
Hermes-Agent——(二)工具的注册与发现
写一个 AI Agent,工具系统是绕不过去的一道坎。
LLM 本身只是个会推理的脑子。你给它配 read_file,它能读代码。给它配 web_search,它能查资料。给它配 execute_code,它能跑数据分析。工具决定了 Agent 的能力边界。
但工具一多,立刻撞上一个新问题——怎么管。
十几个工具还能靠手维护列表,五十个工具就崩了。改一个工具影响好几个文件,第三方插件想加进来你得给它开权限改你的代码,外部进程想接进来根本找不到统一的接入方式。
这个问题所有做 Agent 框架的人都会撞上。上一篇讲了 Agent 的核心循环,这一篇来看 hermes-agent 怎么解决工具注册与发现。
工具系统看着简单,但读到好几处我都得停下来想想为啥要这么写。这一篇挑几个我读的时候愣了一下的地方讲讲,重点是背后的设计决策。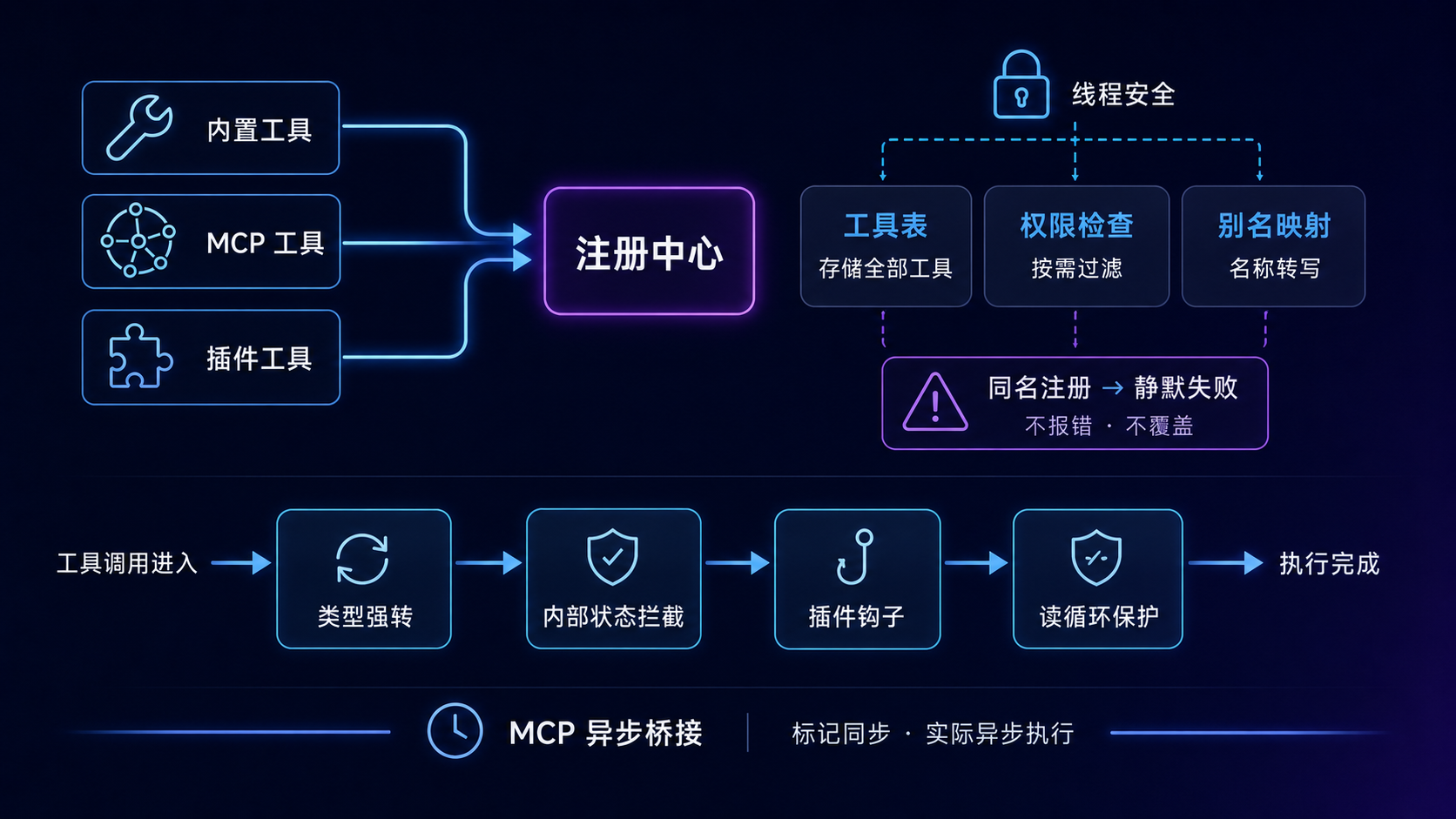
Agent 调工具的完整流程
在讲怎么管工具之前,先说清楚工具是怎么被调用的。这是后面所有讨论的基础。
Agent 调一个工具的完整流程分四步:
- Agent 启动时,把所有可用工具的「说明书」打包发给 LLM。说明书里包括工具名字、功能描述、参数格式
- LLM 决策,看到用户问题后决定要调哪个工具,返回一个调用请求
- Agent 分发,拿到调用请求后,按工具名字找到对应的代码并执行
- 结果回传,工具执行完返回结果,Agent 把结果丢回给 LLM,LLM 继续推理
这个流程里有三个关键概念,后面会反复用到:
- schema:工具的说明书。告诉 LLM 这个工具叫什么、要什么参数、参数是什么类型
- handler:工具被调用时真正执行的那段代码。比如 read_file 的 handler 就是那个打开文件读内容的函数
- dispatch:Agent 拿到 LLM 的调用请求后,按工具名找到 handler 并执行的过程
后面所有的设计讨论,都是围绕「怎么组织 schema、handler 和 dispatch」展开的。
自注册:工具自己举手
中心化列表的问题
最直觉的写法是搞一个中心列表,所有工具在这个列表里登记:
TOOL_REGISTRY = {
"read_file": {"handler": ..., "schema": ...},
"web_search": {"handler": ..., "schema": ...},
# ... 50 个工具全堆在这里
}
你想加新工具,就来这个文件加一行。工具一多就出问题。
第三方插件接不进来。
中心列表在你的主仓库源码里。第三方插件是个独立的 pip 包,它没法改你的主仓库源码。你想让它接入,要么给它开权限改你的源码,要么要求用户手动把插件信息复制进中心列表。两条路都难看。
改动历史被淹没。
五十个工具挤在一个文件里,每次有人加工具或改工具都在动同一个文件。你想查 read_file 这个工具的完整改动历史(什么时候加的、参数怎么变的),用 git log 看这个文件,得到的是一堆别人改 web_search、改 execute_code 的提交,你要从里面捞出跟 read_file 相关的那几条。
关于这一点有个常见的理解偏差——git blame 是按行的,read_file 那一行只会显示它自己的最后修改者,blame 本身没被干扰。问题出在 git log 查改动历史的时候,文件级别的提交历史被其他工具的改动淹了。
自注册的解法
hermes-agent 选了个反直觉的路——工具自己注册,没有中心列表。
工具代码在被 Python import 的时候,自己调用 register() 把自己登记进去:
def _handle_read_file(args):
"""打开文件,返回内容"""
...
register(
name="read_file",
schema={...}, # 工具的说明书
handler=_handle_read_file, # 真正执行的函数
)
register 写在模块级别,Python import 这个文件的时候自动跑。你新建一个工具文件,工具就被注册了,没有任何中间环节。
这就是控制反转
这种设计在软件工程里有个名字,叫控制反转。本来是「中心化注册,工具找管理者」,现在是「工具自己登记,管理者只负责接收」。
类似的实现很多:
- VS Code 的扩展系统
- Vim 的插件系统
- Obsidian 的插件市场
- Python 的 entry points(pip install 后自动注册命令行工具)
底层都是这套思路:插件自己声明自己,平台只负责扫描和加载。
自注册的好处
- 少改文件:加新工具只建一个文件,不碰任何中心列表
- 第三方插件可独立注册:不用碰你的代码就能接入
- 外部进程也能接:只要能包装成「调一次 register」的形式(后面讲的 MCP 就是这么接的)
三个字典,一把锁
核心数据结构
整个 registry 的核心数据结构就这么点东西:
_tools: dict[str, ToolEntry] # 工具名 → 工具元数据
_toolset_checks: dict[str, Callable] # 工具集名 → 可用性检查函数
_toolset_aliases: dict[str, str] # 用户友好名 → 内部工具集名
_lock: RLock # 线程安全
_tools是主存储,工具名映射到一条完整的记录(包含 schema、handler 等元信息)_toolset_checks是工具集级别的可用性检查函数_toolset_aliases是别名映射,让用户配github就能找到内部名mcp-github_lock是一把可重入锁,保证线程安全
工具集分组
工具是按集分组的,同一个集下的工具共用同一个检查函数。比如:
| 工具集 | 包含的工具 | 共用的检查函数 |
|---|---|---|
web |
web_search、web_extract、web_crawl | check_web_api_key(有 API key 就返回 True) |
file |
read_file、write_file、patch | 默认始终可用 |
为啥 check_fn 要存两份
check_fn 同时存在 _tools(每个工具一份)和 _toolset_checks(每个工具集一份)里。
这个设计不是为了性能(十几个函数调用的开销是纳秒级,不值得优化)。真正的原因是两个查询场景对应两个不同的概念:
- 「这个工具现在能不能用」——从
_tools拿这个工具自己的check_fn。LLM 要调 web_search 时走这条路。 - 「这个工具集整体活着吗」——从
_toolset_checks直接拿。UI 上显示工具集状态绿点红点,或者诊断命令检查工具集配置时走这条路。
这是两个不同的语义层次。分开存让每条查询路径的代码都干净,不用在「查工具集状态」时去遍历下面的工具——即使遍历的开销很小,概念上的清晰比省那点纳秒更重要。
宁可静默失败,也不覆盖
反直觉的冲突检测
register() 会先做冲突检测。如果这个名字已经被别的工具集占了,直接拒绝注册。不抛异常,不通知调用方,只打个 error 日志。
注意是「拒绝注册」而不是「覆盖」。
举个例子:内置的工具集先注册了 read_file。然后你装了个第三方插件,它也想注册一个叫 read_file 的工具(可能它自己实现了一个增强版)。插件注册的时候,registry 发现 read_file 已经被占用了,直接拒绝。插件那边什么都不知道,它的注册调用看起来是成功的,但工具实际没注册进去。
三种选择及后果
这是个典型的防御性设计。三种选择的后果对比:
| 选择 | 后果 | 评价 |
|---|---|---|
| 抛异常 | 第三方插件大概率不写 try/except(这是现实,第三方代码质量参差不齐),一个烂插件就让整个 Agent 启动失败 | ❌ 风险太大 |
| 允许覆盖 | 恶意插件抢个 read_file 的名字,就能把内置功能替换成自己的版本,悄悄偷用户文件 |
❌ 安全漏洞 |
| 静默失败 ✓ | 插件作者发现工具没生效会去看日志,系统不会被烂插件干挂,也不会被恶意插件劫持 | ✅ 最保守但最稳 |
类似的防御性设计
这不是 hermes-agent 独有的思路,所有需要支持第三方扩展的系统都得考虑这个问题:
- Chrome 扩展不能随便覆盖浏览器内置 API
- Firefox 的扩展签名机制防止恶意扩展伪装成内置功能
- 移动应用的沙箱机制防止应用越权
- 操作系统的权限系统
只要系统的扩展边界对外暴露,就得考虑这个问题。 核心功能不能被不可信代码覆盖,这是一条不能让步的底线。
MCP 怎么接进来
说一下 MCP。你用过的 Agent 产品里大概率已经有它了——你有个 GitHub MCP 服务器,对外暴露「创建 issue」「读 PR」「合并代码」这些工具,任何支持 MCP 的 Agent 都能接进来用,不用每个 Agent 自己写一份 GitHub 集成。
三种工具来源
讲完自注册和 MCP,现在可以把工具发现的来源讲清楚。一个 Agent 框架的工具通常来自三条路:
| 内置工具 | MCP 工具 | 插件工具 | |
|---|---|---|---|
| 代码在哪 | 项目内的工具目录 | 外部进程 | pip 包/插件目录 |
| 谁调 register | 工具文件自己 | MCP 集成层的循环 | 插件的 register 函数 |
| handler 是什么 | 你写的 Python 函数 | 向远端发 RPC | 插件作者写的函数 |
| 加新工具的代价 | 新建一个文件 | 改 yaml 配置 | pip install |
三条路最后都汇到同一个 register 入口。registry 把它们一视同仁。
它把「工具从哪里来」这个复杂性,完全藏在了 registry 背后。LLM 看到的就是一个统一的工具列表,它不需要知道你用了多少 MCP 服务器、装了什么插件。
一个细节:用户友好性 vs 内部命名
MCP 工具集内部叫 mcp-github(带前缀,避免和内置工具集冲突),但用户在配置文件里写 github 更直观。registry 里有个别名字典 {"github": "mcp-github"},做这个映射。每次 MCP server 注册时自动登记一个别名。
这是个用户友好性的小优化。内部命名规则为了安全加了前缀,但用户配置和 CLI 里直接用简短名字。别名字典就是这个内部 vs 用户之间的映射层。
dispatch 前的四层加工
最基础的 dispatch 只做一件事——按名字找到 handler 并执行。但实际调用会在 dispatch 前后加四层处理。
每一层都解决一个具体问题,这四个问题都是任何 Agent 系统迟早会遇到的。
1. 参数类型修正
LLM 输出经常不靠谱:
- 让它传整数
42,它可能传成字符串"42" - 让它传布尔
true,它可能传成字符串"true"
看起来差不多,但 Python 里 "42" + 1 直接报 TypeError。
这层在调 handler 之前,先把每个参数和 schema 比对,字符串能转数字或布尔就转,转不了就保留原值。只要你的 Agent 接的是 LLM,这个问题躲不掉。
2. 拦截需要内部状态的工具
大部分工具的 handler 是纯函数——给它参数,它出结果,不依赖外界任何东西。read_file 拿到路径就能读,web_search 拿到关键词就能搜。
但有四个工具不一样:
| 工具 | 要访问的东西 |
|---|---|
| memory | Agent 的记忆库(self.memory_store) |
| todo | Agent 的待办列表 |
| session_search | 跨会话搜索历史 |
| delegate_task | 派生子 Agent |
它们的 handler 需要碰到 Agent 实例的内部属性。
但 registry 手里根本没有 Agent 实例。它是个全局单例,启动时就被创建了,只存了工具名和 handler 的映射关系。它不知道 Agent 是谁、Agent 的记忆库在哪。正常 dispatch 路径走不通。
hermes-agent 的做法分三步:
- 注册阶段照样注册这些工具,但 handler 不是真正的实现,是个占位函数——一调就返回一个特殊标记(类似
{"error": "internal_tool"}) - dispatch 执行前有一层拦截判断——发现要调的工具在内部工具名单里,直接走占位 handler,拿到「我是内部工具」这个返回值
- Agent 主循环收到这个返回值,不把它当错误,而是按工具名走自己的分支:
if tool == "memory": return self._handle_memory(args)
等价于 registry 和 Agent 之间有个简单协议:registry 说「这个我调不了,你自己来」,Agent 主循环说「行,我知道在哪。」 registry 永远不需要知道 Agent 实例长什么样,Agent 也不需要把自己的内部状态暴露给 registry。
3. 插件钩子
让插件在工具调用前后能介入:
pre_tool_call:可以阻止调用(比如安全插件发现要执行rm -rf就直接 block)post_tool_call:可以做日志、统计、缓存
任何想给 Agent 加观测、安全审计、性能监控的能力,都得靠这层。
4. 循环保护
LLM 有时候会卡在死循环里,比如反复读同一个文件十几次。Agent 通常有个机制叫 read-loop,连续调读类工具超过阈值就触发干预。
但这层有个细节:如果调用序列是「读文件 → 写文件 → 读文件」,这其实是正常工作流(读一个、改一个、再读另一个),不是死循环。所以每次碰到非读类工具,就把 read-loop 计数器清零。
少了这层 Agent 会误判正常工作流为死循环,把用户搞懵。
分层的核心思想
四层加工,每一层都解决一个 registry 不该管但又必须有人管的问题。registry 保持纯粹,调度层把脏活全包了。
这种「核心层纯粹,调度层脏」的分层思路,在系统设计里几乎是个通用模式:Linux kernel(kernel 只管调度,驱动自己实现细节)、数据库的查询优化器(执行引擎纯粹,优化逻辑独立演化)、编译器的 pass 系统,都是这样。
MCP 工具假装自己是同步的
最后讲异步桥接的设计。
Agent 核心循环通常是同步的,代码一行 async 都没有。但 MCP 工具的 handler 内部是异步的(它要 await 远端进程返回结果)。
同步的 Agent 核心怎么调一个异步的 handler?
答案:把异步调用丢给 MCP 自己的后台 event loop,当前线程阻塞等结果。
return _run_on_mcp_loop(_call(), timeout=tool_timeout)
然后所有 MCP 工具注册的时候都标 is_async=False(从 Agent 视角看是同步的)。
这就是个桥接层:
- 从 Agent 视角看:所有工具都是同步的,调一下就拿到结果
- 从 MCP 视角看:调用跑在自己的 event loop 里,跟其他 MCP 调用可以并发
- 复杂性:被这一层全部消化掉,上下两层都看不到对方的存在
这种「假装成对方期望的接口形态」的设计,其实就是适配器模式。接口适配做得好,就是让两边都觉得对方跟自己是同类。
一个最小实现
如果你想自己实现一个类似的工具注册系统,核心其实就这点东西:
class Registry:
def __init__(self):
self._tools = {}
def register(self, name, schema, handler, check_fn=None):
self._tools[name] = {"schema": schema, "handler": handler, "check": check_fn}
def get_schemas(self, names):
result = []
for name in names:
tool = self._tools.get(name)
if not tool:
continue
if tool.get("check") and not tool["check"]():
continue
result.append({
"type": "function",
"function": tool["schema"],
})
return result
def dispatch(self, name, args):
t = self._tools.get(name)
if not t:
return json.dumps({"error": f"Unknown: {name}"})
try:
return t["handler"](args)
except Exception as e:
return json.dumps({"error": str(e)})
registry = Registry()
不多不少,27 行。
自注册、可用性过滤、异常包装,核心全在这。
任何复杂的工具系统(工具集分组、别名、线程安全、异步桥接、动态 schema 修正),全都是在这 27 行之上长出来的扩展。
几个值得带走的设计思想
1. 让东西自己注册,而不是中心化维护
任何「加新东西不想改老代码」的场景都适用:
- VS Code 的扩展
- Obsidian 的插件
- Python 的 entry points
中心化列表短期省事,长期维护成本高。
2. 抽象边界划在「输入格式统一」而不是「来源统一」
三种工具来源(内置、MCP、插件)各有各的接入方式,但只要最后都调同一个 register 入口,Agent 看到的就是统一的工具列表。
这个思路在做插件系统、SDK 设计的时候特别有用。
3. 在不可信边界上,宁可静默失败也不让覆盖生效
类似的案例:浏览器扩展、移动应用沙箱、操作系统的权限系统。
核心功能不能被不可信代码覆盖,这是一条不能让步的底线。代价是开发者发现工具没生效需要去看日志,但这个代价换来的安全性是值得的。
4. 核心层纯粹,调度层脏
registry 只管存储和分发,类型修正、插件钩子、循环保护这些脏活全在上层。
核心层保持纯粹的好处:
- 能被任何上下文复用
- 调度逻辑可以独立演化
- 测试容易(核心无状态)

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐


 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)