
LangGraph 实战:从 0 搭建票据识别智能体,附完整源码
1.项目背景
发票整理一直是一个很典型的“高频但琐碎”的场景:图片格式不统一、票据类型复杂、字段分散,而且人工录入不仅耗时,还容易出错。这个项目的目标,就是把“上传发票 → 自动识别 → 结构化整理 → 导出表格”串成一条完整链路,让发票处理尽可能自动化。
从整体设计上看这个项目把 OCR 识别、规则归一化、LLM 二次分析、Excel 导出、Web 交互 组合成了一个可用的发票管理助手。
项目已开源至GitHub:
2.项目运行
申请APIKEY
打开硅基流动官网:
SiliconCloud
申请一个APIKEY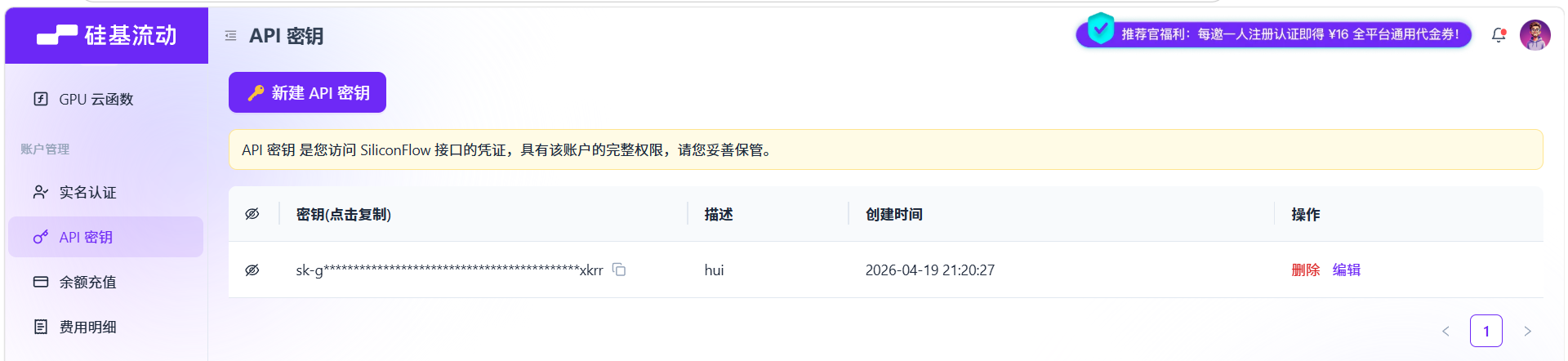
登录腾讯云官网:
腾讯云 产业智变·云启未来 - 腾讯
进入控制台: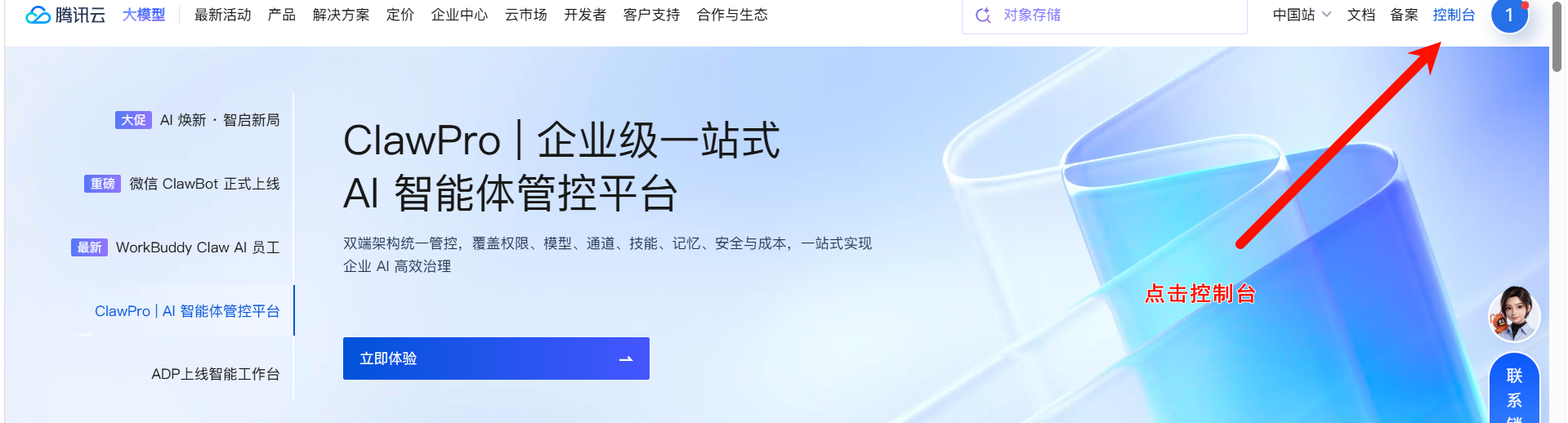
进入OCR控制台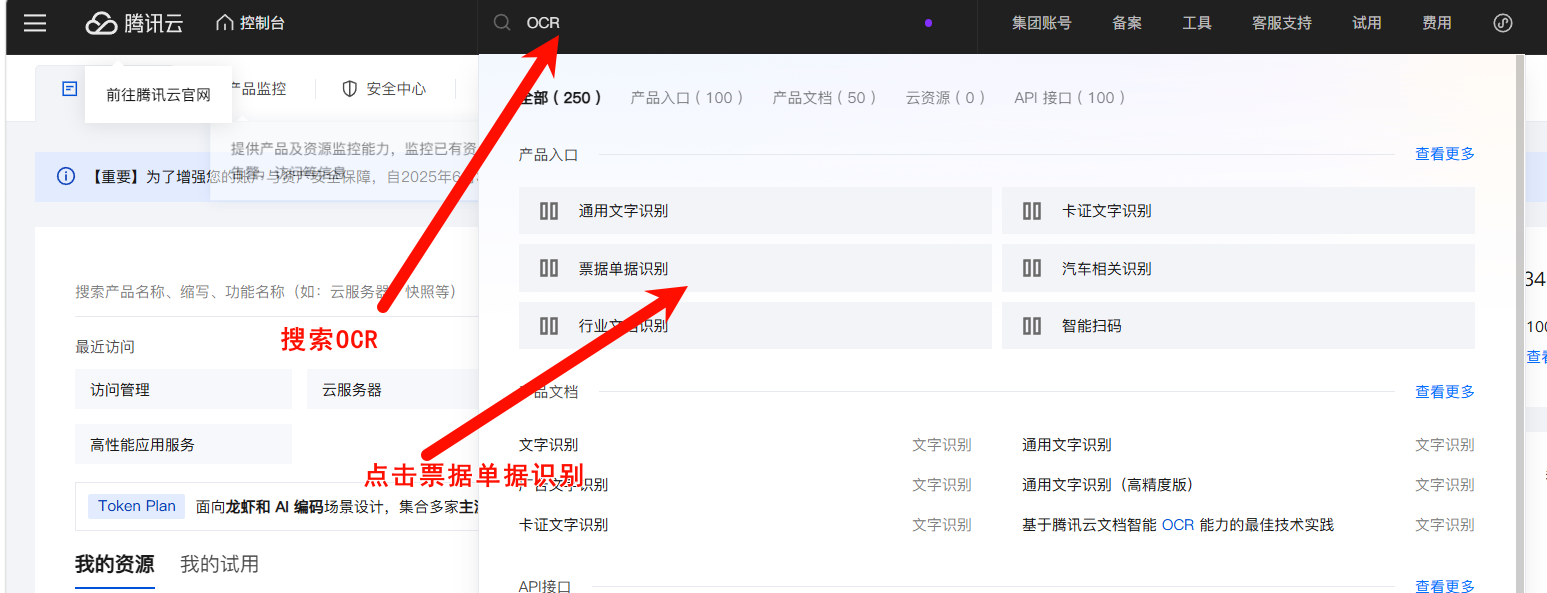
查看免费额度
申请密钥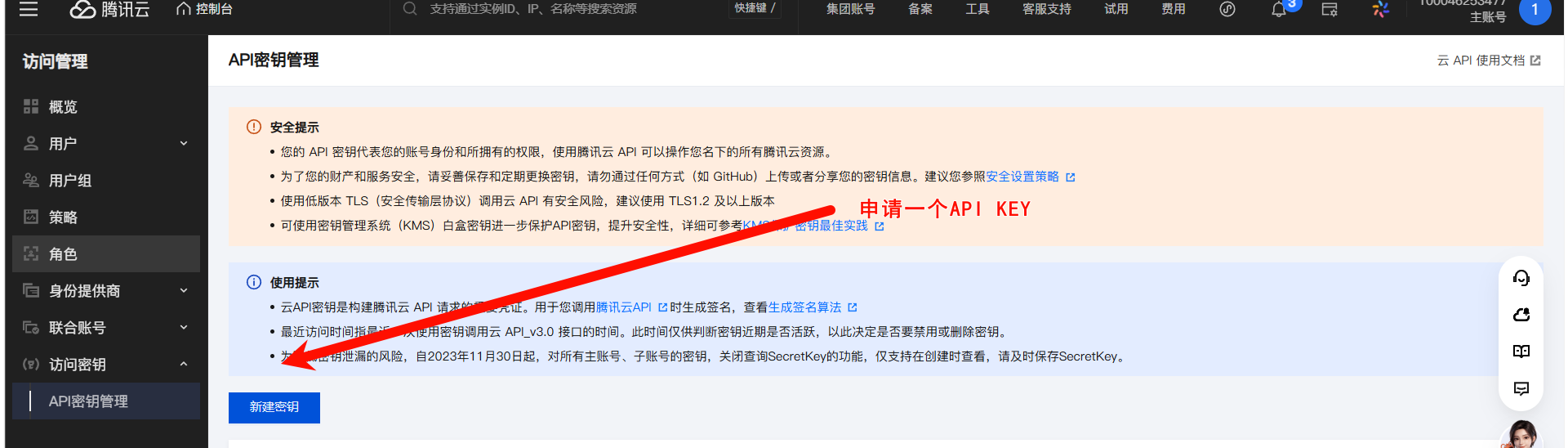
配置.env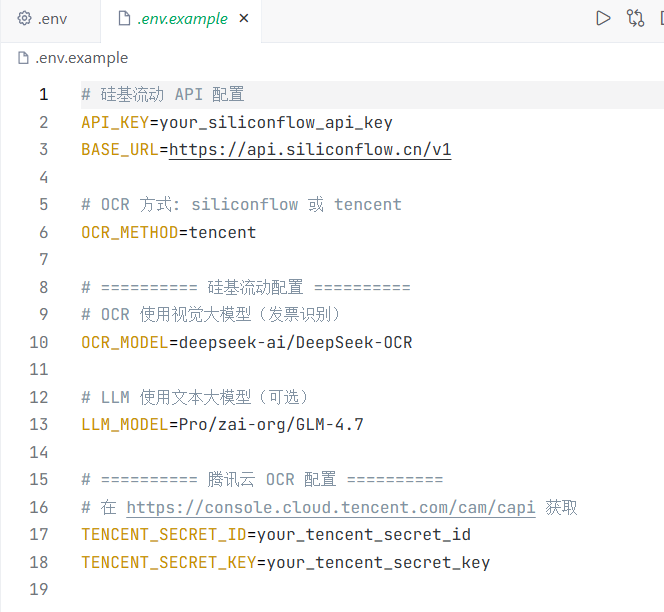
2.1 准备
有python的话直接在window PowerShell安装UV
pip install UV
2.2 进行下载好的项目目录
cd "项目目录"
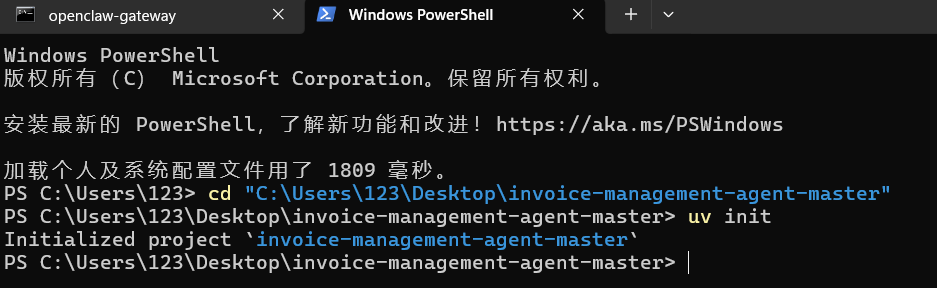
2.3 使用UV进行项目初始化
uv init
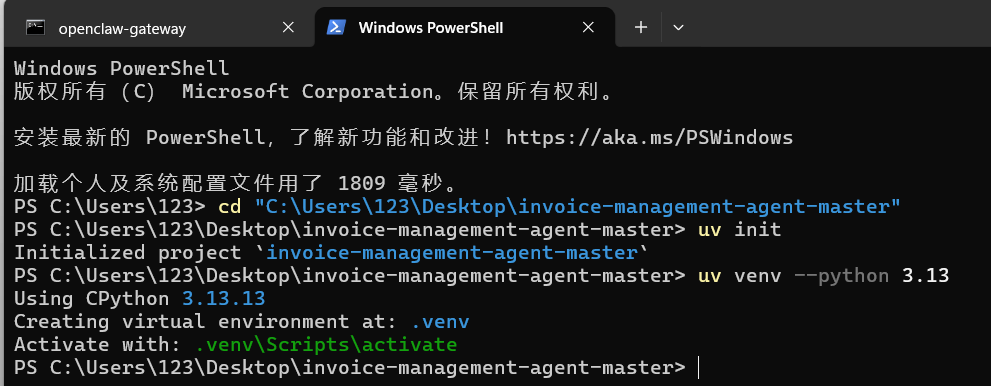
2.4 创建虚拟环境
uv venv --python 3.13
2.5 安装环境所需依赖
uv pip install -r requirements.txt -i https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple
2.6 激活虚拟环境
.\.venv\Scripts\activate

2.7 运行文件
python main.py

2.8 访问页面
http://localhost:5001
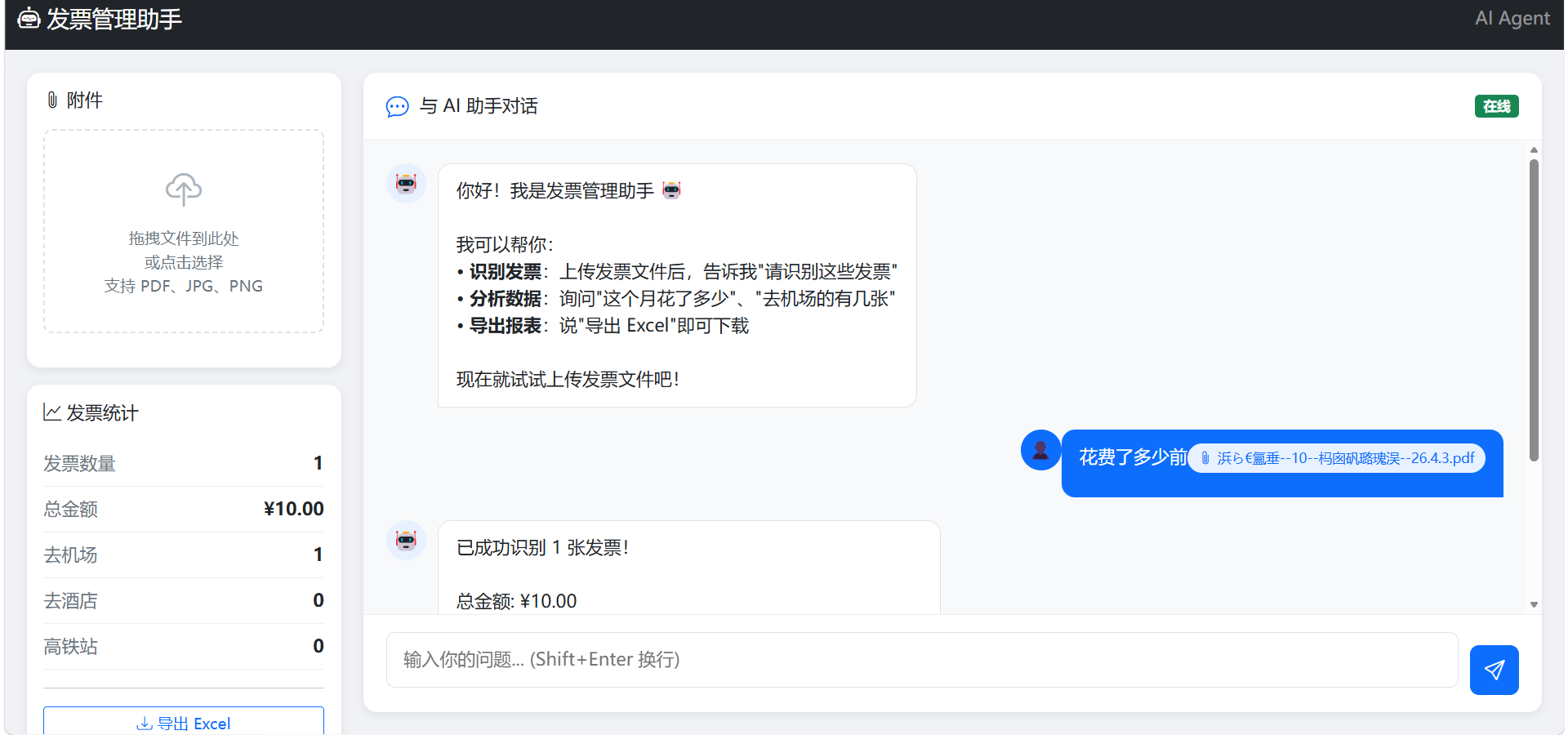
项目运行成功
3.技术栈
| 技术栈 | 作用 |
|---|---|
| FastAPI | 提供API与文件上传接口 |
| Flask | 保留了一个传统Web蓝图版本的交互入口 |
| LangGraph/LangChain | 用于构建Agent工作流与LLM调用 |
| OpenAI-Compatible API | 通过硅基流动等兼容接口调用视觉模型与文本模型 |
| 腾讯云 OCR SDK | 用于通用票据识别 |
| Pandas + openpyxl | 用于 Excel 导出与样式美化 |
4.数据集说明
因为数据集不方便上传:
大家可以到这个网址上去下载类似的数据集:
增值税普通发票_数据集-飞桨AI Studio星河社区
出租车发票识别_数据集-飞桨AI Studio星河社区
5.核心代码实现
5.1 Agent工作流
定义一个可以实时更新的状态字典,用于存储agent运行过程中产生的所有数据
#Agent state
class InvoiceAgentState(TypedDict):
#对话历史
messages:List[dict]
#用户输入
user_input:str
#上传的文件列表
uploaded_files:List[str]
#以处理的发票列表
processed_invoices:List[dict]
#当前任务类型
task_type:Optional[str]
#OCR 识别结果
ocr_results:List[dict]
#LLM 分析结果
llm_analysis_results:List[dict]
#导出的Excel数据
excel_data:Optional[dict]
#错误信息
error:Optional[str]
#调试信息
debug_info:dict
设计一个意图路由器,根据用户输入判断任务类型并决定下一步执行哪一个节点
#Intent Router 意图路由器,根据用户输入判断任务类型并决定下一步执行哪个节点。
def intent_router(state: InvoiceAgentState) -> dict:
#1.获取状态中的数据
user_input = state.get("user_input","")
uploaded_files = state.get("uploaded_files",[])
#2.条件判断
#场景1:如果用户上传了图片,优先处理发票
if uploaded_files:
#next的值决定了条件边要跳转到哪个节点
return {"next":"process_invoice"}
#转小写方便匹配
user_input_lower = user_input.lower()
#场景2:发票处理相关关键词
invoice_keywords = ["处理发票","识别发票","ocr","导出","分析发票","批量处理"]
for kw in invoice_keywords:
if kw in user_input_lower:
return {"next": "process_invoice"}
#场景3:导出相关
export_keywords = ["导出","下载","excel","csv"]
for kw in export_keywords:
if kw in user_input_lower:
return {"next":"export"}
#场景4:查询相关
query_keywords = ["查询","搜索","统计","汇总","多少钱","总计"]
for kw in query_keywords:
if kw in user_input_lower:
return {"next":"query"}
#场景5:默认进入对话模式
return {"next":"chat"}
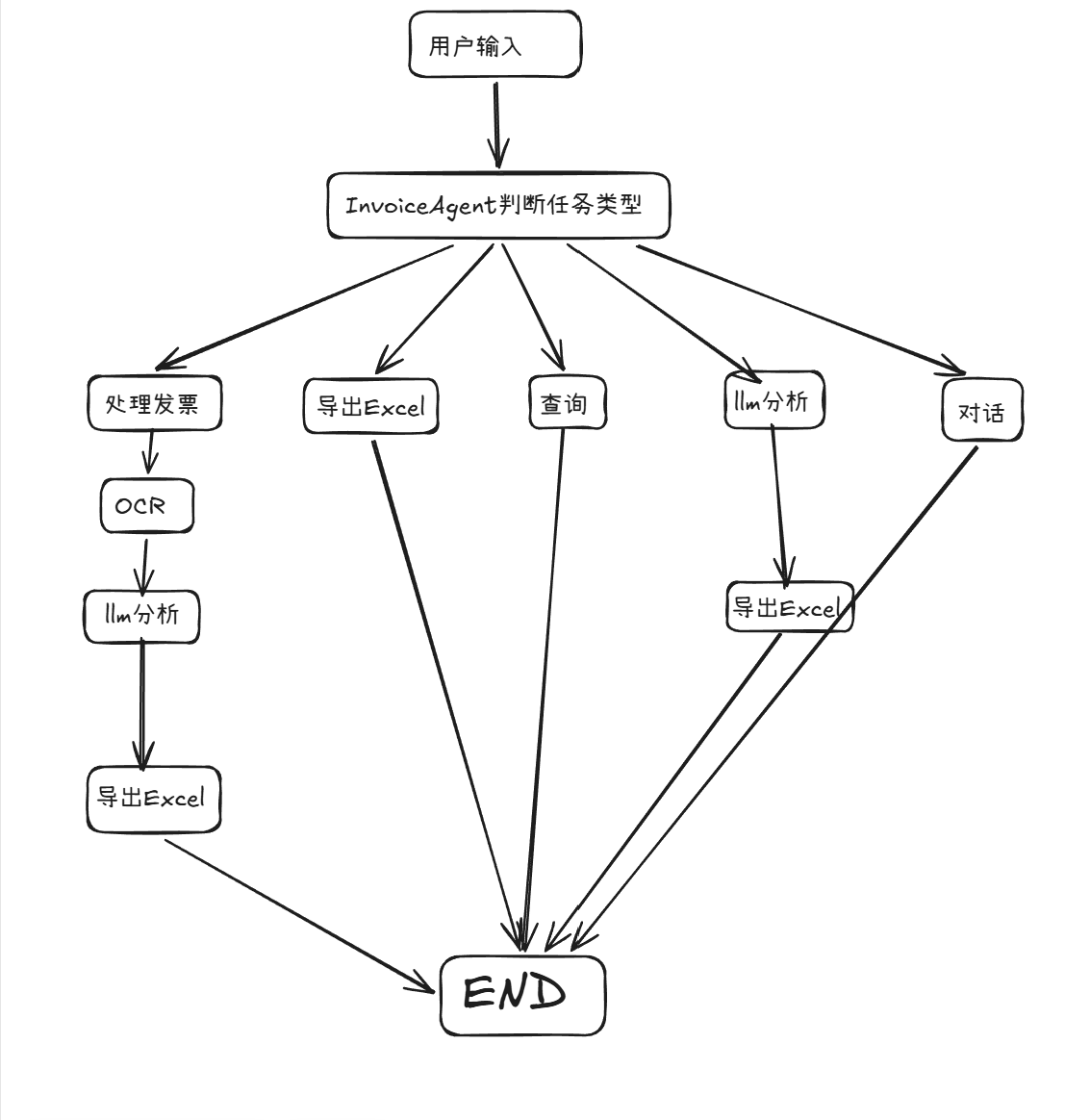
构建了一个完整的Agent Graph
- router :判断用户意图
- ocr :执行OCR识别
- llm_analysis :执行二次分析与去重
- export :到处Excel
- chat/query :用于聊天与查询
def build_agent_graph():
# 作用:定义状态的结构,让 LangGraph 知道如何管理数据
workflow = StateGraph(InvoiceAgentState)
# add_node(name, function) 将一个函数注册为节点
workflow.add_node("router", intent_router) # 意图路由节点
workflow.add_node("ocr", ocr_recognition) # OCR 识别节点
workflow.add_node("llm_analysis", llm_analysis) # LLM 分析节点
workflow.add_node("export", export_excel) # 导出节点
workflow.add_node("chat", chat_with_llm) # 对话节点
workflow.add_node("query", query_invoices) # 查询节点
# 设置入口点
workflow.set_entry_point("router")
# 添加条件边 (Conditional Edges) - 重点!
workflow.add_conditional_edges(
"router",
# 路由函数:从 router 返回的状态中获取 "next" 字段
lambda x: x.get("next", "chat"),
# 映射字典:返回值 -> 目标节点
{
"process_invoice": "ocr", # 处理发票 -> 去 OCR "chat": "chat", # 对话 -> 去对话
"query": "query", # 查询 -> 去查询
"export": "export" # 导出 -> 去导出
}
)
# 添加普通边 (Normal Edges) # 【OCR 处理流程】
# router -> ocr (条件边,已经设置)
# ocr 执行完后 -> llm_analysis workflow.add_edge("ocr", "llm_analysis")
# llm_analysis 执行完后 -> export workflow.add_edge("llm_analysis", "export")
# export 执行完后 -> 结束
workflow.add_edge("export", END)
# 【对话流程】
# router -> chat (条件边)
# chat 执行完后 -> 结束
workflow.add_edge("chat", END)
# 【查询流程】
# router -> query (条件边)
# query 执行完后 -> 结束
workflow.add_edge("query", END)
# 编译图
# compile() 返回一个可执行的图对象
# 返回的 graph 对象有 invoke() 方法,可以传入初始状态
return workflow.compile()
5.2 发票识别
本项目支持双通道识别:优先使用腾讯云OCR进行票据识别,如果腾讯云OCR识别结果不完整则使用硅基流动的视觉模型再进行一次识别
#处理单个发票文件
def process_file(self,file_path,use_llm=True):
"""
参1:文件路径
参2:是否使用llm分析
返回: 标准化后的发票信息
""" filename = os.path.basename(file_path)
result = {"source_file":filename}
#1.优先使用腾讯云OCR
tencent_data = None
if self.tencent_client:
try:
tencent_data = self.tencent_client.recognize_incoice(file_path)
result["tencent_result"] = tencent_data
except Exception as e:
result["tencent_error"] = str(e)
#2.如果需要llm并且腾讯云结果不完整,使用硅基流动OCR
siliconflow_data = None
needs_llm = use_llm and self._needs_llm_analysis(tencent_data)
if needs_llm and self.siliconflow_client:
try:
siliconflow_data = self.siliconflow_client.recognize_invoice(file_path)
result["siliconflow_result"] = siliconflow_data
except Exception as e:
result["siliconflow_error"] = str(e)
5.3 导出Excel
# 将发票列表导出为Excel
def export_to_excel(invoice_list, output_path, append=False):
"""
参数:
invoice_list: 发票信息列表
output_path: 输出Excel路径
append: 是否追加模式(默认覆盖)
""" data = []
for invoice in invoice_list:
if not invoice.get("打车时间") and not invoice.get("金额(元)"):
if invoice.get("error") and not invoice.get("source_file"):
continue
converted = convert_invoice_data(invoice)
data.append(converted)
if not data:
print("警告: 没有有效的发票数据")
return None
# 如果是追加模式,读取已有数据
if append and os.path.exists(output_path):
existing = read_excel(output_path)
data = existing + data
# 计算总金额
total_amount = sum(d.get('金额(元)', 0) for d in data)
# 添加总计行
data.append({
"打车时间": "",
"起始地": "",
"目的地": "总计",
"事由": "",
"金额(元)": total_amount,
"发票类型": "",
"source_file": ""
})
# 创建DataFrame
df = pd.DataFrame(data)
# 排序(按时间),但保留最后一行总计
if "打车时间" in df.columns and not df.empty:
# 先分离总计行
total_row = df.iloc[-1:]
data_rows = df.iloc[:-1]
# 排序非总计行
if not data_rows.empty:
# 对剩下的发票数据按照“打车时间”进行升序排列,让报表看起来更有条理。
data_rows = data_rows.sort_values("打车时间")
# 重新合并 ignore_index=True 会重置行索引,确保生成的 Excel 行号是连续的(1, 2, 3...)。
df = pd.concat([data_rows, total_row], ignore_index=True)
# 保存为Excel
# index=False:不保存 pandas 自动生成的行索引(即左侧的 0, 1, 2... 序号)。这样导出的表格更干净,只包含业务数据
# engine='openpyxl':指定使用 openpyxl 库作为写入引擎。这是处理 .xlsx 格式文件的标准引擎,支持后续的样式美化(如设置颜色、字体、边框等)。
df.to_excel(output_path, index=False, engine='openpyxl')
# 应用格式
apply_excel_format(output_path, has_total=True)
return output_path
6.运行流程
用户在前端页面上传发票文件或输入查询信息后,前端将请求发送给 FastAPI 接口;FastAPI 接收请求后,调用 InvoiceAgent 对任务类型进行判断;如果是发票处理任务,就进一步调用 OCR 识别模块、发票处理模块和 LLM 分析模块,对票据中的关键信息进行提取、补全与归一化;最后再将整理后的结果返回前端展示,并支持继续查询和导出 Excel
7.项目总结
本项目适合对于想要找一个关于langchain和langgraph的项目练手的学习者,项目中对识别出的数据的处理方法,以及规则归一化也是本项目的特色,如果可以自己详细复现的话一定会有很大的收获!
8.项目来源
本项目内容主要基于公开资料与官方文档,部分内容参考了南京中科莲蓉包智能科技有限公司相关技术材料。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐


 18
18 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)