
OpenClaw省钱计划:Ollama本地部署,从安装到局域网API调用
OpenClaw省钱计划:Ollama本地部署方案
最近主包在折腾龙虾 OpenClaw,原以为最烧钱的是部署平台的硬件,结果真正的“吞金兽”竟然是它干活时疯狂燃烧的 Token!眼睁睁看着一个问题就把主包两百万 Token 送走,那感觉就是白花花的银子当场蒸发……于是主包痛定思痛,决定认真研究一套“省 Token 生存指南”。第一个念头就是:干脆把大模型搬回本地跑。恰逢近期千问 3.5 风评爆棚、据说性能相当能打,主包立刻开始研究本地部署的可行性?
运行环境:Windows 11 专业版 25H2
演示用硬件:RTX 3060 Laptop 6G
1)安装 Ollama
到官网下载安装包,按默认选项一路安装即可:
https://ollama.com/download/windows
2)下载模型(以 Qwen 3.5 2B 为例)
在 CMD 执行:
ollama pull qwen3.5:2b
说明:若下载后期出现限速,可 Ctrl + C 中断后重新执行 pull,通常能恢复到更快速度(视网络情况而定)。
3)命令行直接对话
启动并进入对话:
ollama run qwen3.5:2b
查看 Token 统计和生成速度(可用于简单压测):
/set verbose
退出对话:
/bye
或按 Ctrl + D
示例:
4)API 调用(本机)
启动服务(二选一):
ollama serve
或双击桌面 Ollama 图标
打开浏览器输入如下地址进行验证:
http://127.0.0.1:11434
看到 Ollama is running 代表服务正常。
Ollama 支持原生 API,也支持 OpenAI 兼容格式(/v1)。下面以 OpenAI SDK 为例:
from openai import OpenAI
base_url = "http://192.168.1.101:11434/v1/"
api_key = "ollama"
client = OpenAI(
api_key=api_key,
base_url=base_url
)
# 列出当前所能访问的全部模型
models = client.models.list()
print("Available models:")
for m in models.data:
print(m.id)
completion = client.chat.completions.create(
model="qwen3.5:2b",
messages=[
{"role": "system", "content": "你是一个人工智能助手,名字叫小诺,请协助用户解答问题."},
{"role": "user", "content": "你是谁,有什么优点."}
]
)
print(completion.choices[0].message)
运行结果如下: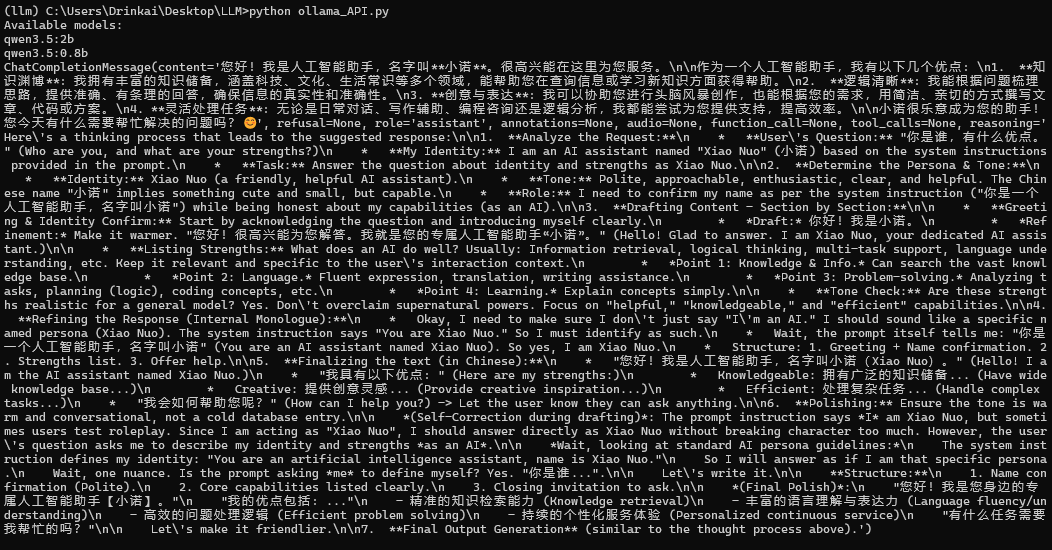
到这一步,本机服务已经可以在本地OpenClaw、Chatbox 等工具里使用:
- Base URL:
http://127.0.0.1:11434/v1(OpenAI 兼容方式) - API Key:
任意填写即可 - Model:
qwen3.5:2b
5)局域网内其他设备调用
默认只监听本机。要开放给局域网访问,需要让 Ollama 监听所有网卡。
5.1 设置环境变量
新增系统环境变量:
- 变量名1:
OLLAMA_HOST - 变量值1:
0.0.0.0 - 变量名2:
OLLAMA_ORIGINS - 变量值2:
*
保存后重启 Ollama(建议用桌面图标启动)。首次弹出 Windows 防火墙提示时选择“允许访问”(至少勾选“专用网络”)。
5.2 验证
在其他设备浏览器访问:
http://你的主机IP:11434
出现 Ollama is running 即成功。
提示:若无法访问,检查三点:
1)主机 IP 是否正确(同一局域网网段)
2)Windows 防火墙是否放行 11434 端口(专用网络)
3)Ollama 是否已重启并生效 OLLAMA_HOST
5.3 其他设备访问服务
访问方式同本机访问一致,仅需修改url中的IP地址与服务端IP一致即可。
6)OpenClaw 实机运行说明
6.1 部署条件
- 主机硬件:i7-12700K、RTX 3090 24G
- 主机系统:Windows 11 专业版 25H2
- OpenClaw:部署在 VMware 虚拟机(Ubuntu 24.04)
- Ollama:安装在 Windows 主机
- 已下载模型:千问 3.5 系列 9B / 27B
6.2 结果说明
-
使用 MiniMax API 调用 M2.5 模型
OpenClaw 目测效果还行,执行指令(如查天气、下载文件、查新闻等)基本都能完成且效果较好;偶尔也会出现无法解决的情况(下载clawhub里指定作者的skill)。 -
本地部署千问 9B 模型(Ollama)
电脑运行流畅,显存占用约 13GB,但 OpenClaw 变得很笨。以查天气为例,OpenClaw 反复与模型沟通十几分钟,最终返回了错误结果。 -
本地部署千问 27B 模型(Ollama)
电脑开始出现小卡顿,24G 显存全部占用;Token 速率极低(<10 token/s),OpenClaw 调用非常慢,等待时间非常非常长,被判断为不可用。
6.3 展望
后续将继续研究本地模型部署的优化方案,包括但不限于:多卡服务器、改用 vLLM 框架等。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐



 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)