
掌握上下文工程,解锁大模型能力:小白程序员必备收藏技巧!
本文深入探讨了 Context Engineering(上下文工程)的原理与实战方法,旨在帮助程序员和小白理解并掌握如何突破大模型的记忆限制。文章详细阐述了 AI Agent 如何通过“守门人”角色管理语言模型的上下文输入,介绍了上下文压缩(如 LLM 摘要压缩、观察掩蔽)、记忆管理(外部存储与检索)、Sub-Agent 自主压缩以及预防性过滤等核心技术。通过结合 OpenClaw 框架案例与未来
引言
–
在 AI Agent 快速发展的今天,一个核心问题始终困扰着研究者和工程师:如何让语言模型在执行复杂任务时,有效管理其有限的上下文窗口?Context Engineering(上下文工程)正是解决这一问题的关键技术。本文将深入探讨 Context Engineering 的原理、方法和实践,揭示 AI Agent 如何突破语言模型的记忆限制。
为什么需要 Context Engineering?
语言模型本质上是在进行"文字接龙"——根据输入的 prompt 生成相应的输出。但语言模型有一个根本特性:它"活在当下",只关注当前的输入,而不记得之前发生过什么。
当 AI Agent 执行复杂任务时,会产生一个不断增长的对话历史:
- 人类给出的初始指令
- 语言模型生成的工具调用指令
- 工具执行后返回的结果
- 新一轮的推理和决策
这些信息必须被串联成一个完整的输入序列,才能让语言模型理解当前的状态。然而,语言模型的输入长度是有上限的——这就是 Context Engineering 存在的根本原因。
AI Agent 的角色:AI Agent 就像语言模型的"守门人"或"经纪人",拦截在语言模型与外界之间,精心筛选和管理语言模型能看到的内容。它确保输入既不会超出长度限制,也不会因过度精简而丢失关键信息。
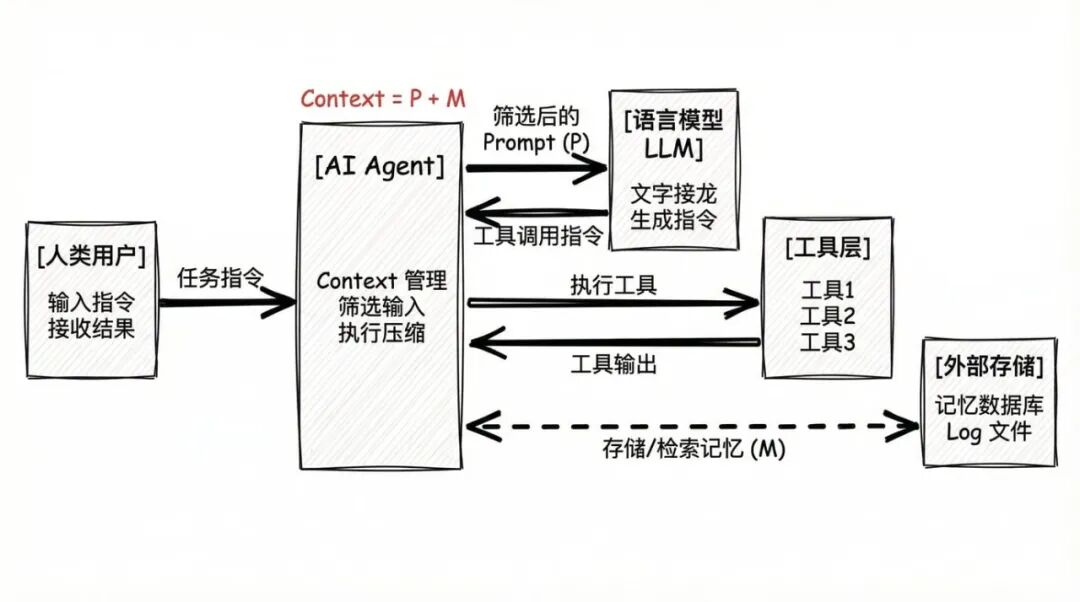
图1:AI Agent 作为语言模型与外界的中介
Context Engineering 的形式化定义
从程序设计的角度看,没有 Context Engineering 的 AI 系统可以表示为一个简单的循环:
for t = 1 to ∞: I_t = 当前输入(用户指令或工具输出) C_t = 历史上下文 O_t = LLM(C_t + I_t) // 语言模型处理 C_{t+1} = C_t + I_t + O_t // 直接累积所有历史
这种方式的问题显而易见:上下文 C 会无限增长,最终超出语言模型的处理能力。
引入 Context Engineering 后,关键变化在于最后一行:
for t = 1 to ∞: I_t = 当前输入 C_t = 历史上下文 O_t = LLM(C_t + I_t) C_{t+1} = F(C_t, I_t, O_t) // 通过函数 F 智能管理上下文
这个函数 F 就是 Context Engineering 的核心——它决定了如何从历史信息中提取、压缩、存储和检索内容。
Context Engineering 的核心技术
1. 上下文压缩(Context Compression)
压缩是 Context Engineering 最基础也最重要的功能。当上下文过长时,需要通过某种方式将其缩短。
1.1 LLM 摘要压缩
最直观的方法是使用语言模型本身对历史记录进行摘要。将较久远的对话历史(排除 system prompt)输入到语言模型,让它生成一段简短的摘要,替换原本冗长的内容。
优点:能够保留语义信息,摘要质量较高
缺点:需要额外的 LLM 调用,增加计算成本
1.2 观察掩蔽(Observation Masking)
一种更简单粗暴但出乎意料有效的方法:直接将工具的输出替换为一句话,如"这里曾经有个工具的输出"。
研究表明,在 SWE-bench(软件工程基准测试)上,这种方法的表现与 LLM 摘要相当。虽然听起来不可思议,但这说明很多时候工具的详细输出并不需要一直保留在上下文中。
1.3 混合策略
实践中最有效的方案是结合两种方法:
- 前期:使用观察掩蔽,快速缩短工具输出
- 后期:当上下文累积到一定程度后,使用 LLM 摘要进行一次性大幅压缩
这种策略在保持性能的同时,最大化了 token 效率。
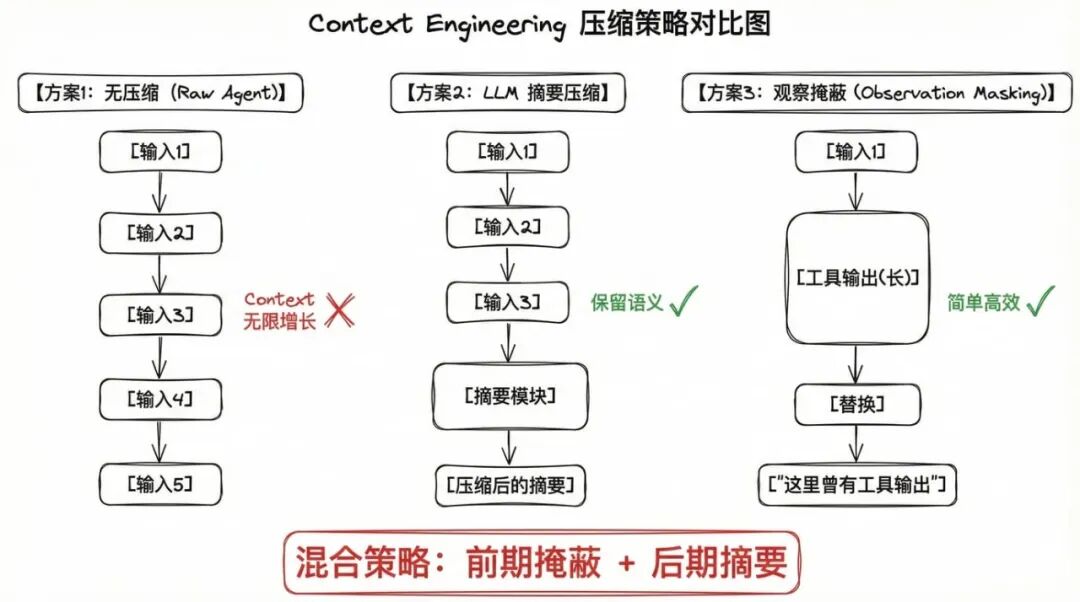
图2:混合压缩策略的工作流程
1.4 压缩的挑战:Context Collapse
压缩并非没有代价。ACON 论文发现了一个现象叫做"上下文坍缩"(Context Collapse)——当压缩丢失了关键信息时,原本能够完成的任务就会失败。
例如,某个 Meta 研究人员让 AI 帮他管理邮件,结果 AI 在压缩时把"删除邮件需要人类同意"这条关键指令压缩掉了,导致 AI 开始不经同意就删除邮件。
解决方案:ACON 提出让另一个语言模型分析压缩前后的性能差异,生成反馈(feedback),指导未来的压缩行为。这种方法无需训练模型参数,仅通过提示工程就能显著提升压缩质量。
2. 记忆管理(Memory Management)
压缩只是治标,更根本的方法是将信息存储到外部,需要时再检索——这就是 AI Agent 的"记忆"机制。
2.1 记忆的本质
对语言模型而言,记忆就是:
-
存储
将上下文中的内容保存到硬盘/数据库(如 log1.txt)
-
检索
在需要时通过工具读取这些文件
在上下文中,原本冗长的内容被替换为一个简短的引用:“详见 log1.txt”。多数情况下,语言模型不需要回看这些细节;但当真正需要时,它可以执行 read 指令重新加载。
这就像《Rick and Morty》中 Morty 发现自己的记忆被存储在地下室的管子里——记忆被外置化,需要时才重新加载。
2.2 记忆的组织方式
不同的研究提出了多种记忆组织方法:
-
图结构
将记忆构建成知识图谱,便于理解记忆间的关联
-
时间标记
为记忆添加时间戳,优先检索最新或最相关的记忆
-
语义索引
通过向量数据库实现语义搜索
2.3 形式化表示
引入记忆后,上下文 C 应该被分为两部分:
-
P (Prompt)
:会被输入到语言模型的部分
-
M (Memory)
:存储在外部的部分
算法变为:
for t = 1 to ∞: I_t = 当前输入 P_t, M_t = C_t 的两个组成部分 O_t = LLM(P_t + I_t) // 只有 P 进入模型 P_{t+1}, M_{t+1} = F(P_t, M_t, I_t, O_t) // 分别更新两部分
当执行 save_memory 时,更新 M;当执行 load_memory 时,更新 P。
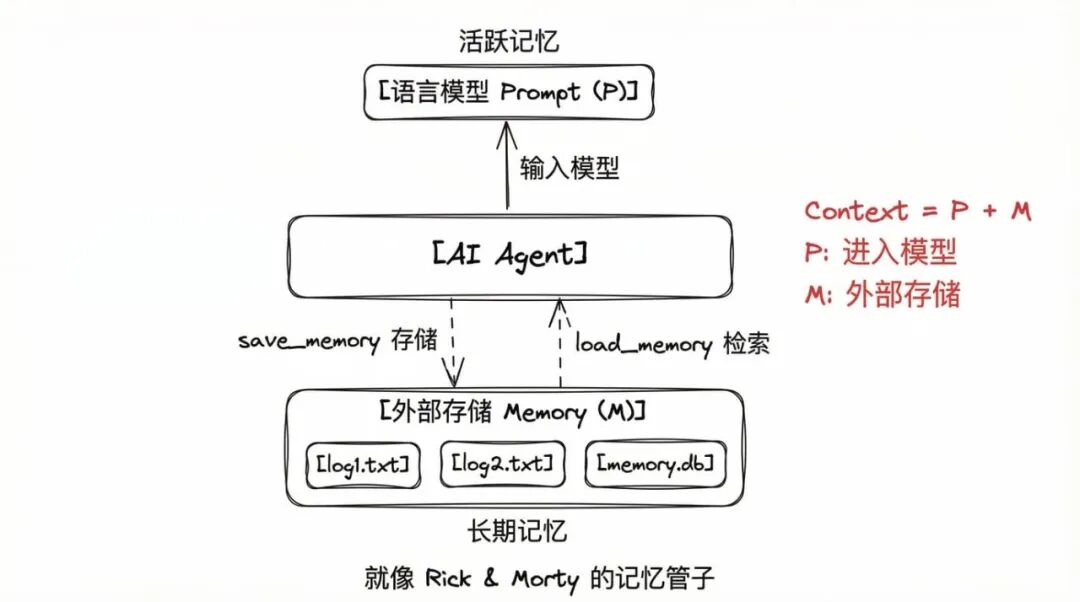
图5:记忆管理的形式化表示
3. Sub-Agent:自主压缩机制
Sub-agent(子代理)是一种更高级的上下文管理方式,它本质上是一种"自主压缩"机制。
3.1 Sub-Agent 的工作原理
当主 Agent 遇到一个可以独立完成的子任务时,它可以执行 spawn 指令,创建一个 sub-agent:
-
Sub-agent 获得一个独立的子任务和初始上下文
-
Sub-agent 与语言模型交互,执行工具,累积自己的上下文
-
完成任务后,sub-agent 执行
return,将结果返回给主 Agent -
关键
Sub-agent 的整个执行历史被压缩为
return中的一句话
这种机制使得上下文长度呈现"锯齿状"变化:创建 sub-agent 时开始累积,return 时大幅缩短。
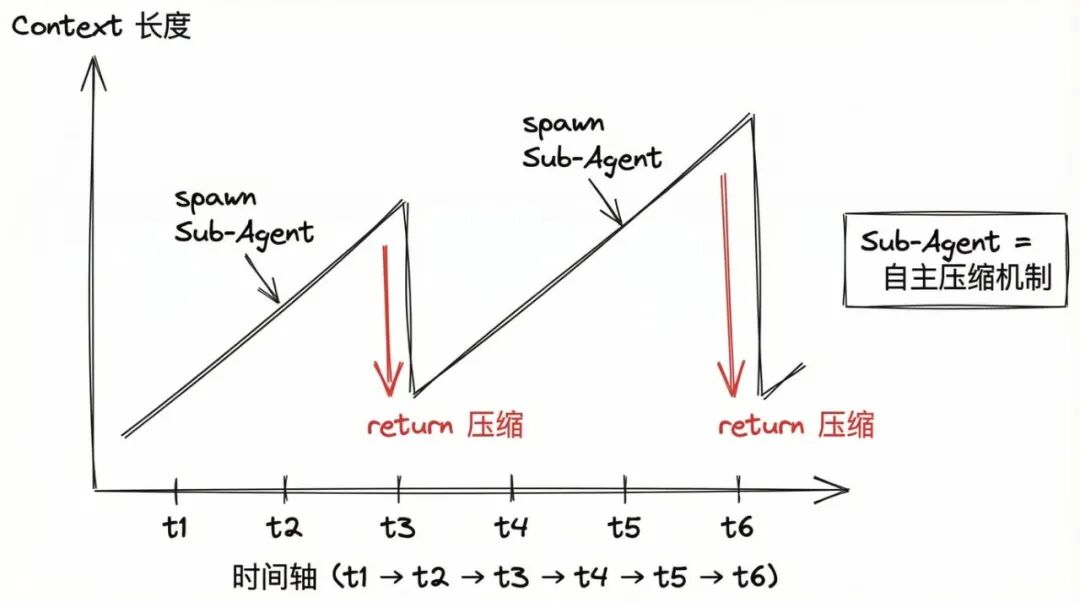
图3:Sub-Agent 的工作流程与上下文压缩
3.2 训练 Sub-Agent 能力
语言模型天然不喜欢"抹除记忆",因此 sub-agent 能力需要通过强化学习训练获得。训练时需要设计特殊的奖励函数:
-
惩罚主干过长
如果主 Agent 的上下文过长,给予负奖励
-
惩罚越界行为
如果 sub-agent 超出其职责范围,完成了整个任务,也给予负奖励
通过这种方式,模型学会在合适的时机创建 sub-agent,并让 sub-agent 专注于其子任务。
4. 预防性过滤(Preventive Filtering)
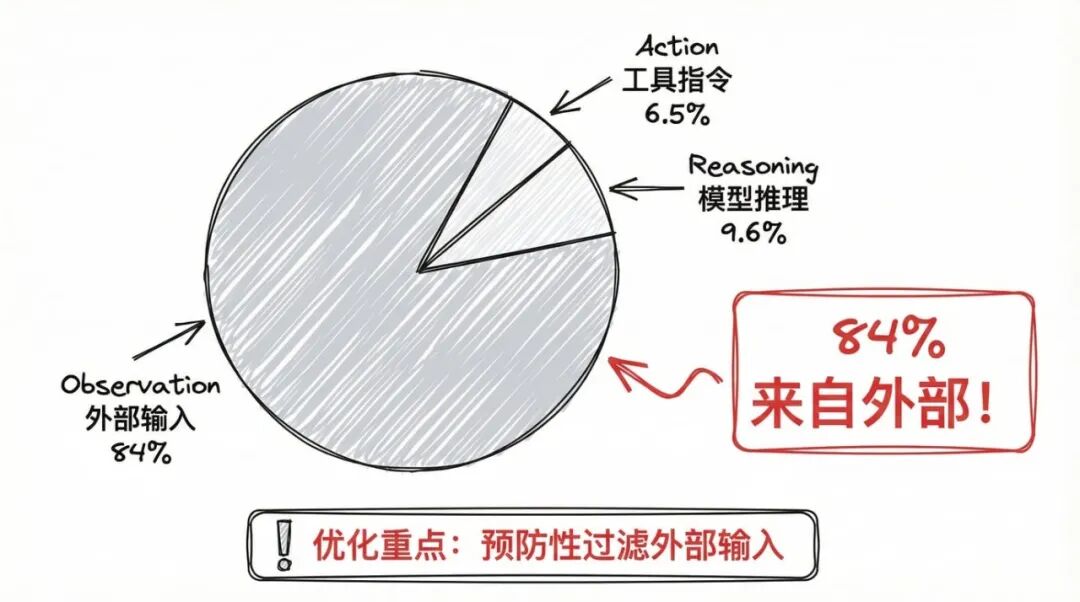
图4:预防性过滤机制
与其事后压缩,不如一开始就防止过多信息进入上下文。研究发现,在 AI Agent 的上下文中:
-
84%
的 token 来自外部输入(observation)
-
只有 6.5% 来自动作指令
-
只有 9.6% 来自模型的推理
这意味着,如果能在信息进入上下文前就进行过滤,效果会更好。
4.1 智能读取工具
传统的 read 工具会将整个文件内容一次性加载到上下文。改进的方案是让 read 工具接受额外的参数,指定需要读取的内容:
read(file="log.txt", filter="与 bug 修复相关的内容")
这个 read 工具本身需要具备一定智能(可以是一个小型语言模型),能够理解过滤条件并提取相关内容。
4.2 按需加载工具
另一个问题是工具说明本身也会占用大量 token。例如,GitHub 工具的完整说明就有 4600 个 token。
解决方案:不要在 system prompt 中预加载所有工具,而是让语言模型动态请求所需工具:
- 语言模型分析任务,输出所需工具的描述
- 搜索引擎根据描述从工具库中检索相关工具
- 将工具说明动态加载到上下文中
这正是 OpenClaw 中 skill 机制的核心思想——按需加载能力。
Context Engineering 的实践案例
OpenClaw 的实现
OpenClaw 作为早期的 AI Agent 框架,已经实现了多种 Context Engineering 技术:
- Compaction:当上下文超过阈值时,强制执行摘要压缩
- Memory Get/Search:
memory_search:语义搜索找到相关记忆片段
-
memory_get:只读取指定行范围的内容,而非整个文件 -
Observation Masking:简化工具输出
-
Sub-agent:通过 spawn 和 return 实现
为什么需要强制规则?
OpenClaw 使用硬编码的规则触发压缩(如上下文超过 N 个 token),而不是让语言模型自主决定。原因很简单:语言模型不喜欢抹除自己的记忆。
研究发现,即使明确告诉模型"当我说 reflection 时,你必须执行 erase 工具",模型仍然会拒绝执行。这种"抗拒遗忘"的特性需要通过专门的训练(如 AgentFold 论文)才能克服。
未来展望:Agentic Context Engineering
Context Engineering 的终极形态是让 AI Agent 自己决定如何管理上下文,而非依赖人类工程师设计的规则。这被称为 Agentic Context Engineering。
在这个范式下:
- 语言模型不仅执行任务,还要自主优化其输入管理策略
- 通过强化学习,模型学会在正确的时机压缩、存储、检索信息
- Context Engineering 从"工程技巧"演变为"模型能力"
这需要在训练阶段就将上下文管理作为一个显式的学习目标,而不是事后通过提示工程来弥补。
结论
–
Context Engineering 是 AI Agent 能够执行复杂、长时任务的基础。它通过压缩、记忆管理、子代理和预防性过滤等技术,突破了语言模型有限上下文窗口的限制。
随着 AI Agent 技术的发展,Context Engineering 也在从"人工设计的规则"向"模型自主学习的能力"演进。未来的 AI Agent 将更加智能地管理自己的"记忆",就像人类一样,知道什么该记住、什么该遗忘、什么该在需要时重新查找。
正如我们现在看 OpenClaw 可能像看初代 iPhone,Context Engineering 的技术也必将在未来几年内发生革命性的变化。但无论如何演进,其核心目标始终不变:让 AI Agent 在有限的资源下,做出无限的可能。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。
随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:
人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】
大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:
04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)
05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!
06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐


 1
1 0
0- 0



 已为社区贡献34条内容
已为社区贡献34条内容

所有评论(0)