
你不需要 GraphRAG!构建一个多策略图谱思维(Multi-Strategy Graph Thinking)AI Agent
BYOKG(Bring Your Own Knowledge Graph,自定义知识图谱)”是一个旨在提升知识图谱问答(KGQA)能力的框架,它通过将多种外部知识源与大语言模型(LLMs)整合来实现这一目标。该框架利用多种图谱检索策略——包括实体链接、子图提取和Cypher查询执行,从不同的知识图谱中收集相关上下文信息。BYOKG 的核心目标是:通过将这些检索技术与 LLMs 的推理能力相结合,提

在本文中,我将通过一个超简洁的教程,向你展示如何构建多策略图谱思维(Multi-Strategy Graph Thinking),进而为你的业务或个人使用打造一个功能强大的 Agent 聊天机器人。
GraphRAG(将知识图谱技术与 RAG 相结合)是今年下半年大语言模型(LLM)应用领域的热门方向。我曾花了大量时间研究 GraphRAG,虽然它们确实非常出色,但也存在一些不足之处。
最近,我通过创建节点和边构建了自己的知识图谱:将输入文档切分为 tokens,记录每个切分块中包含的实体和关系,并利用 LLM 生成输出结果。
知识图谱固然有趣,但它们往往存在缺陷。我的知识图谱依赖大语言模型(LLM)Agent 进行图谱遍历和检索 —— 这种方法对遍历的初始化方式非常敏感,容易出现实体链接错误,而且在自定义(“自带”)知识图谱上的通用性可能较差。
许多知识图谱中充斥着杂乱、过时或缺失的信息。这就像试图用一张破损的地图导航 —— 街道名称错误,道路信息缺失。此外,这些系统在处理需要跨多个关系进行多跳推理的复杂问题时也会遇到困难,尤其是在大型或结构复杂的图谱中。更糟糕的是,它们往往会忽略文本文档等其他有用信息源,而这些文本文档中可能包含更优的答案。
当知识图谱包含过多信息时,可能会给大语言模型带来负担 —— 尤其是那些上下文处理能力有限的模型。这些模型在处理医学或时间推理等专业领域话题时也会力不从心,而这类话题通常需要自定义的检索和推理策略。
这正是 “自定义知识图谱”(Bring Your Own Knowledge Graph)发挥作用的地方。它结合了多种检索策略 —— 例如实体链接、子图检索和 Cypher 查询执行 —— 以收集更丰富、更相关的上下文信息。同时,它采用基于评分的方法,在提升性能的同时减少 LLM 调用次数,动态获取相关图谱数据,并为语言模型提供更优质的推理上下文依据。
接下来,我将通过一个实时聊天机器人的快速演示来向你直观展示上述功能。
我会向聊天机器人提出一个问题:“温顿・马萨利斯(Wynton Marsalis)出生地所在地区相关的电影类型是什么?” 如果你观察 Agent 生成输出的过程,会发现该 Agent 会从 CSV 文件中加载(loads)数据,并打印(prints)出该图谱包含(contains)的节点和边的数量。
它会利用知识图谱处理问题,让 LLM 在图谱模式的引导下,确定哪些实体、路径和答案候选是相关的。随后,它会解析 LLM 生成的产物,并使用模糊字符串匹配器(FuzzyStringIndex)将 LLM 生成的自由文本实体与图谱中的实际节点关联起来。
接下来,它会使用 EntityLinker 将实体和答案候选都关联回图谱,确保所有推理都基于真实数据;AgenticRetriever 会利用 LLM 实现图谱的智能导航,从已关联的实体出发,选择要遵循的关系;而 PathRetriever 则会超越单个三元组,遵循多跳推理路径。
最后,它会使用 “自定义知识图谱”(Bring Your Own Knowledge Graph)将所有环节整合起来 —— 包括关联、检索和生成。它接收问题后,执行所有必要步骤以收集基于图谱的证据,并利用 LLM 生成最终答案。
什么是 BYOKG RAG?
“BYOKG(Bring Your Own Knowledge Graph,自定义知识图谱)”是一个旨在提升知识图谱问答(KGQA)能力的框架,它通过将多种外部知识源与大语言模型(LLMs)整合来实现这一目标。该框架利用多种图谱检索策略——包括实体链接、子图提取和Cypher查询执行,从不同的知识图谱中收集相关上下文信息。
BYOKG 的核心目标是:通过将这些检索技术与 LLMs 的推理能力相结合,提升 KGQA 系统的准确性、鲁棒性和通用性,从而在不同领域和知识库中,生成更精准、更贴合上下文的答案。
它的工作原理是什么?
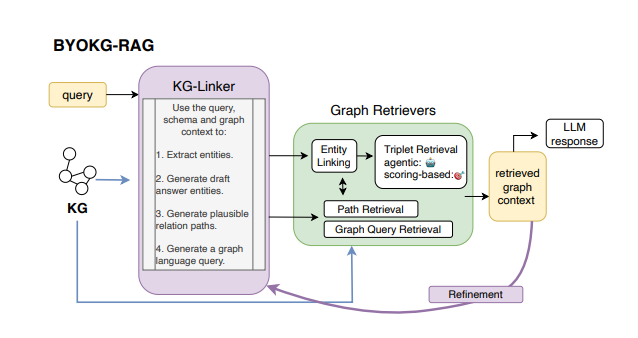
如上图所示,BYOKG 架构包含两个核心组件:KG-Linker 和 Graph Retrievers(图谱检索器)。
-
KG-Linker它是 BYOKG-RAG 框架中基于 LLM 的核心组件,其功能是生成多种图谱产物(graph artifacts),而非直接遍历知识图谱。当输入用户查询、图谱模式(graph schema)以及可选上下文后,它通过单次 LLM 调用生成四类关键产物:从问题中提取的实体、连接这些实体的可能关系路径、可执行的图谱查询(如 OpenCypher)以及候选答案草稿。
-
Graph Retrievers(图谱检索器)它是 BYOKG-RAG 中的专用工具集,接收 KG-Linker 生成的产物,并在知识图谱上执行实际的图谱操作。该组件包含四个主要模块:
-
Entity Linking(实体链接):通过字符串/嵌入匹配,将实体映射到图谱中的对应节点;
-
Path Retrieval(路径检索):通过图谱遍历,执行关系路径查询;
-
Graph Query Retrieval(图谱查询检索):运行 OpenCypher 等可执行查询;
-
Triplet Retrieval(三元组检索):通过智能体(agentic)探索或语义评分,找到相关事实。
-
BYOKG RAG 与 GraphRAG 的对比
BYOKG-RAG 与 GraphRAG 均为用于提升知识图谱问答(KGQA)能力的框架,但二者在设计理念与灵活性上存在差异。BYOKG-RAG 采用多策略检索方法 —— 整合了实体链接、智能体遍历(agentic traversal)、图谱重排序(graph reranking)与基于文本的检索 —— 能动态适配不同的知识图谱(KG)结构与问题类型。
该框架针对零样本(zero-shot)和少样本(few-shot)场景进行了优化,所需训练数据极少,且包含自终止机制(self-termination mechanism),一旦收集到足够信息便会停止检索。
与之相反,GraphRAG 依赖经过大规模标注数据集训练的有监督或微调检索器(supervised or fine-tuned retrievers),通过单一的静态步骤获取相关子图。尽管 GraphRAG 在训练效果良好时能实现较高精度,但它对新的知识图谱(KG)或新问题类型的适应性较弱,且通常需要更高的训练成本。
开始编程吧
在深入开发应用之前,我们需要为代码创建一个合适的运行环境。为此,我们需先安装必要的 Python 库。
-
首先安装支持模型运行的库,通过
pip安装依赖包。由于本演示使用 Claude 模型,你需要先配置好 Bedrock API Key。
!pip install https://github.com/awslabs/graphrag-toolkit/archive/refs/tags/v3.10.7.zip#subdirectory=byokg-rag-
下一步是常规操作:导入相关库,这些库的作用会在后续代码中逐步体现。
我们首先从相关模块中导入所需类:
-
LocalKGStore类提供了操作知识图谱的接口(即“图谱存储”)
from graphrag_toolkit.byokg_rag.graphstore import LocalKGStore
graph_store = LocalKGStore()
graph_store.read_from_csv('freebase_tiny_kg.csv')
# 打印图谱统计信息
schema = graph_store.get_schema()
number_of_nodes = len(graph_store.nodes())
number_of_edges = len(graph_store.get_triplets())
print(f"The graph has {number_of_nodes} nodes and {number_of_edges} edges.")
# 我们也来看一下节点 "Wynton Marsalis" 的相邻边
import random
sample_triplets = graph_store.get_one_hop_edges(["Wynton Marsalis"])
sample_triplets = random.sample(list(sample_triplets["Wynton Marsalis"].items()), 3)
print("Some neighboring edges of node 'Wynton Marsalis' are: ", sample_triplets)上述代码的核心逻辑的如下:
-
使用本地知识图谱(LocalKGStore)管理图谱数据结构;
-
从 CSV 文件中读取数据(该文件包含定义知识图谱的结构化三元组:头实体、关系、尾实体);
-
检查图谱:提取图谱模式(schema)并计算基础统计信息(节点数、边数);
-
聚焦节点“Wynton Marsalis”:使用
get_one_hop_edges()方法获取该节点的直接相邻边(即“一跳”范围内的边); -
用 Python 的
random.sample()从相邻边中随机选择 3 条,最终打印这些边,以此展示与“Wynton Marsalis”相关的示例关系。
KG Linker
question = "What genre of film is associated with the place where Wynton Marsalis was born?"
answer = "Backstage Musical"
from graphrag_toolkit.byokg_rag.graph_connectors import KGLinker
from graphrag_toolkit.byokg_rag.llm import BedrockGenerator
# 初始化大语言模型(LLM)
llm_generator = BedrockGenerator(
model_name='us.anthropic.claude-3-5-sonnet-20240620-v1:0',
region_name='us-west-2')
kg_linker = KGLinker(graph_store=graph_store, llm_generator=llm_generator)
response = kg_linker.generate_response(
question=question,
schema=schema,
graph_context="Not provided. Use the above schema to understand the graph."
)
response
artifacts = kg_linker.parse_response(response)
artifacts研究人员提出的问题是“温顿·马萨利斯(Wynton Marsalis)出生地所在地区相关的电影类型是什么?”,预期答案为“后台音乐剧(Backstage Musical)”。研究目标是让系统能够借助LLM的语义理解能力,完成知识图谱中的多跳推理。
他们使用BedrockGenerator连接到Amazon Bedrock,并调用部署在“us-west-2”区域的Claude 3.5 Sonnet模型。
随后构建了KGLinker实例,用于连接图谱数据与LLM——KGLinker相当于结构化知识与自然语言理解之间的桥梁。在调用时,研究人员传入了问题、图谱模式(schema,用于定义实体与关系的组织方式),以及一条默认提示信息(表明未提供明确的图谱上下文,以此引导模型基于图谱模式进行推理)。
通过generate_response方法生成结构化的LLM响应,该方法会根据问题尝试提取相关路径或推理步骤;之后调用parse_response方法解析响应结果,从中提取出实体路径、子图结构等有意义的产物(artifacts)。
Entity Linking
from graphrag_toolkit.byokg_rag.indexing import FuzzyStringIndex
from graphrag_toolkit.byokg_rag.graph_retrievers import EntityLinker
# 为字符串匹配添加图谱节点文本
string_index = FuzzyStringIndex()
string_index.add(graph_store.nodes())
retriever = string_index.as_entity_matcher()
entity_linker = EntityLinker(retriever=retriever)
linked_entities = entity_linker.link(artifacts["entity-extraction"], return_dict=False)
linked_answers = entity_linker.link(artifacts["draft-answer-generation"], return_dict=False)
linked_entities, linked_answers研究人员构建了一个实体链接流水线,用于将LLM输出中的自由文本提及(free-text mentions)关联回知识图谱中的实际节点。
首先,通过初始化FuzzyStringIndex(模糊字符串索引)实现模糊匹配能力——该索引会从graph_store中读取所有图谱节点名称并建立索引;随后调用as_entity_matcher()方法,将模糊索引转换为可调用的实体消歧工具(retriever)。接着,使用该retriever创建EntityLinker(实体链接器)——EntityLinker的核心作用是将LLM生成的实体转换为知识图谱中的实际节点ID,为后续基于图谱的遍历与推理提供基础。
之后,研究人员将前一步LLM返回的“实体提取(entity-extraction)”和“候选答案草稿(draft-answer-generation)”两类产物传入EntityLinker的link()方法,完成链接处理。这两类产物中包含需要与图谱节点匹配的实体名称和候选答案名称。
Triplet Retrieval
from graphrag_toolkit.byokg_rag.graph_retrievers import AgenticRetriever
from graphrag_toolkit.byokg_rag.graph_retrievers import GTraversal, TripletGVerbalizer
graph_traversal = GTraversal(graph_store)
graph_verbalizer = TripletGVerbalizer()
triplet_retriever = AgenticRetriever(
llm_generator=llm_generator,
graph_traversal=graph_traversal,
graph_verbalizer=graph_verbalizer)
triplet_context = triplet_retriever.retrieve(query=question, source_nodes=linked_entities)
triplet_context接下来,研究人员设计了一个三元组检索器(triplet retriever),它能够模拟智能体(agent)根据问题意图在实体间导航,从而对知识图谱进行推理。该检索器将LLM与图谱遍历工具相结合,形成了AgenticRetriever(智能体检索器)。
具体步骤如下:首先初始化GTraversal(图谱遍历器),它为系统提供了从指定实体集出发遍历知识图谱的能力;接着构建TripletGVerbalizer(三元组描述器),其作用是将每个检索到的三元组(头实体、关系、尾实体)转换为LLM易于理解和评估的格式。
随后,调用retrieve()方法生成三元组上下文(triplet_context),调用时传入原始问题和已完成链接的实体(linked_entities)作为起始点。该方法最终会返回一组三元组——每个三元组代表一个有意义的事实或路径,LLM认为这些三元组对回答当前问题最有帮助。
Path Retrieval
from graphrag_toolkit.byokg_rag.graph_retrievers import PathRetriever
from graphrag_toolkit.byokg_rag.graph_retrievers import GTraversal, PathVerbalizer
graph_traversal = GTraversal(graph_store)
path_verbalizer = PathVerbalizer()
path_retriever = PathRetriever(
graph_traversal=graph_traversal,
path_verbalizer=path_verbalizer)
metapaths = [[component.strip() for component in path.split("->")] for path in artifacts["path-extraction"]]
shortened_paths = []
for path in metapaths:
if len(path) > 1:
shortened_paths.append(path[:1])
for path in metapaths:
if len(path) > 2:
shortened_paths.append(path[:2])
metapaths += shortened_paths
path_context = path_retriever.retrieve(linked_entities, metapaths, linked_answers)
path_context
context = list(set(triplet_context + path_context))
print(f"Success! Ground-truth answer `{answer}` retrieved!") if answer in '\n'.join(context) else print("Failure..")研究人员构建了一个基于路径的推理系统,该系统利用元路径(metapaths,即结构化的关系序列)深入挖掘知识图谱,提取实体间有意义的关联路径。
他们在使用PathRetriever(路径检索器)时,需同时传入graph_traversal(图谱遍历器)组件和PathVerbalizer(路径描述器)。其中,图谱遍历器复用了此前初始化的GTraversal实例,用于遍历图谱;路径描述器则是新初始化的组件,作用是将检索到的路径转换为人类可读、且LLM可理解的格式。
研究人员从LLM的输出结果中生成元路径(metapaths),并补充了较短版本的路径(截取元路径的前1个或前2个组件),以捕捉部分关联模式。随后,调用PathRetriever的retrieve()方法,检索连接问题实体与潜在答案的相关路径。最后,将这些路径结果与之前的三元组结果合并,并检查正确答案“后台音乐剧(Backstage Musical)”是否存在于合并后的结果中——以此判断本次检索成功与否。
BYOKG RAG
from graphrag_toolkit.byokg_rag.byokg_query_engine import ByoKGQueryEngine
byokg_query_engine = ByoKGQueryEngine(
graph_store=graph_store,
kg_linker=kg_linker,
triplet_retriever=triplet_retriever,
path_retriever=path_retriever,
entity_linker=entity_linker
)
retrieved_context = byokg_query_engine.query(question)
answers, response = byokg_query_engine.generate_response(question, "\n".join(retrieved_context))
print("Retrieved context: ", "\n".join(retrieved_context))
print("Generated answers: ", answers)
print(f"Success! Ground-truth answer `{answer}` retrieved!") if answer in '\n'.join(answers) else print("Failure..")最后,研究人员构建了完整的“自定义知识图谱检索增强生成(Bring Your Own Knowledge Graph - RAG,简称BYOKG-RAG)”流水线,即ByoKGQueryEngine(自定义知识图谱查询引擎)。该引擎整合了所有组件——图谱存储(graph_store)、链接器(linkers)和检索器(retrievers),能够处理自然语言问题:先检索相关的图谱上下文,再生成答案。
研究人员将目标问题输入该引擎,然后检查正确答案“后台音乐剧(Backstage Musical)”是否出现在生成结果中。若存在,则判定为成功;反之,则判定为失败。
结论
BYOKG-RAG通过将多种检索策略与大语言模型(LLMs)整合,显著推动了知识图谱问答(KGQA)技术的发展。在多个不同基准数据集上的大量实验表明,该框架无需依赖训练数据,就能实现更优的性能和更强的通用性——这一结果也凸显了迭代式、多策略图谱检索方法的重要价值。
更多推荐

 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)