
WorkBuddy 最强 Skill 来了!智囊团三件套:GPT-5.5、Claude、DeepSeek、GLM 同时帮你干活
小编用了一周,回不去了。真的,一个模型干活太慢了。

你为什么需要多模型?
你有没有想过——你每次打开 WorkBuddy,默认用的是哪个模型?
那个模型,就是你的认知天花板。
不是它不够好。是任何单一模型都有结构性的盲区。GPT-5.5 广度无敌但不够严谨,Claude 严谨但偏保守,DeepSeek V4 Pro 深度强但视角单一,GLM 5.2 逻辑清晰但创意不足,千问均衡但缺乏惊艳。
你让同一个大脑回答所有问题,就像让同一个人做 CEO + CTO + CFO——可以,但不是最优解。
一个人的聪明是单线程的,一群人的智慧是网状的。多模型协作不是在选"最好的答案"——是在编织一张你的单模型永远织不出的思维导图。
那有没有一种可能——你说一句话,GPT-5.5 + Claude + DeepSeek V4 Pro + GLM 5.2 四个顶级模型同时开跑,各自从不同的优势角度给出答案,然后自动整合成一份完整的结构化报告?
有。这就是智囊团。
一张图你就能看懂(这只是其中一种好处,缩短时间。当然还有很多好处:分开合作,高端烧钱快,基础任务不给高端干,大幅减少高端烧的钱;还有对比优势等)
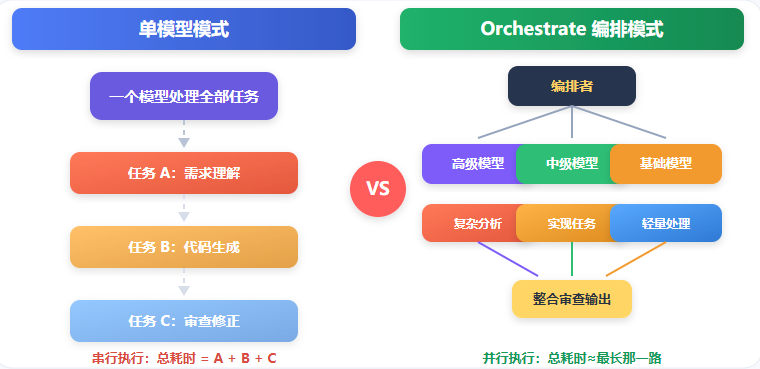
🧠 智囊团怎么工作?
智囊团把模型按能力分成三个 tier,各司其职。这不是随便分——你不会让实习生做架构决策,也不会让架构师去整理表格。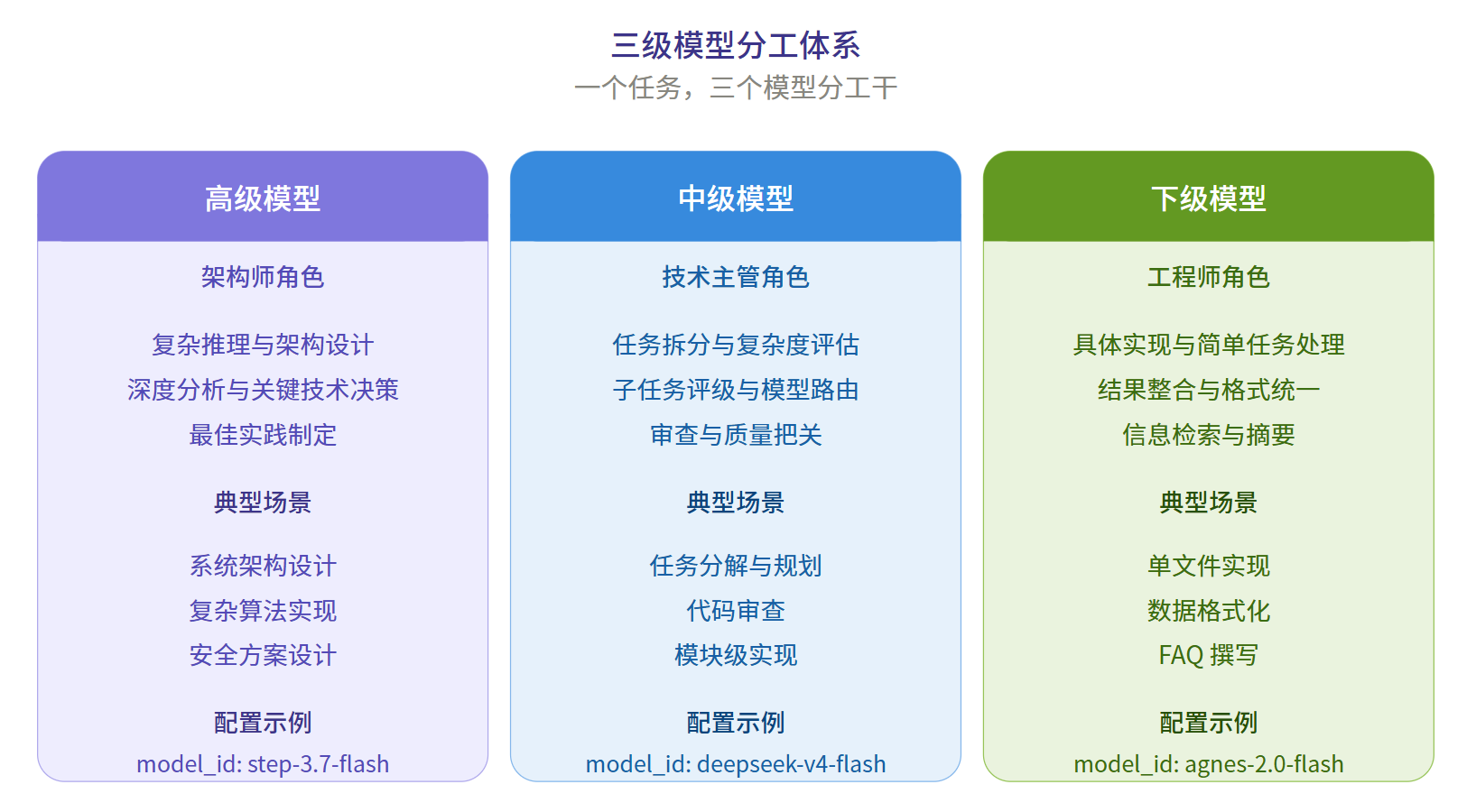
| Tier | 角色 | 代表模型 | 负责 |
|---|---|---|---|
| 🚀 高级 | 架构师 | GPT-5.5、Claude Opus 4.8 | 拆解任务、复杂推理、最终聚合 |
| 💡 中级 | 主工程师 | DeepSeek V4 Pro、GLM 5.2 | 中等难度子任务执行 |
| ⚡ 基础 | 助理 | 千问、StepFun、Agnes AI | 简单查询、格式化、对比整理 |
三种模式,各有所长

模式 1:并行智囊(最快,10-30 秒)
你:智囊团,并行分析 LRU 缓存的三个实现方案 它: GPT-5.5 → 方案 A 分析(广度视角) Claude → 方案 B 分析(严谨视角) ← 四个同时跑! DeepSeek → 方案 C 分析(深度视角) GLM 5.2 → 方案 D 比较(逻辑视角)
四份独立分析,同一个问题你能看到四种不同的思维方式。
模式 2:管道接力
你:智囊团管道,GPT-5.5 拆需求 → DeepSeek 设计方案 → Claude 审查 它: [1/3] GPT-5.5 需求分析 ✅ [2/3] DeepSeek 方案设计 ✅(拿到上一步的输出了) [3/3] Claude 质量审查 ✅(层层精炼)
每个阶段用最适合的模型,上一个的输出喂给下一个。这不叫"串联",这叫逐级放大招。
模式 3:完整智囊团(最强,60-90 秒)
你:智囊团,全面分析纳米弥散增强铝基复合材料的应用前景 它: [1/3] GPT-5.5 拆解任务 ✅ → 3 个子任务 [2/3] 并行执行: Claude → 材料性能深度解读 (25s) DeepSeek V4 Pro → 工艺难点识别 (33s) ← 三个同时跑! GLM 5.2 → 对比分析 (47s) [3/3] GPT-5.5 聚合为结构化报告 ✅ 总耗时 76 秒
一份包含五个章节、两个对比表、工程化建议的结构化报告。
你要是手动做——先问 GPT、复制回答、再问 Claude、再问 DeepSeek、再问 GLM、最后自己整合——半小时起步。还不一定有这种交叉验证的深度。
🔄 完整工作流
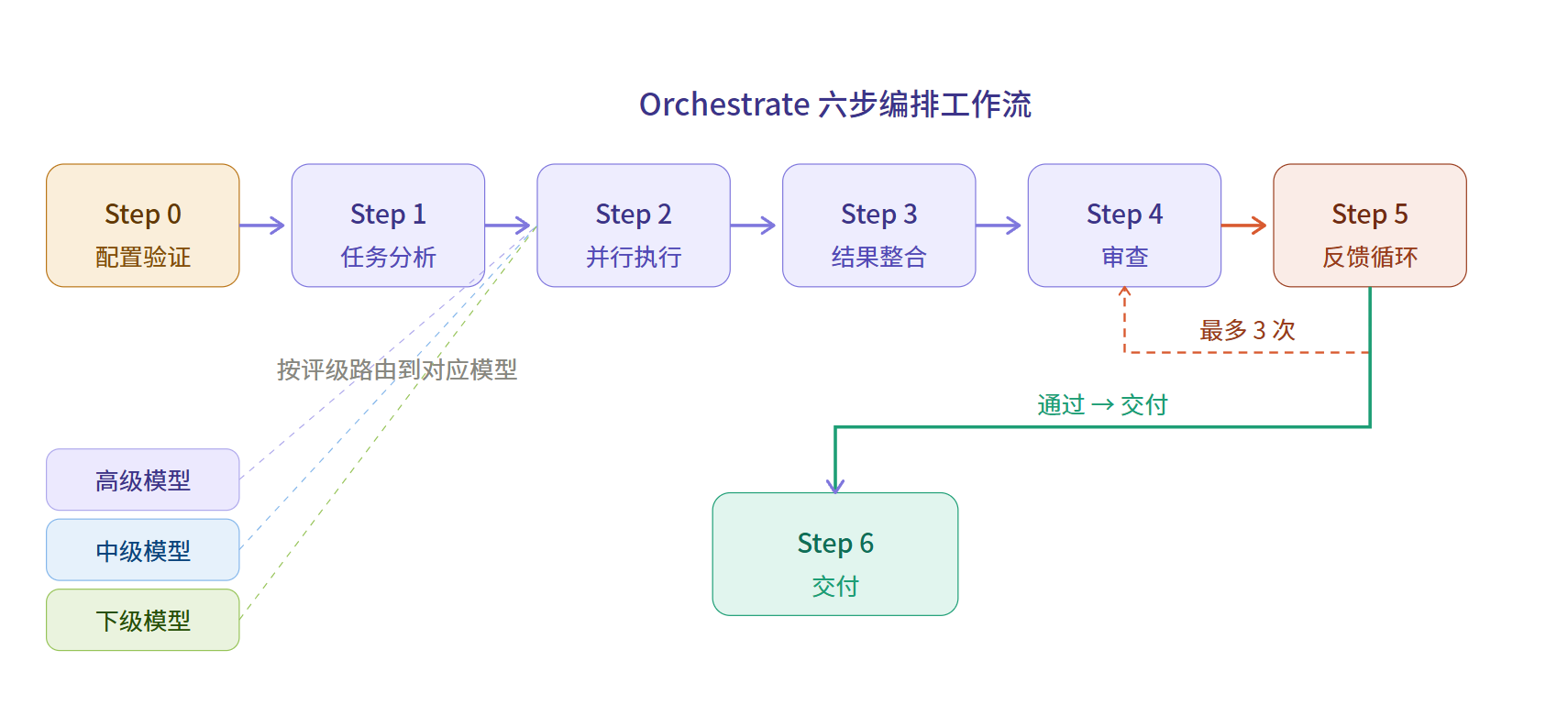
拆解 → 并行 → 聚合,三步出结果。失败自动换备胎,你根本感知不到。
为什么比单模型强?
1. 偏见互相抵消
GPT-5.5 偏向广度,Claude 偏向安全,DeepSeek 偏向深度,GLM 偏向逻辑。
同一个问题分别回答,你会发现:
-
GPT-5.5 看到了你没想到的关联
-
Claude 发现了你忽略的风险
-
DeepSeek 挖出了你没注意的细节
-
GLM 理出了你没整理好的逻辑链
四个视角叠加,任何单模型都不可能同时做到。
2. 不怕模型崩
四个里崩一个不影响整体。Skill 自动切换到同级别的备胎重试——你根本无感。
3. 真并行,不是排队
ThreadPoolExecutor 真并行——四个模型同时调 API,互不阻塞。30-90 秒出完整报告,而不是等一个完了再等下一个。
三兄弟各司其职
这个 Skill 包里其实包含三个独立 Skill,定位完全不同:
| 🧠 智囊团 | 🪶 轻装智囊 | 👥 分身协作 | |
|---|---|---|---|
| 干什么 | 多模型分析推理 | 同上,零依赖 | Agent 代码生成 |
| 依赖 | pip install openai |
pip install requests |
无(纯 Agent) |
| 速度 | 30-90s | 30-90s | 5-10min |
| 产出 | 结构化报告 | 结构化报告 | 代码文件 |
| 适合 | 日常分析推理 | Docker/服务器/离线 | 写前后端代码 |
轻装智囊是零依赖版——不装 openai、langchain 等任何 AI 库,只靠 requests 库裸调 API。适合安全审计和 Docker 环境。
分身协作是 Agent 版——spawn WorkBuddy Agent 分身来真的写代码。虽然慢,但它是唯一能生成代码文件的。
怎么装?就两步
1. 下载 Skill 包(解压到 ~/.workbuddy/skills/) 2. 重启 WorkBuddy → 说「智囊团」触发配置向导
配置向导会自动从你的 models.json 读取已配置的模型,帮你选平台、分 tier。30 秒搞定。
之后在 WorkBuddy 里直接说:
| 你要什么 | 就说 |
|---|---|
| 多角度深度分析 | 「智囊团,分析 xxx」 |
| 四个模型同时回答 | 「并行对比 xxx」 |
| GPT 拆 → DS 写方案 → Claude 审查 | 「管道接力……」 |
| 开发多模块项目 | 「分身,帮我写 xxx」 |
适合谁?
-
📝 写论文/报告的人:一个课题从四个角度透视,文献综述直接生成。每个角度都有模型自身的思维优势
-
🔬 做技术调研的人:方案对比不再是"我觉得 A 好",而是 GPT-5.5 + Claude + DeepSeek + GLM 的交叉验证报告
-
💻 独立开发者:分身协作帮你同时写前后端——真正的并行开发
-
🎓 学生/研究者:复杂概念让四个顶级模型各讲一遍,比任何单一教科书都全面
-
🏢 技术管理者:做技术决策前,让四个模型同时给方案,比较优劣,避免盲区
下载
智囊团系列 Skill 包 → GitHub 下载
解压即用。拿走点个小星星,感谢啦!
小编说
我用完之后最直观的感受——不是"多了一个工具",而是思维方式变了。
以前遇到复杂问题,习惯性地问一个模型、看一个答案、自己琢磨。
现在第一反应是"让四个模型一起看看这件事"。
你不用选哪个模型最好,你让它们全上。GPT-5.5 的广度 + Claude 的严谨 + DeepSeek 的深度 + GLM 的逻辑——就像把四个不同领域的专家关在一个会议室里,让他们从各自的角度分析你的问题,然后交给你一份共识报告。
这种感觉,试一次就能明白为什么多模型协作是下一代 AI 工作方式。
评论区告诉我:你最想让 GPT-5.5 + Claude + DeepSeek V4 Pro + GLM 5.2 这四个人一起分析什么?
tips:如果没有高端模型,拿任意几个模型用也可以!可以对比一下单模型!

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐
 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)