
2025年大模型面试题解析,Flux LoRA模型的完整训练流程
本文详细介绍了Flux LoRA模型的完整训练流程,包括数据集准备(10-30张高质量图像)、环境搭建(ComfyUI+依赖库)、训练参数配置及测试调优技巧。同时解析了Flux模型采用Transformer架构(MM-DiT)相比U-Net的优势,以及CLIP与T5编码器的协同工作机制。一、准备阶段最少 10–20 张图像,高质量、多角度、多场景,可考虑最多不超过 30 张,过多会导致 LoRA
本文详细介绍了Flux LoRA模型的完整训练流程,包括数据集准备(10-30张高质量图像)、环境搭建(ComfyUI+依赖库)、训练参数配置及测试调优技巧。同时解析了Flux模型采用Transformer架构(MM-DiT)相比U-Net的优势,以及CLIP与T5编码器的协同工作机制。文章为程序员提供了16GB显存下的实操方案,帮助读者从零开始掌握Flux模型训练,适合收藏学习。
1.Flux Lora的训练过程详述
一、准备阶段
- 数据集收集与清洗
最少 10–20 张图像,高质量、多角度、多场景,可考虑最多不超过 30 张,过多会导致 LoRA 学习模糊。
分辨率 ≥ 1024×1024,建议统一裁剪为正方形(1:1),主体居中。
可使用 AI 自动生成标签(caption/tagging),辅助模型理解内容。
- 设置触发词(Trigger Word)
为 LoRA 分配一个独一无二且语义安全的关键词,例如 mytoken_artstyle,用于后续模型生成时的激活。
二、环境搭建与工程工具
推荐工具:
本地使用 ComfyUI(搭配 Flux Trainer workflow),适合 10–12 GB VRAM 的环境。
基础依赖建议:
Python≥3.9、PyTorch、Diffusers、PEFT、Transformers、Accelerate、bitsandbytes、protobuf 等。
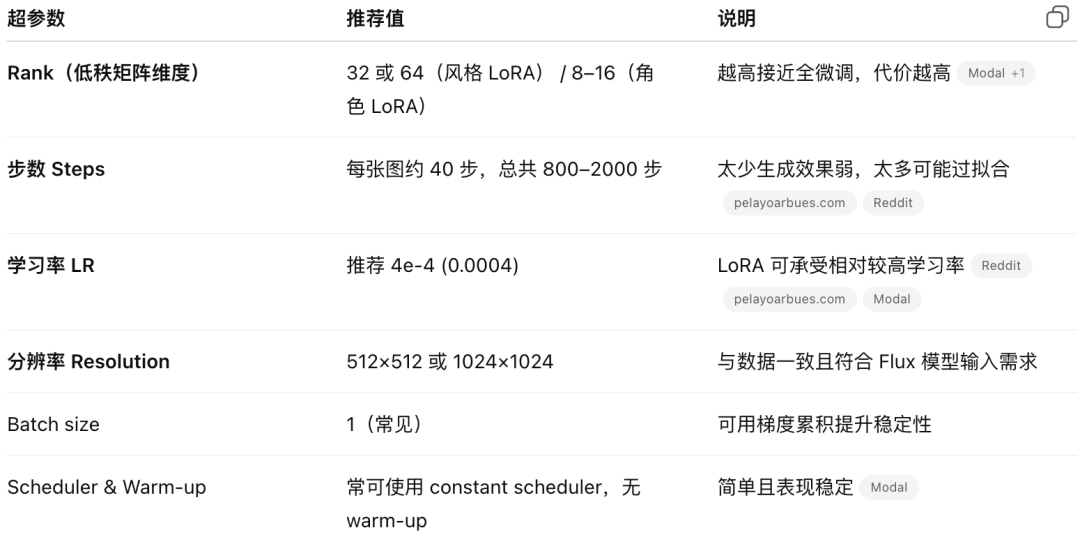
三、训练参数推荐
四、训练流程概述
加载基础模型
使用 black‑forest‑labs/FLUX.1‑dev 模型(文本编码器和 VAE 冻结,仅微调 Transformer)。
构建训练循环
LoRA adapter 插入到 transformer 各层;
仅训练 adapter,基础模型不更新;
使用 Adafactor 或 AdamW 优化器。
监控训练
检查 Loss 曲线,适当停止训练以避免过拟合。(早停)
保存 LoRA 权重
使用 safetensors 格式保存 adapter 权重文件。
合并模型(可选)
后续可通过 diffusers 提供的工具将 LoRA 模型和 base 模型合并,生成一个统一模型输出。
五、测试与调优技巧
数据量:一般使用 20–30 张图效果最好;过多反而降低精准度。
评估生成:在采集过程中使用 trigger word 测试生成质量,观察主体一致性、风格还原度、抑制走样和色彩溢出等问题。
如过拟合或概念扩散:适当降低步数或学习率,或者减少训练图像数量。
六、优化变体与进阶方向
LoRA-GA(Gradient Approximation):通过特殊初始化,使 LoRA 梯度与全微调梯度对齐,可提升收敛速度和性能。
QLoRA + FP8 量化训练:结合 bitsandbytes、torchao 等工具,能在 RTX4090 等环境下实现低显存微调。
七、总体流程总结
收集并剪裁整理数据集
确定 trigger word 和模型命名
搭建训练环境(本地 ComfyUI)
配置 LoRA 参数:rank / steps / lr / batch_size
执行训练并监控效果
保存 LoRA 权重,测试生成质量
必要时合并模型、调整参数迭代
显存16G是够的,采用fp8模型进行2000步的训练,整个过程大约耗时50至60分钟
2.Flux中的textencoder有clip和T5那么它们的区别是什么?
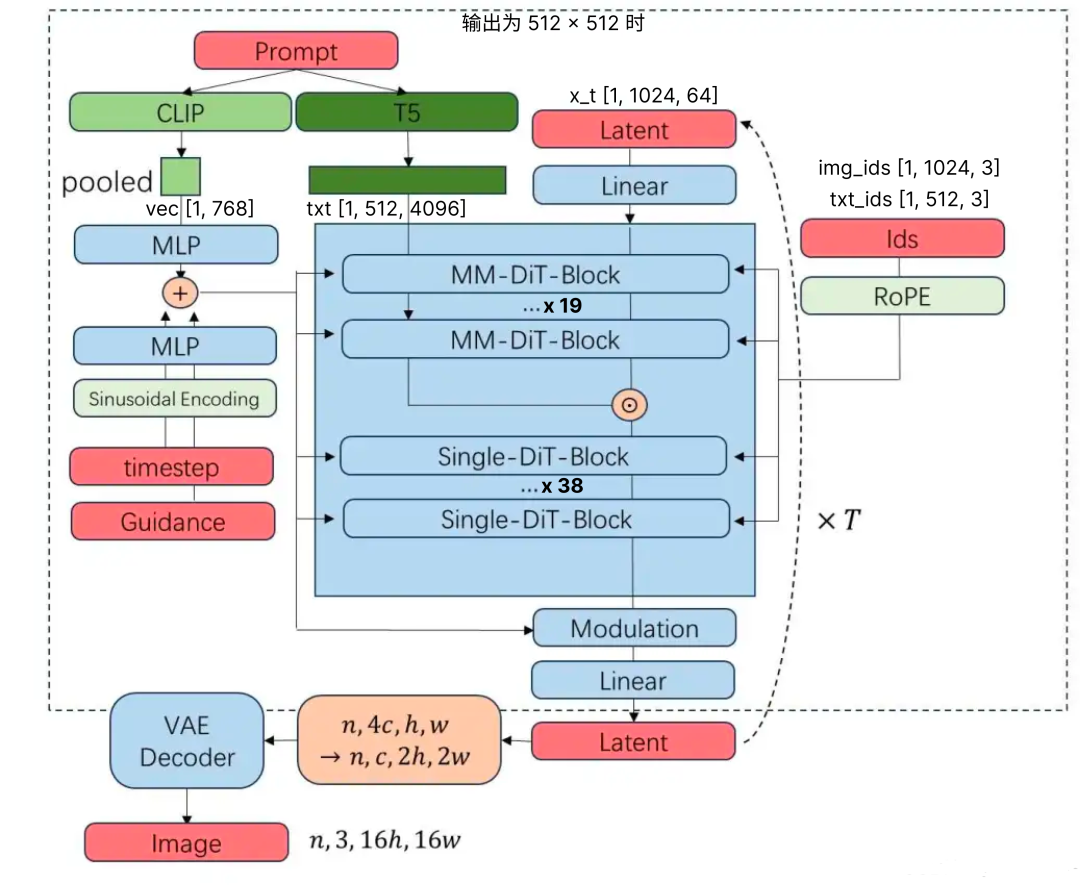
CLIP 和 T5 在 Flux(如 FLUX.1)中各有不同功能,以下是它们的区别与作用:
1️⃣ CLIP vs T5 本质区别
CLIP(Contrastive Language–Image Pretraining)
单一路径将图像与文本编码为共享语义空间,生成整体 pooled embedding
强于短 prompt 的视觉–语言对齐,常用于图像–文本相似度评估与引导
T5(Text‑to‑Text Transfer Transformer)
强大的语言模型,encoder-decoder 架构,只处理文本
输出丰富的 token-level embedding,更善于处理长且复杂的文本提示

2️⃣ 它们在 Flux 中的角色
🔹 文本编码与输入处理阶段
在 Flux 的“Initiation & Pre-processing”阶段,文本 prompt 会同时经过 CLIP 和 T5 编码:
CLIP 生成整个 prompt 的 pooled 向量,提供“global”级别的视觉–语言对齐信号
T5 生成 token 级别 hidden states,每个词都有对应 embedding,用于更细致的语义建模
🔹 在 Transformer 再生成阶段中融合
Flux 的 transformer 采用 MM‑DiT 架构,将 CLIP 和 T5 得到的 embedding 融合,用于 denoising 的条件输入:
CLIP embedding 提供 prompt–图像对齐约束
T5 embedding 提供语义细粒度指导
MM‑DiT 在 self-attention 中融合了这些信息以提升生成效果
3️⃣ 实际价值比较

4️⃣ 技术实现 & 资源占用
Flux 模型使用 frozen(不训练)CLIP 和 T5 编码器
在低显存环境下运行时,为节省资源常只加载 T5(并对其量化)
✅ 总结
CLIP:提供全局图文对齐的信号,用于快速检查与引导生成。
T5:提供 token 级语义理解,更擅处理复杂文本 prompt,丰富生成条件。
Flux 利用这两者的互补性:CLIP 提供“是否对齐”的大局观,T5 提供“如何细节呈现”的局部语义,从而生成高质量且语义精准的图像。
3.Flux和Stable diffusion模型结构上最大的区别是什么?Transformer架构的绘图模型为什么比Unet的效果好?
Flux(通常指 FLUX.1)与 Stable Diffusion 在结构上最大的区别,在于它完全放弃了经典的 U‑Net backbone,转而采用 Transformer(DiT / multimodal diffusion transformer)结构,从而在图像生成的方式、性能和 prompt 对齐能力上带来显著提升。
🔍 一、架构对比:Flux vs Stable Diffusion
Stable Diffusion(版本 1.x、2.x、SDXL)
使用 Latent Diffusion Model(LDM)架构:包含 VAE、U‑Net 网络及文本编码器(CLIP 或 T5)。
U‑Net 拥有下采样和上采样通路,以及 skip connections,负责预测噪声以逐步还原图像。
Flux.1(以及 Stable Diffusion 3 / SD3)
完全基于 Rectified Flow Transformer(DiT)架构:用多模态 & 并行 Diffusion Transformer block 替代 U‑Net。
使用 flow matching 技术代替传统的噪声预测训练方式,同时引入 rotary positional embedding 和 parallel attention layer 提升表现力和效率。
Flux.1 模型规模约 12 B 参数,显著大于 SDXL(约 3–4 B)
✨ 二、为什么 Transformer(DiT)结构通常比 U‑Net 更优?
- 更强的 prompt 对齐与全局语义结合
Transformer 架构可更灵活地融合文本与图像信息,全网络多层次参与交互,而非像传统 U‑Net 那样仅通过 cross‑attention 局部调制 prompt 信息。Flux 的多模态 DiT block 从早期阶段就深度融合 prompt 语义,因此生成效果往往更加忠实准确。
- 长距离依赖与 global coherence 更优
Transformer 可以跨整个图像 patch 做 attention,处理全局结构信息,而 U‑Net 的卷积路径强调局部细节,但对于大型构图或复杂场景,全局一致性较弱。
- 高效流程与更快收敛
Flux 的 flow matching 技术使得噪声消除路径更“线性”,其噪音转移曲线不同于 SD 的逐步逼近,通常仅需少量 step 就能生成高质量图像。此外,它通过 guidance distillation 省略了传统 CFG 双次预测,提高速度与效率。
- 模型可扩展性强,参数规模更大
DiT 架构可以较好扩展参数和层数,Flux 通过增大 transformer 深度与并行 attention,提升质量,特别在高分辨率场景表现突出。
🧠 总结对比

✅ 小结
Flux 彻底转向 Transformer 架构,用全局 attention、prompt-图像早期融合与 flow matching 训练方式,实现了比 U‑Net-based Stable Diffusion 更快、更准确、更高质量的图像生成。Transformer 模型天然擅长长程依赖与复杂语义融合,同时可扩展性强,因此在现代 text-to-image 模型中逐渐成为趋势。
4.Transformer旋转位置编码和绝对位置编码有什么区别
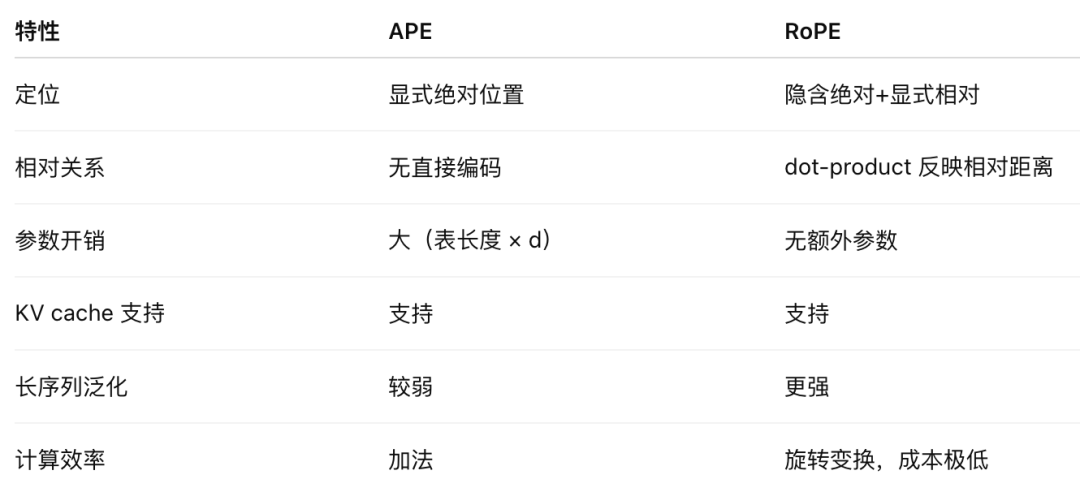
在 Transformer 中,绝对位置编码(Absolute Positional Encoding, APE) 和 旋转位置编码(Rotary Positional Encoding, RoPE) 采用完全不同的方式引入位置信息:
📌 绝对位置编码(APE)
方式:为每个 token 的位置生成一个唯一的向量(可学习或正弦/余弦函数),然后将其加到 token embedding 上 。
特点:
清晰地为每个位置提供“绝对坐标”;
支持 KV cache;
跨越序列边界时容易产生 generalize 问题;
无法直接表达 token 间的相对距离关系
🔄 旋转位置编码(RoPE)
方式:在 Token 的 query/key embedding 中,每对维度(即二维子空间)通过旋转矩阵进行旋转,旋转角度与 token 的位置成比例 。
特点:
融合绝对和相对:旋转量依赖于绝对位置,但 dot‑product 最终只反映相对距离,因此具备相对位置敏感性 ;
高效:无需额外参数表,也不改变 attention 计算复杂度 ;
支持 KV cache:以前生成的 tokens 的旋转固定,不会随着新 token 添加而变化 ;
对长序列更稳定:RoPE 可实质上模拟相对位置 bias,又不会像 APE 那样容易失效 。
📝 对比一览
✅ 为什么现代 Transformer 更青睐 RoPE?
它简洁高效,不需要大量额外参数;
更好支持相对位置建模,有助于语言理解;
扩展性强,能直接应用于超长序列;
极佳兼容性,支持 inference 阶段的 KV cache;
被多款大模型采用(如 LLaMA 3、Gemma)。
📌 总结
绝对位置编码提供静态的位置信息,但对相对关系建模弱;
旋转位置编码(RoPE) 将每个 token 的 embedding 以位置相关的角度旋转,实现绝对 + 相对的隐式编码,兼顾效率、稳定性和推理优化,是现代 Transformer 的主流选择。
5.Transformer里使用的是相对位置编码还是绝对位置编码
Transformer 中既可以使用绝对位置编码(absolute positional encoding),也可以使用相对位置编码(relative positional encoding)——取决于具体实现或变体。
- 原始 Transformer(Vaswani et al., 2017)
使用的是 绝对位置编码,形式如下:
✅ 绝对位置编码的定义:
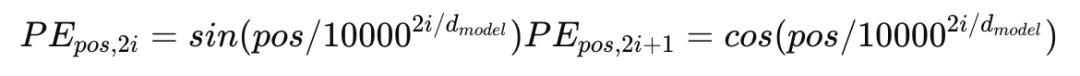
其中 pos 表示位置,i 是维度,d_model 是 embedding 维度。
编码结果加到每个 token 的 embedding 上,告诉模型「这个 token 是在第几个位置」。
优点:实现简单;
缺点:无法捕捉 token 与 token 之间的相对位置关系,不具有平移不变性(permutation equivariance)。
- 相对位置编码(Relative Positional Encoding)
近年来很多改进型 Transformer(如 Transformer-XL, T5, BERT-RPE, DeBERTa 等)使用了 相对位置编码。
✅ 相对位置编码的核心思想:
不编码每个 token 的「绝对位置」,而是让注意力机制 aware of token 之间的位置差值(i-j)。
举个例子:
attention(i, j) += bias(i - j)
比如 Query i 和 Key j 之间的距离是 i-j,这个偏移值用于调节注意力分数。
能更好地建模「who is near whom」,比起绝对坐标更通用。
优点:更强泛化能力;适用于长文本;可平移不变;
缺点:实现稍复杂,训练速度可能稍慢。
3.总结对比:

哪些模型用相对位置编码?
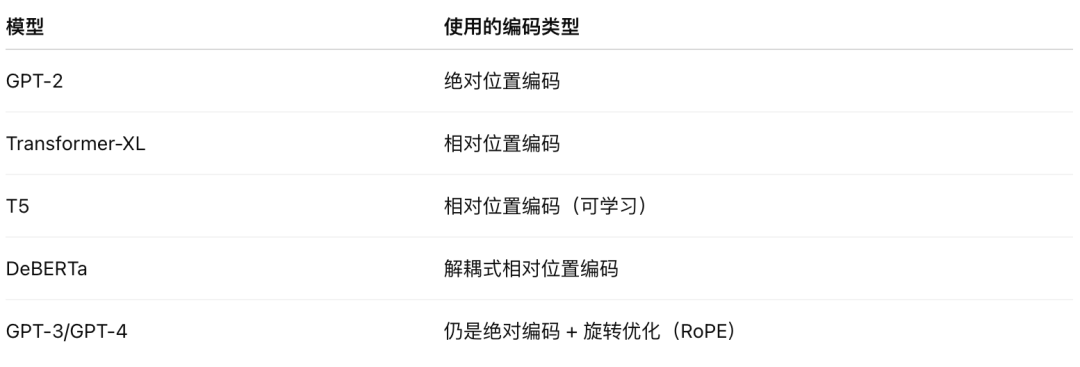
🚀 Bonus:旋转位置编码(RoPE)
如 GPT-NeoX, ChatGLM, LLaMA, 使用的是:
旋转位置编码 RoPE(Rotary Positional Embedding),本质是一种相对位置编码的形式,能支持高效的上下文外推。
RoPE 的优点
1.更强的相对位置信息建模:
RoPE 的设计直接嵌入相对位置关系,提高了模型对长距离依赖的感知能力。
2.支持长上下文扩展:
由于 RoPE 不依赖于固定的绝对位置,它可以支持更长的上下文窗口扩展(如从 2k 扩展到 8k 或更高)。
3.无需额外参数:
RoPE 是一种非参数化的方法,不增加模型的参数量。
Flux 的在 MM-DiT之后,将文本和图像拼接,再送入到 SingleStreamTransformer 中进行处理。这样能够降低单层的参数量,增大网络深度;
为了进行 CFG 蒸馏,Flux dev 版本的 DiT 需要显式地直接接受 guidance scale 作为条件。这个条件与 timestep 条件类似,分别经过正弦 embedding 后加在一起
如何系统学习掌握AI大模型?
AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份
全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。

2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 大模型行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以
微信扫描下方CSDN官方认证二维码,免费领取【保证100%免费】
如何系统学习掌握AI大模型?
AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份
全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!
1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。
2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)
3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。
4. 大模型行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。
5. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。
6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。
全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以
微信扫描下方CSDN官方认证二维码,免费领取【保证100%免费】
更多推荐
 8
8 0
0- 0



 已为社区贡献45条内容
已为社区贡献45条内容

所有评论(0)