
后端大数据工程师转型AI Agent,避开框架陷阱!先吃透LLM、Agent、Tools/Skills、MCP分层,再玩LangGraph
本文为后端和大数据工程师转型AI Agent开发提供了系统化的学习路线建议。核心观点强调不应直接追逐热门框架,而应遵循分层学习路径:先理解LLM、Agent、Tools/Skills、MCP等基础概念,掌握运行循环和工具建模,最后再进行工程化和MCP应用。文章指出这些工程师的优势在于系统边界设计、接口契约和任务编排能力,建议通过构建业务闭环的Agent逐步深入开发,避免后期返工。学习路线分为四个阶
本文为后端和大数据工程师提供了AI Agent工程师的学习路线建议。核心观点是:不应一开始就追逐热门框架,而应先理解LLM、Agent、Tools/Skills、MCP的概念分层,掌握运行循环和工具建模,最后再进行工程化和MCP应用。文章强调,这些工程师转型AI Agent具有优势,关键在于系统边界、接口契约和任务编排能力。通过先建立业务闭环的Agent,再逐步深入,可以避免后期大量返工,实现更高效的AI应用开发。
AI Agent 工程师学习路线:后端和大数据老兵,别先学框架

副标题:先把 LLM、Agent、Tools/Skills、MCP 这几层分工画对,再去碰 LangGraph 和生产系统
会写任务调度、服务编排、SQL、报表的人,转 AI Agent,通常比只会写 Prompt 的人更快上手。真正拦路的,不是模型参数,也不是哪个框架更火,而是一上来把 LLM、Agent、Tool、MCP 混成一锅。
我这半年看过不少团队踩坑,套路都差不多:做了个聊天框就叫 Agent;给模型塞十几个 API 就以为能自动干活;工具接进来了,却没有状态、权限、审计、重试。Demo 很唬人,生产一点都不稳。
所以我的建议很硬:先学概念分层,再学运行循环,然后做工具建模,最后补 MCP 和工程化。顺序反了,后面一定返工。
先把概念分层画对:LLM 不是 Agent,Tool 也不是 Skill
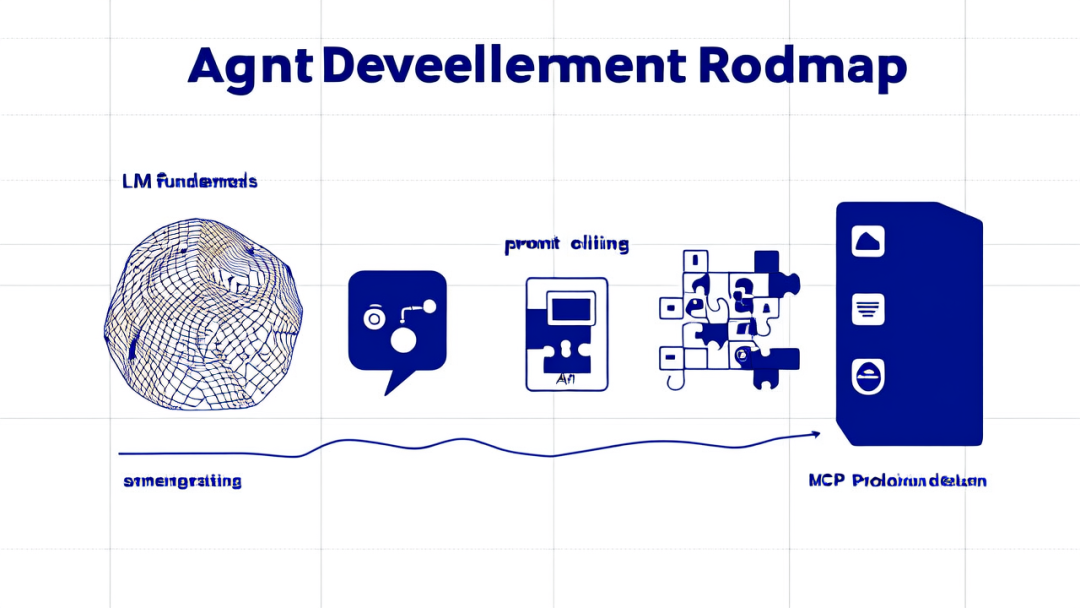
我习惯用公司组织打比方。LLM 像大脑,擅长理解、推理、生成;Agent 像 CEO 或项目经理,负责接任务、拆步骤、做决策;Tools 是手和脚,负责查库、发邮件、调接口;Skills 是打包好的能力模块,比如“生成周报”;MCP 则像统一的 USB-C 接口,负责把外部能力标准化接进来。
LLM 的本质,其实还是“输入文本 → 输出文本”的超大规模语言概率模型。这个定义看起来朴素,但特别重要。因为你一旦接受这个事实,就不会再把它当成能直接执行动作的魔法生物。它会写 SQL,不等于它真的查了数据库;它会说“我已经发邮件”,不等于 SMTP 真收到了请求。
LLM 的几个硬伤,做后端的人一定要记牢:默认没有记忆,不能自己执行真实动作,知识有截止日期,还会幻觉。你把这四个坑理解透了,很多 Agent 设计就自然了:记忆要外置,动作要工具化,实时信息要检索,高风险结果要校验。
Agent 比 LLM 多出来的东西,我一般写成这个公式:LLM + 感知 + 规划 + 记忆 + 工具调用 + 行动循环。这就不是“会聊天的模型”了,而是“带概率规划器的执行系统”。对后端工程师来说,这个东西其实不陌生,本质上就是有状态工作流,只不过决策节点从 if/else 变成了模型。
| 分层 | 我怎么理解 | 工程含义 |
|---|---|---|
| LLM | 大脑 | 负责理解、推理、生成 |
| Agent | 项目经理 | 负责拆任务、决定下一步 |
| Tool | 原子操作 | 查库、调用 API、发消息 |
| Skill | 组合能力 | 多个 Tool + 流程编排 |
| MCP | 统一接口 | 标准化发现和调用工具 |

概念分层
一个闭环任务,看懂 ReAct:查销售、分析趋势、发邮件
拿一个真实任务说最清楚:用户说,“分析华东区最近 30 天销售趋势,给区域负责人发邮件。” 这件事如果只靠 LLM,它最多给你写一段分析模板;如果是 Agent,它会先判断要不要查数据库,要不要做聚合,要不要生成摘要,最后再决定要不要发邮件。
OpenAI 做的 Function Calling,价值就在这里:模型不用靠字符串瞎猜 API 格式,而是按你给的 schema 来调工具。下面这个定义就够说明问题:
[{"type":"function","function":{"name":"query_database","description":"Run read-only SQL against sales warehouse","parameters":{"type":"object","properties":{"sql":{"type":"string","description":"SELECT-only SQL"}},"required":["sql"]}}},{"type":"function","function":{"name":"send_email","description":"Send analysis result to stakeholders","parameters":{"type":"object","properties":{"to":{"type":"array","items":{"type":"string"}},"subject":{"type":"string"},"body":{"type":"string"}},"required":["to","subject","body"]}}}]
运行时的骨架也不复杂。核心就是 ReAct:Thought → Action → Observation → 再规划。你不用迷信“思维链”输出,真正该落库的是计划摘要、工具调用、观测结果和最终结论。
importjsonfromopenaiimport OpenAIclient = OpenAI()messages = [ {"role": "system", "content": "You are a sales analysis agent."}, {"role": "user", "content": "分析华东区最近30天销售趋势,并发邮件给区域负责人"}]whileTrue: resp = client.chat.completions.create( model="gpt-4.1", messages=messages, tools=tools, tool_choice="auto", ) msg = resp.choices[0].message messages.append(msg)ifnot msg.tool_calls:print(msg.content)breakfor call in msg.tool_calls: args = json.loads(call.function.arguments) result = run_tool(call.function.name, args) messages.append({"role": "tool","tool_call_id": call.id,"content": json.dumps(result, ensure_ascii=False) })
这段循环对后端工程师很好理解:模型负责决定下一跳,Tool 负责产生副作用,Observation 负责把真实世界结果写回上下文。查库失败就重试,结果异常就重新规划,发邮件这种高风险动作就加人工确认。你以前在调度平台、补偿机制、Saga 里做过的事,Agent 一样要做。
短期记忆和长期记忆也别神化。短期记忆就是这次任务的状态,像“已经查过哪个表、上次 SQL 返回什么”;长期记忆是用户偏好、固定收件人、报表口径、权限范围。没有这两层,Agent 只是多轮聊天;有了这两层,它才像一个能持续干活的系统。
Tools 和 Skills:你现有的 API、SQL、作业系统,就是切入口
很多人卡在“我不会训练模型,怎么做 Agent”。这问题问偏了。资深后端和大数据工程师最值钱的地方,本来就不是训练模型,而是把既有系统封装成可控能力。
Tool 是原子操作,Skill 是高层封装。比如 query_database 是 Tool,send_email 是 Tool;但“生成销售周报”就更像 Skill,它背后可能串了查库、聚合、画图、润色、发信五个步骤。这个分层很重要,因为你真正复用的,往往不是单个 Tool,而是打过边界和口径的 Skill。
我自己做 Tool 建模时,最低要求只有五条,少一条都容易出事故:
- 参数 schema 要收紧,别给模型无限自由
- 读写权限要分开,生产库默认只读
- 每个 Tool 要有超时、重试、幂等性
- 返回值尽量结构化,别回一坨自然语言
- 高风险动作必须人工确认并留审计日志
后端工程师最容易切进去的,是把内部 HTTP API、RPC、审批流、工单系统包装成 Tool;大数据工程师最容易切进去的,是把 Trino、Spark、dbt、Notebook、报表生成脚本包装成 Tool。你过去写的不是“传统系统”,而是 Agent 未来的执行器。
我反对一上来就让模型自由生成任意 SQL 去打生产库。那不是智能,是放火。正确做法是:先限定数据域,给只读视图,准备 SQL 模板和字段字典,必要时再加一个 SQL reviewer。Agent 工程不是比谁更敢放权,而是比谁更会收边界。
学习路线我建议按四段走,别一上来追 LangGraph
第一段,先学 LLM 的基本能力边界:Prompt、Structured Output、Function Calling、context window、RAG、评估方法。够了。这个阶段别把时间砸在微调上,绝大多数业务 Agent 先把上下文、工具和流程做好,收益更高。
第二段,集中做工具建模。把你手里的 SQL 查询、离线作业、内部 API、告警系统、邮件系统,一个个改造成可调用、可观测、可授权的 Tool。这个阶段做完,你已经不是“会用模型”,而是在搭执行层了。
第三段,再学运行时和状态机。Python 栈我更推荐 LangGraph,原因很直接:节点、边、状态都摆在明面上,适合把 Agent 当工作流系统来维护。Java 团队可以看 Spring AI,但关键不在框架,而在你有没有把“计划、调用、观察、重试、审批”这些节点设计清楚。
第四段,补齐可观测和评估。我建议至少上 Langfuse 或 OpenTelemetry 其中一套,不然你根本分不清失败是模型错、Tool 错,还是上下文错。真正该盯的指标也不是“回答像不像人”,而是任务成功率、Tool 成功率、平均时延、Token 成本、人工接管率。
最后再上 MCP。Anthropic 提出的 Model Context Protocol,我很看好,因为它把工具发现、调用、上下文交换这件事做成了统一接口。对开发者意味着什么?意味着你不用为每个 Agent 框架、每个客户端重复造连接器。你把 Trino、文件系统、搜索、邮件做成一个 MCP Server,Claude、IDE、内部 Agent 平台都能复用,这个工程价值很实在。
最后唠两句
为什么AI大模型成为越来越多程序员转行就业、升职加薪的首选
很简单,这些岗位缺人且高薪
智联招聘的最新数据给出了最直观的印证:2025年2月,AI领域求职人数同比增幅突破200% ,远超其他行业平均水平;整个人工智能行业的求职增速达到33.4%,位居各行业榜首,其中人工智能工程师岗位的求职热度更是飙升69.6%。
AI产业的快速扩张,也让人才供需矛盾愈发突出。麦肯锡报告明确预测,到2030年中国AI专业人才需求将达600万人,人才缺口可能高达400万人,这一缺口不仅存在于核心技术领域,更蔓延至产业应用的各个环节。
那0基础普通人如何学习大模型 ?
深耕科技一线十二载,亲历技术浪潮变迁。我见证那些率先拥抱AI的同行,如何建立起效率与薪资的代际优势。如今,我将积累的大模型面试真题、独家资料、技术报告与实战路线系统整理,分享于此,为你扫清学习困惑,共赴AI时代新程。
我整理出这套 AI 大模型突围资料包【允许白嫖】:
- ✅从入门到精通的全套视频教程
- ✅AI大模型学习路线图(0基础到项目实战仅需90天)
- ✅大模型书籍与技术文档PDF
- ✅各大厂大模型面试题目详解
- ✅640套AI大模型报告合集
- ✅大模型入门实战训练
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

①从入门到精通的全套视频教程
包含提示词工程、RAG、Agent等技术点

② AI大模型学习路线图(0基础到项目实战仅需90天)
全过程AI大模型学习路线
③学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的

④各大厂大模型面试题目详解

⑤640套AI大模型报告合集

⑥大模型入门实战训练

如果说你是以下人群中的其中一类,都可以来智泊AI学习人工智能,找到高薪工作,一次小小的“投资”换来的是终身受益!
应届毕业生:无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型:非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能 突破瓶颈:传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。
👉获取方式:
有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐


 3
3 0
0- 0



 已为社区贡献45条内容
已为社区贡献45条内容

所有评论(0)