
LLaMA-Factory大模型微调全攻略:从零开始学AI模型训练(建议收藏)
本文详细介绍了使用LLaMA-Factory微调大语言模型的完整流程。内容涵盖环境配置(CUDA、Ubuntu、gcc等依赖安装)、数据处理(自定义数据集配置)、WebUI零代码微调界面操作、SFT训练命令、LoRA模型合并方法,以及多种推理方式(chat/webchat/vllm引擎)。文章提供了具体命令示例和配置文件说明,特别强调了dataset_info.json文件的关键作用。最后还包含大
本文详细介绍了使用LLaMA-Factory进行大模型微调的完整流程,包括环境配置、数据处理、WebUI零代码微调、SFT训练、LoRA合并、模型推理与评估等关键步骤。文章提供了详细的命令示例和配置指导,支持自定义数据集训练,并介绍了多种推理方式,帮助开发者快速上手大模型微调技术。
一、安装依赖(以linux服务器为例):
1、NVIDIA 的 GPU,在 https://developer.nvidia.com/cuda-gpus 查看您的 GPU 是否支持CUDA
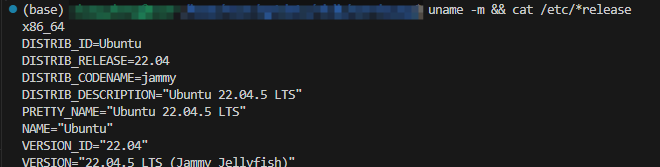
2、Ubuntu操作系统,在linu后台执行在命令行中输入 uname -m && cat /etc/*release查看回显
3、gcc . 在命令行中输入 gcc --version ,应当看到类似的输出
gcc
(
Ubuntu
11
.4.0-1ubuntu1~22.04
)
11
.4.0
如果没有依赖按照下面链接上的指导安装:
https://llamafactory.readthedocs.io/zh-cn/latest/
cuda的驱动兼容问题可找厂商确认。
运行以下指令以安装 LLaMA-Factory 及其依赖:
git
clone
--depth
1
https://github.com/hiyouga/LLaMA-Factory.git
cd
LLaMA-Factory pip
install
-e
".[torch,metrics]"
完成安装后,可以通过使用 llamafactory-cli version 来快速校验安装是否成功
二、数据处理
dataset_info.json 包含了所有经过预处理的 本地数据集 以及 在线数据集。如果您希望使用自定义数据集,请 务必 在 dataset_info.json 文件中添加对数据集及其内容的定义。具体方法看参考文档https://llamafactory.readthedocs.io/zh-cn/latest/
的数据处理页面。
三、打开微调界面WEB
UI
执行命令:llamafactory-cli webui
回显中的网页地址打开 URL: http://0.0.0.0:7860

支持WebUI 零代码微调大语言模型,但是界面不支持视频和图片数据同时训练。
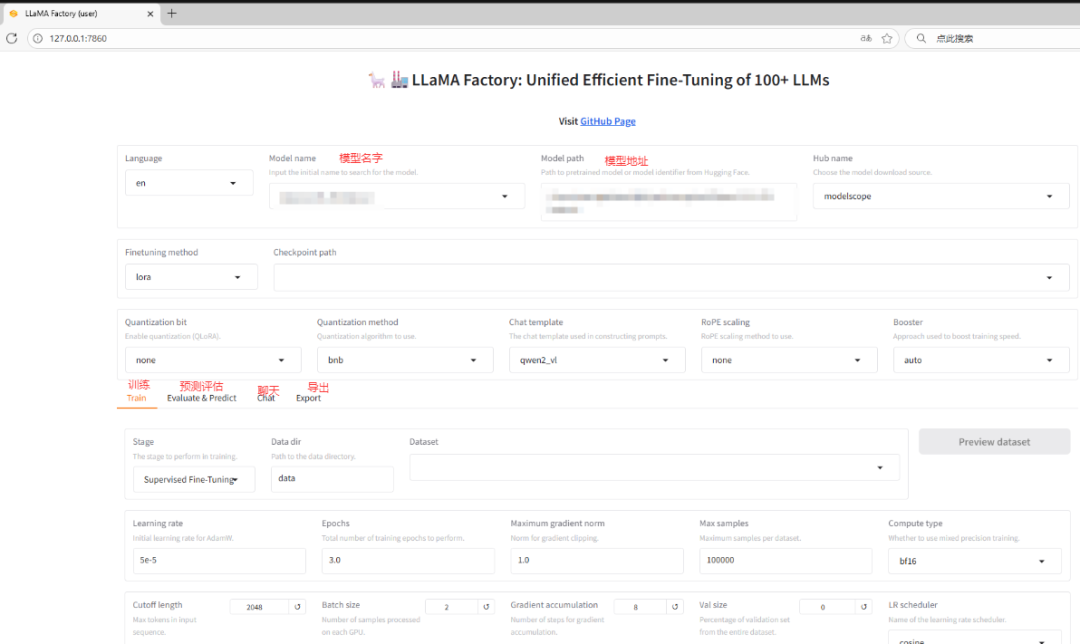
在开始训练模型之前,您需要指定的参数有:
- 模型名称及路径
- 训练阶段
- 微调方法
- 训练数据集
- 学习率、训练轮数等训练参数
- 微调参数等其他参数
- 输出目录及配置路径
随后,您可以点击 开始 按钮开始训练模型。
如果您需要使用自定义数据集,请在 data/data_info.json 中添加自定义数据集描述并确保 数据集格式 正确,否则可能会导致训练失败。
模型训练完毕后,您可以通过在评估与预测界面通过指定 模型 及 适配器 的路径在指定数据集上进行评估。
如果您对模型效果满意并需要导出模型,您可以在导出界面通过指定 模型、 适配器、 分块大小、 导出量化等级及校准数据集、 导出设备、 导出目录 等参数后点击 导出 按钮导出模型。
四、SFT 训练
您可以使用以下命令使用 examples/train_lora/llama3_lora_sft.yaml 中的参数进行微调: llamafactory-cli train examples/train_lora/llama3_lora_sft.yaml
也可以通过追加参数更新 yaml 文件中的参数: llamafactory-cli train examples/train_lora/llama3_lora_sft.yaml \
learning\_rate=1e-5 \
logging\_steps=1
五、LoRA 合并
当我们基于预训练模型训练好 LoRA 适配器后,我们不希望在每次推理的时候分别加载预训练模型和 LoRA 适配器,因此我们需要将预训练模型和 LoRA 适配器合并导出成一个模型,并根据需要选择是否量化。根据是否量化以及量化算法的不同,导出的配置文件也有所区别。 您可以通过 llamafactory-cli export merge_config.yaml 指令来合并模型。其中 merge_config.yaml 需要您根据不同情况进行配置。
六、推理
LLaMA-Factory 支持多种推理方式。 您可以使用 llamafactory-cli chat inference_config.yaml 或 llamafactory-cli webchat inference_config.yaml 进行推理与模型对话。对话时配置文件只需指定原始模型 model_name_or_path 和 template ,并根据是否是微调模型指定 adapter_name_or_path 和 finetuning_type。 如果您希望向模型输入大量数据集并保存推理结果,您可以启动 vllm 推理引擎对大量数据集进行快速的批量推理。您也可以通过 部署 api 服务的形式通过 api 调用来进行批量推理。 默认情况下,模型推理将使用 Huggingface 引擎。 您也可以指定 infer_backend: vllm 以使用 vllm 推理引擎以获得更快的推理速度。
注意:使用任何方式推理时,模型 model_name_or_path (模型位置)需要存在且与 template (数据集模板)相对应。
七、评估
通用评估
在完成模型训练后,您可以通过
llamafactory-cli eval examples/train_lora/llama3_lora_eval.yaml 来评估模型效果。
训练案例(命令微调方式)
1、数据集设置:
dataset_info.json 文件是一个配置文件包含数据集的位置和描述,如果您希望使用自定义数据集,请务必 在 dataset_info.json 文件中添加对数据集及其内容的定义。
例如DPO训练,dataset_info.json 文件中添加的train.json就是实际的数据集
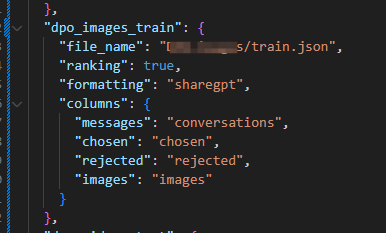
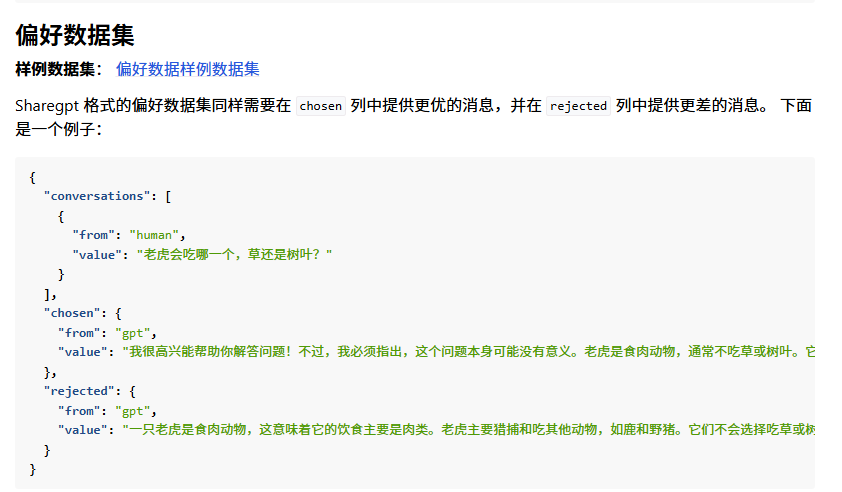
配置数据集train.json,可以写代码生成,数据集少的情况下可以手动写,格式入下:
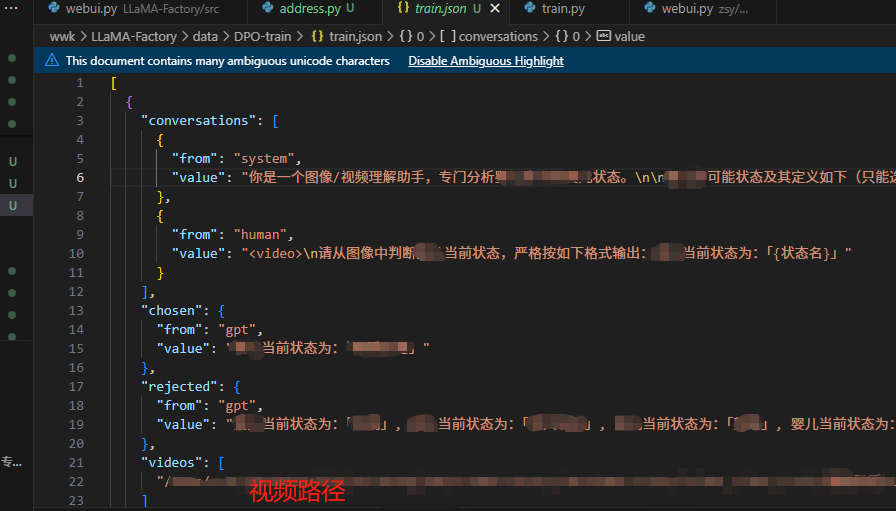
2、执行微调训练

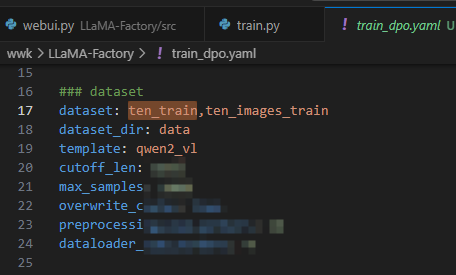
train.yaml 提供了微调时的配置也可以根据实际情况改成其他名字比如dpo_train.yaml。该配置指定了模型参数、微调方法参数、数据集参数以及评估参数等。您需要根据自身需求自行配置。

这里的dataset配置会去data/dataset_info.json查找对应名称的数据集路径。
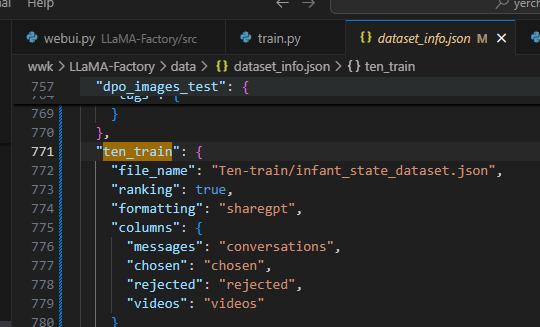
训练结果会保存在对应配置的输出路径里。

读者福利大放送:如果你对大模型感兴趣,想更加深入的学习大模型**,那么这份精心整理的大模型学习资料,绝对能帮你少走弯路、快速入门**
如果你是零基础小白,别担心——大模型入门真的没那么难,你完全可以学得会!
👉 不用你懂任何算法和数学知识,公式推导、复杂原理这些都不用操心;
👉 也不挑电脑配置,普通家用电脑完全能 hold 住,不用额外花钱升级设备;
👉 更不用你提前学 Python 之类的编程语言,零基础照样能上手。
你要做的特别简单:跟着我的讲解走,照着教程里的步骤一步步操作就行。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
现在这份资料免费分享给大家,有需要的小伙伴,直接VX扫描下方二维码就能领取啦😝↓↓↓
为什么要学习大模型?
数据显示,2023 年我国大模型相关人才缺口已突破百万,这一数字直接暴露了人才培养体系的严重滞后与供给不足。而随着人工智能技术的飞速迭代,产业对专业人才的需求将呈爆发式增长,据预测,到 2025 年这一缺口将急剧扩大至 400 万!!
大模型学习路线汇总
整体的学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战,跟着学习路线一步步打卡,小白也能轻松学会!
大模型实战项目&配套源码
光学理论可不够,这套学习资料还包含了丰富的实战案例,让你在实战中检验成果巩固所学知识
大模型学习必看书籍PDF
我精选了一系列大模型技术的书籍和学习文档(电子版),它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。
大模型超全面试题汇总
在面试过程中可能遇到的问题,我都给大家汇总好了,能让你们在面试中游刃有余
这些资料真的有用吗?
这份资料由我和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。
👉获取方式:
😝有需要的小伙伴,可以保存图片到VX扫描下方二维码免费领取【保证100%免费】
相信我,这套大模型系统教程将会是全网最齐全 最适合零基础的!!
更多推荐



 12
12 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)