
收藏必看|2026 版大模型 Function Calling 详解,小白也能吃透 AI Agent 核心原理
Function Calling 的本质:LLM 只输出 JSON 描述"该调哪个工具、传什么参数",执行权在你手里完整调用循环:用户提问 → LLM 决策 → 执行工具 → 结果回传 → LLM 再决策,直到 finish_reason 为 stopLangChain 的价值:用bind_toolsBaseTool统一了各厂商差异,ToolNode 把执行循环封装干净ToolMessage 对应
本文 2026 全新升级深度拆解 LLM工具调用 Function Calling核心机制,带你搞懂大模型如何通过结构化 JSON 完成功能参数定义,真实代码落地执行全流程一目了然。全文从 OpenAI 原生协议、多轮对话调用循环,到 LangChain 工具封装、BaseTool 实战用法全覆盖,新增 2026 工程落地必备的 ToolMessage 消息解析、并行工具调用实战、高频踩坑避坑指南以及工具安全边界设计规范。掌握 Function Calling,是零基础小白、在职程序员入门搭建高性能 AI Agent 的必经之路。
1、 新手必懂:Function Calling 核心本质到底是什么
很多人把 Function Calling 理解成"LLM 帮你调函数",这个理解是错的。
LLM 没有执行权限,它不会真的去调用任何函数。它做的事情只有一件:输出一段结构化 JSON,告诉你"我想调用哪个函数、传什么参数"。
真正执行函数的,是你的代码。
用户提问
│
▼
┌─────────────────────────────────────┐
│ LLM(只做文本预测) │
│ │
│ 输入:用户问题 + 工具描述(JSON Schema)│
│ │
│ 输出:{ │
│ "tool_name": "search_web", │
│ "arguments": { │
│ "query": "今天上海天气" │
│ } │
│ } │
└─────────────────────────────────────┘
│
▼ ← 你的代码负责执行
┌─────────────┐
│ search_web │ ← 真实函数,调真实 API
└─────────────┘
│
▼
工具返回结果,再喂给 LLM
│
▼
LLM 生成最终自然语言回复
这里有一个关键认知:LLM 能输出结构化 JSON,是因为它被训练成了这样。OpenAI 在 GPT-3.5/4 的 fine-tune 阶段专门加入了 Function Calling 的训练数据,让模型学会"识别何时该调工具、该传什么参数"。
2、 OpenAI Function Calling 的原始协议长什么样
在 LangChain 包装之前,我们先看原始 API 长什么样。理解了底层,才能明白 LangChain 帮你省了多少事。
定义工具(JSON Schema 格式):
const tools = [
{
type: "function",
function: {
name: "get_weather",
description: "获取指定城市的当前天气",
parameters: {
type: "object",
properties: {
city: {
type: "string",
description: "城市名称,例如:北京、上海"
},
unit: {
type: "string",
enum: ["celsius", "fahrenheit"],
description: "温度单位"
}
},
required: ["city"]
}
}
}
];
发送请求:
const response = await openai.chat.completions.create({
model: "gpt-4",
messages: [{ role: "user", content: "上海今天多少度?" }],
tools: tools,
tool_choice: "auto" // auto | none | {type: "function", function: {name: "..."}}
});
LLM 返回的内容(不是普通文本!):
{
finish_reason: "tool_calls", // ← 注意这个字段
message: {
role: "assistant",
content: null,
tool_calls: [
{
id: "call_abc123",
type: "function",
function: {
name: "get_weather",
arguments: '{"city": "上海", "unit": "celsius"}'
// ↑ 注意:arguments 是字符串,不是对象!需要 JSON.parse
}
}
]
}
}
这里有几个坑:
finish_reason是"tool_calls"而不是"stop",你需要判断这个arguments是字符串,不是对象,需要手动JSON.parse()- LLM 可能一次返回多个 tool_calls(并行调用)
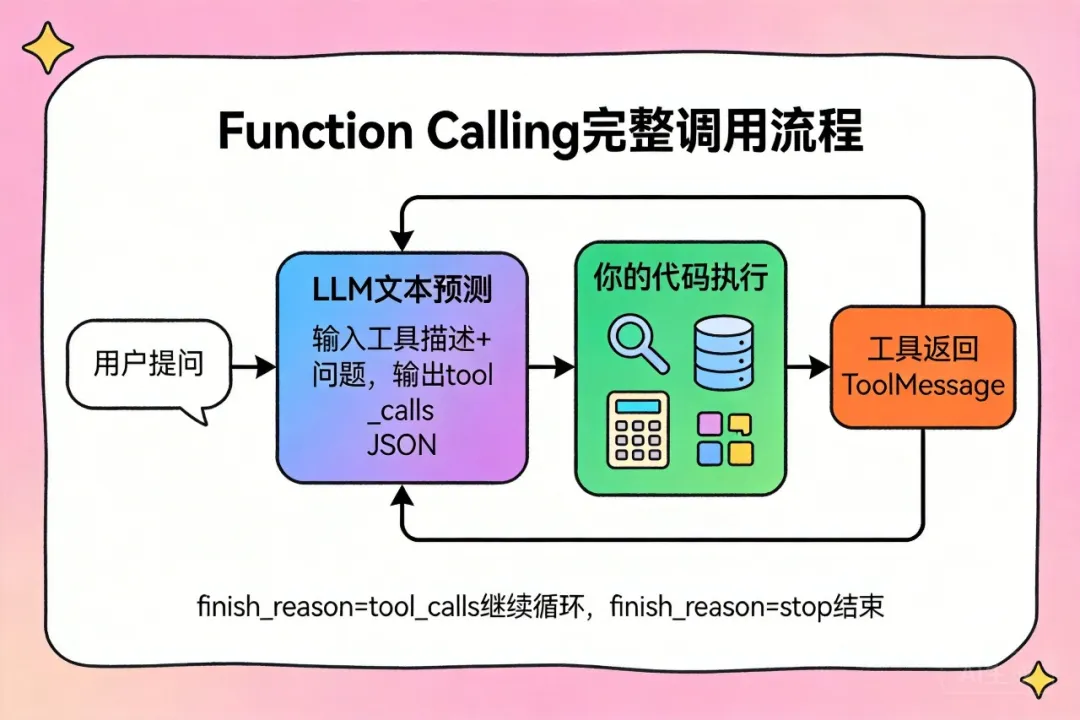
3、 完整工具调用循环:多轮对话机制
单次工具调用只是开始。真实场景里,一次用户请求可能需要多次工具调用才能完成。这就是为什么叫"循环(Loop)"。
┌─────────────────────────────────────────────────┐
│ 工具调用完整循环 │
│ │
│ ┌─────────┐ │
│ │ 用户提问 │ │
│ └────┬────┘ │
│ │ │
│ ▼ │
│ ┌──────────────────────────────┐ │
│ │ LLM 决策 │ │
│ │ finish_reason = "tool_calls"│ │
│ └──────────┬───────────────────┘ │
│ │ │
│ ┌─────▼─────┐ │
│ │ 执行工具 │ ← 你的代码 │
│ └─────┬─────┘ │
│ │ ToolMessage │
│ │ │
│ ┌─────▼───────────┐ │
│ │ 把结果加入消息历史 │ │
│ └─────┬───────────┘ │
│ │ │
│ ┌─────▼──────────────────────────┐ │
│ │ LLM 再次决策 │ │
│ │ finish_reason = "stop" → 结束 │ │
│ │ finish_reason = "tool_calls" │ │
│ │ → 继续循环 │ │
│ └────────────────────────────────┘ │
└─────────────────────────────────────────────────┘
手动实现这个循环(原始 OpenAI SDK):
import OpenAI from "openai";
const openai = new OpenAI();
async function runToolLoop(userMessage: string) {
const messages: OpenAI.Chat.ChatCompletionMessageParam[] = [
{ role: "user", content: userMessage }
];
while (true) {
const response = await openai.chat.completions.create({
model: "gpt-4",
messages,
tools,
tool_choice: "auto"
});
const choice = response.choices[0];
messages.push(choice.message); // 把 AI 回复加入历史
// 如果不需要调用工具,循环结束
if (choice.finish_reason === "stop") {
return choice.message.content;
}
// 执行所有工具调用
for (const toolCall of choice.message.tool_calls ?? []) {
const args = JSON.parse(toolCall.function.arguments);
const result = await executeToolCall(toolCall.function.name, args);
// 把工具结果加入消息历史
messages.push({
role: "tool",
tool_call_id: toolCall.id, // ← 必须对应,LLM 靠这个 id 区分多个工具调用
content: JSON.stringify(result)
});
}
}
}
这段代码每次都要手写。LangChain 把这个循环封装掉了。
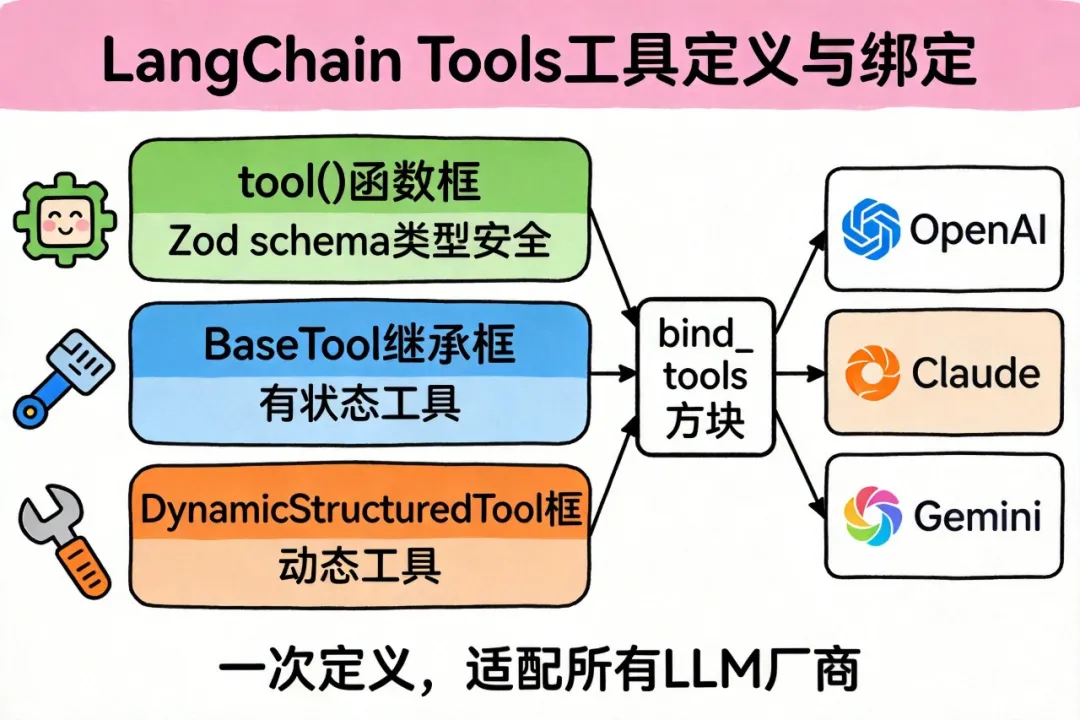
4 、LangChain 的工具链设计:bind_tools 做了什么
LangChain 的核心抽象是:统一不同 LLM 厂商的工具调用接口。
OpenAI、Claude、Gemini、百川——每家的 Function Calling 格式都不一样。LangChain 用 BaseTool 和 bind_tools 做了标准化。
┌──────────────────────────────────────────────────┐
│ LangChain 工具抽象层 │
│ │
│ ┌─────────────┐ ┌──────────────────────────┐ │
│ │ BaseTool │ │ bind_tools(tools) │ │
│ │ │ │ │ │
│ │ .name │───▶│ 自动转换为各厂商格式: │ │
│ │ .description│ │ - OpenAI: tools[] │ │
│ │ .schema │ │ - Claude: tools[] │ │
│ │ ._call() │ │ - Gemini: functionDecl │ │
│ └─────────────┘ └──────────────────────────┘ │
│ │
│ 你只写一次工具定义,适配所有 LLM │
└──────────────────────────────────────────────────┘
三种定义工具的方式:
import { tool } from "@langchain/core/tools";
import { z } from "zod";
import { ChatOpenAI } from "@langchain/openai";
// 方式1:用 tool() 函数(最推荐,类型安全)
const getWeather = tool(
async ({ city, unit = "celsius" }) => {
// 真实实现
const temp = await fetchWeatherAPI(city);
return `${city}当前温度:${temp}°${unit === "celsius" ? "C" : "F"}`;
},
{
name: "get_weather",
description: "获取指定城市的当前天气",
schema: z.object({
city: z.string().describe("城市名称"),
unit: z.enum(["celsius", "fahrenheit"]).optional().describe("温度单位")
})
}
);
// 方式2:继承 BaseTool(适合复杂工具,有状态)
import { BaseTool, ToolParams } from "@langchain/core/tools";
class DatabaseQueryTool extends BaseTool {
name = "query_database";
description = "查询数据库中的用户信息";
constructor(private db: DatabaseConnection) {
super();
}
async _call(input: string): Promise<string> {
const result = await this.db.query(input);
return JSON.stringify(result);
}
}
// 方式3:DynamicStructuredTool(Zod schema + 动态)
import { DynamicStructuredTool } from "@langchain/core/tools";
const searchTool = new DynamicStructuredTool({
name: "search_web",
description: "搜索网页内容",
schema: z.object({
query: z.string(),
maxResults: z.number().optional().default(5)
}),
func: async ({ query, maxResults }) => {
return await webSearch(query, maxResults);
}
});
bind_tools 绑定工具:
const model = new ChatOpenAI({ model: "gpt-4o" });
const tools = [getWeather, searchTool];
// 绑定工具到模型
const modelWithTools = model.bindTools(tools);
// 调用时,LLM 会自动决定是否要调工具
const result = await modelWithTools.invoke("上海今天多少度?");
// result 可能是:
// 1. AIMessage with tool_calls → LLM 决定要调工具
// 2. AIMessage with content → LLM 直接回答
console.log(result.tool_calls);
// [{ name: "get_weather", args: { city: "上海" }, id: "call_xxx" }]
5 、ToolMessage 消息结构:工具结果如何回传 LLM
工具执行完之后,结果怎么传回 LLM?这里有个容易踩的坑:消息类型是 ToolMessage,不是 HumanMessage。
消息历史的完整结构:
HumanMessage: "上海今天多少度?"
↓
AIMessage: content=null, tool_calls=[{id:"call_1", name:"get_weather", args:{city:"上海"}}]
↓
ToolMessage: content="上海当前温度:22°C", tool_call_id="call_1"
↓
AIMessage: content="上海今天22度,比较舒适,适合户外活动。"
用 ToolNode 自动执行工具(LangGraph 的正确打开方式):
import { ToolNode } from "@langchain/langgraph/prebuilt";
import { HumanMessage } from "@langchain/core/messages";
// ToolNode:接收包含 tool_calls 的 AIMessage,自动执行并返回 ToolMessage
const toolNode = new ToolNode(tools);
// 模拟 LLM 输出了一个 tool_calls
const aiMessage = new AIMessage({
content: "",
tool_calls: [
{
id: "call_001",
name: "get_weather",
args: { city: "上海", unit: "celsius" },
type: "tool_call"
}
]
});
// ToolNode 自动执行并返回 ToolMessage
const toolResult = await toolNode.invoke({ messages: [aiMessage] });
// { messages: [ToolMessage { content: "上海当前温度:22°C", tool_call_id: "call_001" }] }
并行工具调用(Parallel Tool Calls):
// LLM 可能一次返回多个 tool_calls
const aiMessage = new AIMessage({
content: "",
tool_calls: [
{ id: "call_001", name: "get_weather", args: { city: "上海" } },
{ id: "call_002", name: "get_weather", args: { city: "北京" } },
{ id: "call_003", name: "search_web", args: { query: "今日股市行情" } }
]
});
// ToolNode 会并行执行这三个工具
// 返回三条 ToolMessage,分别对应三个 tool_call_id
6 、在 LangGraph 中组装完整工具调用 Agent
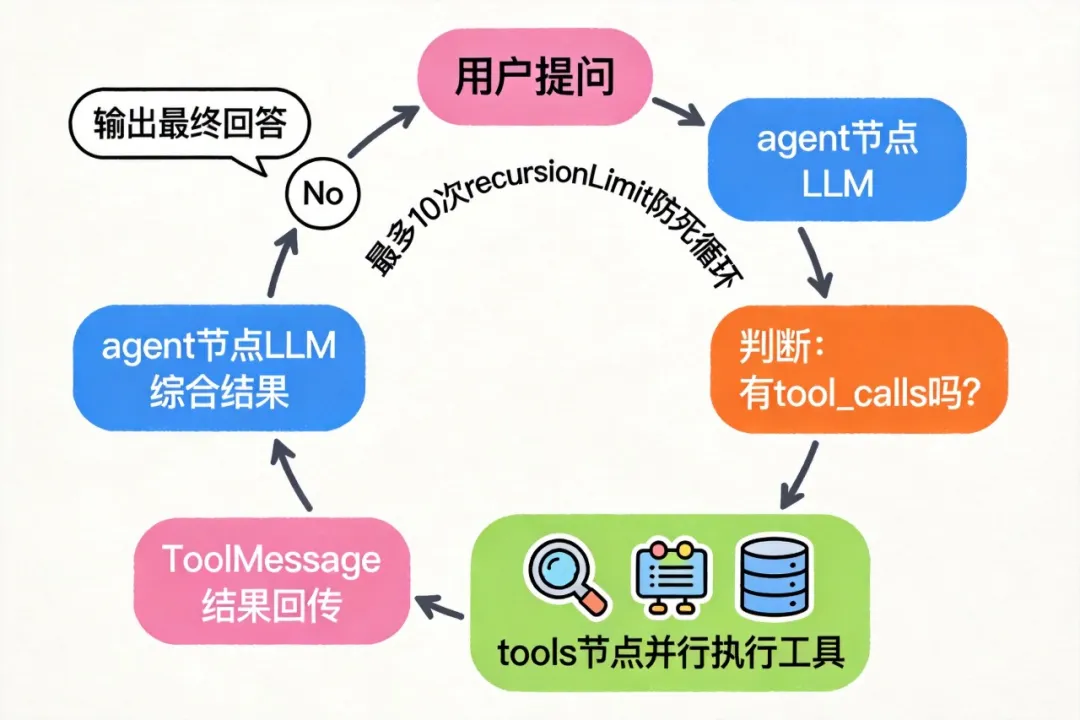
把前面所有东西组合起来,搭一个完整的 ReAct Agent:
importStateGraphMessagesAnnotationfrom"@langchain/langgraph"importToolNodefrom"@langchain/langgraph/prebuilt"importChatOpenAIfrom"@langchain/openai"importfrom"@langchain/core/tools"importfrom"zod"importAIMessagefrom"@langchain/core/messages"// 定义工具consttoolasynctry// 简单计算器(生产环境用更安全的方式)constFunction`"use strict"; return (${expression})`return`计算结果:${result}`catchreturn"计算失败,请检查表达式格式"name"calculator"description"执行数学计算,支持加减乘除和括号"schemaobjectexpressionstringdescribe"数学表达式,例如:(3+5)*2"consttoolasync// 实际实现调用搜索 APIreturn`搜索结果:关于"${query}"的最新信息...`name"search"description"搜索最新信息"schemaobjectquerystringdescribe"搜索关键词"constconstnewToolNode// LLM 绑定工具constnewChatOpenAImodel"gpt-4o"temperature0constbindTools// 判断是否需要继续调用工具functionshouldContinuestate: typeof MessagesAnnotation.Stateconstmessagesmessageslength1asAIMessageiftool_callstool_callslength0return"tools"// 有 tool_calls → 去执行工具return"__end__"// 没有 tool_calls → 结束// 调用 LLM 节点asyncfunctioncallModelstate: typeof MessagesAnnotation.Stateconstawaitinvokemessagesreturnmessages// 构建 GraphconstnewStateGraphMessagesAnnotationaddNode"agent"addNode"tools"addEdge"__start__""agent"addConditionalEdges"agent"addEdge"tools""agent"// 工具执行完 → 回到 agentcompile// 运行constawaitinvokemessagesrole"user"content"帮我查一下今日 GPT-4o 的最新进展,然后算一下 (125 * 8 + 32) / 4 等于多少"consolelogmessagesmessageslength1content
整个执行流程:
用户提问(两个需求:搜索 + 计算)
↓
agent 节点:LLM 分析,输出两个 tool_calls(并行)
↓
tools 节点:并行执行 search + calculator
↓
返回两条 ToolMessage 到 agent
↓
agent 节点:LLM 综合工具结果,生成最终回答
↓
结束(finish_reason = stop)
7、 工具调用常见坑与最佳实践
坑1:工具描述写得太短
// ❌ 差的描述consttoolname"query_db"description"查数据库"schemaobjectsqlstring// ✅ 好的描述——告诉 LLM 什么时候用、用来干什么consttoolname"query_database"description`查询用户数据库。 适用场景:需要查找用户信息、订单记录、消费历史时。 输入 SQL 查询语句(只支持 SELECT,不支持修改操作)。 返回 JSON 格式的查询结果,最多返回 100 条记录。`schemaobjectsqlstringdescribe"SQL SELECT 语句,例如:SELECT * FROM users WHERE id = 123"
坑2:忘记处理工具执行失败
consttoolasynctryconstawaitriskyOperationreturnJSONstringifycatch// ⚠️ 工具报错了,别直接 throw!// LLM 会收到 ToolMessage,需要能读懂这个错误return`工具执行失败:${error.message}。请尝试修改参数后重试。`name"..."description"..."schemaobject
坑3:tool_choice 设置不当
// 强制调用某个工具(适合测试)constbindToolstool_choicetype"function"functionname"get_weather"// 完全禁用工具调用constbindToolstool_choice"none"// 自动判断(生产环境推荐)constbindToolstool_choice"auto"// 默认值
坑4:并行工具调用时 tool_call_id 对不上
// ✅ ToolMessage 必须设置正确的 tool_call_id// 否则 LLM 不知道哪个结果对应哪个工具调用forconstoftool_callsconstawaitexecuteToolpushnewToolMessagecontenttool_call_idid// ← 必须和 AIMessage.tool_calls[i].id 对应
8 、工具安全边界:别让 LLM 干坏事
工具调用是双刃剑。LLM 能帮你查数据库、也能帮你删数据库。工具设计必须有安全边界。
安全工具设计原则:
┌────────────────────────────────────────────────┐
│ 原则1:最小权限 │
│ - 只暴露必要的操作,SELECT 而非全 SQL │
│ - 读写分离,危险操作单独工具并加二次确认 │
│ │
│ 原则2:参数校验(在工具内,不依赖 LLM) │
│ - 用 Zod 做 schema 校验 │
│ - 业务规则在函数内部验证,不在 description 里约定│
│ │
│ 原则3:限制工具调用深度 │
│ - 设置最大循环次数(recursionLimit) │
│ - 避免无限循环调用 │
│ │
│ 原则4:审计日志 │
│ - 记录每次工具调用的参数和结果 │
│ - 异常调用告警 │
└────────────────────────────────────────────────┘
// LangGraph 限制最大循环次数constcompileconstawaitinvokemessagesrole"user"content"..."recursionLimit10// 最多循环 10 次,防止死循环
总结
这篇我们从底层到工程,完整拆解了 Function Calling 与 LangChain 工具链:
- Function Calling 的本质:LLM 只输出 JSON 描述"该调哪个工具、传什么参数",执行权在你手里
- 完整调用循环:用户提问 → LLM 决策 → 执行工具 → 结果回传 → LLM 再决策,直到 finish_reason 为 stop
- LangChain 的价值:用
bind_tools+BaseTool统一了各厂商差异,ToolNode 把执行循环封装干净 - ToolMessage 对应关系:tool_call_id 是关键,确保工具结果和调用请求一一对应
- 安全边界:工具要遵循最小权限原则,参数校验在代码里做,不靠 description 约束 LLM
最后
对于正在迷茫择业、想转行提升,或是刚入门的程序员、编程小白来说,有一个问题几乎人人都在问:未来10年,什么领域的职业发展潜力最大?
答案只有一个:人工智能(尤其是大模型方向)
当下,人工智能行业正处于爆发式增长期,其中大模型相关岗位更是供不应求,薪资待遇直接拉满——字节跳动作为AI领域的头部玩家,给硕士毕业的优质AI人才(含大模型相关方向)开出的月基础工资高达5万—6万元;即便是非“人才计划”的普通应聘者,月基础工资也能稳定在4万元左右。
再看阿里、腾讯两大互联网大厂,非“人才计划”的AI相关岗位应聘者,月基础工资也约有3万元,远超其他行业同资历岗位的薪资水平,对于程序员、小白来说,无疑是绝佳的转型和提升赛道。
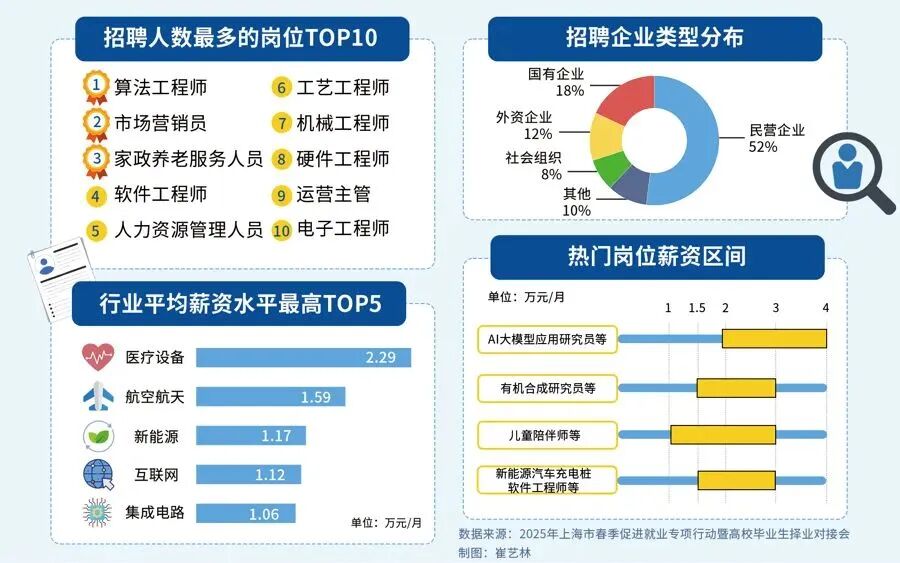
对于想入局大模型、抢占未来10年行业红利的程序员和小白来说,现在正是最好的学习时机:行业缺口大、大厂需求旺、薪资天花板高,只要找准学习方向,稳步提升技能,就能轻松摆脱“低薪困境”,抓住AI时代的职业机遇。
如果你还不知道从何开始,我自己整理一套全网最全最细的大模型零基础教程,我也是一路自学走过来的,很清楚小白前期学习的痛楚,你要是没有方向还没有好的资源,根本学不到东西!
下面是我整理的大模型学习资源,希望能帮到你。
👇👇扫码免费领取全部内容👇👇
1、大模型学习路线

2、从0到进阶大模型学习视频教程
从入门到进阶这里都有,跟着老师学习事半功倍。

3、 入门必看大模型学习书籍&文档.pdf(书面上的技术书籍确实太多了,这些是我精选出来的,还有很多不在图里)

4、 AI大模型最新行业报告
2026最新行业报告,针对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5、面试试题/经验

【大厂 AI 岗位面经分享(107 道)】

【AI 大模型面试真题(102 道)】

【LLMs 面试真题(97 道)】

6、大模型项目实战&配套源码

适用人群

四阶段学习规划(共90天,可落地执行)
第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
-
硬件选型
-
带你了解全球大模型
-
使用国产大模型服务
-
搭建 OpenAI 代理
-
热身:基于阿里云 PAI 部署 Stable Diffusion
-
在本地计算机运行大模型
-
大模型的私有化部署
-
基于 vLLM 部署大模型
-
案例:如何优雅地在阿里云私有部署开源大模型
-
部署一套开源 LLM 项目
-
内容安全
-
互联网信息服务算法备案
-
…
👇👇扫码免费领取全部内容👇👇
3、这些资料真的有用吗?
这份资料由我和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐



 1
1 0
0- 0



 已为社区贡献48条内容
已为社区贡献48条内容

所有评论(0)