
从 Prompt 魔法到系统工程:Claude Code 的 9 大致命误区与生产级 Agentic 系统构建指南
《ClaudeCode系统化设计指南:破解高成本低效困境》摘要 当前开发者普遍陷入Claude使用误区:Token成本高、输出不稳定、维护性差。本文揭示9大典型错误,包括单线程任务混用、重复Prompt编写、无结构化思考框架等,这些问题源于将Claude当作普通聊天工具的错误认知。解决方案在于构建包含9大模块的Agentic系统:通过Subagents隔离任务、Commands复用指令、Skill
在 Claude Code 快速普及的今天,无数开发者都陷入了同一个困境:明明 Claude 的模型能力足够强大,却越用越贵、越写越乱 ——Token 成本居高不下,输出质量忽高忽低,调试修改没完没了,代码的可维护性越来越差。
但绝大多数人都找错了问题的根源:Claude Code 的高成本、低效率,从来不是模型本身的问题,而是你的使用方式出了错。那些上下文管理、结构设计、工作流搭建中的微小错误,会随着使用快速复利放大,最终让你的 Claude 使用陷入 “高成本、低质量、不可控” 的死循环。
本文将拆解 9 个正在悄悄消耗你时间、金钱与 Token 的 Claude 使用误区,并基于完整的系统设计蓝图,详解从单条 Prompt 到生产级 Agentic 系统的 Claude Code 最佳实践,核心只有一句话:不要把 Claude 当 ChatGPT 用,要像设计系统一样设计它。
一、9 个 Claude Code 的致命误区:你的成本浪费,都源于糟糕的系统设计
绝大多数开发者使用 Claude 的方式,本质上是 “ChatGPT 式的对话思维”:把所有需求、规范、上下文都塞进一个超大的 Prompt 里,在同一个线程里反复修改调试,靠临时的指令约束模型行为。这种方式在简单的代码生成场景中勉强可用,但在复杂的工程化开发中,必然会陷入 9 个典型的误区,每一个都在持续消耗你的资源。
1. 单线程运行所有任务:无隔离带来的上下文灾难
这是最基础也最致命的错误:把所有的需求、代码、调试、修改都放在同一个对话线程中执行,没有任何任务隔离。随着对话轮次增加,上下文会变得越来越混乱,旧的错误代码、无关的调试信息、过期的需求会持续堆积,成为干扰模型的噪声,最终导致输出质量持续下降,同时 Token 消耗呈指数级增长。
Claude 的核心设计逻辑之一,就是支持子任务的隔离执行。无隔离的单线程模式,完全违背了这一设计初衷,让模型在越来越杂乱的上下文中,逐渐失去精准的推理与生成能力。
2. 反复重写相同的 Prompt:重复劳动的无效内耗
几乎所有开发者都踩过这个坑:每次生成代码,都要把代码规范、格式要求、检查规则、输出标准重新写一遍。比如每次都要在 Prompt 里加上 “遵循 PEP8 规范”、“添加完整的单元测试”、“代码要包含详细注释” 这类重复内容。
这种做法不仅浪费大量的开发时间,还会带来两个致命问题:一是重复的内容会持续消耗不必要的 Token,推高使用成本;二是每次的 Prompt 措辞难免有差异,会导致模型的输出标准忽高忽低,一致性极差。所有重复出现的 Prompt 内容,都应该被封装成可复用的 Command,而不是每次重写。
3. 不用 Skills 做结构化思考:让模型每次都从零 “猜答案”
很多开发者给 Claude 提需求时,永远只说一句 “帮我写一个 XX 功能的代码”,让模型每次都从零开始思考实现逻辑、技术选型、步骤流程、最佳实践。这种做法,本质上是把所有的思考压力都丢给模型,不仅会大幅提升代码出错的概率,还会让模型在每一次生成中都消耗大量 Token 在基础的逻辑推理上。
Skills 的核心价值,就是把经过验证的结构化思考流程、领域知识、固定工作流沉淀下来。比如 “RESTful 接口开发标准流程”、“Python 代码安全评审检查清单”、“前端组件封装最佳实践”,这些固定的思考框架,完全可以封装成 Skill,让模型每次都按照标准化的流程执行,既保证了输出的质量与一致性,又大幅降低了无效的 Token 消耗。
4. 用无关信息过载上下文:更多 Token≠更好的结果
这是最常见的认知误区:很多人觉得,把所有相关的、不相关的文档、代码、历史记录、需求文档都塞进上下文里,模型就能生成更完美的结果。但事实恰恰相反,更小的上下文 = 更高的准确率。
无关的信息会成为上下文里的噪声,稀释核心需求,让模型更容易出现幻觉,甚至会忽略关键的指令要求。同时,过载的上下文还会直接推高 Token 成本,让每一次调用都变得极其昂贵。正确的做法,是只给模型注入当前任务必须的上下文信息,彻底剔除所有无关内容。
5. 把内存当成垃圾文件夹:只存临时噪声,不存长期真理
很多开发者对 Claude 的内存管理毫无概念,把所有的对话历史、临时调试信息、中间执行结果、过期的需求都一股脑塞进内存里,让内存变成了一个杂乱的垃圾文件夹。最终的结果是,内存里充满了无效的噪声,模型每次调用内存都会拿到无关的信息,不仅输出准确率大幅下降,还会让长期上下文变得完全不可控。
内存的核心设计原则,是只存储长期有效的 “真理”,绝对不存放临时的噪声。你需要严格区分临时的会话上下文与长期内存:临时的中间结果、调试信息只放在当前会话中,任务结束就清理;只有系统规则、架构设计、核心规范、经过验证的长期有效信息,才有资格被放入长期内存中。
6. 没有标准化的工作流:把工程流程变成临时的 Prompt 游戏
代码调试、评审、单元测试生成、文档编写,这些软件工程中的固定流程,在很多开发者手里,都变成了每次临时写 Prompt 的随机游戏。比如每次代码写完,都临时写一句 “帮我 review 一下这段代码”,没有固定的评审标准,没有统一的检查项,每次的输出结果完全不可控。
这种做法,完全抛弃了软件工程的标准化原则,不仅效率极低,还无法沉淀任何最佳实践。调试、评审、文档这些重复的工程流程,应该被封装成标准化的 Workflow,一次设计,每次都按照完全相同的标准执行,既保证了质量,又实现了能力的持续沉淀。
7. 忽略 MCP 集成:把 Claude 困在对话里,限制了 90% 的能力
如果 Claude 无法访问真实的工具、数据与运行环境,你就直接限制了它 90% 的能力。很多开发者至今依然把 Claude 当成一个纯对话里的代码生成器:生成代码后自己复制到编辑器里运行,手动查数据库,手动调 API,手动处理运行结果。
MCP(Model Context Protocol)是 Claude 接入真实世界的核心桥梁,它可以让 Claude 直接对接外部的 API、数据库、代码仓库、开发工具链,实时获取真实的业务数据,直接在你的环境中执行代码与操作。这不仅能省去大量的人工复制粘贴工作,更能让模型的生成基于真实的环境与数据,从根源上降低幻觉,让 Claude 真正融入你的开发工作流,实现端到端的自动化。
8. 没有护栏与钩子:把校验与安全检查变成手动的重复劳动
代码 lint 检查、安全漏洞扫描、合规校验、权限控制,这些代码生成中的必备环节,很多开发者依然在手动执行。不仅浪费大量时间,还极易出现遗漏,最终把有问题的代码带到生产环境中。
Hooks(钩子)与 Guardrails(护栏),是 Claude 为工程化设计的核心能力。它可以实现事件驱动的自动化检查:代码生成后自动触发 lint 检查与安全扫描,调用外部工具前自动触发权限校验,内容输出前自动触发合规与敏感信息检查。所有的校验规则都被封装成自动化的钩子,不需要人工干预,也不需要每次在 Prompt 里重复书写,从源头避免错误与安全风险。
9. 没有迭代循环:失去了对输出的完全控制权
很多开发者用 Claude 写代码,就是一轮一轮的口头修改,改坏了就找不到之前的稳定版本,没有回溯能力,也没有办法沉淀优化经验,整个开发过程完全失控。这就是典型的 “无迭代循环” 开发模式,最终只会陷入 “越改越乱,越写越差” 的死循环。
一个可控的迭代系统,必须包含完整的Build→Review→Checkpoint→Rewind闭环:每次代码修改都建立检查点,保留稳定的版本;如果修改出现问题,可以随时回退到之前的检查点;每次评审的结果,都沉淀到对应的 Command 与 Skill 中,让整个系统持续优化。只有建立了完整的迭代循环,你才能真正掌控 Claude 的输出,而不是被模型牵着走。
说到底,Claude Code 的真正成本,从来不是 Token 的费用。真正的成本,是糟糕的系统设计带来的效率损失、质量风险、维护成本与不可控的迭代过程。而解决这些问题的核心,就是跳出单条 Prompt 的思维,用系统工程的思路,构建一套完整的 Claude Agentic 系统。
二、Claude Code 系统级最佳实践:9 大核心模块构建生产级 Agentic 系统
Claude 的设计初衷,从来不是做一个聊天式的代码生成器,而是成为构建 Agentic 智能系统的核心引擎。围绕 Claude Core,我们可以搭建一套包含 9 大核心模块的完整系统,彻底解决上述 9 个误区,实现高可用、低成本、可扩展、可维护的 Claude 工程化应用。
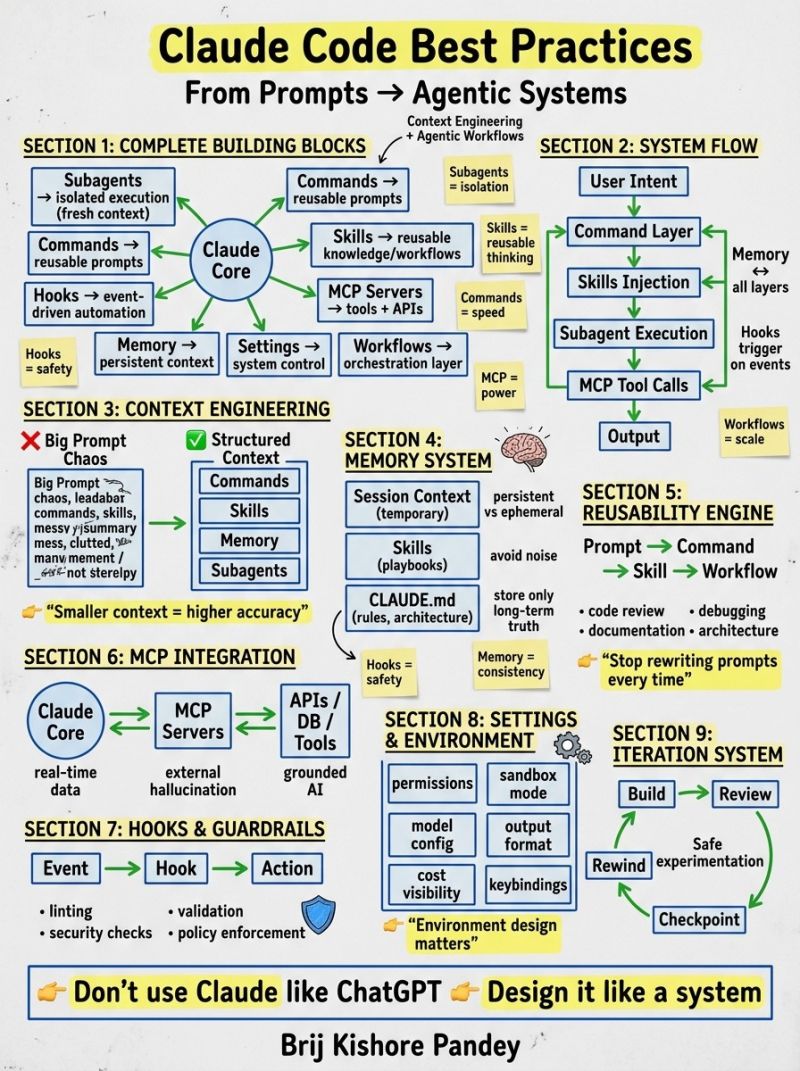
1. 完整构建模块:以 Claude Core 为核心的能力底座
整个系统的核心是 Claude Core,围绕它搭建了 8 个基础能力模块,每个模块都对应解决一个典型的使用误区,构成了系统的完整能力底座:
- Subagents:实现子任务的隔离执行,为每个子任务提供全新的干净上下文,彻底解决单线程上下文混乱的问题;
- Commands:封装可复用的 Prompt 指令,一次定义,到处调用,彻底告别重复写 Prompt 的无效内耗;
- Skills:沉淀可复用的知识与工作流,把结构化的思考流程标准化,让模型无需每次从零推理;
- MCP Servers:对接外部工具与 API,让 Claude 接入真实的运行环境与数据,打破对话的边界;
- Hooks:实现事件驱动的自动化,把校验、检查、安全规则变成自动化流程,无需人工干预;
- Memory:管理持久化上下文,分层存储长期真理与临时信息,保证上下文的一致性与纯净度;
- Settings:实现系统级的控制,管理权限、模型配置、输出格式等底层规则,划定系统的能力边界;
- Workflows:作为系统的编排层,把多个模块、多个步骤组合成标准化的业务流程,实现工程化的落地。
2. 系统流:从用户意图到输出的全链路闭环
一套完整的 Claude 系统,必须有标准化的执行流程,而不是混乱的单轮对话。系统的核心执行流形成了完整的闭环,且每一步都有对应的能力支撑:
- 用户意图输入:用户的需求进入系统,首先进入 Command 层匹配对应的标准化指令;
- 技能注入:根据任务类型,为执行流程注入对应的 Skill,加载标准化的思考与执行流程;
- 子代理执行:将任务交给隔离的 Subagent 执行,使用干净的专属上下文,避免噪声干扰;
- MCP 工具调用:执行过程中,通过 MCP 对接外部工具、数据库与 API,获取真实数据,执行实际操作;
- 结果输出:整合执行结果,按照固定的格式输出给用户。
在整个流程中,Memory 贯穿所有层级,为每一步提供必要的上下文支撑;Hooks 会在对应的事件节点自动触发,执行校验、安全检查等操作,保证整个流程的合规与安全。
3. 上下文工程:告别大 Prompt 混乱,拥抱结构化上下文
上下文工程的核心原则,是彻底告别大 Prompt 的混乱,用结构化的上下文替代臃肿的单条指令,同时坚守 “更小的上下文 = 更高的准确率” 的核心准则。
正确的上下文管理,会把内容拆分为四个结构化的模块:Commands、Skills、Memory、Subagents,根据当前任务的需求,只注入必须的上下文内容。比如执行代码评审任务时,只注入代码评审的 Command、对应的检查清单 Skill、当前仓库的架构规范 Memory,以及隔离的评审 Subagent,绝对不会把无关的代码生成、调试信息塞进上下文里。
这种结构化的设计,既保证了上下文的纯净度,提升了模型输出的准确率,又大幅降低了无效的 Token 消耗,从根源上解决了上下文过载的问题。
4. 内存系统:分层设计,只为一致性与纯净度服务
内存系统的核心设计目标,是保证上下文的一致性,核心原则是 “只存长期真理,不存临时噪声”。整个内存体系分为三层,实现了严格的分层管理:
- 会话上下文(Session Context):临时存储,只存放当前任务的相关信息,任务结束后自动清理,绝不流入长期内存;
- 技能剧本(Skills Playbooks):存放可复用的执行流程、检查清单、思考框架,是系统的标准化能力沉淀;
- CLAUDE.md:系统的核心规则文件,存放整个系统的架构设计、核心规范、长期不变的业务规则,是整个系统的 “宪法”,保证所有执行都遵循统一的底层标准。
这种分层设计,彻底避免了内存变成垃圾文件夹的问题,让内存始终保持纯净,为模型提供稳定、可靠的长期上下文支撑。
5. 可复用引擎:从单次 Prompt 到标准化 Workflow 的能力沉淀
可复用引擎是 Claude 系统越用越好用的核心,它定义了一条清晰的能力沉淀路径:Prompt → Command → Skill → Workflow。
- 把单次使用的 Prompt,封装成可复用的 Command,解决重复书写的问题;
- 把多个相关的 Command 与结构化思考流程,组合成一个完整的 Skill,实现标准化的能力封装;
- 把多个 Skill、执行步骤、自动化规则,编排成一个完整的 Workflow,实现端到端的业务流程自动化。
这套体系的核心目标,是彻底停止每次都重写 Prompt 的无效劳动。你每一次的最佳实践,都会被沉淀到系统中,让系统的能力持续增强,使用成本持续降低,效率持续提升。
6. MCP 集成:让 Claude 从 “代码生成器” 变成 “智能执行体”
MCP 集成是 Claude 系统落地的核心桥梁,它的完整链路是Claude Core ↔ MCP Servers ↔ APIs/DB/Tools。通过 MCP,Claude 可以直接对接你的开发环境、业务系统、数据仓库、第三方服务,实现三大核心价值:
- 实时获取真实的业务数据与环境信息,让代码生成基于真实场景,从根源上降低幻觉;
- 直接执行代码、调用 API、操作数据库,无需人工复制粘贴,实现端到端的自动化执行;
- 把外部工具的能力无缝接入 Claude 系统,无限扩展 Claude 的能力边界,让它真正融入你的业务流程。
没有 MCP 集成的 Claude 系统,永远只是一个脱离实际环境的 “纸上谈兵” 的工具;只有完成了 MCP 的深度集成,Claude 才能真正成为生产环境中的智能执行体。
7. 钩子与护栏:事件驱动的自动化安全网
Hooks 与 Guardrails 是整个系统的安全网,核心设计逻辑是事件驱动的自动化执行,完整链路为Event → Hook → Action。
你可以为系统中的任何事件设置对应的钩子:比如代码生成完成事件,自动触发 lint 检查、安全扫描、单元测试生成;比如工具调用事件,自动触发权限校验、参数合规检查;比如内容输出事件,自动触发敏感信息过滤、合规校验。所有的检查、校验、安全规则,都被封装成自动化的钩子,无需人工干预,也不需要在 Prompt 里反复书写。
这套体系,既保证了所有的输出都符合你的规范与安全要求,又省去了大量的手动检查工作,让系统的安全性与合规性得到了系统性的保障。
8. 设置与环境:环境设计决定系统的边界与稳定性
很多开发者完全忽略了环境设计的重要性,但环境设计才是系统稳定运行的底层基础。Claude 系统的设置与环境模块,涵盖了 6 大核心维度:
- 权限管理:划定 Claude 的操作边界,限制它可以访问的资源、可以执行的操作,避免越权风险;
- 沙箱模式:为代码执行、工具调用提供隔离的沙箱环境,避免误操作影响生产系统;
- 模型配置:固定模型版本、温度值、最大 Token 数等参数,保证输出的一致性;
- 输出格式:标准化模型的输出格式,保证下游系统可以稳定解析与处理;
- 成本可见性:实时监控 Token 消耗与成本,设置成本预警,避免出现超额费用;
- 快捷键配置:为常用的操作设置快捷指令,提升使用效率。
只有做好了底层的环境设计,你才能真正掌控 Claude 系统的行为,保证它在安全、稳定、可控的范围内运行。
9. 迭代系统:可控、可追溯、可优化的闭环开发
迭代系统是 Claude 系统持续优化的核心,它构建了一套完整的Build → Review → Checkpoint → Rewind闭环,实现了安全的实验与持续的优化。
在这套体系中,你每一次的代码生成与修改,都会生成对应的检查点,保留完整的版本记录;如果修改出现问题,可以随时回退到之前的稳定版本,不会出现 “改坏了无法还原” 的情况;每一次的评审结果,都会被沉淀到对应的 Command、Skill 中,让系统的能力持续优化;所有的迭代过程都有完整的追溯记录,让你完全掌控整个开发流程。
这套迭代系统,彻底解决了无规则修改带来的失控问题,让 Claude 的开发过程符合软件工程的标准,真正适配生产级的应用场景。
三、终极设计哲学:不要把 Claude 当 ChatGPT 用,要像设计系统一样设计它
写到这里,我们可以清晰地看到:用好 Claude Code 的核心,从来不是写出完美的 Prompt,而是构建一套完整的、结构化的、可扩展的系统。
ChatGPT 的核心定位,是通用的对话助手,它的使用逻辑是单轮、临时、非结构化的 Prompt 对话,适合解决简单、一次性的需求;而 Claude Code 的核心定位,是构建 Agentic 智能系统的核心引擎,它的设计初衷,是让你用工程化的思维,搭建一套可复用、可维护、安全可控的完整系统。
绝大多数人用不好 Claude,本质上是用错了思维模型:你在用聊天的思维,试图用一个超大的 Prompt 让模型一次给出完美的结果,最终只会陷入上下文混乱、成本高企、质量失控的困境。而 Claude 真正奖励的,是那些用系统思维思考的工程师 —— 他们关注的不是单条 Prompt 的措辞,而是上下文的结构化设计、工作流的标准化搭建、工具的深度集成、系统的模块化与可扩展性。
Claude Code 的真正成本,从来不是 Token 的费用,而是糟糕的系统设计带来的所有隐性损失。9 个常见的误区,本质上都是工程化思维的缺失;而 9 大核心模块的最佳实践,就是帮你构建生产级 Claude Agentic 系统的完整蓝图。
告别 “Prompt 魔法” 的草莽时代,拥抱系统工程的严谨设计,才是用好 Claude Code 的终极答案。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐


 11
11 0
0- 0



 已为社区贡献27条内容
已为社区贡献27条内容

所有评论(0)