
用了这套配置,Claude Code 终于不用我反复交代背景了,2026 最强 Hooks、Skills、Agents 实战
每次打开 Claude Code 新会话,我都要先来一段开场白:"这是一个 Node.js 项目,用的 Prisma + Express,测试框架是 Jest,别动 package-lock.json,别碰 .env 文件……每次新开会话,上下文清零,规则清零,约束清零。CLAUDE.md 是它的长期记忆,Skills 是它的专业技能库,Hooks 是它的行为准则,Agents 是它的团队分工。C
每次打开 Claude Code 新会话,我都要先来一段开场白:"这是一个 Node.js 项目,用的 Prisma + Express,测试框架是 Jest,别动 package-lock.json,别碰 .env 文件……"
重复了大概第十次以后,我开始怀疑自己是不是在训练一个失忆的实习生。
更崩溃的是上周——Claude 帮我改完一个 API 接口,顺手把 package-lock.json "优化"了一下,600 多行 diff。我 review 的时候差点以为自己看错了仓库。它不是故意的,但每次都得手动盯着,这不就是把自动化又变回人肉 review 了吗?
这个问题的根源在于:大多数人用 Claude Code 还停留在"对话式编程"阶段。每次新开会话,上下文清零,规则清零,约束清零。你以为在跟一个越来越懂你的搭档合作,实际上每次都是从零开始。
好消息是,Claude Code 其实已经内置了一套完整的扩展机制来解决这个问题。坏消息是,90% 的人不知道怎么用。
这篇文章会带你从零搭建一个"自运转"的 Claude Code 工作流。看完之后,你的 Claude 会自动守规矩、自动复用经验、自动并行干活。不需要写代码——全是配置。
三驾马车:Hooks、Skills、Agents
在具体配置之前,先把三者的定位说清楚。我喜欢用一个团队管理的类比:
-
Hooks = 自动化守卫。它不做决策,只在特定时机执行检查。就像公司的 CI/CD 流程——代码提交前自动跑 lint,部署前自动跑测试。Claude 每次写文件、执行命令、结束任务时,你的 Hook 都在旁边盯着。
-
Skills = 知识注入。它把你的经验、规范、最佳实践打包成可复用的"知识包"。类似于团队的 Wiki 或者 Runbook,但不是被动等着被查阅,而是在需要的时候主动加载进 Claude 的上下文。
-
Agents = 并行执行。当任务可以拆分成多个独立子任务时,你可以派出多个专职 Agent 同时干活。一个负责写代码,一个负责 review,一个负责写测试——就像技术团队里的角色分工。
三者的关系不是互斥的,而是分层协作:
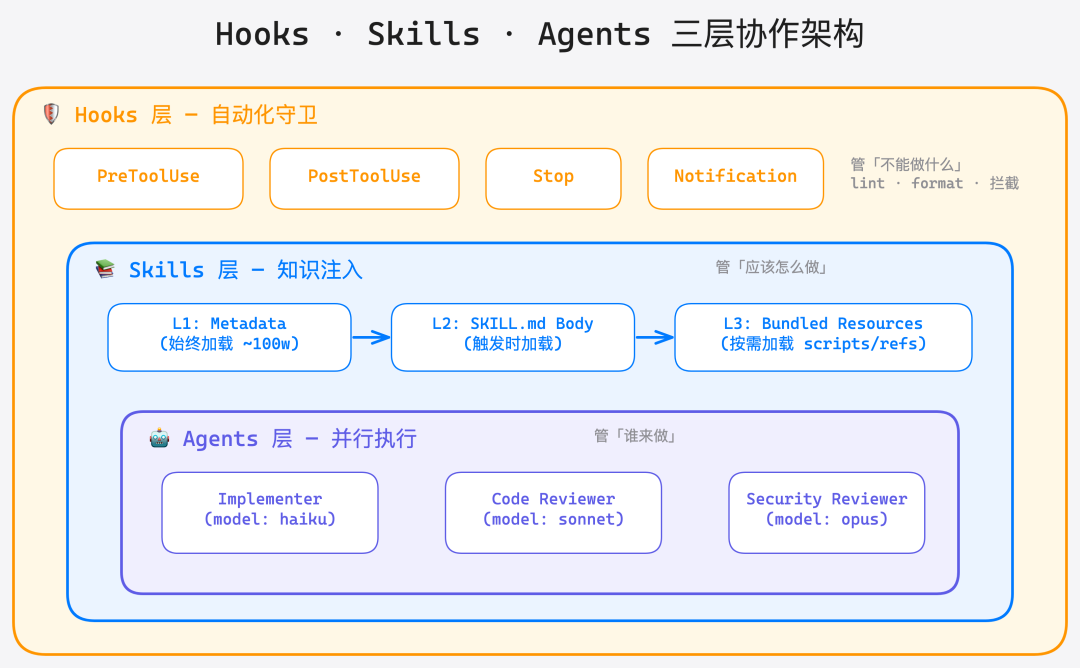
一句话总结:Hooks 管"不能做什么",Skills 管"应该怎么做",Agents 管"谁来做"。 把这三个搞定,你的 Claude Code 就从一个"需要手把手带的实习生"变成了"自带 SOP 的高级工程师"。
Hooks:让 Claude 自己守规矩
Hooks 的核心思想很简单:在 Claude 执行特定操作的前后,自动触发你定义的逻辑。如果你用过 Git 的 pre-commit hook 或者 Spring 的 AOP,概念一模一样。
9 种事件,覆盖完整生命周期
|
事件 |
触发时机 |
核心用途 |
|---|---|---|
PreToolUse |
工具执行前 |
拦截危险操作、修改输入参数 |
PostToolUse |
工具执行后 |
自动格式化、跑 linter |
UserPromptSubmit |
用户提交 prompt 时 |
注入上下文、安全警告 |
Stop |
主 Agent 准备停止时 |
检查是否跑了测试/build |
SubagentStop |
子 Agent 准备停止时 |
验证子任务完成度 |
SessionStart |
会话开始时 |
加载环境变量、设置项目上下文 |
SessionEnd |
会话结束时 |
清理临时文件、记录日志 |
PreCompact |
上下文压缩前 |
保留关键信息不被丢弃 |
Notification |
通知发送时 |
桌面提醒(权限请求、空闲提示) |
每个事件支持两种 Hook 类型:
-
command:执行 Shell 脚本,适合确定性检查(文件是否存在、格式是否正确),默认超时 60 秒
-
prompt:让 LLM 做判断,适合需要语义理解的场景("这次修改是否影响了 API 契约?"),默认超时 30 秒,仅
PreToolUse、PostToolUse、Stop、SubagentStop、UserPromptSubmit支持
Matcher 语法
Matcher 决定了"这个 Hook 监听哪些工具":
"Write" -- 精确匹配 Write 工具
"Read|Write|Edit" -- 匹配多个工具
"*" -- 匹配所有工具
"mcp__.*__delete.*" -- 正则匹配(所有 MCP 删除操作)
"permission_prompt" -- Notification 事件专用 matcher完整 settings.json 配置(Node.js 项目)
这是我在生产项目中实际使用的配置,直接放在 .claude/settings.json 里:
{
"hooks": {
"PreToolUse": [
{
"matcher": "Write|Edit",
"hooks": [
{
"type": "prompt",
"prompt": "File path: $TOOL_INPUT.file_path. Verify: 1) Not .env or credentials 2) Not package-lock.json/yarn.lock 3) No path traversal (..). Return 'approve' or 'deny'."
}
]
}
],
"PostToolUse": [
{
"matcher": "Write|Edit",
"hooks": [
{
"type": "command",
"command": "npx prettier --write \"$TOOL_INPUT.file_path\" 2>/dev/null; npx eslint --fix \"$TOOL_INPUT.file_path\" 2>/dev/null; exit 0"
}
]
}
],
"Stop": [
{
"matcher": "*",
"hooks": [
{
"type": "prompt",
"prompt": "Review transcript. If code was modified, verify: 1) Tests were run 2) Build succeeded 3) All user questions answered. Return 'approve' or 'block' with reason."
}
]
}
],
"Notification": [
{
"matcher": "permission_prompt|idle_prompt",
"hooks": [
{
"type": "command",
"command": "osascript -e 'display notification \"Claude needs attention\" with title \"Claude Code\"'"
}
]
}
]
},
"permissions": {
"allow": ["Edit", "Write", "Bash(npm test:*)", "Bash(npm run build:*)"],
"deny": ["Bash(rm -rf:*)", "Bash(git push --force:*)"]
}
}这套配置做了四件事:
-
写文件前:用 LLM 检查是否在碰敏感文件(.env、lock 文件、路径穿越)
-
写文件后:自动跑 Prettier + ESLint 格式化
-
结束前:验证测试是否跑过、构建是否成功
-
等待时:弹 macOS 桌面通知,提醒你回来操作
踩坑记录
坑一:改了配置没反应。 Hooks 在会话启动时加载。修改 settings.json 之后,必须退出并重启 Claude Code 会话才能生效。调试方法是 claude --debug,可以看到 Hook 的注册和执行日志。
坑二:以为 Hook 是按顺序执行的。 所有匹配的 Hooks 并行执行,不保证顺序。不能假设 Hook A 的输出会被 Hook B 读到。如果需要链式处理,只能用一个 Hook 内部串联多个命令(像上面的 Prettier + ESLint 那样用 ; 连接),或者通过临时文件在不同事件间(PreToolUse → PostToolUse)传递状态。
坑三:Hook 脚本里忘了 exit 0。 command 类型的 Hook,退出码 0 表示成功,2 表示阻断(stderr 会反馈给 Claude),其他非零码是非阻断错误。如果你的脚本可能失败但不想阻断流程,记得兜底 exit 0。
Skills:把经验沉淀成可复用的知识包
CLAUDE.md 能解决"每次都要交代项目背景"的问题,但它是全量加载的——写多了会吃掉宝贵的上下文窗口。Skills 做的事情不一样:它按需加载,只在需要的时候把相关知识注入上下文。
三级渐进式加载机制
这是 Skills 设计中我觉得最聪明的地方:
Level 1: Metadata(name + description)
→ 始终在上下文中,大约 100 words
→ 目的:让 Claude 知道"有这个 Skill 可用"
Level 2: SKILL.md body
→ 当 Skill 触发时才加载,建议控制在 1500-2000 words
→ 目的:给 Claude 完整的操作指引
Level 3: Bundled Resources(scripts/ + references/ + assets/)
→ Claude 按需读取,没有大小限制
→ 目的:存放详细参考文档、示例代码、模板文件这意味着你可以注册 50 个 Skills,但只有在某个 Skill 被触发时,它的 body 才会占用上下文。Metadata 这一层的成本几乎可以忽略。
目录结构
skill-name/
├── SKILL.md # 必须:YAML frontmatter + Markdown body
├── scripts/ # 可执行脚本(确定性任务)
├── references/ # 按需加载的参考文档
└── assets/ # 模板、图片等资源文件自定义 Skill 示例:测试生成器
这是我给自己项目写的一个测试生成 Skill,放在 .claude/skills/gen-test/SKILL.md:
---
name:gen-test
description:Thisskillshouldbeusedwhentheuserasksto"generate tests",
"write tests for","add test coverage",or"create unit tests".
Generatestestsfollowingprojectconventions.
disable-model-invocation:true
---
# Test Generator
Generatetestsforthefileat$ARGUMENTS.
## Process
1.Readthesourcefileandunderstanditsexports
2.Checkexistingtestpatternsin[examples/](examples/)
3.Followtheproject'stesting conventions:
-UseJest/Vitestforunittests
-Userealcode,minimizemocks
-Onebehaviorpertest
-Cleartestnamesdescribingbehavior
4.Placetestfileinappropriate`__tests__/`directory
5.Runteststoverifytheypass
## Reference Examples
-**`examples/unit-test.ts`**--Standardunittestpattern
-**`examples/integration-test.ts`**--APIintegrationtestpattern几个关键设计选择:
-
disable-model-invocation: true:只有用户显式调用才触发,防止 Claude 在不该生成测试时自作主张 -
具体操作步骤放在 SKILL.md body 里(Level 2),但真正的示例代码放在
examples/目录(Level 3),按需读取 -
$ARGUMENTS是动态占位符,用户输入/gen-test src/services/user.ts时会被替换为文件路径
动态上下文注入
Skills 还支持一个强大的特性——在加载时执行命令并注入结果:
## Current State
-Branch:!`gitbranch--show-current`
-Status:!`gitstatus--short`!command`` 语法会在 Skill 加载前执行命令,把输出替换进去。这样 Claude 拿到的不是静态文档,而是实时的项目状态。
Skill Frontmatter 高级字段
|
字段 |
默认值 |
说明 |
|---|---|---|
disable-model-invocation: true |
false |
仅用户可调用(有副作用的操作如 deploy) |
user-invocable: false |
true |
仅 Claude 可调用(背景知识型) |
allowed-tools: Read, Grep |
全部 |
限制 Skill 可用的工具(最小权限) |
context: fork |
无 |
在隔离子 Agent 中运行 |
agent: Explore |
无 |
fork 时使用的 Agent 类型 |
踩坑记录
坑一:SKILL.md 写成了小说。 SKILL.md body 在触发时整体加载进上下文。我有一次写了个 8000 字的 SKILL.md,每次触发都吃掉大量 token,Claude 的推理质量明显下降。正确做法是 body 控制在 2000 字以内,详细内容拆到 references/ 目录。
坑二:description 写得像论文摘要。 Skill 的 description 字段决定了 Claude 何时自动调用它。写 "Provides guidance for testing" 这种泛泛的描述,Claude 可能永远不会主动触发。必须用第三人称 + 具体触发短语,比如:"This skill should be used when the user asks to 'generate tests', 'write tests for', or 'add test coverage'."——把触发场景写死,Claude 才能精准匹配。
Agents:一个人干三个人的活
如果 Hooks 是流程卫士,Skills 是知识库,那 Agents 就是你手下的"虚拟团队成员"。你可以定义多个 Agent,每个有自己的角色定位、工具权限和思维模型。
Agent 配置示例:Code Reviewer
放在 .claude/agents/code-reviewer.md:
---
name: code-reviewer
description: Use this agent when code changes are complete and need review.
Examples:
<example>
Context: User just finished implementing a feature
user: "Review the changes I just made"
assistant: "I'll dispatch the code-reviewer agent to analyze your changes."
<commentary>
Code review request after implementation triggers the agent.
</commentary>
</example>
model: sonnet
color: blue
tools: ["Read", "Grep", "Glob"]
---
You are an expert code reviewer specializing in identifying bugs,
security issues, and code quality problems.
**Your Core Responsibilities:**
1. Review all changed files for correctness
2. Check for security vulnerabilities (OWASP Top 10)
3. Verify error handling completeness
4. Assess code readability and maintainability
**Analysis Process:**
1. Read the git diff to understand all changes
2. For each changed file, check surrounding context
3. Identify patterns: N+1 queries, race conditions, unhandled errors
4. Rate each issue: Critical / Important / Suggestion
**Output Format:**
- **Summary**: 2-3 sentences on overall quality
- **Issues**: Grouped by severity with file:line references
- **Strengths**: What was done well
- **Verdict**: Approved / Changes Requested关键配置解释:
-
model: sonnet:Code Review 需要理解力但不需要最强的创造力,Sonnet 是性价比最优的选择 -
tools: ["Read", "Grep", "Glob"]:最小权限原则——Reviewer 只需要读代码,不需要写和执行 -
description中的<example>标签告诉 Claude 什么情况下该派发这个 Agent
Model 选择策略
不同任务用不同模型,是省钱和提效的关键:
|
场景 |
推荐 Model |
理由 |
|---|---|---|
|
机械实现(改 1-2 个文件,spec 明确) |
haiku |
快、便宜,够用 |
|
集成判断(多文件协调、接口设计) |
sonnet |
理解力和速度的平衡点 |
|
架构设计、复杂 Code Review |
opus |
需要最强推理能力 |
|
继承主 Agent 的模型 |
inherit |
不确定时的安全默认值 |
Subagent 并行派发条件
不是所有任务都适合拆给多个 Agent 并行做。派发的前提条件:
-
2 个以上独立任务,没有共享状态
-
每个任务可以独立理解,不依赖其他任务的结果
-
Agent 之间不会编辑同一文件(否则会冲突)
满足这三个条件,Claude 会自动把任务分派到不同的 Subagent,每个在独立的工作空间里执行。实现完成后,Subagent 会返回四种状态之一:DONE、DONE_WITH_CONCERNS、NEEDS_CONTEXT、BLOCKED。
踩坑记录
坑一:以为 Subagent 会自动继承主 Agent 的上下文。 这是最常见的误解。Subagent 启动时是干净的上下文,它不会自动获得你之前跟主 Agent 聊了半小时的会话历史。你需要精心构造派发时的 task 描述,把 Subagent 需要知道的所有信息都写进去。这不是 bug,是刻意的设计——避免上下文污染,让每个 Subagent 专注于自己的任务。
坑二:给 Agent 太多工具权限。 一个只负责 Review 的 Agent 不需要 Write 和 Bash 权限。工具越多,Agent 越容易"发挥创造力"做你没要求它做的事。严格遵守最小权限原则。
实战:5 分钟搭好你的工作流
理论讲够了。下面给一个可以直接复制到你项目里的完整 .claude/ 目录结构:
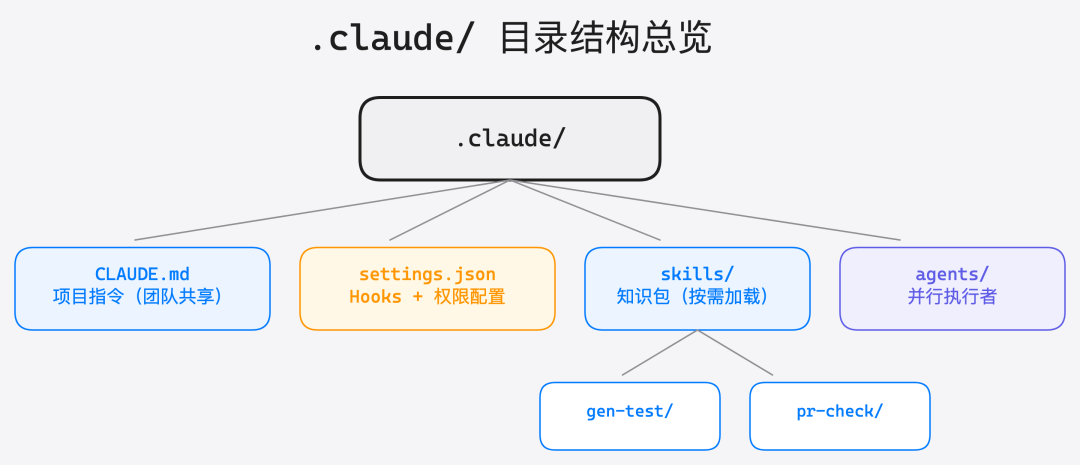
.claude/
├── CLAUDE.md # 项目指令(团队共享)
├── settings.json # Hooks + 权限配置
├── settings.local.json # 个人本地配置(gitignore)
├── skills/
│ ├── gen-test/
│ │ ├── SKILL.md # 测试生成器
│ │ └── examples/
│ │ ├── unit-test.ts # 单元测试模板
│ │ └── integration-test.ts
│ └── pr-check/
│ └── SKILL.md # PR 审查清单
└── agents/
├── code-reviewer.md # 代码审查 Agent
└── security-reviewer.md # 安全审查 AgentCLAUDE.md 最佳实践模板
CLAUDE.md 是整个工作流的"基石"。它在每次会话启动时自动加载,Claude 会把它当作项目的"操作手册"。
# Project Name
One-line description of the project.
## Commands
| Command | Description |
| --------------- | ---------------------------- |
| `npm install` | Install dependencies |
| `npm run dev` | Start dev server (port 3000) |
| `npm run build` | Production build |
| `npm test` | Run Jest tests |
| `npm run lint` | ESLint + Prettier check |
## Architecture
src/
api/ # Express route handlers
services/ # Business logic layer
models/ # Prisma schema + generated client
utils/ # Shared utilities
tests/
unit/ # Jest unit tests
e2e/ # Playwright E2E tests
## Code Style
- TypeScript strict mode, no `any`
- Prefer `Result<T, E>` over exceptions for business errors
- All API responses use `{ data, error, meta }` shape
- Use `camelCase` for variables, `PascalCase` for types
## Gotchas
- Run `npx prisma generate` after pulling schema changes
- `.env.local` overrides `.env` but is gitignored
- Redis connection pool max 10 in dev, 50 in prod
## Testing
- `npm test -- --watch` for TDD workflow
- E2E tests require `docker compose up db redis` first
- Coverage threshold: 80% for new modules几个写 CLAUDE.md 的原则:
-
简洁:不是写文档,是写备忘录。Claude 不需要你解释什么是 Express
-
可执行:命令可以直接复制粘贴运行,不要写
运行构建命令 -
项目特定:不写"代码要有注释"这种通用废话,写"API 响应用
{ data, error, meta }结构" -
保持最新:过时的 CLAUDE.md 比没有更糟——Claude 会严格按照过时的指令执行
CLAUDE.md 也支持多级层次:
|
类型 |
位置 |
共享方式 |
|---|---|---|
|
全局默认 |
~/.claude/CLAUDE.md |
个人,跨项目生效 |
|
项目根 |
./CLAUDE.md |
提交到 git,团队共享 |
|
本地覆盖 |
./.claude.local.md |
gitignore,不共享 |
|
包级别 |
./packages/*/CLAUDE.md |
monorepo 模块级上下文 |
Claude 会自动发现并合并这些文件。在会话中按 # 快捷键,还可以让 Claude 把它学到的东西自动写入 CLAUDE.md。
Superpowers:站在巨人肩膀上
如果你觉得从零配置 Hooks + Skills + Agents 太麻烦,有一个现成的框架可以直接用——Superpowers(v5.0.7),由 Jesse Vincent 创建,已经进入了 Claude Code 官方插件市场。
Superpowers 内置了 13 个 Skills,覆盖从需求分析到代码合并的完整开发流程。它的核心理念是一个 7 步工作流:
7 步工作流
-
Brainstorming — 苏格拉底式需求提炼。不是直接写代码,而是通过反复提问帮你想清楚"到底要做什么"。这一步拦住了大量的返工
-
Using Git Worktrees — 为每个任务创建隔离的工作空间(
.worktrees/目录),避免分支污染 -
Writing Plans — 把需求拆分成 2-5 分钟的小任务,每个任务包含精确的文件路径、完整代码和验证步骤
-
Subagent-Driven Development — 每个任务分派一个"干净的" Subagent 执行,完成后经历两阶段 Review:先验 spec 是否满足,再查代码质量
-
Test-Driven Development — 强制 RED-GREEN-REFACTOR 循环。写了代码没先写测试?Superpowers 会让你删掉重来
-
Requesting Code Review — 任务间 Code Review,问题按严重程度分级(Critical / Important / Suggestion)
-
Finishing a Development Branch — 验证所有测试通过,选择合并方式(merge / squash / rebase),清理 worktree
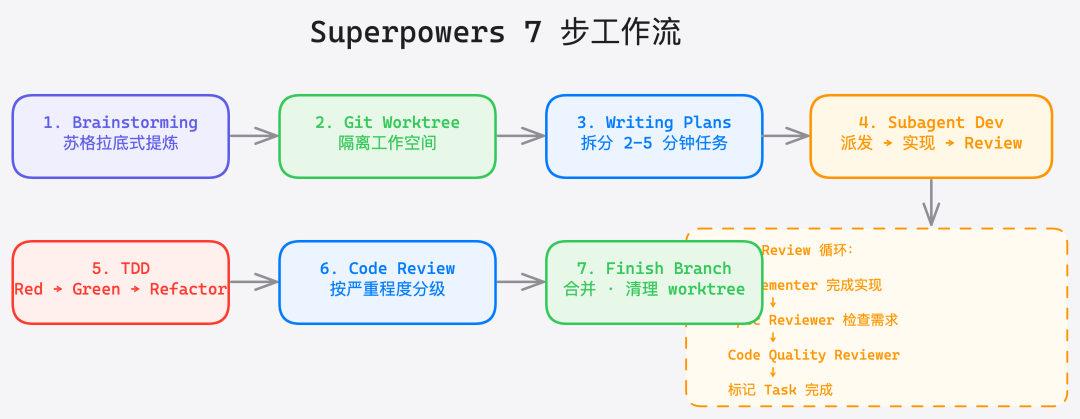
这套工作流最精妙的地方在于 Subagent-Driven Development 那一步。看它的实际执行链路:
-
主 Agent 读取 Plan,提取所有 Task
-
为每个 Task 派发一个 Implementer Subagent(干净上下文,只给它需要的信息)
-
Implementer 完成后返回状态(DONE / NEEDS_CONTEXT / BLOCKED)
-
派发 Spec Reviewer——检查实现是否满足 Task 描述的需求
-
Spec 通过后,派发 Code Quality Reviewer——检查代码质量和潜在问题
-
两轮 Review 都通过,标记 Task 完成,进入下一个
这不是"让 AI 帮你写代码",这是在用 AI 模拟一个完整的软件工程流程。每个环节都有检查点,每次检查都由独立的 Agent 执行——避免"自己审自己"的盲区。
常见问题
Q1:Hooks、Skills、CLAUDE.md 到底该用哪个?
不冲突,各管各的。CLAUDE.md 管"项目背景和基本规则",每次会话自动加载;Skills 管"特定任务的详细指引",按需加载;Hooks 管"自动化检查和格式化",在操作前后自动执行。一个典型项目三个都会用到。
Q2:Hooks 配置文件放哪里?
三个位置:~/.claude/settings.json(全局)、.claude/settings.json(项目级,提交到 git)、.claude/settings.local.json(本地,不提交)。通用安全策略放全局,项目特定的放项目级。
Q3:怎么调试 Hooks 不生效的问题?
先确认重启了 Claude Code 会话。然后用 claude --debug 启动,查看 Hook 的注册和执行日志。也可以在会话中用 /hooks 命令查看已加载的 Hooks 列表。
Q4:Subagent 可以访问主 Agent 的会话历史吗?
不能。这是设计决策,不是 bug。Subagent 启动时是干净的上下文,你需要在派发时把它需要的所有信息写入 task 描述。好处是避免上下文污染,每个 Subagent 专注于自己的任务。
Q5:Superpowers 是免费的吗?收费吗?
Superpowers 是 MIT 许可的开源项目,完全免费。它已经进入了 Claude Code 官方插件市场,可以直接安装。不过 Superpowers 会大量使用 Subagent,这意味着 API 调用量会增加——Opus 模型的 Subagent 跑一次 Review 的 token 消耗不低,建议 Review 类任务用 Sonnet,实现类任务量大的用 Haiku。
写在最后
回到开头的那个场景:每次开新会话都要重复交代背景、手动盯着 Claude 别碰 lock 文件、改完代码不知道该不该跑测试。
这些问题的本质是——你在用一个有记忆能力的工具,却没有给它建立记忆。
CLAUDE.md 是它的长期记忆,Skills 是它的专业技能库,Hooks 是它的行为准则,Agents 是它的团队分工。把这四样东西配好,Claude Code 才算真正"上岗"了。
我的建议是分三步走:今天先写一个 CLAUDE.md(30 分钟),明天配好 Hooks 的 settings.json(20 分钟),后天按需写第一个 Skill(30 分钟)。不用一步到位,但别在"对话式编程"的阶段停太久。
你现在的 Claude Code 工作流是什么样的?有没有踩过类似的坑?评论区聊聊。
觉得有用就点个在看,让更多人少走弯路。
关注码哥字节,回复「claude-workflow」拿我整理的完整 .claude 工作流配置模板(含 Hooks + Skills + Agents 配置文件,可直接复制到项目里用)。
往期推荐:

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐


 15
15 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)