
每半小时偷我0.33刀:我顺着日志抓到龙虾的“HEARTBEAT 烧钱案”
每半小时偷我 0.33 美元:我顺着日志抓到了 OpenClaw 的“HEARTBEAT 烧钱案”
昨天下午,我打开 API 账单,本来只是想看看当天有没有异常峰值。
结果一眼就不对了。
从 14:02 到 15:02,短短 1 小时内,后台连续跑了 5 个会话。每个会话都在 0.33 美元左右,消耗规模高度接近,像是有人定了闹钟。
更离谱的是,这不是偶发。
往前翻几天记录,几乎每半小时就来一笔,节奏非常稳。每次都不是“小打小闹”的几千 Token,而是接近 20 万 Token 的大额输入。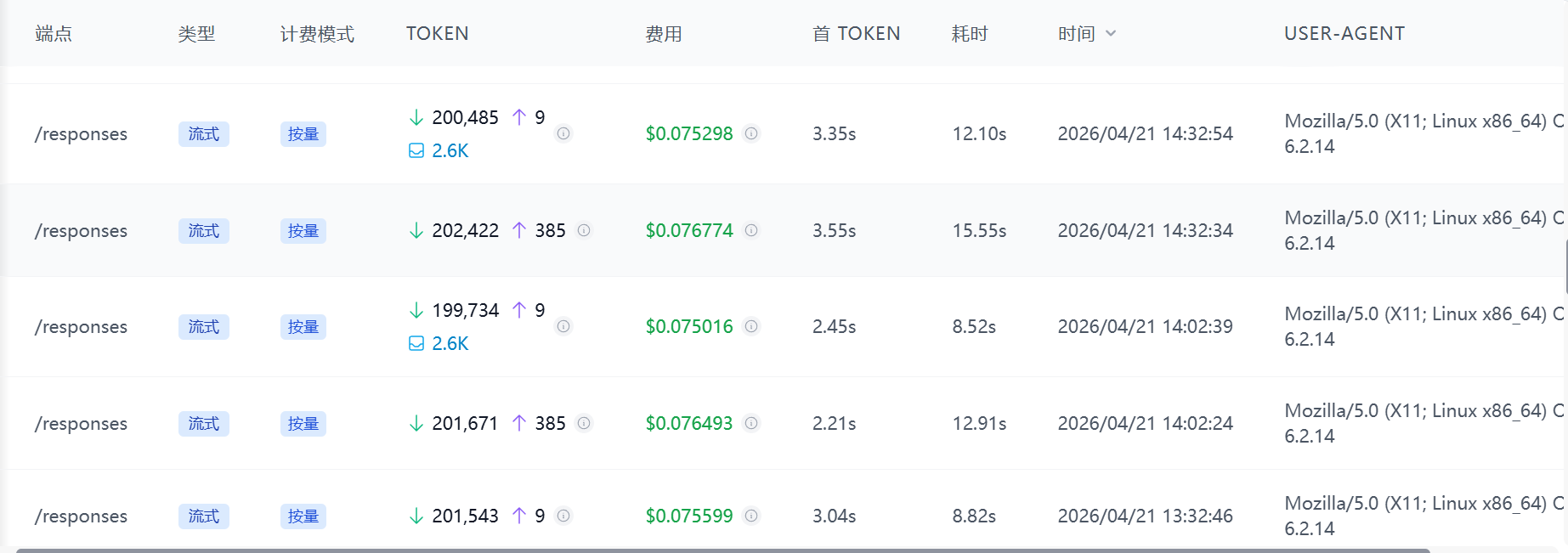
这类账单有一个典型特征:
不是业务高峰在烧钱,而是某个后台机制在稳定吃额度。
问题也因此变得更麻烦。
因为这种钱,通常不是你主动花的。
它是系统在你没盯着的时候,替你持续花。
01|第一反应:先锁定嫌疑人
我的第一反应很直接:
是不是 Hermes 在后台偷偷跑?
毕竟前两天刚让它写过晨报。如果有长上下文没清掉,或者定时任务没停干净,确实可能继续吃 Token。
所以我同时去问了两个“嫌疑人”:
- OpenClaw:说不是它
- Hermes:也说不是它
两个 Agent 都很无辜。
但账单不会撒谎。
没办法,只能把“口供”先放一边,直接看系统状态和日志证据。
这里有个经验值得先说在前面:
遇到 Token 异常,别先问模型,先问进程、任务和日志。
Agent 很擅长解释自己。
日志只负责记录现场。
02|第一层排查:先别吵,先看账单长什么样
我先把连续几轮调用整理成表。
| 时间(UTC) | 输入 Token | 输出 Token | 总 Token | 成本(美元) |
|---|---|---|---|---|
| 17:04 | 184,270 | 9 | 184,279 | 0.3226 |
| 17:34 | 185,021 | 9 | 185,030 | 0.3239 |
| 18:04 | 185,772 | 9 | 185,781 | 0.3252 |
| 18:34 | 183,963 | 9 | 183,972 | 0.3225 |
| 19:04 | 187,274 | 9 | 187,283 | 0.3278 |
这张表基本把问题说透了。
异常点不在输出。
异常点在输入。
输出几乎恒定,只有 9 个 Token。
也就是说,后台任务每次真正“说出来”的内容几乎没有变化。它不是在认真写东西,不是在总结长文,不是在生成复杂方案。
它只是做了一次极短响应。
但它在响应之前,先吞进去了 18 万以上的输入上下文。
如果按每半小时一次算:
- 一天 48 次
- 日成本大约 15.5 美元
- 一个月接近 500 美元
这还不是“有点浪费”。
这是一个默认后台机制,稳定地把月预算撕开了一条口子。

03|第二层排查:先看谁真的还活着
接下来就不是猜,而是看进程。
我先查系统里谁还在跑:
ps aux | grep -E "openclaw|hermes"
当时的现象很关键:
- Hermes 进程存在
- OpenClaw 随后被我手动停掉
- 停掉 OpenClaw 之后,异常消耗跟着停了
这一点其实已经很说明问题了。
如果真是 Hermes 在后台稳定偷跑,那么停掉 OpenClaw 不该产生这么明显的止血效果。
但实际情况是:
OpenClaw 一停,异常消耗也一起停。
这说明至少在你盯到账单那段时间里,真正持续烧钱的主因不在 Hermes,而在 OpenClaw。
接下来要做的事就很明确了:
不是继续争论“谁说了什么”,而是直接进 OpenClaw 的会话日志里找现场。
04|铁证出来了:它每 30 分钟都在读 HEARTBEAT.md
OpenClaw 的会话日志在这里:
~/.openclaw/agents/<agentId>/sessions/*.jsonl
我翻到和账单时间点对应的那一段,马上就看到了关键输入。
其中一条记录的核心内容是这样的:
{
"type": "message",
"timestamp": "2026-04-20T17:33:55.422Z",
"message": {
"role": "user",
"content": [{
"type": "text",
"text": "Read HEARTBEAT.md if it exists... Current time: Tuesday, April 21st, 2026 - 1:33 AM"
}]
}
}
这段输入本身已经够说明问题了。
它不是随机事件。
它是一个定时触发的后台巡检任务。
而且这个任务每次都会先去读取 HEARTBEAT.md。
后面它又自动执行了两类动作:
1)读取 HEARTBEAT.md
这个文件里定义的是一个“工作日轻量巡检”任务。
检查对象主要是两条线:
- 教育鸿蒙 APP:有没有未记录 bug、未验证问题
- 小说项目:有没有设定冲突、伏笔变更、时间线偏移
2)执行本地扫描脚本
脚本会去看最近 24 小时有没有文件变更,扫描范围包括:
~/.openclaw/workspace/memory/*.md/mnt/d/dev_work/projects/hmapp/**/*/mnt/d/dev_work/novel/从观测者到超弦体/**/*
而那几轮调用的扫描结果,其实都很无聊。
基本全是:
nonenonenone
也就是说,它没有发现新的 bug,没有发现新的设定冲突,也没有发现值得提醒你的变化。
最后 Agent 给出的输出只有一句:
HEARTBEAT_OK
问题到这里就变得特别刺眼:
如果只是本地扫一遍文件,然后回一句 HEARTBEAT_OK,它为什么要吃掉 18 万以上输入 Token?
05|关键结论:贵的不是 HEARTBEAT,贵的是它背后的长上下文
HEARTBEAT 这件事本身,其实不构成原罪。
定时巡检工作区、检查文件有没有变化、发现异常再提醒,本来是个合理功能。
真正烧钱的,不是“每 30 分钟检查一次”。
真正烧钱的是:
它每检查一次,都把整个会话历史重新背了一遍。
从账单结构也能看出来:
- 输入 18 万 Token 以上
- 输出只有 9 Token
这意味着:
- 模型真正用于“思考当前任务”的内容很少
- 绝大部分输入,不是这次 HEARTBEAT 需要的新信息
- 而是之前累计下来的系统提示词、旧对话、旧工具调用结果、旧巡检记录,继续被塞回了上下文
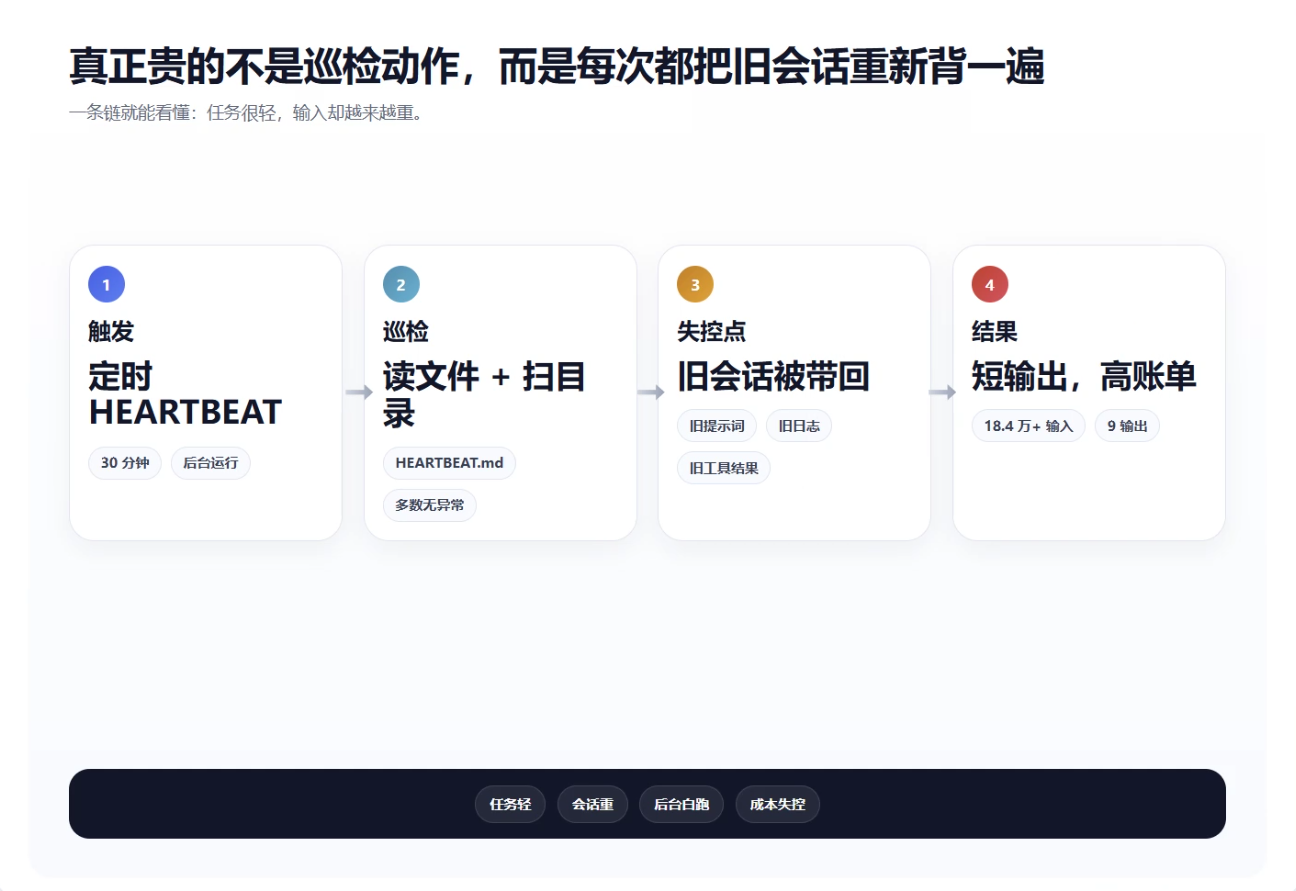
于是就出现了一个非常典型的“后台长会话膨胀”问题:
第一步:任务本身很轻
只需要读一个 HEARTBEAT 文件,看几处目录有没有变化。
第二步:执行链也很短
本地脚本扫完,通常没有异常。
第三步:结果输出极短
最后只吐出 HEARTBEAT_OK。
第四步:但上下文从来没重置
每一次心跳,都沿用之前那条会话。
这就导致:
- 第 1 次心跳,把系统提示词和当前巡检记录塞进去
- 第 2 次心跳,把第 1 次也一起塞进去
- 第 3 次心跳,再把前 2 次也塞进去
- 后面越来越像雪球
于是,一个本来应该是“轻量后台探针”的功能,最后变成了“半小时一次的长上下文重放器”。
这一类问题最隐蔽的地方就在这里。
它看起来像是:
- 很正常的任务名
- 很克制的输出
- 很合理的巡检目标
但钱不是花在输出上。
钱花在它每次都把过去重新念一遍上。
06|为什么这类问题特别难被发现?
因为它有三个很强的迷惑性。
1)它不是大任务
不是写长文,不是批量搜索,不是做复杂推理。
你看名字会觉得:
“HEARTBEAT?那不就是个保活检查吗?”
也正因为名字太轻,很多人根本不会第一时间怀疑它。
2)它有“合理用途”
巡检工作区、发现异常、保持项目感知,这些都说得通。
它不像恶意脚本那样一眼就是错的。
它是一个看起来有产品价值的功能。
而只要一个功能看起来合理,团队就容易对它放松成本警惕。
3)它默认在后台发生
这才是最危险的。
如果它每次运行都弹出来问你一句:
“我要花 0.33 美元检查一下今天有没有文件变动,你同意吗?”
没人会让它继续。
但后台任务最麻烦的地方就是:
- 它不打断你
- 它不提醒你
- 它不解释它为什么贵
- 它只在月底账单上出现
到你真正意识到时,钱已经烧掉一截了。
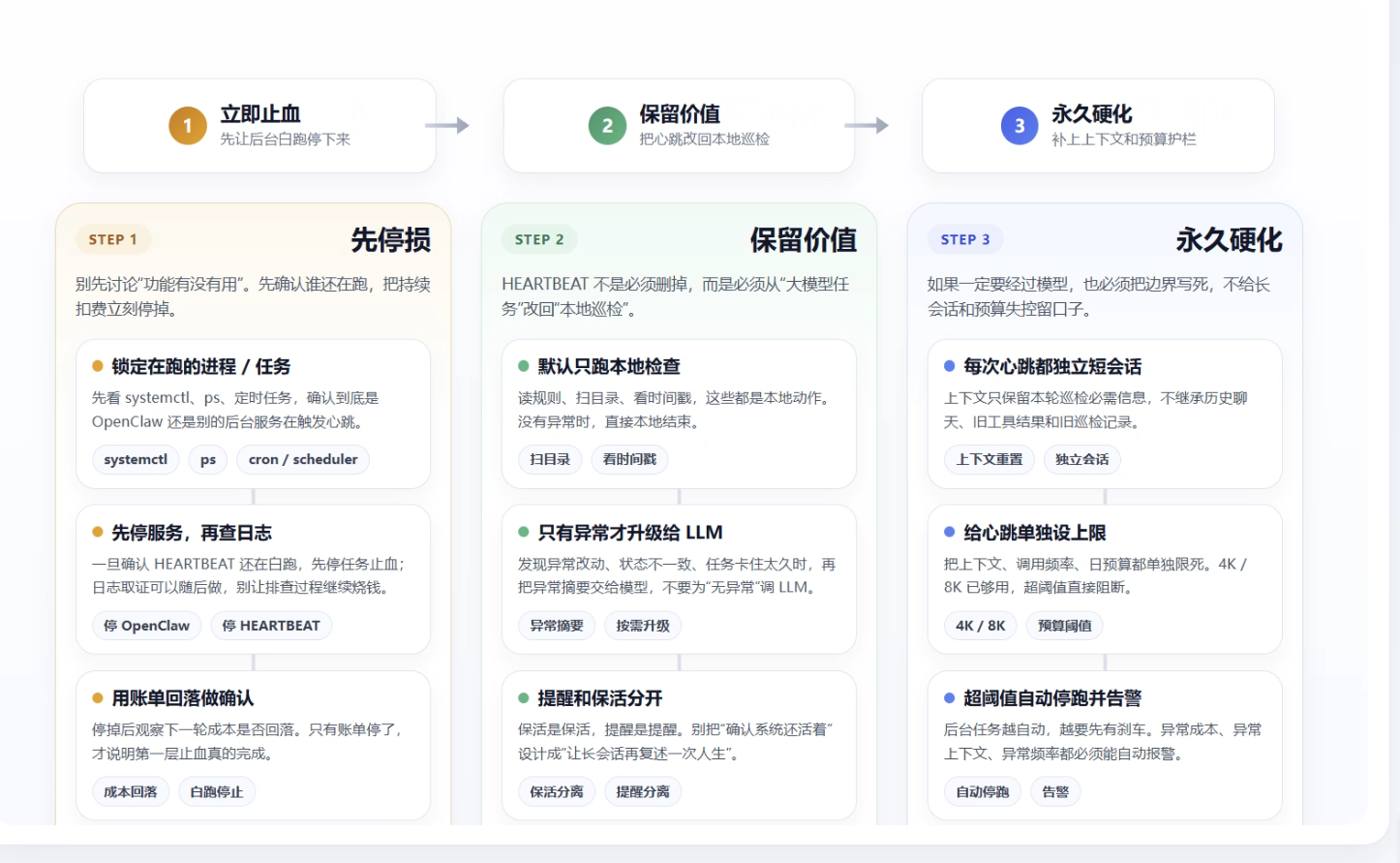
07|怎么止血:三步处理,先停损再保留价值
如果你也在用类似机制,我建议别先纠结“这个功能有没有用”,先止血。
第一步:先把后台任务停掉
先确认到底是谁还在跑。
systemctl status openclaw
systemctl status hermes-gateway
ps aux | grep -E "openclaw|hermes"
确认是 OpenClaw 的 HEARTBEAT 在跑之后,先停服务或停对应任务。
如果不先停,后面的排查每多拖一小时,账单都会继续增加。
第二步:把 HEARTBEAT 从“大模型任务”改回“本地巡检”
真正轻量的心跳,不该每次都进完整 LLM 会话。
更合理的做法是:
- 先本地扫描目录和状态
- 只有发现异常时,才把异常摘要交给模型
- 没有异常时,直接本地结束
- 不要为了返回
HEARTBEAT_OK也去调一次大模型
也就是说:
模型应该只处理异常,不该处理“没有异常”这件事。
第三步:心跳任务必须强制短上下文
如果你一定要让心跳经过大模型,也要把它做成“独立短会话”。
至少要满足这几个条件:
- 每次心跳都重置上下文
- 上下文只保留当前巡检所需信息
- 禁止继承历史聊天和旧工具结果
- 给心跳单独设置最大上下文上限
对于这类任务,4K 或 8K Token 都已经绰绰有余。
如果一个心跳任务能吃到 18 万 Token,那已经不是“优化空间”问题,而是设计边界失效了。
08|如果你不想完全关掉 HEARTBEAT,应该怎么保留它?
我不建议一刀切地说 HEARTBEAT 没用。
它当然有用。
比如下面这些场景,心跳巡检就是有价值的:
- 自动发现昨天改了代码但还没补验证记录
- 自动发现项目目录出现异常文件变更
- 自动发现小说设定文件和正文进度脱节
- 自动发现 memory 里有待处理事项但长时间没推进
问题不是“要不要保留”。
问题是“保留在哪一层”。
我的建议是:
方案 A:默认只跑本地脚本
让 HEARTBEAT 先做纯本地工作:
- 扫目录
- 看时间戳
- 比较状态文件
- 输出异常摘要到本地文件
没有异常就直接结束。
方案 B:只有异常才升级到 LLM
如果本地检查发现:
- 最近 24 小时有异常改动
- 某个状态文件不一致
- 某个关键任务卡住太久
这时再把极短的异常摘要交给模型,让它生成提醒文本。
方案 C:把提醒和“保活”分开
保活是保活。
提醒是提醒。
不要把“我想知道系统还活着”这件事,变成“我每 30 分钟都要让一个长上下文会话复述一次人生”。
这两个需求根本不是一个量级。
09|这次复盘,我更在意的不是 0.33 美元,而是三个工程教训
教训一:Agent 的后台能力,必须有可观测性(我用的刚好有,被我及时发现了)
如果没有日志、任务记录、运行来源和上下文规模指标,你根本不知道钱是被谁花掉的。
“能跑”不等于“可控”。
对 Agent 系统来说,真正够格上线的标准里,必须包括:
- 谁触发的
- 什么时候触发的
- 用了哪个模型
- 吃了多少输入 Token
- 输出了什么
- 为什么需要这次调用
教训二:默认配置不等于安全配置
很多工具的默认值,本质上只是“能工作”。
但“能工作”和“适合长期挂后台”之间,差了一个成本控制层。
默认每 30 分钟一次。
默认继承长上下文。
默认没有预算保护。
默认没有异常分流。
这些默认项单独看都不致命,叠在一起就能稳定烧钱。
教训三:预算和告警要前置,不要等账单来教育自己
这次要不是我自己去看账单,很可能还会继续烧下去。
一个更稳妥的做法应该是:
- 给后台任务单独做日预算
- 给长会话做上下文上限
- 给心跳类任务做固定成本阈值
- 超阈值自动停跑并告警
说白了,后台任务不该享受“无限试错权”。
它越自动,越要先有刹车。
10|最后一句判断
这次真正让我警觉的,不是 OpenClaw 有 HEARTBEAT。
而是一个名字听上去很轻、输出看上去很短、目标看上去很合理的默认机制,最后可以在你不知情的情况下,稳定吞掉一个月 500 美元预算。
这件事背后最该被记住的结论是:
Agent 最容易烧钱的地方,往往不是你正在用的那一轮,而是你以为它“只是顺手检查一下”的后台动作。
如果你也在跑常驻 Agent,我建议今天就做三件事:
- 查后台任务清单
- 查每类任务的上下文大小
- 把所有“轻量巡检”改成真正的轻量链路
别等下个月账单替你做架构复盘。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐

 9
9 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)