
OpenClaw调度框架深度解析
如果你在用AI Agent做复杂任务,你一定遇到过这些问题:
-
对话稍微长一点,AI就开始“犯糊涂”,回答越来越离谱
-
明明用的是顶级模型,Token账单却比工资涨得还快
-
某个模型突然限流或宕机,整个任务就卡住了
-
不知道什么时候该用GPT-5,什么时候该用便宜模型
OpenClaw就是为解决这些问题而生的。
它不是一个聊天机器人,而是一套连接大模型、工具系统、会话机制和记忆系统的AI Agent运行框架。你可以把它理解成AI的“操作系统”——它负责调度、路由、记忆和成本控制,让你能用一套系统管理多个模型、多个Agent、多个渠道。
一、OpenClaw是什么?一句话说清楚
OpenClaw = 一个连接大模型 + 工具系统 + 多渠道通信的AI Agent框架
它本质上是一个TypeScript CLI应用,你可以把它部署在本地或云端。它的核心设计思想是将消息通信、接口适配与AI执行逻辑彻底解耦——用大白话说,就是“谁来发消息、发到哪个平台”和“AI怎么处理、调用什么模型”是两件独立的事,OpenClaw把它们分开管理。
OpenClaw主要解决三个问题:
| 问题 | OpenClaw怎么解决 |
|---|---|
| AI如何接入真实世界 | 通过工具系统,让模型能搜索、读写文件、执行命令、操作浏览器 |
| AI如何持续工作 | 通过会话持久化和记忆系统,对话不会随着页面关闭就消失 |
| AI如何在不同渠道统一服务 | 通过Gateway,把Telegram、飞书、CLI等不同入口统一接入同一套运行时 |
二、调度框架架构:Gateway + Agent的双层设计
OpenClaw的架构可以拆解为网关层(Gateway) 和智能体层(Agent) 两大模块。
2.1 整体架构图
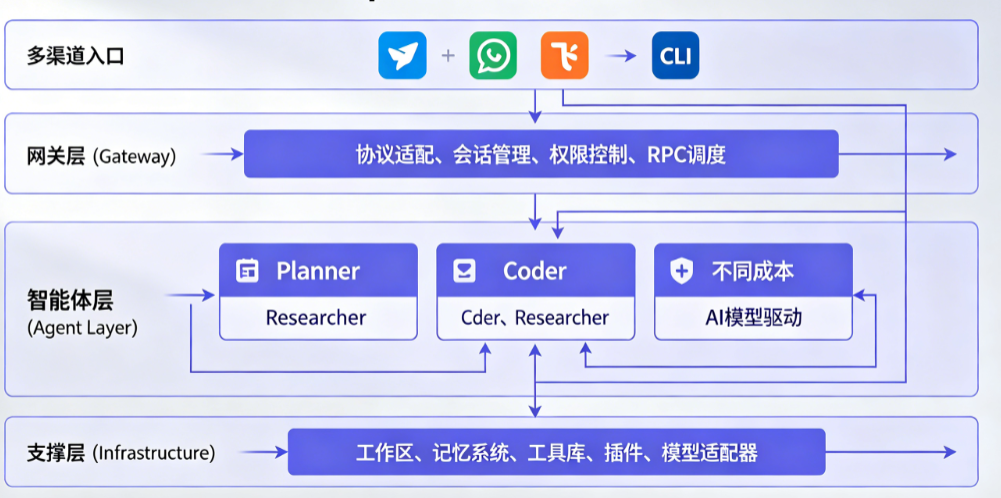
2.2 网关(Gateway):消息流的“交通枢纽”
网关是系统的入口,承担以下职责:
-
协议适配:把不同平台的原始消息(JSON、XML等)转换为内部统一格式
-
会话管理:维护用户会话状态,包括上下文历史、临时变量
-
权限控制:基于签名验证、IP白名单等机制过滤非法请求
-
RPC调度:根据消息类型将请求路由至对应的Agent
技术实现上,网关通常采用WebSocket服务器,监听端口接收消息。
2.3 智能体(Agent):任务执行的“专业团队”
Agent是实际处理业务的模块。OpenClaw支持多Agent分工——你可以为不同任务创建不同的Agent,每个Agent有自己的workspace、记忆和技能。
比如你可以配置:
-
Planner Agent:负责任务拆解和规划(用便宜模型)
-
Coder Agent:负责写代码(用顶级模型)
-
Researcher Agent:负责搜索和信息收集(用中等模型)
这样上下文干净、Token可控、故障隔离。
三、模型调度与切换:OpenClaw的“智能路由”机制
OpenClaw最强大的能力之一,就是灵活调度和切换AI模型。它的调度逻辑集中在src/agents/run.ts这个核心文件中。
3.1 三层防御机制
OpenClaw的模型调度有三个层次:
第一层:多模型弹性调度
OpenClaw允许为每个Agent配置多个候选模型,按优先级排序:
# agents/dev-assistant/config.yaml
models:
- id: "claude-3-5-sonnet"
provider: "anthropic"
- id: "gpt-4o"
provider: "openai"
- id: "gemini-1.5-pro"
provider: "google"调度流程:
-
尝试首选模型(如Claude)
-
若返回可恢复错误(如限流、超时),标记该账号失败,切换至下一模型
-
若所有模型失败,抛出最终错误
这让用户无感知地享受“模型冗余”带来的高可用性。
第二层:API Key轮询与健康管理
一个模型可能绑定多个API Key。OpenClaw通过认证档案(Auth Profile) 管理这些凭证:
const authProfiles = {
"openai-team-a": {
key: "...",
cooldownUntil: 0,
successCount: 12
},
"openai-team-b": {
key: "...",
cooldownUntil: 1710234567,
successCount: 3
}
}轮询策略:
-
每次调用前,从健康账号池中选择一个
-
若调用失败,将该账号加入冷却队列(默认60秒)
-
若调用成功,提升该账号信用分,增加被选中概率
轮询不是随机的,而是基于健康状态的智能选择。
第三层:上下文窗口守护
LLM的上下文长度有限(如Claude 200K,GPT-4o 128K)。OpenClaw通过Token监控 + 自动压缩来守护上下文窗口。
3.2 模型切换的三种方式
OpenClaw支持灵活的模型切换:
| 方式 | 命令 | 说明 |
|---|---|---|
| 命令行切换 | openclaw models set ollama/<model> |
永久切换默认模型 |
| 会话内切换 | /model gpt-5.2 |
当前会话临时切换,无需重启 |
| 配置文件切换 | 编辑config.json |
为不同Agent指定不同模型 |
OpenClaw本身不内置任何大模型,而是通过灵活的配置机制对接各类模型服务。你可以在配置文件中添加任意模型提供商。
3.3 模型分级使用:省钱的核心策略
这是OpenClaw最实用的功能之一——为不同任务配置不同模型。
{
"agents": {
"defaults": {
"model": {
"primary": "qwencode/qwen3.5-plus" // 便宜大碗,处理80%的日常对话
}
},
"list": [
{
"id": "planner",
// 策划机器人:继承默认配置(便宜模型)
},
{
"id": "coder",
"model": {
"primary": "openai-codex/gpt-5.4" // 贵但在刀刃上,只在Coding Agent里调用
}
}
]
}
}配置逻辑:
-
专家任务(写代码、复杂文案、逻辑推理)→ 用顶级模型
-
实习生任务(意图识别、简单问答、提取关键词)→ 用便宜模型
这相当于雇了个年薪百万的专家干专业活,而不是让他去取快递。
四、Token优化实战:7个让你省钱的技巧
OpenClaw每次处理指令时,需要向模型发送的上下文比普通对话多得多:
-
系统提示词
-
已启用的Skills列表
-
历史对话记录
-
记忆文件内容
-
工具调用结果
一次复杂任务的Token消耗量可能是普通对话的几十倍甚至上百倍。下面这7个技巧,能帮你把Token成本降下来。
4.1 技巧一:Prompt Caching(提示缓存)
这是最强大的省Token手段。
原理:模型提供商可以复用未更改的提示前缀(如系统指令),而不是每次重新处理。
没有缓存时,即使大部分输入没变,每一轮都要支付完整的提示词费用。有了缓存,Cache命中的部分Token成本会大幅降低。
OpenClaw对主流模型提供商的缓存支持:
# 配置缓存保留时间
cacheRetention: "long" # 1小时TTL(Anthropic)或24小时(OpenAI)-
Anthropic:
cacheRetention: "short"映射到5分钟缓存,"long"升级到1小时 -
OpenAI:自动缓存,无需额外配置
4.2 技巧二:精简Skills数量
每个Skill的SKILL.md内容都会在每次模型调用时加载到上下文中。
做法:
-
定期审查已安装的Skills
-
禁用或删除不需要的Skills
-
在聊天窗口问OpenClaw:“我目前安装了哪些Skills?哪些最耗Token?”
4.3 技巧三:开启上下文压缩(Compaction)
当对话长度接近模型上下文窗口上限时,OpenClaw会自动将较早的对话内容概括为简短摘要,释放Token空间。
压缩之前系统会自动触发记忆刷新,将重要信息写入磁盘文件,确保关键信息不丢失。
# 调整触发压缩的阈值
context_window: 200000 # 默认值,可根据需要调整4.4 技巧四:使用QMD(Quantum Memory Database)模式
QMD模式通过向量化检索替代将全部记忆文件内容直接加载到上下文的方式。
效果:实测数据显示,开启QMD后Token消耗可降低90%以上。
# 开启QMD模式
memory:
backend: "qmd"首次开启时需要下载Embedding模型(约几百MB)。
4.5 技巧五:三个斜杠命令——手动管理上下文
OpenClaw内置了三个非常实用的指令:
| 命令 | 作用 | 使用场景 |
|---|---|---|
/status |
查看当前上下文占用比例 | 感觉AI反应慢时,先看一眼“脑容量”还剩多少 |
/compact |
压缩历史对话为摘要 | Context占用过高时,或完成一个阶段准备进入下一阶段时 |
/new |
清空所有历史,开启全新会话 | 准备开启完全不同的话题时 |
/status的典型输出:
Context: 12000/200000 (6%)-
占用率低(<10%):AI很清醒,随便聊
-
占用率高(>50%):AI脑子快满了,不仅反应慢,还容易产生幻觉
4.6 技巧六:“收费模型调教 + 免费模型执行”
这是社区总结出来的“骚操作”:
两阶段策略:
-
调教期:用收费模型(如Claude 4.6)处理复杂任务,打磨流程、优化逻辑,最终生成本地可执行脚本
-
执行期:切换到免费模型,直接调用已生成的成熟脚本执行重复任务
关键优势:脚本保留了收费模型的优化逻辑,免费模型仅负责执行,既保证任务效果,又将Token消耗降至最低。
4.7 技巧七:限制工具输出长度
工具调用结果(如浏览器截图、命令执行输出、文件内容)是Token消耗的大户。
做法:在配置中限制工具返回的内容长度,避免把大段无用信息塞进上下文。
五、VSCode实战:配置一个“省钱版”OpenClaw
下面是一套完整的配置示例,你可以在VSCode里直接使用。
5.1 安装OpenClaw
# 通过npm安装
npm install -g openclaw
# 验证安装
openclaw --version5.2 基础配置文件(config.json)
{
"agents": {
"defaults": {
"model": {
"primary": "qwen/qwen3.5-plus"
},
"params": {
"cacheRetention": "long"
}
},
"list": [
{
"id": "planner",
"description": "任务规划和拆解",
"model": {
"primary": "qwen/qwen3.5-plus"
}
},
{
"id": "coder",
"description": "代码编写和调试",
"model": {
"primary": "openai/gpt-5.4"
},
"params": {
"cacheRetention": "long"
}
},
{
"id": "researcher",
"description": "信息搜索和整理",
"model": {
"primary": "anthropic/claude-3.5-sonnet"
}
}
]
},
"memory": {
"backend": "qmd"
},
"context": {
"window": 200000,
"compaction": {
"enabled": true,
"threshold": 0.7
}
}
}5.3 多模型切换的代码示例
// 在OpenClaw中动态切换模型(基于run.ts的调度逻辑)
interface ModelConfig {
id: string;
provider: string;
priority: number;
}
class ModelScheduler {
private models: ModelConfig[] = [];
private currentIndex: number = 0;
private failedModels: Set<string> = new Set();
constructor(models: ModelConfig[]) {
this.models = models.sort((a, b) => a.priority - b.priority);
}
// 获取当前可用的最高优先级模型
getNextModel(): ModelConfig | null {
for (let i = 0; i < this.models.length; i++) {
const model = this.models[i];
if (!this.failedModels.has(model.id)) {
this.currentIndex = i;
return model;
}
}
return null;
}
// 标记模型失败,进入冷却
markFailure(modelId: string) {
this.failedModels.add(modelId);
// 60秒后自动恢复
setTimeout(() => {
this.failedModels.delete(modelId);
}, 60000);
}
// 标记模型成功,提升信用分
markSuccess(modelId: string) {
// 成功调用后,将该模型移到更高优先级
const index = this.models.findIndex(m => m.id === modelId);
if (index > 0) {
const [model] = this.models.splice(index, 1);
this.models.unshift(model);
}
}
}
// 使用示例
const scheduler = new ModelScheduler([
{ id: "claude-3.5-sonnet", provider: "anthropic", priority: 1 },
{ id: "gpt-4o", provider: "openai", priority: 2 },
{ id: "gemini-1.5-pro", provider: "google", priority: 3 }
]);
const model = scheduler.getNextModel();
// 如果Claude限流,自动降级到GPT-4o5.4 Token监控与自动压缩
// 上下文窗口守护机制(参考OpenClaw的run.ts实现)
class ContextGuardian {
private maxTokens: number;
private currentTokens: number = 0;
private compactionThreshold: number = 0.7; // 70%时触发压缩
constructor(maxTokens: number) {
this.maxTokens = maxTokens;
}
// 监控Token使用情况
monitor(tokensUsed: number): string {
this.currentTokens = tokensUsed;
const ratio = this.currentTokens / this.maxTokens;
if (ratio > this.compactionThreshold) {
return `⚠️ 上下文占用 ${(ratio * 100).toFixed(1)}%,建议执行 /compact 压缩`;
} else if (ratio > 0.9) {
return `🚨 上下文即将溢出!请立即执行 /new 开启新会话`;
} else {
return `✅ 上下文健康,占用 ${(ratio * 100).toFixed(1)}%`;
}
}
// 自动压缩逻辑
shouldCompact(): boolean {
return (this.currentTokens / this.maxTokens) > this.compactionThreshold;
}
}
// 使用示例
const guardian = new ContextGuardian(200000);
console.log(guardian.monitor(150000));
// 输出: ⚠️ 上下文占用 75.0%,建议执行 /compact 压缩一张表看懂OpenClaw
| 维度 | 说明 |
|---|---|
| 本质 | 连接大模型 + 工具系统 + 多渠道通信的AI Agent运行框架 |
| 核心架构 | Gateway(网关层)+ Agent(智能体层)+ 支撑层 |
| 模型调度 | 多模型优先级降级 + API Key健康轮询 + 上下文窗口守护 |
| 模型切换 | 命令行切换 / 会话内切换(/model)/ 配置文件切换 |
| 省Token核心手段 | Prompt Caching、上下文压缩、QMD模式、斜杠命令、模型分级 |
| 适用场景 | 企业知识管理、个人助理、多平台AI服务、复杂任务自动化 |
一句话总结
OpenClaw是一套让AI Agent“聪明干活、省钱办事”的调度框架——通过Gateway统一管理消息路由,通过多模型调度保证高可用,通过上下文压缩和QMD记忆把Token成本降到最低。
小编建议
-
先做模型分级:别所有任务都用GPT-5,80%的日常对话用便宜模型就够了
-
养成用斜杠命令的习惯:
/status看占用,/compact压缩,/new开新会话 -
开启QMD模式:Token消耗直接降90%,性价比最高的配置
-
用好Prompt Caching:配置
cacheRetention: "long",长会话省Token效果明显 -
多Agent分工:不同任务用不同Agent,上下文隔离、故障可控、优化有针对性

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐


 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)