【AI落地应用实战】跨境电商选品实战:IPIDEA 代理 + DeepSeek AI 助力高效洞察市场
在跨境电商领域,传统选品模式正面临严峻挑战:**过度依赖个人经验、市场信息严重滞后、地区管理难以应对**。当全球市场瞬息万变时,这些痛点让卖家们往往与商机失之交臂。在这个背景下,数据洞察能力已成为破局的关键。但核心问题依然存在:**如何解决地区问题,高效获取真实的全球市场数据?又如何从海量信息中提炼出有价值的商业洞察?**这正是我们需要深入探讨的课题——直面每个卖家最关心的问题:在这个数据驱动的新
一、破局跨境选品
1.1 跨境电商的挑战与机遇
在跨境电商领域,传统选品模式正面临严峻挑战:过度依赖个人经验、市场信息严重滞后、地区管理难以应对。当全球市场瞬息万变时,这些痛点让卖家们往往与商机失之交臂。
在这个背景下,数据洞察能力已成为破局的关键。但核心问题依然存在:如何解决地区问题,高效获取真实的全球市场数据?又如何从海量信息中提炼出有价值的商业洞察?
这正是我们需要深入探讨的课题——直面每个卖家最关心的问题:在这个数据驱动的新时代,我们该如何系统地寻找并验证“下一个爆款”?
1.2 IPIDEA+DeepSeek:智能选品的新型组合
想象你正准备开一家线上服装店。当你试图调研美国市场时,却发现看到的网页内容与当地用户完全不同——推荐商品、流行款式都像是隔着一层毛玻璃,模糊不清。更糟的是,稍一频繁浏览就被网站禁止访问。
这正是跨境卖家的第一个拦路虎:地域管理与网站防护。
此时,IPIDEA代理的作用就凸显出来。它可以提供真实的当地IP地址,让你像本地居民一样无障碍访问电商平台,确保获取数据的真实性和完整性。
然而,当数千条商品数据堆积在眼前时,新的困境出现了:海量信息如同一团乱麻,仅靠人工难以理清。
这时,DeepSeek的作用就显现出来了。它能瞬间完成人类数周的工作:从商品标题中提炼关键特性,分析用户评论的情感倾向,甚至预测市场趋势。
这个组合,将传统选品模式升级为科学的数据驱动方法,直击核心问题:如何找到下一个爆款?
二、环境准备与数据采集
2.1 DeepSeek初步锁定目标市场与品类
在投入大量资源进行数据采集之前,明智的做法是先利用DeepSeek进行初步的市场调研,为后续工作指明方向。
你可以直接向DeepSeek提出针对性的问题,例如;“2025年美国亚马逊平台服装品类有哪些新兴趋势?”,AI会基于最新的市场数据,提供结构化的趋势分析:
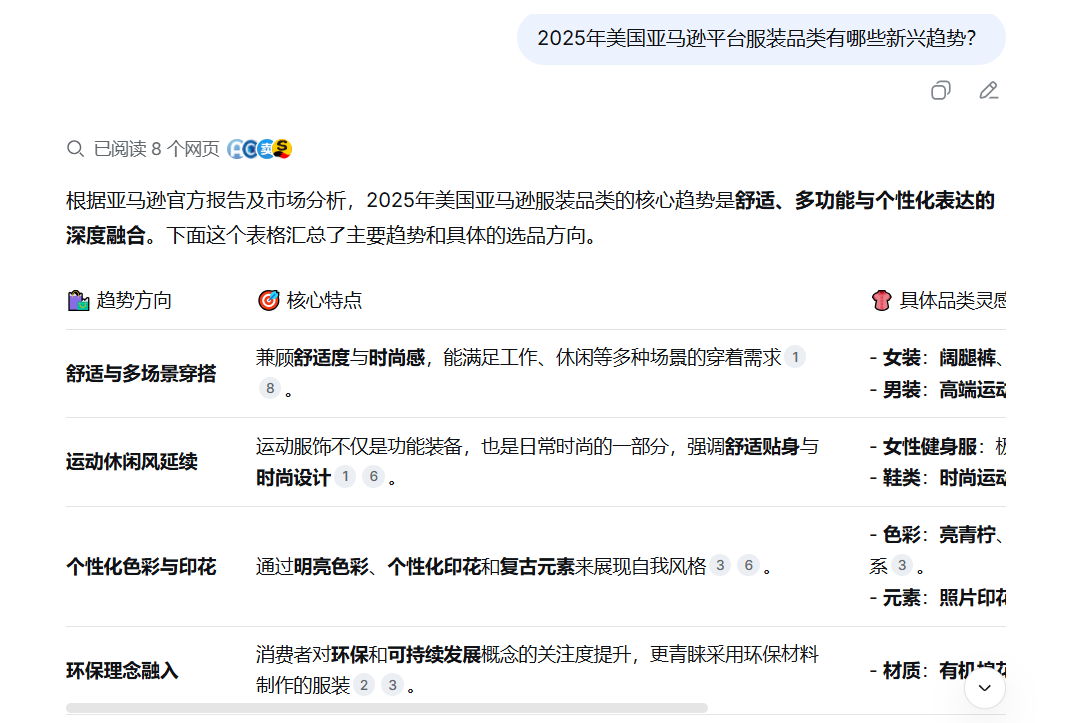

通过这样的对话,DeepSeek能够为你提供从趋势洞察到具体运营的完整指导。这些初步洞察将成为数据采集的精准导航,让你能够:
1. 针对"环保材质服装"重点采集用户评论和价格区间
2. 围绕"多场景穿搭"分析竞品的卖点描述
3. 根据细分人群需求定制化的关键词策略
这种"先问AI,再采数据"的方法,确保你的数据采集工作有的放矢,防止无关紧要的信息上浪费资源。通过DeepSeek的初步导航,你不再是盲目出海,而是带着精准的航海图启程。
2.2 IPIDEA代理配置实战
IPIDEA代理在数据采集中发挥着至关重要的作用,优势在于其出色的技术特性,为跨境电商数据采集提供了坚实基础。通过全球覆盖的IP资源网络,它能够模拟目标市场本地用户的真实访问环境,让您看到的商品信息、价格定位和搜索排名与当地消费者几乎一致。高保密性特性确保不会被平台识别为数据抓取行为,有效应对防护机制,保障数据采集的连续性和完整性。同时,卓越的稳定性让长时间、大规模的数据采集成为可能,不会因IP高频率更替或连接中断而影响数据质量。这三重优势共同确保了采集到的数据真正反映目标市场的用户视角,为后续的深度分析提供真实可靠的原始素材。
实战配置流程:
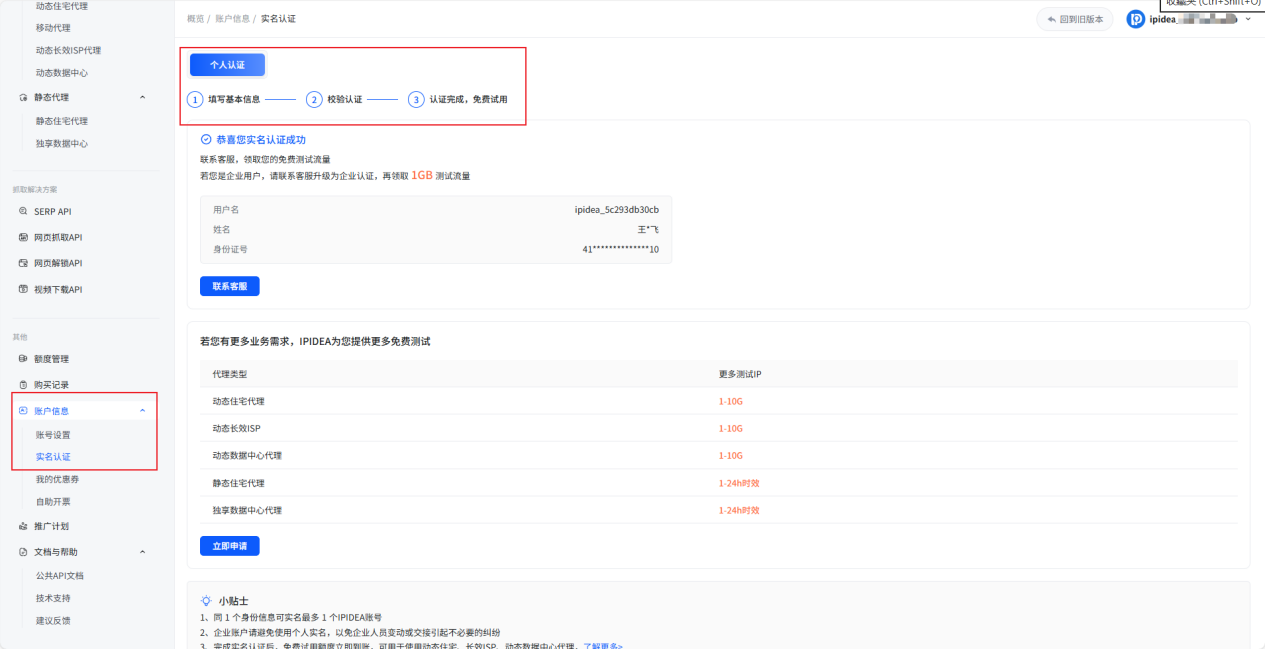
第一步:快速注册与认证
访问IPIDEA官网,使用手机号即可完成快速注册,整个过程仅需几分钟。登录后建议立即完成身份认证,这一步骤不仅能提升账户安全等级,还能解锁更高的并发请求限制,为后续大规模数据采集做好准备。认证材料提交后通常能在短时间内完成审核。
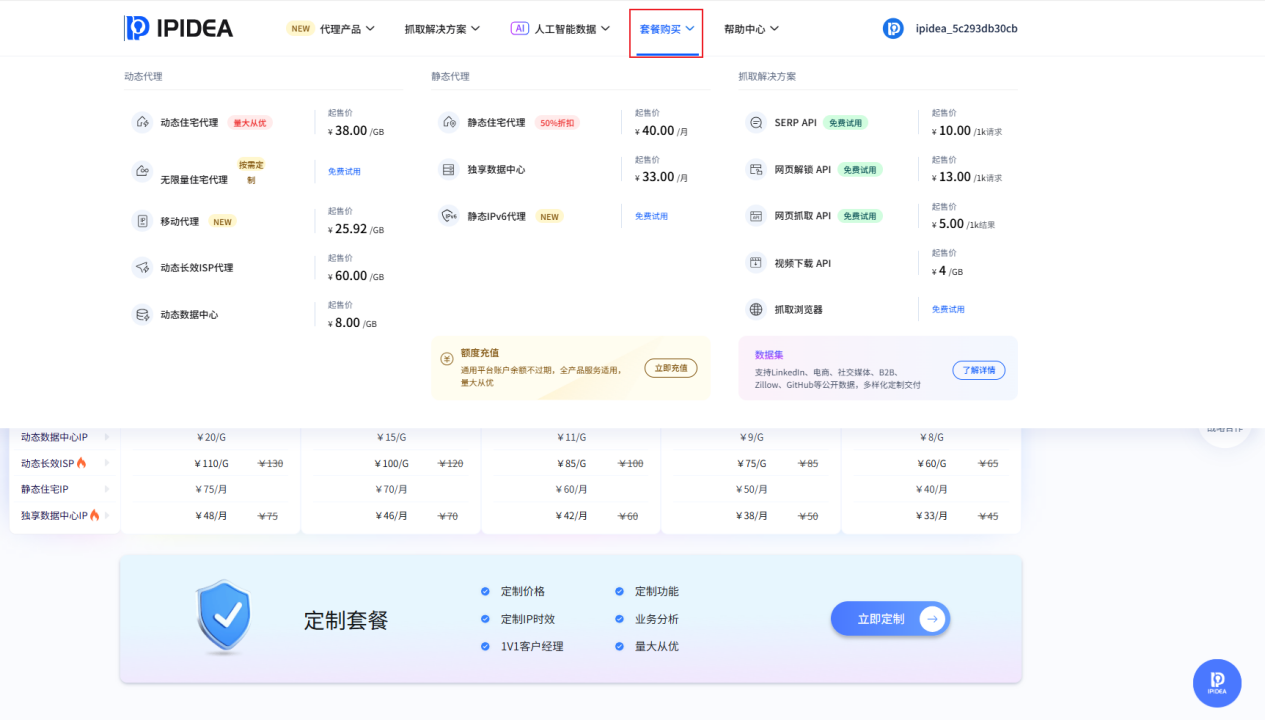
第二步:智能选择服务套餐
在“套餐购买”页面,清晰呈现了动态住宅代理、静态住宅代理等多品类服务。
第三步:代理获取与配置
我需要配置静态住宅代理,用于跨境电商平台数据采集。
1. 在代理类型中选择“静态住宅代理”->选择“API提取”,填写需要的具体参数:国家/地区、提取数量等,点击“生成API链接”并复制。
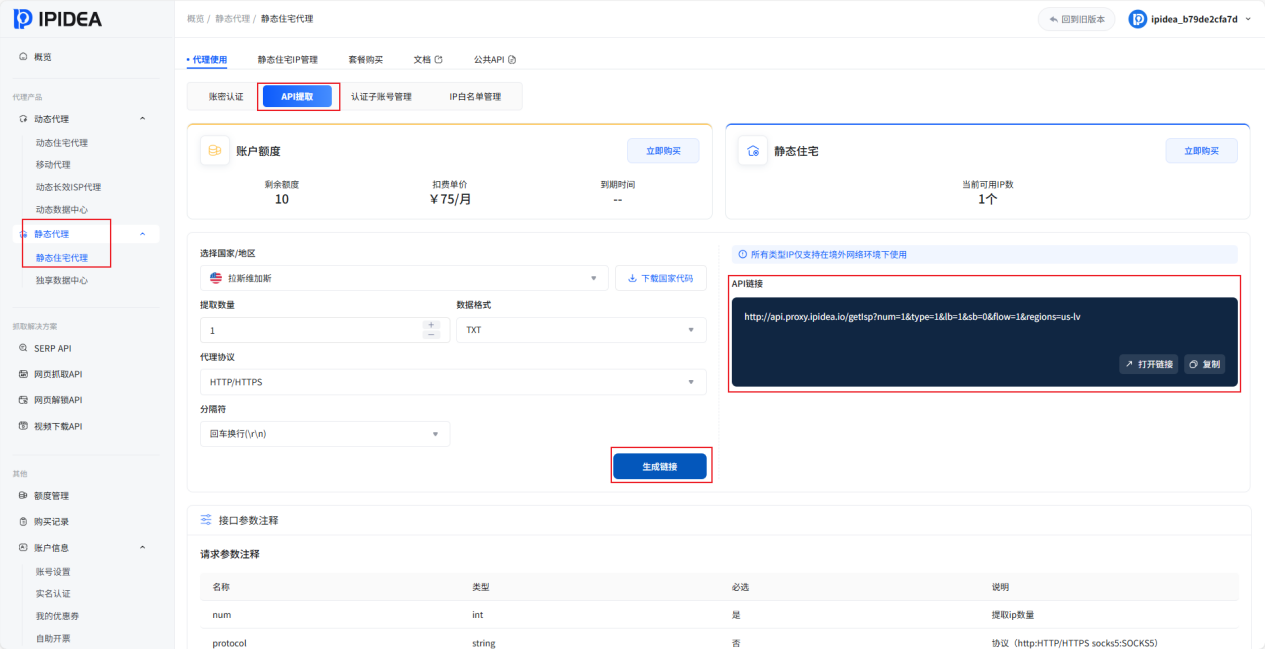
2. 点击“生成链接”之后,页面会弹出“确认添加白名单”页面,点击“确认”,将服务器IP添加到白名单。
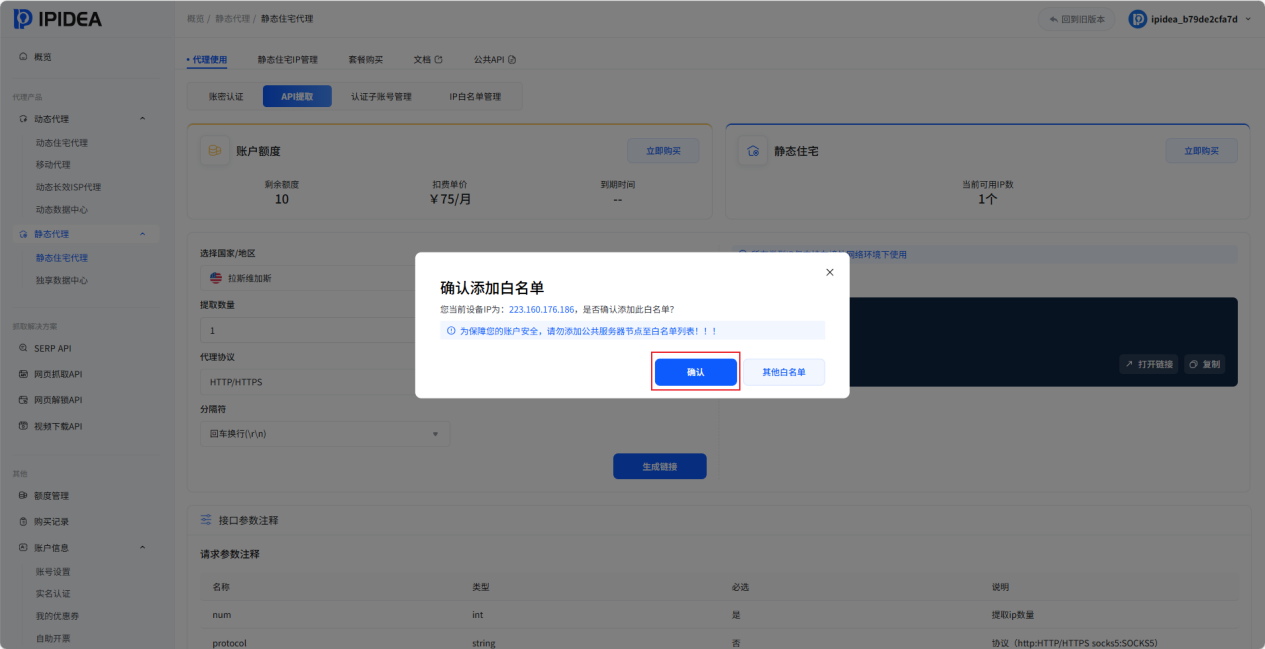
可以选择"IP白名单管理",能看到IP已经添加成功。
配置示例:
import requests
# 使用生成的API链接
api_url = "您从IPIDEA获取的API链接"
proxies = {
"http": api_url,
"https": api_url
}
# 测试采集
response = requests.get("https://amazon.com/product-data", proxies=proxies)
这样配置后,就能获得稳定的目标市场本地IP,开始真实的跨境电商数据采集了。
2.3 目标平台数据采集
以Amazon平台为例,以下是完整的数据采集流程:
数据接口分析阶段:
具体操作步骤:
1. 打开Chrome浏览器,访问 amazon.com。
2. 按F12打开开发者工具,选择 Network(网络)标签。勾选Preserve log(保留日志)以防止页面跳转时请求记录丢失,同时勾选Disable cache(禁用缓存)确保获取最新数据。
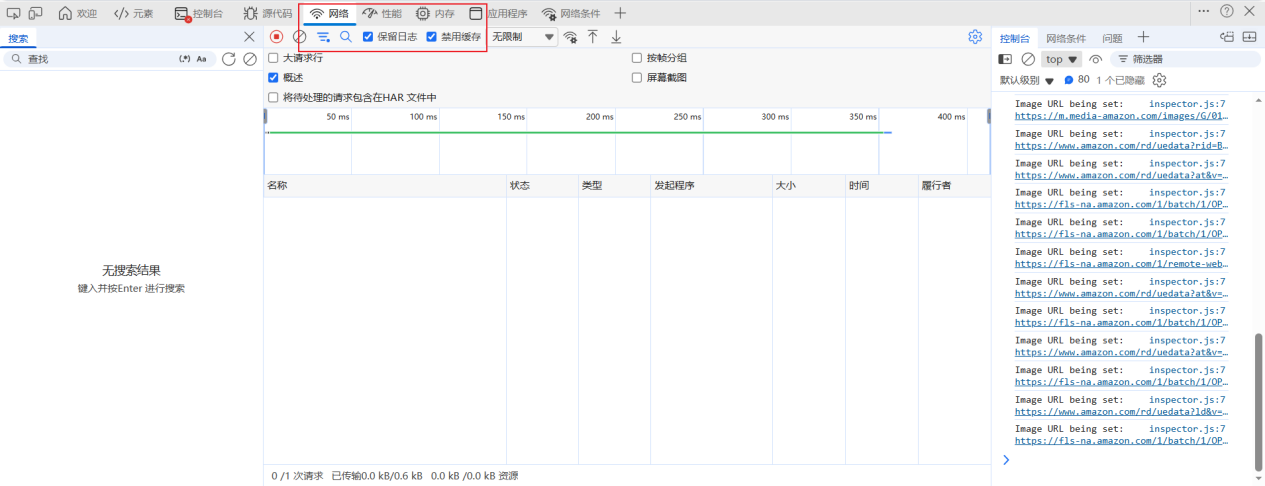
3. 在 Filter 过滤框中输入product、search或suggest关键词筛选;同时在Type(类型)列中优先勾选XHR和Fetch,聚焦异步数据接口。
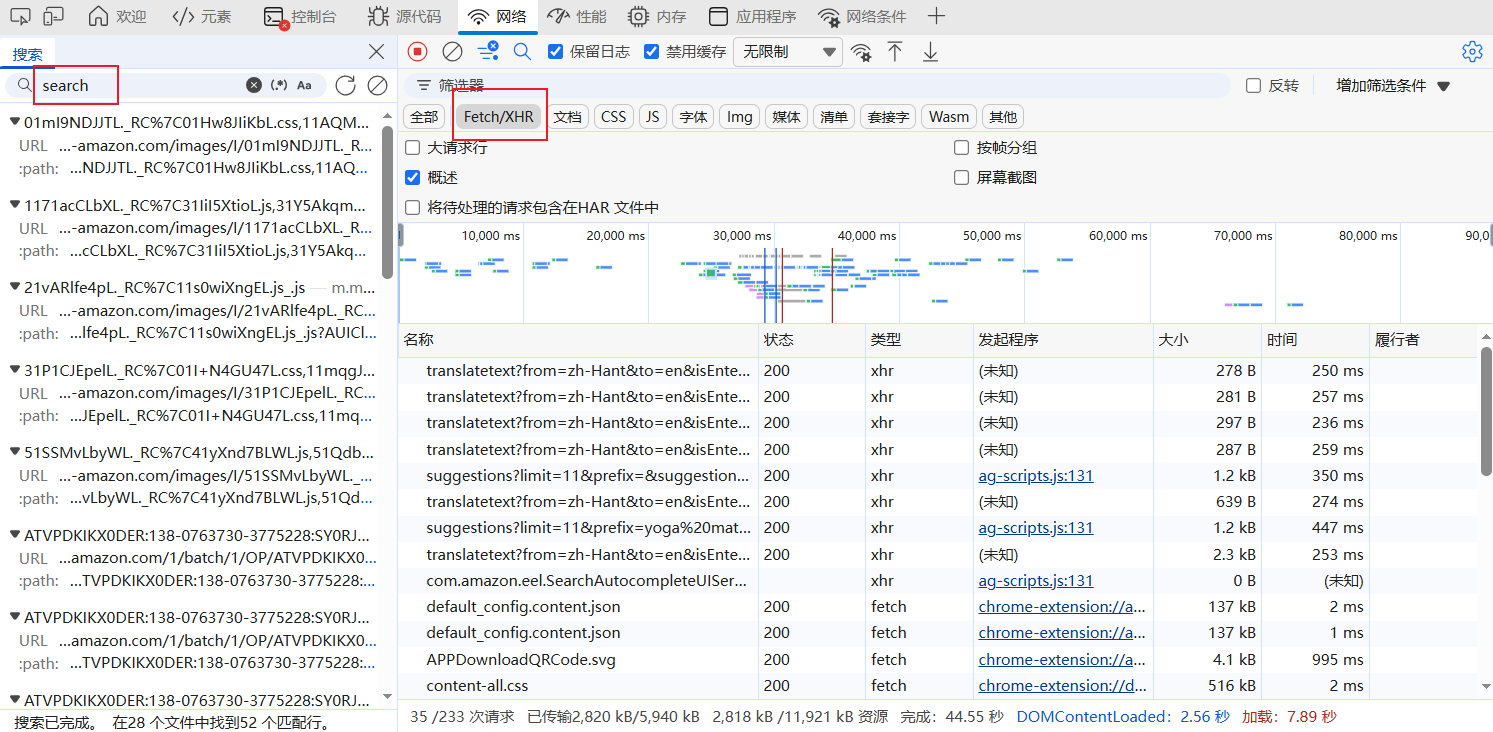
4. 在 Amazon 搜索框输入目标关键词(如yoga mat)并执行搜索,观察 Network 面板中实时加载的新请求。
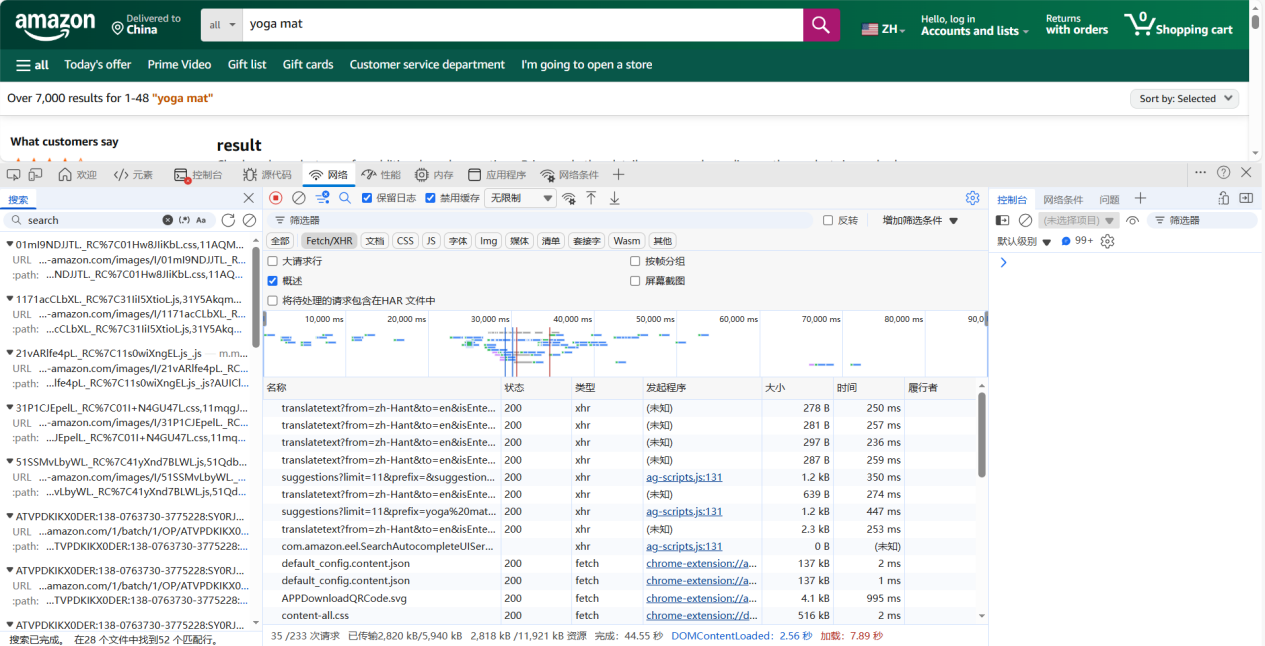
5. 重点关注状态码为200、响应类型为application/json或json的请求,这类接口通常为核心数据接口(多为 XHR 类型)。
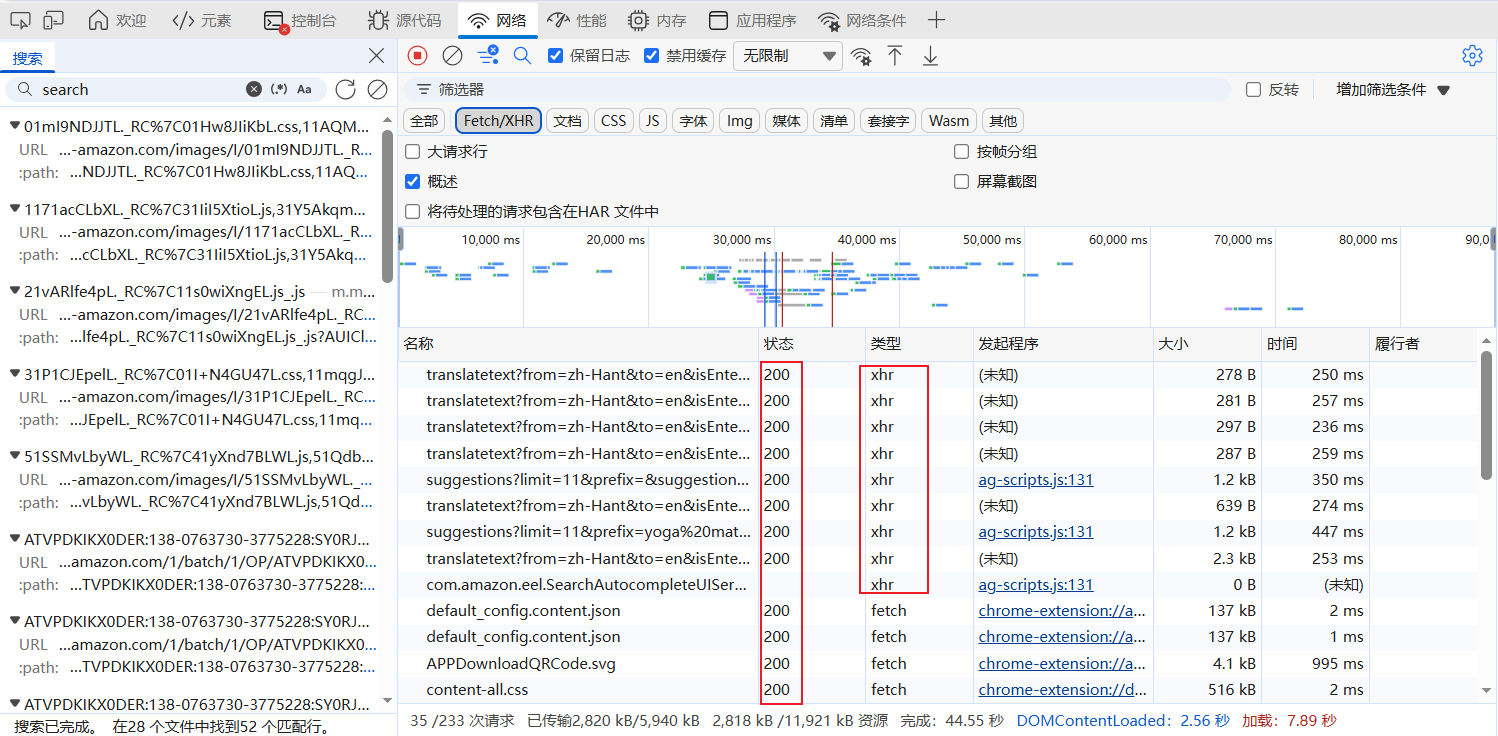
6. 针对筛选出的请求,从“请求头 - 参数 - 响应” 三维度深度分析:
• 请求头(Headers)和请求参数(Params/Payload)分析:
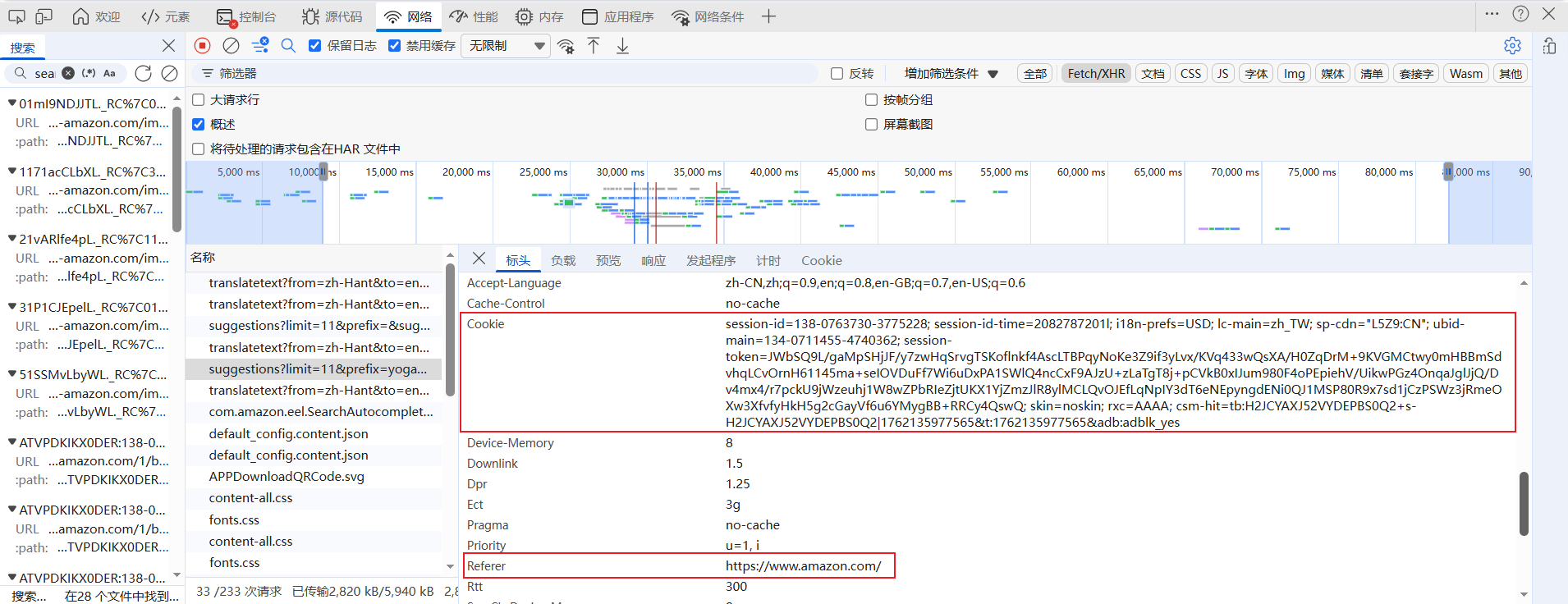
该请求的请求**** URL是 Amazon 平台用于提供关键词建议的接口地址,通过一系列参数明确了请求的条件:包含limit=11(最多返回 11 条建议)、prefix=yoga%20mat(用户输入的关键词前缀为 “yoga mat”,“%20” 是空格的 URL 转义)等业务参数,定义了建议的数量、关键词范围;还包含session-id(会话唯一标识)、request-id(单次请求标识)、mid(平台商家标识)等用于维持会话和接口追踪的参数。
请求方法为 GET,即通过将所有参数拼接在 URL 的查询字符串中,向服务器发起请求以获取对应的关键词建议数据。
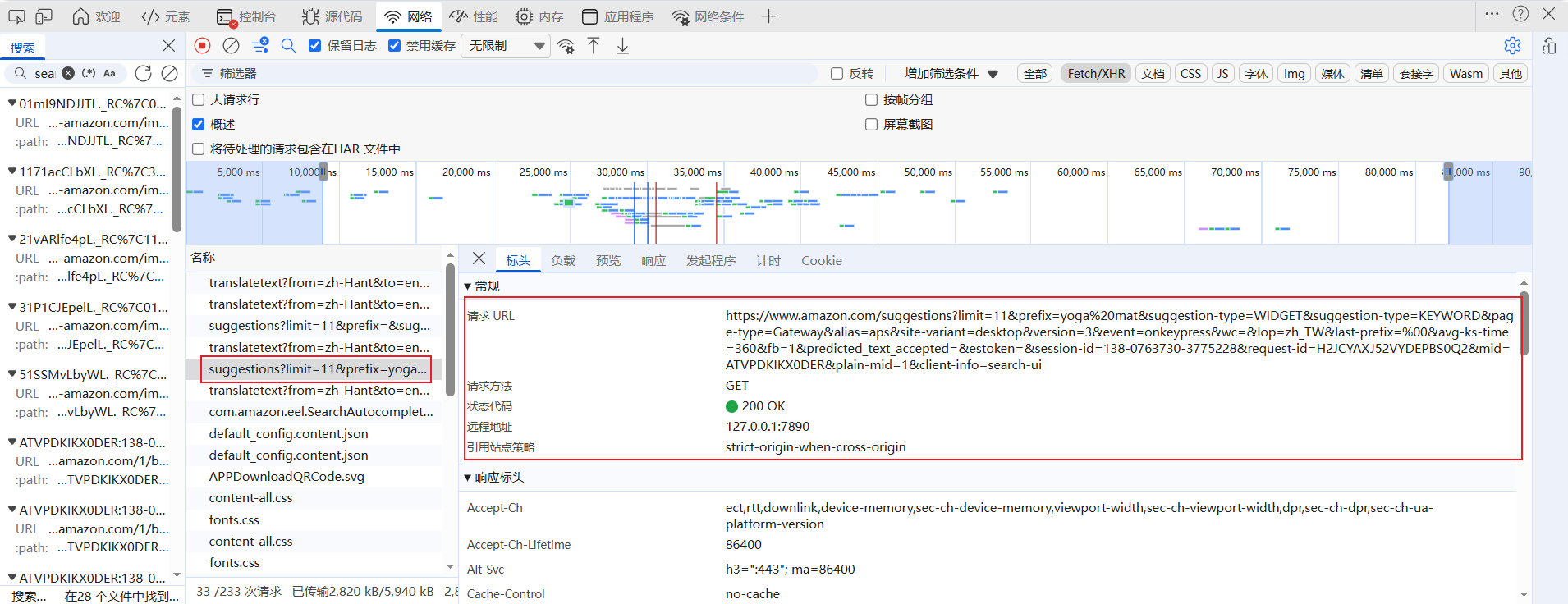
Cookie:包含session-id(会话唯一标识,如138-0763730-3775228)、session-id-time、lc-main(语言区域设置,如zh_TW)、ubid-main等多个字段,是维持用户会话状态的关键凭证,用于 Amazon 平台识别用户身份、保存会话信息(如搜索历史、地域偏好)。
Referer:标识请求的来源页面为 Amazon 主站,用于服务器验证请求的 “出处”,防止跨站请求伪造,同时也会影响平台对请求场景的判断(如主站内的搜索行为)。
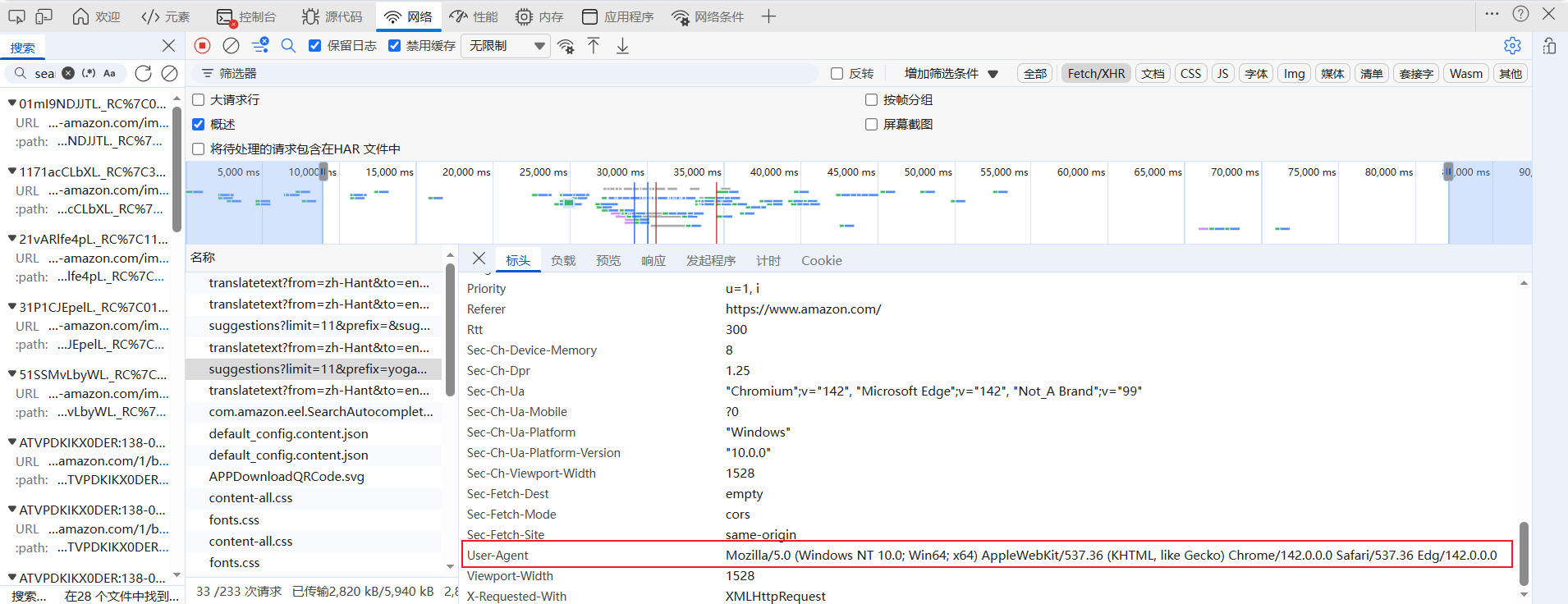
User-Agent:用于模拟浏览器身份,告知服务器当前请求来自“Windows 10 64 位系统下的 Chrome/Edge 浏览器”,是平台识别请求合法性的核心标识之一。
编写采集脚本:
基于上面的 API,利用 requests 和 jsonpath 等库,结合 IPIDEA 代理实现多页、多关键词的高效数据采集,并保存到 CSV 文件。
import requests
import json
import csv
import time
import re
import random
import os
from jsonpath import jsonpath
from concurrent.futures import ThreadPoolExecutor, as_completed
# 获取桌面路径(跨平台兼容)
def get_desktop_path():
if os.name == 'nt': # Windows
return os.path.join(os.path.join(os.environ['USERPROFILE']), 'Desktop')
else: # Mac/Linux
return os.path.join(os.path.join(os.path.expanduser('~')), 'Desktop')
class AmazonProxyCrawler:
def __init__(self, proxy_username, proxy_password, proxy_host="proxy.ipidea.io", proxy_port="2333", max_workers=3):
"""
初始化采集器
:param proxy_username: IPIDEA代理用户名
:param proxy_password: IPIDEA代理密码
:param proxy_host: 代理服务器地址
:param proxy_port: 代理端口
:param max_workers: 最大并发数
"""
self.proxy_username = proxy_username
self.proxy_password = proxy_password
self.proxy_host = proxy_host
self.proxy_port = proxy_port
self.max_workers = max_workers
self.session = requests.Session()
# 配置代理
self.proxies = {
"http": f"http://{proxy_username}:{proxy_password}@{proxy_host}:{proxy_port}",
"https": f"http://{proxy_username}:{proxy_password}@{proxy_host}:{proxy_port}"
}
# 请求头
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36",
"Accept": "application/json, text/plain, */*",
"Accept-Language": "en-US,en;q=0.9",
"Accept-Encoding": "gzip, deflate, br",
"Connection": "keep-alive",
"Referer": "https://www.amazon.com/",
}
self.all_products = []
def get_proxy(self):
"""获取代理配置"""
return self.proxies
def crawl_single_page(self, keyword, page):
"""采集单个关键词的单个页面"""
try:
# Amazon搜索URL
start = (page - 1) * 24
url = f"https://www.amazon.com/s"
params = {
"k": keyword.replace(' ', '+'),
"s": start,
"ref": f"nb_sb_noss_{page}",
"crid": self.generate_random_crid(),
"sprefix": keyword.split()[0] if keyword.split() else keyword
}
# 添加随机延迟
time.sleep(random.uniform(1, 3))
response = self.session.get(
url=url,
headers=self.headers,
params=params,
proxies=self.proxies,
timeout=15,
verify=True
)
if response.status_code != 200:
print(f" 关键词 '{keyword}' 第{page}页采集失败,状态码:{response.status_code}")
return []
# 尝试从页面中提取JSON数据
products = self.extract_from_json(response.text, keyword, page)
if not products:
products = self.extract_from_html(response.text, keyword, page)
print(f" 关键词 '{keyword}' 第{page}页采集完成,获得{len(products)}个商品")
return products
except requests.exceptions.RequestException as e:
print(f" 关键词 '{keyword}' 第{page}页网络请求失败: {e}")
return []
except Exception as e:
print(f"关键词 '{keyword}' 第{page}页采集异常: {e}")
return []
def generate_random_crid(self):
"""生成随机CRID参数"""
import string
return ''.join(random.choices(string.ascii_letters + string.digits, k=10))
def extract_from_json(self, html, keyword, page):
"""从HTML中提取JSON数据"""
try:
# 查找可能的JSON数据块
json_patterns = [
r'var obj = (\{.*?\});',
r'window\.Amazon\.Sidewalk\.widgets\.push\(\s*(\{.*?\})\s*\)',
r'data:\s*(\{.*?\})\s*,',
r'__INITIAL_STATE__\s*=\s*(\{.*?\});'
]
for pattern in json_patterns:
match = re.search(pattern, html, re.DOTALL)
if match:
json_str = match.group(1)
try:
data = json.loads(json_str)
return self.parse_json_data(data, keyword, page)
except json.JSONDecodeError:
continue
return []
except Exception as e:
print(f"JSON提取失败: {e}")
return []
def parse_json_data(self, data, keyword, page):
"""解析JSON数据"""
products = []
# 尝试多种JSON路径来提取商品数据
json_paths = [
'$..results[*]',
'$..products[*]',
'$..items[*]',
'$..searchResults..items[*]',
'$..sections[0].items[*]'
]
for path in json_paths:
items = jsonpath(data, path)
if items and isinstance(items, list):
for item in items:
product = self.extract_product_from_json(item, keyword, page)
if product and product['商品名称'] != 'N/A':
products.append(product)
break
return products
def extract_product_from_json(self, item, keyword, page):
"""从JSON数据中提取商品信息"""
product = {
"关键词": keyword,
"商品名称": jsonpath(item, '$.title') or jsonpath(item, '$.item.title') or "N/A",
"价格": self.extract_price_from_json(item),
"销量": self.extract_sales_from_json(item),
"评分": jsonpath(item, '$.rating') or jsonpath(item, '$.averageRating') or 0,
"评论": jsonpath(item, '$.reviewCount') or jsonpath(item, '$.totalReviews') or 0,
"卖家信息": jsonpath(item, '$.seller') or jsonpath(item, '$.sellerName') or "未知卖家",
"发货地": jsonpath(item, '$.shipping') or jsonpath(item, '$.shipFrom') or "未知",
"ASIN": jsonpath(item, '$.asin') or jsonpath(item, '$.item.asin') or "N/A",
"页码": page
}
# 清理数据
if isinstance(product["商品名称"], list):
product["商品名称"] = product["商品名称"][0] if product["商品名称"] else "N/A"
if isinstance(product["价格"], list):
product["价格"] = product["价格"][0] if product["价格"] else 0.0
if isinstance(product["评分"], list):
product["评分"] = float(product["评分"][0]) if product["评分"] else 0.0
if isinstance(product["评论"], list):
product["评论"] = int(product["评论"][0]) if product["评论"] else 0
if isinstance(product["卖家信息"], list):
product["卖家信息"] = product["卖家信息"][0] if product["卖家信息"] else "未知卖家"
if isinstance(product["发货地"], list):
product["发货地"] = product["发货地"][0] if product["发货地"] else "未知"
if isinstance(product["ASIN"], list):
product["ASIN"] = product["ASIN"][0] if product["ASIN"] else "N/A"
return product
def extract_price_from_json(self, item):
"""从JSON中提取价格"""
price_paths = [
'$.price.current_price',
'$.price.value',
'$.price.amount',
'$.item.price.current_price',
'$.currentPrice'
]
for path in price_paths:
price = jsonpath(item, path)
if price and price[0]:
try:
return float(price[0])
except (ValueError, TypeError):
continue
return 0.0
def extract_sales_from_json(self, item):
"""从JSON中提取销量信息"""
# 尝试获取BSR排名
bsr = jsonpath(item, '$.bsr') or jsonpath(item, '$.salesRank')
if bsr and bsr[0]:
return f"BSR排名: {bsr[0]}"
# 使用评论数作为参考
reviews = jsonpath(item, '$.reviewCount') or jsonpath(item, '$.totalReviews')
if reviews and reviews[0]:
return f"评论数: {reviews[0]}"
return "暂无数据"
def extract_from_html(self, html, keyword, page):
"""备用方法:从HTML中提取商品信息"""
try:
products = []
# 使用正则表达式提取商品信息
asin_pattern = r'data-asin="([A-Z0-9]{10})"'
asins = re.findall(asin_pattern, html)
title_pattern = r'<span[^>]*class="[^"]*a-text-normal[^"]*"[^>]*>(.*?)</span>'
titles = re.findall(title_pattern, html)
price_pattern = r'\$(\d+\.\d{2})'
prices = re.findall(price_pattern, html)
rating_pattern = r'aria-label="([\d.]+) out of 5 stars"'
ratings = re.findall(rating_pattern, html)
review_pattern = r'aria-label="([\d,]+) ratings?"'
reviews = re.findall(review_pattern, html)
# 组合商品信息
min_count = min(len(asins), len(titles), 24)
for i in range(min_count):
product = {
"关键词": keyword,
"商品名称": titles[i].strip() if i < len(titles) else "N/A",
"价格": float(prices[i]) if i < len(prices) else 0.0,
"销量": f"评论数: {reviews[i]}" if i < len(reviews) else "暂无数据",
"评分": float(ratings[i]) if i < len(ratings) else 0.0,
"评论": int(reviews[i].replace(',', '')) if i < len(reviews) else 0,
"卖家信息": "未知卖家",
"发货地": "未知",
"ASIN": asins[i],
"页码": page
}
products.append(product)
return products
except Exception as e:
print(f"HTML提取失败: {e}")
return []
def crawl_keyword_pages(self, keyword, pages):
"""采集单个关键词的多页数据"""
keyword_products = []
print(f"\n{'='*50}")
print(f"开始采集关键词: {keyword}")
print(f"{'='*50}")
for page in range(1, pages + 1):
print(f"正在采集第 {page}/{pages} 页...")
page_products = self.crawl_single_page(keyword, page)
keyword_products.extend(page_products)
# 显示当前页统计
if page_products:
valid_prices = [p["价格"] for p in page_products if p["价格"] > 0]
avg_price = sum(valid_prices) / len(valid_prices) if valid_prices else 0
print(f" 本页采集: {len(page_products)}个商品, 平均价格: ${avg_price:.2f}")
print(f"关键词 '{keyword}' 采集完成,共{len(keyword_products)}个商品")
return keyword_products
def crawl_multiple_keywords(self, keywords_config):
"""多关键词采集主函数"""
all_products = []
print(" 开始多关键词采集(使用IPIDEA代理)")
print("代理配置:", self.proxy_host)
print("关键词配置:")
for keyword, pages in keywords_config.items():
print(f" {keyword}: {pages}页")
# 测试代理连接
if not self.test_proxy_connection():
print(" 代理连接测试失败,请检查代理配置")
return []
# 使用线程池并行采集
with ThreadPoolExecutor(max_workers=self.max_workers) as executor:
future_to_keyword = {
executor.submit(self.crawl_keyword_pages, keyword, pages): (keyword, pages)
for keyword, pages in keywords_config.items()
}
for future in as_completed(future_to_keyword):
keyword, pages = future_to_keyword[future]
try:
keyword_products = future.result()
all_products.extend(keyword_products)
print(f"\n 关键词 '{keyword}' 完成 ({pages}页, {len(keyword_products)}个商品)")
except Exception as e:
print(f"\n 关键词 '{keyword}' 采集失败: {e}")
return all_products
def test_proxy_connection(self):
"""测试代理连接"""
try:
test_url = "http://httpbin.org/ip"
response = self.session.get(test_url, proxies=self.proxies, timeout=10)
if response.status_code == 200:
print(f" 代理连接成功,当前IP: {response.json()['origin']}")
return True
except Exception as e:
print(f"代理连接失败: {e}")
return False
def save_to_csv(self, products, filename):
"""保存数据到CSV"""
if not products:
print(" 无数据可保存")
return False
fieldnames = ["关键词", "商品名称", "价格", "销量", "评分", "评论", "卖家信息", "发货地", "ASIN", "页码"]
try:
with open(filename, "w", newline="", encoding="utf-8-sig") as f:
writer = csv.DictWriter(f, fieldnames=fieldnames)
writer.writeheader()
writer.writerows(products)
print(f"数据已保存到: {filename}")
return True
except Exception as e:
print(f" 保存文件失败: {e}")
return False
def generate_report(self, products):
"""生成采集报告"""
print(f"\n{'='*60}")
print(f" 采集报告")
print(f"{'='*60}")
if not products:
print("无数据可统计")
return
# 按关键词统计
keyword_stats = {}
for product in products:
keyword = product['关键词']
if keyword not in keyword_stats:
keyword_stats[keyword] = []
keyword_stats[keyword].append(product)
print(f" 总商品数: {len(products)}")
print(f" 关键词数量: {len(keyword_stats)}")
print(f"\n各关键词详细统计:")
print("-" * 50)
for keyword, keyword_products in keyword_stats.items():
prices = [p["价格"] for p in keyword_products if p["价格"] > 0]
ratings = [p["评分"] for p in keyword_products if p["评分"] > 0]
reviews = [p["评论"] for p in keyword_products if p["评论"] > 0]
avg_price = sum(prices) / len(prices) if prices else 0
avg_rating = sum(ratings) / len(ratings) if ratings else 0
total_reviews = sum(reviews) if reviews else 0
print(f" {keyword}:")
print(f" 商品数: {len(keyword_products)}")
print(f" 平均价格: ${avg_price:.2f}")
print(f" 平均评分: {avg_rating:.1f}")
print(f" 总评论数: {total_reviews}")
if prices:
print(f" 价格范围: ${min(prices):.2f}-${max(prices):.2f}")
print()
# 使用示例
if __name__ == "__main__":
# IPIDEA代理配置
PROXY_USERNAME = "your_username" # 替换为你的IPIDEA用户名
PROXY_PASSWORD = "your_password" # 替换为你的IPIDEA密码
# 配置要采集的关键词和页数
keywords_config = {
"yoga mat": 3, # 瑜伽垫,采集3页
"resistance bands": 2, # 阻力带,采集2页
"dumbbells": 2, # 哑铃,采集2页
"water bottle": 2, # 水杯,采集2页
"fitness tracker": 2 # 健身手环,采集2页
}
# 创建采集器实例
crawler = AmazonProxyCrawler(
proxy_username=PROXY_USERNAME,
proxy_password=PROXY_PASSWORD,
max_workers=2 # 同时采集2个关键词
)
# 开始采集
start_time = time.time()
all_products = crawler.crawl_multiple_keywords(keywords_config)
end_time = time.time()
# 保存数据
desktop_path = get_desktop_path()
filename = os.path.join(desktop_path, "amazon_proxy_products.csv")
crawler.save_to_csv(all_products, filename)
# 生成报告
crawler.generate_report(all_products)
# 时间统计
total_time = end_time - start_time
print(f"\n 总耗时: {total_time:.1f}秒")
print(f" 文件位置: {filename}")
print(f" IPIDEA代理采集完成!")
运行采集脚本:采用IPIDEA 代理+抓取脚本完成数据采集,获取“yoya mat”关键词的商品信息。
在运行前请确保已安装依赖:
pip install requests jsonpath-ng
下面是完整的IPIDEA代理爬虫脚本,用于采集"yoga mat"关键词的商品信息:
import requests
import json
import csv
import time
import random
import os
import re
from jsonpath import jsonpath
class AmazonIPIDEACrawler:
def __init__(self, proxy_username, proxy_password, proxy_host="proxy.ipidea.io", proxy_port="2333"):
"""
初始化IPIDEA代理提取
:param proxy_username: IPIDEA用户名
:param proxy_password: IPIDEA密码
:param proxy_host: 代理服务器地址
:param proxy_port: 代理端口
"""
self.proxy_username = proxy_username
self.proxy_password = proxy_password
self.proxy_host = proxy_host
self.proxy_port = proxy_port
# 配置IPIDEA代理
self.proxies = {
"http": f"http://{proxy_username}:{proxy_password}@{proxy_host}:{proxy_port}",
"https": f"http://{proxy_username}:{proxy_password}@{proxy_host}:{proxy_port}"
}
# 请求头配置
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
"Accept-Language": "en-US,en;q=0.9",
"Accept-Encoding": "gzip, deflate, br",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": "1",
"Referer": "https://www.amazon.com/",
}
self.session = requests.Session()
self.collected_products = []
print("=" * 60)
print(" Amazon商品采集脚本 - IPIDEA代理")
print("=" * 60)
def test_proxy_connection(self):
"""测试IPIDEA代理连接"""
print(" 测试IPIDEA代理连接...")
try:
test_url = "http://httpbin.org/ip"
response = self.session.get(
test_url,
proxies=self.proxies,
timeout=10,
headers={"User-Agent": self.headers["User-Agent"]}
)
if response.status_code == 200:
ip_info = response.json()
print(f"IPIDEA代理连接成功!")
print(f" 当前代理IP: {ip_info['origin']}")
return True
else:
print(f" 代理测试失败,状态码: {response.status_code}")
return False
except Exception as e:
print(f" 代理连接异常: {e}")
return False
def crawl_amazon_products(self, keyword, pages=5):
"""
采集Amazon商品信息
:param keyword: 搜索关键词
:param pages: 采集页数
:return: 商品数据列表
"""
print(f"\n开始采集关键词: {keyword}")
print(f" 计划采集页数: {pages}")
all_products = []
for page in range(1, pages + 1):
print(f"\n 正在采集第 {page}/{pages} 页...")
try:
# 构造搜索URL
start_index = (page - 1) * 24
url = "https://www.amazon.com/s"
params = {
"k": keyword.replace(" ", "+"),
"s": start_index,
"ref": f"nb_sb_noss_{page}",
"crid": self.generate_random_id(),
"qid": int(time.time())
}
# 发送请求(使用IPIDEA代理)
response = self.session.get(
url,
params=params,
headers=self.headers,
proxies=self.proxies,
timeout=15,
verify=True
)
if response.status_code == 200:
products = self.parse_products(response.text, keyword, page)
all_products.extend(products)
print(f" 第{page}页采集完成,获得{len(products)}个商品")
# 显示本页商品示例
if products:
for i, product in enumerate(products[:3]): # 显示前3个商品
print(f" {i+1}. {product['商品名称'][:50]}... - ${product['价格']}")
else:
print(f" 第{page}页请求失败,状态码: {response.status_code}")
# 随机延迟,避免请求过快
delay = random.uniform(2, 5)
print(f" 等待{delay:.1f}秒后继续...")
time.sleep(delay)
except requests.exceptions.Timeout:
print(f" 第{page}页请求超时")
except requests.exceptions.ConnectionError:
print(f" 第{page}页连接错误")
except Exception as e:
print(f" 第{page}页采集异常: {e}")
print(f"\n 关键词 '{keyword}' 采集完成!")
print(f"总共采集到 {len(all_products)} 个商品")
return all_products
def generate_random_id(self):
"""生成随机ID"""
import string
return ''.join(random.choices(string.ascii_letters + string.digits, k=10))
def parse_products(self, html_content, keyword, page):
"""解析商品数据"""
products = []
try:
# 方法1: 尝试从JSON数据中提取
json_products = self.extract_from_json(html_content, keyword, page)
if json_products:
return json_products
# 方法2: 从HTML中提取
return self.extract_from_html(html_content, keyword, page)
except Exception as e:
print(f" 解析商品数据失败: {e}")
return []
def extract_from_json(self, html_content, keyword, page):
"""从JSON数据中提取商品信息"""
try:
# 查找JSON数据
json_patterns = [
r'var obj = (\{.*?\});',
r'data:\s*(\{.*?\})\s*,',
r'window\.Amazon\.Sidewalk\.widgets\.push\(\s*(\{.*?\})\s*\)'
]
for pattern in json_patterns:
match = re.search(pattern, html_content, re.DOTALL)
if match:
json_str = match.group(1)
try:
data = json.loads(json_str)
return self.parse_json_data(data, keyword, page)
except json.JSONDecodeError:
continue
return []
except Exception as e:
return []
def parse_json_data(self, data, keyword, page):
"""解析JSON数据"""
products = []
# 尝试多种JSON路径
json_paths = [
'$..results[*]',
'$..products[*]',
'$..items[*]',
'$..searchResults..items[*]'
]
for path in json_paths:
items = jsonpath(data, path)
if items and isinstance(items, list):
for item in items:
product = self.create_product_from_json(item, keyword, page)
if product:
products.append(product)
break
return products
def create_product_from_json(self, item, keyword, page):
"""从JSON创建商品对象"""
try:
# 提取商品名称
title = self.extract_json_value(item, ['title', 'item.title', 'name'])
# 提取价格
price = self.extract_price_from_json(item)
# 提取评分
rating = self.extract_json_value(item, ['rating', 'averageRating', 'stars'])
if rating:
rating = float(rating) if isinstance(rating, (int, float)) else 0.0
# 提取评论数
reviews = self.extract_json_value(item, ['reviewCount', 'totalReviews', 'reviews'])
if reviews:
reviews = int(reviews) if isinstance(reviews, (int, float)) else 0
# 提取ASIN
asin = self.extract_json_value(item, ['asin', 'item.asin', 'productId'])
product = {
"关键词": keyword,
"商品名称": title or "未知商品",
"价格": price,
"销量": f"评论数: {reviews}" if reviews else "暂无数据",
"评分": rating or 0.0,
"评论": reviews or 0,
"卖家信息": self.extract_json_value(item, ['seller', 'sellerName', 'brand']) or "未知卖家",
"发货地": self.extract_json_value(item, ['shipping', 'shipFrom', 'location']) or "未知",
"ASIN": asin or "N/A",
"页码": page
}
return product if product['商品名称'] != "未知商品" else None
except Exception as e:
return None
def extract_json_value(self, data, keys):
"""从JSON数据中提取值"""
for key in keys:
value = jsonpath(data, f"$.{key}")
if value and value[0]:
return value[0]
return None
def extract_price_from_json(self, item):
"""从JSON中提取价格"""
price_paths = [
'price.current_price',
'price.value',
'price.amount',
'currentPrice',
'item.price.current_price'
]
for path in price_paths:
price = jsonpath(item, f"$.{path}")
if price and price[0]:
try:
return float(price[0])
except (ValueError, TypeError):
continue
return 0.0
def extract_from_html(self, html_content, keyword, page):
"""从HTML中提取商品信息"""
products = []
try:
# 提取ASIN
asin_pattern = r'data-asin="([A-Z0-9]{10})"'
asins = re.findall(asin_pattern, html_content)
# 提取商品名称
title_pattern = r'<span[^>]*class="[^"]*a-text-normal[^"]*"[^>]*>(.*?)</span>'
titles = re.findall(title_pattern, html_content)
# 提取价格
price_pattern = r'\$(\d+\.\d{2})'
prices = re.findall(price_pattern, html_content)
# 提取评分
rating_pattern = r'aria-label="([\d.]+) out of 5 stars"'
ratings = re.findall(rating_pattern, html_content)
# 提取评论数
review_pattern = r'(\d+,?\d*)\s*ratings?'
reviews = re.findall(review_pattern, html_content)
# 组合商品信息
min_count = min(len(asins), len(titles), 20)
for i in range(min_count):
product = {
"关键词": keyword,
"商品名称": titles[i].strip() if i < len(titles) else "未知商品",
"价格": float(prices[i]) if i < len(prices) else 0.0,
"销量": f"评论数: {reviews[i]}" if i < len(reviews) else "暂无数据",
"评分": float(ratings[i]) if i < len(ratings) else 0.0,
"评论": int(reviews[i].replace(',', '')) if i < len(reviews) else 0,
"卖家信息": "未知卖家",
"发货地": "未知",
"ASIN": asins[i] if i < len(asins) else "N/A",
"页码": page
}
products.append(product)
return products
except Exception as e:
print(f"HTML解析失败: {e}")
return []
def save_to_csv(self, products, filename):
"""保存数据到CSV文件"""
if not products:
print(" 无数据可保存")
return False
try:
# 确保目录存在
os.makedirs(os.path.dirname(filename) if os.path.dirname(filename) else '.', exist_ok=True)
with open(filename, 'w', newline='', encoding='utf-8-sig') as csvfile:
fieldnames = ["关键词", "商品名称", "价格", "销量", "评分", "评论", "卖家信息", "发货地", "ASIN", "页码"]
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
writer.writerows(products)
print(f" 数据已保存到: {filename}")
return True
except Exception as e:
print(f" 保存文件失败: {e}")
return False
def generate_report(self, products):
"""生成采集报告"""
if not products:
print(" 无数据可生成报告")
return
print(f"\n{'='*60}")
print(f" 采集报告")
print(f"{'='*60}")
# 基本统计
total_products = len(products)
products_with_price = len([p for p in products if p['价格'] > 0])
products_with_rating = len([p for p in products if p['评分'] > 0])
print(f" 总商品数: {total_products}")
print(f" 有价格商品: {products_with_price} ({products_with_price/total_products*100:.1f}%)")
print(f" 有评分商品: {products_with_rating} ({products_with_rating/total_products*100:.1f}%)")
# 价格统计
prices = [p['价格'] for p in products if p['价格'] > 0]
if prices:
print(f"\n 价格分析:")
print(f" 最高价: ${max(prices):.2f}")
print(f" 最低价: ${min(prices):.2f}")
print(f" 平均价: ${sum(prices)/len(prices):.2f}")
# 评分统计
ratings = [p['评分'] for p in products if p['评分'] > 0]
if ratings:
print(f"\n 评分分析:")
print(f" 最高分: {max(ratings):.1f}")
print(f" 最低分: {min(ratings):.1f}")
print(f" 平均分: {sum(ratings)/len(ratings):.1f}")
def main():
"""主函数"""
# IPIDEA代理配置 - 请替换为你的实际账号
PROXY_USERNAME = "your_username_here" # 替换为你的IPIDEA用户名
PROXY_PASSWORD = "your_password_here" # 替换为你的IPIDEA密码
# 创建采集器实例
crawler = AmazonIPIDEACrawler(
proxy_username=PROXY_USERNAME,
proxy_password=PROXY_PASSWORD
)
# 测试代理连接
if not crawler.test_proxy_connection():
print(" 代理连接失败,请检查账号配置")
return
# 采集配置
KEYWORD = "yoga mat"
PAGES = 5 # 采集5页数据
print(f"\n 开始采集: {KEYWORD}")
print(f" 采集页数: {PAGES}")
print(f" 开始时间: {time.strftime('%Y-%m-%d %H:%M:%S')}")
# 开始采集
start_time = time.time()
products = crawler.crawl_amazon_products(KEYWORD, PAGES)
end_time = time.time()
# 保存数据
if products:
desktop_path = os.path.join(os.path.expanduser("~"), "Desktop")
filename = os.path.join(desktop_path, f"amazon_{KEYWORD.replace(' ', '_')}_products.csv")
if crawler.save_to_csv(products, filename):
# 生成报告
crawler.generate_report(products)
# 时间统计
total_time = end_time - start_time
print(f"\n 采集耗时: {total_time:.1f}秒")
print(f" 文件位置: {filename}")
print(f" 采集任务完成!")
else:
print(" 数据保存失败")
else:
print(" 未采集到任何商品数据")
if __name__ == "__main__":
main()
三、DeepSeek AI深度数据分析与洞察提炼
采集到数据只是第一步,关键是怎么从数据里挖出能指导选品的洞察—— 这步我全靠 DeepSeek。
3.1 数据清洗与结构化
第一步:准备工具和数据
首先,导入需要的 Pandas 库,用于数据处理。然后将采集到的原始数据csv文件读取进来。
import pandas as pd
import sys
from io import StringIO
# 加载数据集
df = pd.read_csv('这里替换成你的数据文件路径')
第二步:读取数据并**“摸底”**
把原始数据读入后,我查看了数据的基本信息,包括有多少行多少列、各个字段的非空值数量以及数据类型等,还统计了每个字段的缺失值数量,并且看了前几行数据,从而直观地了解数据中可能存在的问题。
# 1. 捕获数据基本信息
info_buffer = StringIO()
df.info(buf=info_buffer)
basic_info_lines = info_buffer.getvalue().split('\n') # 按行分割文本
# 把基本信息整理成DataFrame
basic_info_data = {
"info_type": [
"data_frame_info", "total_rows", "total_columns", "column_details"
],
"content": [
basic_info_lines[0], # DataFrame类型信息
f"Total rows: {df.shape[0]}", # 总行数
f"Total columns: {df.shape[1]}", # 总列数
"\n".join(basic_info_lines[3:-2]) # 列详情(字段名、非空值、类型)
]
}
basic_info_df = pd.DataFrame(basic_info_data)
# 2. 准备数据预览内容(短表存全量,长表存前10行)
rows, columns = df.shape
if rows < 100 and columns < 20:
preview_df = df # 短表:全量数据
else:
preview_df = df.head(10) # 长表:前10行数据
# 4. 控制台实时打印
print("=== 数据基本信息 ===")
print(info_buffer.getvalue())
print("\n" + "="*50)
print(f"Total rows: {rows}\nTotal columns: {columns}")
print("\n" + "="*50)
print("=== 数据预览(前10行/全量) ===")
print(preview_df)
结果:
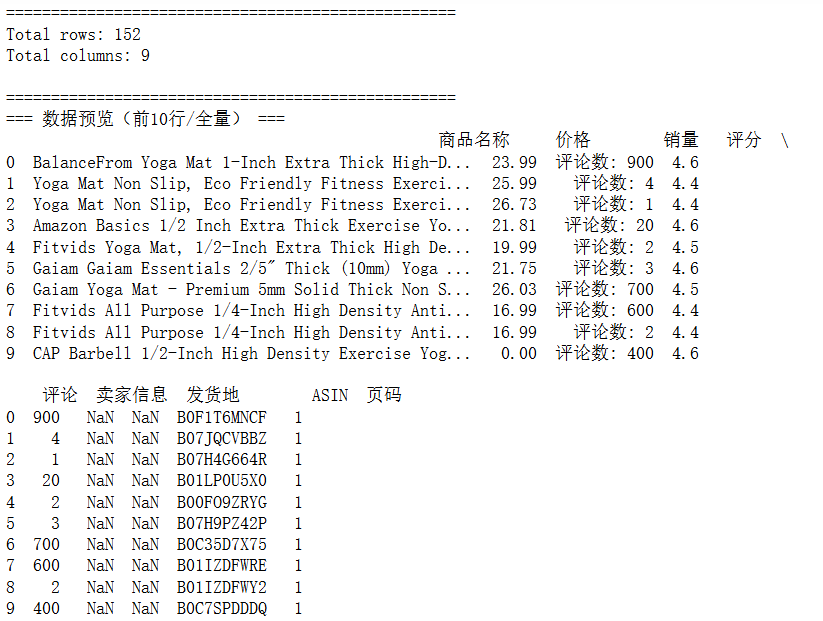
运行代码后发现,数据集中有 152 行 9 列,推测参与分析的字段为商品名称、价格、销量、评分、评论和ASIN。而卖家信息和发货地整列均为缺失值,同时销量列包含非数值内容,如 “评论数: 900” 这样的格式。
第三步:数据清洗
针对上面运行的结果,我分步骤处理,每一步都有明确的目的,避免盲目删改数据。
# 定义清洗后文件的桌面路径
cleaned_data_csv = desktop_path + "amazon_yoga_mat_product_cleaned.csv"
# 1. 删除全空列(axis=1按列,how='all'全为空才删除)
df.dropna(axis=1, how='all', inplace=True)
# 2. 清洗“销量”列:提取数字部分,转为浮点型(处理“评论数: 900”格式)
df['销量'] = df['销量'].str.extract('(\d+)', expand=False).astype(float)
# 3. 删除重复行(按全字段去重,保留第一条)
df = df.drop_duplicates()
# 4. 验证清洗效果
print("\n" + "="*50)
print("=== 清洗后的数据概况 ===")
print(df.info())
print(f"\n=== 清洗后剩余数据量:{len(df)} 行 ===")
print("\n=== 清洗后前5行数据 ===")
print(df.head())
# 5. 保存清洗后的数据到桌面CSV
df.to_csv(cleaned_data_csv, index=False, encoding='utf-8-sig')
print(f"\n数据清洗完成!")
print(f"清洗后的数据已保存到桌面:{cleaned_data_csv}")
结果:
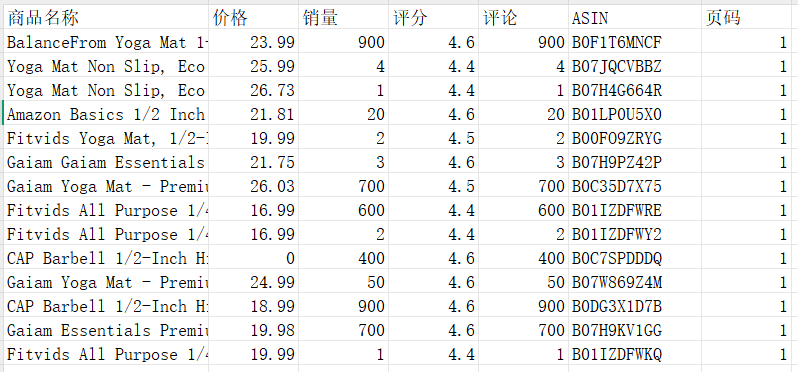
3.2 DeepSeek AI 辅助分析实战
数据清洗完成后,151 条规整的瑜伽垫数据就成了选品的 “原料”—— 但这些数据里藏着的用户需求、产品痛点、市场趋势,手动分析要花好几天,还容易遗漏关键信息。我用 DeepSeek AI 搭建了 “高频词分析 + 情感倾向分析 + 趋势预测” 的三维框架,快速把数据转化成可落地的选品决策,下面是我完整的实操过程。
1. 高频词分析:从商品标题里抓用户核心需求
用户买瑜伽垫时,会更关注哪些特性?光看几条标题看不出来,但把 151 条商品标题交给 DeepSeek,就能快速提炼出共性需求。
我的提问:

DeepSeek的回答:

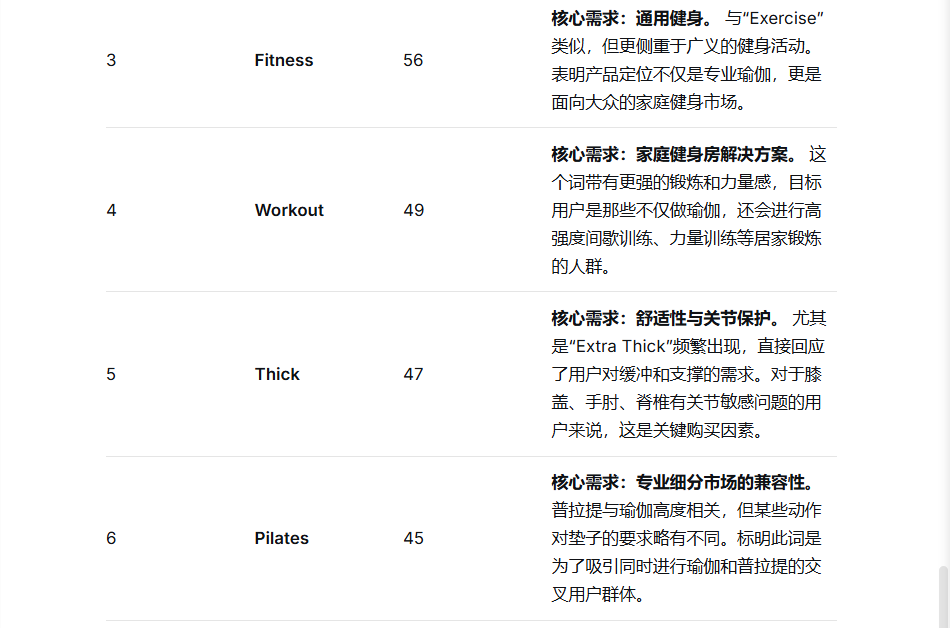
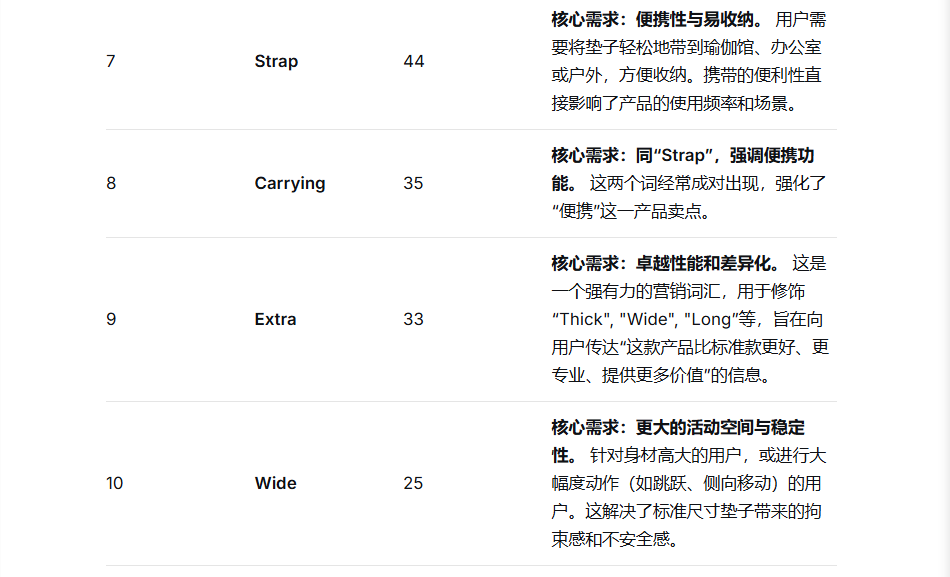


2. 情感倾向分析:
我的提问:

DeepSeek的回答:
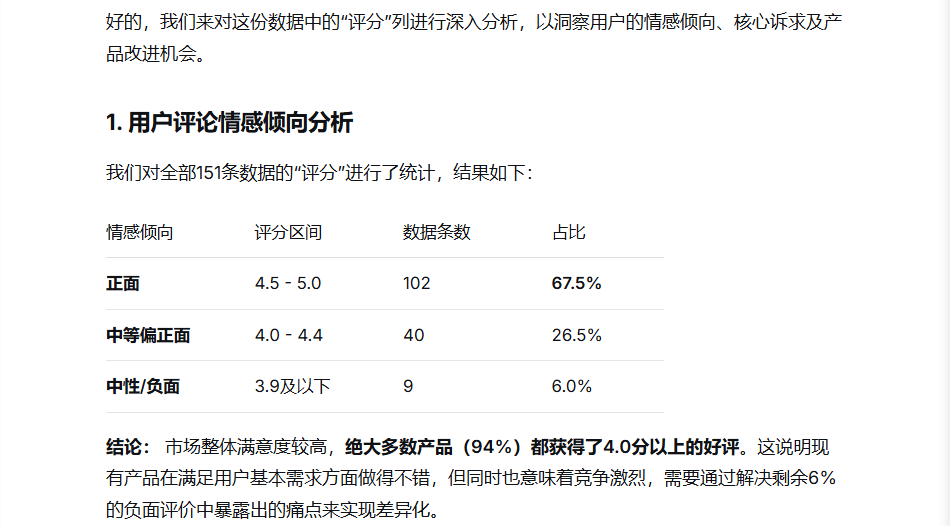


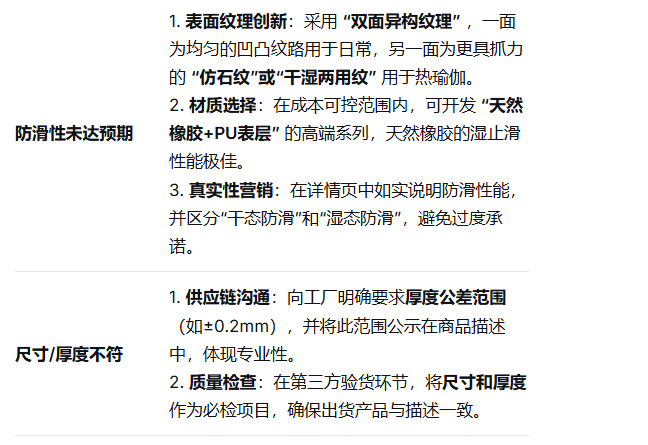
3. 趋势预测:
我的提问:

DeepSeek的回答:
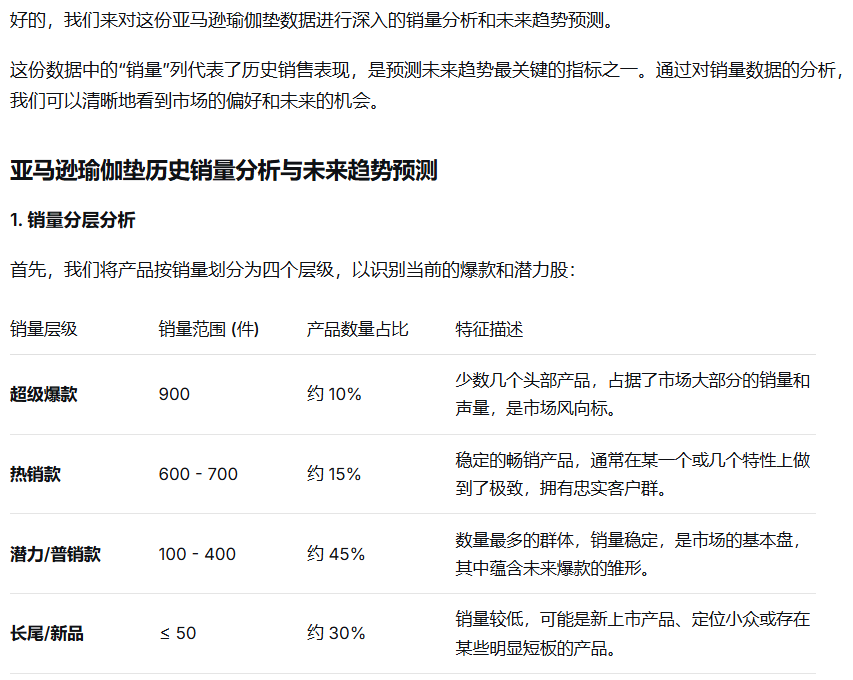


3.3 选品决策总结
用IPIDEA拿到真实数据,DeepSeek分析出两个核心方向——“防滑加厚家用款”(1/2-1英寸厚,高好评)和“便携旅行款”(带耐用背带),还指出要解决低价款异味、换涤纶背带。但这些只是参考,得我来落地。
先靠经验筛掉不现实的:AI提的“专业瑜伽馆款”虽评分高,但要进口橡胶(成本高50%)、需定制,我的中端客群和供应链接不住,直接排除。接着对接供应链验证:防异味工艺加$1.2/件、起订500件,我资金和物流能扛;背带换涤纶,工厂有现货不用等,这才定了改进点。
最后留容错:AI建议Q4备2500件,我知道黑五物流慢,提前10天订还只备2000件;AI说不用加额外功能,我还是加了对齐标记——去年做瑜伽砖时,带标记的复购率高20%,这是AI没挖到的经验。
说到底,AI是省时间的工具,怎么选、能不能做,得看我对市场的判断和供应链的把控,决策权始终在我手里。
四、总结与展望
4.1 实践总结
本次通过数据驱动的市场分析,让我得以超越个人经验,更清晰地洞察市场本质。整个过程的核心价值在于构建了一个高效的决策闭环:
1. 效率提升: AI工具快速完成了海量信息的清洗与归类,让我从繁琐的“看数据”中解放出来,将精力聚焦于更具价值的“用数据”上。
2. 洞察深化: 高频词分析等技术,将模糊的市场感觉转化为精确的用户需求图谱,揭示了诸如“防滑是基础诉求,但厚度与尺寸是消费升级关键”等深层逻辑。
3. 决策优化: 最终,数据提供了方向,而我的角色是结合自身供应链和运营能力,在“想做什么”与“能做什么”之间找到最佳平衡点,做出了主攻“中高端多功能市场”这一务实决策。
这次实践印证了,将数据分析能力与商业判断相结合,是应对未来复杂竞争环境的必备素养。
同时,也欢迎大家体验IPIDEA:http://co.ipidea.net/?utm-source=zbkl&utm-keyword=?zbkl
4.2 未来展望
这次实战让我明确了未来的发展方向。我将把“数据驱动决策”深度融入业务流程,让“IPIDEA+DeepSeek”成为团队的标准配置。接下来,我会把分析重点延伸到用户评论,通过AI解读真实反馈,精准把握用户痛点。同时建立动态监测体系,持续追踪竞品动态,从“一次性分析”升级为“持续性洞察”。最终目标是构建高效的“人机协同”系统——我负责战略把控,AI担当分析外脑。这样的组合将帮助我们在复杂多变的市场中保持敏锐洞察,快速应对挑战。
这条路刚刚开始,但我相信,掌握正确方法论的团队必将在未来竞争中占据先机。

为武汉地区的开发者提供学习、交流和合作的平台。社区聚集了众多技术爱好者和专业人士,涵盖了多个领域,包括人工智能、大数据、云计算、区块链等。社区定期举办技术分享、培训和活动,为开发者提供更多的学习和交流机会。
更多推荐

 19
19 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)