
Multimodal Agent 最新方法盘点:从看懂屏幕到操作真实世界
Multimodal Agent 最新方法盘点:从看懂屏幕到操作真实世界

系列:AI 论文盘点 / 技术趋势
日期:2026-06-28
适合读者:研究生、Agent/多模态方向研究者、做自动化产品或机器人系统的工程读者
检索日期:2026-06-28
摘要
过去两年,Multimodal Agent 从“把截图交给 VLM,再让 LLM 决定点击哪里”快速推进到“跨平台 GUI action model、computer-use skill base、以及能连接数字界面和物理控制的 VLA”。2024 年的 OSWorld、WebVoyager、AndroidWorld 把问题定义清楚:真实环境会变化,任务常跨应用,评价必须看最终状态。2025-2026 年的 UI-TARS、Magma、CUA-Skill、WindowsWorld、MacArena、OmniGUI、MacAgentBench 则把重点转向可训练动作模型、技能复用、多模态事件流和更真实的 benchmark。
本文按技术路线梳理近一年代表论文,并提炼工程启发:Multimodal Agent 的难点已经不只是“看不懂”,而是动作空间、长期状态、错误恢复、权限边界、环境复现和可审计执行共同构成的系统问题。
目录
- 研究背景
- 近一年路线图
- 代表论文分组解读
- 方法对比表
- 技术趋势与工程启发
- 局限与争议
- 总结
- 参考资料
研究背景
传统 LLM Agent 常把环境抽象成文本 API、HTML DOM 或函数调用 schema。这适合研究规划与工具调用,但离真实使用还有距离:用户面对的是屏幕、弹窗、窗口切换、文件系统、通知、权限确认、视频、语音和偶发错误。Multimodal Agent 的核心变化,是让模型直接或间接处理视觉观察,并输出能改变环境状态的动作。
可以把这个方向分成两个逐渐靠近的世界。数字世界包括 Web、手机、桌面 OS、办公软件和开发工具,输入是截图、OCR、accessibility tree、HTML、视频帧或操作历史,动作是点击、输入、滚动、快捷键和文件操作。物理世界包括机器人和 embodied AI,输入是相机、传感器与语言指令,动作是离散技能或连续控制。二者的共同问题是:模型必须把多模态感知、任务记忆、动作选择和环境反馈接成闭环。
基础论文仍然重要。Mind2Web 推动 Web generalist agent 的数据与评测;SeeClick 强调 GUI grounding 是视觉 GUI agent 的关键瓶颈;WebVoyager 用真实网站检验端到端视觉 Web agent;OSWorld 将“真实电脑环境中的开放任务”做成可复现 benchmark。它们共同把问题从“生成脚本”推进到“在状态会变化的 GUI 环境里可靠完成任务”。
近一年路线图
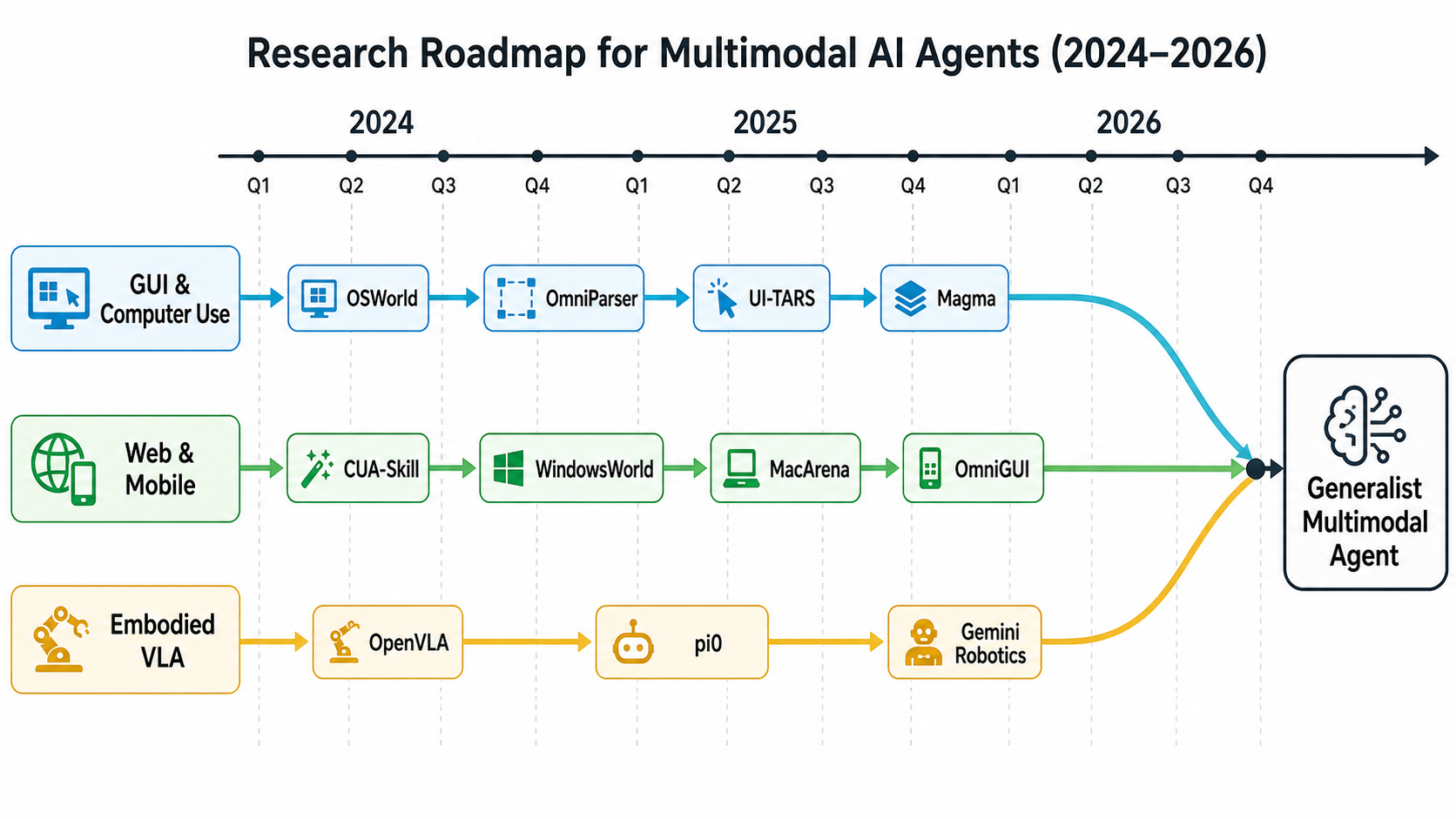
近一年路线可以概括为四条主线。
第一,GUI agent 从 prompt workflow 转向专门训练的 action model。OS-ATLAS、ShowUI、Aguvis、UI-TARS 都在尝试跨桌面、Web、移动端的统一视觉 grounding 与动作建模。UI-TARS 把 GUI screenshot、大规模 action traces、统一动作空间、系统二式推理和在线反思放进 native GUI agent 框架,代表了“模型本身学会操作界面”的路线。
第二,screen parsing 成为实用中间层。OmniParser 将可交互区域检测和语义描述拆出来,帮助上层 VLM/Agent 更稳定地把意图落到坐标。对工程团队来说,可解释的视觉前端通常比完全黑盒端到端 agent 更容易调试、审计和降级。
第三,benchmark 从静态截图走向跨应用、长流程和多模态事件。WindowsWorld 强调专业跨应用流程;MacArena 和 MacAgentBench 说明 macOS 不是普通桌面 GUI 的简单变体;OmniGUI 把手机环境从静态截图推进到图像、音频、视频交织的 step-level 评测。
第四,具身 VLA 把“动作”从点击坐标扩展到连续控制。OpenVLA 推动开放 VLA 研究,π0 用 flow matching 建模连续动作,Magma 尝试把 UI navigation 与 robot manipulation 放进同一个多模态 agent 基座,Gemini Robotics 则代表大模型厂商向物理行动扩展。
代表论文分组解读
Web 与桌面:从真实网页到真实操作系统
WebVoyager 的价值在于选择真实网站,而不是只在简化网页环境里跑任务。OSWorld 进一步覆盖真实电脑任务,包含文件 I/O、多应用流程和执行式检查。论文报告人类完成率显著高于当时最强模型,说明 GUI grounding、操作知识和长程恢复仍是核心短板。
2026 年的 WindowsWorld 把难点推到职业场景:任务通常包含多个子目标,且多数需要跨应用完成。MacArena 与 MacAgentBench 则提醒研究者不要把一个系统上的结果外推到所有桌面环境。macOS 的菜单、窗口、权限、快捷键和应用生态都有独特约束,模型排序也可能随任务子集改变。
手机代理:从单 App 导航到多模态事件流
Mobile-Agent 尽量不依赖 XML 或系统元数据,而用视觉感知识别控件;Mobile-Agent-v2 引入 planning、decision、reflection 多代理结构处理任务进度与错误恢复。AndroidWorld 提供动态 Android 任务和程序化 reward,GUI Odyssey 则强调跨 App navigation。
OmniGUI 的新意是 omni-modal smartphone environments:每个 action step 不只给静态图片,还可能有音频和视频片段。这很贴近现实手机使用,因为很多状态来自短暂 toast、播放器变化、通知声音或动态画面。只把截图交给模型,会天然丢掉这些信息。
GUI action model:从“点哪里”到“怎么连续做”
SeeClick 和 ScreenSpot 类评测说明,GUI agent 的第一道门槛是 grounding。OS-ATLAS 通过跨平台 GUI grounding 语料和 foundation action model 提升开源模型泛化;ShowUI 用 UI-guided visual token selection 减少冗余视觉 token;Aguvis 强调 pure vision、自主 GUI interaction 与开放训练 recipes。
UI-TARS 更接近完整 native GUI agent:它用大量 GUI action trace 学习截图到动作的映射,并通过反思式轨迹增强连续决策。需要注意,论文 benchmark 数字会受模型版本、工具栈、step limit 与 UI 更新影响,本文不把单次 leaderboard 结果视为长期 SOTA 结论。
技能库与具身 VLA
CUA-Skill 提出 skill + execution graph:模型不必每次从截图重新发明 Office、浏览器或系统设置的操作流程,而是检索并参数化可复用技能。这对工程落地很关键,因为企业自动化更需要稳定、可审计、可回滚的动作宏和 RPA fallback,而不是完全自由的即兴操作。
具身方向则把 action 从离散 UI 操作扩展到机器人控制。RT-2 是经典基础:把机器人动作表示成 token,让 VLM 共享语言和动作生成范式。OpenVLA 降低复现门槛;π0 用 flow matching 输出连续动作;Magma 结合 Set-of-Mark 与 Trace-of-Mark 覆盖 UI、视频和机器人任务;Gemini Robotics 显示通用多模态模型正在进入物理行动场景。
方法对比表
| 路线 | 代表工作 | 主要输入 | 主要动作 | 工程启发 |
|---|---|---|---|---|
| Web/桌面 agent | WebVoyager, OSWorld, WindowsWorld, MacArena | 截图、网页、OS 状态、历史轨迹 | 点击、输入、快捷键、文件操作 | 必须做 sandbox、状态重置和执行式验收 |
| 手机 agent | Mobile-Agent, AndroidWorld, GUI Odyssey, OmniGUI | 截图、OCR、音频/视频、操作历史 | 点击、滑动、输入、App 切换 | 静态截图不足,需要事件流与设备状态 |
| GUI action model | SeeClick, OS-ATLAS, ShowUI, Aguvis, UI-TARS | UI screenshot、元素语义、动作轨迹 | 坐标、控件选择、动作 token | 数据质量与统一动作空间比 prompt 更关键 |
| Screen parsing | OmniParser | 截图、图标、文本、可交互区域 | 结构化 UI 元素 | 适合与闭源/开源 VLM 混合部署 |
| 技能库 | CUA-Skill | GUI 状态、任务、技能上下文 | 参数化技能、执行图 | 把模型输出限制在可审计边界内 |
| 具身 VLA | RT-2, OpenVLA, π0, Magma | 图像/视频、语言、机器人状态 | 离散或连续机器人动作 | 真实安全、延迟和数据闭环比 demo 更难 |
技术趋势与工程启发
第一,动作空间正在统一。GUI agent 需要把点击、拖拽、输入、快捷键、App 切换抽象成跨平台动作;VLA 需要把末端执行器、关节轨迹或高层技能抽象成可学习输出。统一动作空间决定数据能否混合训练,错误能否复现,策略能否迁移。
第二,视觉前端正在模块化。屏幕不是普通自然图片,UI 有层级、边界、可点击区域和操作语义。OmniParser、ShowUI、SeeClick、OS-ATLAS 都说明,把这些 inductive bias 写进数据和模型,通常比堆更长 prompt 更有效。
第三,评测正在交互化。OSWorld、AndroidWorld、WindowsWorld、MacArena、OmniGUI 都要求 agent 改变环境状态,并用最终状态或程序化规则检查结果。这会迫使系统处理加载延迟、错误点击、权限弹窗、任务重试和中间失败。
第四,技能、记忆和反思会成为必要系统层。长任务失败常不是第一步看错,而是后续忘记目标、状态不同步或恢复策略错误。工程上推荐“视觉解析层 + 规划模型 + 技能执行层 + 审计日志”的分层架构:模型可以提出计划,关键动作应走受控技能,并对付款、发信、删文件、改权限等操作设置人工确认。
第五,数据闭环比框架选择更重要。GUI grounding 数据、真实操作轨迹、失败轨迹、跨应用流程、音视频事件和机器人 demonstrations 都是稀缺资产。团队若有真实场景,应优先建设任务集、回放环境、失败样本库和验收脚本,而不是频繁更换 agent 框架。
局限与争议
首先,benchmark 仍然碎片化。不同平台、应用生态、任务分布和工具接口会改变模型表现,一个 leaderboard 领先不能证明通用电脑使用能力。
其次,很多结果依赖闭源模型版本、step limit、工具栈和 UI 状态。模型名称、API 版本、网页布局、系统权限和应用更新都会影响复现。本文只保留来源中明确可查的信息;上线选型仍应重新跑本地任务集。
第三,安全问题会比文本 Agent 更棘手。GUI agent 不只会“说错”,还会“点错”。网页、邮件、图片、文档、通知和弹窗都可能成为间接注入或界面误导来源,因此权限、确认、日志和回滚必须前置设计。
第四,具身 VLA 的 demo 与生产机器人之间仍有距离。连续控制需要低延迟、物理安全、传感器可靠性和异常停止机制。跨 embodiment 泛化很重要,但在真实工厂、家庭和医疗场景中仍需严格验证。
总结
Multimodal Agent 的最新方法正在形成清晰图景:模型要看懂屏幕和世界,也要把意图转成可执行动作;系统要能评测、回滚、审计和恢复;数据要覆盖真实轨迹、失败案例和跨平台差异。短期最可靠的落地方式不是完全自主代理,而是受限任务、强环境控制、可复用技能库和人工确认。长期看,GUI action model 与具身 VLA 可能会合流,形成能在数字界面和物理空间中共享感知、记忆、规划和行动能力的通用多模态代理。
参考资料
检索日期:2026-06-28。优先使用 arXiv、项目主页、官方博客或官方文档;benchmark 数字和模型发布时间以链接页面为准。
- OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments. arXiv, 2024-04-11. https://arxiv.org/abs/2404.07972
- WebVoyager: Building an End-to-End Web Agent with Large Multimodal Models. arXiv, 2024-01-25. https://arxiv.org/abs/2401.13919
- SeeClick: Harnessing GUI Grounding for Advanced Visual GUI Agents. arXiv, 2024-01-17. https://arxiv.org/abs/2401.10935
- Mind2Web: Towards a Generalist Agent for the Web. arXiv, 2023-06-09. https://arxiv.org/abs/2306.06070
- AndroidWorld: A Dynamic Benchmarking Environment for Autonomous Agents. arXiv, 2024-05-23. https://arxiv.org/abs/2405.14573
- Mobile-Agent: Autonomous Multi-Modal Mobile Device Agent with Visual Perception. arXiv, 2024-01-29. https://arxiv.org/abs/2401.16158
- Mobile-Agent-v2: Mobile Device Operation Assistant with Effective Navigation via Multi-Agent Collaboration. arXiv, 2024-06-03. https://arxiv.org/abs/2406.01014
- GUI Odyssey: A Comprehensive Dataset for Cross-App GUI Navigation on Mobile Devices. arXiv, 2024-06-12. https://arxiv.org/abs/2406.08451
- OmniParser for Pure Vision Based GUI Agent. arXiv, 2024-08-01. https://arxiv.org/abs/2408.00203
- OS-ATLAS: A Foundation Action Model for Generalist GUI Agents. arXiv, 2024-10-30. https://arxiv.org/abs/2410.23218
- ShowUI: One Vision-Language-Action Model for GUI Visual Agent. arXiv, 2024-11-26. https://arxiv.org/abs/2411.17465
- Aguvis: Unified Pure Vision Agents for Autonomous GUI Interaction. arXiv, 2024-12-05. https://arxiv.org/abs/2412.04454
- UI-TARS: Pioneering Automated GUI Interaction with Native Agents. arXiv, 2025-01-21. https://arxiv.org/abs/2501.12326
- Magma: A Foundation Model for Multimodal AI Agents. arXiv, 2025-02-18. https://arxiv.org/abs/2502.13130
- CUA-Skill: Develop Skills for Computer Using Agent. arXiv, 2026-01-28. https://arxiv.org/abs/2601.21123
- WindowsWorld: A Process-Centric Benchmark of Autonomous GUI Agents in Professional Cross-Application Environments. arXiv, 2026-04-30. https://arxiv.org/abs/2604.27776
- OmniGUI: Benchmarking GUI Agents in Omni-Modal Smartphone Environments. arXiv, 2026. https://arxiv.org/abs/2605.18758
- MacArena: Benchmarking Computer Use Agents on an Online macOS Environment. arXiv, 2026-06-04. https://arxiv.org/abs/2606.06560
- MacAgentBench: Benchmarking AI Agents on Real-World macOS Desktop. arXiv, 2026-06-21. https://arxiv.org/abs/2606.22557
- RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control. arXiv, 2023-07-28. https://arxiv.org/abs/2307.15818
- OpenVLA: An Open-Source Vision-Language-Action Model. arXiv, 2024-06-13. https://arxiv.org/abs/2406.09246
- π0: A Vision-Language-Action Flow Model for General Robot Control. arXiv, 2024-10-31. https://arxiv.org/abs/2410.24164
- VLANeXt: Recipes for Building Strong VLA Models. arXiv, 2026-02-20. https://arxiv.org/abs/2602.18532
- OpenAI Operator research preview. OpenAI, 2025-01-23. https://openai.com/index/introducing-operator/
- Anthropic Computer Use announcement. Anthropic, 2024-10-22. https://www.anthropic.com/news/3-5-models-and-computer-use
- Gemini Robotics brings AI into the physical world. Google DeepMind, 2025-03-12. https://deepmind.google/discover/blog/gemini-robotics-brings-ai-into-the-physical-world/

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐
 2
2 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)