
阿里:解耦奖励培养智能体元认知
多模态智能体如何克服盲目调用工具的缺陷,学会在内部知识与外部工具间进行明智的元认知仲裁?论文提出了分层解耦策略优化框架 HDPO,通过条件优势估计将准确率与效率目标正交化,训练出能大幅减少冗余工具调用且提升推理精度的 Metis 模型。
📖标题:Act Wisely: Cultivating Meta-Cognitive Tool Use in Agentic Multimodal Models
🌐来源:arXiv, 2604.08545v1
🛎️文章简介
🔸研究问题:多模态智能体如何克服盲目调用工具的缺陷,学会在内部知识与外部工具间进行明智的元认知仲裁?
🔸主要贡献:论文提出了分层解耦策略优化框架 HDPO,通过条件优势估计将准确率与效率目标正交化,训练出能大幅减少冗余工具调用且提升推理精度的 Metis 模型。
📝重点思路
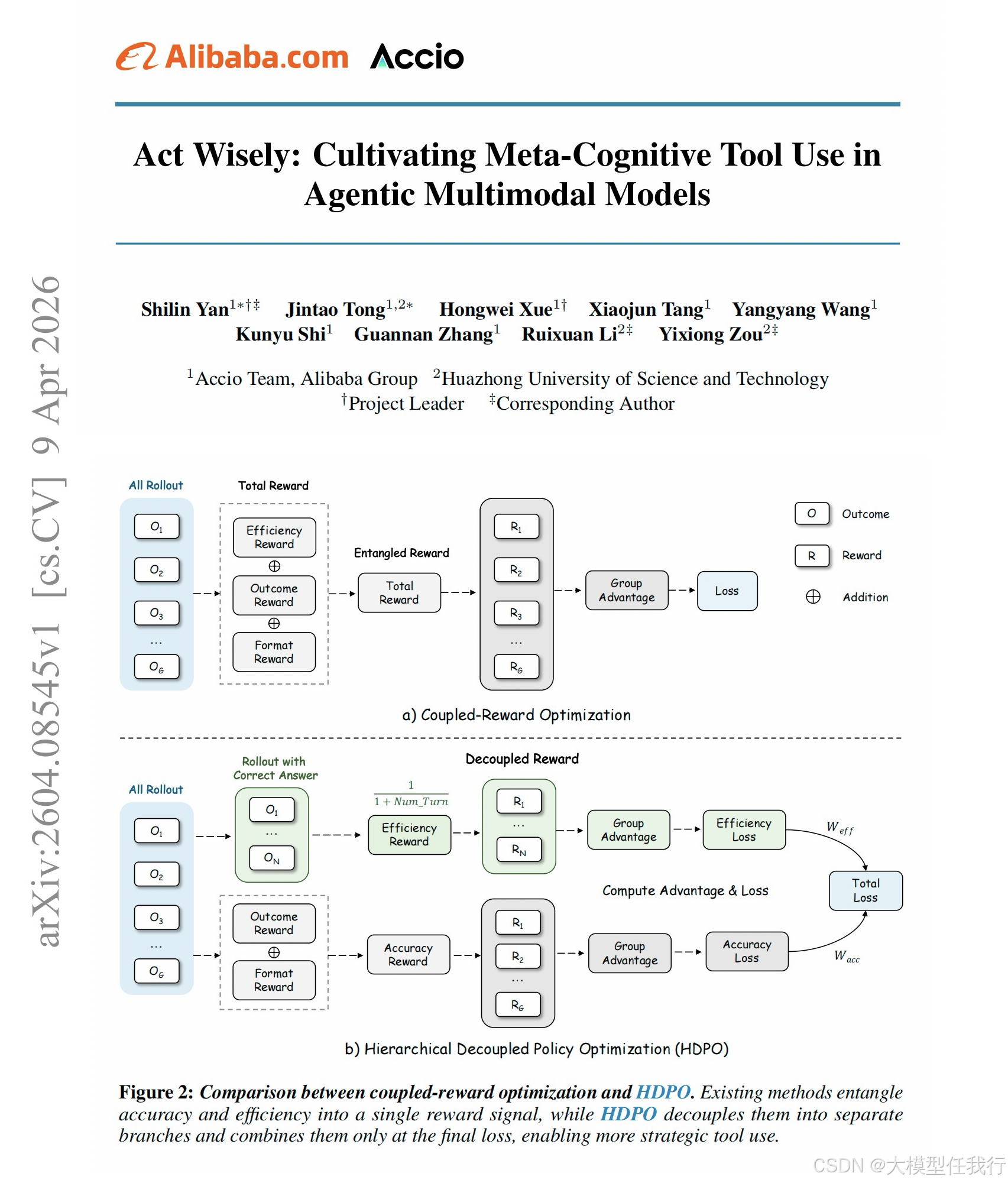
🔸揭示现有强化学习中将准确率与工具效率标量化混合奖励的数学缺陷,指出其导致梯度纠缠及效率信号被方差淹没的问题。
🔸提出 HDPO 框架,构建准确率与效率两个正交优化通道,仅在最终损失计算时线性组合,避免目标间的相互干扰。
🔸设计条件优势估计机制,规定效率奖励仅在回答正确的轨迹集合内计算优势,强制模型先掌握正确解题再追求执行经济。
🔸实施严格的元认知数据清洗流程,剔除环境动态幻觉样本,并过滤掉基座模型可直接求解无需工具的简单样本。
🔎分析总结
🔸实验表明 Metis 在多个基准测试中达到最先进水平,同时将工具调用率从常见的 98% 降至 2%,证明高效与高精度可兼得。
🔸消融实验证实解耦优化显著优于标准 GRPO,适当的效率权重能抑制噪声调用从而反哺推理准确性,形成正向催化。
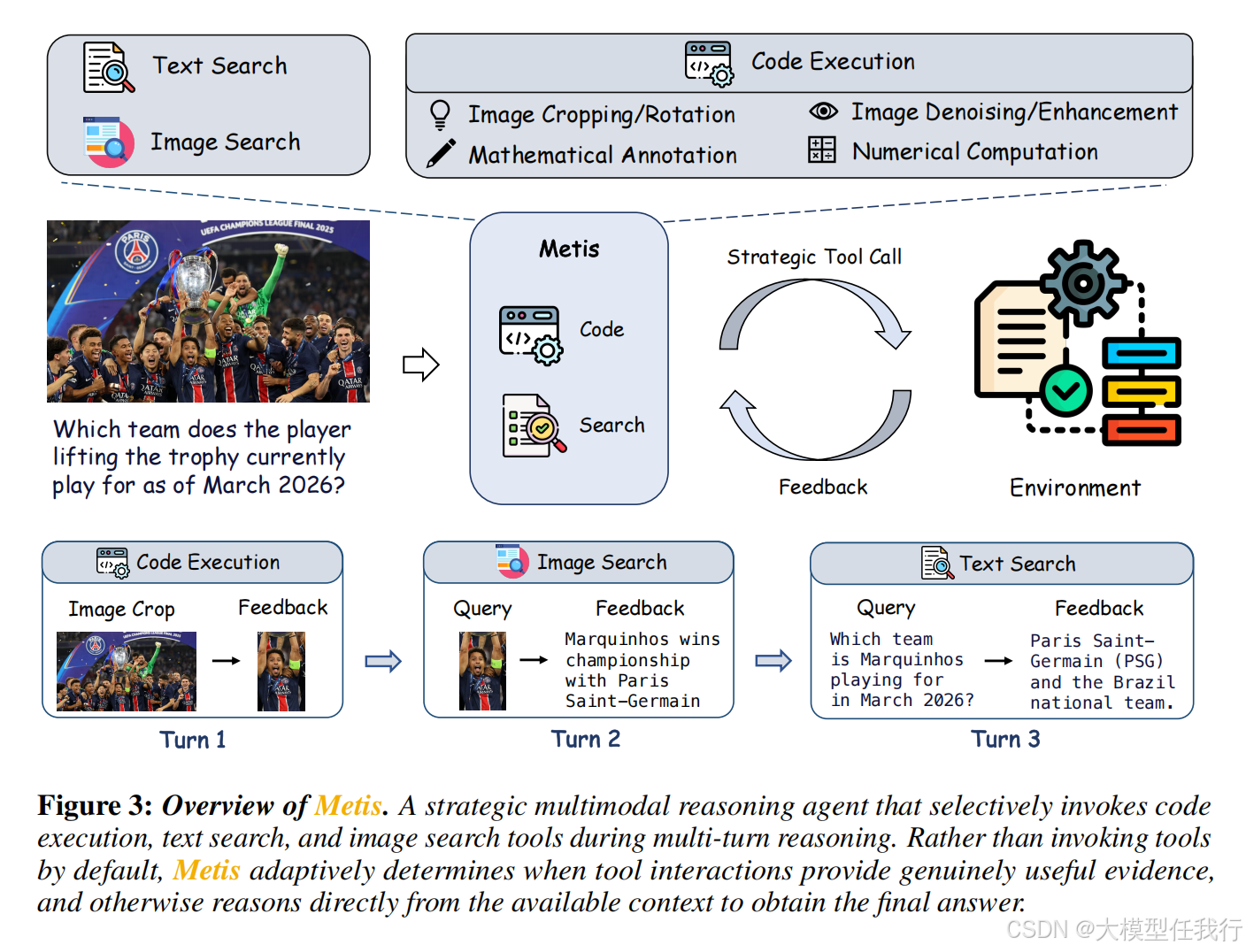
🔸案例分析显示模型已习得元认知智慧:对于视觉清晰或知识内化的问题直接作答,仅在真正需要细粒度分析或事实检索时才调用工具。
🔸训练过程自然涌现出认知课程,早期专注于提升任务正确率,随着能力成熟自动转向优化工具使用的精简度,无需人工调度超参数。
💡个人观点
论文打破了传统强化学习中多目标优化的标量加权范式,利用“条件优势”将效率约束严格限定在成功轨迹子空间内,实现了从教模型“怎么用工具”到教模型“何时不用工具”的范式跃迁。


小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐



 9
9 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)