
【强化学习】用 PPO 玩转倒立摆,20W字总结(七)

😊你好,我是小航,一个正在变秃、变强的文艺倾年。
🔔本文讲解【强化学习】用 PPO 玩转倒立摆,20W字总结(七),期待与你一同探索、学习、进步,一起卷起来叭!
🎯 把我的博客装进你的 Claude Code,它就是你的 AI 学习搭子
想随时搜我的文章、让 AI 帮你深度讲解甚至出面试题?复制下面这段提示词丢进你的 Claude Code——它会自动生成一个本地 SKILL,之后你直接说「搜一下强化学习的文章」就行。RSS 自动同步最新内容,不用手动存任何文件。
请为这个 CSDN 博客创建一个本地 SKILL(存到 .claude/skills/csdn-blog/SKILL.md): RSS 源:https://rss.csdn.net/m0_51517236/rss/map 支持三件事:① 列出最新文章(标题+链接+摘要);② 按关键词搜索; ③ 抓取指定文章全文,作为 AI 学习助手 / 面试官深度讲解并出题考核我。 SKILL.md 里写清楚 RSS URL、调用方式和示例。生成完就能用自然语言搜文章了。一键订阅,长期可用。🚀
上一篇我们把 PPO 的理论掰开了——clip 裁剪、六种情况、概率比。但理论再漂亮,不跑起来都是空的。
这篇就直接上手:把完整的 PPO 代码写出来,在 CartPole 倒立摆上实跑,看看这个"装了刹车"的策略梯度法到底稳不稳。

两个网络:Actor + Critic
PPO 还是 Actor-Critic 架构,先定义演员(策略网络)和评论家(价值网络)。和第 5 篇的结构一样,只是这次把维度参数化:
class PolicyNet(torch.nn.Module):
'''策略网络(演员)'''
def __init__(self, state_dim, hidden_dim, action_dim):
super().__init__()
self.fc1 = torch.nn.Linear(state_dim, hidden_dim)
self.fc2 = torch.nn.Linear(hidden_dim, action_dim)
def forward(self, x):
x = F.relu(self.fc1(x))
return F.softmax(self.fc2(x), dim=1) # 输出动作概率
class ValueNet(torch.nn.Module):
'''价值网络(评论家)'''
def __init__(self, state_dim, hidden_dim):
super().__init__()
self.fc1 = torch.nn.Linear(state_dim, hidden_dim)
self.fc2 = torch.nn.Linear(hidden_dim, 1)
def forward(self, x):
x = F.relu(self.fc1(x))
return self.fc2(x) # 输出状态价值
💡 代码解析:倒立摆的状态是 4 维(state_dim=4),动作 2 个(action_dim=2),隐藏层 128 个神经元。两个网络结构对称,区别只在输出层——策略走 Softmax 出概率,价值直接出标量。
PPO 类:核心实现
PPO 类把两个网络和训练逻辑捏在一起。__init__ 装配演员、评论家、两个优化器,还有一堆超参:
class PPO:
'''PPO 算法,采用截断(clip)方式'''
def __init__(self, state_dim, hidden_dim, action_dim,
actor_lr, critic_lr, lmbda, epochs, eps, gamma, device):
self.actor = PolicyNet(state_dim, hidden_dim, action_dim).to(device)
self.critic = ValueNet(state_dim, hidden_dim).to(device)
self.actor_optimizer = torch.optim.Adam(self.actor.parameters(), lr=actor_lr)
self.critic_optimizer = torch.optim.Adam(self.critic.parameters(), lr=critic_lr)
self.gamma = gamma # 折扣因子
self.lmbda = lmbda # GAE 参数
self.epochs = epochs # 一批数据重复训练几轮(K 步微批次)
self.eps = eps # clip 截断范围
self.device = device
选动作很直接——策略网络出概率,从中采样:
def take_action(self, state):
state = torch.tensor([state], dtype=torch.float).to(self.device)
probs = self.actor(state)
action_dist = torch.distributions.Categorical(probs)
action = action_dist.sample()
return action.item()
update 是 PPO 的灵魂——上一篇的 clip 理论全在这里落地:
def update(self, transition_dict):
states = torch.tensor(transition_dict['states'], dtype=torch.float).to(self.device)
actions = torch.tensor(transition_dict['actions']).view(-1, 1).to(self.device)
rewards = torch.tensor(transition_dict['rewards'], dtype=torch.float).view(-1, 1).to(self.device)
next_states = torch.tensor(transition_dict['next_states'], dtype=torch.float).to(self.device)
dones = torch.tensor(transition_dict['dones'], dtype=torch.float).view(-1, 1).to(self.device)
# ① 算 TD 目标和 TD 误差
td_target = rewards + self.gamma * self.critic(next_states) * (1 - dones)
td_delta = td_target - self.critic(states)
# ② 用 GAE 算优势
advantage = compute_advantage(self.gamma, self.lmbda, td_delta.cpu()).to(self.device)
# ③ 记录旧策略的动作概率(detach,当作固定参考)
old_log_probs = torch.log(self.actor(states).gather(1, actions)).detach()
# ④ K 步微批次更新
for _ in range(self.epochs):
log_probs = torch.log(self.actor(states).gather(1, actions))
ratio = torch.exp(log_probs - old_log_probs) # 概率比 p_t
surr1 = ratio * advantage
surr2 = torch.clamp(ratio, 1 - self.eps, 1 + self.eps) * advantage
actor_loss = torch.mean(-torch.min(surr1, surr2)) # PPO 损失
critic_loss = torch.mean(F.mse_loss(self.critic(states), td_target.detach()))
self.actor_optimizer.zero_grad()
self.critic_optimizer.zero_grad()
actor_loss.backward()
critic_loss.backward()
self.actor_optimizer.step()
self.critic_optimizer.step()
💡 代码解析:对照上一篇的理论看就清楚了——ratio 就是概率比 p t p_t pt,surr1 是未裁剪项 p t A t p_t A_t ptAt,surr2 是裁剪项 clip ( p t ) A t \text{clip}(p_t) A_t clip(pt)At,取 min 就是 PPO 那个目标函数。old_log_probs 用 .detach() 固定住(旧策略不参与梯度)。外层 for _ in range(self.epochs) 就是上一篇说的"一批数据 K 步微批次"——同一批数据榨 10 次。
广义优势估计 GAE
update 里用到的 compute_advantage 是 GAE(广义优势估计)——比单步 TD 误差更稳的优势估计:
def compute_advantage(gamma, lmbda, td_delta):
td_delta = td_delta.detach().numpy()
advantage_list = []
advantage = 0.0
for delta in td_delta[::-1]: # 逆序遍历
advantage = gamma * lmbda * advantage + delta
advantage_list.append(advantage)
advantage_list.reverse()
return torch.tensor(advantage_list, dtype=torch.float)
💡 代码解析:和算回报 G t G_t Gt 的逆序递推一个套路,只是多了个 lmbda( λ \lambda λ)控制"看几步"。 λ = 0 \lambda=0 λ=0 退化成单步 TD, λ = 1 \lambda=1 λ=1 退化成蒙特卡洛,中间值就是 n n n 步 TD 的平滑混合。倒立摆里取 lmbda=0.95。
训练:在 CartPole 上跑
超参定下来,开始训练:
actor_lr = 1e-3 # 策略学习率
critic_lr = 1e-2 # 价值学习率(大一点,学快点)
num_episodes = 500
hidden_dim = 128
gamma = 0.98
lmbda = 0.95 # GAE 的 λ
epochs = 10 # 一批数据训练 10 轮
eps = 0.2 # clip 范围
env = gym.make('CartPole-v0')
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.n
agent = PPO(state_dim, hidden_dim, action_dim, actor_lr, critic_lr,
lmbda, epochs, eps, gamma, device)
return_list = train_on_policy_agent(env, agent, num_episodes)
训练框架是标准的 on-policy 套路——采一回合数据,存进 transition_dict,回合结束调一次 update:
def train_on_policy_agent(env, agent, num_episodes):
return_list = []
for i_episode in range(num_episodes):
episode_return = 0
transition_dict = {'states': [], 'actions': [], 'next_states': [],
'rewards': [], 'dones': []}
state = env.reset()
done = False
while not done:
action = agent.take_action(state)
next_state, reward, done, _ = env.step(action)
transition_dict['states'].append(state)
transition_dict['actions'].append(action)
transition_dict['next_states'].append(next_state)
transition_dict['rewards'].append(reward)
transition_dict['dones'].append(done)
state = next_state
episode_return += reward
return_list.append(episode_return)
agent.update(transition_dict) # 一回合结束,更新一次
return return_list
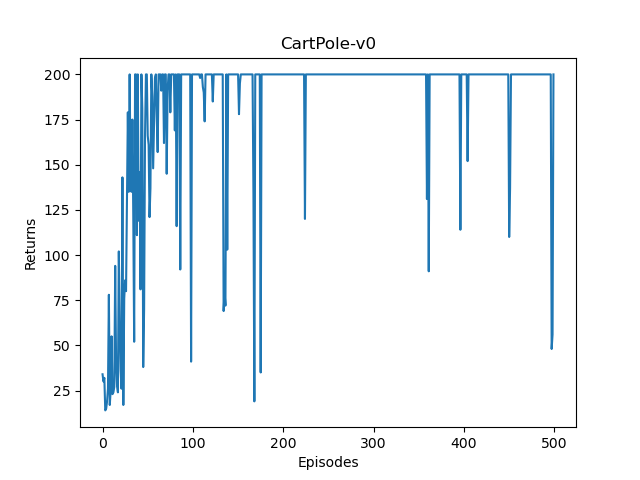
🚩 运行结果:曲线稳稳上升,很快就能稳定在 200 分(CartPole-v0 的上限)。对比之前 REINFORCE 的震荡,PPO 这"刹车"装得值。

小结
这篇把 PPO 从理论落到了代码:两个网络、一个带 clip 的 update、一个 GAE 优势估计,在 CartPole 上稳稳跑到满分。
PPO 是 OpenAI 使用的默认强化学习算法。
到这里,强化学习的"游戏通关"部分就告一段落了——从随机策略、策略梯度、REINFORCE、基线、Actor-Critic,一路到 PPO,我们让倒立摆从"几步就倒"变成了"稳稳 200 分"。
但强化学习真正出圈,不是靠玩游戏,而是靠对齐大模型。下一篇我们进入 RLHF(基于人类反馈的强化学习)——看看 PPO 是怎么被用来微调 ChatGPT、让 AI 说话像人话的。
📌 [ 笔者 ] 文艺倾年
📃 [ 更新 ] 2026.06.14
❌ [ 勘误 ] /* 暂无 */
📜 [ 声明 ] 由于作者水平有限,本文有错误和不准确之处在所难免,
本人也很想知道这些错误,恳望读者批评指正!


小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐

 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)