
当 AI 研究员学会了“搜索“,搜索引擎该怎么配合?——深度研究中的文本排序再审视
这篇论文系统比较了不同检索方法在AI深度研究任务中的表现。研究发现,传统的BM25算法在段落级检索中显著优于神经网络方法,但在文档级检索中表现较差。实验使用了5种检索器和3种重排序器,在固定语料库上测试了两个AI Agent的搜索性能。关键发现包括:段落级检索整体优于文档级检索;BM25的表现差异源于文档长度归一化问题;AI Agent的查询风格(含精确匹配和布尔运算)与人类不同,导致神经检索模型
当 AI 研究员学会了"搜索",搜索引擎该怎么配合?——深度研究中的文本排序再审视
论文:Revisiting Text Ranking in Deep Research
作者:Chuan Meng, Litu Ou, Sean MacAvaney, Jeff Dalton
机构:The University of Edinburgh, University of Glasgow
日期:2026年2月
链接:https://arxiv.org/abs/2602.21456
🎯 一句话总结
这篇论文拆开了"深度研究"(Deep Research)任务中搜索引擎的黑盒子,系统地比较了5种检索器、3种重排序器在文档级和段落级语料上的表现,发现了一个反直觉的结论:古老的 BM25 在段落级检索上居然吊打了一众神经网络检索器,而背后的原因竟然是 AI Agent 发出的查询长得太像"网页搜索"了。
📖 为什么需要这篇论文?
想象一下,你给 ChatGPT 布置了一个复杂的调研任务:「帮我查查2025年全球半导体产业的并购趋势,要有具体案例和数据」。ChatGPT Deep Research 模式会怎么做?它会像一个真人研究员一样,反复搜索、阅读网页、提炼信息,最终给你一份完整的报告。
这个过程里,"搜索"是核心动作。每一次搜索的质量直接决定了 Agent 能不能找到关键证据。但问题来了——目前几乎所有的 Deep Research 系统都依赖黑盒的网络搜索 API(比如 Google Search API、Bing API),研究者根本看不到搜索引擎内部在做什么。这就好比你雇了一个研究助理,他每次去图书馆查资料,但你完全不知道他是怎么检索的、用了什么索引策略、翻了哪些书架。
这篇来自爱丁堡大学和格拉斯哥大学的论文,做了一件很朴素但很重要的事:把黑盒打开,用一个固定的文档语料库(10万篇文档),系统地测试各种经典和前沿的检索方法在深度研究任务中到底表现如何。
他们测了 BM25(1994年的经典算法)、SPLADE-v3(学习稀疏检索)、RepLLaMA(基于 LLaMA 的密集检索)、Qwen3-Embed-8B(千问嵌入模型)和 ColBERTv2(多向量后交互模型),搭配 monoT5、RankLLaMA、Rank1 三种重排序器,在两个不同的 Agent 上跑了大量实验。这种规模的系统对比,在深度研究领域还是头一次。
🧠 核心问题:Agent 搜索和人搜索,有什么不一样?
在展开实验结果之前,得先理解这篇论文抓住的一个关键洞察:AI Agent 发出的搜索查询和人类用户的查询,风格上差异巨大。
人类在搜索引擎里输入的往往是自然语言问题,比如「什么是量子计算」。但 AI Agent 不一样——它们发出的查询更像一个老练的搜索引擎用户,会使用精确匹配引号、布尔运算符、关键词堆叠这些"高级搜索语法"。举个例子:
- 人类查询:
quantum computing applications in drug discovery - Agent 查询:
"quantum computing" "drug discovery" 2025 breakthrough application
这带来了一个严重的训练-推理不匹配(train-inference mismatch)问题。大多数神经检索模型是在 MS MARCO 之类的数据集上训练的,那些训练数据里的查询都是自然语言风格。当你突然丢给它一个满是引号和关键词的 Agent 查询时,模型可能会懵——就像一个英语考试训练出来的翻译,突然让他翻译编程术语一样。
🏗️ 实验设计:怎么做的?
数据集:BrowseComp-Plus
论文使用的是 BrowseComp-Plus 数据集,这是在 OpenAI 的 BrowseComp 基础上扩展而来的一个深度研究基准。它包含:
- 830 个查询:每个都是需要深入研究才能回答的复杂问题
- 100,195 篇文档:固定语料库(不是开放网络),方便做可控实验
- 约 277 万个段落:将文档切分成段落后得到的段落级语料
- 人工标注的相关性判断:知道每个查询的正确答案在哪
用固定语料库而不是开放网络,是这篇论文的一个聪明选择。开放网络实验里,你没法控制搜索引擎返回了什么——今天搜到的结果明天可能就变了。固定语料库保证了实验的可复现性和公平性。
检索器
论文测试了 5 种检索器,覆盖了信息检索领域的主要技术路线:
| 检索器 | 类型 | 核心思路 |
|---|---|---|
| BM25 | 词汇匹配 | 基于词频和文档长度的经典统计方法,1994年提出,至今仍是很多系统的基线 |
| SPLADE-v3 | 学习稀疏 | 用 BERT 学习每个词的重要性权重,生成稀疏向量,可以用倒排索引加速 |
| RepLLaMA | 单向量密集 | 基于 LLaMA 的双编码器,把查询和文档各编码成一个向量,算余弦相似度 |
| Qwen3-Embed-8B | 单向量密集 | 千问团队的 8B 参数嵌入模型,同样是双编码器架构 |
| ColBERTv2 | 多向量后交互 | 每个 token 都有一个向量,查询和文档之间做 token 级的 MaxSim 交互 |
如果用找餐厅来类比:BM25 就像按菜名精确搜——你搜"宫保鸡丁",它就找包含这四个字的餐厅;RepLLaMA 更像按"口味偏好"搜——它理解你想吃辣的、有花生的鸡肉菜,但可能漏掉那些菜名里没明确写"辣"的餐厅;ColBERTv2 则是把你的每个偏好词都单独去匹配菜单上的每道菜,综合打分。
重排序器
| 重排序器 | 类型 | 特点 |
|---|---|---|
| monoT5-3B | 非推理型 | 基于 T5 的 pointwise 重排序,直接预测相关性分数 |
| RankLLaMA-7B | 非推理型 LLM | 基于 LLaMA 的 pointwise 重排序 |
| Rank1-7B | 推理型 | 基于 CoT(思维链)的重排序器,会"想一想"再打分 |
两个 Agent
- gpt-oss-20b:上下文窗口 131k tokens
- GLM-4.7-Flash(30B):上下文窗口 200k tokens
两个 Agent 在检索时都能用 Search 工具(输入查询,返回 top-5 段落/文档摘要),段落模式下直接返回段落内容,文档模式下返回文档前 512 个 token。文档模式还可以选择性地配备 GetDoc 工具来读取完整文档。
🧪 实验结果:BM25 的逆袭
段落级 vs. 文档级:段落碾压
先看最核心的对比——用 gpt-oss-20b Agent,不同检索器在段落语料和文档语料上的表现:
Table 3:gpt-oss-20b Agent 在不同检索器下的表现
| 检索器 | 段落语料 Recall / Acc | 文档语料 Recall / Acc | 文档+GetDoc Recall / Acc |
|---|---|---|---|
| BM25 | 0.616 / 0.572 | 0.366 / 0.259 | 0.343 / 0.301 |
| SPLADE-v3 | 0.545 / 0.516 | 0.628 / 0.476 | 0.602 / 0.529 |
| RepLLaMA | 0.449 / 0.406 | 0.514 / 0.363 | 0.476 / 0.399 |
| Qwen3-Embed-8B | 0.470 / 0.417 | 0.570 / 0.421 | 0.559 / 0.455 |
| ColBERTv2 | 0.552 / 0.521 | 0.633 / 0.481 | 0.612 / 0.538 |
这张表里有几个很有意思的发现:
BM25 的"两面性":在段落语料上,BM25 以 0.572 的准确率遥遥领先,比第二名 ColBERTv2(0.521)高了 5 个百分点。但切到文档语料,BM25 直接崩盘——0.259 的准确率垫底,被 ColBERTv2(0.481)甩了 20 多个点。这个反差太戏剧性了。
为什么会这样?论文给出了一个很精准的诊断:文档长度归一化。BM25 公式里有个 bbb 参数控制文档长度的惩罚力度。文档语料里文档长短差异巨大,默认参数(k1=0.9, b=0.4)归一化力度不够,长文档会"淹没"真正相关的短文档。段落语料里段落长度相对均匀,这个问题就不存在了。
段落级检索全面优于文档级:对 BM25 来说这个优势是碾压级的(Acc: 0.572 vs 0.259)。即便给文档模式加上 GetDoc 全文阅读工具,效果也没好多少(0.301),因为检索阶段已经错过了关键文档。对其他检索器,段落级也基本持平或略优。
换用 GLM-4.7-Flash Agent,趋势一致:
Table 4:GLM-4.7-Flash Agent 在不同检索器下的表现
| 检索器 | 段落 Recall / Acc | 文档 Recall / Acc | 文档+GetDoc Recall / Acc |
|---|---|---|---|
| BM25 | 0.581 / 0.445 | 0.309 / 0.196 | 0.282 / 0.263 |
| SPLADE-v3 | 0.578 / 0.466 | 0.639 / 0.448 | 0.597 / 0.525 |
| RepLLaMA | 0.456 / 0.331 | 0.493 / 0.330 | 0.471 / 0.407 |
| Qwen3-Embed-8B | 0.482 / 0.357 | 0.580 / 0.374 | 0.482 / 0.456 |
| ColBERTv2 | 0.571 / 0.464 | 0.640 / 0.430 | 0.595 / 0.535 |
另一个有趣的现象是,GLM-4.7-Flash 的搜索调用次数远高于 gpt-oss-20b(约 70 次 vs 30 次),说明这个模型在深度研究中需要更多轮搜索才能聚合够信息。但无论哪个 Agent,BM25 在文档语料上的灾难性表现和在段落语料上的强势表现是一致的。
BM25 参数调优:老方法也需要新参数
既然 BM25 在文档语料上崩是因为参数问题,那调参能救吗?论文做了细致的网格搜索:
Table 7:BM25 不同参数设置下的表现(gpt-oss-20b, 文档语料)
| BM25 参数 | 索引方式 | Recall | Acc |
|---|---|---|---|
| k1=0.9, b=0.4(默认) | 全文档 | 0.366 | 0.259 |
| k1=0.9, b=0.4 | 截断512 token | 0.642 | 0.513 |
| k1=3.8, b=0.87(MS MARCO) | 全文档 | 0.601 | 0.443 |
| k1=10, b=1(网格搜索最优) | 全文档 | 0.647 | 0.506 |
这组数据太说明问题了。默认参数下 BM25 在文档语料上 Recall 只有 0.366,但把文档截断到 512 个 token 后直接飙到 0.642——几乎翻倍!这证明了问题确实出在长文档归一化上。而通过网格搜索找到的最优参数(k1=10, b=1,即完全按文档长度归一化)也能达到 0.647 的 Recall。
下面四张图是论文中 BM25 参数网格搜索的热力图,直观展示了 k1 和 b 参数对检索效果的影响:
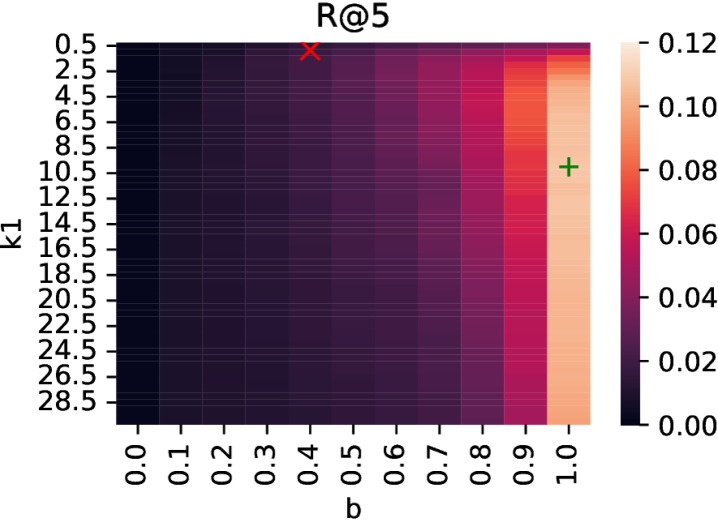
图1:BM25 在文档语料上的 R@5 热力图。横轴是 b 参数(控制长度归一化力度),纵轴是 k1 参数(控制词频饱和度)。颜色越深效果越好。可以看到右上角(高 k1、高 b)区域效果最好,而左下角(低 k1、低 b,即默认参数区域)效果最差。
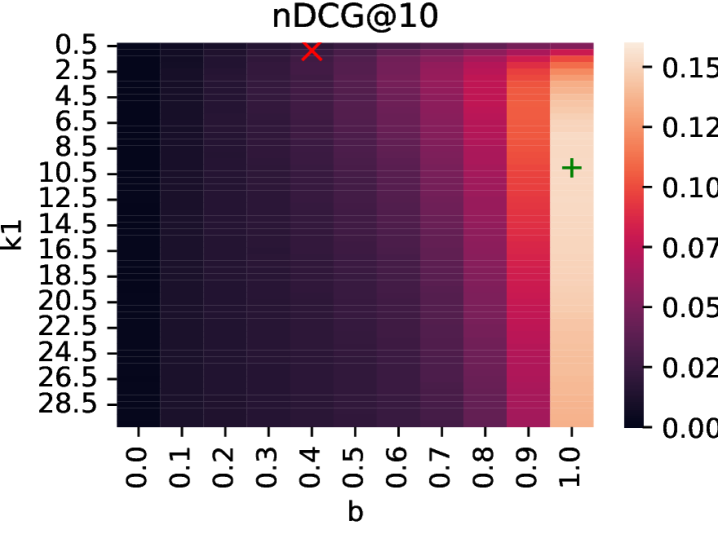
图2:BM25 在文档语料上的 nDCG@10 热力图。趋势与 R@5 一致——长度归一化越强(b 越大),效果越好。
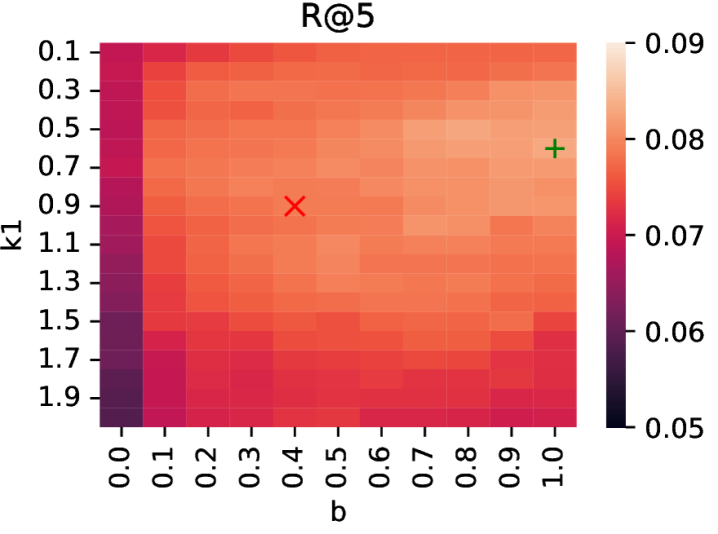
图3:BM25 在段落语料上的 R@5 热力图。和文档语料形成鲜明对比——颜色分布更均匀,说明 BM25 对参数不那么敏感了。段落长度差异小,归一化参数影响不大。
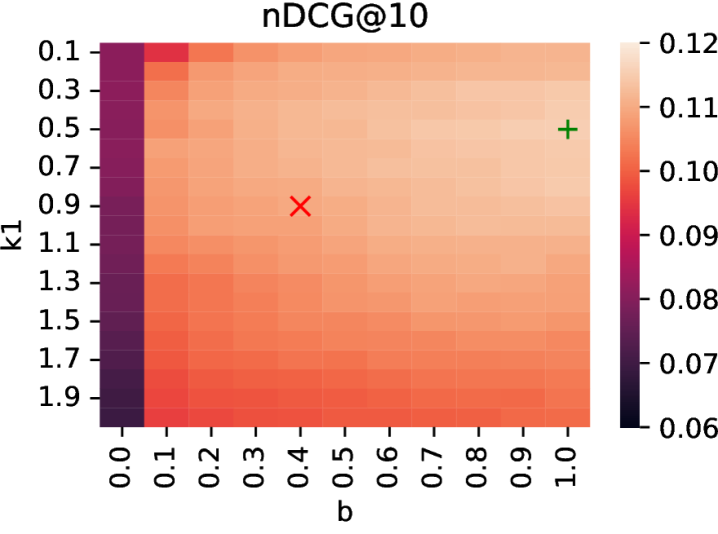
图4:BM25 在段落语料上的 nDCG@10 热力图。同样地,参数敏感度远低于文档级。这解释了为什么 BM25 在段落检索上"开箱即用"就很强。
这四张热力图讲了一个完整的故事:在文档级检索中,BM25 的参数选择至关重要,默认参数会导致灾难性失败;而在段落级检索中,由于段落长度相对均匀,BM25 对参数不敏感,默认设置就能跑出很好的效果。 这也从另一个角度解释了为什么段落级检索更适合深度研究——它降低了对检索器调优的依赖。
🔧 重排序:稳赚不赔的优化
检索器负责从上百万条候选中快速筛出 top-N,重排序器则负责对这 top-N 做精细排序。论文测了三种重排序器在不同检索器上的效果:
Table 8:gpt-oss-20b 在段落语料上不同排序管线的表现(部分)
| 重排序器 | BM25 Recall / Acc | SPLADE-v3 Recall / Acc | Qwen3-Embed Recall / Acc |
|---|---|---|---|
| 无重排序 | 0.616 / 0.572 | 0.545 / 0.516 | 0.470 / 0.417 |
| monoT5 (d=10) | 0.660 / 0.631 | 0.630 / 0.599 | 0.524 / 0.471 |
| monoT5 (d=50) | 0.716 / 0.689 | 0.689 / 0.646 | 0.614 / 0.559 |
| RankLLaMA (d=10) | 0.657 / 0.617 | 0.632 / 0.595 | 0.508 / 0.465 |
| RankLLaMA (d=50) | 0.710 / 0.678 | 0.691 / 0.663 | 0.613 / 0.568 |
| Rank1 (d=10) | 0.662 / 0.628 | 0.617 / 0.580 | 0.530 / 0.454 |
| Rank1 (d=50) | 0.712 / 0.687 | 0.702 / 0.643 | 0.630 / 0.564 |
几个清晰的结论:
1. 重排序是"稳赚不赔"的操作。 无论用哪个检索器,加上重排序后 Recall 和 Accuracy 都有明显提升。BM25 + monoT5 (d=50) 组合把准确率从 0.572 提到了 0.689,涨了 11.7 个百分点。对本来就不太强的 Qwen3-Embed-8B,monoT5 (d=50) 也把准确率从 0.417 拉到了 0.559,涨了 14.2 个点。
2. 重排序深度越深越好。 d=50 几乎在所有组合上都优于 d=20 和 d=10。这很好理解——给重排序器看更多候选,它能找到更多"被检索器排低但实际相关"的结果。代价是计算量增加,但对离线研究任务来说可以接受。
3. 推理型重排序器没有明显优势。 这个结论可能出乎很多人的意料。Rank1 作为一个基于思维链推理的重排序器,理论上应该"想得更深"。但实验中它和 monoT5、RankLLaMA 基本打平,甚至在某些设置下略弱。论文分析原因是 Agent 查询里充斥着引号和关键词,Rank1 的推理过程有时候反而会被这些格式干扰——就像让一个善于深度思考的人去做快速匹配任务,深度思考的优势反而发挥不出来。
GLM-4.7-Flash 上的结果也验证了这些趋势:
Table 9:GLM-4.7-Flash 在段落语料上的部分结果
| 检索器 | 重排序器 | Recall | Acc |
|---|---|---|---|
| BM25 | 无重排序 | 0.581 | 0.445 |
| BM25 | monoT5 (d=50) | 0.696 | 0.586 |
| BM25 | RankLLaMA (d=50) | 0.707 | 0.576 |
| SPLADE-v3 | 无重排序 | 0.578 | 0.466 |
| SPLADE-v3 | monoT5 (d=50) | 0.693 | 0.575 |
| SPLADE-v3 | RankLLaMA (d=50) | 0.695 | 0.543 |
重排序带来的 Recall 提升约 10-12 个百分点,Acc 提升约 10-14 个百分点,趋势非常稳定。
🔬 Q2Q:给 Agent 查询做"翻译"
论文最有趣的贡献之一是 Q2Q(Query-to-Question) 方法。思路非常直觉——既然 Agent 发出的查询是"网页搜索风格"的,而神经检索器是在"自然语言问题"上训练的,那为何不在中间加一个翻译层,把 Agent 查询转换成自然语言问题?
Q2Q 有两个变体:
- Q2Q (Q):只用原始查询来生成问题
- Q2Q (Q+R):用查询加上 Agent 的推理轨迹来生成问题
这就像是给一个外国客户配了一个翻译:Q2Q (Q) 是只翻译客户说的话,Q2Q (Q+R) 是翻译的时候还参考了会议上下文,翻译得更准确。
Table 11:Q2Q 对不同检索器的影响(gpt-oss-20b, 段落语料)
| 检索器 | 查询方式 | Recall | Acc |
|---|---|---|---|
| BM25 | 原始查询 | 0.616 | 0.572 |
| BM25 | Q2Q (Q) | 0.593 | 0.578 |
| BM25 | Q2Q (Q+R) | 0.583 | 0.557 |
| SPLADE-v3 | 原始查询 | 0.545 | 0.516 |
| SPLADE-v3 | Q2Q (Q) | 0.550 | 0.510 |
| SPLADE-v3 | Q2Q (Q+R) | 0.585* | 0.557* |
| Qwen3-Embed-8B | 原始查询 | 0.470 | 0.417 |
| Qwen3-Embed-8B | Q2Q (Q) | 0.457 | 0.404 |
| Qwen3-Embed-8B | Q2Q (Q+R) | 0.507* | 0.459* |
带 * 号表示统计显著(paired t-test, p<0.05)
这组结果非常有意思:
Q2Q (Q+R) 对神经检索器有显著提升。SPLADE-v3 的 Accuracy 从 0.516 涨到 0.557(+4.1个点),Qwen3-Embed-8B 从 0.417 涨到 0.459(+4.2个点),而且都达到了统计显著。推理轨迹提供了额外的上下文,让 LLM 能生成更精准的自然语言问题。
但 Q2Q 对 BM25 反而有害。BM25 的 Recall 从 0.616 降到了 0.583。这完全可以理解——BM25 靠的就是精确的关键词匹配,Agent 查询里的引号和精确关键词恰好是 BM25 的"母语"。把这些翻译成自然语言问题,反而丢失了 BM25 最擅长利用的信号。
Q2Q 还能和重排序叠加:
Table 13:Q2Q + Rank1 重排序的叠加效果(SPLADE-v3, d=10)
| 重排序器 | 查询方式 | Recall | Acc |
|---|---|---|---|
| Rank1 (d=10) | 原始查询 | 0.617 | 0.580 |
| Rank1 (d=10) | Q2Q (Q+R) | 0.638* | 0.613* |
Q2Q (Q+R) 让 Rank1 的 Accuracy 从 0.580 涨到了 0.613,说明查询翻译对重排序器同样有效。有意思的是,Rank1 作为推理型重排序器,在原始查询上没什么优势,但配合 Q2Q 翻译后的查询,推理能力似乎能更好地发挥——因为输入变成了它训练时见过的自然语言问题形式。
📊 综合分析:什么组合最优?
把所有结果综合来看,最佳实践的画面变得很清晰:
| 场景 | 推荐配置 | 理由 |
|---|---|---|
| 资源有限,追求简单 | BM25 + 段落级检索 | 开箱即用效果好,不需要 GPU |
| 追求最佳效果 | BM25 + monoT5/RankLLaMA (d=50) + 段落级 | 重排序带来稳定提升 |
| 神经检索器场景 | SPLADE-v3/ColBERTv2 + Q2Q (Q+R) + Rank1 | Q2Q 弥补查询不匹配 |
| 只能用文档级语料 | 调优 BM25 参数 (k1=10, b=1) 或用 SPLADE-v3/ColBERTv2 | 避免默认 BM25 参数的坑 |
一个比较反直觉的结论是:在深度研究这个场景下,BM25 + 段落级检索的"穷人方案"可以打败很多昂贵的神经检索器方案。 0.572 的准确率已经超过了文档级 ColBERTv2 + GetDoc 的 0.538。不需要 GPU,不需要向量索引,只要把文档切成段落丢进倒排索引就行。
当然,加上重排序后差距会缩小——BM25 + monoT5 (d=50) 的 0.689 比 ColBERTv2 + monoT5 (d=50) 的大约 0.66-0.68 也只是略优。但考虑到 BM25 的部署成本几乎为零,这个性价比确实惊人。
💡 我的思考和启发
1. BM25 为什么在这个场景下这么强?
表面原因是 Agent 查询的"网页搜索风格"恰好契合了 BM25 的精确匹配能力。但深层原因我认为是:深度研究中 Agent 的查询质量本身就很高。Agent 已经经过推理,知道自己要找什么,发出的查询非常精准。在查询质量高的情况下,精确匹配本身就是一种非常有效的策略——你已经知道了目标文档里有哪些关键词,何必再费劲去做语义理解?
这让我想到一个更广泛的问题:在 AI Agent 时代,信息检索的范式可能需要重新思考。 传统 IR 假设用户的查询是模糊的、不完整的,所以需要语义理解来"猜"用户想要什么。但 Agent 的查询恰恰相反——它们精准、具体、目标明确。这种情况下,精确匹配可能比语义匹配更可靠。
2. 段落级检索的工程启示
论文的结果强烈暗示了一条工程路径:对于 Deep Research 系统,应该优先考虑段落级索引。 原因有三:
- 避免了文档长度归一化的困难
- 段落本身就是信息的自然单元,直接塞进 Agent 的上下文窗口效率更高
- 对检索器参数不敏感,鲁棒性更强
实际工程中,这意味着你可以用一个简单的固定长度滑动窗口把文档切成段落,然后直接上 BM25。这比部署一个 8B 参数的嵌入模型要便宜太多了。
3. Q2Q 的潜力和局限
Q2Q 这个想法很优雅,但有一个明显的局限:它需要一个额外的 LLM 调用来做查询翻译。 在 Agent 已经在迭代搜索的场景下,每次搜索多一个 LLM 调用意味着延迟翻倍。而且 Q2Q (Q+R) 需要用到推理轨迹,这意味着翻译模型需要理解 Agent 的内部状态。
我觉得更实际的做法可能是:直接在 Agent 的提示词里引导它生成自然语言风格的查询,而不是事后翻译。不过这需要平衡——如果 Agent 查询变成纯自然语言,BM25 的优势就没了。也许最好的方案是让 Agent 同时生成两种风格的查询,分别送给不同类型的检索器。
4. 推理型重排序器的"尴尬"
Rank1 作为推理型重排序器,在这个实验中并没有展现出优势。这让我重新审视了"推理型 IR"这个方向。推理需要时间和计算,在延迟敏感的搜索场景下这是个硬伤。更关键的是,如果输入查询本身就和训练分布不匹配(充斥着引号和关键词),再多的推理也只是在错误的输入上做文章。
这给"推理型 X"这个大方向提了个醒:不是所有任务都需要推理,有时候快速精确的模式匹配比深度思考更有效。
🔗 写在后面
这篇论文做了一件看似"复古"但实则很有价值的工作:在 Deep Research 这个新兴场景下,重新审视了 IR 领域积累了几十年的知识。结果发现,很多经典的 wisdom 依然成立(重排序有效、段落级优于文档级),但也有一些新的发现(Agent 查询风格对检索器选择的影响、Q2Q 的有效性)。
对于正在构建 Deep Research 系统的团队来说,这篇论文的实用价值很高:别急着上最贵的神经检索器,先试试 BM25 + 段落级检索 + monoT5 重排序。这可能就是你需要的 80/20 方案。
论文的一个遗憾是只在固定语料库上做了实验,没有测试开放网络场景。作者在结尾也承认了这一点,并将其作为未来工作。另外,实验只用了两个 Agent,不同 Agent 的查询风格差异可能会影响结论的泛化性。这些都是后续研究可以补充的方向。
不管怎样,在 LLM 时代,"搜索"这个看似古老的问题正在以新的面貌回归。理解检索器在 Agent 场景下的行为特性,可能比训练一个更大的 LLM 更具投入产出比——毕竟,Agent 的推理能力再强,如果搜不到关键证据,也是巧妇难为无米之炊。
论文信息
- 标题:Revisiting Text Ranking in Deep Research
- 作者:Chuan Meng, Litu Ou, Sean MacAvaney, Jeff Dalton
- 机构:The University of Edinburgh, University of Glasgow
- 链接:https://arxiv.org/abs/2602.21456
- 日期:2026年2月

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐


 18
18 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)