allowed"]:
return {"error": permission_check["reason"]}
# 创建临时文件
temp_dir = tempfile.mkdtemp(prefix="mcp_temp_")
temp_file = f"{temp_dir}/temp_data.txt"
with open(temp_file, 'w') as f:
f.write("这是一个临时文件,将在指定时间后自动删除")
# 提取元数据
metadata = self.metadata_manager.extract_metadata(temp_file)
metadata.category = "temporary"
metadata.tags.extend(["temporary", f"ttl_{ttl_hours}h"])
# 设置过期时间
expire_time = datetime.now() + timedelta(hours=ttl_hours)
# 注册临时文件
temp_id = f"temp_{len(self.temp_file_registry) + 1}"
self.temp_file_registry[temp_id] = {
"path": temp_file,
"expire_time": expire_time,
"owner": user_context.user_id,
"metadata": metadata
}
self.metadata_manager.store_metadata(metadata)
return {
"temp_id": temp_id,
"path": temp_file,
"expires_at": expire_time.isoformat(),
"ttl_hours": ttl_hours
}
elif action == "list_temp":
# 列出用户的临时文件
user_temp_files = []
current_time = datetime.now()
for temp_id, info in self.temp_file_registry.items():
if info["owner"] == user_context.user_id:
is_expired = current_time > info["expire_time"]
user_temp_files.append({
"temp_id": temp_id,
"path": info["path"],
"expires_at": info["expire_time"].isoformat(),
"is_expired": is_expired,
"size": info["metadata"].size
})
return {"temp_files": user_temp_files}
elif action == "cleanup_expired":
# 清理过期的临时文件
permission_check = self.access_controller.check_permission(
user_context, "temp_files", Permission.ADMIN)
if not permission_check["allowed"]:
return {"error": permission_check["reason"]}
current_time = datetime.now()
cleaned_files = []
expired_ids = []
for temp_id, info in self.temp_file_registry.items():
if current_time > info["expire_time"]:
try:
# 安全删除文件和目录
temp_dir = os.path.dirname(info["path"])
if os.path.exists(temp_dir):
shutil.rmtree(temp_dir)
cleaned_files.append(temp_id)
expired_ids.append(temp_id)
except Exception as e:
print(f"清理临时文件失败 {temp_id}: {str(e)}")
# 从注册表中移除
for temp_id in expired_ids:
del self.temp_file_registry[temp_id]
return {
"cleaned_count": len(cleaned_files),
"cleaned_files": cleaned_files
}
# 综合场景演示
def demo_resource_scenarios():
"""演示资源管理的典型场景"""
manager = MCPResourceManager()
# 创建不同角色的用户
developer = AccessContext("dev_001", UserRole.DEVELOPER, "192.168.1.100")
admin = AccessContext("admin_001", UserRole.ADMIN, "10.0.0.1")
user = AccessContext("user_001", UserRole.USER, "192.168.1.200")
print("=== MCP资源管理场景演示 ===\n")
# 场景1:文档库管理
print("📚 场景1:文档库管理")
# 开发者列出文档
doc_result = manager.manage_document_library(developer, "list_documents")
print(f"开发者可访问文档数量: {doc_result.get('count', 0)}")
# 普通用户访问文档
access_result = manager.manage_document_library(user, "access_document", "readme.md")
print(f"用户访问文档: {access_result}")
print()
# 场景2:配置文件管理
print("⚙️ 场景2:配置文件管理")
# 开发者读取开发环境配置
config_read = manager.manage_config_files(developer, "development", "app.json", "read_config")
print(f"读取开发配置: {config_read}")
# 管理员更新生产环境配置
config_update = manager.manage_config_files(admin, "production", "app.json", "update_config")
print(f"更新生产配置: {config_update}")
print()
# 场景3:临时文件管理
print("🗂️ 场景3:临时文件管理")
# 用户创建临时文件
temp_create = manager.manage_temp_files(user, "create_temp", ttl_hours=2)
print(f"创建临时文件: {temp_create}")
# 列出临时文件
temp_list = manager.manage_temp_files(user, "list_temp")
print(f"临时文件列表: {temp_list}")
# 管理员清理过期文件
cleanup_result = manager.manage_temp_files(admin, "cleanup_expired")
print(f"清理结果: {cleanup_result}")
if __name__ == "__main__":
demo_resource_scenarios()
看到这里,你是不是已经被MCP资源管理系统的强大功能震撼到了?从基础的权限控制到智能的元数据管理,再到实际的应用场景,这套系统就像一个超级智能的数字管家,既安全又高效。掌握了这些知识,你就能让AI助手在复杂的资源环境中游刃有余地工作了!
欢迎大家关注同名公众号《凡人的工具箱》:关注就送学习大礼包

更多推荐
 15
15 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)