
GEMS: Agent-Native Multimodal Generation with Memory and Skills翻译
⚠️ 在开始阅读之前,如果你对 实时 Agent / 数字人 / 多模态系统 / LiveKit 架构 感兴趣,
欢迎先到 GitHub 给项目点一个 ⭐ Star,这是对开源作者最大的支持。
🚀 AlphaAvatar 项目地址(强烈建议先收藏,该项目正在持续更新维护):
👉 https://github.com/AlphaAvatar/AlphaAvatar
🚀 AIPapers 项目地址(具有更全的有关LLM/Agent/Speech/Visual/Omni论文分类):
👉 https://github.com/AlphaAvatar/AIPaperNotes
摘要
近年来,多模态生成模型在通用生成任务上取得了显著进展,但在处理复杂指令和特定下游任务时仍然面临挑战。受 Claude Code 等先进智能体框架的成功启发,我们提出了 GEMS (Agent-Native Multimodal GEneration with Memory and Skills),该框架突破了基础模型在通用任务和下游任务上的固有局限性。GEMS 由三个核心组件构成:智能体循环(Agent Loop)引入了一个结构化的多智能体框架,通过闭环优化迭代地提升生成质量;智能体记忆(Agent Memory)提供了一个持久的轨迹级记忆,以分层方式存储事实状态和压缩的经验摘要,从而实现对优化过程的全局视图,并减少冗余;智能体技能(Agent Skill)提供了一个可扩展的领域特定专业知识集合,支持按需加载,使系统能够有效地处理各种下游应用。在五个主流任务和四个下游任务上,并在多个生成后端进行评估后,GEMS 始终能够显著提升性能。最值得注意的是,它使轻量级 6B 模型 Z-Image-Turbo 在 GenEval2 上超越了最先进的 Nano Banana 2,证明了 Agent 框架在扩展模型功能方面超越其原始限制的有效性。
1.Introduction
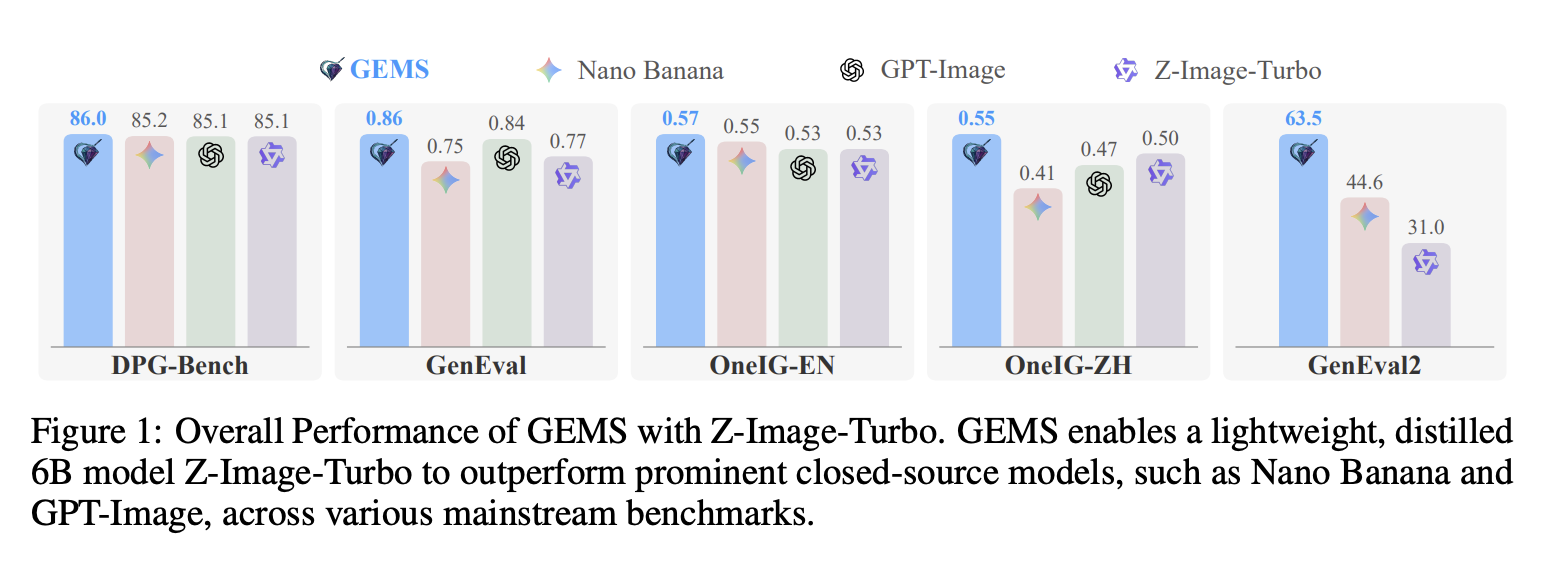
近年来,多模态图像生成技术经历了变革性的发展,先进的算法和架构设计显著提升了视觉合成的质量和易用性。诸如 GPT-Image 和 Nano Banana 等领先的闭源模型,以及 Qwen-Image 和 Z-Image 等知名的开源框架,在各种基准测试中都创造了新的最先进记录。这些模型在处理主流且简单的任务方面表现出色,能够持续生成与通用文本提示高度吻合的高保真结果。尽管取得了这些成就,但它们在处理复杂、多方面的指令或专门的下游应用时往往力不从心,这构成了持续存在的“长尾”挑战,即通用能力达到极限的情况。
为了弥合这些差距,推理时扩展已成为提升模型性能的关键策略。目前的研究主要集中于迭代优化循环或多智能体协作系统,以应对复杂任务。同时,针对特定下游领域(例如创意绘画和学术插图)也开发了专门的多智能体框架,以提供领域特定的优化。然而,现有的多智能体系统面临着一些关键的局限性。例如,Maestro 等框架依赖于连续的单步更新,而许多迭代方法只是简单地积累历史上下文,导致指导不足或信息冗余过多。另一方面,虽然针对特定下游任务优化的系统在局部取得了成功,但由于其特殊的协调机制,它们通常难以与主流的生成式流程集成,从而导致架构碎片化且适应性较差。
受 Claude Code 和 OpenClaw 等开创性智能体框架近期突破性进展的启发,我们提出了 GEMS (Agent-Native Multimodal GEneration with Memory and Skills),该框架从创新的智能体视角进行了重新设计。GEMS 的架构旨在通过三大核心支柱克服复杂指令和专门下游任务的局限性:(1)Agent Loop,引入结构化的多智能体框架,通过闭环优化迭代地提高生成质量,从而确保在复杂任务上实现高保真性能;(2)Agent Memory,一种持久机制,与简单的上下文累积或连续的单步更新不同,它维护优化轨迹的全局记录,同时利用分层压缩来保留事实信息并提炼高级经验,从而有效消除信息冗余并提高迭代改进的整体质量;(3)Agent Skill,是一个可扩展的领域特定专业知识库,它通过采用按需加载和渐进式暴露机制来解决孤立任务特定系统碎片化的问题,从而最大限度地提高可扩展性并最大限度地降低认知负荷,使系统能够有效地处理各种下游任务。通过集成这些组件,GEMS 超越了传统迭代循环的限制,为复杂的指令和下游任务提供了一个更具可扩展性和智能性的解决方案。
为了验证 GEMS 的有效性,我们针对九项不同的任务进行了广泛的实验,其中包括五项具有挑战性的主流基准测试(例如 GenEval2)和四项涵盖不同领域的专业下游任务。我们的框架在多个生成后端上验证了其泛化能力。具体而言,利用轻量级的精简版 Z-Image-Turbo,GEMS 在主流基准测试和下游任务上分别取得了平均 14.22 和 14.03 的显著性能提升。最值得注意的是,我们的框架使 6B Z-Image-Turbo 在 GenEval2 上超越了目前最先进的 Nano Banana 2,这表明智能推理和领域特定专业知识可以有效地突破基础模型的固有局限。我们还在另一个主流开源模型 Qwen-Image-2512 上验证了我们的框架,该模型在主流任务和下游任务上分别取得了平均16.24和7.96的性能提升。这些结果凸显了我们的智能体系统在不同模型架构和规模下的强大通用性和可扩展性。
总而言之,我们的主要贡献如下:
- 我们提出了 GEMS,这是一个智能体原生多模态生成框架,它采用迭代改进来显著提高复杂生成任务的性能。
- 我们引入了一种利用分层压缩的持久 Agent Memory 机制,该机制能够有效地管理多轮优化轨迹中的历史上下文。
- 我们开发了一个可扩展的 Agent Skill 模块,利用高效的按需加载,为系统配备特定领域的专业知识,以用于专门的下游应用程序。
- 针对九项不同任务的大量实验验证了 GEMS 的有效性,突显了智能体框架在多模态生成方面的变革潜力。
2.Related Works
2.1 Inference-Time Scaling for Multimodal Generation
近年来,多模态生成领域取得了显著进展,推理时扩展已成为一种极具前景的性能提升策略。早期方法主要依赖于简单的提示重写或随机搜索来优化生成。其他方法引入了思维链(CoT)推理,为多模态生成提供更多指导。更先进的方法则采用迭代优化循环来逐步优化结果。近期研究也探索了多智能体系统。一些方法利用多智能体协作和迭代优化来增强复杂任务的生成过程,但仍局限于基本的智能体循环。另一些研究则专注于针对特定下游任务的定制化设计,但通常难以与主流的生成式工作流程集成。相比之下,GEMS 采用了先进的智能体范式来克服这些局限性。
2.2 Agent Systems
智能体系统作为自主框架,通过结构化的规划和交互扩展了 LLM 的推理和执行能力。基础性工作建立了智能体循环,使模型能够在自我纠错的循环中交替进行推理和行动。在此基础上,多智能体系统采用专门的角色,通过通信协议进行协作,以应对更为复杂的目标。此外,Agent Memory 的集成增强了系统在长上下文和多轮交互中的性能。最近,Agent Skill 进一步拓展了智能体系统的边界,使其能够通过特定领域的工作流程执行复杂任务。基于这些能力,诸如 Claude Code 和 OpenClaw 等最先进的智能体系统在执行复杂的现实世界操作方面展现了卓越的能力,这启发我们将这些智能体范式应用于多模态生成。
3.Method
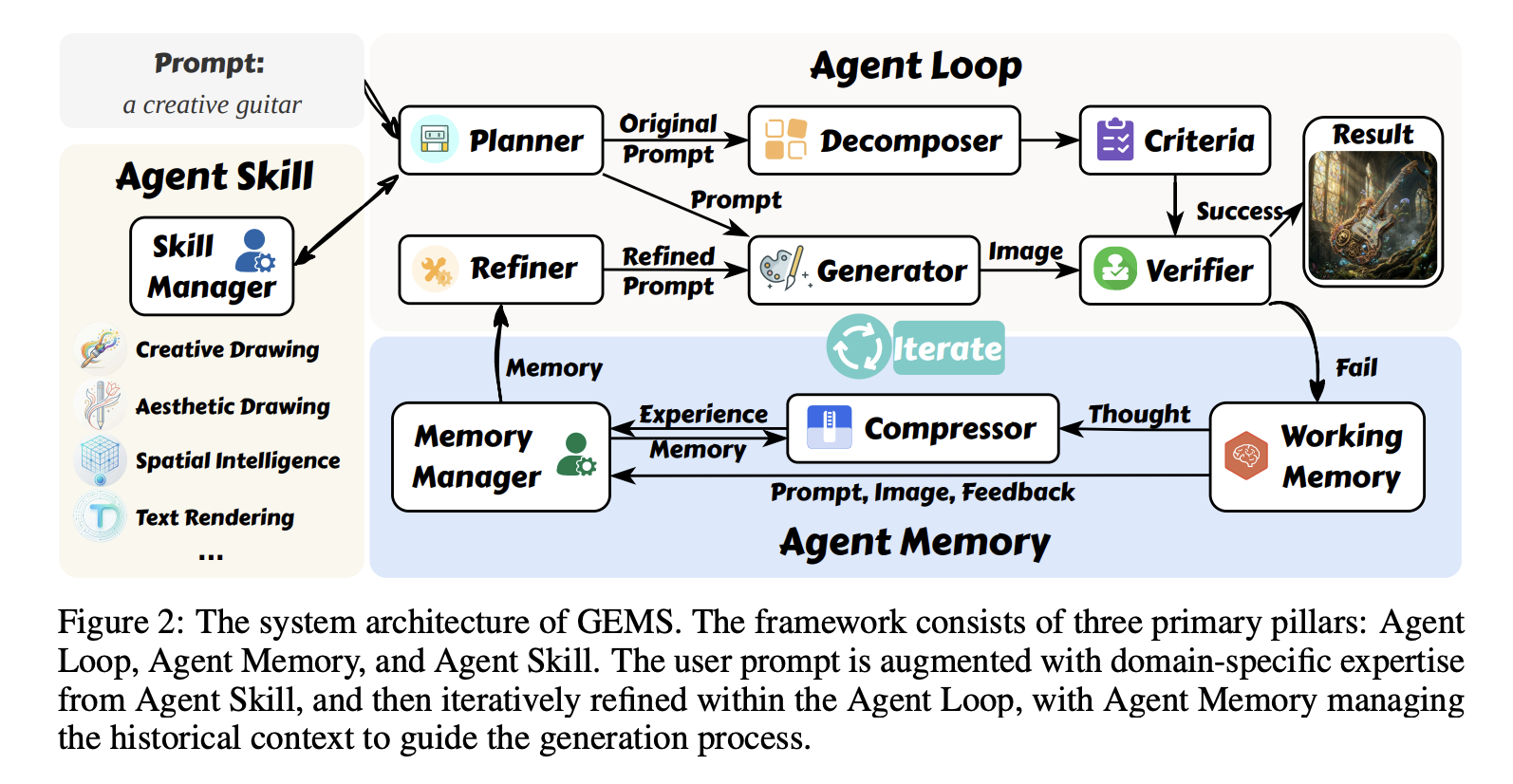
如图 2 所示,GEMS 由三个核心组件构成:Agent Loop、Agent Memory 和 Agent Skill。这些模块协同工作,以应对复杂指令执行和特定下游任务的挑战。以下各小节将详细介绍每个组件。
3.1 Agent Loop
Agent Loop 是 GEMS 的骨干,由几个协作模块组成:规划器、分解器、生成器、验证器和精炼器。
Planner。规划器(记为 Fplan\mathcal F_{plan}Fplan)是系统的战略入口点。它首先与 Skill Manager 交互,根据用户提示 UUU 从领域特定知识库 S\mathcal SS(第 3.3 节)中识别相关专业知识。此交互会检索已触发技能的子集 Strig⊆S\mathcal S_{trig} ⊆ \mathcal SStrig⊆S;如果任务不属于任何专业领域,则 Strig\mathcal S_{trig}Strig 为空。规划器利用检索到的技能(如有),合成一个增强的初始提示 P1P_1P1,旨在为生成过程提供更优的指导。同时,它将原始提示 UUU 发送给分解器,以建立基础评估框架。该操作定义如下:
(P1,U)=Fplan(U,S).(1)(P_1, U)=\mathcal F_{plan}(U, \mathcal S).\tag{1}(P1,U)=Fplan(U,S).(1)
Decomposer。为了确保细粒度的评估,分解器 Fdec\mathcal F_{dec}Fdec 将用户的原始提示 UUU 分解为一组原子视觉需求 C={c1,c2,...,cn}\mathcal C = \{c_1, c_2, . . . , c_n\}C={c1,c2,...,cn}。每个标准 cjc_jcj 都被表述为一个二元(是/否)探测,代表一个重要的语义或结构约束:
C=Fdec(U).(2)\mathcal C=\mathcal F_{dec}(U).\tag{2}C=Fdec(U).(2)
Generator。生成器 Fgen\mathcal F_{gen}Fgen 是一个与模型无关的模块,负责合成视觉输出。在每次迭代 iii 中,它根据当前优化的提示 PiP_iPi 生成图像 IiI_iIi:
Ii=Fgen(Pi).(3)I_i=\mathcal F_{gen}(P_i).\tag{3}Ii=Fgen(Pi).(3)
Verifier。验证器 Fver\mathcal F_{ver}Fver 由多模态大语言模型 (MLLM) 驱动,它根据预定义的原子标准集 C\mathcal CC 评估生成的图像 IiI_iIi。它将视觉和文本输入映射到二进制反馈向量 Vi={vi,1,...,vi,n}V_i = \{v_{i,1}, . . . , v_{i,n}\}Vi={vi,1,...,vi,n}:
Vi=Fver(Ii,C),vi,j∈{0,1}.(4)V_i=\mathcal F_{ver}(I_i,\mathcal C),\quad v_{i,j}\in \{0,1\}.\tag{4}Vi=Fver(Ii,C),vi,j∈{0,1}.(4)
系统随后根据 ViV_iVi 的结果执行条件分支。如果所有条件都满足(即,∀j,vi,j=1∀j, v_{i,j} = 1∀j,vi,j=1),则迭代循环终止,并将 IiI_iIi 作为最终输出返回。如果任何条件未满足,且当前迭代次数 iii 低于最大值 NmaxN_{max}Nmax,则将向量 ViV_iVi 作为诊断反馈发送给 Refiner。但是,如果系统在未满足所有条件的情况下达到 NmaxN_{max}Nmax,则会对优化轨迹进行全局评估,并返回满足最多条件的图像 IbestI_{best}Ibest:
Ibest=argmaxIk∑j=1nvk,j,k∈{1,...,Nmax}.(5)I_{best}=\mathop{argmax}\limits_{I_k}\sum^n_{j=1}v_{k,j},\quad k\in\{1,...,N_{max}\}.\tag{5}Ibest=Ikargmaxj=1∑nvk,j,k∈{1,...,Nmax}.(5)
Refiner。精炼器 Fref\mathcal F_{ref}Fref 通过闭合反馈回路来促进提示演化。在第 iii 次迭代中,它通过分析当前状态和历史上下文来合成一个精炼后的提示 Pi+1P_{i+1}Pi+1。关键在于,Mi−1M_{i−1}Mi−1 代表了在第 i−1i−1i−1 次迭代结束时 Agent Memory 的状态,它概括了先前尝试的累积轨迹。精炼器将当前提示 PiP_iPi、生成的图像 IiI_iIi、验证反馈 ViV_iVi 和内部推理 TiT_iTi(反映了 MLLM 在精炼过程中的思考过程)与历史状态 Mi−1M_{i−1}Mi−1 相结合,从而推导出下一轮提示:
Pi+1=Fref(Pi,Ii,Vi,Ti,Mi−1).(6)P_{i+1}=\mathcal F_{ref}(P_i,I_i,V_i,T_i,\mathcal M_{i-1}).\tag{6}Pi+1=Fref(Pi,Ii,Vi,Ti,Mi−1).(6)
3.2 Agent Memory
以往的多模态智能体系统,例如 Maestro,往往采用一种演化式设计,只关注紧邻上一步的结果或当前表现最优的状态,而缺乏对整个生成过程的完整历史视角。为突破这种简单逐步更新方式的局限,我们实现了一种持久化记忆机制,用于维护优化轨迹的全局记录。为了同时兼顾信息密度与 token 效率,我们提出了一种 Hierarchical Compression(层次化压缩)策略来管理历史上下文。具体而言,我们将迭代状态划分为两个不同层级。具有最小 token 开销的事实性产物,例如提示词 PiP_iPi、生成图像 IiI_iIi 以及验证反馈 ViV_iVi,作为可靠且客观的数据点,以原始形式归档保存,以确保历史准确性。相对地,推理轨迹 TiT_iTi 往往冗长且存在冗余,因此会由一个 Compressor Fcomp\mathcal{F}_{comp}Fcomp 进行处理,将其提炼为简洁的高层经验 EiE_iEi:
Ei=Fcomp(Pi,Ii,Vi,Ti,Mi−1).(7) E_i = \mathcal{F}_{comp}(P_i, I_i, V_i, T_i, \mathcal{M}_{i-1}). \tag{7} Ei=Fcomp(Pi,Ii,Vi,Ti,Mi−1).(7)
随后,得到的记忆状态 Mi\mathcal{M}_iMi 会被更新为这些混合状态元组构成的序列,从而确保系统同时保留事实锚点与策略性反思:
Mi=(P1,I1,V1,E1),…,(Pi,Ii,Vi,Ei).(8) \mathcal{M}_i = {(P_1, I_1, V_1, E_1), \ldots, (P_i, I_i, V_i, E_i)}. \tag{8} Mi=(P1,I1,V1,E1),…,(Pi,Ii,Vi,Ei).(8)
通过归档这种层次化压缩后的表示,系统在提供整个生成轨迹的稳健长上下文视角给 Refiner 的同时,也消除了信息噪声。
3.3 Agent Skill
传统的智能体系统在下游应用中通常依赖面向特定任务的实现方式;然而,这类专用化设计很难与主流生成式流水线相集成,从而导致系统架构割裂,且适应性较差。为了解决这些局限并提升下游性能,我们引入了 Agent Skill 模块——一个领域专长的知识库,使系统能够突破通用能力的限制。Planner 在流水线初始阶段与该模块交互,将用户意图与专门技能进行匹配,在迭代循环开始前获得增强后的 prompt。
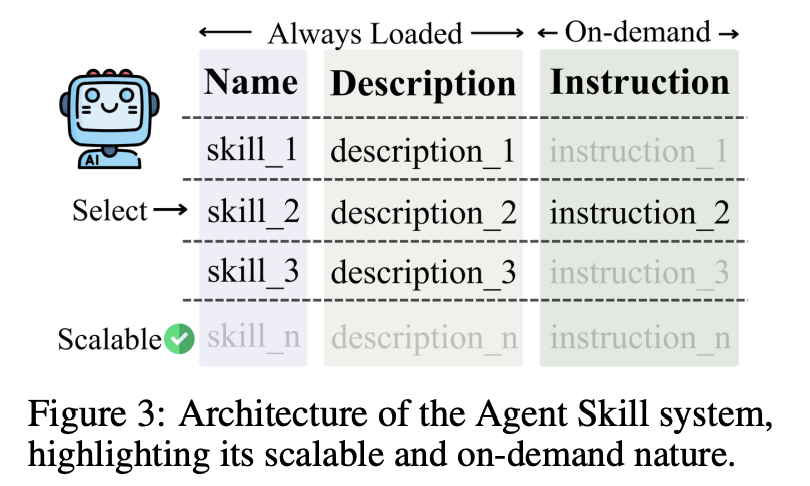
如图 3 所示,我们的系统采用了一种**按需加载(on-demand loading)与渐进式暴露(progressive exposure)**机制。为了保证 token 效率,技能的名称和描述会作为轻量级清单被“始终加载(always loaded)”。而包含高密度领域知识的完整指令,则仅在某项具体技能被触发时才会被获取。这样的设计直接带来了更高的可扩展性与更好的用户友好性。
由于详细指令只在必要时加载,系统能够支持大规模的专业知识库,而不会给推理过程带来显著的计算负担或认知负担。此外,这也显著降低了贡献门槛;用户无需理解系统完整的底层运行逻辑。只需提供一个概述相关信息的 markdown 文件(例如 SKILL.md),系统便能够自动理解并激活新技能,从而帮助用户以显著更高的保真度和领域精度生成任意内容。这种模块化设计确保系统在面对日益多样化的需求时,依然保持可访问性与适应性。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐


 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)