
大模型微调(四)——LLaMA Factory微调Qwen3 8B,大模型入门到精通,收藏这篇就足够了!
LLaMA Factory 是一个简单易用且高效的大型语言模型训练与微调平台。通过 LLaMA Factory,可以在无需编写任何代码的前提下,在本地完成上百种预训练模型的微调。
LLaMA Factory 是一个简单易用且高效的大型语言模型训练与微调平台。通过 LLaMA Factory,可以在无需编写任何代码的前提下,在本地完成上百种预训练模型的微调。并且更新及时,是微调的好工具。
配置数据集
使用构建完成的数据集,命名为CCER.json。
-
-
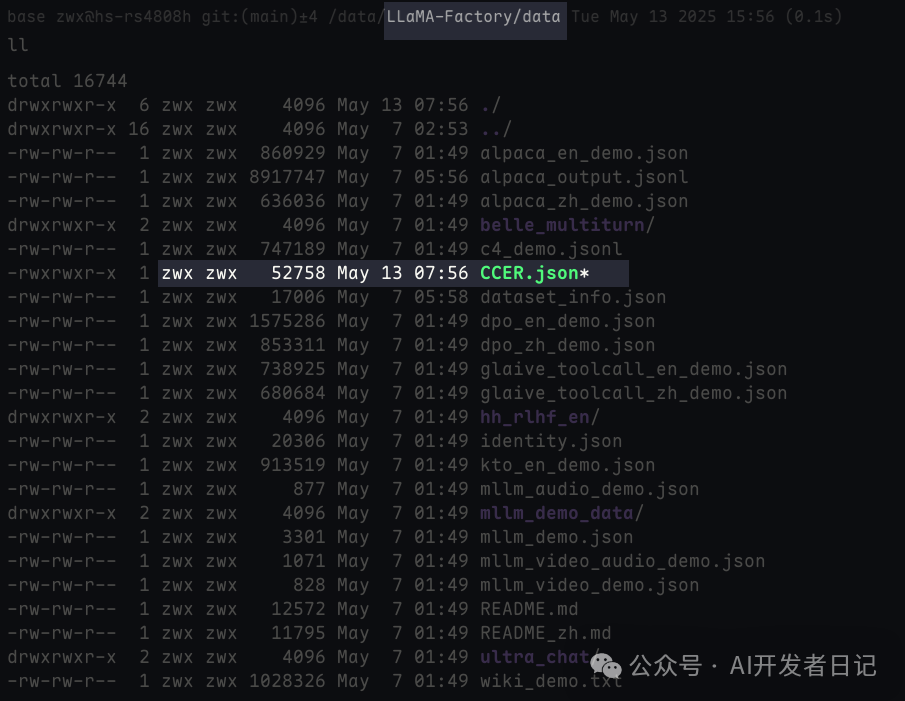
将CCER.json数据集添加到LLaMA Factory的data目录
-
-
-
修改dataset_info.json注册数据集
将我们的ccer数据集添加进去,可以看到LLaMA Factory自带了很多数据集
{ ... "ccer": { "file_name":"CCER.json" }, ... } -
配置微调参数
-
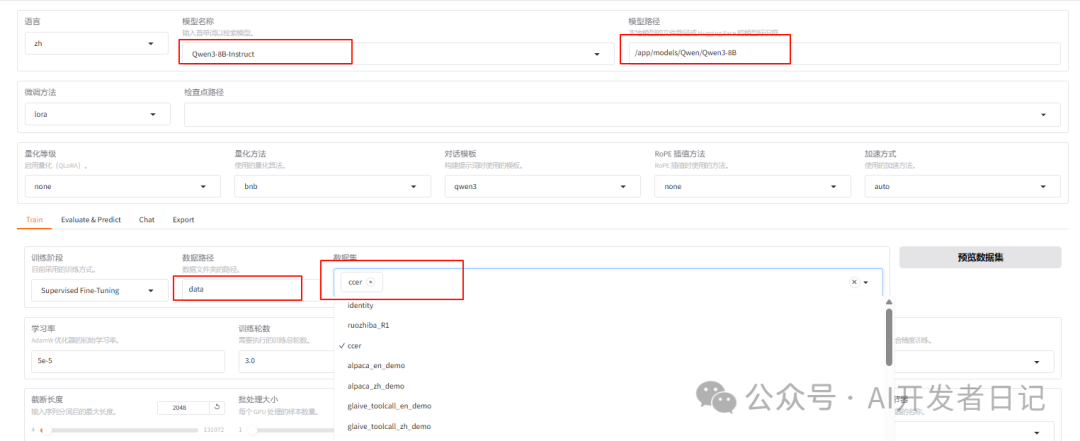
选择模型、模型路径
-
选择微调方法,有lora,full,freeze三种(参考系列文章第二篇),选择lora
-
选择训练数据集,在下拉框中,可以看到我们上一步注册ccer数据集
通用训练参数
-
学习率
-
描述:控制模型参数更新的步长。
-
建议:
-
常见范围是 1×10−4 到 5×10−4 (例如,1e-4, 3e-4)。
-
具体最佳值取决于模型、数据集和批次大小,需要实验调整。
-
可以配合学习率调节器 (learning rate scheduler) 使用,如 cosine 或 linear 衰减。
-
训练轮数
-
描述:整个训练数据集被模型学习的次数。
-
建议:
-
通常 1 到 5 个 epochs 可能就足够了,具体取决于数据集大小和任务复杂度。
-
密切监控验证集上的性能,以避免过拟合,并根据需要进行早停。
-
批处理大小
-
描述:每次参数更新所用的样本数量。
-
建议:
-
在显存允许的范围内,较大的批次大小通常能提供更稳定的梯度。
-
常见的批次大小有 4, 8, 16, 32 等。
LoRA参数
-
LoRA秩(r)
-
描述:LoRA 适配器中低秩分解矩阵的秩。它直接决定了添加到模型中的可训练参数数量。r 越大,可训练参数越多,理论上模型能学习到更复杂的模式,但也可能增加过拟合的风险和计算成本。
-
建议:
-
通常从较小的值开始尝试,如 4, 8, 16, 或 32,如果任务非常复杂或数据集非常大,可以尝试更大的 r 值,如 64 甚至 128。
-
权衡性能提升和增加的参数量/训练时间。较小的 r 值可以实现更快的训练和更小的模型文件。
-
LoRA缩放系数
-
描述:用于调整 LoRA 适配器输出的权重。通常,它被设置为与 r 相同的值或 r 的两倍。这个参数可以看作是对 LoRA 适配器激活的“强度”进行调整。
-
建议:
-
一个常见的做法是将 lora_alpha设置为 r 的两倍。例如,如果 r=8,则 lora_alpha=16。
-
需要实验确定
-
LoRA随即丢弃
-
描述:在 LoRA 层的 A 矩阵之后应用 dropout,以防止过拟合。
-
建议:
-
如果担心过拟合,可以设置一个较小的值,如 0.05 或 0.1。某些数据集或任务,不需要 dropout (可以设置为 0)。
-
如果训练数据较少,或者模型表现出过拟合的迹象,可以尝试增加 dropout 值。
-
LoRA+ 学习率比例(λ)
-
描述:LoRA+ 是一种对标准 LoRA微调方法的改进。对于嵌入维度较大的模型,这种做法可能略优于LoRA微调。
-
建议:
-
λ 应该大于等于 1。
-
标准的 LoRA 微调效果未达到预期,或者希望在相似的计算成本下获得更好的性能和更快的收敛速度,可以尝试 LoRA+。
-
rslora
-
描述:rsLoRA 旨在解决标准 LoRA 在使用较高秩 (r) 时可能出现的训练不稳定和性能下降问题。
-
建议:
-
如果在使用标准 LoRA 并尝试增加秩时观察到训练困难、收敛缓慢或性能反而下降的情况,此时可以尝试 rsLoRA。
-
LoRA 在高秩下表现不佳或训练不稳定,那么 rsLoRA 是一个很好的选择。
-
DoRA
-
描述:DoRA 的目标是进一步缩小 LoRA 与全参数微调之间的性能差距,逼近全参数微调。
-
建议:
-
对微调后的模型性能有非常高的要求,如果发现标准 LoRA 的效果与全参数微调仍有一定差距,DoRA 提供了一个有潜力缩小这一差距的选项。
-
PiSSA
-
描述:PiSSA 的核心思想是改进 LoRA 中低秩适配器矩阵 A 和 B 的初始化方式以及优化目标,逼近全参数微调。
-
建议:
-
期望更快收敛和更好性能时。
-
需要对模型量化时,可以尝试,减少量化误差(与 QLoRA 结合时)。
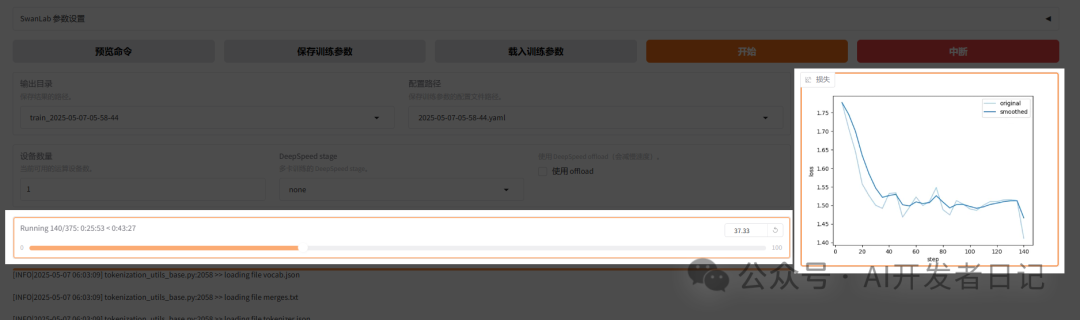
开始微调
点击开始后,可以方便的查看进度以及loss趋势。
模型导出与测试
LLaMA Factory可以方便的导出模型到指定目录。
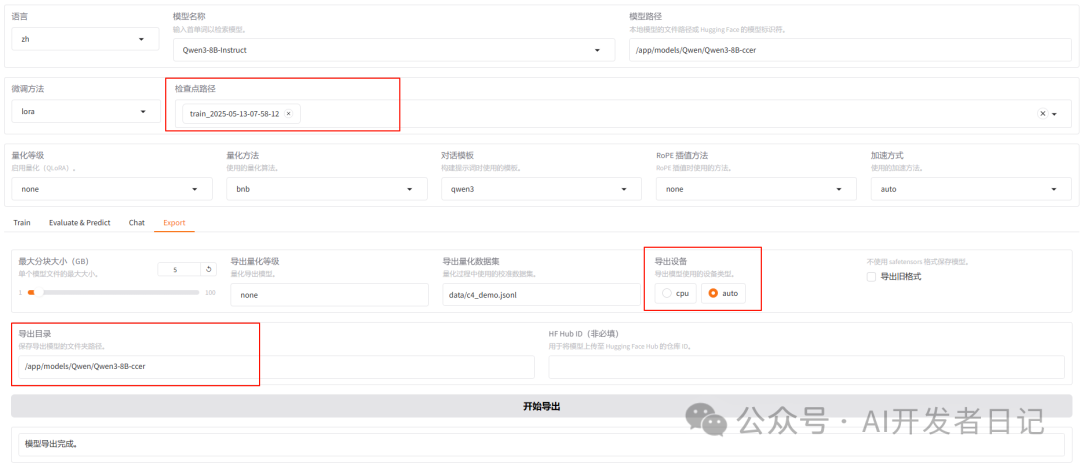
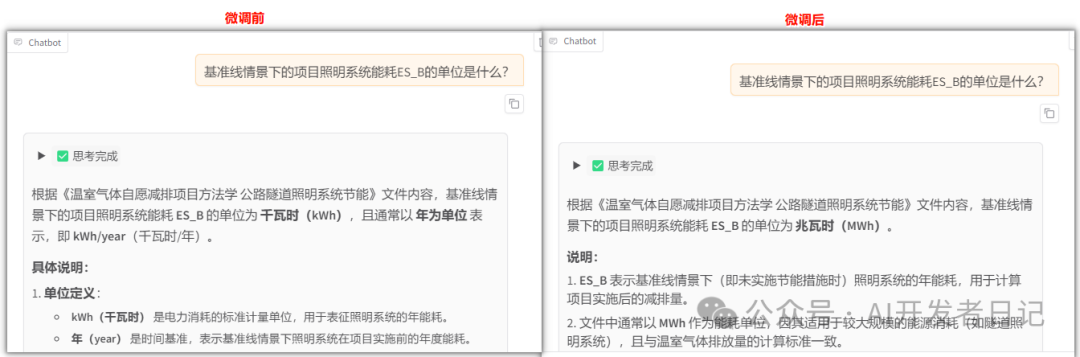
可以明显看出微调前后,对同一问题,微调后模型回答正确。
最后
至此,我们的大模型微调系列四篇文章已经全部完成。整个过程比较简单,但在实际工作中,需要不停的实验,尝试不同的数据集,参数组合,才能真正提升性能。
💡
优秀的模型,需要的数据质量 远大于 数量。
推荐阅读前三篇文章,了解整个过程
LLaMA Factory官方地址:https://github.com/hiyouga/LLaMA-Factory
我们该怎样系统的去转行学习大模型 ?
很多想入行大模型的人苦于现在网上的大模型老课程老教材,学也不是不学也不是,基于此,我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近100余次后,终于把整个AI大模型的学习门槛,降到了最低!
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包,现在将这份 LLM大模型资料 分享出来: 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、大模型经典书籍(免费分享)
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套大模型报告(免费分享)
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)
三、大模型系列视频教程(免费分享)

四、2025最新大模型学习路线(免费分享)
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:我们会去了解大模型的基础知识,以及大模型在各个行业的应用和分析;学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段是我们的AI大模型RAG应用开发工程,我们会去学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,我们会去学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造我们自己的Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,我们会更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调。

L5阶段:专题集丨特训篇 【录播课】

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以微信扫描下方二维码,免费领取
更多推荐
 10
10 0
0- 0



 已为社区贡献37条内容
已为社区贡献37条内容

所有评论(0)