
阿里:技能驱动统一奖励模型
📖标题:Skill-RM: Unifying Heterogeneous Evaluation Criteria via Agent Skill
🌐来源:arXiv, 2606.03980v1
🛎️文章简介
🔸研究问题:如何构建一个统一框架来整合规则、参考答案及核查清单等异构评估标准以解决现有奖励模型评价机制割裂的问题?
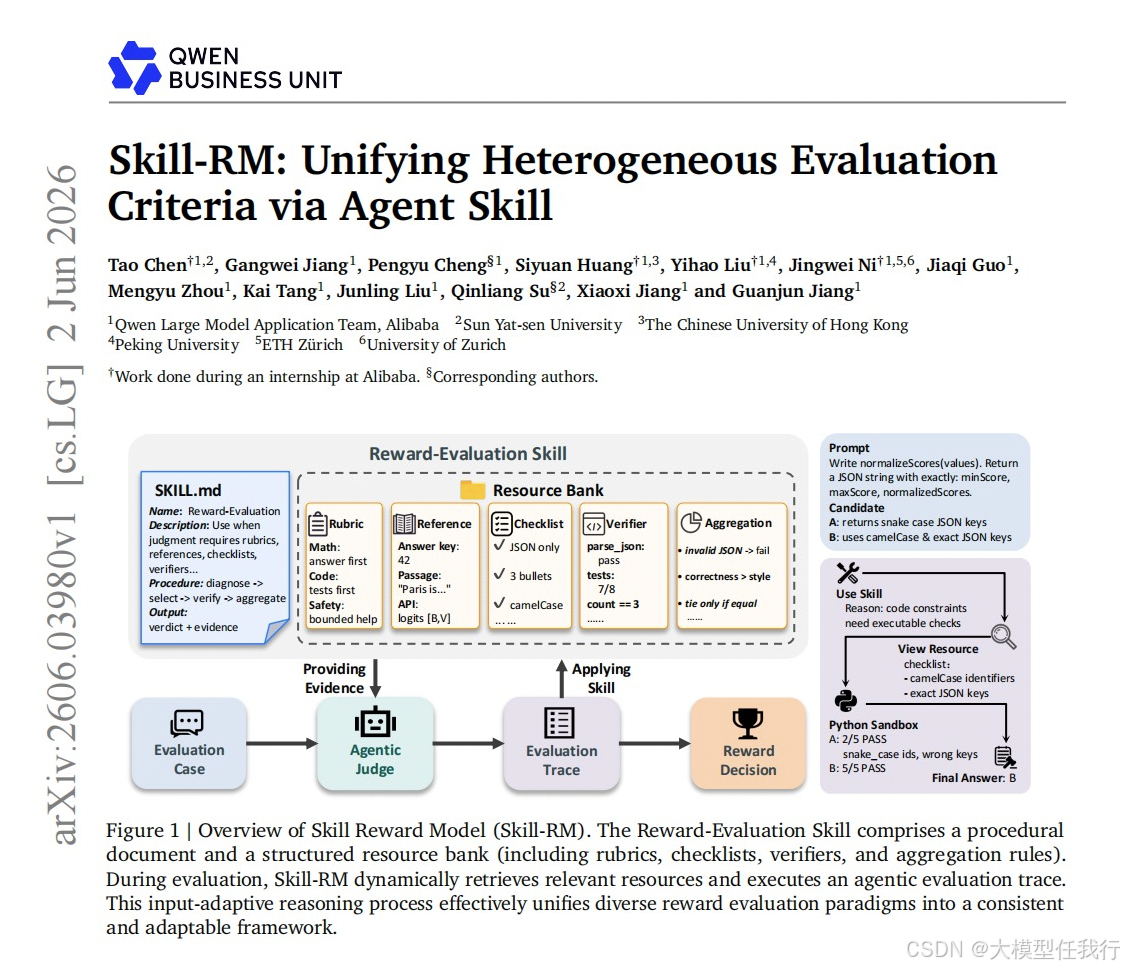
🔸主要贡献:论文提出Skill-RM框架,将奖励建模重构为可复用的智能体技能执行过程,通过动态编排异构资源实现了评估的一致性与透明度。
📝重点思路
🔸将奖励计算重新定义为结构化的智能体任务,设计“奖励评估技能”作为核心抽象单元,包含程序化规范文档与结构化资源库,替代传统的扁平化提示词或单一标量预测。
🔸构建包含评分细则、参考答案、约束清单、验证器及聚合规则在内的异构资源库,资源按需加载而非全量输入上下文,以减少噪声并支持模块化复用。
🔸采用技能介导的评估流程,智能体裁判根据输入动态识别适用标准,按协议检索并执行相关资源,收集准则级证据,将评估转化为可追溯的动作-观察序列。
🔸设计确定性奖励读出函数,将包含多维证据的结构化判断映射为具体任务所需的点式分数或排序结果,确保最终决策显式依赖于底层证据而非隐式参数。
🔸通过LLM辅助策展流程构建标准化技能与资源,剥离特定任务启发式规则,形成版本控制且冻结的可复用评估工件,保证评估逻辑的外部化与可审计性。
🔎分析总结
🔸在RewardBench2等多个主流基准测试中,Skill-RM显著优于同基座的LLM-as-a-Judge及传统奖励模型基线,证明了技能化编排对提升评估质量的有效性。
🔸消融实验表明,性能增益源于技能介导的资源组织方式,单纯将资源拼接到提示词或仅提供工具访问反而可能导致性能下降,证实了结构化调度的必要性。
🔸当挂载样本特定的外部资源时,Skill-RM能进一步利用额外证据提升表现,展现了框架在处理复杂验证任务时的灵活性与扩展能力。
🔸在Best-of-N响应选择任务中,Skill-RM在指令遵循与代码生成等场景下大幅超越基线,接近理论上界,验证了其作为离线重排器的实用价值。
🔸作为强化学习的奖励源,Skill-RM在指令遵循RL训练中取得了最优平均成绩,表明其生成的反馈信号能有效指导策略优化,且优于现有的验证工程方法。
💡个人观点
论文将“评估知识”外化为可执行的软件工程制品,通过显式证据链实现了可解释性。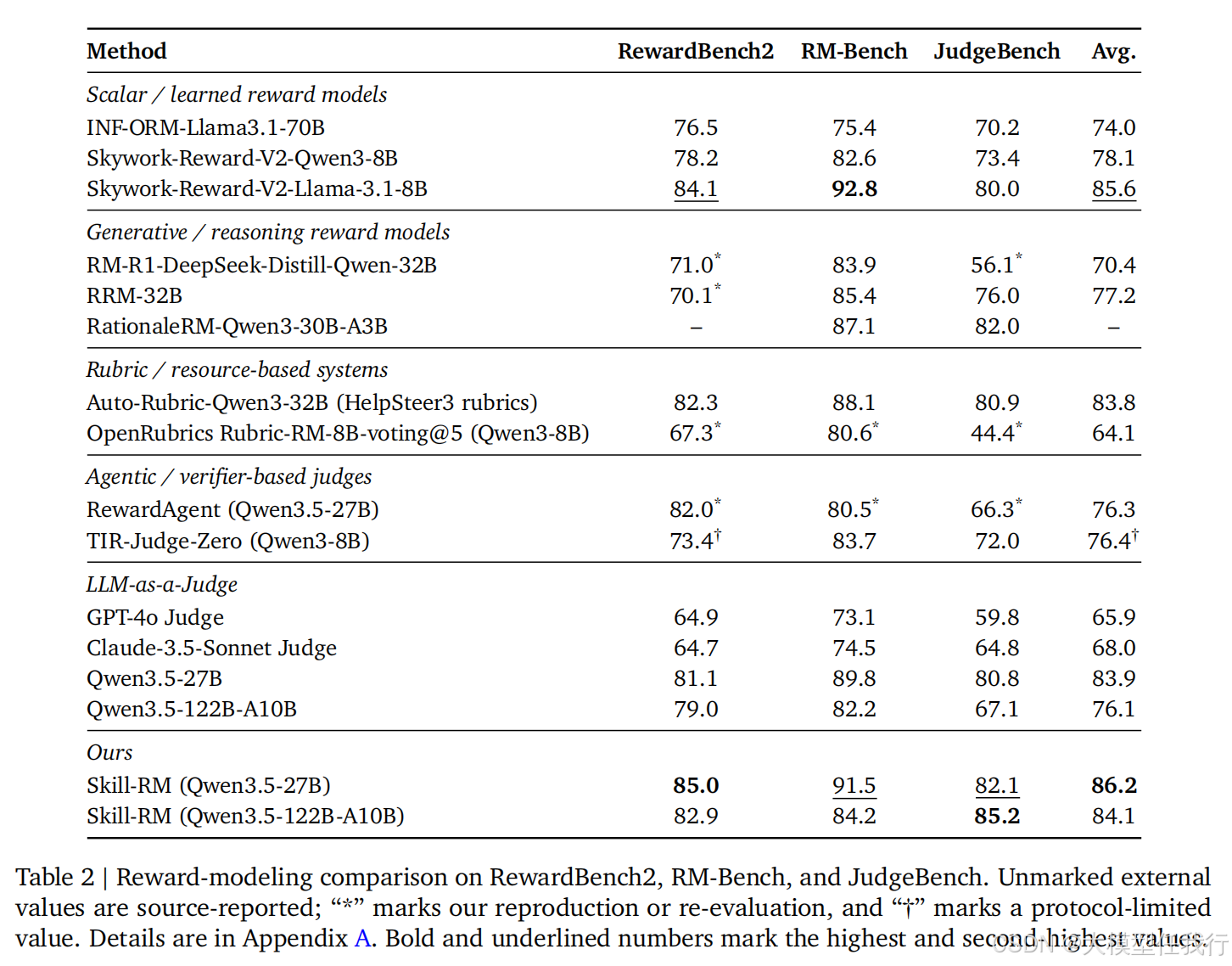

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐
 11
11 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)