
法律 AI Agent:从架构到案例匹配的技术方案与工程实践
我们一听到 RAG(检索增强生成),脑海里立刻浮现出的是:AI、ChromaDB、Milvus、向量数据库、复杂的 Python 依赖…… 还没开始写代码,就已经被繁琐的部署环境劝退了。
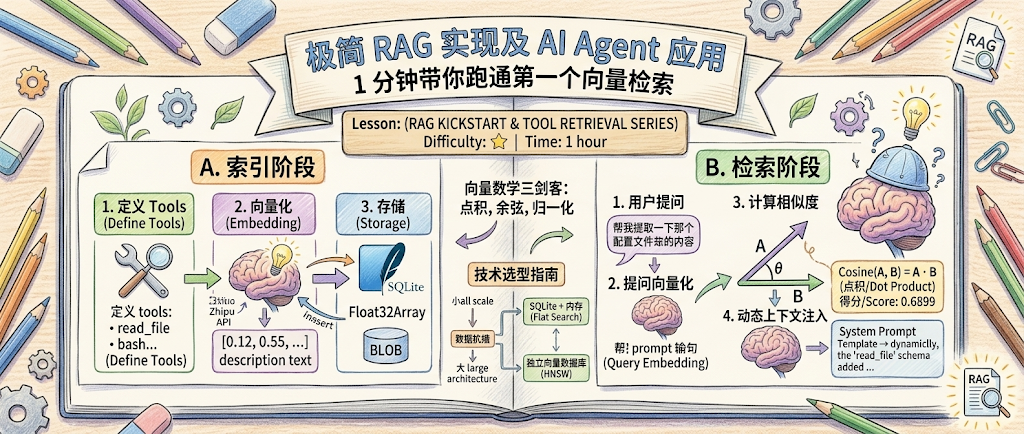
其实,RAG 的底层逻辑极其简单,无非就是三步:
-
1. 向量化(Embedding):把文本变成一串浮点数数组。
-
2. 向量存储:把这些浮点数存起来。
-
3. 计算相似度:计算两个数组之间的“夹角”(余弦距离),找出最接近的。
在本文中,我们不用任何专业的向量数据库,只用 TypeScript + Node.js 22 自带的 SQLite,手把手带大家在 1 分钟内跑通一个真正的 RAG 工具检索系统。
通过这个实例,我们不仅能亲手写出 RAG,还能看到“跨语言语义检索”(用中文匹配英文代码工具)的奇妙效果。
🛠️ 第一步:环境准备(仅需 10 秒)
新建一个空文件夹,初始化项目并安装唯一的依赖项 dotenv(用于读取智谱的 API Key):
mkdir rag-demo && cd rag-demo
npm init -y
npm install dotenv
npm install -D tsx typescript @types/node
在根目录下创建一个 .env 文件,填入你的智谱 API Key(你可以去 智谱大模型开放平台[1] 免费申请一个):
ZHIPU_API_KEY=你的智谱API_KEY
使智谱的 embedding 模型是因为它对跨语言的语义检索有非常好的支持,在这个例子中,在数据库中保存的是英语"read file"的向量,但是在搜索时,会使用中文相似的语义进行搜索,非常方便!
💻 第二步:手写极简 RAG(只要一个文件)
创建 index.ts,把下面的代码直接复制进去,或者让 AI 按这个文件生成一个可以运行的项目(Claude Code 或 Codex 都行)。
为了做到“极简启动”,我们直接使用 Node.js 22 的内置 SQLite,在内存中(:memory:)建表、写入向量,并进行相似度计算。当然也可以使用一个本地db文件可以更加清楚地看到保存的数据。
import { DatabaseSync } from'node:sqlite';
import dotenv from'dotenv';
dotenv.config();
constAPI_KEY = process.env.ZHIPU_API_KEY;
if (!API_KEY) {
console.error("❌ 请先在 .env 文件中配置 ZHIPU_API_KEY");
process.exit(1);
}
// ==========================================
// 1. 定义我们要检索的工具数据 (Tools)
// ==========================================
constTOOLS = {
"read_file": "Read a file from disk and return its contents. View source code, config files, logs.",
"bash": "Run shell commands on the server. Install packages, git operations, builds.",
"web_search": "Quick single web lookup for a fact, current event, latest/current information.",
"manage_calendar": "Calendar event management: list, create, update, delete events."
};
// ==========================================
// 2. 向量数学工具:归一化 & 点积计算
// ==========================================
// 归一化:把向量模长缩放到 1,保持方向不变
functionnormalize(v: Float32Array): Float32Array {
let sum = 0.0;
for (let i = 0; i < v.length; i++) sum += v[i] * v[i];
const norm = Math.sqrt(sum);
if (norm > 0) {
for (let i = 0; i < v.length; i++) v[i] /= norm;
}
return v;
}
// 两个已归一化向量的点积,完全等同于它们的余弦相似度
functiondotProduct(a: Float32Array, b: Float32Array): number {
let score = 0.0;
for (let i = 0; i < a.length; i++) score += a[i] * b[i];
return score;
}
// ==========================================
// 3. 智谱 Embedding 接口对接
// ==========================================
asyncfunctiongetEmbeddings(texts: string[]): Promise<Float32Array[]> {
const res = awaitfetch('https://open.bigmodel.cn/api/paas/v4/embeddings', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'Authorization': `Bearer ${API_KEY}`,
},
body: JSON.stringify({
model: 'embedding-3', // 智谱最新第三代向量模型
input: texts,
dimensions: 1024, // 输出 1024 维度的向量
}),
});
const data = await res.json();
return data.data.map((item: any) =>normalize(newFloat32Array(item.embedding)));
}
// ==========================================
// 4. 主程序运行
// ==========================================
asyncfunctionmain() {
console.log("🚀 正在初始化内存 SQLite 数据库...");
const db = newDatabaseSync(':memory:'); // 内存数据库,进程退出自动销毁
db.exec(`
CREATE TABLE tool_index (
name TEXT PRIMARY KEY,
description TEXT,
embedding BLOB
)
`);
// A. 索引阶段:生成向量并写入 SQLite
console.log("📡 正在调用 API 为工具描述生成向量...");
const names = Object.keys(TOOLS);
const descriptions = Object.values(TOOLS);
const vectors = awaitgetEmbeddings(descriptions);
const insertStmt = db.prepare("INSERT INTO tool_index (name, description, embedding) VALUES (?, ?, ?)");
for (let i = 0; i < names.length; i++) {
// Float32Array 转换为 Node 的二进制 Buffer 存入 BLOB
const buffer = Buffer.from(vectors[i].buffer);
insertStmt.run(names[i], descriptions[i], buffer);
}
console.log(`✅ 成功将 ${names.length} 个工具向量化存入 SQLite BLOB 字段。/n`);
// B. 检索阶段:模拟用户提问
const userQuery = "帮我提取一下那个配置文件的内容";
console.log(`🔎 用户提问: "${userQuery}"`);
console.log("⏳ 正在检索最匹配的工具...");
// 1. 将用户的提问向量化
const queryVector = (awaitgetEmbeddings([userQuery]))[0];
// 2. 从 SQLite 读出所有向量,在内存中进行相似度比对
constrows: any[] = db.prepare("SELECT name, description, embedding FROM tool_index").all();
const results = rows.map(row => {
// 从二进制 BLOB 中恢复出 Float32Array
const buffer = row.embedding;
const vector = newFloat32Array(buffer.buffer, buffer.byteOffset, buffer.byteLength / 4);
// 计算点积得分
const score = dotProduct(queryVector, vector);
return { name: row.name, score };
});
// 3. 排序并展示前 3 个结果
results.sort((a, b) => b.score - a.score);
console.log("/n🎯 检索推荐结果:");
results.slice(0, 3).forEach((res, index) => {
console.log(` [${index + 1}] 工具名: ${res.name.padEnd(18)} 相似度得分: ${res.score.toFixed(4)}`);
});
}
main().catch(console.error);
🏃♂️ 第三步:一键运行(仅需 10 秒)
在终端直接运行这个 TS 文件:
npx tsx index.ts
运行后,你将看到如下输出:
🚀 正在初始化内存 SQLite 数据库...
📡 正在调用 API 为工具描述生成向量...
✅ 成功将 4 个工具向量化存入 SQLite BLOB 字段。
🔎 用户提问: "帮我提取一下那个配置文件的内容"
⏳ 正在检索最匹配的工具...
🎯 检索推荐结果:
[1] 工具名: read_file 相似度得分: 0.6899
[2] 工具名: bash 相似度得分: 0.4435
[3] 工具名: web_search 相似度得分: 0.3541
核心知识点拆解(真正理解 RAG)
在这几十行代码中,其实隐藏了向量检索中最核心的数学思想和工程取舍。我们逐一拆解:
1. 向量数学三剑客:点积、余弦、归一化
为什么我们能把繁琐的相似度计算,简化为简单的“乘加循环”?这背后是一套精妙的数学简化:
- 点积(Dot Product):
数学公式为 。
它是把两个向量对应位置的数相乘再相加。
- 问题:点积不仅受“方向”影响,还深受向量 “长度(模长)” 的影响。如果一个词在文章里重复了 100 遍,它的向量长度会变长,导致算出来的点积异常大。这在搜索中会导致“长文章霸榜”的灾难。
- 余弦相似度(Cosine Similarity):
为了消除长度的干扰,余弦相似度在点积的基础上,除以了两个向量的模长乘积:
这样,无论文章长短,它只关注向量的夹角(语义方向),值域永远在 之间。 - 向量归一化(L2 Normalization):
归一化就是把向量的长度缩放到恒等于 (即单位向量,单位圆上的点),但保持它的方向不变。
- 魔法时刻:一旦两个向量 和 在存入/查询前都被归一化了,
那么它们的模长 且 。 - 此时,余弦公式的分母 。
- 余弦相似度公式直接简化为:(点积)!
- 工程意义:这帮我们在高频的检索循环中,彻底消除了开平方根(Math.sqrt)和浮点数除法这两个最耗 CPU 周期的指令,本地比对速度直接飙升数倍。
2. 架构对比:SQLite 内存算法 vs 向量数据库
为什么我们的 Demo 不用 ChromaDB 这种专业的向量数据库,反而能跑得更快?
向量数据库(如 Chroma, Milvus, pgvector):
它们使用 HNSW(分层可导航小世界) 算法。这是一种近似最近邻(ANN)检索。它不会傻傻地把库里所有向量都比对一遍,而是通过构建“树状/图状索引”,实现类似二分查找的 检索速度。
我们的 SQLite + 内存暴力检索(Flat Search):
这是最原始的 遍历——把所有向量全读出来,挨个算点积。
为什么小规模更快:因为在数据量极小(比如几十个工具描述)时,构建和查询 HNSW 索引树的系统开销,远远大于直接暴力遍历。更重要的是,我们省去了跨进程/跨网络的 IPC 通信延迟(通常为 2~10ms),内存循环计算 50 个向量仅需 0.02 毫秒。
在我们的实例中,只有几条 Tools 数据,那么全部读取出来后,每条都对比一下归一后的相似度,与读取数据库的速度相比,时间基本可以多忽略不计(在归一化后只会计算乘法和加法,速度非常快),作为一个 Demo (后面会讲到的在 AI Agent中的使用场景),可以更加快速地理解 RAG 的核心机制。
3. 技术选型指南:以后遇到项目怎么选?
在实际的 Agent 和 RAG 开发中,面对不同的数据规模,我们应该采取不同的技术选型:
是
否
是
否
确定数据规模 - 向量条数
小于 500 条?
极简方案: 本地 SQLite 存储 + 内存点积计算 零依赖, 响应 <1ms
500 ~ 10,000 条?
轻量方案: SQLite + sqlite-vec 向量扩展 或 PostgreSQL + pgvector
企业方案: 独立向量数据库Chroma / Qdrant / Milvus启用 HNSW 索引
选型决策表:
| 场景特点 | 数据规模(向量数) | 推荐架构 | 选型理由 |
|---|---|---|---|
| 轻量级检索(工具检索/个性化记忆/菜单匹配) | < 500 条 | 内存计算 + SQLite 存储 | 性能最高,开发最快,完全不增加系统架构的复杂度。 |
| 中型知识库(单机文档库/个人笔记 RAG) | 500 ~ 10,000 条 | 嵌入式扩展(如 sqlite-vec 插件) | 不需要搭建独立服务,直接通过 SQL 插件实现单机 检索。 |
| 企业级应用(百万文档库/高并发 SaaS 搜索) | > 10,000 条 | 独立向量数据库(Chroma / Milvus / Qdrant) | 需要处理分布式横向扩展、高并发连接池以及超大规模 HNSW 索引的内存开销。 |
🤖 在 AI Agent 中的实战场景
在 AI Agent 的架构设计中,核心是 LLM Contex(上下文)的管理,为了更加有地利用上下文空间,需要对 Agent 需要涉及的 Tools 以及 Skills 进行精心的设计,确保它们足够但是又不能太多。
如果我们的 Agent 拥有 50 个工具(比如:查邮件、写文件、调 API、跑脚本…),把所有工具的详细说明都塞进 System Prompt,不仅每次对话消耗巨大 Token,大模型还容易产生 “幻觉”,在复杂的工具列表中选错工具。
最后在看一个项目时,发现它使用了将 Tools 工具进行向量化处理的方法,操作流程如下:
-
1. 用户的 Prompt 进来(比如:“帮我查一下昨天关于苹果发布会的新闻”)。
-
2. 在本地 SQLite 向量库里快速比对。
-
3. 发现得分最高的是
web_search(得分0.38)和web_fetch。 -
4. 动态把这两个工具的 Schema 和使用指南塞进当前的 System Prompt 发给大模型。
-
5. 运行结束,下次对话重新匹配。
通过这套极简 RAG,Agent 就可以轻松拥有上百个工具,而不需要担心 Prompt 的长度限制。
而工具的定义大体如下:
const TOOLS = {
"read_file": "Read a file from disk and return its contents. View source code, config files, logs.",
"bash": "Run shell commands on the server. Install packages, git operations, builds.",
"web_search": "Quick single web lookup for a fact, current event, latest/current information.",
"manage_calendar": "Calendar event management: list, create, update, delete events.",
.........
};
这里需要解决几个问题:
- 在入库时使用的是英文,而用户的 prompt 可能是任何语言(比如我们例子中是中文),是否能跨语言匹配?
- 这种 RAG 处理后的准确度如何?
从我们做的几个实验来看,准确度是基本有保证的(而且我们并不是只需要匹配最合适的那个,可能需要有多个工具的话,是可以形成一个工具列表的)。
结语
RAG 从来不是什么高不可攀的技术。对于小规模、高频的本地检索(如工具检索、个性化偏好匹配、小知识库),内存计算 + 轻量存储才是最高效、最清爽的架构。
动手跑通这几十行 TypeScript 代码,就已经迈出了走向 RAG 实战开发的最关键一步。
希望这篇文章可以帮你跨过理解 RAG 第一个门槛。
引用链接
[1] 智谱大模型开放平台: https://open.bigmodel.cn/
这里给大家精心整理了一份全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!
👇👇扫码免费领取全部内容👇👇
1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。
2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 2026行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

7. 资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐

 4
4 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)