
一文说清楚人工智能黑话:人工智能、机器学习、深度学习、强化学习与大模型智能体
本文系统梳理了人工智能相关概念与技术:1. 人工智能(AI)是让机器模拟人类智能的科学,核心包括机器学习、自然语言处理、计算机视觉等技术。2. 机器学习分为监督学习(有标签数据训练)和非监督学习(无标签数据聚类),常见算法包括线性回归、决策树、随机森林等。3. 深度学习是机器学习的分支,使用多层神经网络自动提取特征,需要大数据和强大算力支持。4. 强化学习通过"试错-奖励"机制
你是不是经常对这些专业词汇傻傻分不清楚?
人工智能、AI、机器学习、监督学习、非监督学习、神经网络、深度学习、强化学习、大模型、智能体......,
今天我用一篇文章给大家说清楚。
一、人工智能(AI)
1、什么是人工智能
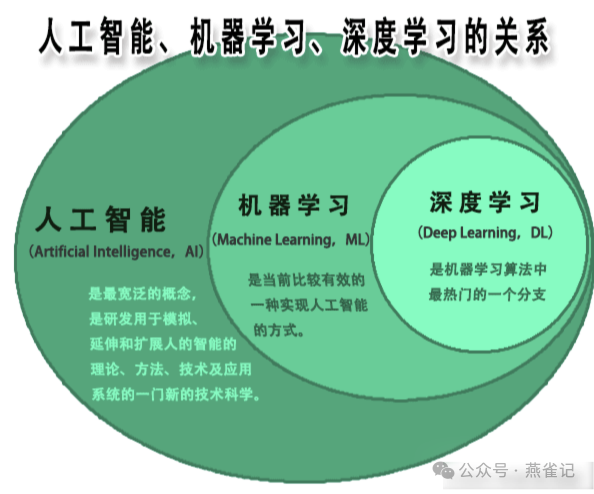
人工智能是一个比较宽泛的概念,包括了机器学习、深度学习、神经网络、深度学习等。就比如有人问你是做什么的?你说是做IT技术的,其实包括了前端开发、后端开发、数据开发、产品设计、UI设计、测试、运维等。
简单来说,人工智能(Artificial Intelligence,英文缩写为 AI)是让机器模拟人类智能的科学与工程。
那么什么是“智能”呢?
机器具备以下通常需要人类才能完成的能力,就可以称为“智能”了。
-
学习(Learning):从数据和经验中获取知识和技能。
-
推理(Reasoning):根据已有信息进行逻辑判断和推导,以解决问题或做出决策。
-
感知(Perception):通过传感器(如摄像头、麦克风)识别和理解环境(如计算机视觉、语音识别)。
-
语言(Language):理解和生成人类语言(自然语言处理)。
-
解决问题(Problem-solving):找到达成特定目标的方法。
2、AI主要的关键技术
AI主要依赖于以下技术:
-
机器学习(Machine Learning, ML):这是AI的核心驱动力。它不是直接给计算机编程指令,而是让计算机通过分析大量数据来自行学习和改进。
-
例子:给一个机器学习系统看一百万张猫的图片,它自己能总结出“猫”的特征,从而学会识别新的猫图片。
-
-
神经网络:神经网络就是一个通过模仿大脑、由相互连接的节点,类似神经元(专家) 组成的计算模型。通过大量数据训练调整连接权重(经验)、从而能够解决极其复杂问题的强大算法。(神经网络又分:全连接神经网络、卷积神经网络、循环神经网络、残差网络、生成对抗网络、Transformer等)
-
例子:一个简单的神经网络可以通过学习大量手写数字的图片和对应标签,最终学会准确识别新的手写数字。
-
-
深度学习(Deep Learning):是机器学习的一个更强大的子领域。它使用类似于人脑的人工神经网络(尤其是多层的“深度”神经网络)来处理复杂的数据。
-
例子:它不仅能用像素识别猫,还能理解自然语言(翻译、生成文本)、生成图片(AI绘画),以及在围棋中做出复杂的决策。
-
-
自然语言处理(Natural Language Processing, NLP):让计算机能够理解、解释和生成人类语言。
-
例子:机器翻译、 chatbots、情感分析。
-
-
计算机视觉(Computer Vision):让计算机能够“看”和理解图像和视频。
-
例子:医疗影像分析、人脸识别、自动驾驶中识别行人和交通标志。
-
3、AI相关技术的关系
人工智能、机器学习、深度学习的关系
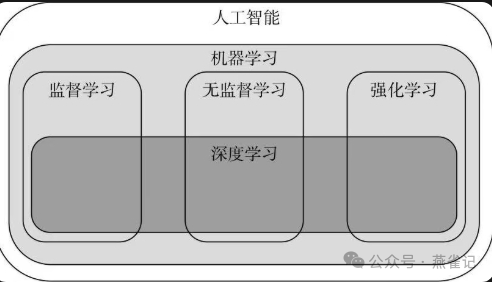
机器学习与监督、非监督学习与强化学习的关系
二、机器学习
1、什么是机器学习
机器学习是一门以问题为导向的学科,能不能解决问题、解决问题的效果好不好是评价算法优劣的唯一标准,许多算法都源自对习以为常的日常生活的深刻观察和思考。
下面用一个通俗的“教小孩认猫”的比喻来理解「机器学习」
想象一下,你想教一个从没见过猫的小孩什么是“猫”。
传统编程方法(死记硬背):
你会给他一本厚厚的规则手册,上面写着:
-
有尖耳朵的动物。
-
眼睛是椭圆的。
-
有胡须。
-
会“喵喵”叫。
...
但问题来了,如果小孩遇到一只没有胡须的猫,或者耳朵耷拉的折耳猫,他可能就认不出来了。这个世界太复杂,很难用几条规则完全概括。
机器学习方法(从经验中学习):
你不需要告诉他规则。你只需要做一件事:
给他看成千上万张不同的猫的图片,同时也给他看一些不是猫(比如狗、汽车、杯子)的图片,并告诉他哪些是猫,哪些不是。
在这个过程中,小孩的大脑(相当于电脑的“算法”)会自己主动寻找和总结规律:
-
“哦,原来这些叫‘猫’的东西,虽然大小颜色不一样,但好像脸都是圆圆的,眼睛有点特别…”
-
“而那些狗,脸型好像更长一些…”
他看的图片越多,总结出的规律就越精准、越抽象。最后,当你再拿出一张他从来没见过的猫的图片时,他就能根据之前总结的经验,大概率准确地认出“这是一只猫”!
最后总结机器学习的核心三要素:
这个过程和机器学习一模一样,需要三个东西:
-
数据(Data):就是上面提到的成千上万张图片。数据是机器学习的“燃料”,没有数据它什么都学不了。数据可以是图片、文字、声音、销售记录等等任何东西。
-
算法(Algorithm):就是小孩大脑的学习方法。是“死记硬背”式地找规律,还是“联想推理”式地找规律?伟大的科学家们发明了各种不同的学习方法(算法模型),用于解决不同的问题。下面会介绍这些不同的算法主要解决什么样的问题。
-
模型(Model):学习的结果。当机器学习算法消化了海量数据后,最终会形成一套它自己总结出来的“规律”或“判断标准”,这个东西就叫“模型”。你可以把它理解成那个已经学会了认猫的小孩的大脑。
之后,我们就可以用这个训练好的“模型”去做预测或判断了。
机器学习 = 给电脑大量数据 + 一种学习方法 → 电脑自己总结出规律(模型) → 用这个规律去解决新问题。
2、监督学习与非监督学习
按照学习方法的不同进行划分,机器学习算法可以分为监督学习、无监督学习、非监督学习、集成学习、深度学习和强化学习。本文重点介绍一下最常提到的监督学习与非监督学习。
上面通过教小朋友认东西来让大家理解什么是机器学习,接下来我们接着用这个比喻:把“机器学习”想成“教小朋友认东西”来认识什么是监督学习与非监督学习。
-
监督学习——“有标准答案的辅导作业”
你拿一摞卡片,每张正面是图片,背面写着正确答案。小朋友先看图,猜答案,再翻背面核对。猜错了就改,猜对了就记住。练得多了,下次看见新图也能猜出来。
特点:-
每张图都有“标准答案”标签(甜/不甜、猫/狗、垃圾/正常)。
-
目标是学会“对号入座”,以后看见新样本就能准确分类或预测数值。
-
-
非监督学习——“没有答案的整理玩具箱”
你把一箱混在一起的乐高倒在地上,小朋友不知道它们该叫啥,只能自己观察:颜色一样的放一堆,形状相似的放一堆。最后可能分出“红方块”“蓝长条”几小堆,但他并不知道官方叫法。
特点:-
没有任何标签,不知道谁是谁。
-
目标是“找结构”——把相似的自动聚一起,或者把异常的挑出来。
-
监督学习=“有答案地学套路”,非监督学习=“没答案地找相似”。
这里要啰嗦一下什么是数据的标签?
标签 = 对一条数据事先记录好的“正确答案”或“目标信息”。
标签可以是:
类别:垃圾邮件/正常邮件
数值:房价 368 万
序列:语音每帧对应的“文字”
图形:卫星图像里每个像素是“建筑”还是“道路”
层级:整幅 CT 图同时带“有结节/无结节”+“结节位置”+“恶性程度”
那么标签到底长什么样呢?
例 1 图像分类
数据 x:一张 224×224 的猫狗照片
标签 y:字符串 “cat” 或 “dog”
(one-hot 编码后可能是 [1,0] 或 [0,1])例 2 房价预测
数据 x:{面积=89 m², 学区=“实验二小”, 地铁距离=300 m, 朝向=“南”}
标签 y:3680000(人民币,连续值)例 3 目标检测
数据 x:街景照片
标签 y:一组框 [{左上(x1,y1), 右下(x2,y2), 类别=“bus”}, {…, 类别=“person”}, …]
JSON 里可能写 50 个数字,对应 10 个框。
PS:标签就是“数据背后的答案纸”。监督学习靠它当“标准答案”来刷题。
3、常用的机器学习算法总结
机器算法按照解决的问题类型及用途可以分为回归、分类、聚类等几大类。
一、监督学习算法分析总结
|
算法名称 |
类型 |
通俗易懂的解释 |
优点 |
缺点 |
主要使用场景及主要使用领域 |
|---|---|---|---|---|---|
| 线性回归 |
回归 |
“找趋势线”
:在一堆散点中画一条最合适的直线或曲线来预测数值。 |
1. 简单直观,易于理解和实现。 |
1. 难以拟合复杂非线性关系。 |
场景
:预测连续的数值结果。 |
| 逻辑回归 |
分类 |
“算概率的专家”
:计算一个事物属于某个类别的概率,用于做出“是”或“否”的判断。 |
1. 计算成本低,速度快,适合大规模数据。 |
1. 难以捕捉复杂的非线性模式。 |
场景
:解决二分类问题。 |
| 决策树 |
分类 |
“自动问答流程图”
:通过一系列 if-else 问题对数据进行层层筛选,最终得出结论。 |
1. 非常直观,模型可可视化,易于解释(白盒模型)。 |
1. 非常容易过拟合,导致泛化能力差。 |
场景
:需要高度可解释性的分类/回归任务。 |
| 随机森林 |
分类 |
“决策树团队投票”
:构建多棵不同的决策树,让它们共同投票,以得到更准确、更稳定的结果。 |
1. 精度高,抗过拟合能力强(集体决策)。 |
1. 相比单棵树可解释性差(黑盒模型)。 |
场景
:对预测精度要求高,且对解释性要求不高的任务。 |
| 支持向量机 |
分类 |
“画最宽安全线的专家”
:努力在两类数据间画一条最宽的“街道”,保证离两边都最远,容错率最高。 |
1. 在中小型数据集上能产生高精度模型。 |
1. 对大规模数据集训练速度慢。 |
场景
:样本量不大但特征复杂的分类问题。 |
| 朴素贝叶斯 |
分类 |
“快刀手”
:基于“特征相互独立”的朴素假设,快速计算属于各个类别的概率,选择最高的那个。 |
1. 速度极快,训练和预测效率非常高。 |
1. “特征条件独立”的假设在现实中很少成立,影响精度。 |
场景
:文本分类和情感分析。 |
| K-最近邻 |
分类 |
“近朱者赤,近墨者黑”
:判断一个新样本的类别,就看它离得最近的K个邻居大多数属于谁。 |
1. 简单易懂,原理清晰。 |
1. 预测阶段计算量大,速度慢(需计算所有距离)。 |
场景
:样本量较小、特征维度较低的分类和回归任务。 |
| 神经网络 |
分类、回归 |
“模仿大脑的专家团队”
:由大量相互连接的“神经元”组成,层层传递和处理信息,能够解决极其复杂的问题。 |
1. 拟合能力极强,能处理极其复杂的非线性模式。 |
1. 是典型的黑盒模型,可解释性极差。 |
场景
:处理感知类复杂问题(图像、语音、文本)。 |
二、非监督学习算法分析总结
|
算法名称 |
类型 |
通俗易懂的解释 |
优点 |
缺点 |
主要使用场景及主要使用领域 |
|---|---|---|---|---|---|
| K-Means |
聚类 |
“物以类聚,自动分组”
:事先指定要分K个组,通过“选中心-分组-重新计算中心”的流程,让组内成员尽可能相似。 |
1. 简单高效,易于理解和实现。 |
1. 必须预先指定K值(簇数)。 |
场景
:快速将数据划分为预定义数量的簇。 |
| 层次聚类 |
聚类 |
“构建层次树”
:要么从单个点开始慢慢合并(自底向上),要么从一个大簇开始慢慢分裂(自顶向下),形成一棵树状结构。 |
1. 无需预先指定簇数。 |
1. 计算复杂度高,不适合大规模数据。 |
场景
:数据量不大且需要可视化层次结构的任务。 |
| DBSCAN |
聚类 |
“找密度相连的部落”
:基于密度进行聚类,能找到被噪声包围的、任意形状的密集区域,并把稀疏处的点标记为噪声。 |
1. 无需指定簇数。 |
1. 对密度变化大的数据集效果不佳。 |
场景
:寻找被噪声干扰的任意形状的密集区域。 |
| 主成分分析(PCA) |
降维 |
“抓住核心,简化数据”
:找到数据中最重要的几个方向(主成分),将高维数据投影到这些方向上,从而实现降维和简化。 |
1. 能有效降低数据维度,缓解维度灾难。 |
1. 可解释性降低,主成分的含义是原始特征的混合。 |
场景
:数据可视化、特征压缩、去除数据噪声和冗余。 |
| 关联规则学习(Apriori) |
数据挖掘 |
“购物篮分析”
:从大量交易数据中挖掘出物品之间的关联规则,最经典的例子就是“买尿布的人经常也会买啤酒”。 |
1. 产生的规则简单易懂,易于解释。 |
1. 会产生大量冗余规则,需要后续筛选。 |
场景
:从大规模交易数据中挖掘物品之间的关联关系。 |
三、深度学习
深度学习是神经网络的一个子领域,也是机器学习的一个分支(机器学习的一种高级方法),特指“层数很深”的神经网络,它模仿人脑的神经网络结构,通过多个“层”来自动学习和提取越来越抽象和复杂的特征。
可以简单的这样理解,深度学习 ≈ 深度神经网络。
前面讲机器学习的时候举了一个“认猫”的例子,其实是基于我们规定好的特征(耳朵的形状、胡须的长度、眼睛的样子等)去学习和判断,但是现实情况会复杂得多,比如出现我们没有告诉过它的特征怎么办?如果把猫耳朵藏起来怎么办?所以规则会限制它的能力。
深度学习怎么办的呢?
你只给她海量的猫图片和不是猫的图片,然后说:“你自己去研究,找出到底是什么规律定义了”猫“。
深度学习这个多层、自下而上、自动提取特征的过程就是深度学习的核心思想,它不需要人类告诉它“猫有胡须”,它能自己从数据中发现并定义出“胡须”这个概念,以及无数其他我们可能都没有想到的细微特征。
总结:如果把传统机器学习比作一个需要详细指令的实习生,那么深度学习就是一个拥有多层分析团队的天才侦探,它能自动从数据中挖掘出最核心、最复杂的规律。 正是这种能力,让它成为了当前人工智能领域最强大的工具。深度学习需要的三大”燃料“:大数据、强大的算力(GPU、TPU)、先进算法。
四、强化学习
强化学习是对英文Reinforced Learning的中文翻译,它的另一个中文名称是“增强学习”。相对于有监督学习和无监督学习而言,强化学习是一个相对独特的分支;前两者偏向于对数据的静态分析,后者倾向于在动态环境中寻找合理的行为决策。
强化学习又称基于人类反馈的强化学习(RLHF),DeepSeek-R1就是使用了强化学习进行训练。
强化学习是“范式”:它是一种学习方法,一套训练规则。它规定了如何通过“尝试-错误-奖励”来学习和优化决策。这个模式是不是我们学习一个很相似,比如:迟到-扣钱;工作业绩好-绩效A(涨工资-继续业绩好。
所以,人们说:强化学习是最接近人工智能的一个机器学习领域。
强化学习的基本流程
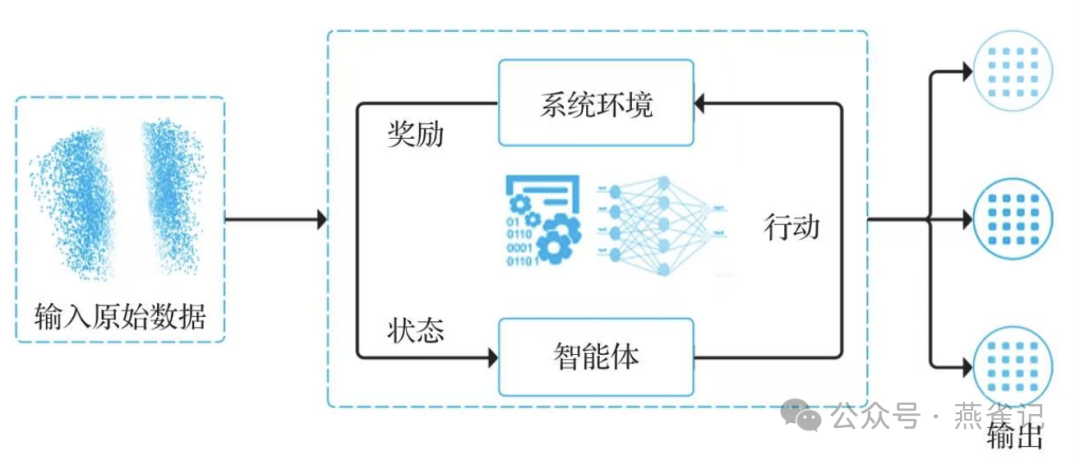
那么强化学习和机器学习的其他方式有什么不同呢?一个最非常重要的区别:
-
监督学习 (像老师教学生):你有完整的“标准答案”。比如,你给机器看一万张标好了“这是猫”、“这是狗”的图片让它学习。学习过程需要标注好的数据。
-
强化学习 (像自学成才):没有标准答案! 只有一把“快乐尺”——奖励。智能体一开始什么都不知道,只能通过不停地尝试各种动作(甚至是错误的、搞砸的动作),从环境给的奖励或惩罚中自己摸索出最佳做法。
它的最大特点是:试错探索和延迟奖励。
强化学习就是让一个智能体在环境中通过不断试错,并根据结果带来的奖励或惩罚,自我学习和进化,最终找到能获得最多奖励的最佳行为方式。
它是最接近人类“实践经验”学习方式的一种人工智能,也是让AI在复杂决策领域(如游戏、机器人、自动驾驶)超越人类的关键技术。
五、大模型与智能体
大模型是指参数规模庞大、训练数据海量、能力广泛的深度学习模型,如GPT、豆包、deepseek、通义千问等。
大模型具有巨大的参数规模,包含数十亿甚至数千亿个以上的参数,这使它具有强大的表达能力和学习能力。(不了解什么是大模型的参数的同学可以看我之前写的文章:你不得不知道的大模型参数)其通过训练海量数据来学习复杂的模式和特征,具有涌现能力(随着规模增大,表现出“举一反三”、逻辑推理等复杂能力),能够从原始训练数据中自动学习并发现新的、更高层次的特征和模式,还具有更好的性能和泛化能力,可在多种任务(文本生成、翻译、问答、代码等)上表现出色,同时具备多任务学习能力。
智能体是指通过持续感知外部环境、自主决策并执行行动来达成预设目标的先进人工智能实体。
可以理解为智能体是利用AI技术软件程序或者系统,严格意义上来说这里的AI技术不仅限于大模型。现在人们提到的智能体大多数都和大模型相关,那么大模型与智能体是一个什么关系呢?
-
大模型是智能体的“大脑”:提供知识、推理和语言理解能力。
-
智能体是大模型的“延伸”:通过补充记忆、工具使用和反馈机制,克服大模型的静态性局限。
-
大模型像一本百科全书+推理引擎,需人类提问才能发挥作用;
-
智能体像一位自主实习生,能主动用百科全书解决问题,甚至调用工具(如搜索、发邮件)完成任务。
最后,相信你对人工智能涉及到的相关概念已经有了一个比较清晰的认识。下次跟别人交流人工智能的时候不再傻傻分不清楚,像在听天书了。
我建了一个专注于探索AI技术与应用的知识星球,感兴趣的欢迎加入,让我们一起交流、成长、成事、成就自我。

更多推荐
 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)