
AI Agent新手入门:从零开始学习大模型,收藏这份学习指南
tool"""获取指定时区的当前时间。Args:timezone: 时区名称,如 "Asia/Shanghai", "US/Eastern", "Europe/London""""函数名就是工具名——LLM 在代码中直接调用docstring是 LLM 理解工具的唯一依据——写不清楚,Agent 就不会正确使用类型注解告诉 LLM 参数类型——让 LLM 知道要传字符串description ="
本文系统性介绍了AI Agent的概念、与LLM的区别,并通过Python代码实例展示了如何实现一个最小的ReAct Agent。文章还深入解析了smolagents框架的内部机制,包括System Prompt、Agent执行日志、记忆机制等,并对比了CodeAgent和ToolCallingAgent两种执行范式。此外,还探讨了多Agent协作、Agent调控方法以及生产环境注意事项,为读者提供了全面的学习指南。
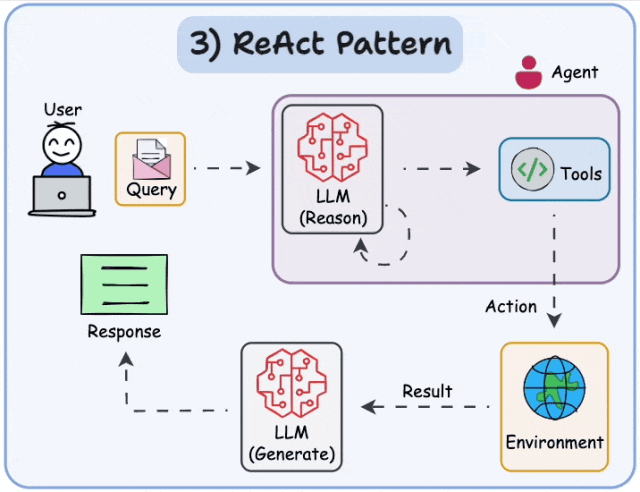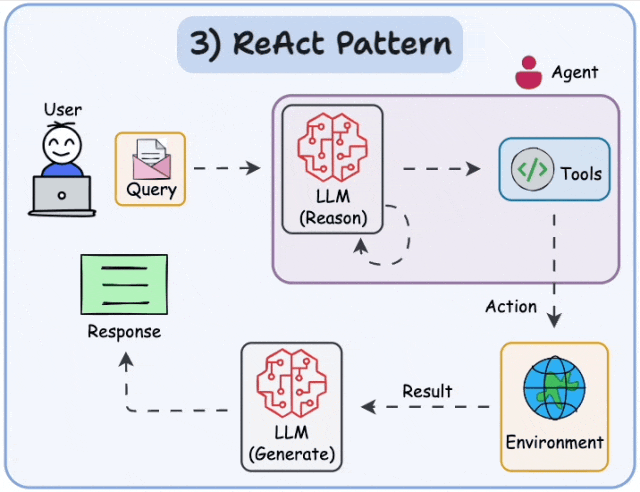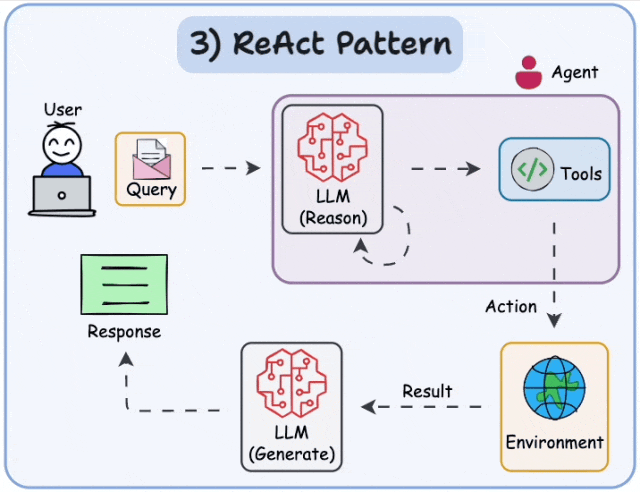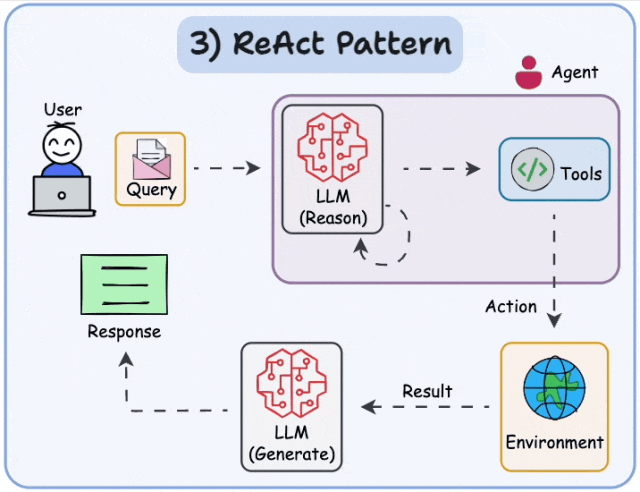
1、 AI Agent 到底是什么
1.1 LLM 和 Agent 的核心区别
你用过 ChatGPT 或者 DeepSeek 对话,它们能写文章、翻译、写代码。但你让它"帮我查一下今天北京的天气,然后订一家评分最高的餐厅"——它做不到。
为什么?因为 LLM 本质上只做一件事:输入文本,输出文本。它没有手,不能上网查天气,不能调用订餐 API,甚至不知道"现在"是几点。
Agent 解决的就是这个问题。一句话概括:
LLM 是一个只能说话的大脑,Agent 是一个能思考、能动手、能从结果中学习的完整系统。
| LLM | Agent | |
|---|---|---|
| 能力 | 生成文本 | 生成文本 + 调用工具 + 观察结果 |
| 状态 | 无状态(每次对话独立) | 有记忆(记住之前做了什么) |
| 决策 | 一次性回答 | 多步推理,自主决定下一步 |
| 边界 | 训练数据截止日期内的知识 | 可以访问实时数据和外部系统 |
1.2 Agent 的四大支柱
一个完整的 Agent 系统由四个核心组件构成:
┌─────────────┐
│ 用户任务 │
└──────┬──────┘
▼
┌────────────────────────┐
│ LLM │
│ (大脑 / 推理引擎) │
└────────────────────────┘
▲ ▲ ▲ ▲
│ │ │ │
┌─────┘ ┌──┘ ┌──┘ ┌──┘
▼ ▼ ▼ ▼
┌────────┐┌──────┐┌─────┐┌──────────┐
│ 规划 ││ 记忆 ││ 工具 ││ 行动循环 │
│Planning││Memory││Tools││Action Loop│
└────────┘└──────┘└─────┘└──────────┘
- 规划(Planning):把复杂任务拆解成可执行的步骤
- 记忆(Memory):记住之前的对话和操作结果
- 工具(Tools):扩展 LLM 的能力边界——计算器、搜索引擎、API 调用
- 行动循环(Action Loop):把上面三者串起来的执行引擎,也就是 ReAct 循环
1.3 为什么现在 Agent 变得实用了
Agent 的概念并不新,但直到最近才真正可用,原因有三:
- LLM 能力跃升:GPT-4、Claude、DeepSeek 等模型的推理能力足够强,能可靠地遵循复杂指令和工具调用格式
- 工具调用标准化:OpenAI 的 Function Calling、Anthropic 的 Tool Use、以及 MCP 让工具集成有了统一接口
- 框架生态成熟:LangChain、LangGraph、smolagents、CrewAI 等框架大幅降低了构建 Agent 的门槛
理论讲够了,我们来写代码。
2、手写一个最小 ReAct Agent
2.1 ReAct 是什么
ReAct 来自 2022 年 Yao et al. 的论文 “ReAct: Synergizing Reasoning and Acting in Language Models”。核心思想极其简单:
让 LLM 交替进行"思考"和"行动",每次行动后观察结果,再决定下一步。
┌──────────────────────────────────────────────────┐
│ 用户任务 │
└──────────────────────┬───────────────────────────┘
▼
┌─────────────┐
┌───▶│ Thought │ LLM 思考:我需要做什么?
│ └──────┬──────┘
│ ▼
│ ┌─────────────┐
│ │ Action │ LLM 决定:调用哪个工具?
│ └──────┬──────┘
│ ▼
│ ┌─────────────┐
│ │ Observation │ 执行工具,拿到结果
│ └──────┬──────┘
│ ▼
│ 还需要更多 ──── 是 ────┐
│ 步骤吗? │
│ │ │
│ 否 │
│ ▼ │
│ ┌─────────────┐ │
│ │ Final Answer│ │
│ └─────────────┘ │
└─────────────────────────────────┘
为什么这比让 LLM 一次性回答更好?因为每一步都有真实的观察结果来"校准"推理。LLM 不是在凭空想象答案,而是基于实际数据一步步推导。
2.2 纯 Python 实现 ReAct 循环
下面这段代码不依赖任何 Agent 框架,只用 Python + LLM API,实现一个完整的 ReAct Agent。注意 calculator 中的 eval() 仅用于学习演示,生产环境必须使用沙箱:
"""
minimal_react.py — 纯手写 ReAct Agent(不依赖任何框架)
"""
import json, re
from litellm import completion
# ── 第一步:定义工具 ──────────────────────────────────
def calculator(expr: str)-> str:
"""安全受限的计算器(生产环境应使用 AST 解析或沙箱)"""
import ast, operator
allowed ={ast.Add: operator.add, ast.Sub: operator.sub,
ast.Mult: operator.mul, ast.Div: operator.truediv, ast.Pow: operator.pow}
tree = ast.parse(expr, mode="eval")
def _eval(node):
if isinstance(node, ast.Expression):return _eval(node.body)
if isinstance(node, ast.Constant):return node.value
if isinstance(node, ast.BinOp):return allowed[type(node.op)](_eval(node.left), _eval(node.right))
raiseValueError(f"不支持的操作: {ast.dump(node)}")
return str(_eval(tree))
def weather(city: str)-> str:
return{"北京":"晴 22°C","上海":"多云 26°C"}.get(city,"未知城市")
tools ={"calculator": calculator,"weather": weather}
tool_desc ="\n".join(f"- {name}: 调用方式 {name}(参数)"for name in tools)
# ── 第二步:设计 System Prompt ─────────────────────────
SYSTEM_PROMPT = f"""你是一个 ReAct Agent。收到任务后,按以下格式交替输出:
Thought: <你的思考过程>
Action: <工具名>(<参数>)
等待系统返回 Observation 后,继续思考。
当你得出最终答案时,输出:
Thought: 我已经得到了答案。
Final Answer: <最终答案>
可用工具:
{tool_desc}
"""
# ── 第三步:ReAct 循环 ─────────────────────────────────
def react_agent(task: str, max_steps: int =5)-> str:
messages =[
{"role":"system","content": SYSTEM_PROMPT},
{"role":"user","content": task},
]
for step in range(max_steps):
response = completion(model="deepseek/deepseek-chat", messages=messages)
output = response.choices[0].message.content
print(f"\n── Step {step} ──\n{output}")
if"Final Answer:"in output:
return output.split("Final Answer:")[-1].strip()
action_match = re.search(r"Action:\s*(\w+)\((.+?)\)", output)
if action_match:
tool_name, arg = action_match.group(1), action_match.group(2).strip("\"'")
observation = tools[tool_name](arg)if tool_name in tools else"未知工具"
print(f"Observation: {observation}")
messages.append({"role":"assistant","content": output})
messages.append({"role":"user","content": f"Observation: {observation}"})
else:
messages.append({"role":"assistant","content": output})
return"达到最大步数,未得出答案"
# ── 运行 ──────────────────────────────────────────────
answer = react_agent("北京今天天气怎么样?如果气温超过 20 度,计算 20 * 3.14 的值。")
print(f"\n最终答案: {answer}")
这段代码只有 ~50 行,但它包含了一个 Agent 的全部核心要素:
| 要素 | 对应代码 |
|---|---|
| 工具注册 | tools 字典 |
| System Prompt | 告诉 LLM 用 Thought/Action/Observation 格式 |
| ReAct 循环 | forstepinrange(max_steps) |
| 工具调用 | 正则解析 Action,执行对应函数 |
| 记忆 | messages 列表累积对话历史 |
| 终止条件 | 检测 FinalAnswer: 或达到 max_steps |
2.3 手写的局限性
这个最小实现能跑,但离生产可用差得远:
- 解析脆弱:靠正则匹配
Action:tool(arg),LLM 稍微变一下格式就挂了 - 没有沙箱:即使用了 AST 解析,复杂场景下仍有安全隐患
- 错误处理缺失:工具调用失败、LLM 输出格式错误都没处理
- 不支持复杂工具:多参数、嵌套调用、异步工具都搞不定
这就是为什么我们需要框架。接下来用 smolagents 看看同样的事情怎么做。
3、 用 smolagents 10 行代码跑起来
上面我们手写了 50 行代码实现 ReAct。smolagents 把这些全部封装好了——模型适配、Prompt 模板、循环控制、工具解析、错误恢复——你只需要关心业务逻辑。
from smolagents importCodeAgent,LiteLLMModel
model =LiteLLMModel(model_id="deepseek/deepseek-chat", temperature=0.7)
agent =CodeAgent(tools=[], model=model, add_base_tools=True)
result = agent.run("斐波那契数列的第 20 项是多少?请同时告诉我计算过程。")
print(result)
三个核心要素,和手写版一一对应:
| 手写版 | smolagents |
|---|---|
completion() 调用 LLM |
LiteLLMModel 封装模型调用 |
tools 字典 + 正则解析 |
CodeAgent 自动管理工具 |
forstepinrange(max_steps) |
Agent 内部的 ReAct 循环 |
关键区别:smolagents 的 CodeAgent 不是让 LLM 输出 Action:tool(arg) 这种文本格式,而是让 LLM 直接写 Python 代码。LLM 可以用循环、条件判断、变量赋值——表达力远超文本格式。
add_base_tools=True 会添加内置工具(如 PythonInterpreterTool),让 Agent 即使没有自定义工具也能通过写代码来解决问题。
4、深入 ReAct 内部机制
框架帮我们封装了细节,但理解内部机制才能在出问题时知道怎么调试。这一节我们拆开 smolagents 的 Agent,看看每一层发生了什么。
4.1 System Prompt — LLM 看到了什么
Agent 的行为由 System Prompt 决定。smolagents 使用 Jinja2 模板,在初始化时把工具描述、managed_agents 信息注入进去:
agent =CodeAgent(tools=[], model=model, add_base_tools=True)
# 查看 System Prompt 模板
system_prompt = agent.prompt_templates["system_prompt"]
print(f"System prompt 长度: {len(system_prompt)} 字符")
print(system_prompt[:500])
这个 System Prompt 告诉 LLM:
- 你是一个 Agent,要按 Thought → Code → Observation 的格式工作
- 你可以使用这些工具(自动列出每个工具的名称、描述、参数类型)
- 当你得出最终答案时,调用
final_answer()函数
你还可以通过 instructions 参数追加自定义指令,不需要修改模板:
custom_agent =CodeAgent(
tools=[], model=model, add_base_tools=True,
instructions="你是一个数学教授。回答问题时,请用通俗易懂的方式解释推理过程。",
)
result = custom_agent.run("为什么 0.1 + 0.2 不等于 0.3?")
4.2 Agent 执行日志 — 逐步拆解 ReAct 循环
agent.logs 记录了每一步的详细信息。我们用一个斐波那契工具来观察:
from smolagents import tool
@tool
def fibonacci(n: int)-> str:
"""
计算斐波那契数列的第 n 项。
Args:
n: 要计算的项数(从第 1 项开始)
"""
if n <=0:
return"n 必须是正整数"
a, b =0,1
for _ in range(n -1):
a, b = b, a + b
return f"斐波那契数列第 {n} 项是 {b}"
log_agent =CodeAgent(tools=[fibonacci], model=model, max_steps=5)
result = log_agent.run("斐波那契数列第 10 项和第 20 项分别是多少?它们的比值接近什么数?")
运行后查看日志:
for i, step in enumerate(log_agent.logs):
if hasattr(step,"model_output"):
print(f"\n--- Step {i} ---")
print(f"LLM 输出: {step.model_output[:200]}...")
if hasattr(step,"observations"):
print(f"观察结果: {step.observations[:200]}...")
你会看到类似这样的执行过程:
──Step0──
LLM 输出:Thought:我需要分别计算第10项和第20项,然后算比值...
Code:
result_10 = fibonacci(10)
result_20 = fibonacci(20)
print(result_10, result_20)
观察结果:斐波那契数列第10项是55斐波那契数列第20项是6765
──Step1──
LLM 输出:Thought:比值是6765/55≈123,这接近黄金比例的幂...
Code:
ratio =6765/55
final_answer(f"第10项=55, 第20项=6765, 比值≈{ratio:.2f}")
注意 CodeAgent 在一步内就调用了两次 fibonacci(用 Python 变量存储结果),这是它比 ToolCallingAgent 高效的原因。
4.3 Agent 的记忆 — writememoryto_messages()
Agent 的"记忆"就是对话历史。每一步的 LLM 输出和工具观察结果都会被追加到消息列表中,作为下一步的上下文:
messages = log_agent.write_memory_to_messages()
print(f"总消息数: {len(messages)}")
for msg in messages:
print(f" {str(msg.content)[:100]}...")
这个方法做了两件事:
- 把 System Prompt 转成消息格式
- 把每个执行步骤(
memory.steps)转成消息追加进去
这就是 Agent 能"记住"之前做了什么的原因——所有历史都在 messages 里,每次调用 LLM 时一起发送。
5、工具系统入门
5.1 为什么需要工具
LLM 有三个硬伤:不知道实时信息、不能精确计算、不能操作外部系统。工具就是给 LLM 装上的"手":
| LLM 做不到的 | 工具解决方案 |
|---|---|
| 不知道现在几点 | 时间查询工具 |
| 算不准浮点数 | 计算器工具 |
| 不能查数据库 | 数据库查询工具 |
| 不能发邮件 | 邮件 API 工具 |
工具的本质是一个函数,它有名称、描述、输入参数类型和返回值。LLM 通过阅读工具描述来决定什么时候用、怎么用。
5.2 @tool 装饰器 — 最简单的定义方式
from smolagents import tool
@tool
def get_current_time(timezone: str ="Asia/Shanghai")-> str:
"""
获取指定时区的当前时间。
Args:
timezone: 时区名称,如 "Asia/Shanghai", "US/Eastern", "Europe/London"
"""
from datetime import datetime
import zoneinfo
zone = zoneinfo.ZoneInfo(timezone)
now = datetime.now(zone)
return now.strftime("%Y-%m-%d %H:%M:%S %Z")
三个关键点:
- 函数名就是工具名——LLM 在代码中直接调用
get_current_time() - docstring 是 LLM 理解工具的唯一依据——写不清楚,Agent 就不会正确使用
- 类型注解告诉 LLM 参数类型——
timezone:str让 LLM 知道要传字符串
5.3 Tool 子类 — 复杂工具的定义方式
当工具需要初始化状态(比如数据库连接)或有复杂的输入结构时,用子类更合适:
from smolagents importTool
classUnitConverter(Tool):
name ="unit_converter"
description ="单位换算工具,支持长度、重量、温度的常见单位转换"
inputs ={
"value":{"type":"number","description":"要转换的数值"},
"from_unit":{"type":"string","description":"原始单位,如 km, mile, kg, lb"},
"to_unit":{"type":"string","description":"目标单位"},
}
output_type ="string"
conversions ={
("km","mile"):lambda v: v *0.621371,
("mile","km"):lambda v: v *1.60934,
("celsius","fahrenheit"):lambda v: v *9/5+32,
("fahrenheit","celsius"):lambda v:(v -32)*5/9,
}
def forward(self, value: float, from_unit: str, to_unit: str)-> str:
key =(from_unit.lower(), to_unit.lower())
if key in self.conversions:
result = self.conversions[key](value)
return f"{value} {from_unit} = {result:.4f} {to_unit}"
return f"不支持从 {from_unit} 到 {to_unit} 的转换"
两种方式的选择很简单:简单无状态用 @tool,复杂有状态用 Tool 子类。
5.4 Agent 自主选择工具
把多个工具交给 Agent,它会根据任务自动选择合适的工具——你不需要告诉它用哪个:
@tool
def weather_lookup(city: str)-> str:
"""
查询城市的天气信息(模拟数据)。
Args:
city: 城市名称,如 "北京", "上海", "东京"
"""
mock_weather ={
"北京":{"temp":22,"condition":"晴","humidity":35},
"上海":{"temp":26,"condition":"多云","humidity":65},
"东京":{"temp":20,"condition":"小雨","humidity":78},
}
if city in mock_weather:
w = mock_weather[city]
return f"{city}: {w['condition']}, 温度 {w['temp']}°C, 湿度 {w['humidity']}%"
return f"暂无 {city} 的天气数据"
agent =CodeAgent(
tools=[get_current_time, weather_lookup,UnitConverter()],
model=model,
)
# Agent 自动选择 weather_lookup + 推理
agent.run("北京和东京今天哪个城市更适合户外活动?请给出理由。")
# Agent 自动选择 UnitConverter
agent.run("100 公里换算成英里是多少?")
这就是 Agent 的"自主决策"能力——它读了每个工具的描述,理解了任务需求,然后自己决定调用哪些工具、以什么顺序调用。
6、CodeAgent vs ToolCallingAgent
smolagents 提供两种 Agent,代表两种截然不同的执行范式:
┌─────────────────┬──────────────────────────────────────┐
│CodeAgent│ LLM 生成Python代码,直接执行│
││支持循环、条件、变量→更灵活│
││研究表明比 JSON 方式少30%步骤│
├─────────────────┼──────────────────────────────────────┤
│ToolCallingAgent│ LLM 生成 JSON 格式的工具调用│
││类似OpenAIFunctionCalling│
││更安全可控,但表达力有限│
└─────────────────┴──────────────────────────────────────┘
用同一个任务对比:
from smolagents importCodeAgent,ToolCallingAgent
tools =[lookup_population, lookup_gdp]
task ="比较中国、美国和日本的人口和 GDP,哪个国家的人均 GDP 最高?"
# CodeAgent:一步搞定
code_agent =CodeAgent(tools=tools, model=model)
result = code_agent.run(task)
# LLM 写了一个 for 循环,一次查完 3 个国家的数据,直接算出结果
# ToolCallingAgent:需要多步
tc_agent =ToolCallingAgent(tools=tools, model=model)
result = tc_agent.run(task)
# LLM 每次只能调一个工具:查中国人口 → 查中国GDP → 查美国人口 → ...
CodeAgent 的执行过程(1-2 步):
# LLM 生成的代码(一步内完成)
countries =["中国","美国","日本"]
for c in countries:
pop = lookup_population(c)
gdp = lookup_gdp(c)
print(f"{c}: 人口={pop}, GDP={gdp}")
# 然后直接计算人均 GDP,给出答案
ToolCallingAgent 的执行过程(6+ 步):
Step0:调用 lookup_population("中国")→"14.1 亿"
Step1:调用 lookup_gdp("中国")→"17.8 万亿美元"
Step2:调用 lookup_population("美国")→"3.3 亿"
Step3:调用 lookup_gdp("美国")→"25.5 万亿美元"
Step4:调用 lookup_population("日本")→"1.25 亿"
Step5:调用 lookup_gdp("日本")→"4.2 万亿美元"
Step6:计算并给出答案
选择建议:
- 学习和原型阶段 → CodeAgent(更灵活高效)
- 生产环境 → ToolCallingAgent(更安全可控),或 CodeAgent + 沙箱
7、 多 Agent 协作初探
当任务足够复杂时,一个 Agent 搞不定。smolagents 支持 Manager-Worker 模式:
┌──────────────┐
│Manager│←接收用户任务,决定分发给谁
│Agent│
└──────┬───────┘
│分发任务
┌──────┴───────┐
││
▼▼
┌────────┐┌────────────┐
│Search││Analyst│
│Agent││Agent│
│搜索信息││分析推理│
└────────┘└────────────┘
# Worker 1:搜索 Agent
search_agent =CodeAgent(
tools=[search_tech_news, search_company_info],
model=model,
name="search_agent",
description="搜索 Agent:负责搜索科技新闻和公司信息。当需要查找事实性信息时,交给它。",
)
# Worker 2:分析 Agent
analyst_agent =CodeAgent(
tools=[], model=model,
name="analyst_agent",
description="分析 Agent:负责数据分析、趋势判断和撰写报告。当需要对信息进行深度分析时,交给它。",
add_base_tools=True,
)
# Manager:管理两个 Worker
manager =CodeAgent(
tools=[],
model=model,
managed_agents=[search_agent, analyst_agent],
)
result = manager.run(
"请帮我分析当前 AI 行业的竞争格局。"
"先搜索 AI 领域的最新新闻和主要公司(OpenAI、Anthropic、Google)的信息,"
"然后基于这些信息写一份简短的行业分析报告。"
)
Manager 把 Worker 当作"工具"来使用——它读 Worker 的 description,决定把子任务分给谁。Worker 执行完后把结果返回给 Manager,Manager 汇总后给出最终答案。
多 Agent 的核心价值:专业分工。搜索 Agent 专注信息检索,分析 Agent 专注推理总结,各司其职。
8、Agent 调控三板斧
8.1 max_steps — 防止无限循环
Agent 可能陷入死循环(反复尝试同一个失败的操作)。 max_steps 是安全阀:
limited_agent =CodeAgent(tools=[fibonacci], model=model, max_steps=2)
# 给一个需要很多步的任务,但只允许 2 步
result = limited_agent.run("计算斐波那契第 5、10、15、20、25、30 项,画出增长趋势。")
# Agent 会在 2 步内尽力完成,超出则停止
默认值通常是 6-10 步。简单任务设小一点(2-3),复杂任务设大一点(8-10)。
8.2 instructions — 定制 Agent 人设
不需要修改 System Prompt 模板,直接追加指令:
agent =CodeAgent(
tools=[], model=model, add_base_tools=True,
instructions="你是一个数学教授。回答时用通俗易懂的方式解释,就像给学生上课。",
)
instructions 会被追加到 System Prompt 末尾,是最简单的定制方式。
8.3 planning_interval — 定期反思
复杂任务中,Agent 可能走偏。 planning_interval 让它每 N 步暂停,更新已知事实、反思进展、调整计划:
planning_agent =CodeAgent(
tools=[search_database, get_user_budget],
model=model,
planning_interval=2,# 每 2 步反思一次
max_steps=8,
)
这三个参数覆盖了 80% 的 Agent 调优需求。
9、 生产环境注意事项
CodeAgent 让 LLM 生成并执行代码,这意味着安全风险。在部署到生产环境前,需要了解四类威胁:
| 威胁类型 | 说明 | 风险等级 |
|---|---|---|
| LLM 自身错误 | LLM 无意中生成有害命令 | 低 |
| 供应链攻击 | 使用被篡改的 LLM 模型 | 中 |
| Prompt 注入 | Agent 浏览网页时遇到恶意指令 | 高 |
| 公开暴露 | 恶意用户构造对抗性输入 | 高 |
smolagents 提供多种沙箱方案:
| 方案 | 安全级别 | 适用场景 |
|---|---|---|
| Local(默认) | AST 沙箱 | 开发/学习 |
| E2B | 云端隔离 | 云端生产环境 |
| Docker | 容器隔离 | 本地生产环境 |
| Blaxel | 云端 VM | 低延迟生产 |
开发阶段用默认的 Local executor 足够。生产阶段必须上 E2B 或 Docker 沙箱,加上输入验证和输出过滤。
10、 总结与下一步
这篇文章我们走过了 Agent 的完整认知路径:
- Agent = LLM + 工具 + 循环。LLM 是大脑,工具是手,ReAct 循环是行动引擎。
- ReAct = Thought + Action + Observation。交替思考和行动,每步都有真实观察来校准推理。
- 我们从 50 行纯 Python 手写了一个 ReAct Agent,理解了底层原理;再用 smolagents 框架看到了工业级实现。
- CodeAgent 写代码更灵活,ToolCallingAgent 调 JSON 更安全。多 Agent 实现专业分工。
那么如何学习大模型 AI ?
对于刚入门大模型的小白,或是想转型/进阶的程序员来说,最头疼的就是找不到系统、全面的学习资源,要么零散不成体系,要么收费高昂,白白浪费时间走弯路。今天就给大家精心整理了一份全面且免费的AI大模型学习资源包,覆盖从入门到实战、从理论到面试的全流程,所有资料均已整理完毕,免费分享给各位!
核心包含:AI大模型全套系统化学习路线图(小白可直接照做)、精品学习书籍+电子文档、干货视频教程、可直接上手的实战项目+源码、2026大厂面试真题题库,一站式解决你的学习痛点,不用再到处搜集拼凑!
👇👇扫码免费领取全部内容👇👇

1、大模型系统化学习路线
学习大模型,方向比努力更重要!很多小白入门就陷入“盲目看视频、乱刷资料”的误区,最后越学越懵。这里给大家整理的这份学习路线,是结合2026年大模型行业趋势和新手学习规律设计的,最科学、最系统,从零基础到精通,每一步都有明确指引,帮你节省80%的无效学习时间,少走弯路、高效进阶。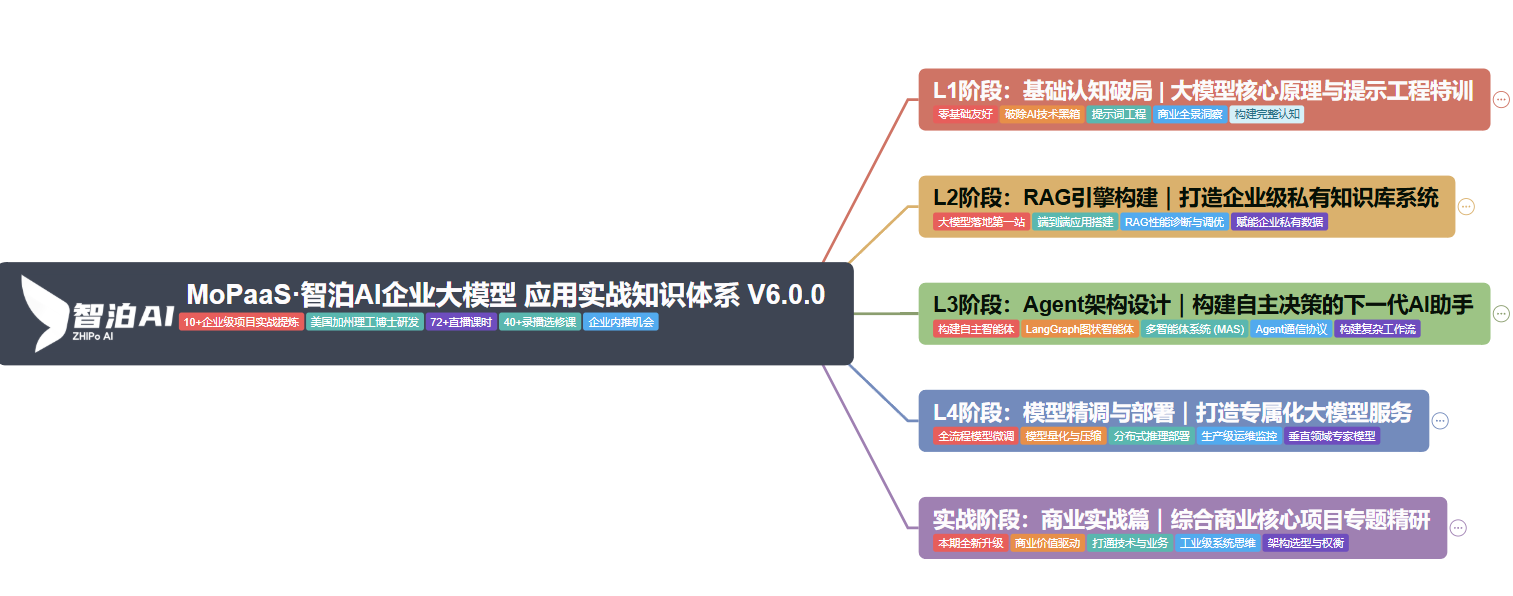
2、大模型学习书籍&文档
理论是实战的根基,尤其是对于程序员来说,想要真正吃透大模型原理,离不开优质的书籍和文档支撑。本次整理的书籍和电子文档,均由大模型领域顶尖专家、大厂技术大咖撰写,涵盖基础入门、核心原理、进阶技巧等内容,语言通俗易懂,既有理论深度,又贴合实战场景,小白能看懂,程序员能进阶,为后续实战和面试打下坚实基础。

3、AI大模型最新行业报告
无论是小白了解行业、规划学习方向,还是程序员转型、拓展业务边界,都需要紧跟行业趋势。本次整理的2026最新大模型行业报告,针对互联网、金融、医疗、工业等多个主流行业,系统调研了大模型的应用现状、发展趋势、现存问题及潜在机会,帮你清晰了解哪些行业更适合大模型落地,哪些技术方向值得重点深耕,避免盲目学习,精准对接行业需求。值得一提的是,报告还包含了多模态、AI Agent等前沿方向的发展分析,助力大家把握技术风口。

4、大模型项目实战&配套源码
对于程序员和想落地能力的小白来说,“光说不练假把式”,只有动手实战,才能真正巩固所学知识,将理论转化为实际能力。本次整理的实战项目,涵盖基础应用、进阶开发、多场景落地等类型,每个项目都附带完整源码和详细教程,从简单的ChatPDF搭建,到复杂的RAG系统开发、大模型部署,难度由浅入深,小白可逐步上手,程序员可直接参考优化,既能练手提升技术,又能丰富简历,为求职和职业发展加分。

5、大模型大厂面试真题
2026年大模型面试已从单纯考察原理,转向侧重技术落地和业务结合的综合考察,很多程序员和新手因为缺乏针对性准备,明明技术不错,却在面试中失利。为此,我精心整理了各大厂最新大模型面试真题题库,涵盖基础原理、Prompt工程、RAG系统、模型微调、部署优化等核心考点,不仅有真题,还附带详细解题思路和行业踩坑经验,帮你精准把握面试重点,提前做好准备,面试时从容应对、游刃有余。

6、四阶段精细化学习规划(附时间节点,可直接照做)
结合上述资源,给大家整理了一份可直接落地的四阶段学习规划,总时长约2个月,小白可循序渐进,程序员可根据自身基础调整节奏,高效掌握大模型核心能力,快速实现从“入门”到“能落地、能面试”的跨越。
第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
-
硬件选型
-
带你了解全球大模型
-
使用国产大模型服务
-
搭建 OpenAI 代理
-
热身:基于阿里云 PAI 部署 Stable Diffusion
-
在本地计算机运行大模型
-
大模型的私有化部署
-
基于 vLLM 部署大模型
-
案例:如何优雅地在阿里云私有部署开源大模型
-
部署一套开源 LLM 项目
-
内容安全
-
互联网信息服务算法备案
-
…
👇👇扫码免费领取全部内容👇👇
3、这些资料真的有用吗?
这份资料由我和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐



 26
26 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)