
AI Agent如何架构选型?8个问题吃透Agent技术栈选型
从8个问题看懂Agent技术栈选型,一张图覆盖8层完整架构
所有做AI Agent的人,基本都遇到过这个问题:团队说要开发一套“智能客服”,大家立马热火朝天地挑选模型、调试Prompt、搭建基础框架。
忙活两个月,终于跑出了可用的Demo,可落地后各种问题接踵而至:对话上下文经常丢失、工具调用时稳时不稳、出了问题无从排查,想要适配新场景还得全部推倒重来。
这根本不是大模型能力不够,而是整体架构没搭对。就好比盖房子没打地基就直接砌墙,问题不在砖块质量,而是整体施工图纸出了漏洞。
这篇内容不讲晦涩抽象的分层理论,只用8个核心问题,对应Agent技术栈的8大架构层。每一个问题,都是开发Agent过程中必须敲定的关键决策,每一个决策,都有一套成熟可落地的技术方案可供选择。

问题1:你的Agent要解决什么业务问题?对应:应用层(Application Layer)
很多人做项目容易踩坑:纯靠技术驱动做产品。看到别人做AI编码工具就跟风复刻,看到别人做AI客服就照搬搭建。最后做出来的功能要么没人使用,要么和实际场景完全脱节。
用户根本不需要一个只会闲聊的机器人,他们需要的是能查订单、能处理退款、能解决实际问题的工具。
真正合理的开发逻辑,是场景驱动技术选型。先明确三个核心点:用户是谁?要解决什么实际痛点?项目落地的成功标准是什么?要记住,Agent开发的终点不是模型,而是能落地、好用的产品。
核心转变:技术驱动 → 场景驱动
技术选项(按场景划分):
AI Coding:Devin、Cursor、Claude Code
AI 客服:自建(LangGraph + RAG)
AI 数据分析:自建(Text-to-SQL)
AI 搜索:Perplexity、自建 RAG
AI 知识库:Notion AI、自建管道
AI 办公助手:ChatGPT、自建工作流
问题2:怎么让Agent不“裸奔”?对应:AI工程层(AI Engineering Layer)
很多新手开发都会犯一个错:把Prompt直接写死在代码里。项目上线后,Agent的输出就会越来越不稳定,也就是常说的“行为漂移”。
同一个问题,答案时对时错,团队没法协同迭代,没有测试机制、没有版本管理,Prompt改都不敢随便改,每次调整全靠反复试错。
正确的做法,是用软件工程的思维运营AI项目。
- Spec-Driven Development:像写PRD文档一样,明确界定Agent的角色定位、可用工具、运行约束以及输出格式;
- PromptOps:对Prompt做版本管理、线上发布、版本回滚、A/B测试,规范化迭代;
- Review Gate:Agent执行高危操作前,输出内容必须经过校验或人工审批;
- Multi-Agent协作规范:按照Planner、Researcher、Coder、Reviewer的角色明确分工,实现高效协作。
核心转变:AI原型 → AI产品
技术选项:
Spec-Driven:自建规范流程
PromptOps:LangSmith Hub、Git版本管理
Review Gate:Human-in-the-Loop流程
评估体系:LangSmith Evaluation、自建测试集
问题3:Agent的执行流程怎么编排?对应:工作流编排层(Workflow / Orchestration Layer)
不合理的开发方式,是让Agent的执行顺序完全依赖大模型的“自主判断”。出错了不会自动重试,流程卡顿没人察觉,单个子任务失败就会导致整体流程崩盘,线上运行全靠运气。
专业的落地方式,是用DAG(有向无环图)或状态机固化执行流程。通过条件路由、并行执行、故障重试与恢复、人工介入机制,全权把控流程稳定性。让大模型只专注推理决策,流程的确定性全部交给编排层负责。
核心转变:不可控单步执行 → 可控DAG工作流
技术选项:
LangGraph:适配AI Agent工作流,原生支持StateGraph、条件路由、多Agent协作
Temporal:适配通用微服务编排,稳定性强,支持长期运行工作流
Prefect:适配数据管道,原生基于Python,重试策略丰富
Airflow:适配批处理调度,生态成熟,主打定时任务场景
Dagster:适配数据资产编排,可观测性表现优异
CrewAI Flow:适配多Agent流程,和CrewAI深度适配
问题4:用什么框架搭建Agent主体?对应:Agent框架层(Agent Framework Layer)
很多团队初期会选择从零开发Agent逻辑,Prompt拼接、工具调用循环、输出解析、记忆管理等所有基础功能,全部手写代码。一个简单功能就要写几百行胶水代码,更换模型后,大半代码都要重写,效率极低。
高效的开发方式,是借助成熟框架快速落地。选一款优质的Agent框架,相当于AI开发领域的“Spring Boot”,框架会全权承接Prompt管理、工具调用、执行调度、记忆接口、输出解析等基础能力,开发者只需专注核心业务逻辑开发。
核心转变:从零造轮子 → 选用成熟Agent SDK
技术选项:
LangChain:生态最完善、集成能力最全,适配从原型开发到生产落地的全流程
LlamaIndex:数据检索能力突出,主打RAG相关场景
AutoGen:擅长多Agent对话交互,适配多智能体协作场景
CrewAI:支持角色化Agent搭建,模拟真实团队分工协作
Semantic Kernel:微软出品,对.NET环境友好,适配企业级.NET项目
DSPy:可自动优化Prompt,能对推理逻辑做精细化控制
Haystack:端到端NLP管道能力成熟,适配搜索、RAG场景
问题5:怎么让Agent学会“思考”?对应:Agent认知层(Agent Theory / Cognitive Layer)
未做认知优化的Agent,遇到复杂问题会直接仓促作答,要么直白说“不知道”,要么凭空编造错误答案,不会拆解问题、不会自查纠错、不会多维度推理,像经验不足的新人,态度到位但能力跟不上。
想要提升Agent能力,就要为其配置成熟的思维模式,让它在作答前先梳理思路、调用工具前先制定计划、输出结果前先自查反思。
核心转变:直给式回答 → 结构化推理
核心技术模式:
CoT(Chain of Thought):核心是逐步推理,适配数学运算、逻辑分析类问题
ReAct:推理与工具调用交替进行,适配需要实时查资料的复杂场景
ToT(Tree of Thoughts):多路径并行探索推演,适配创意创作、方案规划类开放场景
Reflexion:自我审视、纠错优化,适配代码编写、文案创作等可迭代任务
Plan-and-Execute:先整体规划、再分步执行,适配多步骤复杂任务
Multi-Agent认知:多智能体辩论协作,适配需要多视角分析的复杂问题
问题6:Agent上线了怎么监控和评估?对应:可观测层(Observability Layer)
很多Agent上线后完全是“黑盒状态”,用户反馈功能出错,开发者翻看日志也无法定位问题根源,分不清是模型异常、工具调用失败还是Prompt配置错误,排查问题全靠猜测,更别说效果评估和成本管控。
完善的落地方案,是为Agent搭建全维度监控仪表盘,实现链路追踪、Prompt日志记录、Token消耗统计、延迟监控、效果评估、回归测试全覆盖,做到运行状态可观测、问题可追溯、数据可分析。
核心转变:黑盒盲猜 → 全链路可观测
技术选项:
LangSmith:与LangChain原生集成,同时支持链路追踪和效果评估
LangFuse:开源友好、成本低廉,支持私有化部署
Helicone:轻量代理工具,专注API级别监控
Phoenix (Arize):开源专属LLM可观测工具
Weights & Biases:主打实验追踪与Prompt管理
问题7:Agent怎么记住用户和上下文?对应:Memory / RAG层
基础版对话机器人普遍存在“失忆问题”,每次重启对话、新会话开启后,就会清空历史上下文,记不住用户偏好、过往对话内容以及业务数据,也无法检索企业内部知识库资料。
专业的Agent需要搭建分层记忆体系,覆盖全场景记忆需求:
- 会话记忆:留存短期对话上下文,保障单次会话连贯;
- 向量检索(RAG):精准调取知识库中的相关业务资料;
- 混合搜索:结合关键词与语义双路径召回内容,提升检索准确率;
- 知识图谱:存储并推理实体之间的关联关系;
- 缓存:加速常用查询响应,降低运行延迟。
核心转变:一次性聊天机器人 → 具备持久记忆的AI工具
技术选项:
向量数据库:用于语义检索,代表产品有Pinecone、Milvus、Weaviate、Chroma、FAISS
图数据库:用于关系存储与推理,代表产品为Neo4j
混合搜索:关键词+语义召回,依托Elasticsearch+向量插件实现
会话缓存:用于短期记忆加速,核心工具为Redis
知识图谱:用于结构化知识推理,代表产品有Neo4j、Amazon Neptune
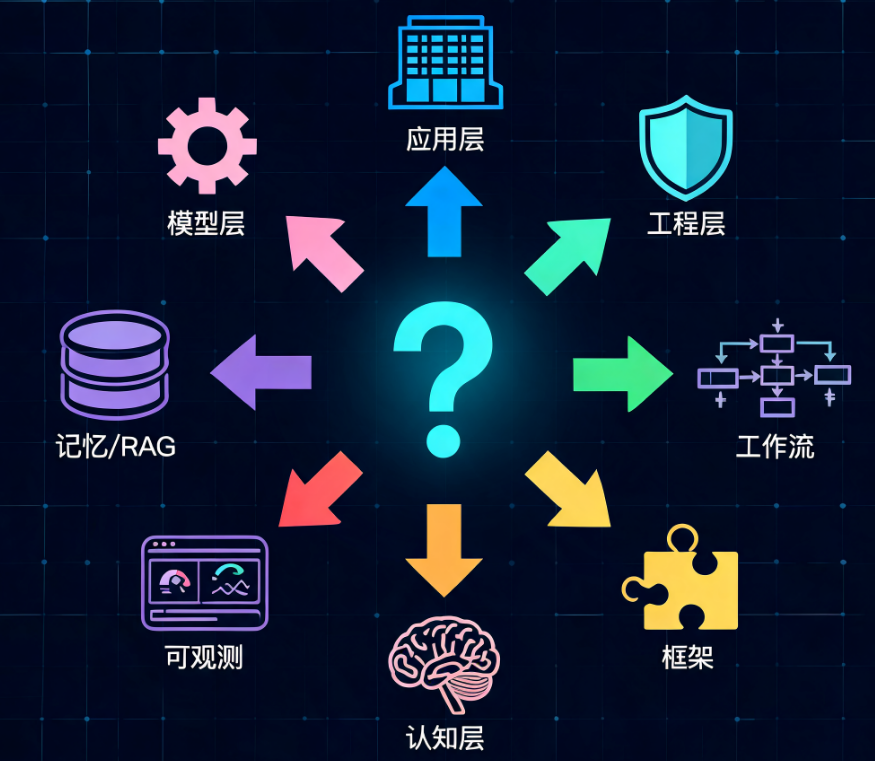
问题8:模型底座怎么选、怎么部署?对应:模型运行层(Model Runtime Layer)
很多人选型模型全凭主观感受,一味觉得GPT最贵就最好、开源模型免费但效果差,没有科学的选型标准。
最终要么模型成本居高不下,要么输出效果达不到业务要求。部署环节也随意搭建,导致推理速度慢、运行不稳定、GPU利用率极低等各类问题。
合理的落地逻辑,是根据业务场景选模型、根据项目规模做部署:
- 简单任务(内容分类、信息提取):选用小模型,最大程度节约成本;
- 复杂推理任务(代码生成、深度数据分析):选用大模型,保障输出质量;
- 高频低延迟场景:自建vLLM、TensorRT-LLM等推理引擎;
- 低频原型测试场景:直接调用API,省时省力。
核心转变:凭感觉选型 → 按场景分层选型
技术选项:
闭源API:OpenAI、Anthropic、Gemini、Grok
开源模型:Llama、Qwen、DeepSeek
推理引擎:vLLM、TensorRT-LLM、SGLang、Ollama
部署平台:Kubernetes、GPU云平台
结语
8个问题,对应8大架构层,核心逻辑一目了然:
- 解决什么业务?——应用层:技术驱动 → 场景驱动
- 怎么避免裸奔?——AI工程层:AI原型 → AI产品
- 流程怎么编排?——工作流层:单步执行 → DAG控制
- 用什么框架搭建?——框架层:造轮子 → Agent SDK
- 怎么学会思考?——认知层:直给回答 → 结构化推理
- 上线怎么监控?——可观测层:黑盒盲猜 → 全链路可观测
- 怎么记住东西?——Memory/RAG层:失忆聊天 → 持久记忆
- 模型怎么选型?——运行层:凭感觉 → 按场景分层
开展任何Agent项目时,只要逐一核对这8个问题,就能梳理出清晰的架构方案。不用纠结各类技术热点和专业名词,把这8个问题想通透,技术选型自然水到渠成。
未来Agent行业的竞争,从来都不是单一模型的比拼,而是整体系统架构的较量。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐


 1
1 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)