HAMi 2.7.0 发布:全面拓展异构芯片支持,优化GPU资源调度与智能管理
HAMi 2.7.0版本发布,全面拓展异构芯片支持并增强调度稳定性。本次更新亮点包括:新增昆仑芯XPU、燧原GCU等硬件支持;优化核心调度器,引入失败事件聚合和异常处理机制;增强vLLM兼容性并集成Xinference;社区新增多位贡献者,多个CNCF案例展示实践成果。特别针对沐曦MetaX GPU实现sGPU共享和QoS管理,通过两阶段拓扑寻优算法提升调度效率。该版本进一步巩固了HAMi作为云原
HAMi 2.7.0 重磅发布 | 异构芯片全面拓展,调度更稳、生态更强
芯与序(Of Silicon & Scheduling)
—— 万般之芯,合于一序。
向 Kubernetes 1.34 的 Of Wind & Will 致意:彼处以风与志命名航向;
此处,我们以 芯 与 序 为坐标。
芯,是世间万象的硅与算:形态各异,自有脾性;
序,是人们给出的节律与秩序:在复杂中取可走之径。
当多样之芯汇入同一片海,我们不许诺风向,只承诺给出 可被遵循的序 。
于是,一个版本得以成形:
不是因为一切完美,而是因为 秩序让不完美也能 并行。
我们激动地宣布 HAMi 的最新版本正式发布!本次更新在硬件厂商生态支持、核心调度器优化、关键稳定性修复以及开发者社区建设方面取得了显著进展,旨在为用户提供更强大、更稳定、更易用的 GPU 资源管理和调度解决方案。

文章目录
版本亮点速览
- 硬件生态全面拓展:新增对昆仑芯 XPU、燧原 GCU、AWS Neuron 从整卡、虚拟化到拓扑感知的完整支持,并在沐曦 MetaX 上实现 sGPU 算力显存共享、三种 QoS 管理模式,同时依托 MetaXLink 增强拓扑感知与智能调度能力;NVIDIA GPU 的拓扑调度能力也同步升级。
- 调度器核心优化:引入调度失败事件聚合、NVIDIA 异常卡处理,以及支持扩展的 ResourceQuota 等机制,使得能正确计算多 GPU 请求的显存/算力配额,大幅提升可观测性和系统健壮性。
- 应用层生态整合:增强 vLLM 兼容性,完成 Xinference 集成,并支持 Volcano Dynamic MIG。
- 社区蓬勃发展:新增多位贡献者(含 Reviewer)和维护者,多篇 CNCF 案例与生态演讲展示 HAMi 的广泛实践。
- WebUI 功能增强:沐曦监控全链路打通,异构指标可视化更直观。
社区动态
CNCF 案例分享
HAMi 在云原生社区持续落地,以下为近期的用户实践:
- 顺丰科技(Effective GPU ):基于 HAMi 实现大规模异构算力的池化与调度,详见 CNCF 案例研究 [1]。
- PREP-EDU:借助 HAMi 优化教育平台的 AI 训练任务,显著提升资源利用率,详见 CNCF 案例研究 [2]。
vCluster 云原生专家推荐
在 vCluster 技术研讨会上,云原生专家将 HAMi 作为一个“很有意思”的创新方案进行推荐,并指出其核心优势在于通过代理层拦截 CUDA API,实现细粒度的资源治理与隔离。会议回放可在 YouTube 视频 [3] 查看。
The Linux Foundation AI_dev
在 AI_dev 峰会上,我们分享了 HAMi 如何通过灵活的 GPU 切分与软件定义隔离,缓解云原生环境中的算力浪费问题。会议回放可在 YouTube 视频 [4] 查看。
越南电信:Kubernetes 上的 GPU 与 eBPF
在越南电信的落地实践中,HAMi 展示了在 Kubernetes 环境下对 GPU 资源进行管理与可观测的能力。更多详情可参阅 CNCF Cloud Native Hanoi Meetup [5] 以及 YouTube 视频 [6]。
核心特性展开
硬件厂商生态完善
本次版本对主流异构计算硬件平台的支持进行了深度优化和扩展,旨在为用户提供更广泛的选择和更高效的资源管理能力。
沐曦 MetaX - 支持 sGPU 算力显存共享并接入 QoS 管理(三种模式),基于 MetaXLink 的智能调度 & WebUI 全面适配
HAMi v2.7.0 版本为沐曦 MetaX GPU 提供了统一的调度方案,其核心特性包括:
-
GPU 共享 (sGPU): 允许多个容器任务共享同一张物理 GPU 卡,类似于 vGPU,提高了资源利用率。
-
资源隔离与限制: 可以精确限制每个任务能使用的显存大小(例如 4G)。可以限制每个任务使用的计算核心(vcore)比例(例如 60%)。
-
拓扑感知调度: 针对单机多卡的场景,调度器能感知 GPU 间的连接拓扑(如 MetaXLink、PCIe Switch),并为多卡任务优先选择通信带宽最高的 GPU 组合,提升训练性能。
-
服务质量 (QoS) 策略: 支持为任务设置不同的资源服务等级,如 BestEffort (尽力而为)、FixedShare (固定份额) 和 BurstShare (突发份额),以满足不同业务场景的需求。
-
健康检查与监控: 提供设备健康状态检查,在 HAMi-WebUI 中打通沐曦监控全链路,使得异构指标在界面中更直观呈现,可视化地展示整个集群的资源分配和使用情况。
拓扑寻优原理详解
HAMi 调度器对沐曦 MetaX GPU 的拓扑寻优,其核心目标是确保多卡任务在高速互联的 GPU "群组"内部执行,从而最大化通信效率。其核心思想是:一个结合了节点内“优先级”和节点间“量化评分”的两阶段决策机制。
它首先在每个节点内部,通过一套确定性的优先级规则直接选出最优的 GPU 组合,优先从单个高速互联域 (linkZone) 中分配。
随后,在多个候选节点之间,它通过一个综合了“分配质量”和“拓扑损失”的评分公式进行量化评估,选出不仅对当前任务最好,也对集群未来资源布局最有利的节点。
这个“两阶段”详细流程如下:
第一阶段:节点内设备选择 - “规则至上”
此阶段核心是在节点内部找到一个符合拓扑最优的 GPU 组合。这个过程不是一个评分竞赛,而是一个确定性的、遵循严格优先级的决策树。
工作流程详解
-
输入: 节点上所有满足 Pod 资源请求(如显存、算力)的候选 GPU 列表。
-
分组: 算法首先将这些候选 GPU 按照它们的 linkZone ID (高速互联域标识) 进行分组。
-
决策树: 算法开始按以下优先级顺序进行决策:
-
- 第一优先级 (最优解:域内满足): 算法会检查是否存在任何一个 linkZone 分组,其内部的 GPU 数量足以满足任务的全部需求。
- 第二优先级 (次优解:跨域组合): 算法会创建一个新的空列表,然后逐个遍历所有 linkZone 分组,将里面的 GPU 全部添加到这个新列表中,直到列表中的 GPU 总数满足任务需求。
- 第三优先级 (保底解:补充无互联信息设备): 如果遍历完所有 linkZone 分组后,列表中的 GPU 数量仍然不够,算法最后会用那些没有 linkZone 信息的 GPU 来补足剩余的数量。
阶段一的本质: 通过强制的优先级规则,用最高效的方式锁定节点内部理论上通信性能最高的 GPU 组合。
第二阶段:节点间评分决策 - “综合评估”
当多个节点都能通过第一阶段(即都能提供一个有效的 GPU 组合)时,调度器需要在这几个候选节点中做出最终选择。这个阶段采用的是量化评分机制。
评分机制详解
每个候选节点都会被计算一个最终得分,得分最高的节点胜出。最终得分公式:
Final Score = (10 * allocatedScore) - lossScore
我们来拆解这个公式:
-
allocatedScore (分配质量分): 这个分数衡量的是第一阶段选出的那个 GPU 组合本身的内部连接紧密程度。组合内处于相同 linkZone 的设备对越多,这个分数就越高。10 * allocatedScore 表明调度器极度重视为当前任务分配一个高质量的组合。权重乘以 10,使其在最终得分中占据主导地位。
-
lossScore (拓扑损失分 / 碎片化惩罚): 这是一个非常关键的“远见”指标。它衡量的是:“为了完成本次分配,我们对节点上剩余的、未被分配的 GPU 的拓扑完整性造成了多大的破坏?”
-
- 计算方式:lossScore = (分配前总分) - (分配组合得分) - (剩余设备得分)
- 这意味着调度器会惩罚那些会导致节点拓扑资源“碎片化”的分配行为,在分配质量分相同的时候会起作用,保护了集群为未来的大型任务保留优质、完整拓扑资源的能力。
最终总结: 这个两阶段原理,首先通过刚性的优先级规则在每个节点内部“优中选优”,然后通过一个兼顾“当前利益”与“长远规划”的评分公式,在所有候选节点中做出全局最优决策。
调度策略与拓扑寻优的协同
调度策略与拓扑寻优目前是通过一个正负权重进行强力干预。在 binpack 模式下,拓扑优化是加分项;
而在 spread 模式下,拓扑优化反而成了减分项,这使得调度器会优先选择一个拓扑结构较差但更空闲的节点,而非一个拓扑结构很好但同样空闲的节点。
使用 node-scheduler-policy=spread 时,尽可能将 Metax 资源分配在同一个 Metaxlink 或 PCIe Switch 下,如下图所示:
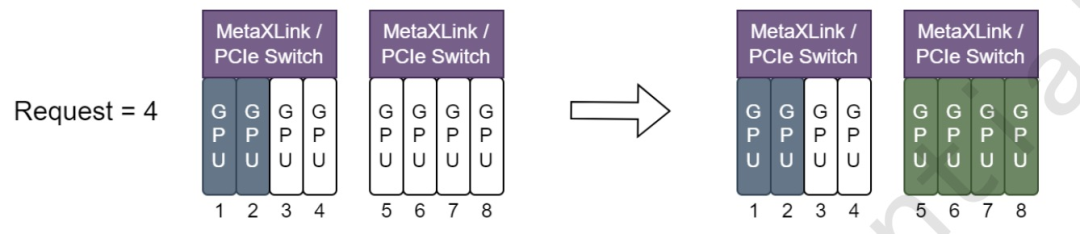
- 由沐曦提供
使用 node-scheduler-policy=binpack 时,分配 GPU 资源,以尽量减少对 MetaxXLink 拓扑的破坏,如下图所示:
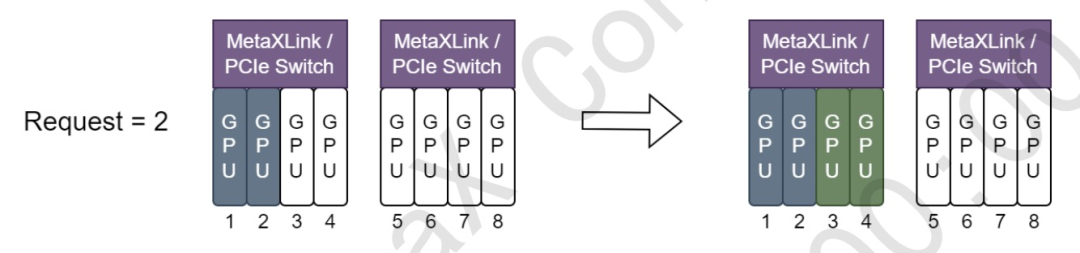
- 由沐曦提供
使用方式
apiVersion: v1
kind: Pod
metadata:
name: gpu-pod1
annotations:
hami.io/node-scheduler-policy: "binpack" # 当此参数设置为 binpack 时,调度器将尝试最小化拓扑损失。
spec:
containers:
- name: ubuntu-container
image: cr.metax-tech.com/public-ai-release/c500/colossalai:2.24.0.5-py38-ubuntu20.04-amd64
imagePullPolicy: IfNotPresent
command: ["sleep","infinity"]
resources:
limits:
metax-tech.com/gpu: 1 # 请求 1 个沐曦 GPU
apiVersion: v1
kind: Pod
metadata:
name: gpu-pod1
annotations:
hami.io/node-scheduler-policy: "spread" # 当此参数设置为 spread 时,调度器将尝试为此任务找到最佳拓扑。
spec:
containers:
- name: ubuntu-container
image: cr.metax-tech.com/public-ai-release/c500/colossalai:2.24.0.5-py38-ubuntu20.04-amd64
imagePullPolicy: IfNotPresent
command: ["sleep","infinity"]
resources:
limits:
metax-tech.com/gpu: 4 # 请求 4 个沐曦 GPU
沐曦 sGPU 的三种 QoS Policy
- BestEffort (尽力而为): 默认策略。资源尽力分配,追求最大化的资源利用率。
- FixedShare (固定份额): 严格保证任务分配到的算力 (vcore) 和显存 (vmemory),性能稳定,不受其他任务干扰。
- BurstShare (突发份额): 有资源份额,但在 GPU 空闲时允许被 sGPU 使用,适合有突发负载的业务。
sGPU 的 QoS Policy 核心调度原理:“同类聚合”
这个原理由 checkDeviceQos 函数实现,我们可以将其总结为一句话:
一张物理 GPU 卡,从第一个任务入驻开始,就只能接受和它“同类”的后续任务。
这意味着,一个 GPU 的“身份”在被第一个 Pod 占用时就被决定了。
- 如果第一个 Pod 是 FixedShare,这张卡就变成了“FixedShare 专用卡”。
- 如果第一个 Pod 是 BestEffort,这张卡就变成了“BestEffort 专用卡”。
任何试图进入一张“身份”不符的卡的 Pod,都会在调度阶段被拒绝,其核心逻辑如下:
- 如果 GPU 完全空闲,允许任何 QoS 任务入驻。
- 如果 GPU 已被占用,则新任务的 QoS 注解必须严格等于卡上现有任务的 QoS,否则拒绝。
- 请求 100% 算力的独占任务不受此规则限制。
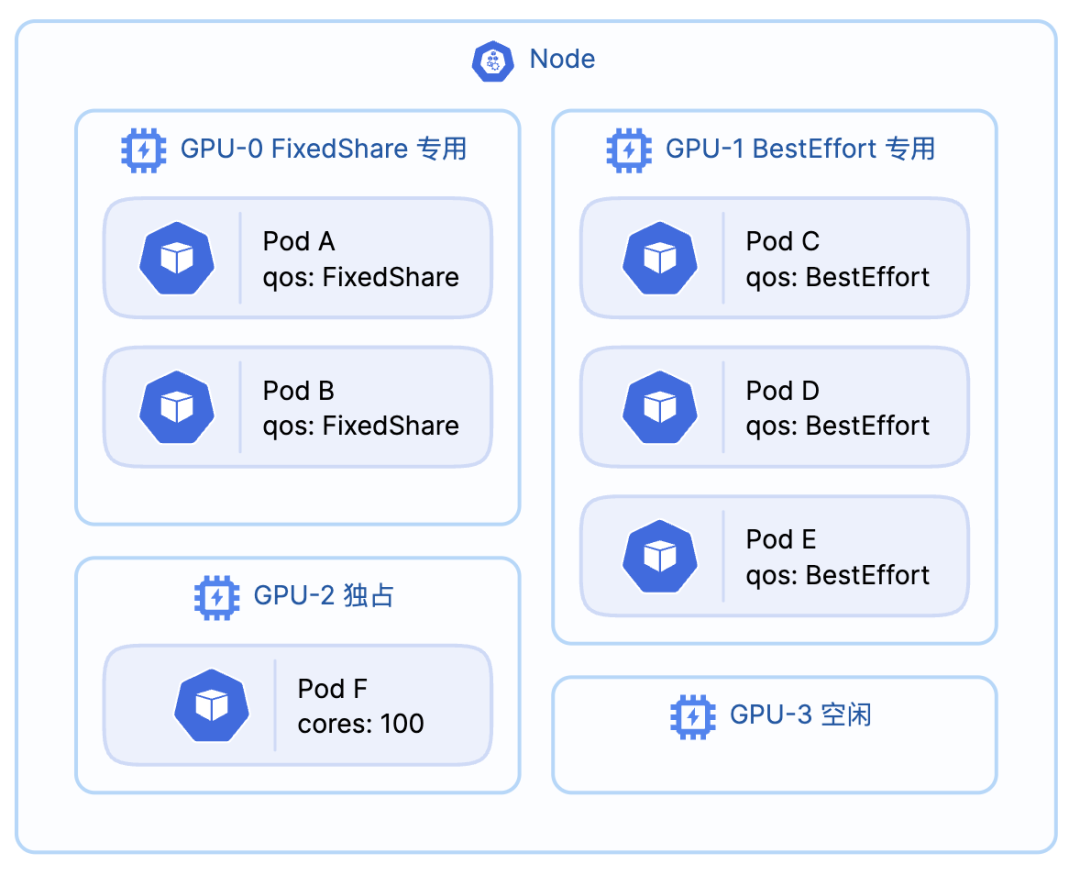
使用方式
apiVersion: v1
kind: Pod
metadata:
name: gpu-pod
annotations:
metax-tech.com/sgpu-qos-policy: "best-effort" # 分配指定的 qos sgpu
spec:
containers:
- name: ubuntu-container
image: ubuntu:22.04
imagePullPolicy: IfNotPresent
command: ["sleep","infinity"]
resources:
limits:
metax-tech.com/sgpu: 1 # 请求 1 个 GPU
metax-tech.com/vcore: 60 # 每个 GPU 使用 60% 的计算核
metax-tech.com/vmemory: 4 # 每个 GPU 需要 4 GiB 设备显存
WebUI 全面支持
WebUI 现已全面支持沐曦 MetaX GPU 的监控指标展示,提供直观的资源使用情况概览。
说明文档:MetaX GPU 支持说明 [7]
使用文档:MetaX GPU 样例 [8]
Related PRs:
- https://github.com/Project-HAMi/HAMi/pull/1123
- https://github.com/Project-HAMi/HAMi/pull/1193
- https://github.com/Project-HAMi/HAMi/pull/1295
- https://github.com/Project-HAMi/HAMi-WebUI/pull/46
由衷感谢社区开发者 @Kyrie336,@darker-thanBlack 对以上特性的贡献!
同时也特别感谢 沐曦团队 在整个特性设计与实现过程中的深度参与,为这一系列特性的成功落地提供了坚实支持。
昆仑芯 XPU - 新增完整 vXPU 支持:设备切分,显存对齐,拓扑感知
HAMi v2.7.0 版本为昆仑芯 XPU 提供了统一的调度方案,其核心特性包括:
- 混合部署与虚拟化:可以在一个集群中同时调度昆仑芯的整卡和 vXPU(虚拟化切片),虚拟化支持 1/4 卡和 1/2 卡两种粒度的切分。提高了资源利用率的灵活性。
- 显存****自动对齐:用户请求 vXPU 显存时,无需关心硬件具体的显存规格。系统会自动将请求的显存值向上对齐到最接近的硬件支持规格(例如 24G、48G),简化了资源申请。
- 拓扑感知调度:调度器能够感知节点上 XPU 卡的拓扑结构(如翼侧互联信息:将索引 0-3 的设备视为 leftwing,将索引 4-7 的设备视为 rightwing)。在分配多个 vXPU 切片时,调度算法会优先选择位于同一物理卡、同一翼侧的切片组合,以确保最低的通信延迟和最高的应用性能。
- 精细化设备指定:支持通过 Pod 的 annotation (hami.io/use-xpu-uuid & hami.io/no-use-xpu-uuid) 来白名单或黑名单指定具体的物理卡 UUID,满足特定测试或灰度发布等高级调度需求。
拓扑寻优原理详解
HAMi 调度器对昆仑芯 XPU 的拓扑寻优,其核心目标是在分配多个 XPU 时,尽可能将它们放置在物理位置最接近的地方,以降低通信延迟。
其逻辑可以概括为两步:
- 资源分组:函数首先将节点上的 8 个设备索引强制划分为两个逻辑单元:leftwing(索引 0-3)和 rightwing(索引 4-7)。
- 贪心选择:当任务需要 N 个 XPU 时,算法进行一个简单的 if-else 决策:
- IF: leftwing 或 rightwing 任何一个的可用资源足以满足 N。
- THEN: 立即在该 wing 内部完成所有分配。这是最优且唯一的选择。
- ELSE: 尝试寻找预定义的跨 wing 互联方案作为补救。
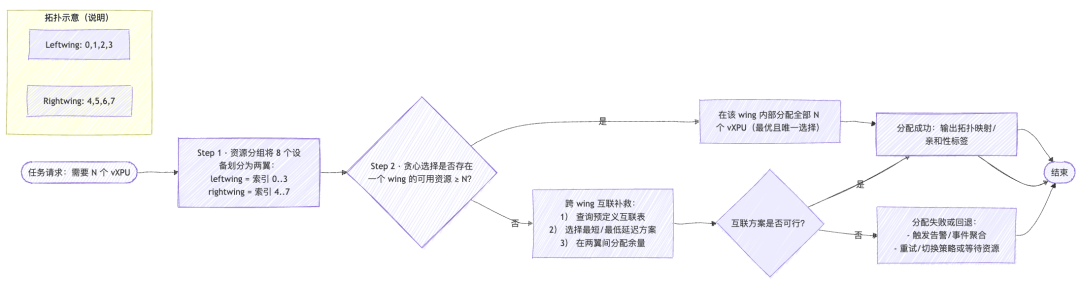
这个实现简单而高效,它放弃了复杂的组合计算,直接追求最理想的分配方案。
使用方式
apiVersion: v1
kind: Pod
metadata:
name: kunlun-vxpu-demo
annotations:
# 指定只能使用 KL-UUID-01 和 KL-UUID-03 这两张卡
# 调度器只会从这两张卡上切分 vXPU 资源
hami.io/use-xpu-uuid: "KL-UUID-01,KL-UUID-03"
spec:
containers:
- name: my-app
image: my-kunlun-app:latest
resources:
limits:
# 申请 1 个 vXPU
kunlunxin.com/vxpu: 1
# 申请 24G 显存 (如果填 20G 会被自动对齐到 24G)
kunlunxin.com/vxpu-memory: 24576
apiVersion: v1
kind: Pod
metadata:
name: topo-aware-demo-pod
labels:
app: kunlun-topo-test
spec:
containers:
- name: my-kunlun-container
image: my-kunlun-app:latest
resources:
limits:
# 请求 2 个 XPU 来触发拓扑感知调度
kunlunxin.com/vxpu: 2
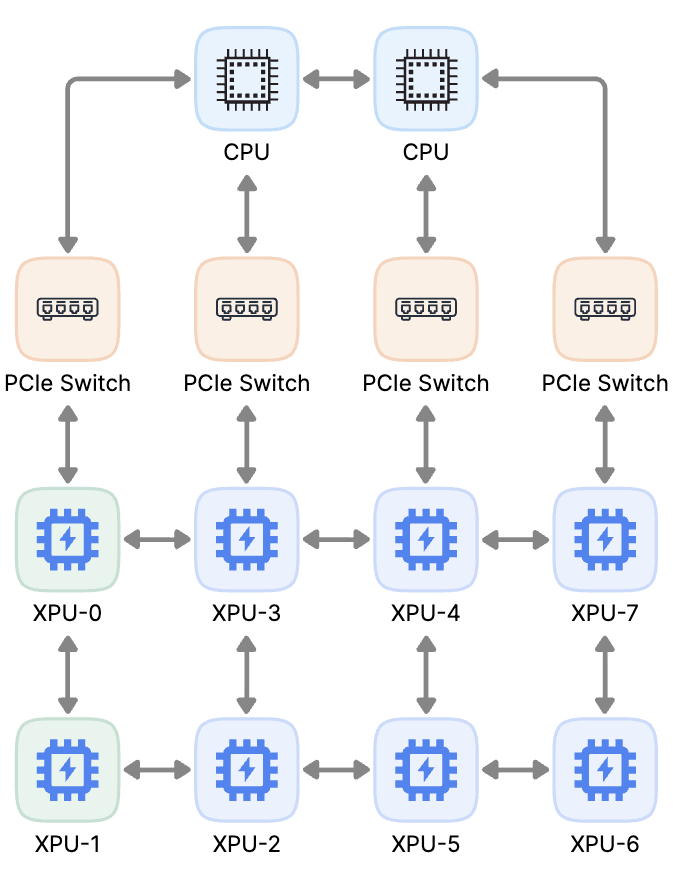
优先选择 leftwing -> 从 leftwing 的开头(索引 0)开始 -> 依次拿下 0 和 1。
重要限制
根据昆仑芯驱动规范,vXPU 的切分受到句柄数量的限制(最多 32 个)。这意味着当节点满配 8 张 P800-OAM 卡时,存在以下调度限制:
- 不支持同时申请 8 个 1/4 卡规格的 vXPU 实例(即 kunlunxin.com/vxpu: 8 搭配 kunlunxin.com/vxpu-memory: 24576)。
- 但支持其他组合,例如申请 6 个 1/4 卡规格的 vXPU,或 8 个 1/2 卡规格的 vXPU。
使用文档:Kunlun XPU 支持 [9]
Related PRs:
- https://github.com/Project-HAMi/HAMi/pull/1141
- https://github.com/Project-HAMi/HAMi/pull/1336
- https://github.com/Project-HAMi/HAMi/pull/1337
- https://github.com/Project-HAMi/HAMi/pull/1338
- https://github.com/Project-HAMi/HAMi/pull/1366
由衷感谢社区开发者 @ouyangluwei163,@FouoF,@archlitchi 对该特性的贡献!
同时也特别感谢 百度智能云 和 昆仑芯团队 在整个过程中的深度支持,为这一特性的成功落地提供了关键助力。
AWS Neuron - 支持设备级和核心级两种资源分配粒度和拓扑感知调度
AWS 自主设计 Inferentia / Trainium 芯片,是为了在其云服务中构建更加高效、成本可控的 AI 加速基础设施。Inferentia 偏向于 推理加速,Trainium 偏向于 训练加速。这些芯片专为 AI 工作负载设计,其设计目标不仅在算力提升,同时在功耗控制和成本效率上发力。Inferentia2 在性能/瓦特比(perf per watt)上做了显著优化,Trainium2 宣称比同类 GPU 实例节省 30–40%。 HAMi 这次也是突破性的完成了和 AWS 芯片的集成、包含调度、虚拟化、可观测性。
HAMi 对 AWS Neuron 的支持,主要是指能够在 Kubernetes 环境中对 AWS Trainium 和 Inferentia 加速器进行精细化的调度和共享。核心特性如下:
-
核心级共享: AWS Neuron 设备通常包含多个 NeuronCore。HAMi 允许用户以单个 NeuronCore 为最小单位来申请资源,而不是必须占用整个物理设备。这极大地提高了昂贵的加速器芯片的利用率。
-
拓扑感知调度: 对于需要多个 NeuronCore 的任务,HAMi 调度器能够感知节点的拓扑结构,尽量将任务调度到网络延迟最低、通信效率最高的 NeuronCore 组合上。
-
简化用户体验: 用户无需关心底层的 NeuronCore 分配细节。只需在 Pod 的 YAML 中像申请 CPU/Memory 一样声明需要多少个 aws.amazon.com/neuron 资源即可。
拓扑感知原理详解
HAMi 对 AWS Neuron 的拓扑感知调度,其根本设计思想是基于先验知识的策略性调度,而非运行时的动态拓扑发现。基于 AWS 原生调度器的逻辑,对特定硬件平台(AWS EC2 Neuron 实例)的调度策略的理解,直接固化为了 HAMi 内部的调度规则。
其实现原理如下:
- 识别实例类型: 调度器首先读取节点的 EC2 实例类型(如 trn1 或 inf2),以此作为判断硬件拓扑的唯一依据。
- 线性抽象: 它将节点上所有 Neuron 设备视为一个从 0 开始的连续编号列表(如 [0, 1, 2, …]),而不是一个复杂的拓扑图。
- 强制连续分配: 这是最核心的规则。当任务请求 N 个设备时,调度器必须在此编号列表中找到一个长度为 N 的、完全空闲的、连续的设备块。如果节点有足够数量的空闲设备但它们不相邻,调度依然会失败。
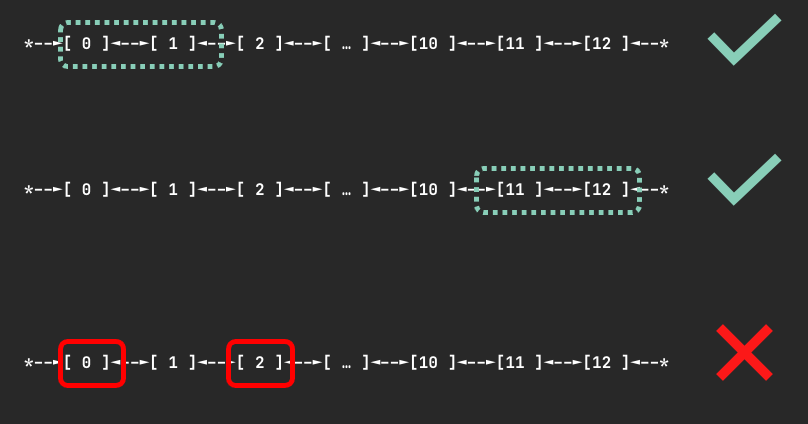
此外,针对 Trainium 实例,策略更严格,只允许分配特定数量(如 4, 8, 16 个)的设备组,以匹配其物理上的高速互联集群。
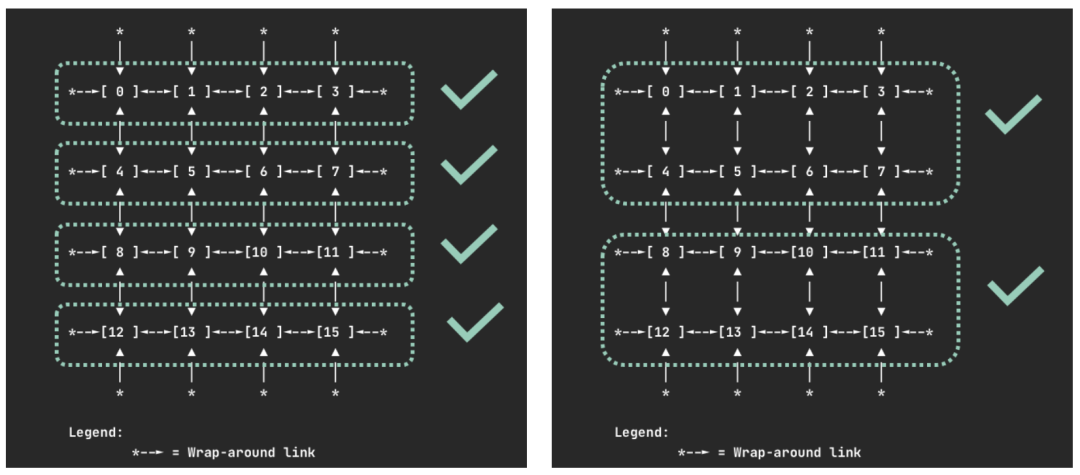
使用方式
apiVersion: v1
kind: Pod
metadata:
name: nuropod
spec:
restartPolicy: Never
containers:
- name: nuropod
command: ["sleep","infinity"]
image: public.ecr.aws/neuron/pytorch-inference-neuron:1.13.1-neuron-py310-sdk2.20.2-ubuntu20.04
resources:
limits:
cpu: "4"
memory: 4Gi
aws.amazon.com/neuron: 4
requests:
cpu: "1"
memory: 1Gi```
apiVersion: v1
kind: Pod
metadata:
name: nuropod
spec:
restartPolicy: Never
containers:
- name: nuropod
command: ["sleep","infinity"]
image: public.ecr.aws/neuron/pytorch-inference-neuron:1.13.1-neuron-py310-sdk2.20.2-ubuntu20.04
resources:
limits:
cpu: "4"
memory: 4Gi
aws.amazon.com/neuroncore: 1
requests:
cpu: "1"
memory: 1Gi
使用文档:AWS Neuron 示例与操作指南 [10]
Related PRs:
- https://github.com/Project-HAMi/HAMi/pull/1238
由衷感谢社区开发者 @archlitchi 对该特性的贡献!
同时也特别感谢 AWS Neuron 团队 在开发过程中的深度协作与支持,为该特性的顺利落地提供了关键保障。
燧原 GCU - 实现 gcushare 机制的完整集成,支持整卡百分比切片
HAMi v2.7.0 版本对燧原 GCU(以 S60 为例)提供了全面的支持,主要包括两种使用模式:整卡调度和虚拟化共享(vGCU)。这使得资源分配更加灵活,能够适应不同业务场景的需求。主要特性如下:
- GPU 共享: 允许多个任务容器共享同一张物理 GCU 卡,极大提高了资源利用率。
- 百分比切片能力: 用户可以通过百分比(例如 25%)来申请 GCU 的算力和显存。
- 设备 UUID 选择: 用户可以通过 Pod 的 annotation 来精确指定希望使用或排除的 GCU 设备,方便进行任务隔离或设备绑定。
使用方式
apiVersion: v1
kind: Pod
metadata:
name: gcu-shared-pod-with-uuid
annotations:
# 指定使用 UUID 为 node1-enflame-0 的 GCU 设备
enflame.com/use-gpuuuid: "node1-enflame-0"
spec:
containers:
- name: my-shared-gcu-app
image: ubuntu:20.04
command: ["sleep", "3600"]
resources:
limits:
enflame.com/vgcu: 1
enflame.com/vgcu-percentage: 25
使用文档:Enflame GCU/GCUshare 支持 [11]
Related PRs:
- https://github.com/Project-HAMi/HAMi/pull/1013
- https://github.com/Project-HAMi/HAMi/pull/1334
由衷感谢社区开发者: @archlitchi,@zhaikangqi331 对该特性的贡献!
NVIDIA GPU 拓扑调度 - 新增 GPU 拓扑感知调度
此特性主要解决 高性能计算(HPC) 和 AI 大模型训练 场景下的性能瓶颈问题。当一个任务需要使用 2、4、8 甚至更多 GPU 时,如果这些 GPU 只能通过相对较慢的 PCIe 总线通信,数据交换会成为短板,严重影响整体训练效率。而如果它们能被调度到通过 NVLink 高速互联的 GPU 组合上,数据交换速度会成倍提升,从而最大化加速计算任务。
拓扑寻优原理详解
它基于一个核心原则:优先选择最匹配的,同时最大程度保留大块、完整的拓扑结构给未来的任务。
其核心分为 “拓扑注册” 和 “调度决策” 两个阶段:
阶段一:拓扑注册 - 让物理布局可见
此阶段的目标是将每个节点上不可见的 GPU 物理连接,转化为集群调度器可以理解的标准化数据。
- 信息探测: 在每个 GPU 节点上,DevicePlugin 会通过 NVIDIA 的 NVML 来获取到所有 GPU 两两之间的物理连接类型,精确识别出哪些是通过高速 NVLink 互联,哪些是通过普通 PCIe 总线连接。
- 数据建模: 探测结果被构建成一个清晰的 “连接矩阵”。这本质上是一个二维表格,记录了任意两块 GPU 之间的连接关系(“NVLink” 或 “PCIe”)。这个矩阵就是该节点拓扑结构的数字蓝图。
- 公开注册: 系统将这个“连接矩阵”转换成一段 JSON 文本,并将其作为一条 Annotation 附加到该节点上。通过这一步,节点的物理拓扑就从一个本地信息,变成了整个集群可见、可查询的全局数据。
阶段二:调度决策 - 智能选择最优解
调度器在收到一个需要 GPU 的任务后,会读取所有节点的拓扑注解,在内存中重建出它们的“连接矩阵”,然后执行一个两步决策过程。
- 过滤:筛选“合格”的节点
这是一个硬性门槛。调度器会检查一个节点当前空闲的 GPU中,是否存在一个或多个能满足任务需求的组合。例如,对于一个需要 4 块 NVLink GPU 的任务,节点上必须至少有一组 4 个空闲的、且内部均为 NVLink 互联的 GPU。任何无法满足此基本条件的节点都会被直接淘汰。
- 打分:在“合格者”中选出“最优者”
这是选优的精髓。调度器会对所有合格的节点打分,以找出最佳选择,其核心思想是最大化满足当前需求,同时最小化对未来资源的破坏。
具体场景
- 对于多卡任务,遵循“最佳匹配”原则:
调度器偏爱“刚刚好”的分配方案。如果一个任务需要 4 块 GPU,它会给一个恰好有 4 卡空闲 NVLink 组的节点打高分,而给一个需要从 8 卡组中拆分出 4 卡的节点打低分。此举旨在防止宝贵的大块拓扑资源被打碎,避免“资源碎片化”。
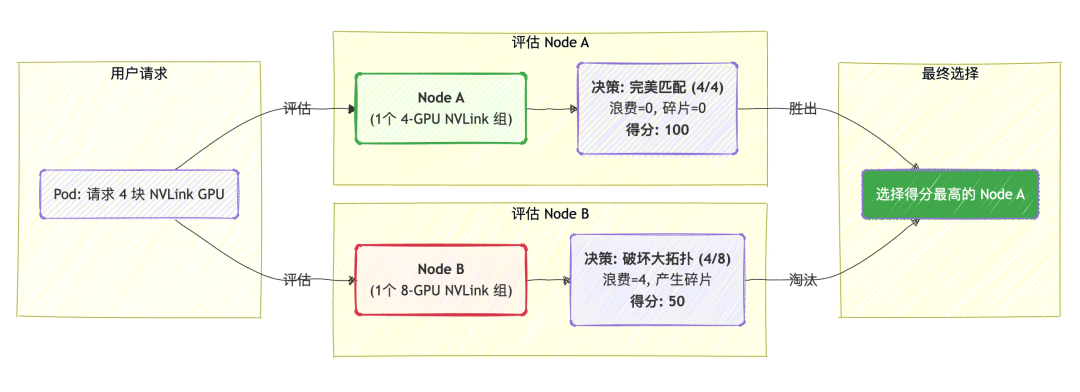
- 对于单卡任务,遵循“最小破坏”原则:
调度器会尽力保护完整的拓扑组。它会优先选择那些不属于任何 NVLink 拓扑组的“独立”GPU 来满足单卡任务。只有当没有独立 GPU 可用时,才会考虑动用拓扑组内的资源。此举确保了高速互联的 GPU 组合,被预留给真正需要它们的、更有价值的多卡任务。
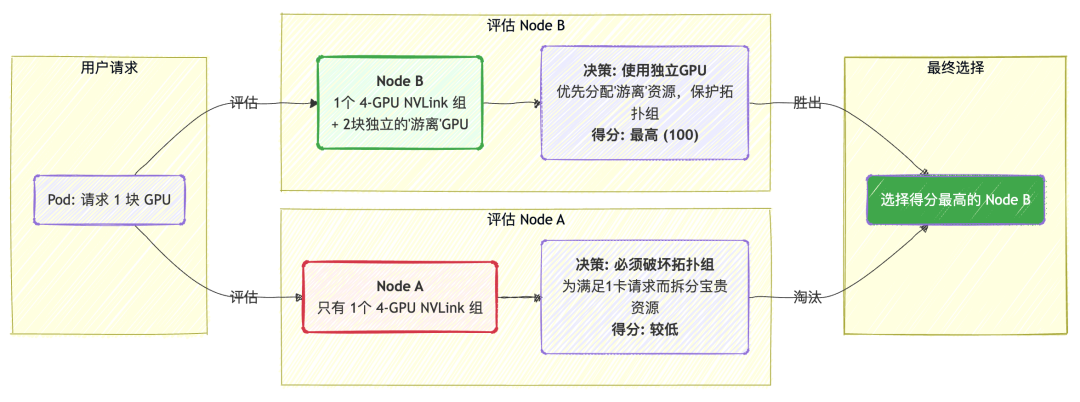
使用方式
apiVersion: v1
kind: ResourceQuota
metadata:
name: gpu-quota
namespace: default
spec:
hard:
limits.nvidia.com/gpu: "2"
limits.nvidia.com/gpumem: "3000"
设计文档:NVIDIA GPU Topology Scheduler [12]
使用文档:NVIDIA GPU 拓扑调度启用指南 [13]
Related PRs:
- https://github.com/Project-HAMi/HAMi/pull/1018
- https://github.com/Project-HAMi/HAMi/pull/1276
由衷感谢社区开发者 @lengrongfu,@fyp711 对该特性的贡献!
调度器核心优化
扩展的 ResourceQuota 支持
核心痛点:原生 ResourceQuota 的两大局限性
- 无法理解资源关联:
原生 ResourceQuota 独立计算每项资源,无法理解其内在关联。例如,当一个 Pod 请求 2 个 GPU,每个分配 2000MB 显存时 (nvidia.com/gpu: 2, nvidia.com/gpumem: 2000),原生 Quota 会错误地将总显存需求记为 2000MB,而不是正确的 2 * 2000MB = 4000MB。这导致配额管理严重失真。
- 无法处理动态资源:
对于按百分比申请显存的请求(如 gpumem-percentage: 50),其实际显存占用量只有在调度决策完成后(即确定了具体分配到哪一块物理 GPU 上)才能计算出来。原生 ResourceQuota 在调度前进行检查,无法处理这种需要“先调度,后扣减”的动态资源值。
解决方案:智能扩展 ResourceQuota
HAMi 引入了对 ResourceQuota 的扩展机制,使其能够智能地处理与 GPU 设备相关的复合资源请求。HAMi 的解决方案主要包含以下两个核心增强:
- 智能关联计算:HAMi 调度器能够识别出同一个 Pod 请求中的多个 GPU 资源,并将它们关联起来进行计算。对于上面的例子,HAMi 会正确地将总显存请求量计算为 2 (个 GPU) * 2000MB = 4000MB。这确保了 ResourceQuota 能够精确反映真实的资源消耗。
- 动态实时计算:对于按百分比或未指定具体值的请求,HAMi 会在调度决策时,根据 Pod 即将被分配到的物理 GPU 的实际规格,动态计算出确切的资源占用量并计入配额。例如,一个 50% 显存的请求若被调度到一块 24GB 的 GPU 上,ResourceQuota 将准确扣除 12GB。
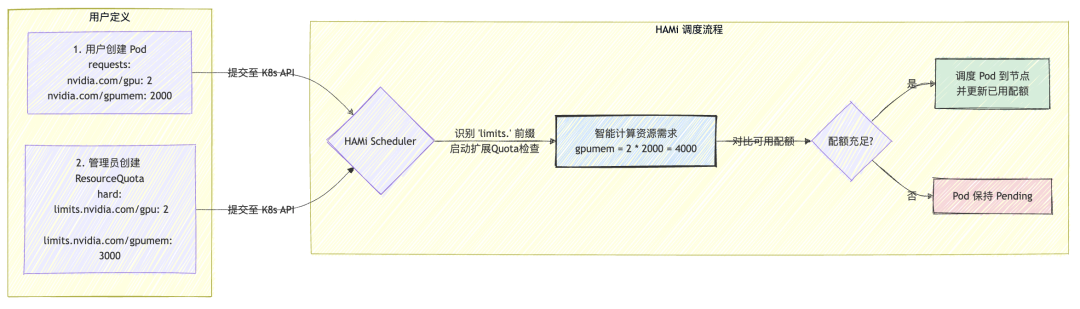
使用方式
apiVersion: v1
kind: Pod
metadata:
name: gpu-pod1
annotations:
volcano.sh/vgpu-mode: "mig"
spec:
containers:
- name: ubuntu-container1
image: ubuntu:20.04
command: ["bash", "-c", "sleep 86400"]
resources:
limits:
volcano.sh/vgpu-number: 1
volcano.sh/vgpu-memory: 8000
使用文档:NVIDIA 扩展 ResourceQuota 指南 [14]
Related PRs:
- https://github.com/Project-HAMi/HAMi/pull/1359
由衷感谢社区开发者 @FouoF 对该特性的贡献!
调度事件聚合
针对 Pod 仅返回 “no available node” 的模糊提示,调度器现在会在筛选失败时统计每类节点拒绝原因,并将 “CardInsufficientMemory”“NumaNotFit”等标准化标签连同节点数量写入 FilteringFailed 事件,直观呈现资源不足、拓扑不匹配等真实瓶颈。
事件系统增强了成功/失败两条链路:若筛选阶段仍未找到候选节点,将按原因聚合写入 Warning 事件;若找到合适节点,则在 Normal 事件里同时列出命中的节点与得分,配合 v4/v5 分级日志格式帮助用户定位问题,详见 docs/scheduler-event-log.md 的诊断示例。
使用文档:Scheduler Event 可观测性说明 [15]
Related PRs:
- https://github.com/Project-HAMi/HAMi/pull/1333
由衷感谢社区开发者 @Wangmin362 对该特性的贡献!
应用层生态
HAMi 不仅关注底层硬件支持,也致力于与上层 AI 应用生态的紧密结合,提升用户开发和部署体验。
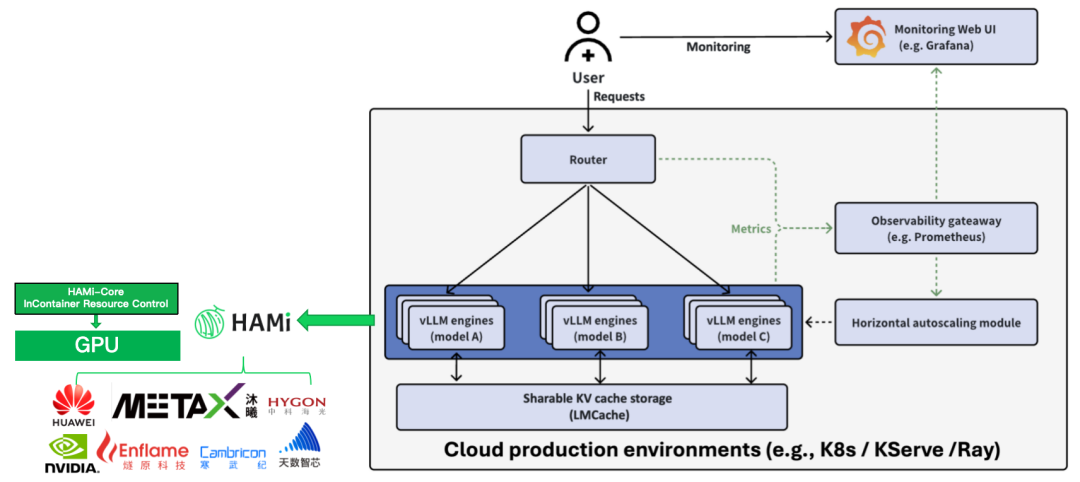
vLLM - 兼容性增强
在 vLLM 进行张量并行(TP)时,底层依赖 NCCL 库来完成高效的通信处理。在此基础上,HAMi-core 的新版本带来了以下改进和修复:
- 显存 异步申请优化:修复了在异步申请显存时偶尔会突破 MemPool 上限的 bug,提升了内存管理的稳定性。
- 显存 统计完善:修复了
cuMemCreate部分分配未能被正确统计的问题,确保内存使用数据更加准确。 - 符号引用错误修复:解决了部分符号引用异常导致进程挂起(hang)的情况,增强了系统健壮性。
- 上下文管理修复:修复了重复创建上下文时上下文大小未能正确统计的问题,避免了因数据溢出引发的潜在错误。
此外,vLLM 社区近期正式合并了 [PR [#579](javascript:😉: Feat - Add Support HAMi Resources Variables],使 vLLM 原生支持 HAMi 。这意味着用户在运行 vLLM 时,可以直接基于 HAMi 的虚拟化与调度能力配置资源,进一步降低集成成本,提升兼容性与易用性。
Related PRs:
- https://github.com/vllm-project/production-stack/pull/579
由衷感谢社区开发者 @andresd95 对该特性的贡献!
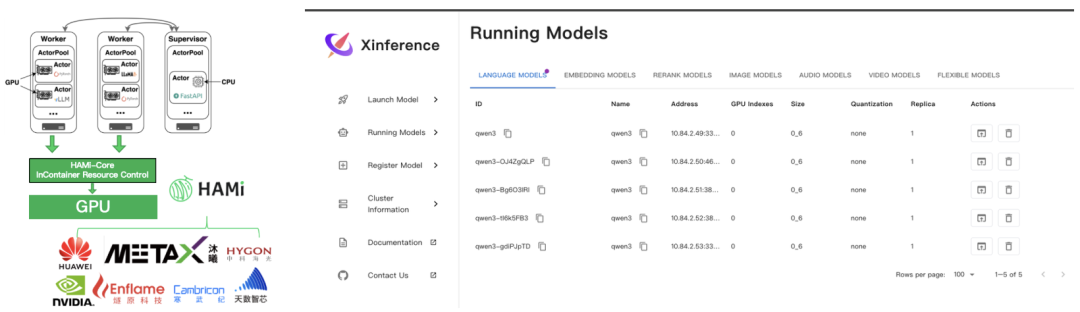
Xinference
Xinference 是 Xorbits 开源的多模型推理框架,提供 Supervisor/Worker 架构,方便在 Kubernetes 中部署和管理多模型服务。 在企业实践中,Xinference 常遇到 轻量模型独占整卡、资源浪费 以及 多租户场景下缺乏精细化配额与可观测性 的问题。 为此,社区合并了 [PR [#6](javascript:😉]:在 Helm Chart 中原生支持 HAMi vGPU,通过参数开关即可启用,并透传 HAMi 的 gpucores、gpumem-percentage 等资源变量到 Supervisor/Worker。
效果:
- 小模型可安全共享 GPU,整体利用率显著提升;
- 部署层面简化,用户无需二次开发即可直接原生使用 HAMi 的虚拟化能力;
- 支持配额化与可观测性管理,更适合多用户、多任务并发的生产场景。
Related PRs:
- https://github.com/xorbitsai/xinference-helm-charts/pull/6
由衷感谢社区开发者 @calvin0327 对该特性的贡献!
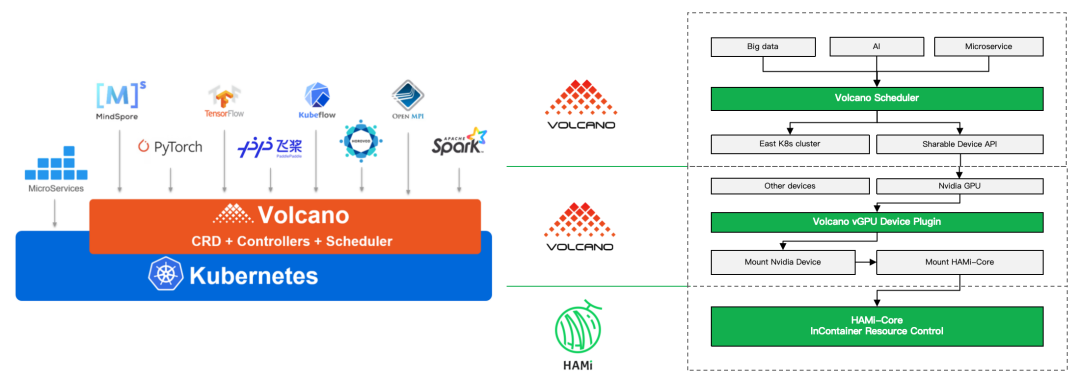
Volcano Dynamic MIG
Volcano 提供的 GPU 虚拟化功能支持按显存和算力申请部分 GPU 资源,通过与 Device Plugin 配合实现硬件隔离,从而提升 GPU 利用率。传统 GPU 虚拟化通过拦截 CUDA API 方式限制 GPU 使用。NVIDIA Ampere 架构引入的 MIG (Multi-Instance GPU) 技术允许将单个物理 GPU 划分为多个独立实例。然而,通用 MIG 方案通常预先固定实例大小,存在资源浪费和灵活性不足的问题。
Volcano v1.12 提供了动态 MIG 切分与调度能力,可根据用户申请的 GPU 用量实时选择合适的 MIG 实例大小,并使用 Best-Fit 算法减少资源浪费。同时支持 BinPack 和 Spread 等 GPU 打分策略,以减少资源碎片并提升 GPU 利用率。用户可使用统一的 volcano.sh/vgpu-number、volcano.sh/vgpu-cores、volcano.sh/vgpu-memory API 申请资源,无需关注底层实现。
apiVersion: v1
kind: Pod
metadata:
name: gpu-pod1
annotations:
volcano.sh/vgpu-mode: "mig"
spec:
containers:
- name: ubuntu-container1
image: ubuntu:20.04
command: ["bash", "-c", "sleep 86400"]
resources:
limits:
volcano.sh/vgpu-number: 1
volcano.sh/vgpu-memory: 8000
设计文档:Dynamic MIG 设计文档 [16]
使用文档:Dynamic MIG 使用文档 [17]
Related PRs:
- https://github.com/volcano-sh/volcano/pull/4290
- https://github.com/volcano-sh/volcano/pull/3953
由衷感谢社区开发者 @sailorvii, @archlitchi 对该特性的贡献!
开发者社区
HAMi 社区的壮大离不开每一位贡献者的辛勤付出!


为进一步推动 HAMi 社区的发展与治理,咱们迎来了新的贡献者与角色任命:
- HAMi 成员:@fyp711
- HAMi Reviewer: @lengrongfu、@chaunceyjiang、@Shouren、@ouyangluwei163
- volcano-vgpu-device-plugin Reviewer & Approver: @SataQiu
- HAMi Website Owner: @windsonsea
我们感谢上述成员的长期贡献与付出,并期待他们在新角色中继续推动社区的成长与繁荣。
版本优化与修复
HAMi
-
调度器核心优化
-
- 调度失败事件聚合 - 提升可观测性和故障排查效率
- NVIDIA 异常卡处理 - 防止异常 GPU 卡继续被调度使用
- 统一设备接口重构 - 移除冗余注解,简化设备接口架构
- 昇腾 910 调度策略 - 更新调度策略优化
- ResourceQuota - 解决多卡申请,原生配额无法统计的问题
-
关键稳定性修复
-
- 类型安全增强 -
int8Slice到uint8Slice转换,提升类型安全 - CI 构建修复 - 修复构建流程,增加 910B4-1 模板
- vGPU 监控指标修复 - 修复监控指标错误和设备分配问题
- 代码质量提升 - 修复
golangci-lint问题和代码重构
- 类型安全增强 -
HAMi-core
作为 HAMi 的底层引擎组件,HAMi-core 在 2.7 版本中同步完成了多项核心能力增强与工程优化:
-
核心功能增强
-
- 接口兼容性增强:新增
cuMemcpy2D函数 hook - 容器化****优化:Dockerfile 重构,减少镜像层数,优化缓存使用和体积
- 工程化升级:集成
cpplint代码检查 + CI/CD 管道 + 贡献者规范文档
- 接口兼容性增强:新增
-
关键稳定性修复
-
- 内存****安全:修复 NVML 接口空指针解引用,消除潜在崩溃风险
- 并发优化:解决多进程 GPU 利用率统计重复累加问题,确保监控数据准确性
- 资源监控:修复高并发场景下进程记录空指针访问,提升系统健壮性
-
代码质量提升
-
- 标准化:消除硬编码,使用
CUDA_DEVICE_MAX_COUNT宏统一设备限制 - 代码清理:移除冗余注释和空行,提升代码整洁度
- 架构优化:统计算法从累加模式重构为汇总-赋值模式,提升性能和准确性
- 标准化:消除硬编码,使用
WebUI
-
核心功能增强
-
沐曦监控全面支持:WebUI 现已全面支持沐曦 MetaX GPU 的监控指标展示,提供直观的资源使用情况概览。
未来展望
展望未来,HAMi 将继续致力于提升 GPU 资源管理的智能化和自动化水平,重点关注以下方向:
- DRA (Dynamic Resource Allocation):我们将逐渐完善对 Kubernetes DRA 的支持,在 DRA 的框架下支持以细粒度、灵活的异构资源动态分配,进一步提升资源利用率和调度效率。
- WebUI 持续优化:WebUI 将继续迭代,增加更多高级功能,更丰富的可视化图表,为用户提供更强大、更友好的操作界面。
- 生态系统扩展:持续与更多硬件厂商和 AI 框架进行深度集成,拓宽 HAMi 的应用场景,打造更开放、更繁荣的异构计算生态。
感谢所有社区成员和贡献者的大力支持!期待与大家共同建设更强大的 HAMi!在“芯”与“序”的坐标中,绘制更远的开源航图。
参考资料
- 顺丰 CNCF 案例研究: 点击查看
- PREP EDU CNCF 案例研究: 点击查看
- vCluster YouTube 视频: 点击查看
- The Linux Foundation AI_dev YouTube 视频: 点击查看
- 越南电信 Meetup: 点击查看
- 越南电信 YouTube 视频: 点击查看
- MetaX GPU 支持说明: 点击查看
- MetaX GPU 样例: 点击查看
- Kunlun XPU 支持: 点击查看
- AWS Neuron 示例与操作指南: 点击查看
- Enflame GCU/GCUshare 支持: 点击查看
- NVIDIA GPU Topology Scheduler: 点击查看
- NVIDIA GPU 拓扑调度启用指南: 点击查看
- NVIDIA 扩展 ResourceQuota 指南: 点击查看
- Scheduler Event 可观测性说明: 点击查看
- Dynamic MIG 设计文档: 点击查看
- Dynamic MIG 使用文档: 点击查看
原文链接🔗:https://mp.weixin.qq.com/s/Pdyw4XGn_uxC_nF4Z1tFbg
本文为©️HAMi 社区 开源共创授权发布


欢迎加入西安开发者社区!我们致力于为西安地区的开发者提供学习、合作和成长的机会。参与我们的活动,与专家分享最新技术趋势,解决挑战,探索创新。加入我们,共同打造技术社区!
更多推荐



 26
26 0
0- 0



 已为社区贡献113条内容
已为社区贡献113条内容

所有评论(0)