
Meta:长程智能体测试时扩展新范式
如何有效利用额外的推理计算资源来提升长周期代码智能体(Agentic Coding)的性能,解决传统方法难以直接比较和复用冗长交互轨迹的难题?提出了一种基于紧凑结构化摘要表示的统一测试时扩展框架,结合递归锦标赛投票与并行蒸馏优化,显著提升了前沿模型在复杂代码基准上的表现。

📖标题:Scaling Test-Time Compute for Agentic Coding
🌐来源:arXiv, 2604.16529v1
🛎️文章简介
🔸研究问题:如何有效利用额外的推理计算资源来提升长周期代码智能体(Agentic Coding)的性能,解决传统方法难以直接比较和复用冗长交互轨迹的难题?
🔸主要贡献:提出了一种基于紧凑结构化摘要表示的统一测试时扩展框架,结合递归锦标赛投票与并行蒸馏优化,显著提升了前沿模型在复杂代码基准上的表现。
📝重点思路
🔸将冗长且充满噪声的智能体交互轨迹转化为紧凑的结构化摘要,保留关键假设、进展和失败模式,作为后续选择与复用的核心接口。
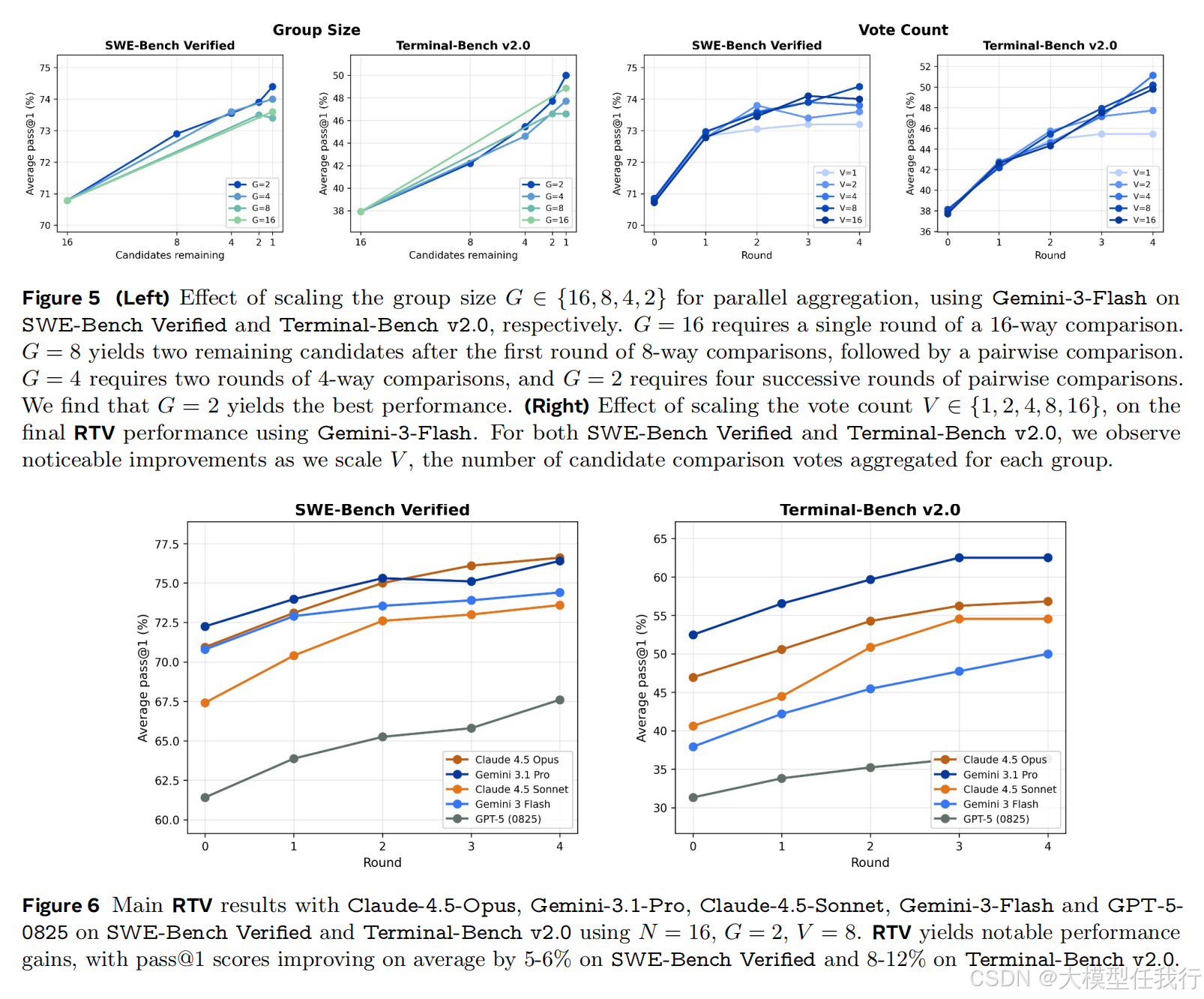
🔸引入递归锦标赛投票机制,通过将候选摘要分组进行多轮小规模比较和投票聚合,在无真实标签情况下从并行生成的多个尝试中筛选出最优解。
🔸适配并行蒸馏优化方法至智能体场景,利用前一轮精选出的高质量摘要作为上下文条件,指导新一轮智能体在初始化环境中进行更高效的探索与修复。
🔸构建统一流水线,先通过并行生成与投票筛选出高质量经验子集,再基于此进行顺序迭代优化,最后再次投票选出最终结果,平衡了探索与利用。
🔎分析总结
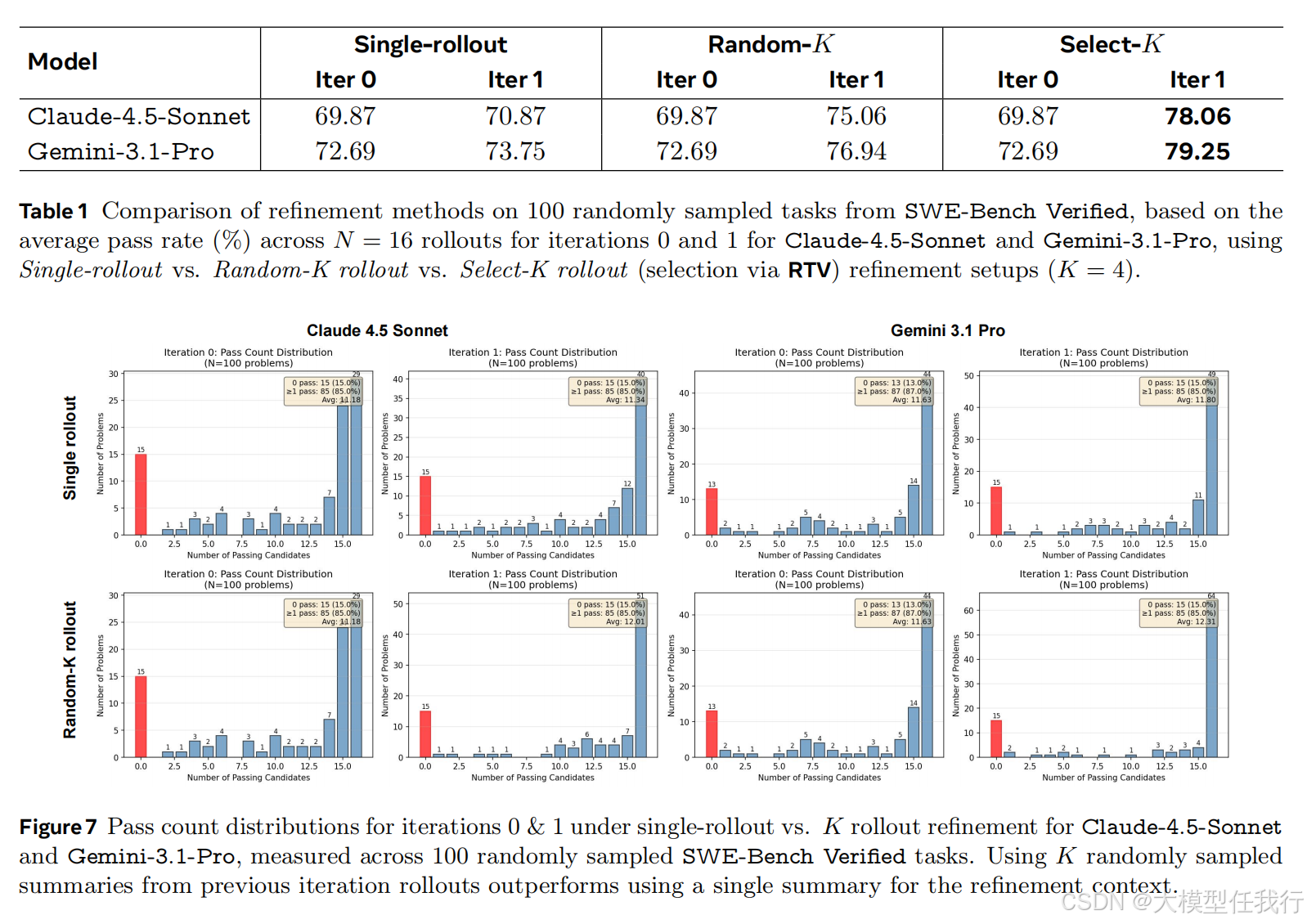
🔸实验表明,使用紧凑结构化摘要作为比较对象比直接使用完整轨迹能显著提升选择准确率,证明了表示形式是扩展性能的关键瓶颈。
🔸递归式的小组两两比较配合多次投票聚合,优于一次性对所有候选者进行全局排序,能有效处理长周期任务中的细微差别。
🔸顺序优化的效果高度依赖于复用上下文的质量,基于投票筛选出的高质量摘要进行微调,比随机采样或单条轨迹复用能带来更大的性能提升。
🔸该方法在 SWE-Bench Verified 和 Terminal-Bench v2.0 等多个基准上,使 Claude-4.5-Opus 等前沿模型的通过率提升了 6% 至 12% 不等,并减少了约一半的解题步骤。
💡个人观点
论文洞察到长周期智能体测试时扩展的核心并非单纯增加计算量,而是如何高效地“表示、选择和复用”过往经验,要将非结构化的漫长交互压缩为高信噪比的摘要。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐



 13
13 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)