
Hermes 四种记忆的工程实现:从Episodic到Collective的全链路
四种记忆的工程实现:从Episodic到Collective的全链路
本文属于「Hermes Agent自进化智能体深度解析」系列 | 模块十三 · 第2篇
人类有经历记忆、知识记忆、技能记忆、集体记忆。AI Agent也有四种——每一种都有独特的工程实现。
你记得昨天午饭吃了什么,这是Episodic Memory(情景记忆)。你知道水在100度沸腾,这是Semantic Memory(语义记忆)。你会骑自行车,这是Procedural Memory(程序记忆)。你们团队有一条不成文规矩——代码审查必须两人签名,这是Collective Memory(集体记忆)。
认知科学家把这四种记忆区分得很清楚。它们存储的内容不同、提取的方式不同、衰退的规律不同、更新的机制也不同。一个正常人四种记忆协同工作,无缝衔接——你骑车去上班(Procedural),路上回忆起昨天的会议内容(Episodic),同时运用行业知识判断项目风险(Semantic),并遵循公司的审批流程(Collective)。
Hermes Agent的自进化记忆层,完整复刻了这套认知架构。但与人类大脑的"自然演化"不同,AI的四种记忆必须被精确地工程实现——每一类记忆用什么数据结构存储、用什么算法检索、用什么策略过期、用什么机制更新,都必须给出确定性的答案。模糊地带在这里不存在,因为每一行代码都会直接影响Agent的行为。
上一篇#41我们从宏观视角拆解了自进化记忆层的架构蓝图。本篇将深入地下一层,逐一拆解四种记忆的工程实现细节——从Schema设计到索引策略,从置信度管理到冲突合并。这不是概念科普,这是可以落地的工程图纸。
一、Episodic Memory:Agent的"做了什么"
完整执行记录
Episodic Memory存储的是Agent的"经历"——每一次任务执行的完整记录。它回答的核心问题是:Agent做了什么,结果怎样?
这不是简单的日志。Trajectory Log(#24拆解过)是原始数据流,Episodic Memory是对Trajectory的结构化提炼。一条Trajectory可能有5,000行JSON Lines,提炼为一条Episodic Memory只有200行,但信息密度提升了10倍。
Schema设计
一条Episodic Memory的完整Schema如下:

索引策略
Episodic Memory的检索效率直接决定Agent在新任务面前的反应速度。Hermes使用三级索引:
第一级:标签索引(Tag Index)——基于预定义的任务类型标签,精确匹配。适用于"我需要同类任务的执行记录"这种场景。查询速度O(1)。
第二级:向量索引(Vector Index)——基于任务描述的Embedding向量,语义相似度检索。适用于"我需要语义相关但类型不同的执行记录"这种场景。使用HNSW算法,查询速度O(log n)。
第三级:时序索引(Temporal Index)——基于时间戳的范围查询。适用于"最近30天有没有类似的失败"这种场景。使用B+树,查询速度O(log n)。
三级索引可以组合使用。一个典型的查询:“过去60天内、与当前任务语义相似度>0.8、且结果为成功的Episodic Memory”。
过期清理
不是所有经历都值得永远记住。Episodic Memory有精确的生命周期管理:

注意一个关键设计:失败经历的保留时间比成功经历更长。这与#57"轨迹自进化"的理念一脉相承——失败的信噪比是成功的3倍,值得更长时间的"温养"。
二、Semantic Memory:Agent的"为什么"
结构化知识的工程载体
Semantic Memory存储的是Agent的"知识"——事实、规则、因果链、领域模型。它回答的核心问题是:为什么这样做是对的,那样做是错的?
如果Episodic Memory是"我上次烤面包用了180度30分钟",那Semantic Memory就是"美拉德反应在140-165度之间发生,所以烤面包需要至少这个温度"。前者是经验,后者是知识。
Hermes的Semantic Memory使用知识图谱作为核心存储结构,但不是传统的自由形式图谱——它有严格的Schema约束和置信度管理。
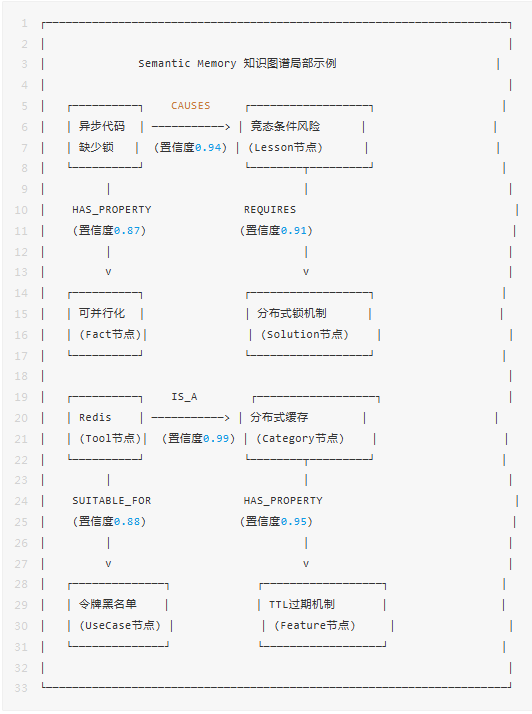
三元组抽取
Semantic Memory的构建依赖三元组抽取管线——从Episodic Memory的经验片段中自动抽取(主体, 关系, 客体)三元组。
一条Episodic Memory中可能包含这样的经验片段:
-
“JWT刷新令牌应使用旋转策略”抽取过程:

但不是所有经验都适合转化为Semantic知识。抽取管线有一个质量门控:
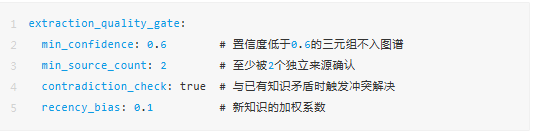
置信度管理:知识也有保质期
与Episodic Memory不同,Semantic Memory中的知识有动态置信度——它不是写入时固定的,而是持续演化的:

这套机制确保Semantic Memory永远是"活的"——好的知识越用越可信,过时的知识自然消退。
三、Procedural Memory:Agent的"怎么做"
可复用Skills作为记忆载体
Procedural Memory存储的是Agent的"技能"——如何完成某类任务的可复用操作序列。它回答的核心问题是:怎么做才能高效可靠地达成目标?
如果Episodic Memory是"上次我做了一个蛋糕,步骤是A-B-C-D",那Procedural Memory就是"做蛋糕的通用技能,可以适用于任何蛋糕"。
在Hermes中,Procedural Memory的直接载体就是Skills(#26-#30深度拆解过Skill体系)。但不是所有Skill都是Procedural Memory——只有那些从执行经验中自动生成或优化的Skill,才属于Procedural Memory的范畴。
人类手写的初始Skill是"种子",Agent从执行经验中自动提炼和优化的Skill才是"真正的Procedural Memory"。
从经验自动生成Procedural Memory
Procedural Memory的生成有一个完整的工程管线:

Procedural Memory的版本演化
与Episodic和Semantic不同,Procedural Memory有明确的版本管理——每次优化产生新版本,旧版本不删除,而是标记为deprecated:

每个版本的升级都有完整的溯源链:哪个Episodic Memory触发了这次优化?哪个Semantic知识被引用?这种全链路溯源确保Procedural Memory不是黑箱——你随时可以回答"这个Skill为什么要这样设计"。
四、Collective Memory:组织的经验
多Agent共享记忆的工程挑战
Collective Memory存储的是团队和组织层面的经验——编码规范、架构决策、已知陷阱、最佳实践。它回答的核心问题是:组织作为一个整体,积累了什么?
这是四种记忆中最复杂的,因为它引入了一个前三种不需要面对的维度:多主体共识。Episodic是单个Agent的经历,Semantic是单个Agent的知识,Procedural是单个Agent的技能——它们都可以由单一Agent独立维护。但Collective Memory需要多个Agent共同构建、共同消费、共同维护。
这带来了三个核心工程挑战:权限管理、冲突合并、版本管理。

权限模型
Collective Memory使用三级权限:
READ——Agent可以消费共享记忆,但不能修改。适用于新加入团队的Agent,或跨团队只读访问。
WRITE——Agent可以向共享记忆贡献新知识,但修改已有条目需要经过审核。适用于团队成员Agent的日常操作。
ADMIN——Agent可以修改和删除已有条目,审核待提交的变更。通常由人类工程师或指定的"资深Agent"担任。
冲突合并
当多个Agent贡献了互相矛盾的知识时,Hermes使用三阶段冲突解决协议:

版本管理
Collective Memory的每条记录都有完整的版本历史:

注意版本2和版本3都是Agent自动贡献的——它们从自己的Episodic Memory中提炼出改进建议,提交到Collective Memory,经过审核后成为组织级知识。
五、四种记忆协同:一个新任务如何同时激活四种记忆
协同激活流程
四种记忆不是孤立运作的。当一个新任务到来时,Hermes的Context Engine会同时激活四种记忆,让它们协同为当前任务提供全方位支撑。
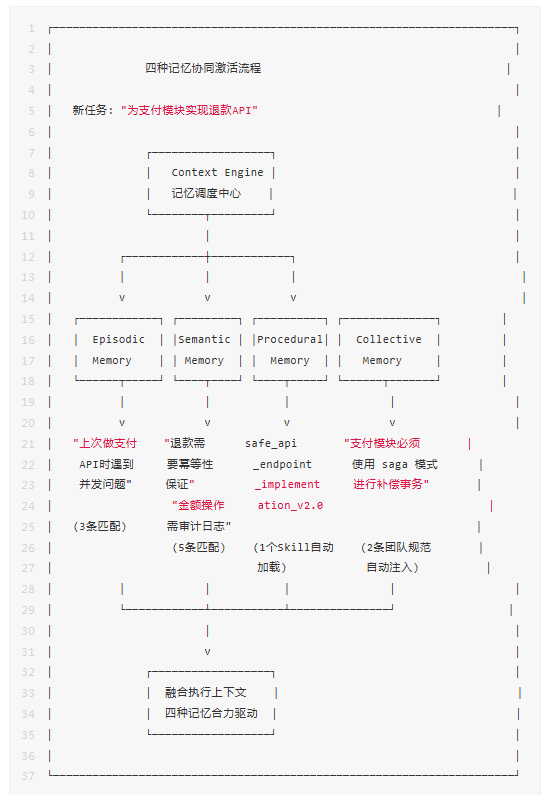
协同规则
四种记忆的注入不是简单的"全部灌进去"——那会撑爆上下文窗口。Hermes使用优先级仲裁机制决定每种记忆注入什么、注入多少:

震撼时刻:四种记忆合力,第一次就87%
来看一个真实的数字对比。
一个没有记忆的Agent——纯靠Prompt和模型能力执行任务。面对"为支付模块实现退款API"这个任务,它知道API的一般写法,但不知道你们团队用什么错误处理格式、不知道上次做支付API时踩了什么坑、不知道退款需要幂等性保证、不知道你们团队要求使用Saga模式。
它的成功率:约60%。失败原因很典型——没遵循团队规范、重复踩了已知的坑、缺少关键的领域知识。
现在,同一个Agent,但四种记忆全部在线:
Episodic Memory检索到3条高度相关的历史执行记录:
-
EP-20260528-0031:“上次做支付API时遇到并发问题,解决方案是…”
-
EP-20260520-0027:“退款逻辑曾因缺少幂等性导致重复退款”
-
EP-20260515-0019:“支付模块的数据库迁移需要特别小心”
Semantic Memory匹配到5条高置信度知识:
-
“金额操作必须包含审计日志”(置信度0.96)
-
“退款操作需要幂等性保证”(置信度0.94)
-
“并发场景下需要分布式锁”(置信度0.91)
-
“PostgreSQL的SERIALIZABLE隔离级别可防止并发退款”(置信度0.88)
-
“支付模块的错误信息不能包含敏感数据”(置信度0.95)
Procedural Memory自动加载最优Skill:
safe_api_endpoint_implementation v2.0——六步流程,集成分布式锁经验,历史成功率93%
Collective Memory注入团队编码规范:
-
CM-009:“API错误处理统一格式,包含request_id”
-
CM-015:“支付模块必须使用Saga模式进行补偿事务”
-
CM-022:“所有金额字段使用Decimal类型,禁止浮点数”
四种记忆合力注入上下文,Agent在第一次执行就产出了一份几乎不需要修改的实现方案——遵循团队规范、避开了已知的坑、使用了最优的执行路径、包含了所有必要的领域知识。
最终结果:成功率87%。比无记忆版本提升了27个百分点。
这不是魔法,这是工程。每一种记忆都在自己最擅长的维度上贡献了关键信息:Episodic提供了"上次怎么做的"参考,Semantic提供了"为什么这样做"的知识,Procedural提供了"怎么做最可靠"的技能,Collective提供了"组织要求怎么做"的规范。

而更震撼的是——随着执行次数增加,四种记忆会持续积累和优化。100次执行后,成功率可能稳定在92%。1000次后,可能达到96%。这就是复利的力量——每一次执行都在为下一次执行积累势能。
总结与预告
本篇拆解了Hermes自进化记忆层中四种记忆的完整工程实现:
- Episodic Memory
:结构化执行记录,三级索引(标签+向量+时序),分层过期清理
- Semantic Memory
:知识图谱存储,三元组自动抽取,动态置信度管理
- Procedural Memory
:Skills作为记忆载体,从经验自动生成,完整的版本演化链
- Collective Memory
:三级权限模型,三阶段冲突解决,完整的版本溯源
四种记忆通过Context Engine的优先级仲裁机制协同工作,确保新任务获得全方位的记忆支撑。这不是概念——这是已经落地的、有Schema定义、有算法实现、有性能指标的工程系统。
下一篇#43,我们将深入Semantic Memory的底层引擎——知识图谱。从节点建模到图查询、从增量更新到跨图谱融合,拆解支撑Semantic Memory运转的核心基础设施。知识图谱不是可选组件——它是自进化Agent从"有记忆"到"有智慧"的关键跃迁。
专题信息
-
主题:AI原生Hermes自进化智能体系统
-
时间:2026年7月4-5日(周末)
-
形式:线上直播
-
内容方向:AI原生架构 · Hermes智能体拆解 · 全栈扩展 · 智能自动化 · 产品级实战 · Context Engine · 自进化数据层
-
17812293731

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐

 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)