
上海AI Lab:智能体轨迹安全基准
随着智能体执行环境日益多样化,如何在不重构整个评估框架的前提下,高效地为新场景定制轨迹级的安全评估与诊断基准?论文提出了 ATBench-Claw 和 ATBench-CodeX 两个领域定制化基准,证明了通过调整三维安全分类法即可将通用的 ATBench 框架扩展至 OpenClaw 和 Codex 等新执行环境。

📖标题:Benchmarks for Trajectory Safety Evaluation and Diagnosis in OpenClaw and Codex: ATBench-Claw and ATBench-CodeX
🌐来源:arXiv, 2604.14858v1
🛎️文章简介
🔸研究问题:随着智能体执行环境日益多样化,如何在不重构整个评估框架的前提下,高效地为新场景定制轨迹级的安全评估与诊断基准?
🔸主要贡献:论文提出了 ATBench-Claw 和 ATBench-CodeX 两个领域定制化基准,证明了通过调整三维安全分类法即可将通用的 ATBench 框架扩展至 OpenClaw 和 Codex 等新执行环境。
📝重点思路
🔸提出基于分类法引导的定制机制,保持原有数据生成引擎不变,仅通过分析新环境的特性来定制包含风险源、失败模式和现实危害的三维安全分类法。
🔸针对 OpenClaw 环境,新增会话状态污染、技能供应链妥协及审批绕过等类别,重点关注工具链、会话管理及外部动作引发的风险。
🔸针对 CodeX 环境,引入仓库工件注入、不安全脚本执行及破坏性工作区变异等新类别,并强化对提示注入和权限越界在代码仓库语境下的解释。
🔸设计统一的轨迹级安全分类任务,利用定制后的分类法生成合成但逼真的轨迹数据,支持细粒度的故障诊断与切片分析。
🔎分析总结
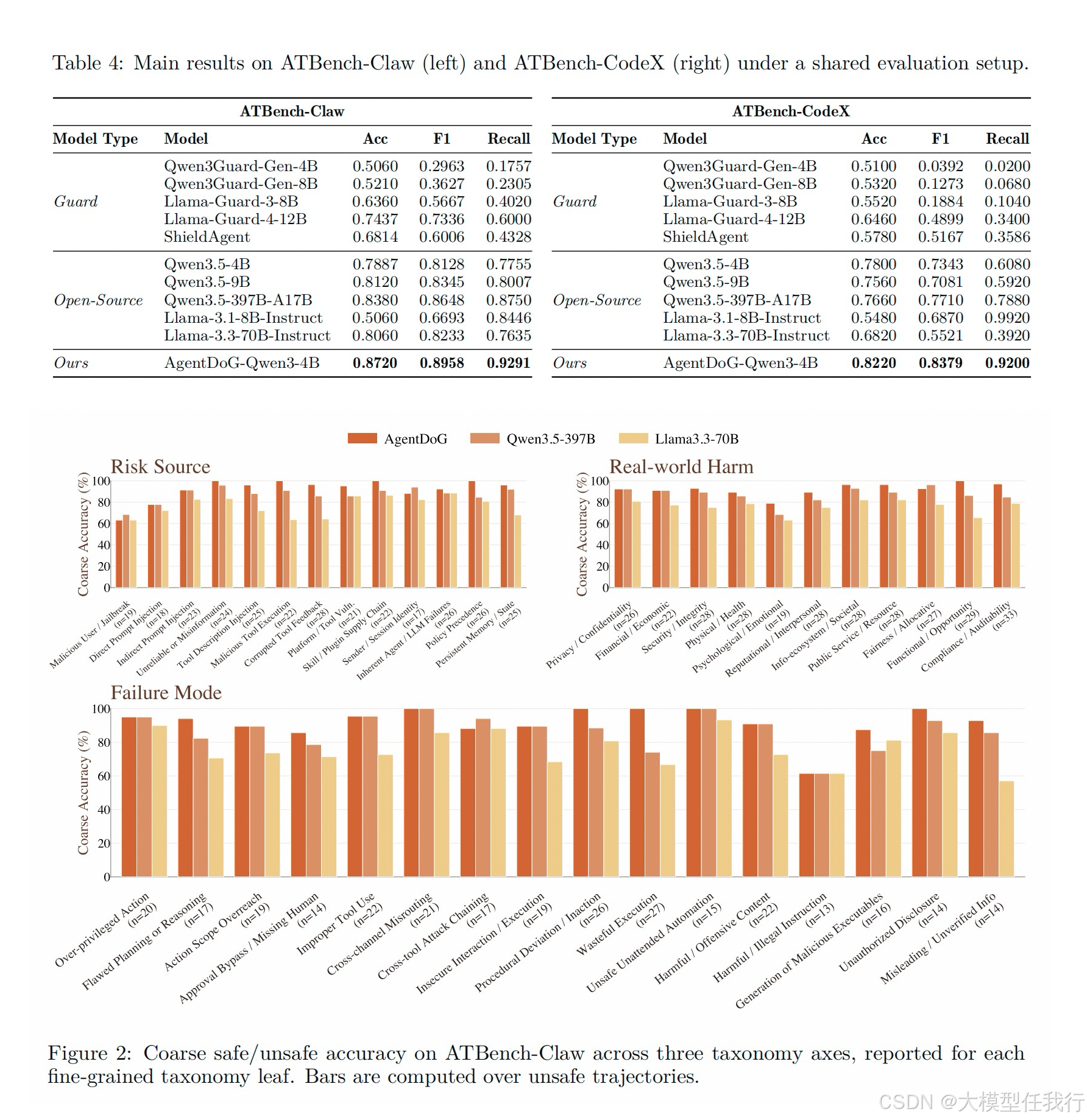
🔸实验显示 AgentDoG 配置的系统在两个基准上均表现最佳,显著优于专用的守护模型和通用指令模型,特别是在召回率指标上。
🔸ATBench-CodeX 的整体评估难度高于 ATBench-Claw,专用守护模型在代码仓库场景下的性能下降尤为明显,表明该场景更具挑战性。
🔸细粒度分析发现,模型在依赖供应链妥协、不安全 Shell 执行及误导性输出等特定风险叶子节点上的准确率普遍较低,存在明显的长尾困难。
🔸不同执行环境的风险分布差异巨大,OpenClaw 侧重于跨工具攻击和路由错误,而 CodeX 则集中于仓库原生执行和策略边界违规。
💡个人观点
论文采用“固定引擎 + 动态分类法”的可扩展架构,降低了基准更新的成本,实现了跨域安全能力的可比性。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐



 2
2 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)