




- @qq_28385535
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
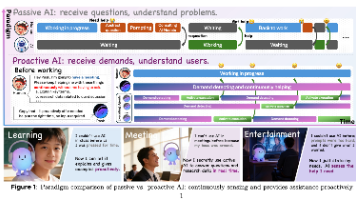
主动性是通用人工智能(AGI)的核心期望。以往的研究大多局限于实验室环境,在现实世界的主动智能体方面存在明显的不足:深度、复杂性、模糊性、精确性和实时性等约束。我们研究了这一场景,其中有效的干预需要从持续的上下文中推断潜在需求,并在延迟和长期约束下,将行动建立在不断演变的用户记忆之上。我们首先提出 **DD-MM-PAS (Demand Detection, Memory Modeling, Pr
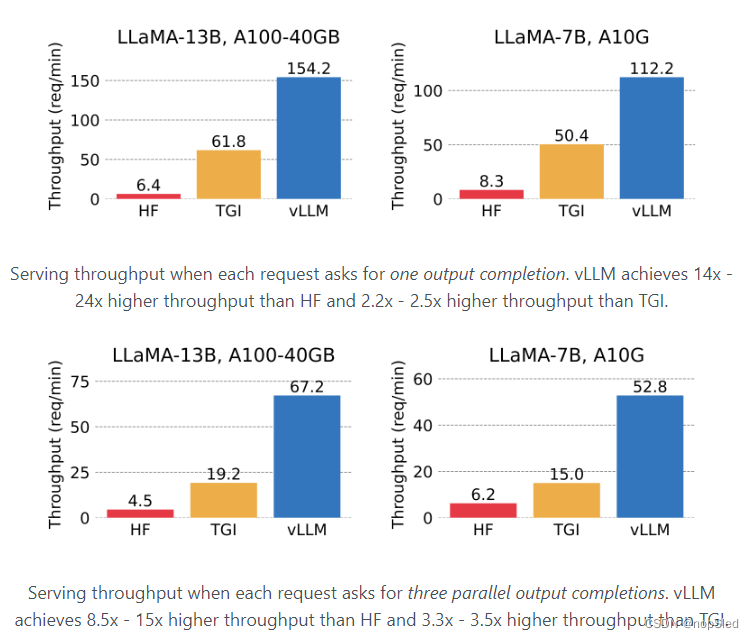
LLMS从根本上改变了我们在所有行业中使用AI的方式。但是,实际上为这些模型提供服务是具有挑战性的,即使在昂贵的硬件上也可能会具有很慢的推理速度。今天,我们很高兴介绍vLLM,这是一个用于快速LLM推理和服务的开源库。vLLM利用了,这是我们能有效地管理注意力key和value的新的注意力算法。配备了PagedAttention的vLLM重新定义了LLM服务中的SOTA:它比HuggingFace
Muon 是一种用于神经网络隐藏层的优化器。它被用于 NanoGPT 和 CIFAR-10 速通的当前训练速度记录中。许多使用 Muon 的实证结果已经发表,因此本文将主要关注 Muon 的设计。首先,我们将定义 Muon,并概述其迄今为止取得的实证结果。然后,我们将详细讨论其设计,包括与先前研究的联系以及我们对它有效机制的最佳理解。最后,我们将讨论优化研究中的证据标准。

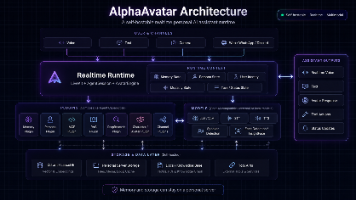
AlphaAvatar项目通过MCP(Multi-Cloud Platform)插件实现了实时Agent的工具统一管理和并行调度优化。在数字人和多模态系统中,传统串行工具调用方式面临性能退化、响应延迟等问题。MCP作为工具编排中间件,为Agent提供单一入口,内部实现工具发现、参数校验、并行执行和结果聚合功能。这种设计显著降低了LLM决策压力,减少了延迟,同时避免了工具列表膨胀污染上下文。项目采用
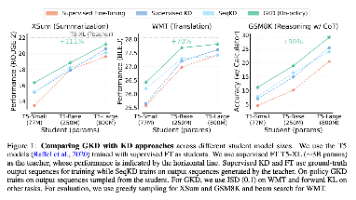
知识蒸馏(KD)广泛用于压缩 teacher 模型,通过训练一个更小的 student 模型来降低其推理成本和内存占用。然而,目前针对自回归序列模型的 KD 方法存在一个问题:**训练过程中观察到的输出序列与学生在推理过程中生成的输出序列之间存在分布不匹配**。为了解决这个问题,我们提出了 Generalized Knowledge Distillation (GKD)。GKD 并非仅仅依赖于一组
AlphaAvatar 是一个开源、可自托管的实时全模态个人 AI 助手运行时,目标是从传统的无状态聊天机器人,演进为能够长期理解和协助用户的个人 AI 管家。
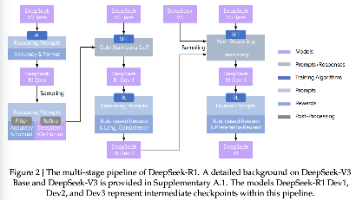
通用推理一直是人工智能领域长期存在的艰巨挑战。近年来,以大语言模型(LLM)和思维链提示为代表的突破性进展,在基础推理任务上取得了显著成效。然而,这些成功很大程度上依赖于大量的人工标注示例,模型的能力对于更复杂的问题仍然不足。本文表明,可以通过纯强化学习(RL)激励 LLM 的推理能力,从而无需人工标注推理轨迹。所提出的 RL 框架促进了高级推理模式的涌现式发展,例如自我反思、验证和动态策略适应。
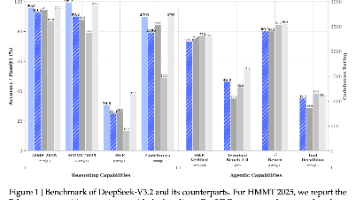
我们推出了 DeepSeek-V3.2 模型,该模型兼顾了高计算效率、卓越的推理能力和智能体性能。DeepSeek-V3.2 的关键技术突破如下:(1) **DeepSeek Sparse Attention (DSA)**:我们引入了 DSA,这是一种高效的注意力机制,能够在长上下文场景下显著降低计算复杂度,同时保持模型性能。(2) **Scalable Reinforcement Learni
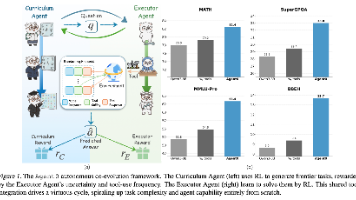
大语言模型(LLM)智能体通常使用强化学习(RL)进行训练,但由于依赖人工整理的数据,其可扩展性受到限制,并将人工智能束缚于人类知识。现有的自进化框架提供了一种替代方案,但通常受限于模型的固有能力和单轮交互,阻碍了涉及工具使用或动态推理的复杂课程的开发。我们提出了 **Agent0**,这是一个完全自主的框架,它通过多步协同进化和无缝工具集成,在无需外部数据的情况下进化出高性能智能体。Agent0
人工智能辅助研究正跨越一个重要的门槛:全自动系统现在只需 15 美元即可生成研究论文,而长周期智能体只需极少的人工干预即可执行实验、撰写论文初稿并模拟评论。然而,这种生产力的飞跃也暴露出一个更深层次的诚信问题:在科学压力下,即使是最先进的长周期智能体仍然会捏造结果、忽略隐藏的错误,并且无法可靠地判断创新性。本文研究了截至2026年4月的发展情况,并对人工智能在整个研究生命周期中的作用进行了端到端的
