Java面试实录:Spring AI与测试框架在数据分析平台中的深度应用
本文通过模拟互联网大厂Java开发工程师面试场景,深度解析Spring AI与测试框架在数据分析平台中的实际应用。包含三轮技术面试对话,详细讲解RAG架构、向量数据库优化、测试框架最佳实践等核心技术,提供完整的代码示例和架构设计思路。
Java面试实录:Spring AI与测试框架在数据分析平台中的深度应用
📋 面试背景
公司背景:某头部互联网大厂的数据智能部门,正在招聘Java开发工程师,负责构建新一代数据分析平台的AI能力。
岗位要求:
- 精通Java开发,熟悉Spring生态
- 有AI/ML项目经验,熟悉RAG、向量数据库等技术
- 掌握测试框架,能够构建高可靠的数据处理系统
- 具备大数据平台开发经验者优先
🎭 面试实录
第一轮:基础概念考查
面试官:你好小润龙,欢迎参加我们的面试。首先请你简单介绍一下你对Spring AI的理解。
小润龙:Spring AI啊,这个我知道!就是让Spring应用变得更"聪明"的框架,就像给Spring加了个AI大脑一样。它主要提供了统一的API来调用各种AI模型,比如OpenAI、Azure AI这些。
面试官:不错,那你能具体说说RAG(检索增强生成)的工作原理吗?
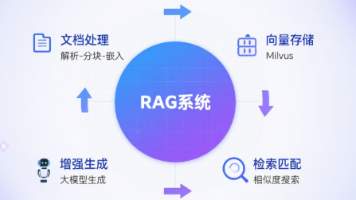
小润龙:RAG嘛,就像是给AI配了个"参考书"。当用户问问题时,AI不是凭空回答,而是先去向量数据库里找相关的文档,然后基于这些文档内容来生成答案。这样回答就更准确,不容易"胡说八道"。
面试官:很形象的比喻。那向量数据库在其中扮演什么角色?
小润龙:向量数据库就是那个"参考书库",它把文档内容转换成向量形式存储,然后通过相似度搜索快速找到最相关的文档。就像图书馆的索引系统一样。
面试官:好的,我们再聊聊测试框架。你在数据分析平台中如何使用JUnit 5进行单元测试?
小润龙:JUnit 5我用得可熟了!比如测试数据转换函数时,我会用@Test注解,然后用@ParameterizedTest测试不同的输入情况。数据分析平台的数据处理逻辑复杂,测试覆盖率很重要。
第二轮:实际应用场景
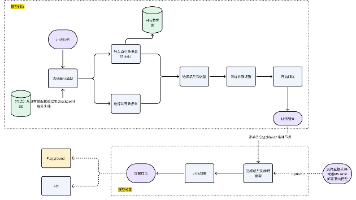
面试官:现在我们来讨论实际应用。假设我们要在数据分析平台中构建一个智能文档问答系统,你会如何设计架构?
小润龙:这个我思考过!我会用Spring AI的VectorStore来存储文档向量,然后用RAG模式构建问答服务。具体来说:
- 文档预处理:用Spring AI的DocumentReader读取文档
- 向量化:使用EmbeddingModel生成向量
- 存储:存入向量数据库(比如Redis或Cassandra)
- 检索:用户提问时进行相似度搜索
- 生成:基于检索到的文档生成答案
面试官:很清晰的思路。那在测试方面,如何确保这个系统的可靠性?
小润龙:测试这块我会分层进行:
- 单元测试:用JUnit 5测试各个组件,比如文档解析、向量计算
- 集成测试:用TestContainers测试向量数据库集成
- 端到端测试:用Selenium模拟用户问答流程
- Mockito用来模拟外部AI服务,避免测试时产生费用
面试官:如果遇到AI幻觉(Hallucination)问题,你有什么解决方案?
小润龙:这个问题很关键!我会从几个方面入手:
- 设置相似度阈值,只使用高相关度的文档
- 添加事实校验机制,比如与权威数据源对比
- 在Prompt中明确要求基于给定文档回答
- 记录用户反馈,持续优化检索策略
第三轮:性能优化与架构设计
面试官:当文档数量达到百万级别时,检索性能会成为瓶颈,你有什么优化策略?
小润龙:百万级文档确实是个挑战!我会考虑:
- 使用分层索引:先粗筛再精筛
- 向量量化:减少向量维度,提升搜索速度
- 缓存热点查询结果
- 异步处理文档更新,避免阻塞查询
- 考虑使用专门的向量数据库如Milvus
面试官:在数据管道测试中,如何处理大数据量的测试场景?
小润龙:大数据测试我有个"三化"原则:
- 数据样本化:用代表性样本代替全量数据
- 测试并行化:用JUnit 5的并行测试特性
- 环境容器化:用Docker构建一致的测试环境
另外,我会用AssertJ的流式断言来验证数据处理结果,代码更清晰。
面试官:最后一个问题,如何设计监控系统来跟踪AI问答的质量?
小润龙:监控系统我会设计几个关键指标:
- 检索相关性得分
- 用户满意度反馈
- 回答置信度
- 响应时间分布
- 错误率统计
用Micrometer集成到Spring Boot中,配合Grafana做可视化。
面试结果
面试官:感谢你的回答。总体来说,你对Spring AI和测试框架有不错的理解,特别是在实际应用场景的思考比较深入。技术基础扎实,能够结合业务需求提出合理的解决方案。建议在系统架构设计和性能优化方面继续深入学习。我们会在3个工作日内通知结果。
📚 技术知识点详解
Spring AI RAG架构详解
Spring AI提供了完整的RAG解决方案,核心组件包括:
@Configuration
public class RagConfig {
@Bean
public VectorStore vectorStore(EmbeddingModel embeddingModel) {
return new InMemoryVectorStore(embeddingModel);
}
@Bean
public RagService ragService(VectorStore vectorStore, ChatModel chatModel) {
DocumentRetriever retriever = VectorStoreDocumentRetriever.builder()
.vectorStore(vectorStore)
.similarityThreshold(0.7)
.topK(5)
.build();
return new RagService(retriever, chatModel);
}
}
@Service
public class RagService {
private final DocumentRetriever retriever;
private final ChatModel chatModel;
public String answerQuestion(String question) {
// 1. 检索相关文档
List<Document> relevantDocs = retriever.retrieve(question);
// 2. 构建上下文
String context = relevantDocs.stream()
.map(Document::getContent)
.collect(Collectors.joining("\n\n"));
// 3. 生成回答
Prompt prompt = new Prompt("基于以下文档内容回答问题:\n" + context + "\n\n问题:" + question);
return chatModel.call(prompt).getResult().getOutput().getContent();
}
}
向量数据库性能优化
在处理大规模数据时,向量数据库的性能优化至关重要:
@Component
public class OptimizedVectorSearch {
// 使用分层搜索策略
public List<Document> hierarchicalSearch(String query, VectorStore vectorStore, int coarseK, int fineK) {
// 第一层:粗粒度搜索
List<Document> coarseResults = vectorStore.similaritySearch(
SearchRequest.builder()
.query(query)
.topK(coarseK)
.build()
);
// 第二层:在粗结果中精搜索
return vectorStore.similaritySearch(
SearchRequest.builder()
.query(query)
.topK(fineK)
.filterExpression(createIdFilter(coarseResults))
.build()
);
}
private String createIdFilter(List<Document> documents) {
return documents.stream()
.map(Document::getId)
.map(id -> "id == '" + id + "'")
.collect(Collectors.joining(" OR "));
}
}
测试框架最佳实践
在数据分析平台中,测试框架的使用需要特别注意:
@ExtendWith(MockitoExtension.class)
class DataProcessingServiceTest {
@Mock
private EmbeddingModel embeddingModel;
@Mock
private VectorStore vectorStore;
@InjectMocks
private DataProcessingService service;
@Test
void shouldProcessDocumentCorrectly() {
// Given
Document document = new Document("测试文档内容");
when(embeddingModel.embed(anyString())).thenReturn(new float[1536]);
// When
service.processDocument(document);
// Then
verify(vectorStore).add(argThat(docs -> docs.size() == 1));
}
@ParameterizedTest
@CsvSource({
"数据分析报告, 0.8",
"技术文档, 0.6",
"用户反馈, 0.9"
})
void shouldReturnAppropriateSimilarityThreshold(String docType, double expectedThreshold) {
double actualThreshold = service.calculateSimilarityThreshold(docType);
assertThat(actualThreshold).isEqualTo(expectedThreshold);
}
}
AI系统监控与可观测性
构建完整的监控体系确保系统稳定性:
@Component
public class AiSystemMetrics {
private final MeterRegistry meterRegistry;
private final Counter retrievalSuccessCounter;
private final Timer responseTimeTimer;
public AiSystemMetrics(MeterRegistry meterRegistry) {
this.meterRegistry = meterRegistry;
this.retrievalSuccessCounter = Counter.builder("ai.retrieval.success")
.description("Successful document retrieval count")
.register(meterRegistry);
this.responseTimeTimer = Timer.builder("ai.response.time")
.description("AI response time distribution")
.register(meterRegistry);
}
public void recordSuccessfulRetrieval() {
retrievalSuccessCounter.increment();
}
public Timer.Sample startTiming() {
return Timer.start(meterRegistry);
}
public void stopTiming(Timer.Sample sample, String operation) {
sample.stop(responseTimeTimer);
}
}
💡 总结与建议
通过这次面试对话,我们可以看到在现代Java开发中,AI技术与测试框架的结合变得越来越重要。对于想要进入这个领域的开发者,建议:
学习路径建议:
- 基础巩固:深入掌握Spring框架核心原理
- AI技术学习:从RAG基础开始,逐步学习向量数据库、Embedding模型等
- 测试技能提升:掌握现代化测试框架和最佳实践
- 实战项目:通过实际项目积累经验,特别是大数据量场景的处理
技术成长要点:
- 关注AI技术的最新发展,特别是开源生态
- 重视系统可观测性和监控体系建设
- 培养性能优化和架构设计能力
- 保持对新技术的好奇心和学习热情
在数据分析平台这样的复杂系统中,扎实的技术基础和系统的架构思维同样重要。希望本文的面试实录和技术解析能为你的技术成长提供有价值的参考。

为武汉地区的开发者提供学习、交流和合作的平台。社区聚集了众多技术爱好者和专业人士,涵盖了多个领域,包括人工智能、大数据、云计算、区块链等。社区定期举办技术分享、培训和活动,为开发者提供更多的学习和交流机会。
更多推荐
 8
8 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)