
什么是Decoder-only架构?为什么GPT系列专注于预测下一个词?
🚀 本文收录于Github:AI-From-Zero 项目 —— 一个从零开始系统学习 AI 的知识库。如果觉得有帮助,欢迎 ⭐ Star 支持!
什么是Decoder-only架构?为什么GPT系列专注于预测下一个词?
一、简介
Decoder-only架构是一种只包含解码器(Decoder)组件的神经网络结构,它专注于自回归地生成新文本,通过预测序列中的下一个词来逐步构建完整的输出。最著名的Decoder-only模型就是GPT系列(Generative Pre-trained Transformer)。
说人话就是: 想象你有一位才华横溢的作家,他擅长根据已有的开头续写故事、回答问题、创作诗歌。但他不会像图书管理员那样深入分析已有文本的每个细节——他更专注于"接下来该写什么"。这就是Decoder-only架构的核心思想:专业化地做好"生成"这一件事。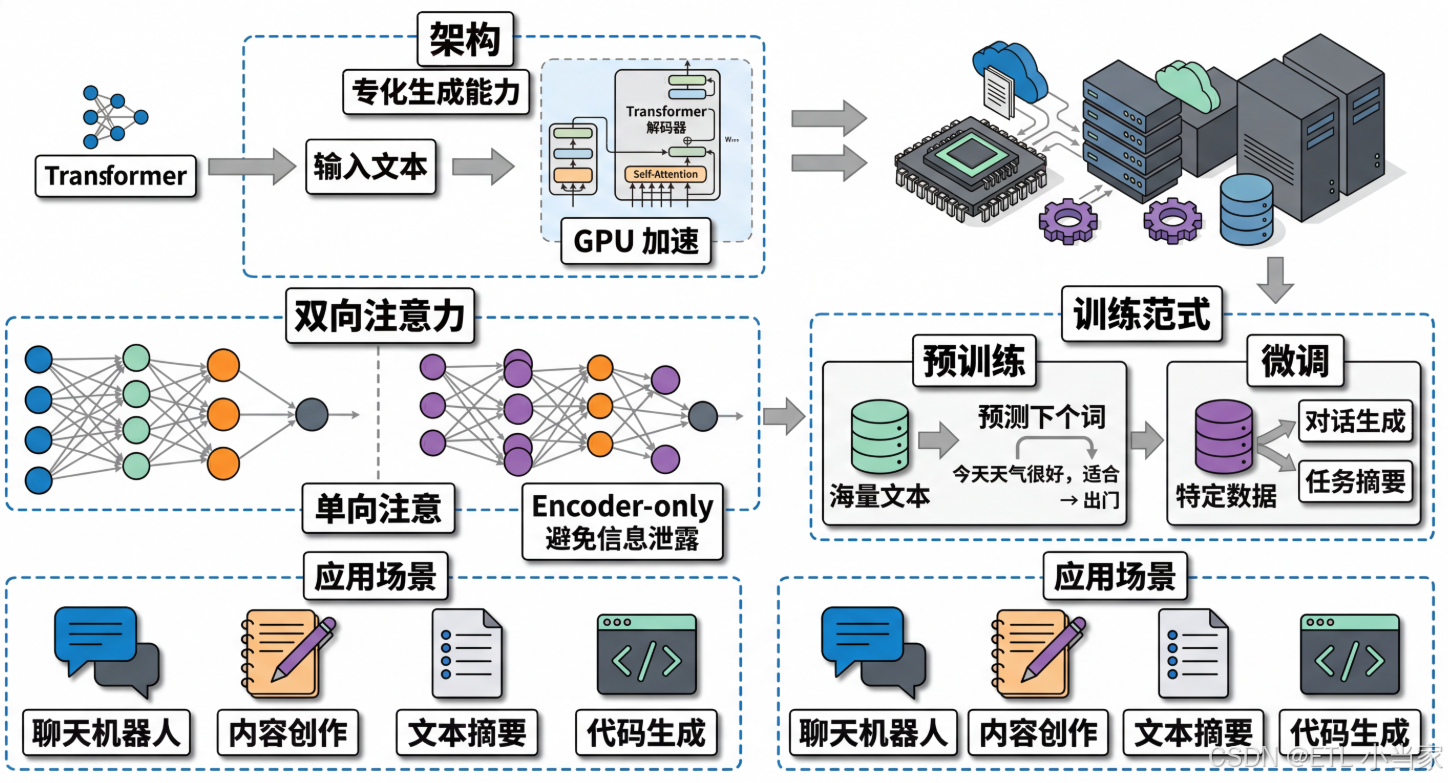
二、为什么需要专门的"生成"模型?
在人工智能应用中,生成任务有着独特的需求:
- 自回归生成:每次只生成一个词,但要确保整体连贯性
- 上下文依赖:新生成的内容必须与之前的上下文保持一致
- 创造性:在遵循规则的同时,还需要一定的创新性
Decoder-only架构通过单向注意力机制完美地满足了这些需求。
单向注意力 vs 双向注意力
| 模型类型 | 注意力方向 | 核心优势 | 典型代表 |
|---|---|---|---|
| Decoder-only | 单向(从左到右) | 自回归生成、避免信息泄露 | GPT |
| Encoder-only | 双向 | 完整上下文理解 | BERT |
GPT的单向注意力确保了在生成第n个词时,只能看到前n-1个词的信息,这模拟了人类写作的真实过程——我们总是基于已写的内容来决定下一步写什么。
三、GPT的训练方式
自回归语言建模
GPT通过"续写游戏"来学习:
输入:今天天气很好,
GPT预测:适合(概率0.65)、阳光(概率0.20)、出门(概率0.15)
输入:今天天气很好,适合
GPT预测:出门(概率0.70)、散步(概率0.25)、运动(概率0.05)
这种训练方式让GPT专注于学习语言的生成规律,而不是理解已有文本的深层含义。
预训练 + 微调范式
- 预训练阶段:在海量文本上学习通用的语言生成能力
- 微调阶段:在特定任务数据上调整生成风格(如问答、摘要、翻译)
这种两阶段训练让GPT既能掌握通用语言知识,又能适应具体应用场景。
四、实际应用场景
1. 聊天机器人
GPT系列模型是现代聊天机器人的核心技术,能够进行自然、连贯的对话。
2. 内容创作
自动生成文章、故事、诗歌、代码等,大大提升创作效率。
3. 文本摘要
将长篇文章压缩成简洁的摘要,保留核心信息。
4. 代码生成
根据自然语言描述生成可执行的代码,降低编程门槛。
5. 机器翻译
将一种语言的文本翻译成另一种语言,保持语义准确性。
五、Decoder-only的优势与挑战
优势
- 强大的生成能力:能够创造连贯、自然的新文本
- 灵活的应用场景:适用于各种生成任务
- 规模化效应:模型越大,生成质量越高
挑战
- 可能产生幻觉:生成看似合理但事实错误的内容
- 缺乏深度理解:对复杂逻辑推理能力有限
- 计算资源消耗大:生成长文本需要大量计算资源
GPT vs BERT:互补而非竞争
| 维度 | GPT (Decoder-only) | BERT (Encoder-only) |
|---|---|---|
| 核心能力 | 生成 | 理解 |
| 注意力机制 | 单向 | 双向 |
| 训练目标 | 预测下一个词 | 填空 + 判断句子关系 |
| 典型应用 | 聊天、创作、翻译 | 分类、问答、实体识别 |
| 类比角色 | 作家 | 图书管理员 |
实际上,GPT和BERT代表了AI处理语言的两个不同方向,它们在实际应用中往往是互补的。比如在一个智能客服系统中,BERT可以用来理解用户问题的意图,而GPT则用来生成自然的回复。
六、架构演进与未来方向
从GPT-1到GPT-4
GPT系列的发展体现了Decoder-only架构的持续进化:
- GPT-1:首次证明了大规模预训练的有效性
- GPT-2:展示了zero-shot学习能力
- GPT-3:实现了few-shot学习,参数规模达到1750亿
- GPT-4:支持多模态输入,推理能力显著提升
混合架构的兴起
虽然纯Decoder-only架构在生成任务上表现出色,但研究者也在探索混合方案:
- Encoder-Decoder架构(如T5、BART):结合理解与生成能力
- Retrieval-Augmented Generation(RAG):结合检索与生成,减少幻觉
这些演进说明,未来的AI系统可能会更加灵活地组合不同的架构组件,以适应复杂的实际需求。
结语
Decoder-only架构的成功告诉我们:专注生成,也能创造奇迹。GPT系列通过专注于"预测下一个词"这一看似简单的任务,却实现了令人惊叹的语言生成能力。
就像人类社会中的专业分工一样,AI模型也在向着专业化发展。Decoder-only架构证明了,在特定领域做到极致,往往比试图面面俱到更有效。
在未来,我们可能会看到更多针对特定生成任务优化的专用架构,同时也会看到不同架构组件的智能组合。这正是GPT给我们的重要启示:理解自己的优势,专注做好一件事,然后不断放大这个优势。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐
 6
6 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)