
阿里面试官:如何设计工业级 Skills 进化体系? 一个工业级 技能 Infra 底座如何设计?
不管是面试候选人还是线上故障复盘,有一个共性问题特别突出:绝大多数人对 Agent Skill 的理解,还停留在 “写提示词” 的初级阶段。
要么只会手写 Skill,要么写出来的 Skill 就是空架子,一用就错,甚至完全不知道 Skill 可以自动生成、自动进化。
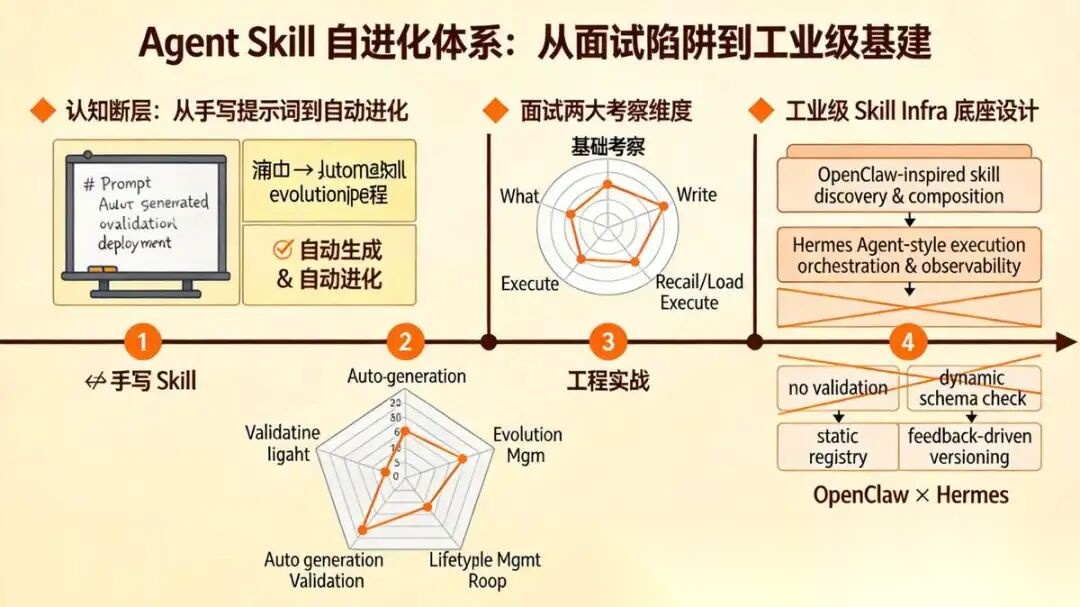
目前 Agent 面试过程中,面试官最喜欢考察与技能有关的两大类问题:
一、基础考察:到底什么是 Skill?
如何编写高质量的 Skill?
Skill 怎么被正确召回、加载和执行?
二、工程实战:如何实现工业级的 Skill 自进化体系?
今天我们站在一线架构师的角度,参考 OpenClaw 和 Hermes Agent 的架构理念,结合团队自研 Skill 引擎的踩坑经验、字节 / 阿里大厂面试标准,拆透这套自进化技能体系的底层逻辑,帮你彻底吃透这个面试必考题。
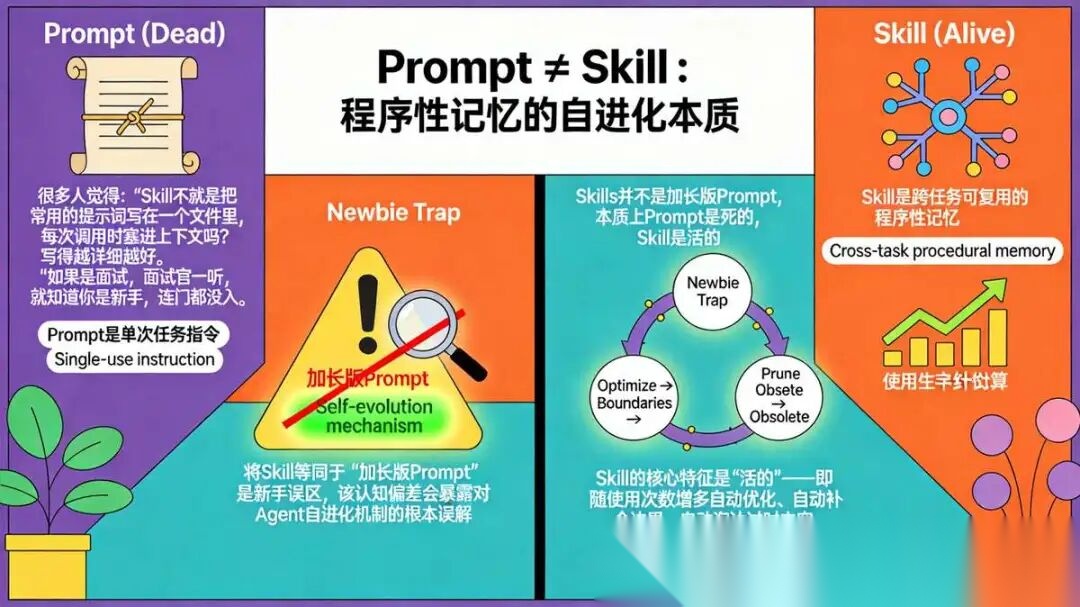
一、基础知识 :Skills 并不是 加长版 Prompt
很多人觉得:“Skill 不就是把常用的提示词写在一个文件里,每次调用时塞进上下文吗?写得越详细越好。”
如果是面试, 面试官一听, 就知道你是新手,连门都没入。
如果 Skill 只是加长版的 Prompt,那 Hermes Agent 凭什么两个月破 10 万 Star? 而且,Hermes 凭什么专门做一个 Curator 后台自学习器?
所以, Skills 并不是 加长版 Prompt , 本质上:
- Prompt 是单次任务指令,
- Skill 是跨任务可复用的程序性记忆。
更本质的区别:Prompt 是死的,Skill 是活的。
在 Hermes 这类平台里,Skill 会随着 Agent 使用次数增多自动优化、自动补全边界、自动淘汰过时内容,这才是自进化的核心。
1.1 以 撰写 AI 新技术调查报告为例 做对比:
Prompt 手工版 → 企业级标准化 Skill → 工业级自进化 Skill Infra 的完整演进链路,彻底讲透面试核心考点。
下面是一份 撰写 AI 新技术调查报告 的 【System Prompt】
你是一位资深技术分析师,请写一篇关于"[topic]"的调查报告,包含背景、技术演进、代表项目、优劣势对比、风险与落地建议。要求客观、有引用、不要太广告。
写好提示词,然后寄希望于模型这次正好搜对、引对、别漏关键项。
要知道, 写调查报告表面看是"生成任务",在企业里它实际是 多步骤研究流程(Research Pipeline):
(1) 选题/范围收敛(不能写成百科堆砌)
(2) 可信信息获取(搜索/内部知识库/论文/会议纪要)— 不是靠模型幻觉
(3) 去重 + 交叉验证(多条来源对同一事实是否一致)
(4) 结构化成文(执行摘要 / 对比维度 / 风险与落地建议 / 时间线)
(5) 引用合规(每条结论必须追溯到来源,可审计)
(6) 审阅门控(合规性、保密级别、对外发布口径)
而 上面的 Prompt 只能管第 4 步的"文风",但管不了 2/3/5/6 的稳定性 。
换句话说, 普通 Prompt 只能管控最后一步“文风优化”,完全无法保证信息获取、事实校验、合规审计、标准化输出的稳定性,而这恰恰是企业业务最核心、最看重的能力,也是 Prompt-only 方案的致命短板。
1.2. 企业级 Skill 写法:把“写调查报告”封装成标准化能力包
标准目录结构(SKILL.md 工程体系)
skills/ └─ ai_tech_investigation_report/ ├─ SKILL.md # 核心:frontmatter 元数据 + 正文指令 ├─ schema/ │ └─ report_schema.json # 输出 JSON Schema(强制结构) ├─ references/ │ ├─ source_policy.md # 信源分级规则(一级/二级/禁止) │ ├─ redline_template.md # 对外发布删减红线 │ └─ dimension_catalog.md # 对比维度字典(可跨 topic 复用) ├─ scripts/ │ ├─ search_and_collect.py # 稳定操作:调搜索/向量库/爬虫白名单 │ ├─ dedupe_and_crosscheck.py# 稳定操作:URL 归一、正文哈希、矛盾检测 │ └─ enforce_references.py # 硬校验:每结论必须有 traceable citation └─ tests/ └─ test_report_contract.py # 回归:schema 校验 + 必填 section + citation coverage
Skill 区别于 Prompt 的关键:前置元数据用于引擎快速召回匹配,完整正文与脚本用于精准执行,支持渐进式加载,不膨胀上下文。
Skill 的 核心规范文件 SKILL.md如下:(前面的 元数据负责召回,后面的 正文负责执行质量)
---name: ai_tech_investigation_reportdescription: > 针对指定 AI 新技术/框架/平台,产出标准化调查报告: 含执行摘要、技术定位、演进脉络、代表实现、对比矩阵、 风险项(安全/合规/成本/工程复杂度)、落地路线图建议与可追溯引用。 适用触发:用户明确要"调查报告/竞品调研/技术选型报告/state-of-art 综述"。 不适用的别触发:纯代码答疑、一次性总结、闲聊概览。version: "2.4.0"inputs: topic: {type: string, required: true} scope: {type: string, enum: [external, internal_only, mixed], default: external} audience: {type: string, enum: [eng, pm, exec, public], default: eng} max_sources: {type: integer, default: 20} require_primary: {type: boolean, default: true, description: "至少要有官方 docs/GitHub/论文/设计文档"}tags: [research, report, investigation, ai-tech]lifecycle: created_by: agent ttl_days: 180---## Task(Skill 交付契约,刚性约束)输出 ,必须满足:- 每个"事实结论"块都有 标注来源编号- 必须包含 表(URL / 类型 / 可信等级 / 是否有冲突)- 若 audience=exec,则必须先给 ≤6 行 ,再展开正文## Procedure(固定编排流程,禁止模型自由发挥)### Phase 0 · 准入校验- 拒绝泛化选题(如"AI 的现状"),主动反问用户收敛到具体技术、项目、版本区间### Phase 1 · 可信信息获取(脚本+工具兜底,杜绝幻觉)- 调用 批量采集信源 - arxiv论文、GitHub官方仓库、官方文档、行业顶会资料 - 无署名转载、论坛杂谈、非权威自媒体 - ### Phase 2 · 交叉验证 & 去重治理- 执行 完成URL归一、内容哈希去重- 检测多源事实冲突,标记 conflict_flag,报告中如实披露分歧,不主观选边### Phase 3 · 结构化成文(LLM在约束内生成)- 读取通用对比维度字典,统一分析标准- 严格遵循 结构生成内容- 所有事实结论强制挂载溯源引用标记### Phase 4 · 合约门控校验(最终质量兜底)- 执行 刚性校验- 结论引用覆盖率 ≥ 80%- 对外发布内容,禁止仅依靠二级低可信信源支撑- 校验失败自动回退扩源重试,最大重试2次## Examples(锚定统一输出风格) - 重点输出组件拆解、调度逻辑、故障适配模式 - 重点输出抽象层级、团队适配形态、运维成本差异## Anti-patterns(明确避坑规则,降低出错率)- 禁止全量塞入搜索原文,仅保留摘要与索引,精简上下文- 禁止模糊主观表述,所有行业结论必须带溯源引用- 禁止规避风险分析,风险研判模块为必填项,不可省略
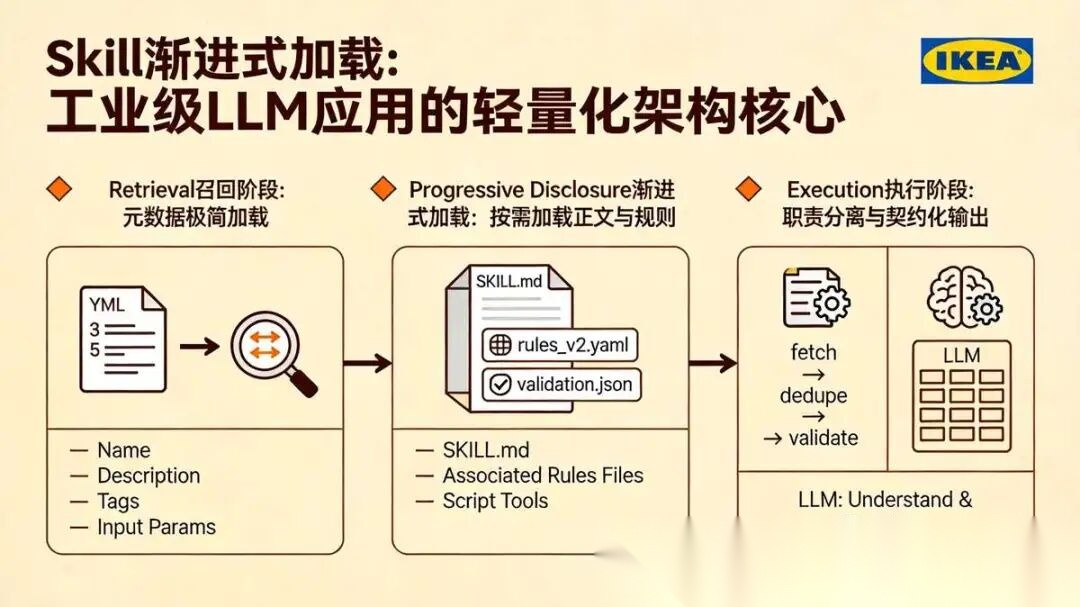
1.3 skills的 渐进式加载机制(工业级核心:不膨胀上下文)
这是面试高频加分点,彻底解释清楚「Skill 为什么比长 Prompt 更适合工业化部署」:
-
Retrieval召回阶段: 引擎仅加载几十行YAML元数据(名称、描述、标签、入参),快速完成意图匹配、技能排序,极低性能消耗;
-
Progressive Disclosure 渐进式加载: 判定用户诉求精准匹配调查报告场景后,再加载完整SKILL.md与关联规则文件;
-
Execution 执行阶段: 重复、稳定、易错的采集、去重、校验逻辑走脚本工具,LLM仅负责内容理解与结构化组织。
总结核心本质:Skill 不是更长的 Prompt,而是元数据可检索 + 正文可延迟加载 + 动作可脚本化 + 输出可契约化的程序性记忆。
第一阶段 召回(Retrieval / Matching)
- 意图信号: 命中「调查报告/技术调研/State-of-Art/竞品分析」关键词,且主题为AI技术类实体;
- 入参校验: topic参数非空,满足技能触发前置条件;
第二阶段 加载(Progressive Disclosure 渐进式加载)
load_meta() // name/desc/tags/inputs → Router 用if score(utterance, meta) > threshold: load_instructions(SKILL.md body) load_references(only those referenced by body, not all)
第三阶段 执行(Execution = 编排,不是"把文件粘进 system prompt")
- Router 层: 解析用户自然语言诉求,把零散口语, 转成标准化结构化 inputs 参数(topic/scope/audience/max_sources 等)
- Executor调度层: 按顺序推进 Phase 0→1→2→3→4,或者说 按 Phase0-Phase4 固定顺序串行推进; 不允许模型乱序、不允许跳步骤、不允许自定义流程
- Phase 1/2/4 确定性执行(Deterministic)(scripts/tools)
- Phase 3 才是 约束式 LLM 生成 ( LLM generation under constraints) ,LLM 只负责内容组织成文,全程被 schema结构 + citation溯源规则 强制绑定,不能自由发挥
最终产物:
report.mdreport_meta.json(sources信源, conflict_flags冲突标记, citation_coverage引用覆盖率, credibility_distribution, elapsed, retries重试记录)
产物 1:业务交付物 report.md
面向用户 / 业务方的最终成果:标准化、结构统一、带溯源引用、合规的 AI 新技术调查报告,是看得见的交付文档。
产物 2:工程可审计元数据 report_meta.json
面向引擎、运维、迭代体系的后台数据,是支撑Skill 自进化的核心原料,包含:
- 本次调用的所有信源列表、可信等级、冲突标记
- 引用覆盖率、有效数据源数量、重试次数
- 各阶段执行状态、耗时、成败结果
- 人工是否干预、用户隐性反馈
skill 绝非简单粘贴Prompt,而是标准化流水线编排:
真正的工业级 Skill 核心壁垒不是“写好规则”,而是可观测、可版本化、可自愈、可迭代的自进化闭环,整套体系完全对标 Hermes Agent 架构设计。
所有技能统一注册管理,留存全量版本与运行指标,杜绝黑盒迭代:
1.4 工业级 Skill 自进化体系
普通开发者只会写 Skill 规则,架构师要能搭建 Skill 自进化 Infra。
Skill 自进化不是让模型自己乱改 Prompt,而是一套「可观测数据 + 可版本注册表 + 自动化生命周期治理 + 回归评估」的闭环工程体系。
整套体系分为四层,自底向上:遥测采集 → 版本注册中心 → Curator 策展治理 → 双层 Eval 防漂移。
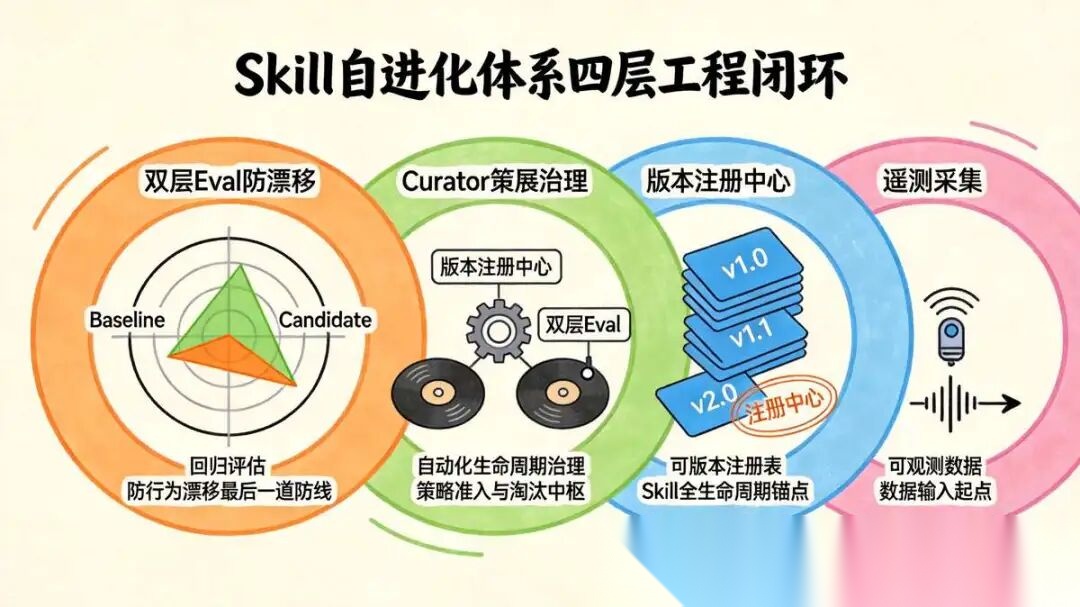
1.4.1 底层底座:Skill Registry 技能注册中心
自进化的前提是可追溯、可版本化、可量化。
所有 Skill 不允许裸奔上线,必须统一注册托管。
注册中心核心存储:Skill 唯一 ID、多版本快照、生命周期状态、运行指标、依赖关系。
# registry/skill_entry.yamlid: ai_tech_investigation_reportversions: - v: "2.4.0" sha256: xxxxxxxx created: 2026-03-12 created_by: agent state: active ttl_days: 180 metrics: n_runs: 37 n_success: 33 avg_citation_coverage: 0.86 reject_rate: 0.10 depends_on: - skills/data_source_policy
核心作用:
-
版本锁: 每次迭代生成新 Version + SHA,杜绝覆盖式改代码,支持回滚
-
状态机管理: active / stale / archived 三态流转
-
指标量化: 成功率、拒绝率、引用覆盖率、调用量,一切可量化
1.4.2 数据采集:Telemetry 全链路 监测
每一次 Skill 执行,都必须产出一条结构化事件日志,不能只有最终文本输出。
监测数据是自进化的唯一数据源。
Telemetry 就是 Skill 的监控仪表盘 + 行为日志,没有 Telemetry,自进化就没有数据依据,属于「无信号、无法迭代」。
Telemetry 采集维度:版本、执行阶段、门控结果、冲突标记、人工干预、用户反馈、重试次数。
{ "run_id": "r_20260620Txxxx", "skill_id": "ai_tech_investigation_report", "version": "2.4.0", "topic": "OpenClaw Skill 机制", "phase_transitions": ["0_ok", "1_done", "2_done", "3_done", "4_pass"], "gate_result": {"pass": true, "citation_coverage": 0.91}, "human_override": false, "feedback": null}
有了这批Telemetry 数据,系统才知道:哪个 Skill 烂、哪个场景老报错、哪条规则过时、哪类 topic 信息采集不全。
1.4.3 自动治理核心:Curator 维护 组件(Hermes 核心思想)
Curator 是后台常驻治理组件,不训练模型、不更新权重,只治理 Skill 资产,周期扫描并自动完成技能迭代与生命周期管理。
Curator 四大核心治理能力:
1)状态巡检与过期归档 - 30天零调用: 标记 stale(失活) - 90天持续失活: 自动 archived(归档) - 策略: 只归档、不删除,保留快照,支持回滚
2)冗余技能合并治理
- 通过 Embedding 语义相似度 + 入参结构对比,识别重复、重叠 Skill
- 自动产出 Merge 合并建议,避免技能仓库臃肿、误召回冲突
3)质量缺陷复盘与补丁迭代
- 监控 reject_rate、引用覆盖率不达标、高频报错场景
- 自动分析根因: 是描述不准、触发范围过泛、采源策略缺失、还是规则老旧
- 自动生成 Skill Patch 补丁(修正description、调整phase )
4)安全灰度兜底
- 所有自动迭代默认 dry_run 试运行
- 人工核心 Skill 禁止自动修改,仅 Agent 产出的规则可自治迭代
- 每次迭代留存快照,可一键回滚
核心哲学(面试必背):自进化不是自由进化,是 可审计状态机 + LLM 智能建议 + 刚性规则保护。
1.4.4 防漂移兜底:双层 Eval 评估体系
自进化最大风险是 能力漂移、越迭代越烂。
必须双层校验锁死质量。
1)高速契约测试(CI 极速校验)
每次 Skill 更新立即自动化校验:
- Schema 结构合法性
- 必填章节完整性
- 引用覆盖率达标
- 反模式不违规
作用:杜绝低级语法、规则、结构错误。
2)黄金样本回归测试(版本迭代防退化)
固定 10~20 个行业标准 AI 技术调研 Topic 作为 Golden Set 基准集。
每一次 Skill 版本升级,全量回归对比:
- 是否丢失原有正确结论
- 引用质量是否下降
- 风险研判是否缺失
作用:彻底解决「自主进化导致能力退化」的工业级痛点。
1.4.5 最终闭环:工业级自进化完整链路
用户调用 Skill → Telemetry 产出运行数据 → Registry 记录版本与指标 → Curator 周期治理迭代 → Eval 双层校验防漂移 → 新版本上线闭环。
这也是工业级 Skill 和 手写 Prompt、普通 Skill 的本质区别:Prompt 靠人维护,工业 Skill 靠数据与工程体系自我迭代。
二.skills 四大误区辟谣:绝大部分候选人都答错了
先把几个流传最广的错误认知拍死,这些都是面试里一开口就扣分的雷区。
2.1 误区 1:Skill 写得越全越好,越多越专业
“把所有能想到的规则都写进去,覆盖的场景越多,这个 Skill 就越强大。系统里攒几百个 Skill,Agent 就无所不能。”
这是典型的 “上下文污染” 思维。
很多 团队落地时踩过这个大坑:一口气写了 50 多个 Skill,每次任务全量塞进上下文,结果:
- Token 消耗暴涨 3 倍
- 模型注意力分散,反而频繁选错 Skill
- 规则冲突时模型无所适从
- 出了问题根本不知道是哪个 Skill 搞的鬼
工业级标准:Skill 不是越多越好,是越准越好。
好的 Skill 系统,90% 的时间只加载 1-2 个最相关的 Skill,其余只存索引,按需加载。
2.2 误区 3:Skill 写完就完事了,不用管后续迭代
“Skill 就是个配置文件,写完往目录里一扔,Agent 就能用了。一劳永逸。”
这是把 Skill 写成了 “技术债务”。
业务会变、工具会升级、模型能力会进化、用户反馈会带来新的边界 case。
一个写死的 Skill,三个月后就会变成:
- 描述的工具参数早已过时
- 覆盖的场景早已不是主流
- 没处理的边缘 case 越来越多
- 反而成为 Agent 犯错的根源
真正的 Skill 系统,核心不是 “写 Skill”,而是 “进化 Skill”。
从轨迹采集、自动蒸馏、反馈迭代到质量评估,这是一整套闭环,不是单个文件。
2.3 误区 4:Skill 可以替代工具治理和安全管控
“在 Skill 里写清楚 ’ 删除文件前要确认 ‘、’ 不要编造事实 ',就能保证安全了。”
这是把软约束当成了硬边界。
Skill 是给模型看的 “操作手册”,模型可以选择遵守,也可以选择忽略。
真正的高风险动作:删除文件、调用付费 API、访问生产数据、执行系统命令,这些必须在 Tool Registry、Harness 层做硬拦截,加审计日志,加人工审批。
只把安全写在 Skill 里,就像在高速公路旁立个 “请勿超速” 的牌子,却不装摄像头和限速带。
2.4 误区 5:Skill 召回靠模型自己判断就行
“把所有 Skill 的描述都写进系统提示词,让大模型自己判断该用哪个。”
这是最不稳定的设计。
模型选 Skill 的准确率,我们实测只有 60%-70%,经常出现:
- 相似任务误召回(比如把 “代码优化” 当成 “代码生成”)
- 高风险 Skill 被误触发
- 多个 Skill 同时命中造成冲突
生产级方案:Harness 统一管控 Skill 注入。
先做语义匹配算置信度,低于阈值的要用户确认,高风险 Skill 必须显式授权。
2.5 六大组件 Tool、Skill 、Harness、 MCP 、Memory、Prompt 的概念边界
讲完误区,先把最基础的概念边界理清楚。
面试第一题基本都是这个,答清楚边界,面试官就知道你不是新手。
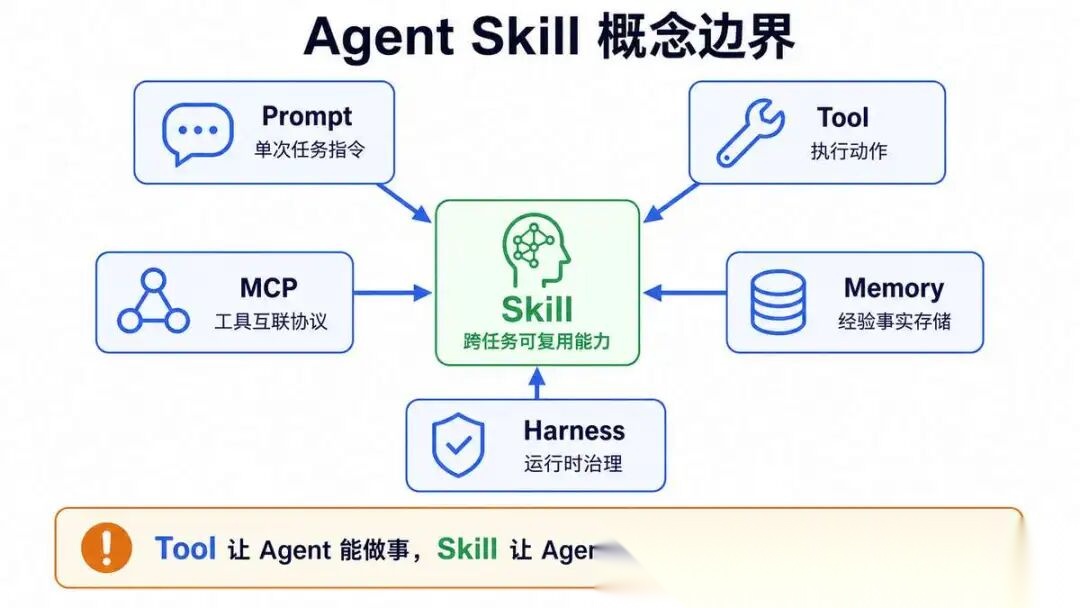
六维概念边界对比表
| 概念 | 核心定位 | 解决的问题 | 边界特征 | 生命周期 |
|---|---|---|---|---|
| Prompt | 单次任务指令 | 这次任务怎么做 | 一次性、静态、无进化 | 任务结束就失效 |
| Skill | 局部可复用能力 | 这类任务以后都怎么做 | 跨任务、动态、可进化 | 长期存在,持续迭代 |
| Tool | 执行动作能力 | 能不能做这件事 | 只负责执行,不负责判断 | 相对稳定 |
| MCP | 工具接入协议 | 工具怎么互联互通 | 只负责标准化,不负责业务逻辑 | 协议级稳定 |
| Memory | 经验事实存储 | 记住发生过什么 | 存材料,不存执行方法 | 长期存储 |
| Harness | 全局运行时治理 | 整个系统怎么跑稳 | 硬约束、权限、审计、生命周期 | 系统级稳定 |
一句话总结边界,面试就这么说:
Tool 让 Agent 能做事,Skill 让 Agent 会做事,Harness 让 Agent 不出事,MCP 是一般是远程工具,Memory 是笔记本,Prompt 是临时便签。
- Skills 底座的注册中心:从文件到运行时的完整链路
Skill 写完往目录里一扔,Agent 是不会自动发现的,必须有一套注册机制。
Skill 系统的本质矛盾是:Skill 库越大能力越强,但上下文窗口有限,全量塞进去必然爆掉。
解决思路就一句话:注册时全量入库,运行时按需加载,执行时才展开全文。
OpenClaw、Hermes 都有 Skill 注册中心,核心都在做这件事——让 200 个 Skill 的系统,常驻上下文只有 500 Token,需要时才逐层展开。
3.1 Skill 的注册机制:让系统知道有哪些 Skill 可用
三种主流注册方式
方式一:文件系统扫描注册(OpenClaw 模式)
最朴素也最实用:约定一个目录结构,启动时扫描所有 .md 文件,解析 frontmatter 元数据,注册到 Skill Registry。
~/.agent/skills/├── resume-review.md # 简历点评 Skill├── code-review.md # 代码 Review Skill├── api-500-debug.md # 接口 500 排查 Skill└── deploy-app/ # 伞状 Skill 目录 ├── deploy-app.md # 主 Skill ├── docker-deploy.md # 子 Skill └── k8s-deploy.md # 子 Skill
每个 Skill 文件的 frontmatter 里写元数据:
---name: resume-reviewdescription: 简历项目经历点评与优化domain: hrrisk_level: R1version: 1.2tags: [简历, 求职, 点评]last_used: 2026-06-15status: active---
OpenClaw 就是这个思路,启动时扫描工作区,把所有 Skill 文件注册到索引里,同时建立 SQLite 全文检索索引,支持后续的语义匹配和关键词检索。
方式二:配置文件集中注册(Hermes 模式)
Hermes 更偏向有界管理,用一个集中配置文件管理所有 Skill 的元数据,Skill 正文可以是独立文件,也可以是配置内联:
{ "skills": [ { "name": "resume-review", "path": "skills/resume-review.md", "domain": "hr", "risk_level": "R1", "enabled": true }, { "name": "deploy-production", "path": "skills/deploy-production.md", "domain": "devops", "risk_level": "R3", "enabled": true, "requires_confirm": true } ]}
好处是管控集中,坏处是新增 Skill 要改配置。
方式三:动态注册(运行时热加载)
工业级系统必须支持运行时动态注册,不重启 Agent 就能新增 Skill。
蒸馏层自动生成的新 Skill、Curator 后台合并的伞状 Skill,都要通过动态注册接口注入:
class SkillRegistry: def register(self, skill: Skill, source: str = "manual"): """动态注册一个 Skill source: manual(手动) / auto(自动蒸馏) / merged(合并生成) """ skill.metadata.source = source skill.metadata.registered_at = datetime.now() self._skills[skill.name] = skill self._rebuild_index(skill) # 重建检索索引 self._audit_log("register", skill.name, source)
动态注册必须做两件事:重建检索索引(让新 Skill 能被召回)、写审计日志(追溯来源)。
注册时的三层校验
注册不是无脑接收,必须做三层校验:
【1】Schema 校验: 九要素是否齐全,“不适用场景” 不能为空
【2】安全扫描: 正则 + LLM 双重扫描,拦截恶意指令、数据外泄、破坏性命令
【3】冲突检测: 和已有 Skill 做相似度比对,相似度 > 0.85 的拒绝注册,提示合并
很多小伙伴 没做冲突检测,结果技能库里同时存在 deploy-docker、deploy-k8s、deploy-vercel 三个高度相似的 Skill,召回时三个一起命中,模型直接懵圈。
这种场景,必须加上冲突检测,强制要求合并为伞状 Skill deploy-app,问题就会解决。
3.2 Skill 的加载机制:三层渐进式加载
这是 Hermes 的核心设计,也是面试常考点,绝对不是把所有 Skill 全塞进上下文。
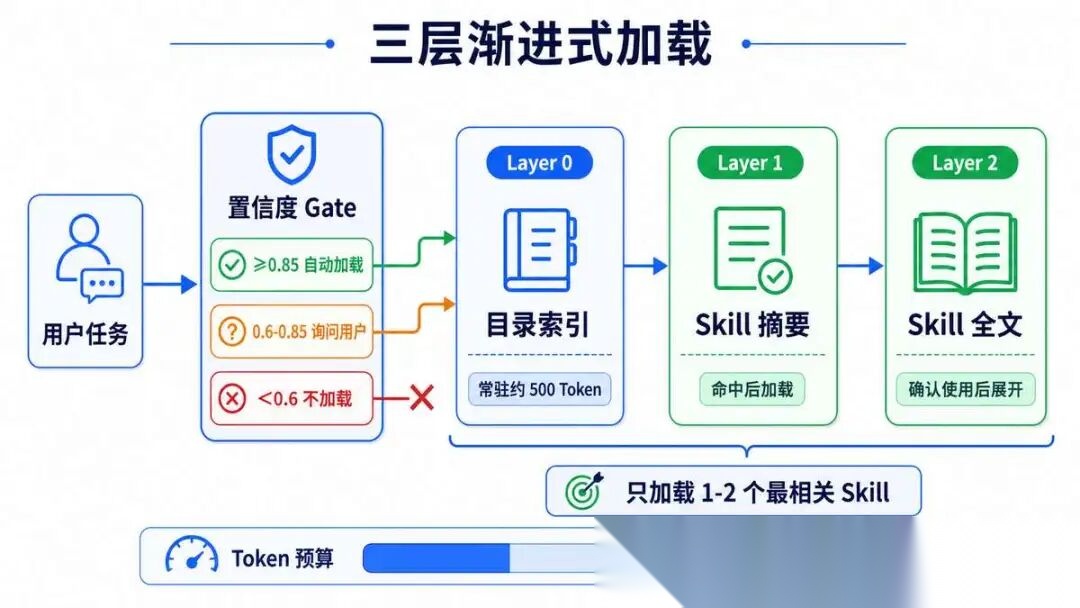
Layer 0:Skill 目录索引(常驻,~500 Token) ↓ 只有名称、一句话描述、分类标签 ↓ 用户任务进来,先匹配索引,算置信度Layer 1:Skill 摘要(命中后加载,~300 Token) ↓ 适用场景、核心流程、主要边界 ↓ 判断是不是真的需要这个 SkillLayer 2:Skill 全文(确认使用后加载,~1000 Token) ↓ 完整步骤、详细规则、异常处理 ↓ 真正执行时才展开全文
效果:就算有 200 个 Skill,常驻上下文也只有 500 Token,需要时才逐层展开。
工业级系统技能再多也不爆上下文,秘密就在这里。
三层加载的具体实现
class SkillLoader: def (self, registry: SkillRegistry): self.registry = registry self._index_cache = None # Layer 0 缓存 self._summary_cache = {} # Layer 1 缓存 self._full_cache = {} # Layer 2 缓存(LRU) def load_index(self) -> str: """Layer 0:加载所有 Skill 的索引摘要,常驻上下文""" if self._index_cache is None: lines = [] for skill in self.registry.all_skills(): lines.append(f"- {skill.name}: {skill.one_liner_desc} [{skill.domain}]") self._index_cache = "\n".join(lines) return self._index_cache def load_summary(self, skill_name: str) -> str: """Layer 1:命中后加载 Skill 摘要""" if skill_name not in self._summary_cache: skill = self.registry.get(skill_name) self._summary_cache[skill_name] = skill.render_summary() return self._summary_cache[skill_name] def load_full(self, skill_name: str) -> str: """Layer 2:确认使用后加载完整 Skill""" if skill_name not in self._full_cache: skill = self.registry.get(skill_name) self._full_cache[skill_name] = skill.render_full() self._touch_usage(skill_name) # 更新使用统计 return self._full_cache[skill_name]
关键设计点:
- Layer 0 常驻,只在 Skill 库变更时重建
- Layer 1 按需加载,命中后缓存
- Layer 2 用 LRU 缓存,控制内存占用,同时更新使用统计(驱动后续的状态机流转)
3.3 Skill 的召回机制:四层过滤,层层把关
面试官特别爱问:“Skill 多了以后怎么选?怎么避免上下文污染?”
很多人说 “让模型自己选”, 这就是典型的玩具级思维,生产环境这么搞必崩。
四种召回方式对比
| 召回方式 | 实现方式 | 准确率 | 灵活性 | 适用场景 |
|---|---|---|---|---|
| 显式指定 | 用户或系统直接指定用哪个 | 100% | 最低 | 后台任务、固定流程 |
| 任务描述匹配 | 根据用户输入语义匹配 Skill 描述 | ~70% | 中等 | 通用场景 |
| Metadata 检索 | 根据 Skill 元数据(领域、类型、风险)检索 | ~85% | 较高 | 生产环境 |
| Harness 控制注入 | 全局路由根据任务类型、权限、风险等级注入 | ~95% | 最高 | 工业级标准 |
工业级标准做法:四层召回机制,层层过滤
用户任务输入 ↓【第 1 层】任务类型粗筛 ↓ 排除明显不相关的 Skill(按 domain、tags 过滤)【第 2 层】风险等级过滤 ↓ 高风险 Skill 必须显式授权,未授权的直接排除【第 3 层】向量相似度计算 ↓ 算置信度,> 0.85 自动加载,0.6-0.85 询问用户,< 0.6 不加载【第 4 层】Harness 统一管控注入 ↓ 结合用户权限、当前会话上下文、冲突裁决,最终决定注入哪些 Skill
为什么必须四层而不是一层?
我们踩过的坑:
-
只做语义匹配: 相似任务误召回严重,“代码优化” 和 “代码生成” 经常搞混
-
只做 Metadata 检索: 覆盖率高但精度不够,召回一堆相关但不精确的 Skill
-
加上风险过滤: 杜绝了高危 Skill 被误触发的事故
-
加上 Harness 管控: 解决多 Skill 同时命中的冲突问题
召回的置信度阈值设计
置信度阈值不是拍脑袋定的,是 A/B 测试跑出来的: - > 0.85: 自动加载,不打扰用户 - 0.6 - 0.85: 询问用户 “检测到可能相关的 Skill,是否使用?”
- < 0.6: 不加载,但记录日志用于后续优化
很多开发团队, 早期把阈值定在 0.7,结果误召回率高达 15%;调到 0.85 后误召回率降到 3%,但漏召回率上升了。
最终方案是:高风险 Skill 阈值提到 0.9,低风险 Skill 维持 0.85,兼顾安全和覆盖。
3.5 Skill 的执行引擎:从加载到执行的全流程
Skill 加载进上下文后,怎么保证 Agent 真的按 Skill 执行?
执行引擎的三大核心能力
能力一:执行轨迹追踪
Skill 执行过程中,引擎要全程记录:每一步是否按 Skill 规定的流程走、有没有偏离、工具调用对不对、输出格式符不符合要求。
这些轨迹数据, 是后续 GEPA 进化闭环的原材料。
class SkillExecutor: def execute(self, skill: Skill, task_context: TaskContext): trace = SkillTrace(skill_name=skill.name, version=skill.version) for step in skill.steps: result = self._run_step(step, task_context) trace.add_step( step_id=step.id, expected=step.expected_action, actual=result.action, deviation=result.deviation_score, success=result.success ) if result.deviation_score > 0.3: trace.add_warning(f"步骤 {step.id} 偏离 Skill 规定流程") trace.finalize() self.trace_store.save(trace) return trace
能力二:偏离检测与纠偏
执行过程中如果检测到 Agent 偏离了 Skill 规定的流程,引擎可以做软纠偏:在下一轮推理时注入提醒 “你正在执行 XXX Skill,请按步骤 Y 操作”。
注意是软纠偏不是硬拦截——Skill 是操作手册不是代码约束,硬拦截会破坏 Agent 的灵活性。
能力三:执行结果评估
执行完成后,引擎自动做多维度评估:
- 有没有按 Skill 规定的流程走?
- 有没有触发 Skill 没覆盖的边界 case?
- 用户有没有修正?
修正了什么?- 最终结果有没有达到质量标准?
这些评估结果直接喂给进化层,驱动 Skill 迭代。
执行引擎与工具调用的协作
Skill 里规定的工具使用策略,要和 Tool Registry 联动。
比如 Skill 里写了 “失败时重试 3 次”,执行引擎就要把这个策略下发给 Tool Orchestrator,让工具调用层按这个策略执行。
这也是为什么 Skill 不能替代 Tool Registry 的原因:Skill 写的是 “应该怎么做”(软策略),Tool Registry 执行的是 “实际怎么做”(硬执行),两层各司其职。
3.6 上下文治理的五大原则
【1】最小必要原则: 只加载当前任务真正需要的 Skill,最多同时加载 2 个
【2】优先级原则: 系统安全 > 项目规则 > 任务 Skill > 用户偏好
【3】作用域原则: 局部 Skill 不要影响全局任务
【4】过期淘汰原则: 连续 30 天没人用的 Skill 自动归档
【5】冲突裁决原则: 规则冲突时,高优先级覆盖低优先级,平级问用户
- 工业级标准:四层自进化skills Infra 底座架构总览
这一章是整个面试的核心。
能把四层架构讲清楚,面试基本就拿下了。
很多人讲 Skill,就只讲怎么写 Skill,这就是只看到了冰山一角。
真正的工业级系统,是一整套从数据采集到治理的完整闭环。
为什么是四层?为什么不是三层 / 五层?
这是经过大量工程实践验证的最优分层,每一层解决一个不可替代的核心问题:
【1】没有感知层: Skill 只能人工手写,永远做不到自进化
【2】没有蒸馏层: 有数据也提炼不出有用的 Skill,数据就是垃圾
【3】没有进化层: Skill 写完就死了,三个月后就过时
【4】没有治理层: Skill 系统很快就乱成一锅粥,没人敢用
少一层就缺一块能力,多一层就增加不必要的复杂度: 这就是四层架构的精妙之处。
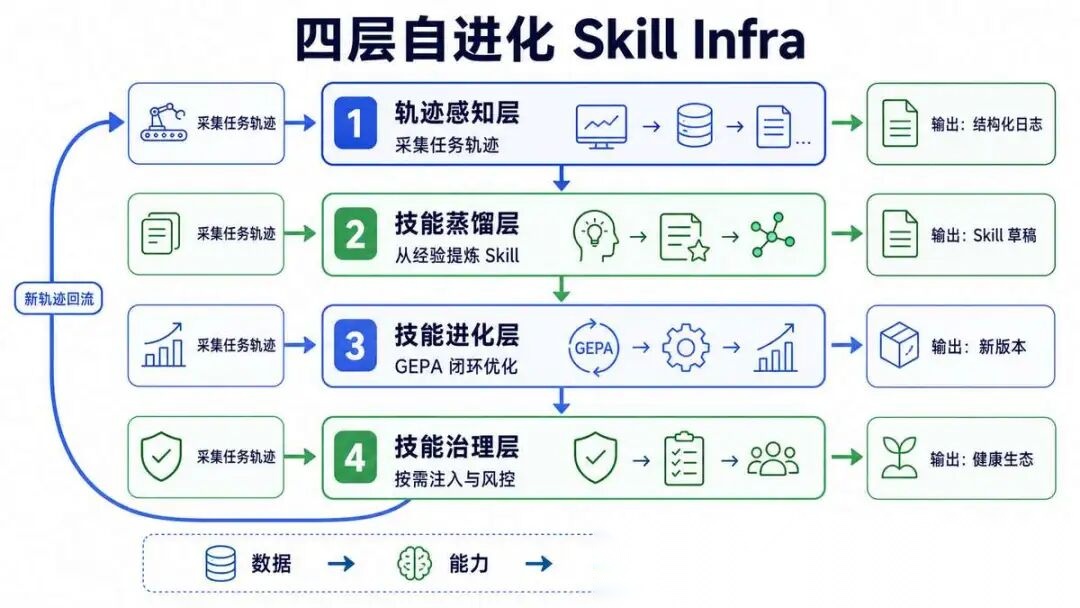
把整个数据流串起来,你就懂了:
用户输入任务 ↓【感知层】采集完整轨迹 → 结构化存储 → 计算任务指纹 ↓ ├─→ 相似任务 < 3 次 → 正常执行,继续积累数据 │ └─→ 相似任务 ≥ 3 次 → 触发蒸馏 ↓【蒸馏层】聚类 → 抽象 → 补边界 → 生成初版 Skill ↓ ├─→ 审核不通过 → 打回,继续积累更多数据 │ └─→ 审核通过 → 进入 Skill 库 ↓【进化层】用户使用 → 收集反馈 → 自动评估 → 打补丁更新 ↓ ├─→ 效果变好 → 继续使用 │ └─→ 效果变差 → 回滚到上一版本 ↓【治理层】按需加载 → 冲突裁决 → 版本管理 → 质量监控 → 过期淘汰 ↓ └─→ 产生新的轨迹数据 → 回到感知层 → 进入下一轮循环
这就是一个完整的、永不停歇的自进化飞轮。
每一次用户使用,都是在给系统投喂数据,都是在让系统变得更好。
四层架构总览表
| 层级 | 核心定位 | 输入 | 输出 | 核心价值 | 典型技术栈 | 主要风险 |
|---|---|---|---|---|---|---|
| 轨迹感知层 | 全链路数据采集 | 用户交互、工具调用、修正记录、失败案例 | 结构化轨迹日志 | 所有进化的原材料 | SQLite FTS5、Trace 系统、事件总线 | 数据噪音、隐私泄露、存储膨胀 |
| 技能蒸馏层 | 从经验提炼能力 | 结构化轨迹、相似任务聚类 | 初版 Skill 草稿 | 从 0 到 1 生成 Skill | LLM 蒸馏、DSPy 优化、聚类算法 | 过度抽象、边界不清、质量参差不齐 |
| 技能进化层 | GEPA 闭环优化 | 用户反馈、执行结果、失败案例 | 迭代优化后的 Skill | 从 1 到 N 越来越好 | Curator 后台、A/B 测试、反馈引擎 | 过度修正、回归问题、版本混乱 |
| 技能治理层 | 全局管控运维 | Skill 元数据、调用日志、评估指标 | 健康的 Skill 生态 | 系统可控可运维 | 版本管理、权限控制、生命周期管理 | 上下文污染、规则冲突、僵尸 Skill |
- 第一层:轨迹感知层:所有进化的起点
这一层, 全链路、无侵入地采集 Agent 执行过程中的所有有价值信息,为后续技能沉淀提供原材料。
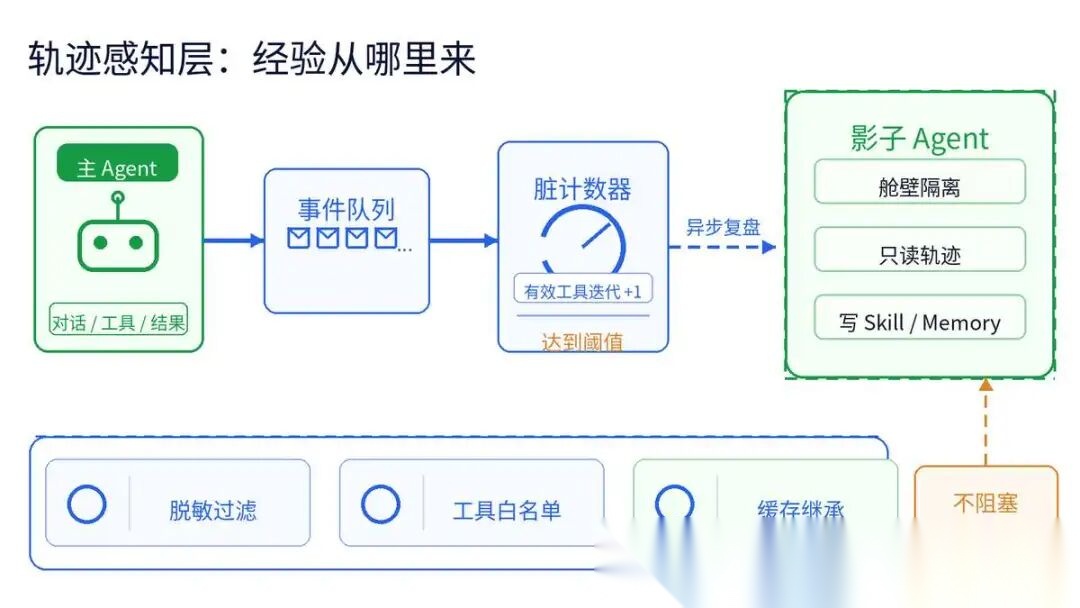
采集标准:五类核心数据
| 数据类型 | 采集内容 | 用途 |
|---|---|---|
| 任务轨迹 | 完整对话历史、每一步 Thought、Action、Observation | 还原完整执行流程 |
| 工具调用 | 工具名、参数、返回结果、耗时、成功 / 失败状态 | 提炼工具使用最佳实践 |
| 用户修正 | 用户打断、纠错、补充说明、重新指令 | 发现 Skill 的边界缺陷 |
| 执行结果 | 最终输出、是否完成目标、人工评价 | 评估 Skill 效果 |
| 异常事件 | 循环卡死、工具报错、格式错误、幻觉内容 | 补充失败处理规则 |
5.1 触发机制设计:脏计数器(Dirty Counter)
轨迹感知层面临的第一个设计决策:什么时候该触发经验复盘?
每次会话结束都反思,资源消耗过高;完全不反思,经验无法沉淀。
用固定对话轮数触发也不靠谱:
- 3 轮简单对话可能只调了 2 次工具(无经验可沉淀),
- 1 轮复杂部署任务可能包含 15 次工具迭代(沉淀价值极高)。
工业级解法是脏计数器:本质是任务有效工作量累加器,仅统计实际工具调用迭代次数,不统计对话轮数。
工具迭代数才是"做了多少事"的精确度量,与经验沉淀价值高度正相关。
每 N 次有效工具迭代自动触发一次异步复盘。
5.2 隔离机制设计:影子 Agent 舱壁隔离
轨迹感知层面临的第二个设计决策:复盘操作怎么做到不干扰主会话? , 直接在主会话线程中执行复盘,会污染上下文、阻塞响应、产生安全风险。
工业级解法是 fork 一个影子 Agent——继承父 Agent 的运行时配置(模型、凭证、缓存),但运行在严格隔离的沙盒里,就像赛后复盘的教练,只能"读对话、写技能/记忆",别的什么都干不了。
影子 Agent 的舱壁隔离策略需要覆盖六个维度:
【1】记忆隔离: 跳过外部记忆插件,防止复盘内容泄漏到用户记忆空间
【2】递归防护: 禁止影子 Agent 再产生影子 Agent,杜绝无限套娃的资源耗尽
【3】工具白名单: 只开放记忆和技能管理工具,拦截所有高危工具
【4】危险命令自动拒绝: 后台线程无用户交互渠道,高风险命令直接拦截不弹审批
【5】前端输出隔离: 屏蔽复盘中间状态日志,仅向用户展示最终结果
【6】日志隔离: 吞掉所有冗余控制台输出,避免敏感信息泄露
架构上这叫舱壁设计模式(Bulkhead Pattern):各跑各的,一个炸了不牵连别人。
这是分布式系统中的经典容错模式,应用到 Agent 复盘场景同样适用。
5.3 成本优化设计:缓存继承
轨迹感知层面临的第三个设计决策:异步复盘的 API 成本怎么控?
容易被忽视但极其重要:影子 Agent 应当继承父 Agent 的系统提示词缓存。
主流大模型平台均有前缀缓存机制,请求前缀一样就命中缓存,跳过重复计算。
如果影子 Agent 重建系统提示词(新的时间戳、新的会话 ID),缓存命中率归零,每次反思都是全价 API 调用。
继承缓存后,影子 Agent 的出站请求命中同一个缓存 key。
业界实测数据显示,这一设计可带来约 26% 的端到端算力成本降低。
一天触发 20 次复盘就是 20 次 API 调用的节省,长期累积效果显著。
额外的防御性细节:即使继承了缓存,也需要把会话启动时间和会话 ID 固定下来,防止代码逻辑迭代、提示词压缩等场景导致字节级不匹配,100% 保障缓存命中稳定性。
6、第二层:技能蒸馏层:从经验到能力的跃迁
这一层是最体现技术含量的。
有了数据,怎么从一堆杂乱的轨迹里,自动提炼出高质量、可复用的 Skill?
人工写 Skill 靠的是专家经验,自动蒸馏 Skill 靠的是算法 + 大模型的结合。
这也是面试官区分普通开发和架构师的地方。
6.1 核心设计思想
把 “Agent 这次是这么做成功的”,变成 “以后这类任务都这么做”。
核心难点三个:
(1) 怎么从大量相似任务中找出共性?
(2) 怎么把具体场景的步骤,抽象成通用的流程?
(3) 怎么保证蒸馏出来的 Skill 不是空架子,真的能用?
6.2 核心定位
从大量相似的成功执行轨迹中,抽象出通用、稳定、可复用的任务执行流程,生成标准化的 Skill 文档。
6.3 GEPA 蒸馏四步法(面试必背)
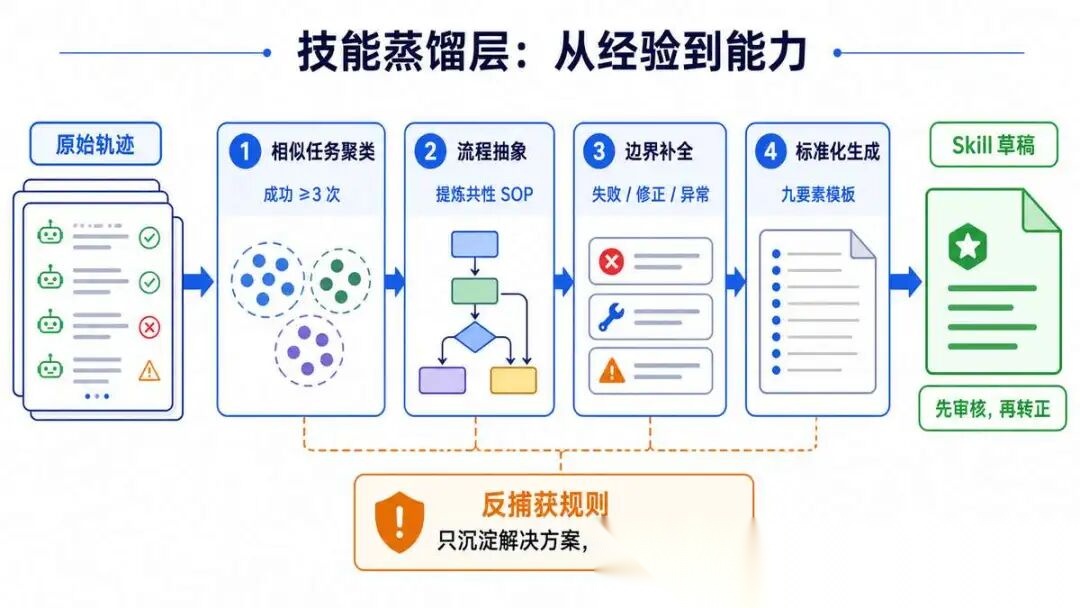
第一步:相似任务聚类
- 计算任务嵌入向量,用余弦相似度找相似任务
- 同一个模式累计成功 3 次以上,触发蒸馏条件
- 过滤掉单次、偶然、不可复用的特殊情况
第二步:流程抽象与泛化 - 输入: 3-5 条相似的完整执行轨迹
- 让 LLM 找出共性步骤,去掉具体场景的细节
- 区分 “必须做的” 和 “可选做的”
- 提炼出通用的 SOP 框架
第三步:边界与异常补全
- 这是最容易被忽略,但最关键的一步
- 从失败案例、用户修正里提炼: 什么情况不能用这个 Skill?
- 信息不足怎么办?
工具失败怎么办?
结果不对怎么办?
- 没有这一步,蒸馏出来的 Skill 就是个空架子
第四步:标准化 Skill 生成
- 严格按照九要素清单生成
- 自动生成元数据: name、domain、version、risk_level
6.4 实战案例:接口 500 排查 Skill 是怎么蒸馏出来的
比如, 用户连续三次让 Agent 排查 Python 接口 500 错误,
每次 Agent 都是:先看错误日志 → 搜相关代码 → 检查最近变更 → 复现验证 → 给出修复方案
蒸馏层自动把这个流程提炼成 “接口 500 排查 Skill”
同时补充边界:不要直接改生产代码、信息不足时要用户提供日志路径、不要猜测根因
6.5 关键机制:四级技能迭代优先级链
蒸馏新 Skill 时,系统应严格遵循**“优先迭代存量资产、最低成本沉淀能力”**的原则,四级优先级从高到低:
| 优先级 | 动作 | 具体做法 | 适用条件 |
|---|---|---|---|
| 1 | 迭代当前会话已加载的 Skill | 补充新经验、优化触发条件、完善执行流程 | 本次任务使用过的 Skill |
| 2 | 迭代已有伞状 Skill | 将新场景经验补充为子模块 | 技能库中存在覆盖面广的同类 Skill |
| 3 | 新增支撑文件 | 沉淀为参考文档、模板、脚本等支撑资产 | 窄维度经验,无通用复用价值 |
| 4 | 新建品类级伞状 Skill | 命名覆盖一类任务,禁止单次任务碎片化命名 | 技能库无任何匹配场景时 |
6.7 对比表格:自动蒸馏 vs 人工编写
| 维度 | 自动蒸馏 | 人工编写 |
|---|---|---|
| 生成速度 | 快,几分钟一个 | 慢,几小时一个 |
| 贴合真实场景 | 都是真实跑通的 | 容易拍脑袋 |
| 质量稳定性 | 参差不齐 | 质量可控 |
| 规模化能力 | 理论上无限 | 人工瓶颈明显 |
| 边界完整性 | 需要人工补全 | 专家考虑更周全 |
- 第三层:技能进化层:GEPA 学习闭环的核心
这一层是整个自进化系统的灵魂,也是自进化 Agent 和传统 Agent 最本质的区别。
7.1 核心设计思想
Skill 不是写完就结束了,而是每次使用都是一次进化的机会。
人类专家也是这样:第一次做这件事可能做得一般,做多了就越来越熟练,踩过的坑越来越多,处理异常的经验越来越丰富。
GEPA 闭环就是让 Agent 也具备这种学习能力。
7.2 核心定位
基于真实使用反馈、执行结果、用户修正,持续迭代优化 Skill,形成 “使用 → 反馈 → 优化 → 更好用” 的正向闭环。
7.3 完整的 GEPA 学习闭环
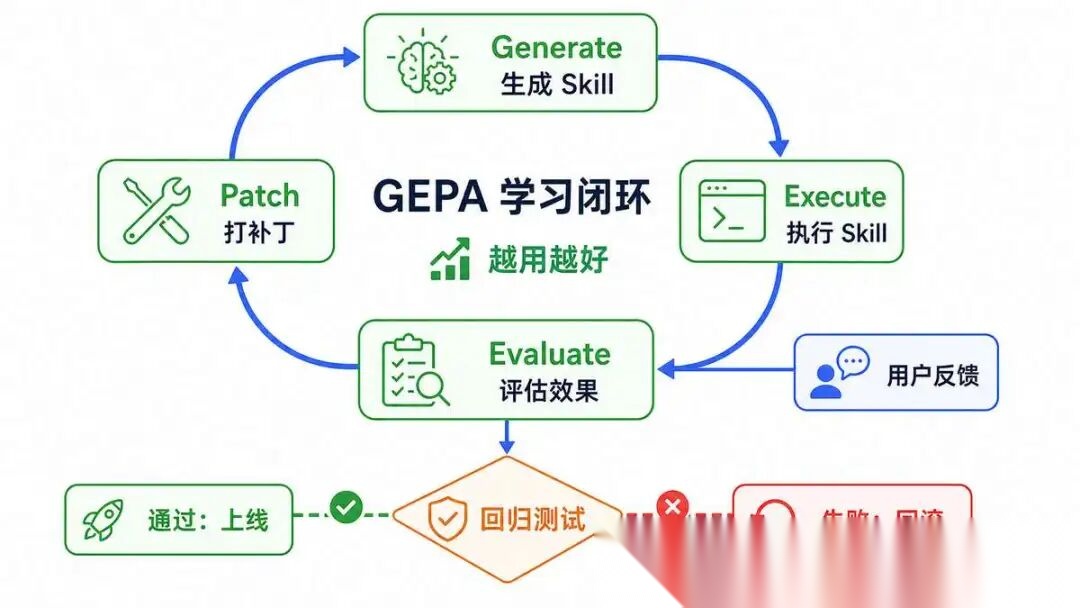
阶段 1:执行(Execute)
- Agent 加载并使用 Skill 完成任务
- 全程记录: 每一步是否按 Skill 执行、有没有偏离、效果怎么样
- 收集用户隐式反馈(有没有打断、有没有纠错、有没有重做)和显式反馈(好评 / 差评)
阶段 2:评估(Evaluate)
- 任务完成后自动做多维度评估
- 有没有按 Skill 规定的流程走?
- 有没有触发 Skill 没覆盖的边界 case?
- 用户有没有修正?
修正了什么?
- 最终结果有没有达到质量标准?
阶段 3:补丁(Patch)
- 如果发现问题,自动生成 Skill 补丁
- 用户纠正了某个步骤 → 更新操作流程
- 遇到了新的异常情况 → 补充失败处理
- 工具参数变了 → 更新工具使用说明
- 输出格式不符合预期 → 更新输出标准
阶段 4:回归(Regress)
- 更新后的 Skill 要跑回归测试
- 确保修复了新问题,没引入旧问题
- A/B 测试对比新旧版本效果
- 没问题才正式上线
7.4 实战案例:一个 Skill 的进化之路
初始 Skill:“排查接口 500 错误,先看日志再搜代码”
第 1 次使用:用户说 “还要检查数据库连接池” → Skill 自动加了这一步
第 2 次使用:遇到日志不存在的情况 → Skill 自动补充 “日志不存在时要告知用户”
第 3 次使用:用户反馈 “不要直接建议改生产” → Skill 自动加了安全边界
第 N 次使用:Skill 已经非常完善,覆盖了各种边界情况
7.5 进化引擎设计:定期合并与异步治理
专门做了一个独立的后台进程叫 Curator,专门负责 Skill 进化: - 异步进化: Curator 跑在后台,不阻塞主对话流程,用户无感知 - 周期性优化: 每天凌晨批量处理当天的所有反馈,集中更新 Skill - 增量更新: 不是每次都重写整个 Skill,而是打补丁,保留历史 - 版本控制: 每次更新都生成新版本,支持回滚 - 剪枝优化: 定期清理 Skill 里的冗余内容,控制长度
7.6 三层引擎架构:自进化不是单向管线
工业级自进化能力应拆分为三层独立引擎,各司其职,通过标准化数据流联动形成闭环。
不是单向流水线,而是双向联动、互相驱动:
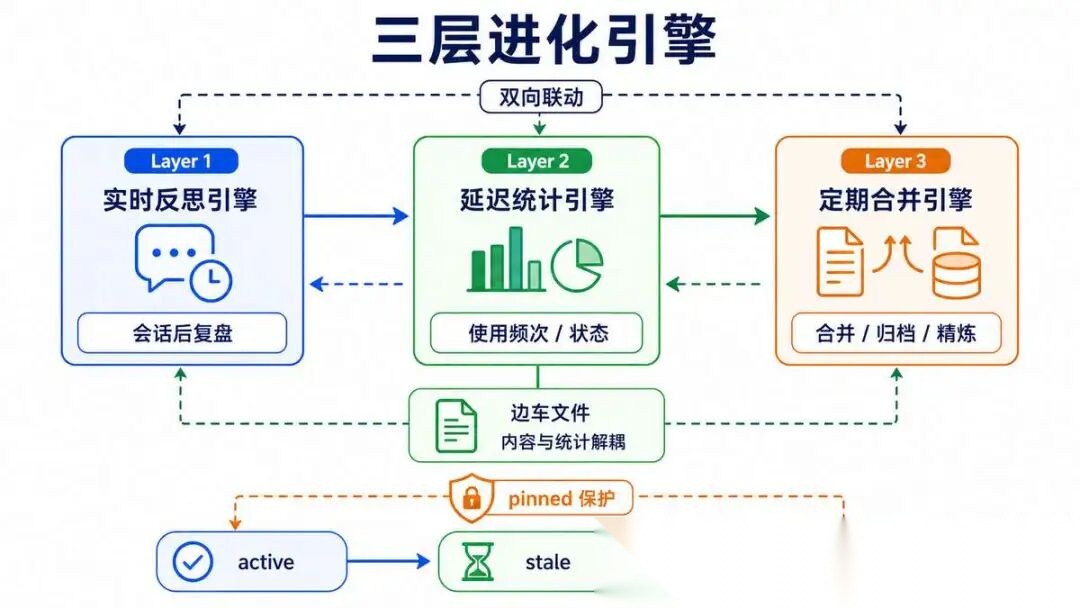 - Layer 1 实时反思引擎: 解决"经验有无沉淀"。
- Layer 1 实时反思引擎: 解决"经验有无沉淀"。
会话结束后通过影子 Agent 异步复盘,从对话中提炼可复用经验写入 Skill 库。
用脏计数器精准触发,不阻塞主会话
- Layer 2 延迟统计引擎: 解决"技能活性存续"。
通过边车文件独立存储每个 Skill 的使用频次、状态、修改记录,驱动活跃 → 陈旧 → 归档的状态转换,为上层治理提供客观数据支撑
- Layer 3 定期合并引擎: 解决"技能质量优劣"。
定期巡检技能库,将碎片化窄 Skill 聚合为伞状 Skill,归档过期 Skill,修复冗余和冲突
双向联动才是闭环的关键:Layer 3 的合并操作会更新 Layer 2 的修改时间,影响技能活性判定;Layer 2 的使用数据反过来约束 Layer 3 的合并方向——使用次数高、最近活跃的 Skill 在群集里权重更大,优先保留为伞的主体。
没有反向通路的"自进化",不过是自动化的碎片堆积。
7.7 边车文件模式:Skill 内容与使用数据解耦
Skill 的使用统计数据存哪?
最容易想到的是写在 Skill 文件的元数据头里,但有三个致命缺陷:用户手动编辑易误删、官方内置技能元数据只读无法写入、频繁修改正文易导致文件损坏。
边车文件架构(Sidecar Pattern):Skill 内容和使用统计分离存储,互不干扰。
- Skill 文件专注存储执行逻辑、场景说明、操作步骤,面向用户可读可编辑;
- 独立的统计文件专注存储运营数据(使用次数、查看次数、修改次数、最后使用时间、状态、是否置顶等),面向系统自动化治理。
写入安全靠原子替换 + 跨进程文件锁保证:先写临时文件,再用操作系统级的原子替换操作一步到位,杜绝并发写入导致的文件损坏或半写状态。
核心理念:使用统计是操作性的,不应该污染用户编写的内容。
一个管"教 Agent 怎么做",一个管"Agent 用得怎么样"。
这个设计原则在微服务架构中叫边车模式,应用到 Skill 存储同样成立。
7.8 四状态双向可逆状态机
Skill 的状态机有 四种状态 ,由纯规则引擎驱动,无需 LLM 参与:
-
active(活跃): 正常使用中
-
stale(陈旧): 超过 30 天无活动,标记为陈旧
-
archived(归档): 超过 90 天无活动,自动归档
-
pinned(置顶保护): 用户手动置顶,跳过所有自动状态变更
状态转换规则:
| 当前状态 | 触发条件 | 目标状态 | 说明 |
|---|---|---|---|
| active | 超过 30 天无任何活动 | stale | 自动降级,标记为陈旧 |
| stale | 超过 90 天无任何活动 | archived | 自动归档,不再参与匹配 |
| stale | 被重新使用 / 查看 / 修改 | active | 双向复活,锚点时间重置 |
| archived | 被用户手动恢复 | active | 手动复活 |
| 任意状态 | 用户手动置顶 | pinned | 跳过所有自动状态变更 |
| pinned | 用户取消置顶 | 回到原状态 | 恢复自动状态流转 |
核心创新:双向可逆复活机制。
- 被标记为 stale 的 Skill,一旦被重新使用、查看、修改,锚点时间自动更新,恢复为 active 状态。
解决了"低频有用 Skill 被误归档"的问题。
如果没有状态恢复机制会怎样?
- 一个 Skill 31 天没用被标记 stale,第 32 天用户又用了它,但状态还是 stale,再过 59 天(总共 90 天)直接归档, 问题来了: 一个明明还在被用的 Skill,被当垃圾清理了。
所以: 状态机是双向的,不是单行道。
使用行为改变了治理策略,这才是数据驱动的闭环。
9. Skill 质量评估体系:如何证明一个 Skill 真的有用?
尼恩提示:原文3w字以上, 超过平台限制, 此处省略 1000字,具体请参考 免费pdf。
完整版本,请参考 尼恩 免费百度网盘 免费pdf ,点赞收藏本文后,截图 找尼恩获取
8 第四层:技能治理层: 大规模 Skill 体系全域可控运维底座
尼恩提示:原文3w字以上, 超过平台限制, 此处省略 1000字,具体请参考 免费pdf。
完整版本,请参考 尼恩 免费百度网盘 免费pdf ,点赞收藏本文后,截图 找尼恩获取
9、Skill 量化质量评估体系:数据化证明技能业务价值
依靠 “主观感觉效果变好” 做迭代是典型工程反模式,无量化评估的 Skill 体系等价于盲人驾驶;
评估体系核心目标:剥离主观体感,用可复现指标量化 Skill 投入产出、优劣等级、退化趋势,为迭代、下线、推广提供客观决策依据。
9.1 核心设计思想
【1】量化价值: 精准衡量 Skill 对任务成功率、推理成本、人工干预量、执行稳定性的正向增益
【2】劣化预警: 及时识别性能下滑、误召回激增、参数报错的劣质 Skill,触发整改熔断
【3】迭代依据: 为 GEPA 进化闭环、版本迭代、A/B 灰度验证提供客观数据基准
【4】投入决策: 核算 Skill 研发、维护成本与业务收益 ROI,淘汰低价值冗余技能
9.2 五大类完整评估指标矩阵
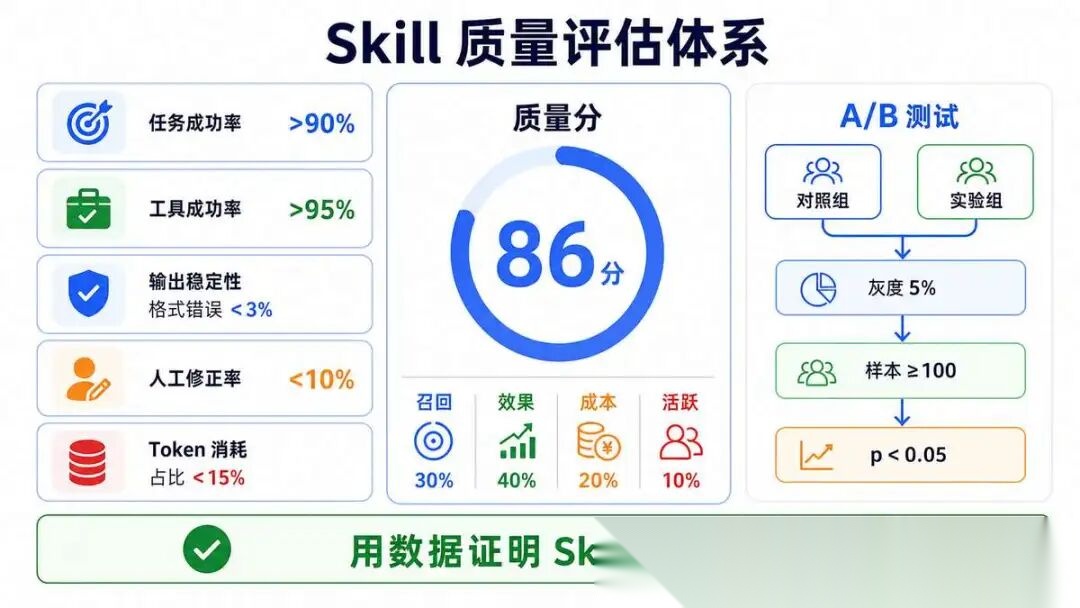
| 指标大类 | 细分指标 | 标准化计算公式 | 优秀阈值 | 告警阈值 | 触发告警处置策略 |
|---|---|---|---|---|---|
| 一、任务达成成功率(业务价值核心) | 全局任务成功率 | 成功闭环任务总量 / 总发起任务量 | >90% | <70% | 全量复盘链路,排查技能匹配、执行异常 |
| 单 Skill 专属成功率 | 该技能下成功任务数 / 该技能总调用次数 | >85% | <60% | 进入质量整改队列,限制流量 | |
| 目标精准达成率 | 用户原始诉求完全满足任务量 / 总任务量 | >80% | <50% | 优化 Skill 适用边界与执行步骤 | |
| 二、工具调用健康度(执行稳定性) | 全局工具调用成功率 | 工具正常返回有效结果次数 / 总工具调用次数 | >95% | <80% | 校验入参规则、第三方接口连通性 |
| 工具错选率 | 意图匹配错误工具次数 / 总调用次数 | <3% | >10% | 优化 Skill 召回语义描述、边界定义 | |
| 参数非法错误率 | 入参格式 / 取值不合规调用 / 总调用次数 | <2% | >8% | 补充参数校验前置逻辑、异常兜底 | |
| 无效重复调用率 | 无意义循环重试调用次数 / 总调用次数 | <5% | >15% | 增加终止判定条件,避免死循环推理 | |
| 三、输出规范稳定性(标准化约束) | 格式错误率 | 输出不符合预设结构化格式占比 | <3% | >10% | 修正 Skill 输出模板、后置格式校验 |
| 必填字段缺失率 | 关键字段缺失样本占总样本比例 | <2% | >8% | 补充输入校验、缺失字段补全逻辑 | |
| 论据引用缺失率 | 要求溯源但未标注来源样本占比 | <5% | >15% | 强制 Skill 内置引用输出约束 | |
| 流程偏离执行率 | 跳过既定步骤自定义执行样本占比 | <5% | >20% | 强化步骤校验,约束推理自由度 | |
| 四、人工干预修正率(降本核心指标) | 全局人工修正率 | 需要人工介入调整任务 / 总任务量 | <10% | >30% | 判定技能成熟度不足,迭代优化 |
| 内容纠错修改率 | 人工改写输出内容样本占比 | <8% | >25% | 优化逻辑、减少幻觉、对齐业务口径 | |
| 格式调整修正率 | 仅修改排版结构样本占比 | <3% | >10% | 固化输出结构模板 | |
| 流程纠正干预率 | 人工纠正执行步骤样本占比 | <5% | >15% | 重构 Skill 执行流程,简化决策分支 | |
| 五、Token 成本效率(算力成本指标) | 单任务平均消耗 Token | 会话总 Token 消耗量 / 有效任务总数 | 基准值 ±10% | 超出基准 30% | 精简 Skill 冗余描述、优化上下文加载 |
| Skill 文本 Token 占比 | Skill 带入上下文 Token / 单次总上下文 Token | <15% | >30% | 裁剪冗余文案,启用摘要渐进加载 | |
| 平均推理重试轮次 | 总推理轮次 / 成功完成任务数量 | <1.2 轮 | >2 轮 | 优化决策逻辑,减少反复反思迭代 | |
| Token 节省增益率 | (无 Skill 基线 Token - 启用 Skill Token)/ 基线 Token | >15% | <0 | 判定该技能负收益,下线重构 |
10、Agent Skill 体系面试全题库
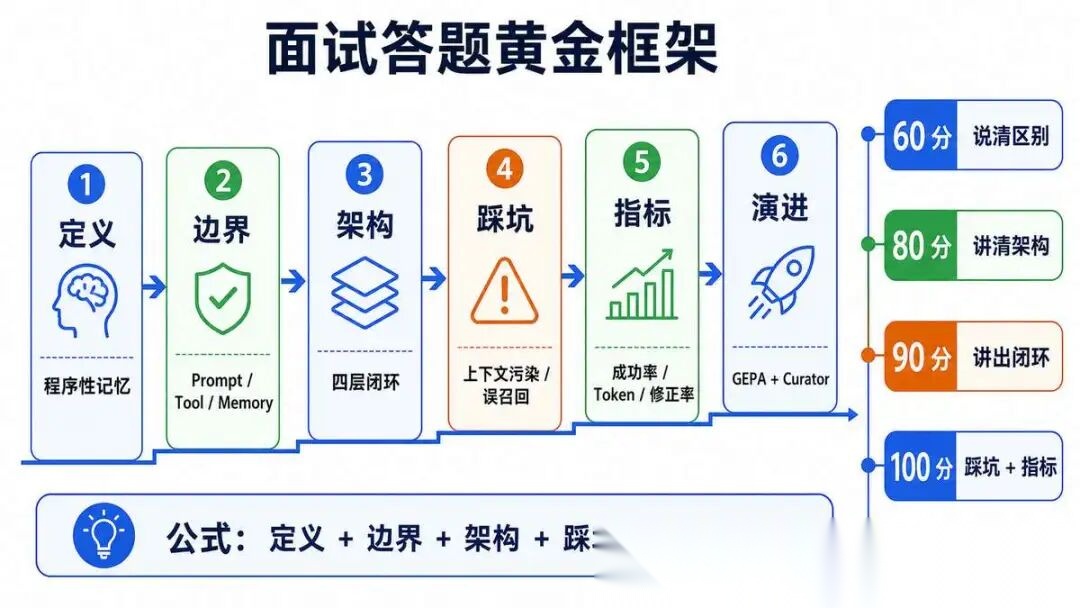
面试作答核心逻辑:
切忌碎片化背诵概念,以工程落地视角 + 踩坑复盘 + 量化指标 + 架构演进表达,体现完整架构设计思维;
固定黄金答题公式:定义本质→边界划分→四层架构闭环→落地踩坑与解法→量化评估指标→长期演进路线,完整展现系统性思考,区别于初级调 Prompt 选手。
Q1:Skill 本质定义是什么?
和 Prompt 核心差异化边界?
不能简单将 Skill 理解为长文本 Prompt。
Prompt 是单次会话瞬时指令,仅约束当前这一轮任务执行逻辑,生命周期仅限单次上下文;
Skill 是面向一类重复任务的标准化程序化记忆单元,沉淀固定适用边界、分步执行流程、工具调用范式、入参校验规则、输出格式规范、异常兜底策略、安全约束七条完整规范,可持久化存储、检索匹配、迭代进化、版本管控。
本质差异:Prompt 静态一次性;Skill 动态可迭代,支撑经验资产沉淀,实现同类任务批量标准化处理,是从临时提示词工程走向知识资产工程的范式跃迁。
Q2:Skill、Tool、MCP、Memory、Harness 五大核心组件边界与协同关系?
五组件各司其职、互补协同,无互相替代关系:
【1】Tool: 底层执行原子动作(能不能做),是系统调用外部能力的最小单元
【2】Skill: 编排多个 Tool 的执行方法论(怎么做稳),封装业务流程、判断分支、异常处理
【3】MCP(Model Context Protocol): 工具标准化互联互通协议,统一 Agent 与外部系统调用接口、隔离进程、做基础权限隔离,解决多工具异构适配问题
【4】Memory: 事实与轨迹存储仓库,存储历史交互、执行案例、用户偏好等原始信息,为 Skill 蒸馏、迭代提供数据源
【5】Harness: 全局运行时治理基座,统筹调度、安全拦截、资源管控、异常熔断,约束整个 Agent 系统运行边界
协同链路:Memory 提供历史素材→Skill 编排 Tool 通过 MCP 发起调用→Harness 全程管控拦截,形成完整执行闭环。
Q3:什么样的业务场景适合沉淀为标准化 Skill?
满足四大特征才具备沉淀复用价值,反之无需额外开发:
【1】高频重复: 同类任务周度出现频次高,沉淀后长期收益覆盖维护成本
【2】流程收敛: 具备固定执行步骤、判断分支,逻辑不会频繁颠覆性变更
【3】模型原生易错: 裸 Prompt 执行极易幻觉、步骤遗漏、参数错误、逻辑跑偏
【4】验收标准明确: 有清晰成功判定条件、输出规范,可量化评估好坏
典型落地场景:代码评审、日志故障排查、文档结构化生成、RAG 问答质控、报表整理、需求拆解;偶发一次性特殊任务无需封装 Skill。
Q4:工业级完备 Skill 必须包含九大要素?
残缺要素会导致 Skill 健壮性不足,生产上线必须补齐九项元定义:
【1】正向适用场景: 明确触发匹配条件、适用业务范围
【2】反向排除场景: 明确禁止触发边界(最容易遗漏,规避误召回根源)
【3】输入前置校验: 所需前置信息、信息缺失时补全逻辑
【4】分步执行流程: 确定性步骤编排、分支判断逻辑
【5】工具调用策略: 优先级选择、调用失败重试 / 降级方案
【6】强制输出格式: 结构化模板、必填字段约束
【7】质量验收标准: 判定执行合格、优秀的量化依据
【8】全异常兜底方案: 各类报错、超时、缺数据应对策略
【9】刚性安全边界: 禁止操作清单、高危动作约束底线
Q5:Skill 召回架构如何设计?
怎么根治上下文 Token 污染?
禁止交由大模型自主选择技能,生产级四层召回架构:标签粗筛→风险过滤→向量相似度置信度打分→治理中心裁决;设置三级置信分流策略。
根治上下文膨胀方案:渐进式分层加载架构
-
L0 常驻索引层: 仅存储 Skill 名称、简介、置信度,整体 Token 压缩至 500 左右常驻
-
L1 摘要加载层: 命中高置信候选后,仅加载精简流程摘要
-
L2 完整加载层: 确认启用该 Skill,才注入完整全文内容
数百规模技能池也不会引发上下文爆炸,从根源解决全量加载带来的算力浪费与注意力偏移。
Q6:详细解释 GEPA 自进化闭环完整原理?
GEPA 全称Generate-Evaluate-Patch-Audit 生成 - 评估 - 补丁迭代 - 审计闭环,是 Hermes、OpenClaw 主流自进化框架核心迭代引擎:
【1】Generate 生成: 采集单次 Skill 完整执行轨迹、用户修正、失败案例
【2】Evaluate 评估: 依托五维指标体系量化本次执行优劣,定位缺陷根因
【3】Patch 补丁更新: 针对性生成增量优化补丁,而非全量重写 Skill,减少破坏性改动
【4】Audit 回归审计: 补丁通过回归用例验证、安全扫描、灰度验证后更新版本
Curator 后台异步调度运行,不阻塞主会话交互;采用增量迭代模式,每次迭代收敛小幅优化,避免大幅度改写引发稳定性震荡,实现 Skill 越调用越精准。
Q7:四层自进化架构每层解决什么核心问题?
整体闭环逻辑?
【1】轨迹感知层: 采集全链路执行轨迹、人工纠错、失败样本,解决进化数据原材料来源问题
【2】技能蒸馏层: 聚类相似任务案例,自动萃取标准化 Skill 资产,解决自动化批量生成能力资产问题
【3】技能进化层: GEPA 闭环持续迭代优化技能精度,解决技能长期退化、持续精进问题
【4】技能治理层: 生命周期、权限、安全、冲突、版本全域管控,解决大规模体系稳定运维、风险可控问题
四层单向依赖、首尾闭环,构成自进化增长飞轮,缺一不可。
Q8:三种 Skill 构建方案选型思路(团队规模、场景匹配)
【1】纯手写定制模式: 适配小团队、低频、极高风险核心场景;优点可控性极强,缺点规模化维护成本极高
【2】模板化固定编排模式(OpenClaw 范式): 通用工具集成、标准化流程场景;成本适中、稳定性中等,中小团队首选折中方案
【3】四层全自动自进化架构: 中大型团队、高频海量业务场景、长期规模化沉淀;前期架构投入高,长期边际成本持续下降,具备复利效应
设计原则:不超前过度设计,不盲目堆砌自动化,匹配团队体量与业务频次选型。
Q9:如何客观论证一个 Skill 具备业务价值,不是无效设计?
摒弃主观感受,依靠完整评估链路:
(1) 五维度指标矩阵统计打分,生成单技能健康评分卡
(2) 上线前必须落地对照 A/B 灰度实验,满足样本量、统计显著性门槛
(3) 核算算力节省、人工减少、故障下降量化收益
(4) 长期跟踪 ROI,持续淘汰零收益、负收益冗余技能
只有数据证明正向增益,才可判定 Skill 具备落地价值。
Q10:Skill 体系落地五大典型致命坑与针对性解决方案?
【1】坑 1: 全量加载所有 Skill,上下文爆炸、Token 暴涨、模型注意力涣散→渐进式分层加载 + 四层精准召回
【2】坑 2: 只写适用场景,缺失排除边界,误召回泛滥→强制九要素模板,必填反适用场景定义
【3】坑 3: Skill 上线无人迭代,慢慢退化沉淀技术债务→GEPA 自动进化闭环 + 质量监控告警
【4】坑 4: 无治理管控,冲突、僵尸技能泛滥、体系混乱→完整治理层 + SLIM 生命周期管理
【5】坑 5: 安全约束仅写在 Skill 内部软约束,极易被绕过→Harness 全局硬拦截 + 分层授信双轨安全架构
Q11:多 Agent 集群场景,Skill 如何实现共享与隔离设计?
采用全局公共池 + 个体私有域双层存储架构:
【1】全局公共 Skill 仓库: 存放通用基础能力(文档处理、代码评审),所有 Agent 可读可检索,版本统一管控
【2】单 Agent 私有隔离空间: 专属业务定制技能,其他 Agent 无访问权限
跨 Agent 共享采用快照分发模式,避免一个 Agent 迭代改动影响集群其他实例;顶层由 Harness 统一做全局冲突仲裁、权限管控。
Q12:Skill 与 Memory 协同运行逻辑,二者定位互补性?
Skill 定义做事的方法流程(How),Memory 存储过往事实与历史经验(What),二者互补不可替代:
- 执行链路:Skill 运行时主动检索 Memory 获取历史上下文、过往案例作为输入参考;
- 单次执行结束后,完整轨迹、修正结果自动写入 Memory 存储,反向作为后续 Skill 蒸馏、迭代的数据源;
- Memory 供给迭代原料,Skill 落地业务执行,形成双向协同闭环。
Q13:从零搭建整套 Skill 自进化系统,分阶段落地路线图?
采用渐进式迭代落地,拒绝一步到位重资产搭建,四阶段稳步落地:
- 阶段 1(基础打底):手写 5~10 个核心业务 Skill,落地九要素规范,搭建 Skill 注册中心、四层召回、渐进加载、轨迹埋点采集能力,跑通基础调用链路
- 阶段 2(数据打底):完善轨迹感知层,全量采集执行样本、人工纠错、失败案例,建立原始样本池
- 阶段 3(自动生成 + 迭代):上线技能蒸馏引擎,批量聚类生成新 Skill;部署 GEPA 闭环 + Curator 后台,实现自主迭代优化
- 阶段 4(治理成型):补齐完整治理层,风险分级、生命周期、权限隔离、安全扫描、质量监控熔断整套机制,完成工业化闭环落地
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐

 2
2 0
0- 0



 已为社区贡献59条内容
已为社区贡献59条内容

所有评论(0)