
Agent 到底把哪些数据发给大模型?
Agent 到底把哪些数据发给大模型?
一篇讲清 Agent、上下文、工具信息和 Skill 工作原理的实战笔记
一、为什么要学这个
这块内容其实是 Agent 的核心。
搞清楚它,你能同时理解三件事:
- Skill 到底是怎么工作的。
- Agent 的工具为什么能被大模型“看懂”并使用。
- 对话为什么能看起来像“有记忆”,但大模型本身却是“无状态”的。
很多人学 Agent 的时候,容易只看到“会调用工具”“会记住上下文”,但没有意识到,真正起作用的是:
- 每一轮请求里,Agent 都会把一整套上下文重新组织好,再发给模型。
- 模型不是自己记住了上一轮,而是又看到了上一轮。
- 工具不是神秘能力,本质上是一份结构化说明书,告诉模型“你有哪些工具、它们怎么用、什么时候该用”。
二、先给结论
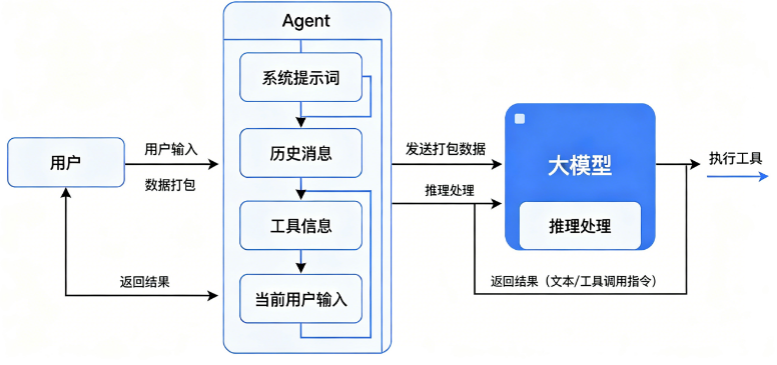
从“模型实际收到的输入”角度看,Agent 每一轮通常会发送 4 类信息:
model区:本轮使用哪个模型、推理参数是什么。system/ 系统提示词区:这轮对模型的总规则是什么。history/ 历史消息区:前面所有对话上下文。tools/ 工具信息区:有哪些工具、工具怎么调用。
更准确地说,不是把“整个世界”都发过去,而是把当前上下文窗口内、需要模型看的信息打包发过去。
如果对话太长,历史消息还可能被截断、摘要或压缩。
图 1:Agent 请求大模型的整体结构
三、四大区块分别是什么
| 区块 | 作用 | 典型内容 | 说明 |
|---|---|---|---|
| model 区 | 选择模型和推理参数 | gpt-4.1、temperature、max_tokens |
这是请求配置,不是模型“理解”的正文 |
| 系统提示词区 | 定义角色、规则和边界 | 身份、风格、优先级、约束 | 对模型影响最大,通常优先级很高 |
| 历史消息区 | 让模型看到上下文 | 过去的用户、助手、工具消息 | 让对话保持连贯 |
| 工具信息区 | 告诉模型有哪些工具能用 | 工具名、描述、参数结构 | 决定模型会不会发起工具调用 |
四、历史消息区:对话为什么能连起来
历史消息区就是把前面的对话一条条喂给模型。
一个最常见的对话长这样:
用户:你好
助手:我是一个大模型
用户:中国首都是哪
助手:北京
在请求里,这些内容通常会被组织成带 role 的消息列表:
[
{ "role": "user", "content": "你好" },
{ "role": "assistant", "content": "我是一个大模型" },
{ "role": "user", "content": "中国首都是哪" },
{ "role": "assistant", "content": "北京" }
]
role 是什么
role 的意思是:这一条消息是谁说的、在上下文里扮演什么角色。
常见角色有:
system:系统级规则,优先级最高。developer:开发者给模型的内部约束,某些平台会使用。user:用户输入。assistant:模型输出。tool:工具执行结果。
你最开始笔记里写的 user 和 assistant 是最核心的两类,但在真实 Agent 里,system 和 tool 往往也很关键。
为什么说大模型是无状态的
这里要讲得严谨一点:
- 模型本身不是像人一样“自己记得上一次说了什么”。
- 它之所以能接着聊,是因为 Agent 又把前面的消息发给它了。
- 所以,对模型来说,状态不是存在“脑子里”,而是存在上下文输入里。
这就是常说的“无状态”:
模型在每一次推理时,看到的都是一份新的输入。
图 2:一次对话的消息流
一个很重要的现实问题:上下文窗口
历史消息不是无限长的。
如果对话越来越长,会出现几个问题:
- 成本上升。
- 延迟增加。
- 超过上下文窗口后,旧消息会被截断或摘要。
所以真实 Agent 往往会配合:
- 历史摘要
- 长期记忆
- 检索增强(RAG)
- 任务状态压缩
来保持“像有记忆”,但又不至于把所有历史都原封不动塞进去。
五、系统提示词区:Agent 的总规则
系统提示词区一般负责回答这些问题:
- 你是谁?
- 你要扮演什么角色?
- 你要遵守什么规则?
- 你能不能胡编?
- 什么时候必须调用工具?
- 回复风格应该是什么?
例如:
你是一个严谨的中文助手。
回答要优先准确,其次简洁。
如果信息不足,先澄清再回答。
需要外部信息时,优先使用工具。
它的作用很像“总开关”。
如果说历史消息负责“记住发生了什么”,那么系统提示词负责“决定你该怎么做”。
六、工具信息区:大模型为什么会用工具
工具信息区是很多人第一次看 Agent 时最容易忽略、但其实最关键的一块。
它不是把工具代码直接塞给模型,而是给模型一份结构化说明,告诉它:
- 工具叫什么。
- 工具是干什么的。
- 工具需要什么参数。
- 参数怎么组织。
你笔记里写的:
namedesc
就是最简化的表达。
真实场景里通常还会有参数结构,比如:
{
"name": "search_web",
"description": "搜索网络信息,适合查最新事实、定义或外部资料。",
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "要搜索的关键词"
}
},
"required": ["query"]
}
}
工具信息区的作用
模型看到这份描述后,会判断:
- 当前问题要不要调用工具。
- 该调用哪个工具。
- 工具参数怎么填。
所以工具信息区本质上是在给模型做“能力说明书”。
七、Skill 的工作原理,为什么能理解
Skill 可以理解成一套打包好的任务能力。
它通常不是“单独魔法”,而是下面几部分的组合:
- 任务说明
- 操作步骤
- 工具描述
- 输出约束
- 示例或模板
也就是说,Skill 的工作原理,本质上还是把“怎么做”这件事写成模型能读懂的上下文或工具信息。
你可以把它理解成:
Skill = 规则 + 工具 + 示例 + 约束
当 Agent 加载某个 Skill 时,它就相当于把这份能力说明放进了模型能看到的内容里。
于是模型就能更容易判断:
- 什么时候该用这个 Skill。
- 用这个 Skill 时要遵守什么格式。
- 产出应该长什么样。
八、一次完整请求到底长什么样
下面是一个简化版请求示意:
{
"model": "gpt-4.1",
"messages": [
{
"role": "system",
"content": "你是一个严谨的中文助手。"
},
{
"role": "user",
"content": "帮我解释一下 Agent 为什么是无状态的。"
}
],
"tools": [
{
"type": "function",
"function": {
"name": "search_web",
"description": "搜索网络信息",
"parameters": {
"type": "object",
"properties": {
"query": { "type": "string" }
},
"required": ["query"]
}
}
}
],
"temperature": 0.7
}
这份请求可以拆成三层理解:
- 选哪个模型来推理。
- 这轮对话的规则是什么。
- 模型能用哪些工具。
具体工作流如下:

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐

 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)