
从 Function Calling 到 MCP:Agent 工具调用的三层境界与生产级安全护栏
前言
在 AI Agent 的演进里,如果 LLM 是“大脑”,那么工具(Tools)就是它的“手脚”。2023 年 Function Calling 的出现让 AI 从“能说”进化到了“能做”;2024 年底 MCP(Model Context Protocol)协议的发布,则标志着工具接入进入了标准化时代。
但真正做过生产级 Agent 的同学都知道:本地 Demo 里“调通一个工具”很爽,上了生产,翻车点却一个接一个——模型编造参数、把只读账号拿去执行了 DELETE、一次重试导致重复发货、上下文塞满后模型开始“忘记”该用哪个工具。
问题的根源在于:“调通工具”只是起点,“稳健、安全地调用”才是真正的工程挑战。
这篇文章会结合一线实践,把 Agent 工具调用拆成三个层次来讲清楚:Function Calling(意图)、MCP(协议)、Agent Skills(经验),并给出一套可直接落地的生产级安全护栏方案。所有核心环节都会配上可运行的代码。
一、背景或问题:工具调用为什么是 Agent 的命门
1.1 工具接入的碎片化之痛
在 MCP 出现之前,做 Agent 最让开发者头疼的往往不是模型能力,而是工具接入的碎片化。同样是“查数据库”这件事,在不同的 Agent 框架或 IDE 里,往往要写完全不同的适配代码:
| 框架/平台 | 工具定义方式 | 调用约定 |
|---|---|---|
| LangChain | @tool 装饰器 / BaseTool |
自有函数签名协议 |
| OpenAI Assistants | functions JSON |
Function Calling schema |
| Claude(Anthropic) | tools JSON |
自有 input_schema |
| 各类 IDE 插件 | 私有 RPC | 各自约定 |
结果就是:你为一个宿主写的工具,换个宿主基本要重写一遍。工具开发方和 Agent 开发方被“点对点的胶水代码”死死绑在一起。
1.2 一个更危险的误区:以为模型在“执行代码”
很多初学者一听到 Function Calling(函数调用),会下意识以为“模型调用了我的函数、执行了我的代码”。
事实完全不是这样。 在整个工具调用链路里,模型做的事情只有一件:生成一段“调用意图”——也就是告诉你“我想调用哪个工具、参数大概长这样”。它生成的是一段结构化的 JSON,而不是真的去跑你的代码。
真正的执行权、校验权和审计权,始终牢牢掌握在你的业务服务端手里。
模型只是“提议”,服务端才是“决策者”。这一点,是本文后面整套安全护栏体系的逻辑起点。
二、核心思路:工具调用的“三层境界”
开发者最容易混淆的,是把 Function Calling、MCP、Skills 这几个概念混为一谈。其实它们根本不在同一个抽象层级上,我们可以用“分层”来理解它们的关系。
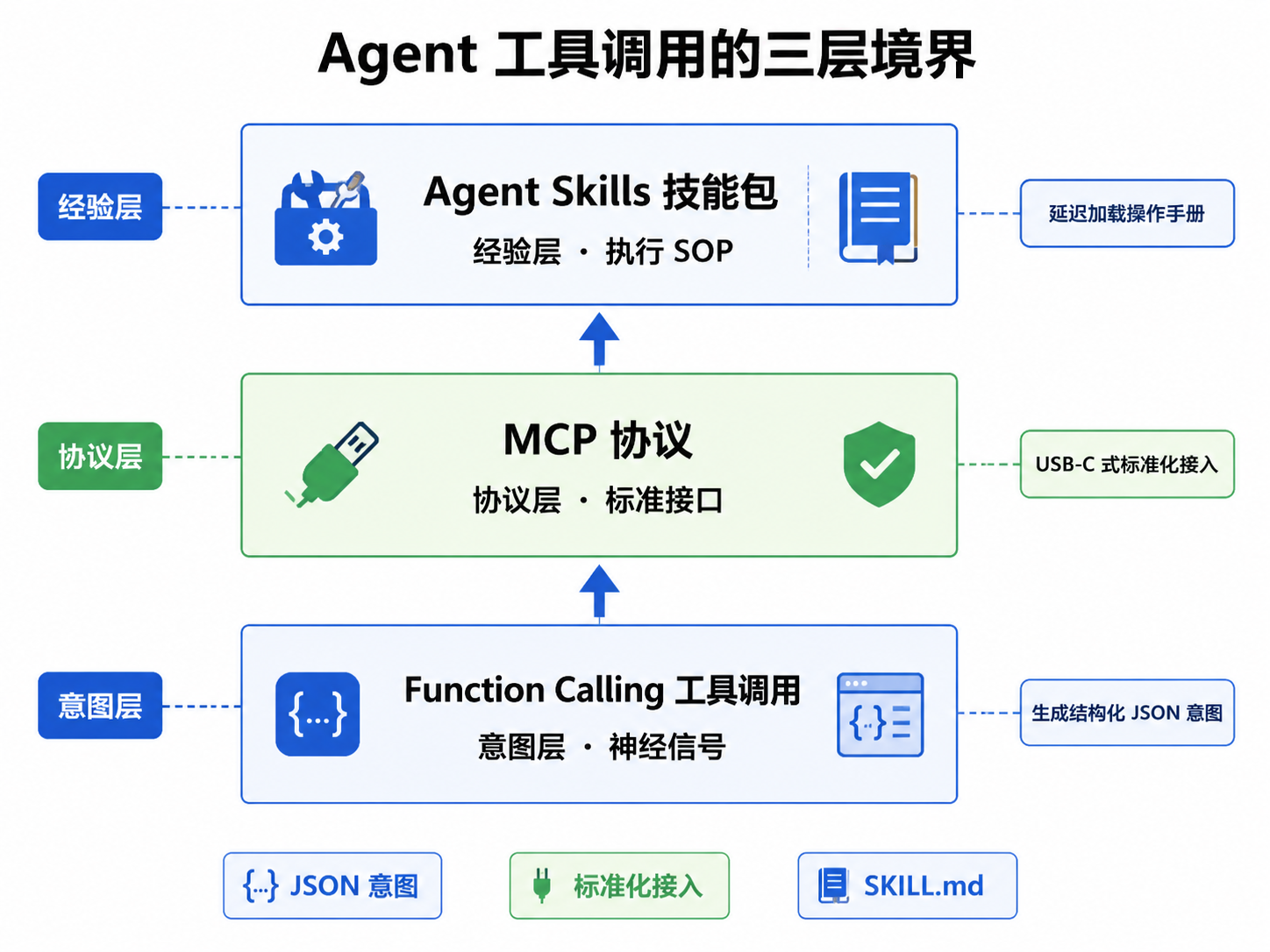
第一层:Function Calling —— 神经信号(意图层)
这是最底层、也是模型本身具备的能力。它表达的是“模型想调什么工具、参数是什么”。
必须明确三件事:
- 模型不直接执行代码,它只生成一份结构化的 JSON 意图;
- 执行权在业务服务端,由你决定要不要真跑;
- Function Calling 本身不解决标准化问题,不同厂商的 schema 格式并不互通。
一个典型的 Function Calling 意图长这样:
{
"tool": "refund_order",
"arguments": {
"orderId": 123,
"reason": "商品损坏"
}
}
注意:这只是一个“提议”。服务端完全可以基于业务规则拒绝它。
第二层:MCP 协议 —— 接口标准(协议层)
MCP 被称为 AI 领域的“USB-C 接口”。它解决的就是上一节说的碎片化问题,让工具开发(Server)与 Agent 开发(Client)彻底解耦。
关键认知:MCP 不替代 Function Calling,而是把它标准化。模型依然用 Function Calling 生成意图,但工具的发现、描述、接入方式,被 MCP 统一成了一份标准协议。你写一次 MCP Server,就能被任何支持 MCP 的宿主(Claude Desktop、各类 IDE、Agent 框架)直接调用。
第三层:Agent Skills —— 执行 SOP(经验层)
这是更高阶的“经验包”。它不仅包含“调用哪个工具”,还包含了完成某类任务的执行顺序、约束条件和反思逻辑。
一个 Skill 通常是一份延迟加载的操作手册(比如 SKILL.md):Agent 在启动时只看到它的名字和简短描述,只有当任务真正需要时,才把详细步骤加载进上下文。这样做的好处是——既沉淀了“怎么做”的经验,又不会一开始就撑爆上下文窗口。
三层境界的本质:Function Calling 解决“能不能表达意图”,MCP 解决“能不能标准化接入”,Skills 解决“能不能按 SOP 稳定执行”。
三、深度起底 MCP:如何实现“一次开发,处处调用”
3.1 Host-Client-Server 架构
MCP 的核心价值是解耦。它采用 Host-Client-Server 三段式架构:
| 角色 | 职责 | 举例 |
|---|---|---|
| Host(宿主) | 提供 Agent 运行环境,管理 Client 与用户会话 | Claude Desktop、Cursor、自研 Agent 应用 |
| Client(客户端) | 宿主内部的连接器,与单个 Server 保持 1:1 会话 | 宿主内为每个 Server 创建的连接实例 |
| Server(服务端) | 暴露具体的工具、资源、提示词能力 | 数据库 Server、GitHub Server、文件系统 Server |
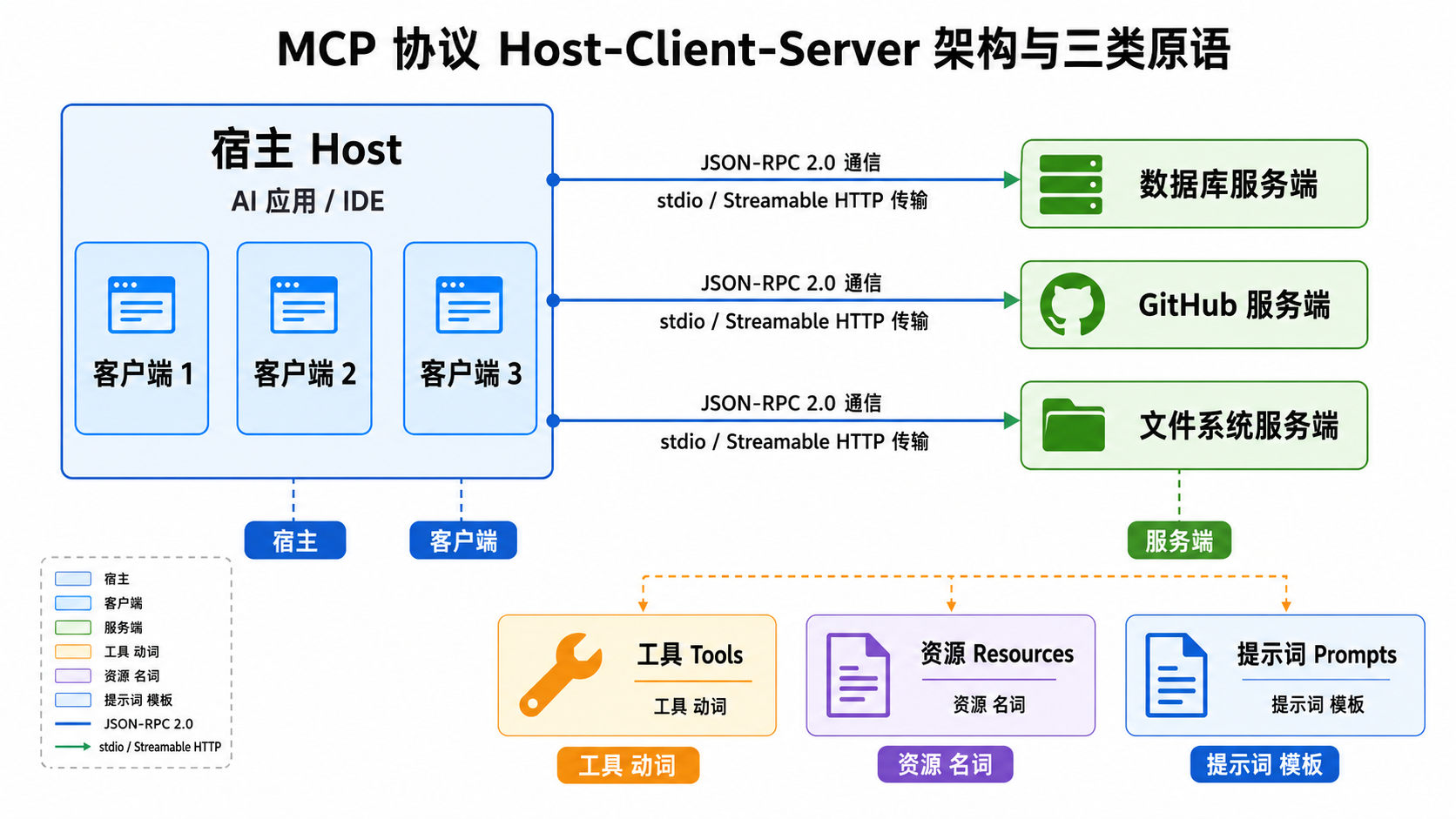
这套架构带来的直接收益是:工具提供方(Server)和 AI 应用(Host)之间,不再需要点对点的胶水代码。
3.2 三类标准原语:不仅仅是“工具”
MCP 定义了三类核心能力,共同构成了 Agent 的完整上下文环境。理解它们的分工,比记住几个 API 重要得多:
| 原语 | 类比 | 语义 | 典型例子 |
|---|---|---|---|
| Tools | 动词 | Agent 主动调用的函数,通常有副作用 | 发送邮件、执行 SQL、创建工单 |
| Resources | 名词 | Agent 按需读取的只读数据 | 本地文件、数据库 Schema、日志流 |
| Prompts | 形容词/模板 | 预定义的提示词模板 | “按团队规范做代码审查” |
一个常见误区是把所有能力都做成 Tools。更好的做法是:只读的上下文数据用 Resources,规范化的任务流程用 Prompts,真正会改变世界的动作才用 Tools。这能显著降低 Agent 误触发写操作的风险。
3.3 通信机制:基于 JSON-RPC 2.0
MCP 底层使用轻量、易调试的 JSON-RPC 2.0 协议。传输层有两种主流方式:
- 本地工具 → stdio:通过标准输入/输出连接,适合和宿主跑在同一台机器上的 Server;
- 远程服务 → Streamable HTTP:通过可流式传输的 HTTP 扩展,适合部署在远端的 Server。
这种设计让工具的部署非常灵活:本地脚本、容器化服务、云端 API 都能用同一套协议接入。
四、实现步骤:从一个最小 MCP Server 到生产级执行层
4.1 一个最小可运行的 MCP Server
下面用官方 Python SDK(mcp 包,FastMCP)写一个最小的数据库工具 Server。安装依赖:
pip install "mcp[cli]"
Server 代码:
# db_server.py —— 一个最小的 MCP Server
from mcp.server.fastmcp import FastMCP
mcp = FastMCP("db-tools")
@mcp.tool()
def query_user(user_id: int) -> dict:
"""根据用户 ID 查询用户基础信息。
使用场景:当需要获取用户姓名、注册时间等基础资料时使用。
禁用场景:不要用它查询订单或财务数据,请改用 query_order。
"""
# 模拟查库,实际项目替换为真实数据源
return {"user_id": user_id, "name": "张三", "created_at": "2025-01-01"}
@mcp.tool()
def query_order(order_id: int) -> dict:
"""根据订单 ID 查询订单状态。
使用场景:当需要查询订单的当前状态、金额时使用。
禁用场景:不要用于退款,退款请用 refund_order。
"""
return {"order_id": order_id, "status": "shipped", "amount": 199.0}
if __name__ == "__main__":
# 本地工具用 stdio 传输
mcp.run(transport="stdio")
把它接入 Claude Desktop(在配置文件里声明):
{
"mcpServers": {
"db-tools": {
"command": "python",
"args": ["/abs/path/to/db_server.py"]
}
}
}
重启宿主后,Agent 就能自动发现 query_user、query_order 这两个工具。这就是“一次开发,处处调用”。
4.2 工具描述(Description)是召回的命门
Agent 选不选得对工具,核心往往不在于模型智商,而在于你写的描述。在向量路由和模型推理中,description 扮演了“分流器”的角色。
反面教材:
@mcp.tool()
def query_sql(sql_string: str) -> list:
"""执行 SQL 语句"""
...
这种描述等于没写。Agent 在任何不确定的时刻都会想去“试一下”,因为它无法判断这个工具到底该什么时候用。
最佳实践:描述应同时包含使用场景和禁用场景。
@mcp.tool()
def query_slow_sql_index(sql_text: str) -> dict:
"""分析某条 SQL 的执行计划并给出索引优化建议。
使用场景:当用户查询慢 SQL 日志,且怀疑问题与数据库索引或执行计划相关时使用。
禁用场景:若慢查询疑似由网络延迟、内存不足或锁等待引起,请勿调用本工具,
改用 diagnose_infra 工具。
"""
...
一句话原则:好的工具描述,是在告诉模型“什么时候该来找我”,更是在告诉它“什么时候别来烦我”。
五、生产级安全护栏:别让模型替你做权限判断
“工具调用”是 Agent 风险最高的环节,尤其是涉及写操作时。一旦 Agent 拥有了“手脚”,风险也随之而来——不能默认信任模型传来的参数,更不能让模型替你做权限判断。
进入生产环境前,一套成熟的工具执行层必须建立“六道关卡”。
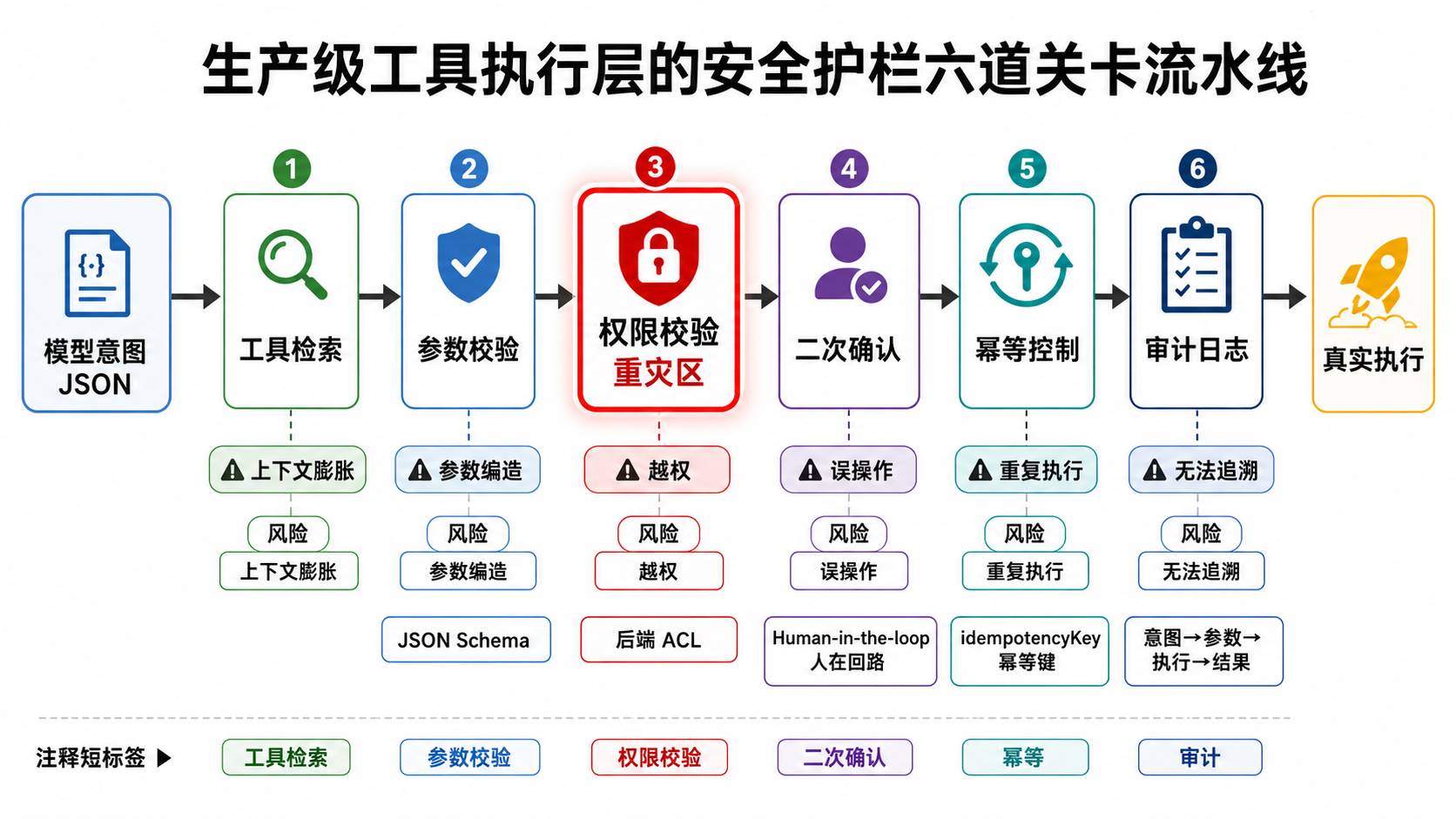
六道关卡一览
| 关卡 | 作用 | 不做的后果 |
|---|---|---|
| ① 工具检索 | 从海量库中选出当前相关的少数工具 | 上下文膨胀,模型迷失(Lost in the Middle) |
| ② 参数校验 | 用 JSON Schema 强类型校验 | 模型编造参数、类型错位,直接打挂下游 |
| ③ 权限校验 | 后端强制执行 ACL | 重灾区:越权读写、数据泄露 |
| ④ 二次确认 | 高风险写操作中断,等待人工确认 | 误删数据、误转账、误发邮件 |
| ⑤ 幂等控制 | 写操作携带 idempotencyKey | 重试导致重复扣费、重复发货 |
| ⑥ 审计日志 | 记录意图、参数、执行 SQL/API、结果 | 出了事故无法追溯 |
一段可运行的安全执行层(Python)
下面的代码把六道关卡串成一条执行流水线,重点突出“权限校验在后端强制执行”“高风险操作二次确认”“写操作幂等”这几个最容易出事的地方:
# safe_dispatcher.py —— 生产级工具执行层(示意,可运行骨架)
from __future__ import annotations
import json
import time
import hashlib
from dataclasses import dataclass, field
from typing import Any
# 风险等级
RISK_READ = "READ"
RISK_WRITE_LOW = "WRITE_LOW_RISK"
RISK_WRITE_HIGH = "WRITE_HIGH_RISK"
# 关卡①:工具注册表(含 schema、风险等级、所需权限)
TOOL_REGISTRY: dict[str, dict] = {
"query_order": {
"risk": RISK_READ,
"required_perm": "order:read",
"param_schema": {"order_id": "int"},
},
"refund_order": {
"risk": RISK_WRITE_HIGH,
"required_perm": "order:refund",
"param_schema": {"order_id": "int", "reason": "str"},
},
}
# 关卡⑥:审计日志(生产环境替换为持久化存储)
AUDIT_LOG: list[dict] = []
# 关卡⑤:幂等缓存(生产环境替换为 Redis)
IDEMPOTENCY_CACHE: dict[str, Any] = {}
@dataclass
class CurrentUser:
user_id: str
permissions: set[str] = field(default_factory=set)
def _audit(record: dict) -> None:
record["ts"] = time.time()
AUDIT_LOG.append(record)
print(f"[AUDIT] {json.dumps(record, ensure_ascii=False)}")
def dispatch_tool(
tool_name: str,
arguments: dict,
user: CurrentUser,
idempotency_key: str | None = None,
) -> dict:
"""统一工具分发入口,串起六道关卡。"""
# —— 关卡① 工具检索:工具是否存在 ——
tool = TOOL_REGISTRY.get(tool_name)
if tool is None:
_audit({"event": "tool_not_found", "tool": tool_name, "user": user.user_id})
return {"ok": False, "error": f"未知工具: {tool_name}"}
# —— 关卡② 参数校验:按 schema 强类型校验 ——
for key, typ in tool["param_schema"].items():
if key not in arguments:
_audit({"event": "param_missing", "tool": tool_name, "key": key})
return {"ok": False, "error": f"缺少必填参数: {key}"}
# 简化的类型判断(生产环境用 jsonschema 库)
if typ == "int" and not isinstance(arguments[key], int):
return {"ok": False, "error": f"参数 {key} 必须是整数"}
# —— 关卡③ 权限校验:后端强制 ACL,绝不交给模型判断 ——
if tool["required_perm"] not in user.permissions:
_audit({
"event": "permission_denied",
"tool": tool_name,
"user": user.user_id,
"need": tool["required_perm"],
})
return {"ok": False, "error": "权限不足"}
# —— 关卡④ 二次确认:高风险写操作中断,等待人工确认 ——
if tool["risk"] == RISK_WRITE_HIGH:
_audit({"event": "need_confirmation", "tool": tool_name, "args": arguments})
return {
"ok": False,
"status": "needs_confirmation",
"message": f"高危操作 {tool_name} 需要人工确认后才能执行",
}
# —— 关卡⑤ 幂等控制:写操作必须带 key,防止重试重复执行 ——
if tool["risk"] in (RISK_WRITE_LOW, RISK_WRITE_HIGH):
if not idempotency_key:
return {"ok": False, "error": "写操作必须提供 idempotency_key"}
dedup_id = hashlib.md5(
f"{tool_name}:{idempotency_key}".encode()
).hexdigest()
if dedup_id in IDEMPOTENCY_CACHE:
_audit({"event": "idempotent_hit", "tool": tool_name, "key": dedup_id})
return {"ok": True, "result": IDEMPOTENCY_CACHE[dedup_id], "cached": True}
# —— 真正执行(这里用占位实现,生产替换为真实业务调用)——
result = {"tool": tool_name, "echo": arguments}
# —— 关卡⑥ 审计日志:完整记录意图→参数→执行→结果 ——
_audit({
"event": "executed",
"tool": tool_name,
"args": arguments,
"user": user.user_id,
"result": result,
})
# 写操作结果回写幂等缓存
if tool["risk"] in (RISK_WRITE_LOW, RISK_WRITE_HIGH):
IDEMPOTENCY_CACHE[dedup_id] = result
return {"ok": True, "result": result}
if __name__ == "__main__":
# 场景一:普通客服,没有退款权限 → 关卡③拦截
customer_service = CurrentUser("u_001", permissions={"order:read"})
print(dispatch_tool("refund_order", {"order_id": 123, "reason": "损坏"},
customer_service, idempotency_key="k-1"))
# 场景二:有退款权限的管理员 → 高风险,关卡④要求二次确认
admin = CurrentUser("u_002", permissions={"order:read", "order:refund"})
print(dispatch_tool("refund_order", {"order_id": 123, "reason": "损坏"},
admin, idempotency_key="k-2"))
# 场景三:只读查询正常放行
print(dispatch_tool("query_order", {"order_id": 123}, admin))
运行后你会看到:客服被权限校验拦下、管理员触发二次确认、只读查询正常放行,且每一步都留下了审计记录。
运行结果说明
[AUDIT] {"event": "permission_denied", ...}
{'ok': False, 'error': '权限不足'}
[AUDIT] {"event": "need_confirmation", ...}
{'ok': False, 'status': 'needs_confirmation', 'message': '高危操作 refund_order 需要人工确认...'}
[AUDIT] {"event": "executed", ...}
{'ok': True, 'result': {'tool': 'query_order', 'echo': {'order_id': 123}}}
这段代码有三个工程上最该死守的点,值得再强调:
- 权限判断永远在后端:哪怕模型“觉得”这个用户可以退款,后端的 ACL 校验也不会让步;
- 高风险写操作必须中断:
refund_order这类WRITE_HIGH_RISK操作,不是直接执行,而是返回needs_confirmation,由前端弹出确认框(Human-in-the-loop); - 写操作必须幂等:
idempotency_key让 LLM 链路的任何重试都不会造成重复执行。
六、性能优化:渐进式披露与分块处理
6.1 对抗“Lost in the Middle”
长任务中,一次性把所有工具的完整描述塞进上下文,会引发“Lost in the Middle”现象——模型对上下文中段的信息敏感度明显下降,推理质量随之降低(经验上,上下文窗口利用率超过 40% 后,质量开始下滑)。
6.2 渐进式披露(Progressive Disclosure)
生产级接入应遵循“渐进式披露”原则:
- 延迟加载(启动期):初始只加载工具的名称和一句话简短描述(Metadata);
- 按需读取(推理期):只有当模型表达出对某个工具的需求时,才加载它的完整 Schema 或参考文档。
这其实也是 Agent Skills 用
SKILL.md做“地图式”延迟加载的原因:先给地图,需要时再翻详细手册。
6.3 大文件分块读取
MCP Server 处理日志、CSV 等大文件资源时,不应一次性返回全文。推荐做法:
- 先返回元数据(文件名、大小、摘要、可分块数);
- 再支持按 chunk(如 100KB)分块加载。
伪代码示意:
@mcp.tool()
def read_log_chunk(file_path: str, chunk_index: int = 0, chunk_size: int = 102400) -> dict:
"""分块读取日志文件。
使用场景:需要分析大体积日志时使用;首次调用先拿到元数据,
再通过 chunk_index 逐块加载,避免一次性撑爆上下文。
"""
import os
size = os.path.getsize(file_path)
total_chunks = (size + chunk_size - 1) // chunk_size
with open(file_path, "r", encoding="utf-8", errors="ignore") as f:
f.seek(chunk_index * chunk_size)
text = f.read(chunk_size)
return {
"file": file_path,
"total_chunks": total_chunks,
"chunk_index": chunk_index,
"text": text,
}
这样做,无论日志多大,Agent 每次都只往上下文里放一块,保持推理质量稳定。
七、常见问题与避坑
-
问:模型总是乱调工具怎么办?
答:先查工具描述。90% 的“乱调”来自描述没写清使用场景和禁用场景。把 description 当成给召回引擎用的“说明书”来写。 -
问:MCP Server 要不要自己做权限校验?
答:必须做。宿主传来的用户身份不可信,权限校验必须在 Server 后端代码层强制执行,禁止依赖模型判断。 -
问:工具数量很多,模型选不准怎么办?
答:用工具检索(关卡①)做初筛,只把当前任务相关的少数工具放进上下文,配合渐进式披露按需加载详细 Schema。 -
问:Streamable HTTP 和 stdio 怎么选?
答:和宿主同机的本地工具用 stdio,部署在远端、需要跨网络访问的 Server 用 Streamable HTTP。 -
问:写操作已经做了幂等,还需要二次确认吗?
答:需要。幂等防的是“重复执行”,二次确认防的是“不该执行”。两者解决的是不同问题,不能互相替代。 -
问:Resources、Prompts 能不能都做成 Tools?
答:能跑通,但不推荐。只读数据用 Resources、流程模板用 Prompts、真正有副作用的动作才用 Tools,能显著降低误触发写操作的风险。
八、总结
决定 Agent 上限的,不仅是模型,更是你为它打造的 Harness(装具工程)。工具调用不应只是一个 API 触发,而是一套包含**标准化协议(MCP)、结构化经验(Skills)与机械化约束(Validation)**的系统工程。
回到三层境界:
- Function Calling 解决“意图能不能表达”;
- MCP 解决“工具能不能标准化接入”;
- Skills 解决“任务能不能按 SOP 稳定执行”。
而贯穿这三层的,是后端那套“六道关卡”式的安全护栏。只有把权限和执行权牢牢握在后端手中,Agent 才能从实验室的 Demo,真正走向稳定、可审计的生产环境。
模型决定 Agent 的“聪明上限”,装具决定 Agent 的“可靠下限”。在生产环境里,下限往往比上限更重要。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐


 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)