
HealthGPT:可统一理解和生成的医疗视觉语言模型
·
HealthGPT:数据与模型构建细节详解
HealthGPT 旨在解决医学领域中视觉理解(Comprehension)与生成(Generation)任务之间的冲突,通过构建高质量的数据集 VL-Health 和引入创新的 H-LoRA 架构,实现了在单一自回归框架下的多模态统一。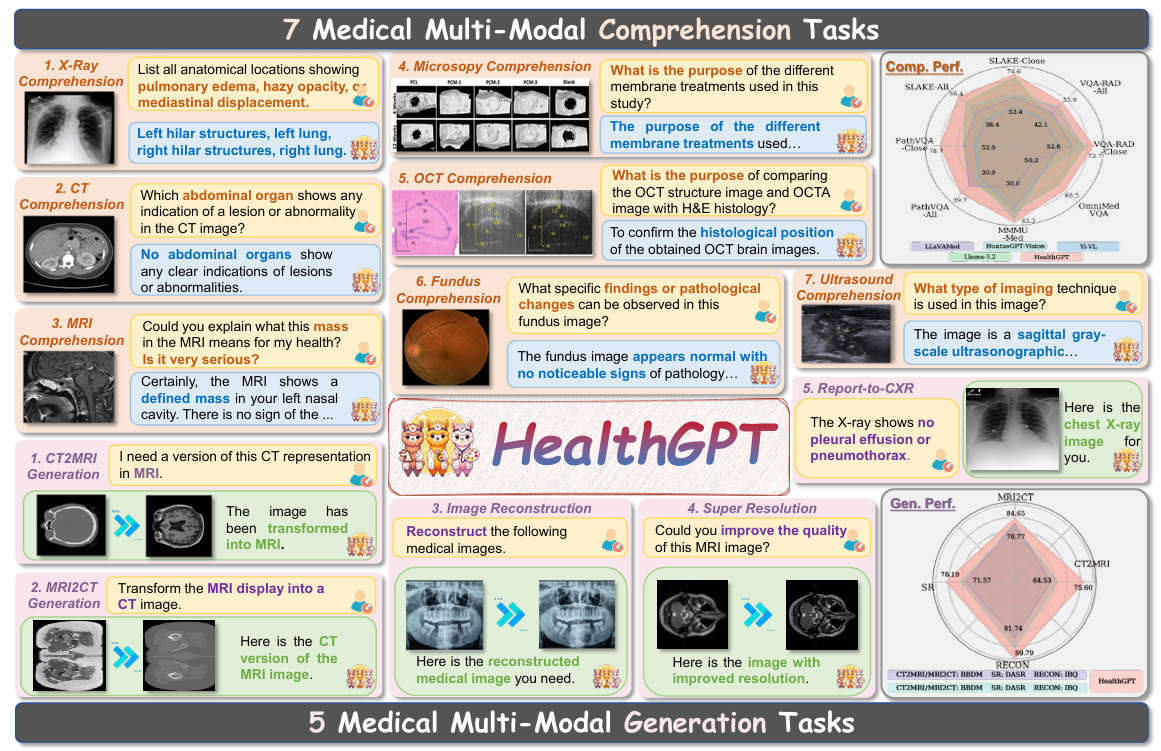
- 图 1:HealthGPT 实现了医学多模态理解与生成,在各项任务中均优于最先进的统一视觉模型和医学专用模型。这突显了其在处理医疗应用中复杂任务时的卓越能力。Comp.Perf. 和 Gen.Perf. 分别表示理解和生成的结果。
1. 数据构建细节:VL-Health 数据集
为了训练 HealthGPT,作者构建了一个全面覆盖理解与生成任务的医学多模态数据集,命名为 VL-Health。
1.1 数据概览
- 总规模:包含约 155万 条高质量数据。
- 理解类数据:约 765,802 条。
- 生成类数据:约 783,045 条。
- 模态覆盖:涵盖 11 种医学模态,包括 CT、MRI、X-ray、超声(Ultrasound)、显微镜图像(Microscopy)、眼底摄影(Fundus)、OCT 等。
- 疾病覆盖:包含肺部疾病、骨骼异常、脑部病变、肿瘤、心血管疾病等广泛病症。
1.2 数据收集来源
数据集分为两大部分,分别针对理解和生成任务:
| 任务类型 | 数据集来源 | 用途/特点 |
|---|---|---|
| 医学理解 | VQA-RAD, SLAKE, PathVQA | 放射学与病理学问答,包含专业标注。 |
| (Comprehension) | MIMIC-CXR-VQA | 基于胸部X光的大规模问答。 |
| LLaVA-Med | 生物医学图像-文本对。 | |
| PubMedVision | 提供广泛的医学知识支持(约50万张图像)。 | |
| LLaVA-1.5 (通用数据) | 引入部分通用领域数据以保持通用指令遵循能力。 | |
| 医学生成 | IXI | 健康脑部 MRI 图像,用于超分辨率任务训练。 |
| (Generation) | MIMIC-CHEST-XRAY | X光图像及报告,用于文生图任务。 |
| SynthRAD2023 | 配对的 CT 和 MRI 图像,用于模态转换任务。 | |
| LLaVA-558k (改写) | 用于图像重建任务。 |
1.3 数据处理与格式化
- 统一格式:所有数据被转换为统一的 指令-响应(Instruction-Response) 格式。
- 任务类型(Task Type):指定视觉特征的粒度(抽象或具体),并选择对应的 H-LoRA 子模块。
- 任务指令(Task Instruction):引导模型理解图像或生成图像的Prompt。
- 输入图像(Input Image):视觉信号输入。
- 响应(Response):
- 理解任务:纯文本回答。
- 生成任务:包含文本 token 和 多模态 token(VQGAN indices),用于自回归生成图像。
- 图像处理:对于生成任务,图像经过切片提取、配准、增强和归一化,并使用 VQGAN 量化为离散的索引序列(Indices)作为监督信号。
2. 模型构建细节
HealthGPT 的核心在于通过架构设计,让预训练的大语言模型(LLM)能够同时适应异构的“理解”和“生成”任务,避免任务冲突。
2.1 基础架构组件
- 视觉编码器 (Visual Encoder):采用 CLIP-L/14。
- 基座 LLM:提供两个版本:
- HealthGPT-M3:基于 Phi-3-mini (3.8B 参数)。
- HealthGPT-L14:基于 Phi-4 (14B 参数)。
- 视觉解码器 (Visual Decoder):采用 VQGAN (f8-8192),用于将模型生成的离散 Token 解码回高质量医学图像。
- 词表扩展:在 LLM 词表中增加了 8192 个 VQGAN 的码本索引(Visual Tokens)。
2.2 关键技术创新
A. 分层视觉感知 (Hierarchical Visual Perception, HVP)
为了解决理解任务(需要语义抽象)和生成任务(需要细节还原)对视觉特征需求的不同,模型动态选择 ViT 的不同层级特征:
- 生成任务:使用 ViT 浅层特征(Concrete-grained features),如第2层。这些层保留了更多像素级细节和全局结构信息。
- 理解任务:使用 ViT 深层特征(Abstract-grained features),如倒数第2层。这些层包含更接近文本空间的抽象语义信息。
- 实现:通过不同的适配器(Adapter, 2层 MLP)将不同层级的特征映射到 LLM 空间。
B. 异构低秩适配 (Heterogeneous Low-Rank Adaptation, H-LoRA)
这是 HealthGPT 的核心微调技术,旨在解耦异构知识,防止灾难性遗忘。
- 设计理念:将理解和生成的知识存储在独立的 LoRA“插件”中。
- 机制:
- 硬路由(Hard Router):根据任务类型(理解或生成),动态激活对应的 H-LoRA 子模块。
- 矩阵合并优化:不同于传统的 MoELoRA 需要多次矩阵乘法,H-LoRA 通过矩阵拼接(Concatenation)和可逆矩阵分块乘法,显著降低了计算开销。
- 效率:在使用4个专家的情况下,训练时间仅为 MoELoRA 的 67%。
2.3 三阶段训练策略 (Three-Stage Learning Strategy)
为了有效融合 H-LoRA 和 HVP,采用了渐进式训练:
-
第一阶段:多模态对齐 (Multi-modal Alignment)
- 分别训练理解任务和生成任务的 Adapter 和 H-LoRA 模块。
- LLM 主干冻结。此阶段让模型初步具备描述医学图像和重建图像的能力。
-
第二阶段:异构 H-LoRA 插件适配 (Heterogeneous H-LoRA Plugin Adaptation)
- 冻结:所有 H-LoRA 模块。
- 训练:仅微调 词嵌入层 (Embedding) 和 输出头 (Output Head)。
- 目的:使用少量混合数据,解决不同任务插件之间的偏差和尺度不一致问题,建立统一的基础。
-
第三阶段:视觉指令微调 (Visual Instruction Fine-Tuning)
- 全量训练 H-LoRA 模块和 Adapter。
- 使用特定任务数据进一步优化,使模型适应复杂的下游任务(如医学对话、超分辨率、模态转换等)。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐


 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)