
阿里:智能体连贯交错工具规划评测
多模态大模型如何在图文交错生成任务中,自主规划何时、何地及调用何种工具以统一事实性与创造性?论文提出了智能体工具规划新范式,构建了首个支持混合图像来源的 ATP-Bench 基准及无需真值的多智能体评估系统 MAM。

📖标题:ATP-Bench: Towards Agentic Tool Planning for MLLM Interleaved Generation
🌐来源:arXiv, 2603.29902v1
🌟摘要
文本和图像的交错生成是多模态大型语言模型(MLLM)的一个重要前沿,它提供了一种更直观的方式来传达复杂的信息。当前的范式依赖于图像生成或检索增强,但它们通常将两者视为相互排斥的路径,未能将真实性与创造性统一起来。我们认为,该领域的下一个里程碑是简化工具规划,该模型作为一个中央控制器,自主决定何时,何地,以及调用哪些工具来产生视觉关键查询的交错响应。为了系统地评估这种范式,我们引入了ATP-Bench,一个由7,702个QA对组成的新基准(包括1,592个VQA对),涉及8个类别和25个视觉关键意图,具有人工验证的查询和地面事实。此外,为了独立于端到端执行和改变工具后端来评估代理计划,我们提出了一个多代理MLLM作为判断(MAM)系统。MAM评估工具调用精度,识别错过的工具使用机会,我们对10个最先进的MLLM进行了广泛的实验,结果表明,模型难以进行连贯的交错规划,并且在工具使用行为方面表现出显著的变化,突出了改进的巨大空间,并为推进交错生成提供了可操作的指导。
🛎️文章简介
🔸研究问题:多模态大模型如何在图文交错生成任务中,自主规划何时、何地及调用何种工具以统一事实性与创造性?
🔸主要贡献:提出了智能体工具规划新范式,构建了首个支持混合图像来源的 ATP-Bench 基准及无需真值的多智能体评估系统 MAM。
📝重点思路
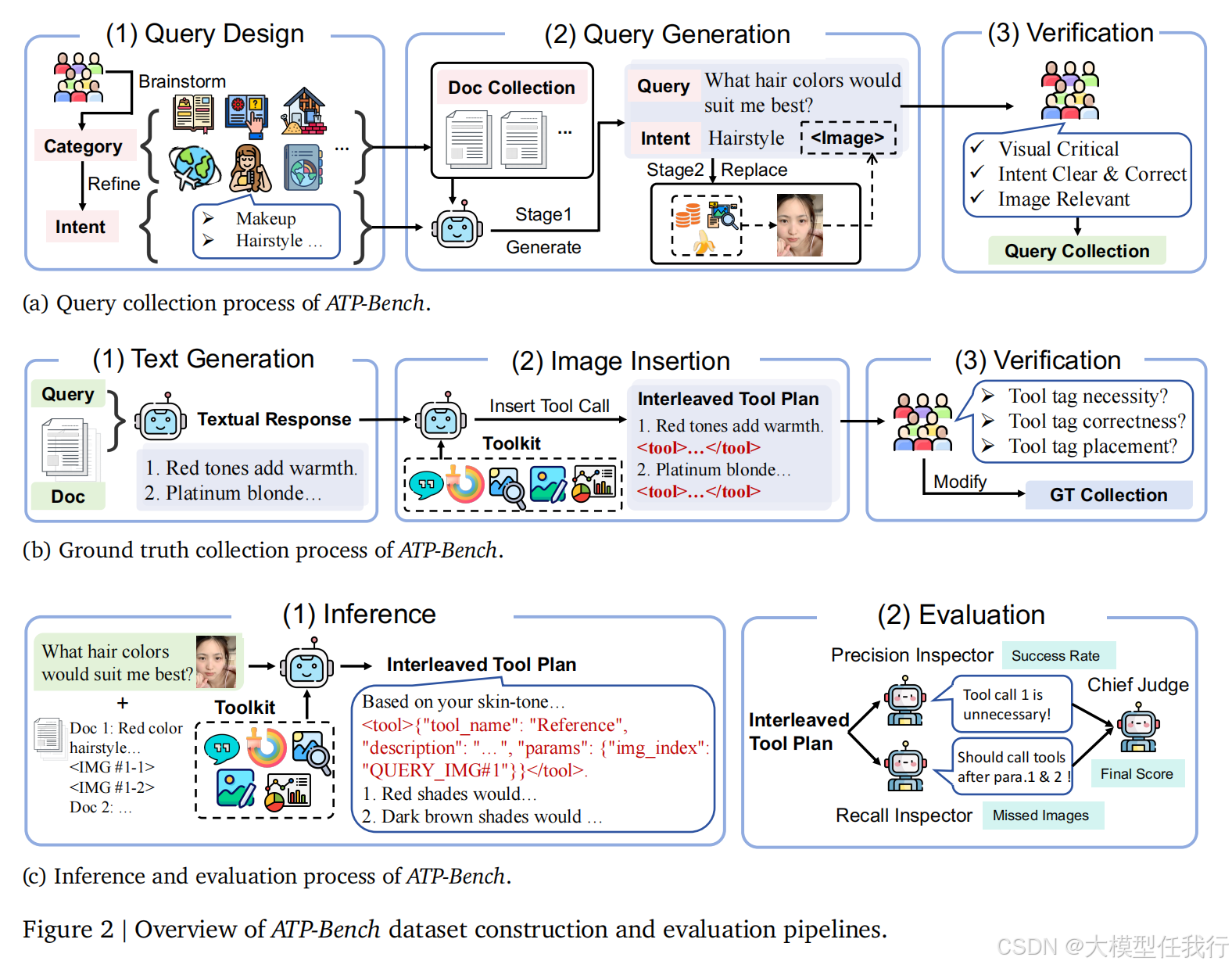
🔸定义智能体工具规划范式,将模型视为中央控制器,自主决定调用引用、扩散生成、搜索、代码绘图及编辑等五类工具来生成交错响应。
🔸构建 ATP-Bench 基准,包含 7702 个问答对,覆盖八类视觉关键场景,采用专家标注确保查询与真值的高质量及视觉必要性。
🔸设计多智能体裁判系统 MAM,由精度检查员评估工具调用必要性及参数正确性,召回检查员识别遗漏的视觉机会,主裁判综合打分。
🔸实施无需端到端执行且独立于具体工具后端的评估策略,通过多智能体协作量化模型的规划能力而非仅仅关注最终生成结果。
🔎分析总结
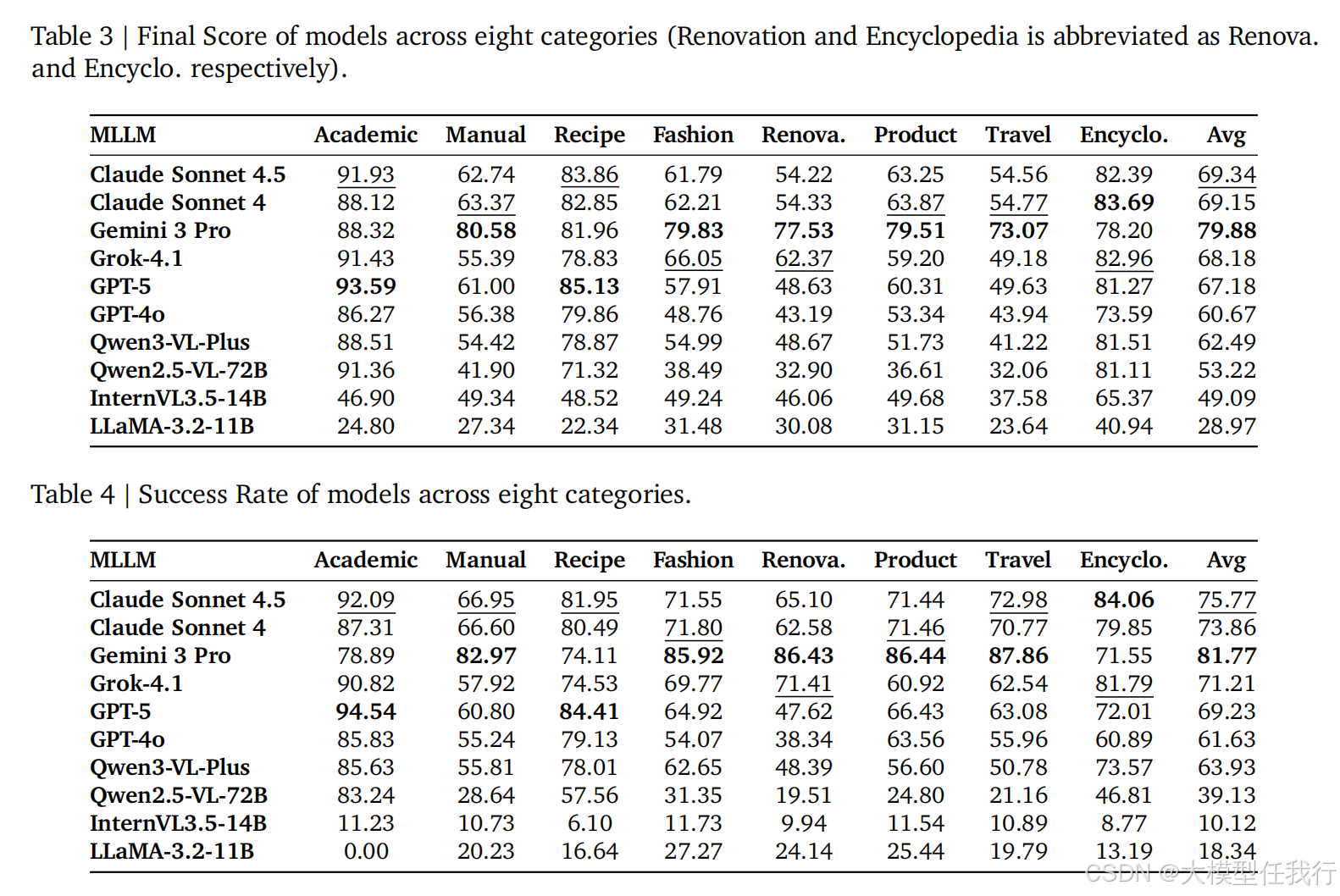
🔸实验显示现有顶尖模型在连贯的交错工具规划上仍存在困难,尤其在旅行和装修等复杂场景中表现不佳。
🔸Gemini 3 Pro 在各项指标中领先,展现出平衡的工具使用策略,而其他模型在工具调用频率和偏好上存在显著差异。
🔸学术和百科类任务相对简单,而需要复杂工具协调的旅行规划任务最难,主要失败原因在于未能识别工具使用机会。
🔸开源模型整体表现较弱,常出现格式错误或无效调用,表明其在视觉差距检测和有效工具执行方面存在复合缺陷。
🔸少样本提示能显著提升具备指令遵循能力模型的表现,但无法弥补基础规划能力薄弱模型的核心缺陷。
💡个人观点
论文将“智能体工具规划”确立为图文交错生成的核心能力,不仅仅是任务分解和单步推理,还有工具调用后的编排。
🧩附录

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐



 6
6 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)