当 OpenClaw 遇上 SenseNova U1,解锁智能体原生多模态新体验
上周五下午,领导让我下班前出那个项目的系统架构图、数据分析和产品设计概念图,周一就要看。我是先在DeepSeekV4里整理素材、撰写报告,再切换到数据可视化工具制作图表,再打开GPT-Image-2喂素材生成图片,然后在Canva里排版。一套流程下来,两个小时没了,而且中间还要在不同工具之间切换格式、不断调整提示词。
整个流程下来,不仅耗时耗力,而且不同工具之间的数据和语义转换,常常会带来不必要的摩擦和效率损耗。你可能需要反复调整,才能让文字和图片真正“心领神会”,达到你想要的效果。这种“分而治之”的工作模式,在追求效率和一致性的今天,显得有些力不从心。
这就是我最近在折腾的一件事:使用OpenClaw和SenseNova-Skills技能库,配合商汤最近刚开源的SenseNova U1模型,搭建一套"从大纲到成品图"的闭环工作流。折腾了一周,有些心得想分享。
一、从“拼凑”到“原生”,多模态模新范式NEO-unify
在正式动手实践之前,先简单聊聊我为什么选了SenseNova U1。
市面上的多模态模型不少,但大多数走的还是"拼盘"路线——这种路线中,图像和文本往往被视为两种独立的模态,需要各自的编码器将其转换为统一的表征空间,再进行融合处理。
而SenseNova U1的不同之处在于,它大胆地摒弃了传统多模态模型中的视觉编码器(VE)与变分自编码器(VAE),而是采用了一个叫NEO-unify的架构,把语言理解和视觉生成放在同一个模型里统一建模。
官方的说法是"语言与视觉信息作为统一的复合体直接建模",我的理解是:我们人类在理解世界时,也是这样将视觉与语言信息融为一体的,对应到架构上,SenseNova U1系列模型在看一张图的时候不是在"识物",而是真的在"理解"图中元素之间的关系;生成的时候也不是在"拼像素",而是在"表达"一种结构化的视觉语义。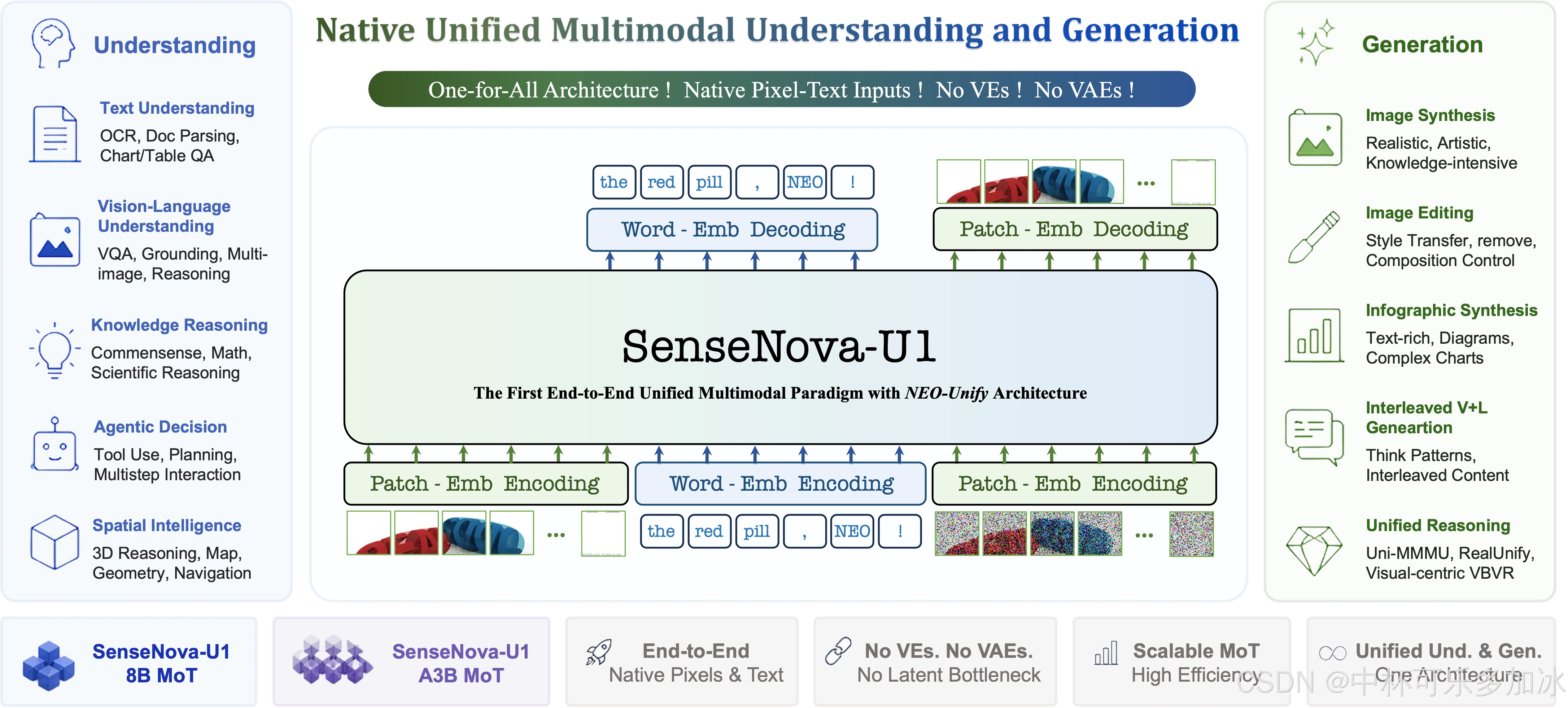
这种统一架构的直接好处就是生成结果的一致性——图片的风格、配色、布局逻辑会和前面的理解上下文自然衔接,不会出现"前一张图是扁平风、后一张图突然变立体感"这种割裂感。
这种架构上的创新,实实在在地带来了令人惊喜的能力突破。SenseNova U1 在统一多模态理解与生成方面树立了新的标杆,在多种理解、推理与生成基准上均达到了开源模型中的先进水平。
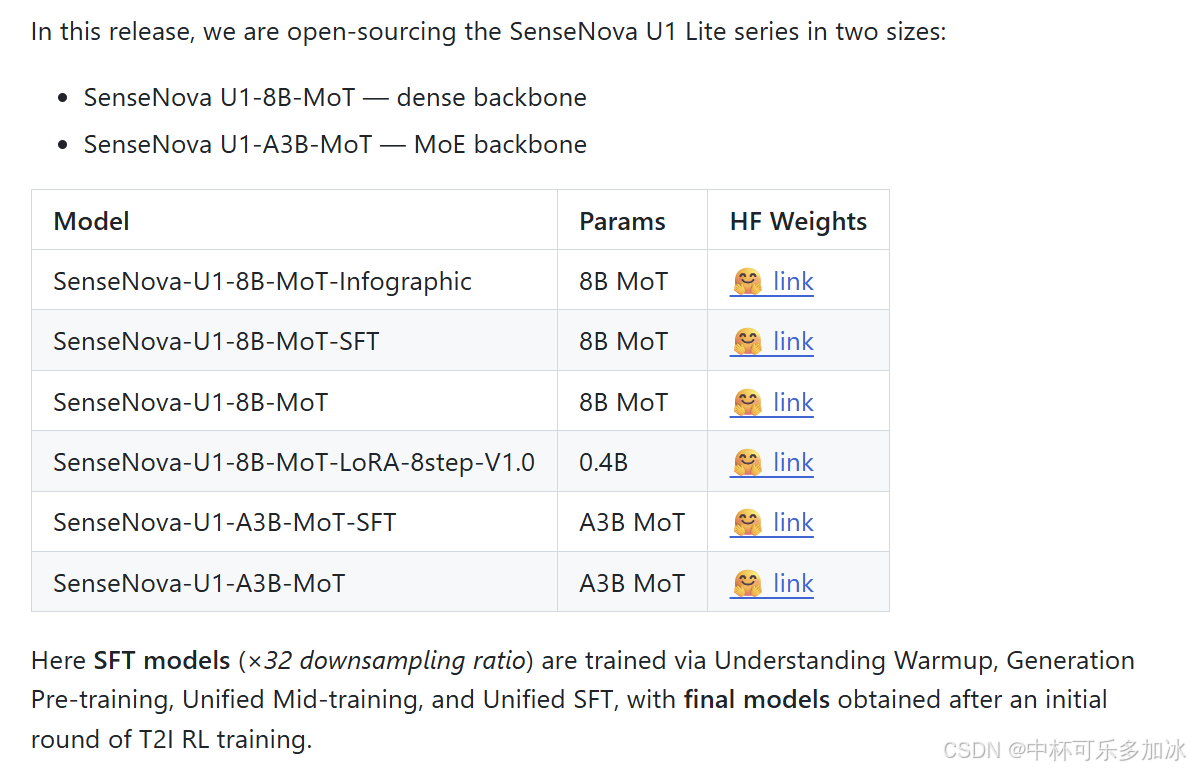
本次开源的 SenseNova U1 Lite 系列围绕两个核心规格展开——SenseNova-U1-8B-MoT(稠密骨干,约 ~8B 理解 + ~8B 生成 = 总参 ~18B)与 SenseNova-U1-A3B-MoT(MoE 骨干,总参 ~39B,对显存更友好),两者均原生支持文生图、图像理解、多轮对话式编辑与交错图文生成。在此基础上,官方目前已放出六个可下载权重仓库:
开源地址:
- GitHub:https://github.com/OpenSenseNova/SenseNova-U1
- HuggingFace:https://huggingface.co/collections/sensenova/sensenova-u1
二、实操指南:手把手教你将 SenseNova U1 接入 OpenClaw
而要将 SenseNova U1 这一强大的原生多模态能力集成到我们自己的智能体或应用中,最便捷、高效的方式莫过于利用其配套的 SenseNova-Skills (OpenClaw) 技能库。这套体系的使用方式很简单,关键在于把几个组件串起来:SenseNova 平台提供模型能力,OpenClaw 提供 Agent 运行时,SenseNova-Skills 则是跑在这个运行时上的技能插件
2.1、环境准备:OpenClaw安装与API Key 准备
在开始实践之前,我们需要准备好 OpenClaw 和 SenseNova 的 API Key,OpenClaw 相信大家都有安装过了,无论是开源版的原版 OpenClaw,还是各个云厂商魔改过的小龙虾都可以——当然如果你不用小龙虾,用 Claude Code、 Hermes 等其他兼容 agentskills.io 标准的智能体框架,也都是能够的。这里我使用的是本地部署的OpenClaw 2026.5.2版本。
准备好OpenClaw后,由于我本地电脑没有独立显卡,需要申请一个 SenseNova 的 API Key ,点击https://platform.sensenova.cn/,注册登录控制台,点击右上角免费申请并复制API Key。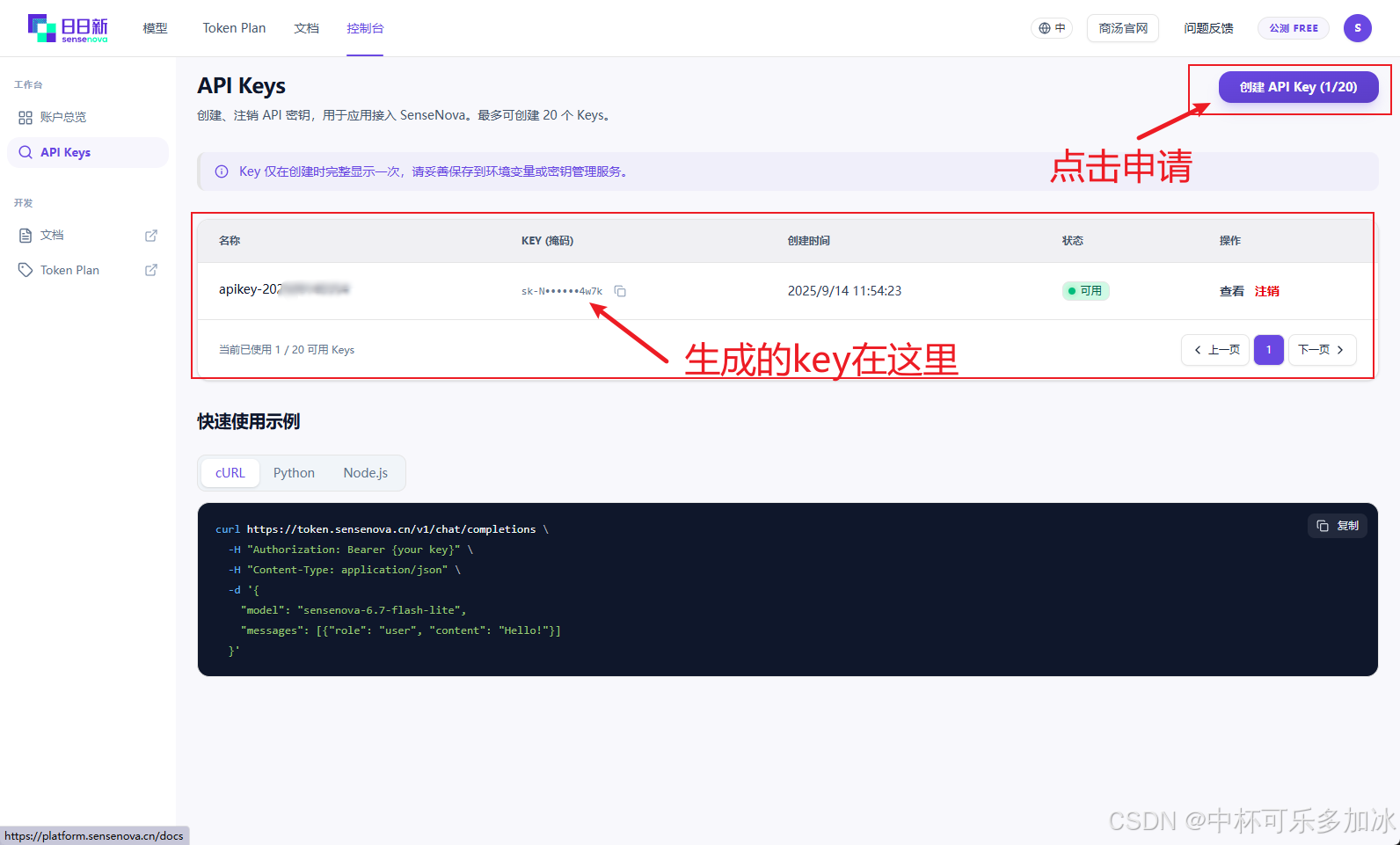
生成的key会在下方显示,拿到API Key之后记下来,后面配置要用,目前公测期间完全免费开放Token计划,支持每模型 1,500 次调用 / 5 小时, 完全够个人开发测试用。
2.2、加载 SenseNova-Skills 技能
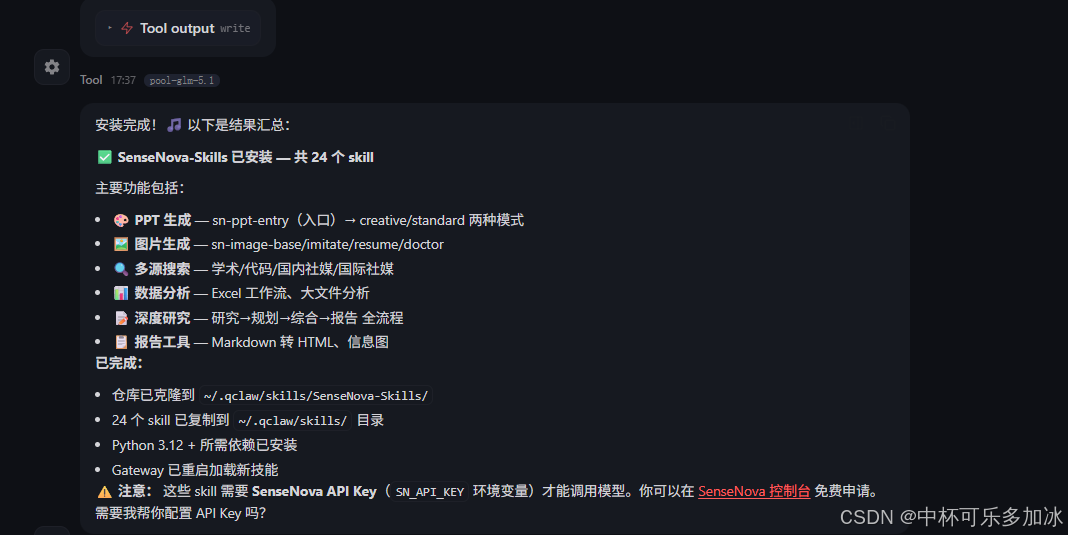
这里有两种方式,推荐的是让 Agent 自动安装——把仓库地址发给它,让它自己 clone 并放到正确目录。比如我这里输入“请帮我把 https://github.com/OpenSenseNova/SenseNova-Skills 安装到 skills 目录”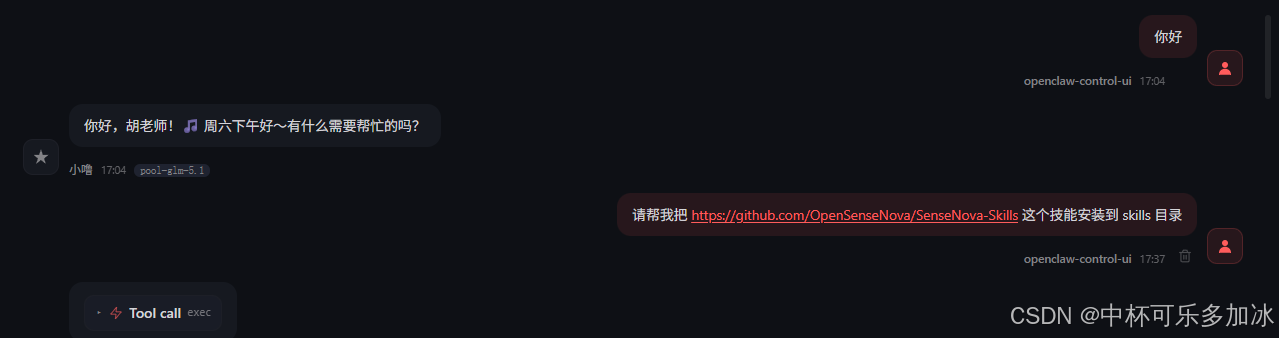
或者更直接的方式是手动执行:
git clone https://github.com/OpenSenseNova/SenseNova-Skills.git --depth=1
mkdir -p ~/.openclaw/skills
cp -r SenseNova-Skills/skills/* ~/.openclaw/skills/
然后把我们api key发给OpenClaw让他帮我们配置,或者手工配置到skills里面,安装完成后,需要手动重启 agent 服务,新 skill 才会被加载。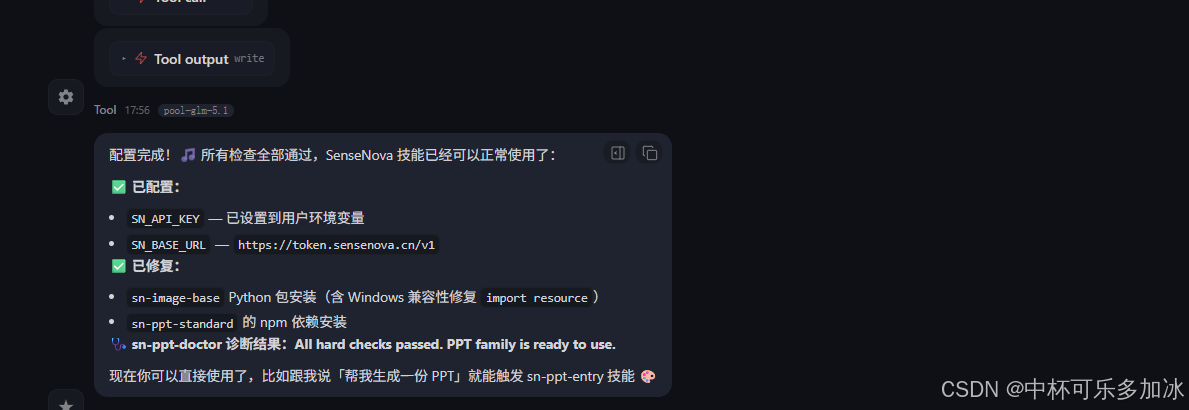
三、深度体验:从“对话”到“创作”的真实感受
成功将 SenseNova-U1 的能力通过 SenseNova-Skills 接入 OpenClaw 之后,接下来是实际使用。我主要测试了三个场景:信息图生成、风格模仿创作。
3.1、一键生成业务信息图
这个案例测试的是端到端的信息图生成能力——你给一段文字描述,它还你一张结构清晰、视觉精美的信息图。
传统方案里,这种任务需要拆成好几步:先用 LLM 理解文本内容,提取关键数据和逻辑结构,然后写 prompt 调用生图模型,生图模型再根据 prompt 生成图像。两步之间的信息传递全靠人工——你得判断哪些信息重要、怎么组织视觉层级、prompt 怎么写才能让生图模型准确理解意图。
而用 SenseNova-Skills 的 sn-infographic 技能,这个过程被压缩成一步。我只需要描述主题,Agent 会自动调用模型。关键在于提示词要足够详细——越是复杂的提示词,生成效果越好。
这里我测试了一个创意场景——生成一张”超级水果:柠檬万能指南”。提示词如下:
用sn-infographic技能,生成一张”超级水果:柠檬万能指南”信息图。
详细要求:
- 风格:清新明亮的青绿色渐变背景,点缀白色星星、气泡和云朵元素,扁平化卡通插画风格
- 布局:垂直分层结构,从底部的”LEVEL_0: 营养核心”开始,向上依次排列 LEVEL_1 烹饪艺术、LEVEL_2 家居清洁、LEVEL_3 身心疗愈
- 背景:青绿色渐变,清新自然
内容要点:
1. LEVEL_0: 营养核心
- 标题:”微观基础:营养宝库”
- 文本:”柠檬是维生素C的发电站。它能增强免疫系统,促进胶原蛋白合成,是身体抵抗病毒的第一道防线。”
- 视觉:显微镜图标,镜头下是放大的柠檬细胞结构
2. LEVEL_1: 烹饪艺术
- 标题:”味觉层级:厨房炼金术”
- 文本:”柠檬汁能通过'美拉德反应'提升肉类风味,防止水果氧化变色,并平衡油腻感。”
- 视觉:正在煎制的鱼排,淋上柠檬汁
3. LEVEL_2: 家居清洁
- 标题:”实用层级:天然清洁剂”
- 文本:”利用柠檬酸的化学力量。它是天然的除油剂和除垢剂,能去除水龙头水垢,杀灭细菌,且没有刺鼻的化学气味。”
- 视觉:装有柠檬片和清水的喷雾瓶
4. LEVEL_3: 身心疗愈
- 标题:”精神层级:提神与疗愈”
- 文本:”柠檬烯的香气能直接影响大脑边缘系统。它能显著减轻压力,提升专注力,甚至在早晨唤醒你的大脑。”
- 视觉:正在工作的香薰机,散发出黄色蒸汽
5. FILTER: 酸度警示
- 标题:”双刃剑(The Acid Limit)”
- 文本:”尽管益处众多,但柠檬的高酸度(pH 2-3)可能会侵蚀牙釉质。建议使用吸管饮用柠檬水,并随后漱口。”
配色:青绿色渐变、白色星星气泡装饰
风格:扁平化卡通插画,生动图标和场景
生成的信息图在视觉呈现上超出预期。它不是简单地把文字配图,而是真正理解了”层级体系”这个核心概念,用垂直分层结构展现从基础营养到高级应用的递进关系。每个层级都有独特的视觉表达——显微镜下的细胞结构、煎鱼场景、喷雾瓶除垢、香薰疗法——既传递了科学知识,又兼具趣味性和实用性。

这种”分层递进”的布局能力,体现了模型对内容逻辑的深层理解。它知道营养是基础、烹饪是应用、清洁是延伸、疗愈是升华,所以能自动设计出符合认知逻辑的视觉层级。
我又测试了一个风格截然不同的案例——生成一张”汽车制动系统工程蓝图”,这个案例考验的是模型对专业技术内容的视觉化表达能力,提示词如下:
用sn-infographic技能,生成一张”汽车制动系统工程蓝图”信息图。
详细要求:
- 风格:工程蓝图(blueprint)风格,深蓝色网格背景,白色线条勾勒
- 布局:中心辐射式结构,围绕核心制动盘和卡钳展开
- 背景:深蓝色网格,工程蓝图质感
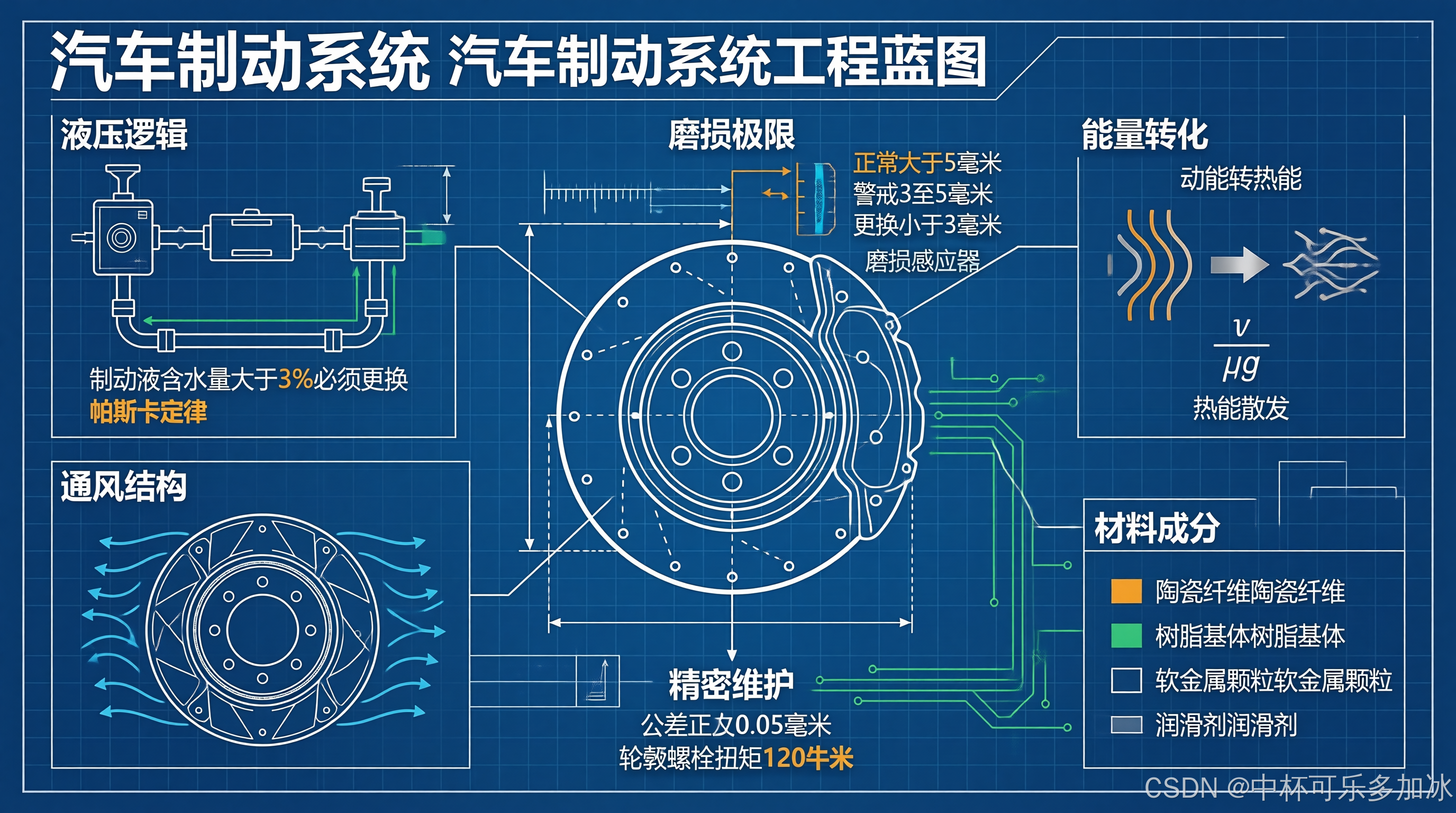
这个案例展现了模型对高密度技术内容的处理能力。它没有把六大模块简单平铺,而是通过中心辐射式结构将内容有机组织,形成清晰的逻辑分组。这种布局能力体现了模型对内容关系的深层理解。
最后,我又测试了一个更常用的场景——生成一张”孜然土豆排骨”菜谱的手绘图。提示词如下:
用sn-infographic技能,生成一张”孜然土豆排骨”手绘风格菜谱信息图。
一张竖版美食食谱卡片,标题为“孜然土豆排骨”,副标题“家常美味·香气四溢”,
右上角标注“约40分钟”和“中等难度”。
其中卡片主体分为左右两栏:
左侧从上到下依次为“主料”“调料”“辅料”列表,包含排骨、土豆、孜然粉、生抽、姜蒜等字样;
右侧为五个带编号的烹饪步骤示意图,每个步骤旁有小插画。
底部有一个“小贴士”区域,包含“小火慢煎”“孜然增量”“浸泡去淀粉”三条建议,并配有一个小火煎锅的简笔画。
整体风格为温馨手绘扁平风,浅米色背景,橙黄色和棕色系点缀,边缘有手绘食物装饰,文字清晰,排版像一张实用的家常菜谱卡。
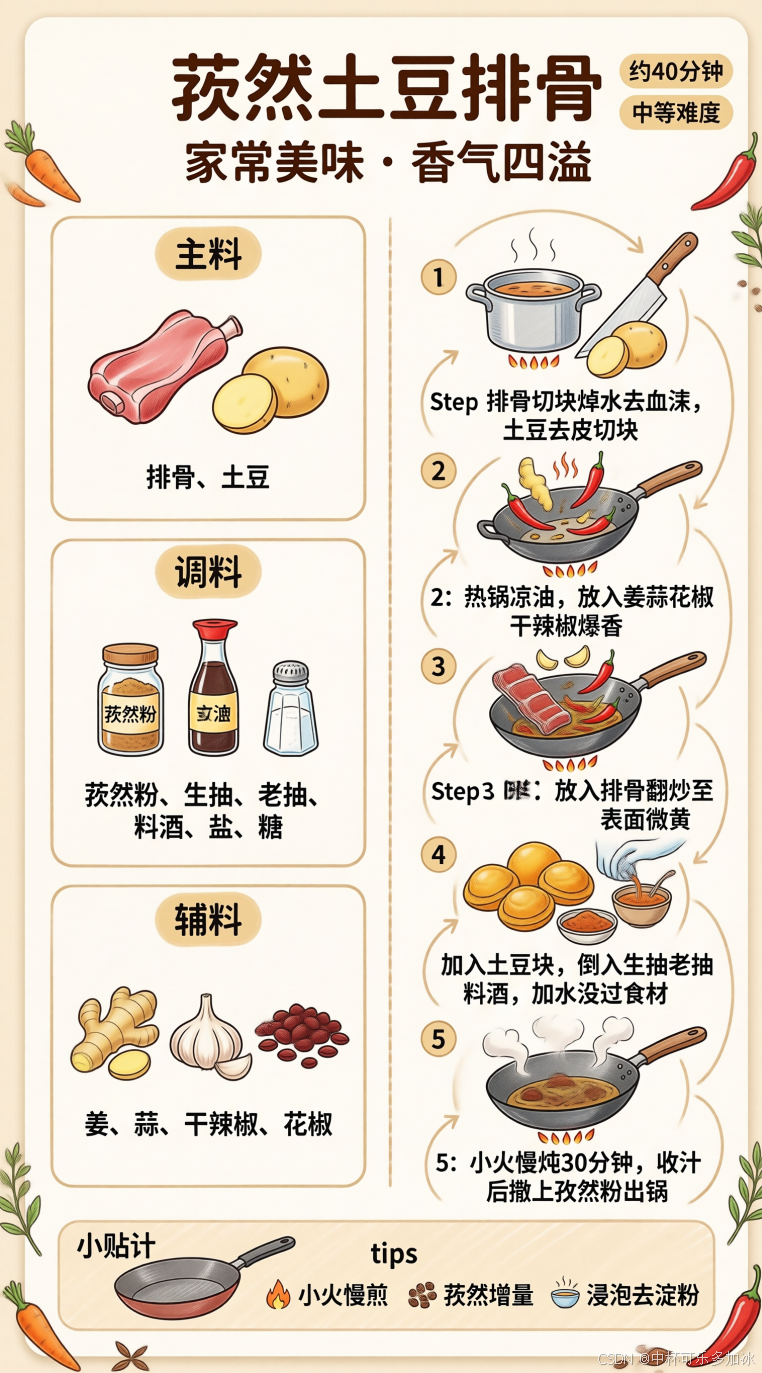
结果完全超出了我对"菜谱手绘图"的想象。它给出的不是简单线稿,而是一张信息密度极高、视觉层次丰富的完整食谱信息图。
3.2、原生交错图文生成
前面演示的信息图生成,本质上还是”单张图+配文”的形式。但 SenseNova-U1 的”原生交错图文生成”能力更进一步——它可以用一个模型生成多张相互关联的图片,每张图片配上对应的文字描述,共同讲述一个完整的故事。这个能力是模型本身的内置特性,这种能力的工作方式与传统方案截然不同:
| 对比维度 | 传统方案 | SenseNova-U1 原生交错图文 |
|---|---|---|
| 生成方式 | 图片和文字分别生成,人工拼接 | 单模型统一生成,图文自然交织 |
| 多图关联 | 需要人工保证风格一致 | 模型自动保持视觉风格统一 |
| 叙事逻辑 | 靠人工编排 | 模型理解故事线,自动分镜 |
| 输出形式 | 单张图或简单拼合 | 多张图+文本,一气呵成 |
举一个具体的例子。我想让模型重新讲述《卖火柴的小女孩》这个经典童话,但给出一个温暖的平行宇宙改编版——在最后一次擦亮火柴时,出现的不是幻象,而是一只拥有魔法的驯鹿,它载着小女孩飞向了有糖果和壁炉的城堡。提示词如下:
讲一下经典童话《卖火柴的小女孩》,但这次请给出一个温暖的平行宇宙改编版图文绘本。
在最后一次擦亮火柴时,出现的不是幻象,而是一只拥有魔法的驯鹿,它载着小女孩飞向了有糖果和壁炉的城堡
生成的结果是一个4页图文故事:冷蓝雪夜中赤脚的小女孩→火柴光芒里出现发着金光的魔法驯鹿→驯鹿用角轻触小女孩带她飞向天空→降落到温暖明亮的糖果城堡。每页都是一张独立的插画,配上叙述性文字。这种”多图+文本”的叙事能力,是传统单图生成方案无法做到的。

3.3、风格模仿:让 AI 读懂"我想要的风格"
这个案例源于一个更具体的需求:我有一张比较喜欢的“相机内部结构爆炸图”,现在我想生成风格一致但内容不同的图。这在品牌视觉设计、内容运营等场景里非常常见——你需要一张主视觉,然后在不同渠道、不同用途上做延伸,这些图必须风格高度统一。传统方案里,这件事几乎做不好。你只能把参考图发给生图模型,让它"学习",但学到什么程度、哪些元素该保留、哪些该替换,全靠玄学。同一个 prompt 跑两次,可能出来两个完全不同的结果。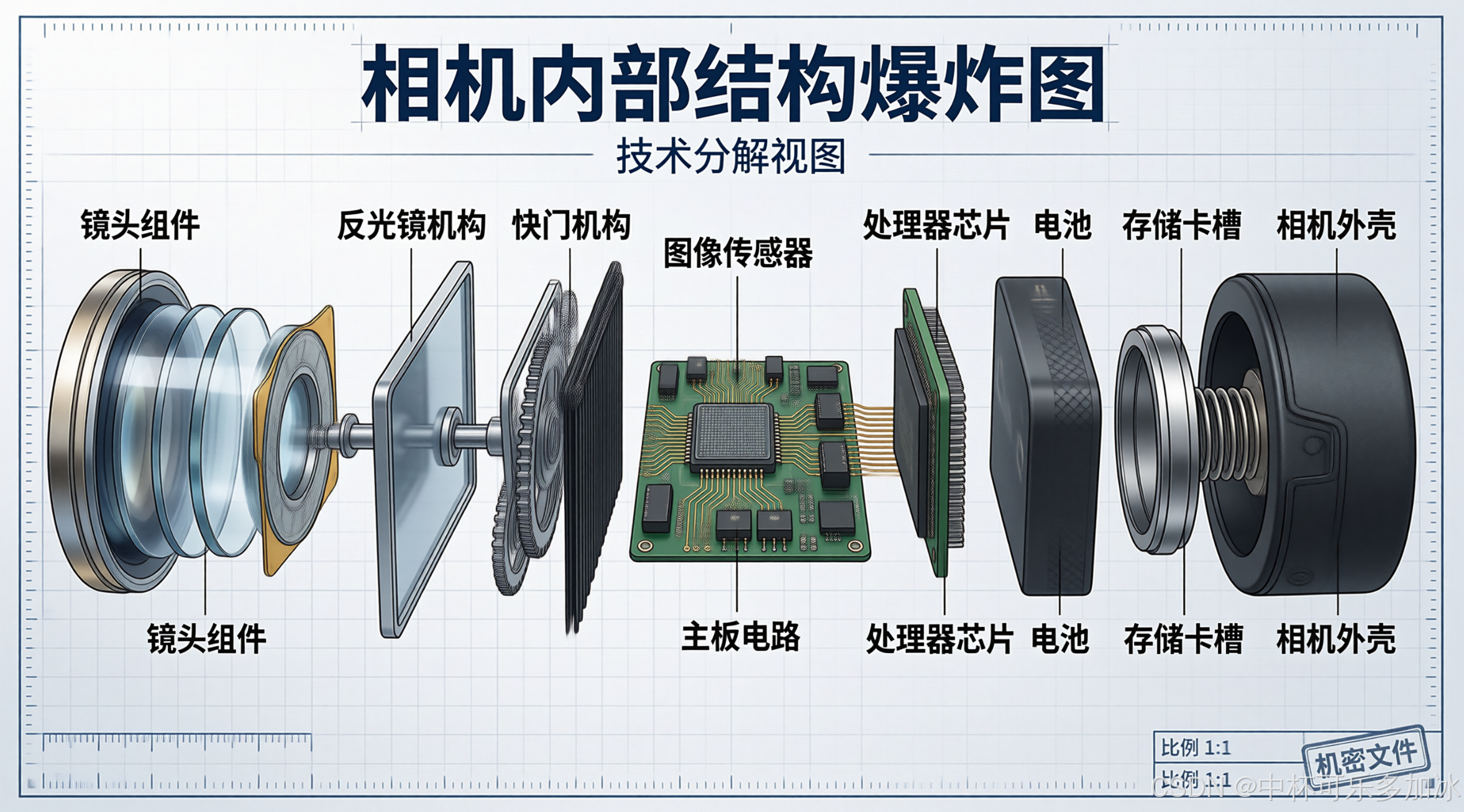
而使用SenseNova-U1模型,我输入了完整的“无人机内部结构拆解分析图”,结果几乎复刻了参考图的风格骨架:同样的深色科技背景、同样的绘制风格、同样的标注方式。飞控模块、电池组、电机、云台——每个组件的层级关系和参考图中相机镜头、传感器、快门组件的排布逻辑如出一辙。
用sn-image-imitate技能,生成一张无人机内部结构拆解分析图。
参考风格:相机内部结构爆炸图(精密技术图纸风格)
详细要求:
- 目标风格:精密技术蓝图风格,模拟专业产品拆解图
- 布局:横向爆炸分解图,各组件沿中心轴线水平排列
- 背景:工程蓝图质感,深浅蓝色网格线,带有微妙纸张纹理
内容结构(从左到右依次排列):
1. 螺旋桨组件 - 描绘四轴旋翼的桨叶结构,碳纤维材质纹理
2. 电机总成 - 无刷电机外壳剖面,线圈绕组细节
3. 飞控模块 - 主控芯片位置,IMU传感器组,LED状态指示灯
4. 动力电池 - 智能飞行电池外观,电量显示条
5. GPS与指南针模块 - 天线结构,陶瓷外壳
6. 视觉避障传感器 - 双目摄像头,红外发射器
7. 云台相机(核心载荷)- 三轴机械稳定结构,镜头组剖面
所有组件通过虚线连接,标注引线清晰
配色:工程蓝、金属银、电路绿、警示橙
文字标注:中文为主,部件名称精确
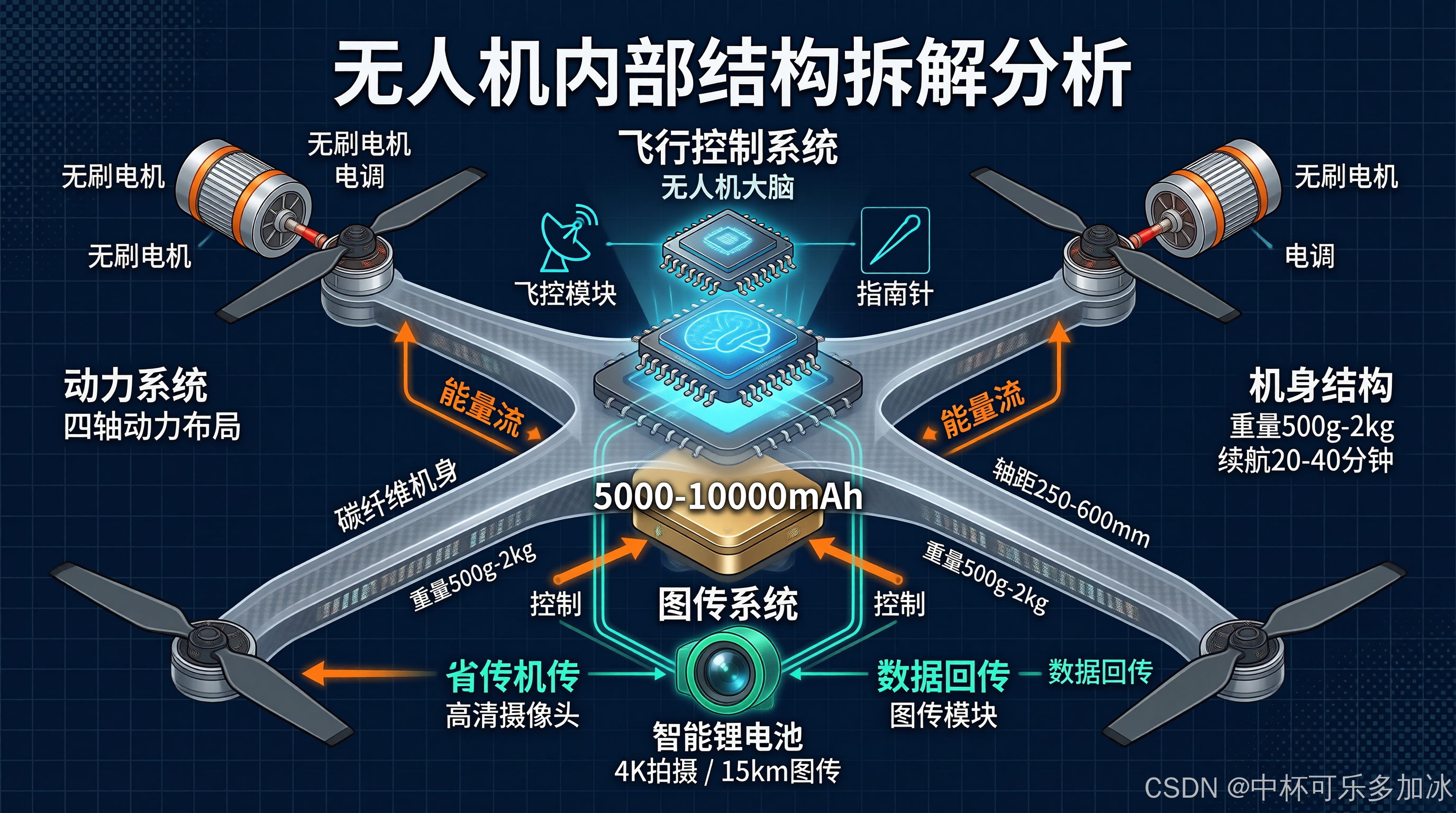
sn-image-imitate 技能解决这个问题的思路很有意思。它不是简单地让模型"学习风格",用 VLM 详细分析参考图,输出一个结构化的"风格蓝图",包含视觉层级、区域拓扑、阅读流向、配色方案等维度。然后进行内容改写——保持风格蓝图的约束不变,只替换核心内容。最后是生成和布局一致性审查,确保输出图的布局拓扑和参考图类似。
四、总结
回看那个周五下午,两小时在几个工具之间来回切,最后交出去的图,说实话也就是“能用”。现在用这套 SenseNova-U1 + OpenClaw 的流程,同样的事情可能半小时就能搞定初稿,出来的东西甚至比之前两小时磨出来的更协调。说几个最直观的感受。
最大的感受是关于"意图传递"的损耗问题。我之前用那些拼接方案,每次都要做一层"翻译"——把脑子里的想法倒成文字,再把文字塞给生图模型。这个过程里损耗了多少?可能连我自己都说不清。但用 SenseNova U1 之后,我发现这种损耗少了很多。不是因为它的 prompt 写得更好,而是架构本身就少了那些跨模型传递的环节。这不是某个参数调一调能弥补的,是从底层设计就决定的事情。
然后是关于"一致性"的惊喜。我之前最头疼的问题就是风格不统一——同一套东西,前一张图是扁平插画风,后一张突然变成写实渲染,放一起怎么看怎么别扭。但用 SenseNova-U1结合上sn-image-imitate 这个 skill,现在只需要一张参考图,剩下的交给这条链路去“对齐”。这不仅仅是省时间,更关键的是让脑子里那个模糊的“感觉”能稳定地落到画面上,不用再靠运气。
回过头来说,这些体验背后真正发挥作用的,还是SenseNova U1系列模型。正是因为它把理解和生成统一在同一套建模体系里,上面那些技能才有可能实现——提示词优化依赖模型对语义的理解,布局一致性依赖模型对视觉结构的把握,。这些能力不是靠堆 prompt 能堆出来的,是架构本身决定的。开源 SenseNova-U1 这件事本身,对于整个开发者生态来说,都是一件值得认真对待的事情。
如果你也在折腾类似的事情,建议直接安装开始体验。门槛很低,半小时就能跑起来,剩下的,自己判断。

为武汉地区的开发者提供学习、交流和合作的平台。社区聚集了众多技术爱好者和专业人士,涵盖了多个领域,包括人工智能、大数据、云计算、区块链等。社区定期举办技术分享、培训和活动,为开发者提供更多的学习和交流机会。
更多推荐
 7
7 0
0- 0



 已为社区贡献36条内容
已为社区贡献36条内容

所有评论(0)