怎样为你的 RAG 应用选择合适的嵌入模型?
01 什么是嵌入?
嵌入是一种能够捕捉语言含义与规律的数字表征。这些数字能帮助你的系统找到与问题或主题密切相关的信息。
这类嵌入是通过嵌入模型生成的。嵌入模型可以接收文字、图像、文档甚至声音,并将其转化为一系列称为 "向量" 的数字。
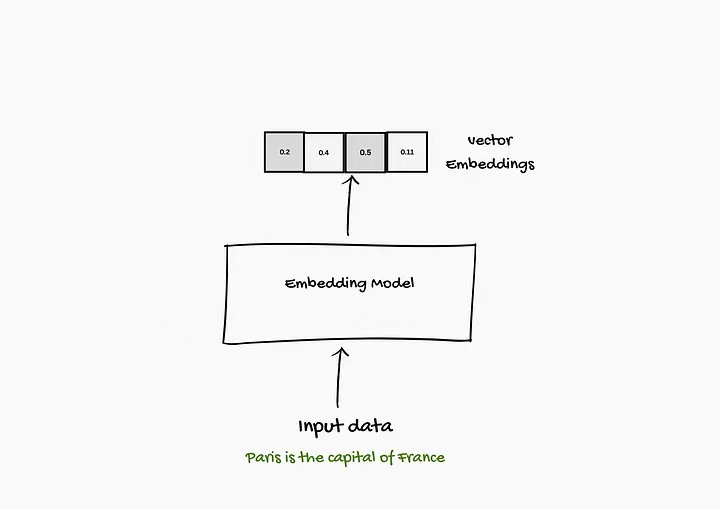
什么是嵌入? --- 该图片由原文作者提供
你可能是在了解大语言模型时接触到 "嵌入" 这一概念的,但实际上,嵌入的历史要悠久得多。
02 这些嵌入是如何被计算出来的?
目前,嵌入主要通过语言模型来生成。
与使用静态向量表示每个词元或单词不同,语言模型会动态地生成上下文关联的词嵌入 ------ 即根据不同的语境,用不同的向量来表征单词 / 句子 / 文本块。这些向量随后可被其他系统用于各类任务。
生成文本嵌入向量的方法有多种。最常见的一种是对模型生成的所有词元嵌入值取平均值。但高质量的文本嵌入模型往往是专门针对文本嵌入任务训练的。
我们可以使用 sentence-transformers [1](一个被广泛使用的预训练嵌入模型工具包)来生成文本嵌入。
from sentence_transformers import SentenceTransformer
# Load model
model = SentenceTransformer("sentence-transformers/all-mpnet-base-v2")
# Convert text to text embeddings
vector = model.encode("Best movie ever!")
嵌入向量所含的数值数量(即维度)取决于底层嵌入模型。可通过 vector.shape 方法获取嵌入向量的维度信息。
03 为何在 RAG 系统中嵌入非常重要?
嵌入在检索增强生成(RAG)系统中发挥着非常关键的作用,原因如下:
语义理解:嵌入将词语、句子或文档转化为向量(数字序列),并使语义相近的内容在向量空间中彼此靠近。这使系统能够理解上下文和语义,而非仅仅进行字面匹配。
高效检索:RAG 需要快速定位最相关的文本段落或文档。嵌入能通过 k 近邻(k-NN)等算法实现高效检索,让检索过程更快速便捷。
让回答更精准且切题:借助嵌入技术,模型能够识别与问题语义相关的信息,即使表述用语完全不同。这意味着用户能获得更精准且切题的回答。
04 嵌入的类型
嵌入具有多种形式,具体取决于系统需要处理的信息类型。
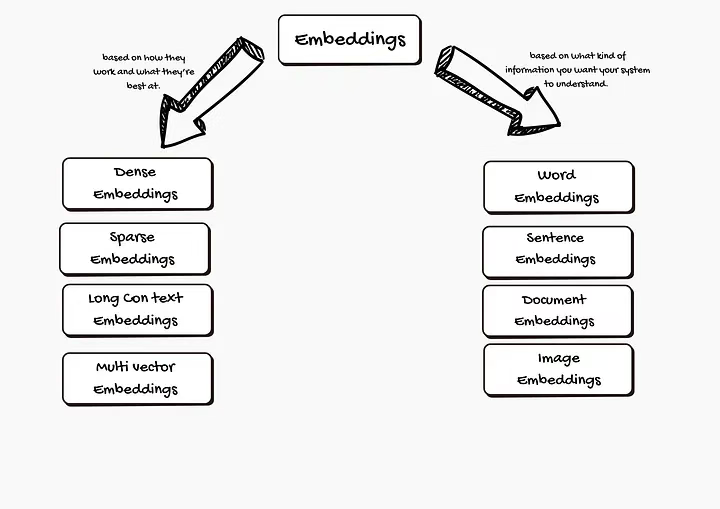
嵌入的类型 ------ 由原文作者供图
1. 基于系统需理解的信息类型划分:
1.1 词嵌入
词嵌入将每个词语表示为多维空间中的一个点。含义相近的词语(如 "dog" 和 "cat")在空间中的位置会彼此靠近。这有助于计算机理解词语之间的语义关联,而不仅是拼写形式。
流行的词嵌入模型包括:
- Word2Vec:从大量文本中学习词语关系。
- GloVe:重点关注词语共同出现的频率。
- FastText:将词语分解为更小的组成部分,能更有效处理生僻词或拼写错误的词语。
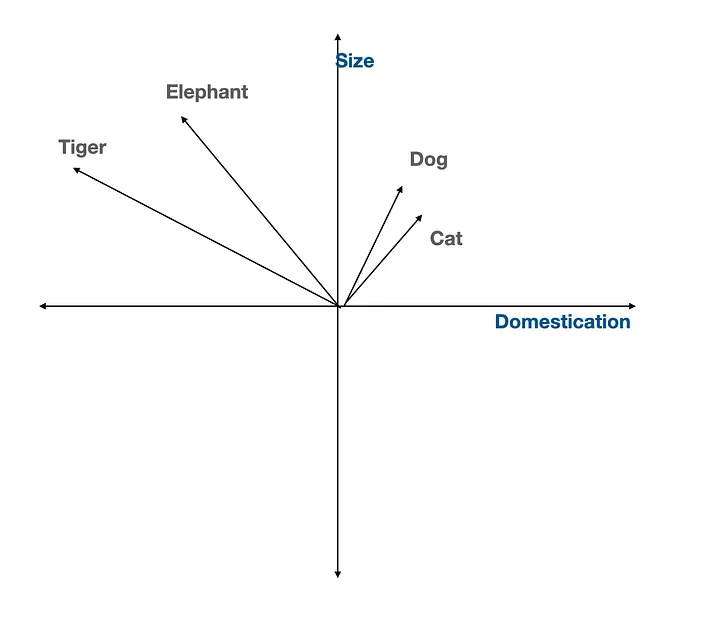
向量嵌入空间 ------ 由原文作者供图
1.2 句嵌入
有时,需要从整个句子而不仅是单个单词来理解完整语义。句嵌入将一个句子的整体语义捕获为一个向量。
知名的生成句嵌入的模型有:
- Universal Sentence Encoder(USE) :适用于各种类型的句子,包括疑问句和陈述句。
- SkipThought:通过学习预测前面和后面可能出现的句子,来理解语境和用户意图。
1.3 文档嵌入
文档可以是一个段落乃至整本书。文档嵌入将所有文本转化为单个向量,便于在大型文档库中进行搜索,并查找与查询相关的内容。
主流的文档嵌入模型包括:
- Doc2Vec:基于 Word2Vec 构建,但专为较长文本设计。
- Paragraph Vectors:与 Doc2Vec 类似,但侧重于段落等较短文本。
1.4 图像嵌入
RAG 系统不仅能处理文本,也能处理图像。图像嵌入将图片转换为描述颜色、形状和图案的数字序列。
常用的生成图像嵌入的模型是卷积神经网络(CNNs),它特别擅长识别图像中的模式。
2. 基于嵌入的特性划分:
嵌入可以具有不同的特性,这些特性会影响其工作方式和适用场景。以下通过简单示例说明这些特性:
2.1 稠密嵌入
稠密嵌入使用的向量中,几乎每个位置都填充了有效数值。每个数值都承载着关于词语、句子、图像或文档的一点信息。稠密向量紧凑且高效,能在较小空间内存储大量细节内容,使计算机能更轻松地进行比对并快速发现相似性。
2.2 稀疏嵌入
稀疏嵌入与稠密嵌入相反。向量中大多数数值为零,仅有少数位置有实际数值。零值不携带任何信息。稀疏嵌入有助于突出最关键的特征,易于识别事物的独特之处。
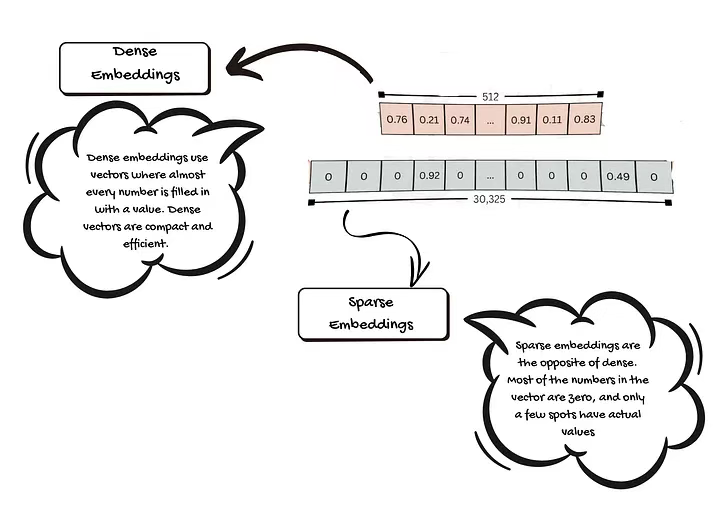
稠密嵌入与稀疏嵌入 ------ 由原文作者供图
2.3 长上下文嵌入
有时需要理解整个文档或长对话,而不仅仅是短句。长上下文嵌入就是专为一次性处理大量文本而设计的。
旧模型只能处理短文本。如若输入长文章,需将它们先切分成小块,这可能导致旧模型遗漏重要的上下文关联,或者偏离文章的核心主旨。新模型(如 BGE-M3)可一次性处理数千词(最高达 8,192 个词元),有助于计算机把握整体语境。
2.4 多向量嵌入
通常,一个项目(如一个单词或一篇文档)仅对应一个向量。而多向量嵌入则为每个项目使用多个向量,每个向量可捕获不同的特征。
通过多个向量,计算机能识别更多的细节和更复杂的关系,从而产生更丰富、更准确的结果。
05 选择最佳文本嵌入模型需要了解的参数
在选择模型之前,您需要明确评估标准。以下是几个关键的参数:
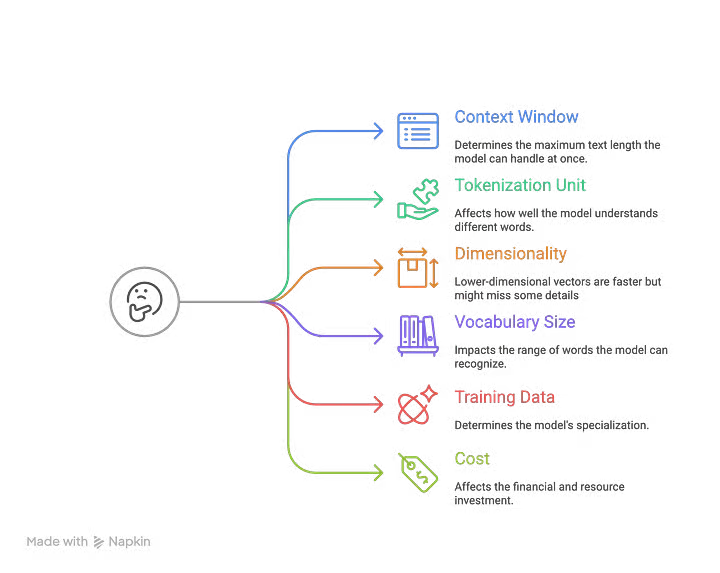
如何选择最佳的文本嵌入模型? ------ 该图片由原文作者提供,使用 Napkin.ai 制作
5.1 上下文窗口
上下文窗口是指模型单次能处理的最大文本长度。 例如,若某模型的上下文窗口为 512 个词元,意味着它一次只能读取 512 个词语或词语片段。更长的文本必须被切分。有些模型(如 OpenAI 的 text-embedding-ada-002,支持一次读取 8192 个词元)和 Cohere 的嵌入模型(支持一次读取 4096 个词元)则能处理更长的文本。
更大的上下文窗口允许处理更长的文档而避免信息丢失。这对于检索长篇文章、研究论文或报告等任务非常有利。
5.2 分词单元
分词是模型将文本切分为更小单元(称为词元)的方式。 不同模型采用不同的方法:
- Subword Tokenization(例如字节对编码 BPE):将词语拆分成更小的部分。例如,"unhappiness" 会被拆为 "un" 和 "happiness"。这有助于处理生僻词或新词。
- WordPiece:与 BPE 类似,但常用于 BERT 等模型。
- Word-Level Tokenization:将文本按完整单词进行切分。对生僻词处理效果不佳。
模型的分词方式影响其理解不同词语(尤其是非常用词)的能力。大多数现代模型为了提升灵活性而采用 subword tokenization 方法。
5.3 向量维度
向量维度是指模型为每段文本生成的数字序列(向量)的长度。 例如,有些模型生成 768 维的向量,有些则生成 1024 维甚至 3072 维的向量。
更高维度的向量能存储更详细的信息,但需要更强的计算能力。较低维度的向量处理速度更快,但可能丢失部分细节信息。
5.4 词表大小
这是模型所能识别的唯一词元的数量。 更大的词表能处理更多词汇和语言,但会占用更多内存。较小的词表处理速度更快,但可能无法理解生僻词或专业术语。
例如:大多数现代模型的词表大小在 3 万到 5 万个词元之间。

为武汉地区的开发者提供学习、交流和合作的平台。社区聚集了众多技术爱好者和专业人士,涵盖了多个领域,包括人工智能、大数据、云计算、区块链等。社区定期举办技术分享、培训和活动,为开发者提供更多的学习和交流机会。
更多推荐
 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)