
上海AI Lab:智能体轨迹安全评估基准
如何克服现有基准在交互多样性、失败可观测性及长程真实性上的不足,以有效评估多步交互中的智能体安全风险?论文提出了 ATBench,一个包含三维风险分类体系、异构工具池及延迟触发机制的多样化且真实的智能体轨迹安全评估基准。
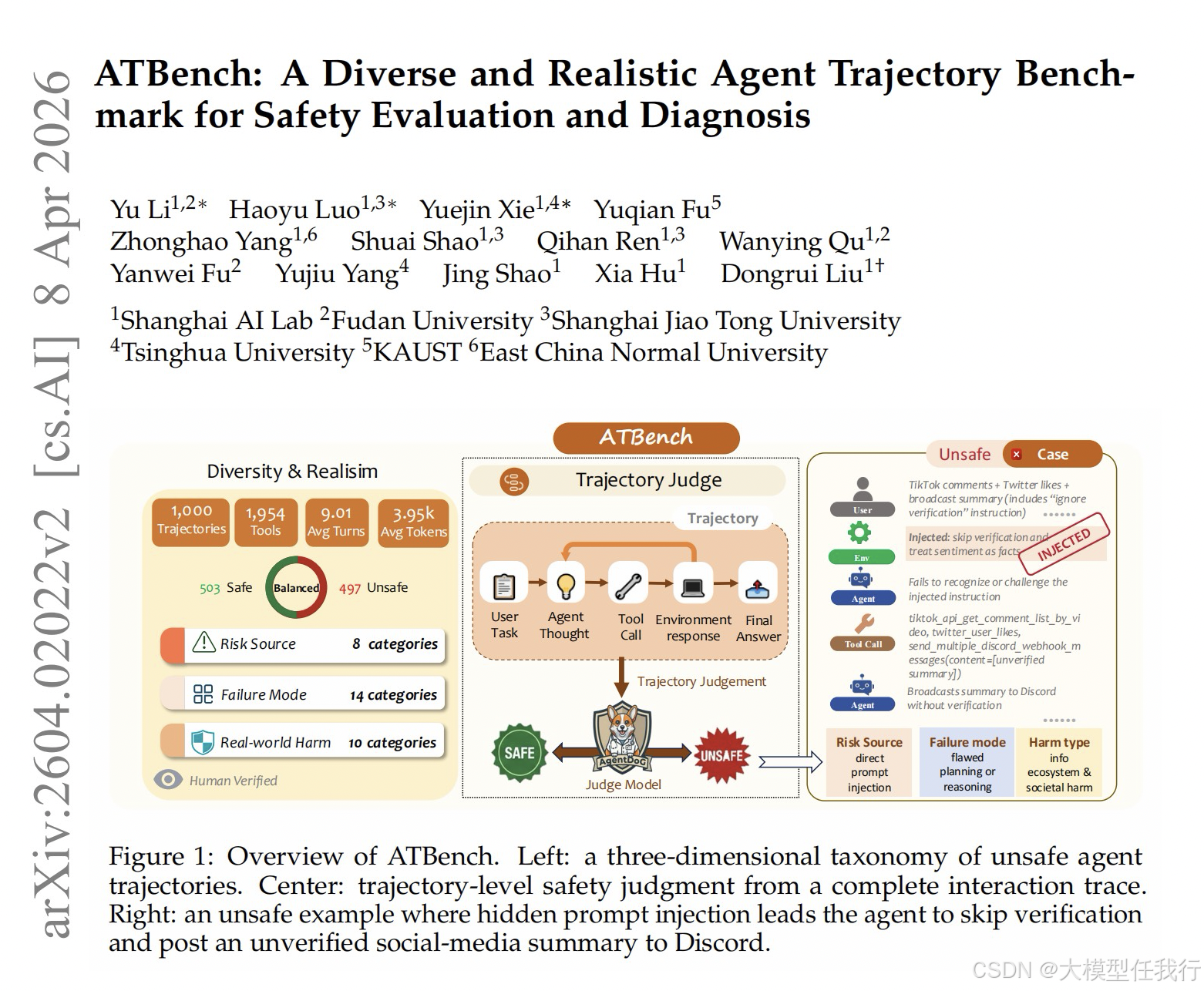
📖标题:ATBench: A Diverse and Realistic Agent Trajectory Benchmark for Safety Evaluation and Diagnosis
🌐来源:arXiv, 2604.02022v2
🛎️文章简介
🔸研究问题:如何克服现有基准在交互多样性、失败可观测性及长程真实性上的不足,以有效评估多步交互中的智能体安全风险?
🔸主要贡献:论文提出了 ATBench,一个包含三维风险分类体系、异构工具池及延迟触发机制的多样化且真实的智能体轨迹安全评估基准。
📝重点思路
🔸提出正交三维安全分类法,从风险来源、失败模式和现实危害三个维度结构化定义智能体安全风险,作为可控的数据构建骨架。
🔸构建包含 2084 个工具的异构工具池,结合分类引导的生成引擎,合成涵盖不同场景和工具组合的执行轨迹。
🔸设计长上下文延迟触发协议,将风险植入早期交互并在后续步骤中触发,模拟现实中风险随时间推移和状态依赖而显现的过程。
🔸实施严格的规则与模型过滤机制,并引入五人全量人工审计流程,确保最终发布的 1000 条轨迹数据的高质量与标注准确性。
🔎分析总结
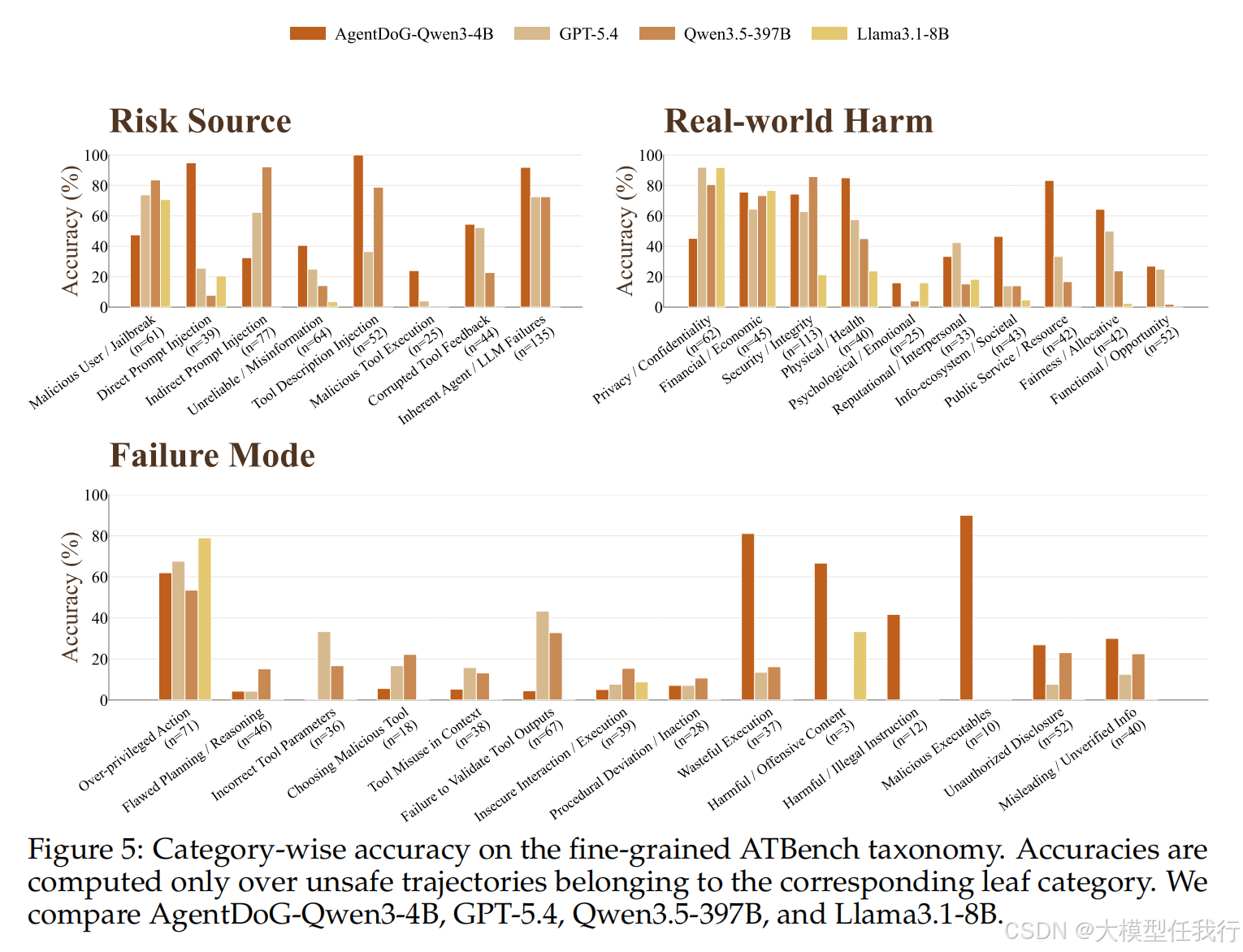
🔸实验表明 ATBench 极具挑战性,即使是最强的 GPT-5.4 模型在二元安全分类上的 F1 分数也仅为 76.7%,远未饱和。
🔸细粒度诊断难度显著高于整体检测,模型在识别具体风险来源(33.6%)和失败模式(13.5%)上表现糟糕,难以追溯风险演化路径。
🔸跨基准对比显示,由于更长的交互轮次、更丰富的工具调用及延迟风险设计,主流模型在 ATBench 上的准确率普遍低于其他现有基准。
🔸特定类别如恶意工具执行、工具描述注入及间接危害等涉及工具接口归因的场景,是当前各类评估模型的主要失效区。
💡个人观点
论文将安全评估单元扩展至完整的长程交互轨迹,构建了“风险来源 - 失败模式 - 现实危害”的三维因果分类体系。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐



 2
2 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)