
DeepSeek发布节后首篇论文,Agentic LLM推理新突破

对比,Anthropic指控&防范 DeepSeek、Moonshot AI和 MiniMax 的 工业规模的蒸馏攻击。
DeepSeek & 清北发表了春节后的首篇Paper,公开了硬核技术:DualPath, 打破Agentic LLM推理中的存储带宽瓶颈。近期,谷歌发表了2篇Multi-Agent协作学习新论文

大语言模型正从单轮对话工具进化为多轮智能体系统——能够自主规划、调用工具、与环境交互完成复杂任务。这种范式转变带来了全新的系统挑战:
Agentic工作负载的典型特征:
-
超长上下文:单次轨迹可达数十万token(如代码助手、自动化任务代理)
-
高KV-Cache命中率:由于多轮交互中上下文高度复用,命中率通常≥95%
-
短追加模式:每轮仅追加数百token,但需加载完整历史KV-Cache
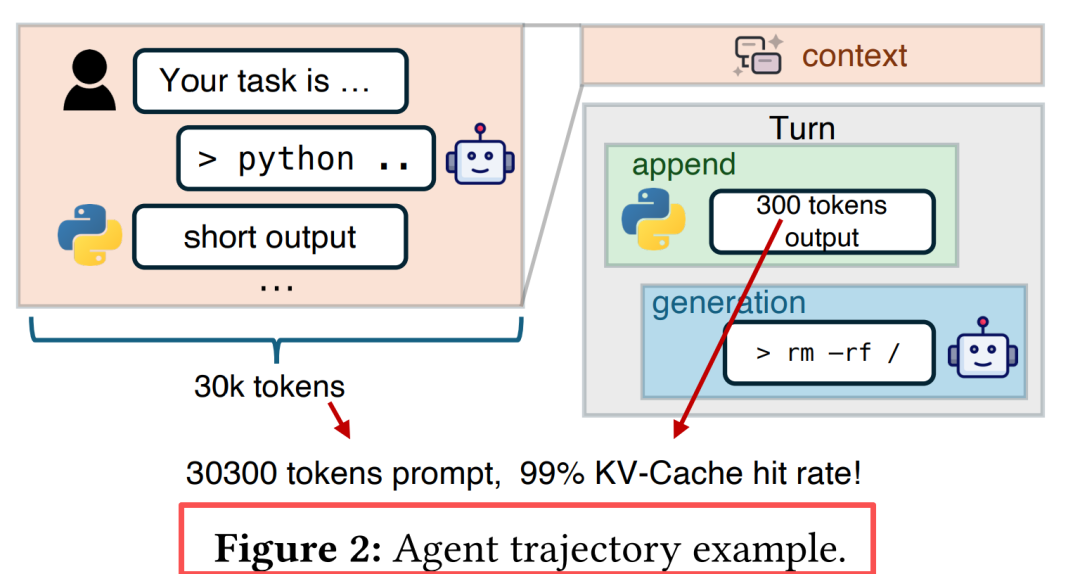
Agent轨迹示意
这导致系统性能瓶颈从计算转向I/O——GPU大部分时间都在等待KV-Cache从存储加载,而非执行计算。
2. 现有架构的根本缺陷:存储网络带宽失衡
现代LLM推理系统普遍采用Prefill-Decode (P/D) 分离架构:
-
**Prefill引擎(PE)**:负责计算密集型预填充,需从存储加载KV-Cache
-
**Decode引擎(DE)**:负责自回归生成,存储NIC基本空闲
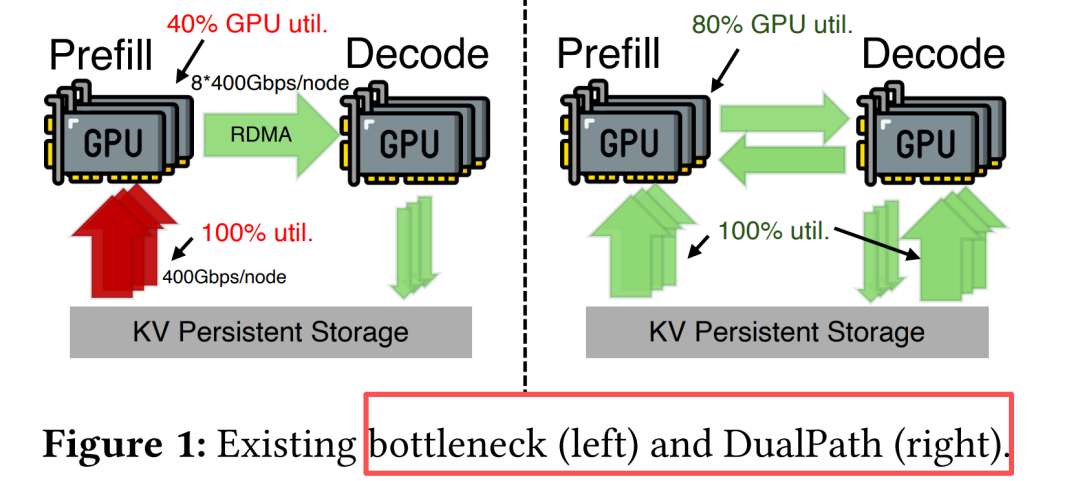
现有瓶颈 vs DualPath
核心问题:Prefill端的存储NIC带宽被完全占满(100%利用率),而Decode端NIC利用率接近0。这种不对称饱和导致:
-
系统吞吐量受限于Prefill端存储带宽
-
大量可用带宽资源被浪费
-
即使增加Prefill节点,成本高昂且难以扩展
3. DualPath核心设计:双路径KV-Cache加载
3.1 架构创新
DualPath打破传统"存储→Prefill"的单一路径,引入双路径加载机制:
|
路径 |
数据流 |
适用场景 |
|---|---|---|
| PE Read Path |
存储 → PE Buffer → PE GPU → DE Buffer |
传统路径 |
| DE Read Path |
存储 → DE Buffer → PE GPU (RDMA) → DE Buffer |
新路径 |
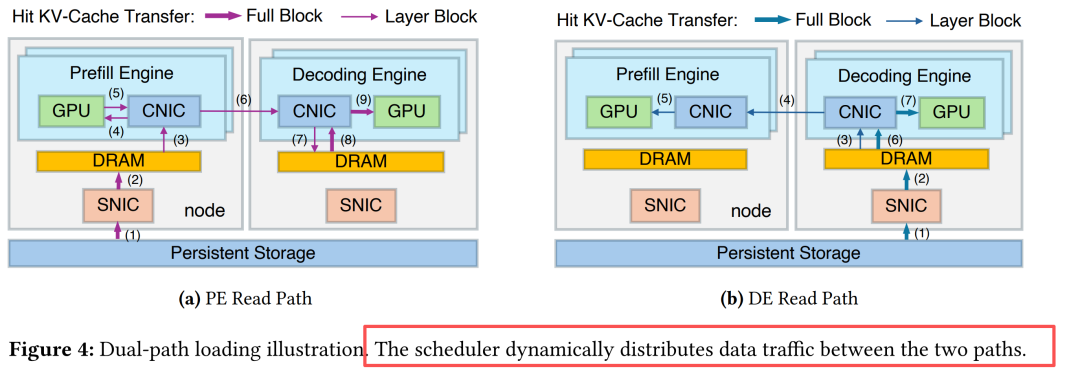
双路径加载示意
关键洞察:利用Decode引擎闲置的存储NIC带宽加载KV-Cache,再通过高速RDMA计算网络传输给Prefill引擎。这样聚合了所有引擎的存储带宽,消除单点瓶颈。
3.2 技术挑战与解决方案
实现这一设计面临三大挑战:
|
挑战 |
DualPath解决方案 |
|---|---|
| 细粒度数据传输 |
层-wise预填充 + Layer Block/Full Block混合布局,实现流式传输与计算重叠 |
| 流量隔离 | CNIC-Centric流量管理
:所有GPU数据流经过计算NIC,利用InfiniBand虚拟通道(VL)QoS隔离KV-Cache流量与模型通信 |
| 动态负载均衡 |
双层调度算法(Inter-engine + Intra-engine),实时平衡NIC流量与GPU计算 |
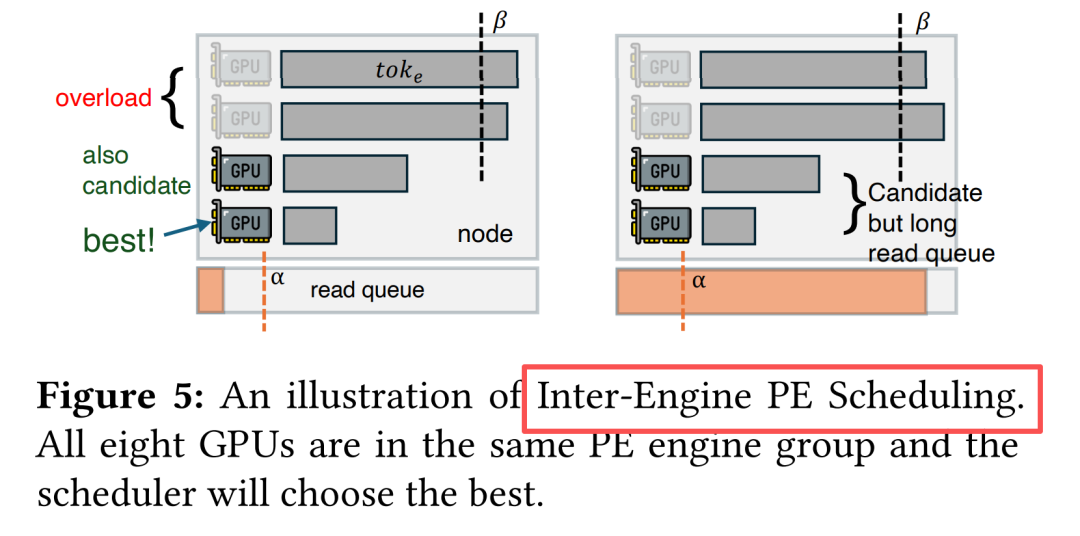
Inter-engine PE调度
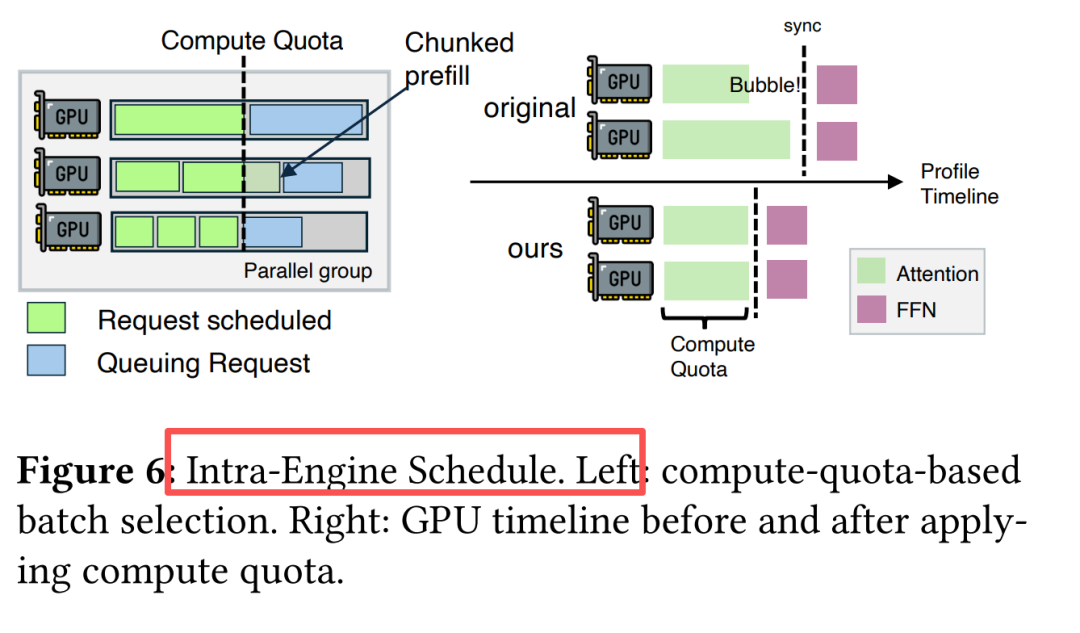
Intra-engine调度
4. 理论分析:无瓶颈运行范围
DualPath通过严格的数学分析证明了架构的可行性。在标准配置下(每节点8 GPU,1个存储NIC),系统可在广泛的P/D比例范围内无瓶颈运行:
这覆盖了绝大多数实际生产配置,确保:
-
存储NIC带宽完全利用
-
计算NIC和DRAM不构成瓶颈
-
网络无拥塞
5. 实验结果:显著性能提升
5.1 离线推理(RL训练Rollout场景)
在三个模型上的测试显示一致的性能提升:
|
模型 |
配置 |
相比Baseline提升 |
|---|---|---|
|
DeepSeek-V3.2 660B |
2P4D |
1.87× |
|
DeepSeek 27B (实验模型) |
1P1D |
1.78× |
|
Qwen2.5-32B |
1P2D |
类似趋势 |
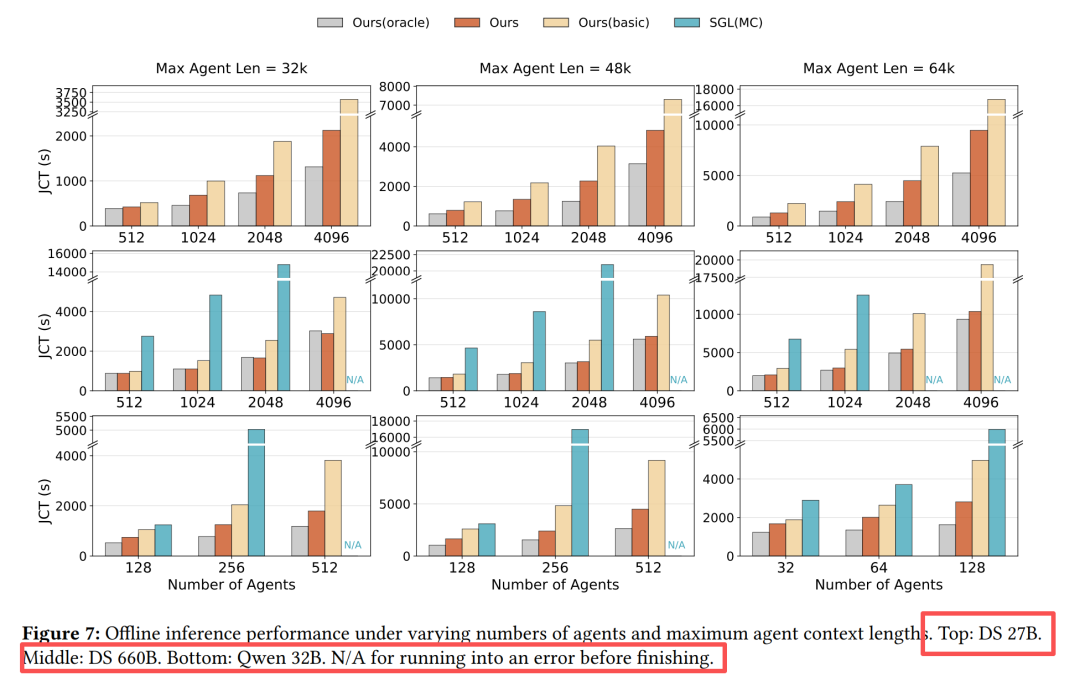
离线推理性能对比
关键发现:
-
批次越大、上下文越长,DualPath优势越明显
-
短追加/短生成场景下提升最大(符合Agent特性)
-
不同P/D比例下均保持1.64×平均加速
5.2 在线服务场景
在保持TTFT≤4s、TPOT≤50ms的SLO下:
|
模型 |
吞吐量提升 |
|---|---|
|
DS 27B |
1.67× |
|
DS 660B |
2.25× |
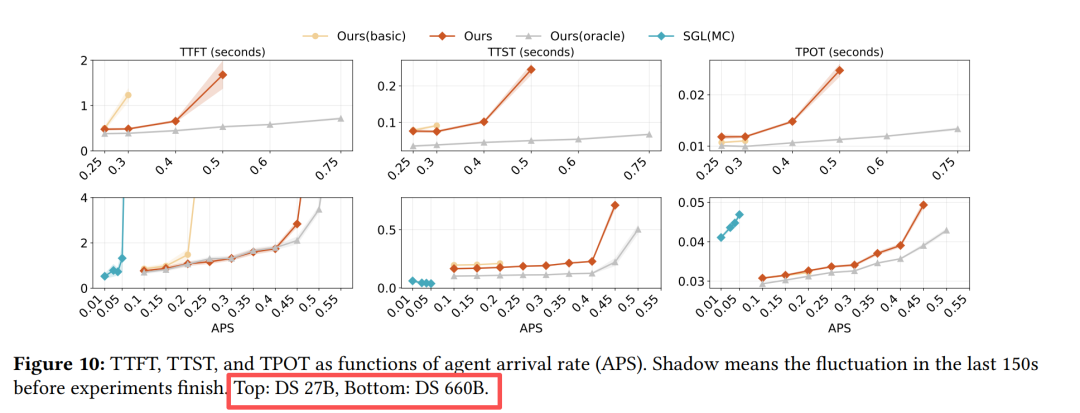
在线服务延迟指标
DualPath在提升吞吐的同时,保持了与Baseline相近的TTST(第二token时间)和TPOT(每token时间),证明未引入额外解码开销。
5.3 大规模扩展性验证
在1,152 GPU规模下的测试:
-
离线推理:JCT 3,201s(接近线性扩展)
-
在线服务:22×吞吐扩展,延迟保持稳定
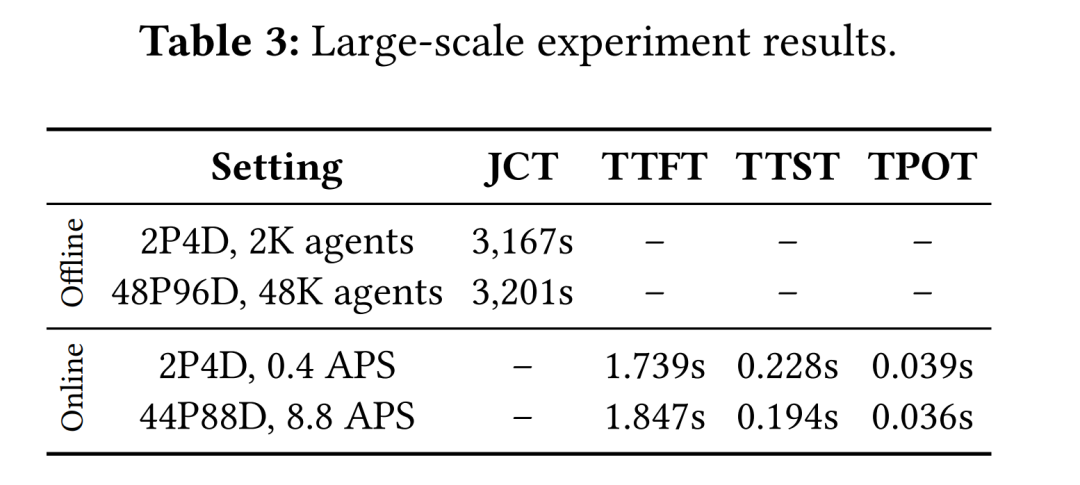
大规模离线推理指标
6. 消融实验:各组件贡献
逐步添加技术组件的效果(DS 660B, 64K上下文):
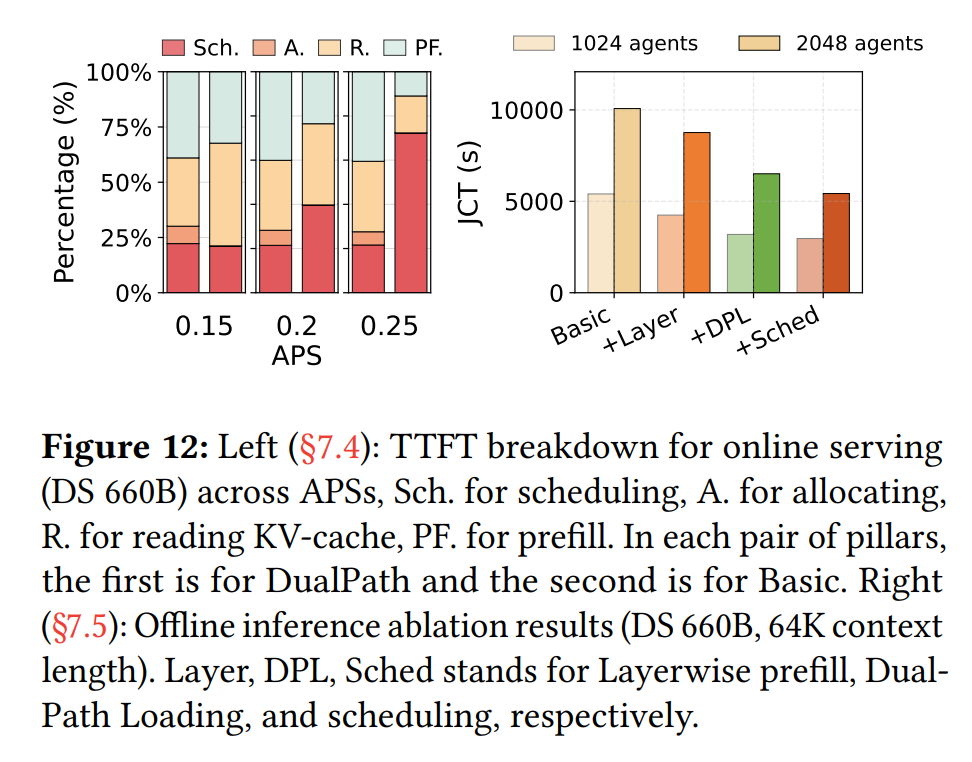
消融实验结果
|
组件 |
JCT降低 |
|---|---|
|
Layerwise Prefill |
17.21% |
|
+ Dual-Path Loading |
38.19%(累计) |
|
+ 调度算法 |
**45.62%**(累计) |
负载均衡效果:
-
存储NIC流量均衡比:从1.53(轮询)→ 1.18(DualPath调度)
-
Attention层执行时间Max/Avg比:低至1.06,显著减少GPU空闲气泡
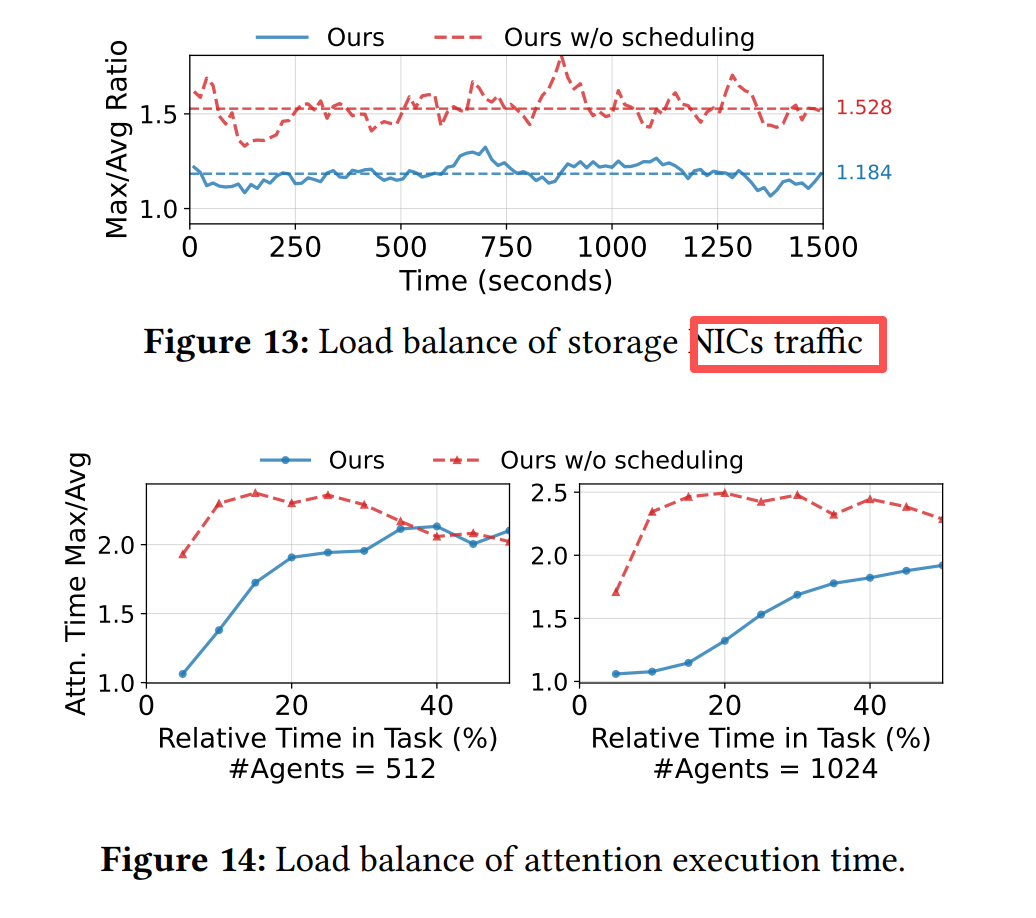
存储NIC负载均衡
从0到1!大模型(LLM)最全学习路线图,建议收藏!
想入门大模型(LLM)却不知道从哪开始? 我根据最新的技术栈和我自己的经历&理解,帮大家整理了一份LLM学习路线图,涵盖从理论基础到落地应用的全流程!拒绝焦虑,按图索骥~~
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取