Fastgpt结合Ragflow构建本地表格知识库,效果拉满!【喂饭级教程】
最近陆续收到一些朋友的提问:Excel该怎么更好的录入fastgpt知识库呢?录入之后知识库问答效果不佳又怎么办呢?
最近陆续收到一些朋友的提问:Excel该怎么更好的录入fastgpt知识库呢?录入之后知识库问答效果不佳又怎么办呢?

虽然fastgpt支持直接导入Excel,但是如果你姿势不对,导入知识库的数据质量将大打折扣,导致知识库问答效果不佳。
优化知识库的问答效果不是一蹴而就的,需要经过反复调整,反复测试。而且是多维度的优化。
语言模型、索引模型、重排模型、RAG的方式、数据的质量、知识库的参数、大模型的参数等等都会对知识库的问答效果产生影响。
本期将以表格数据为例,先分享在fastgpt知识库搭建的数据预处理阶段,借助ragflow优化知识库数据质量的方案。
PS:是本人多次帮助企业搭建知识库后的一些经验分享,建议收藏~

数据预处理

我们先达成共识,在知识库把数据转换为向量之前,对原始文件做的数据清洗、整理、优化叫做数据预处理
构建知识库的第一关就是数据预处理 —— 把各种非结构化文件转化为结构化数据(或者说提取整理、清洗数据)。为的就是让数据更干净、准确,这步可以说是为好的知识库问答效果打好基础的关键。
比如你手头有各种PDF文档、图片、PPT、网页、Excel等各类资料,要把这些变成AI更容易理解的知识,就需要先做预处理:提取PDF中的文字,识别图片中的文字和内容,整理PPT中的资料等。
如果预处理做得不到位,就可能出现数据缺失、乱码、格式混乱,语意不连贯等问题,这些都会直接影响知识库的问答质量。
虽然各家智能体平台都自带数据预处理功能,但说实话,参差不齐,效果往往也不尽如人意。所以建议大家在上传文件之前,根据需求,先用专业的数据处理工具自行完成预处理(本期要用到的就是ragflow)。
PS:今天的教程以fastgpt为例,同样适用于大部分带有知识库的智能体平台。
结合ragflow优化数据质量
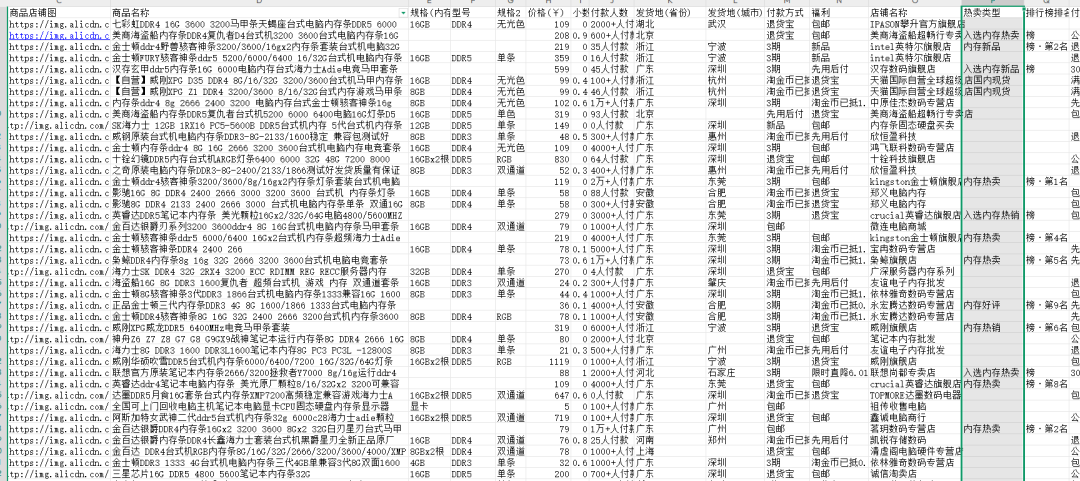
说明:接下来用于知识库测试的表格数据是我从淘宝抓取的3页内存条商品数据,一共90件商品
fastgpt目前有两个地方支持上传表格文件
一个是文本数据集、一个是表格数据集
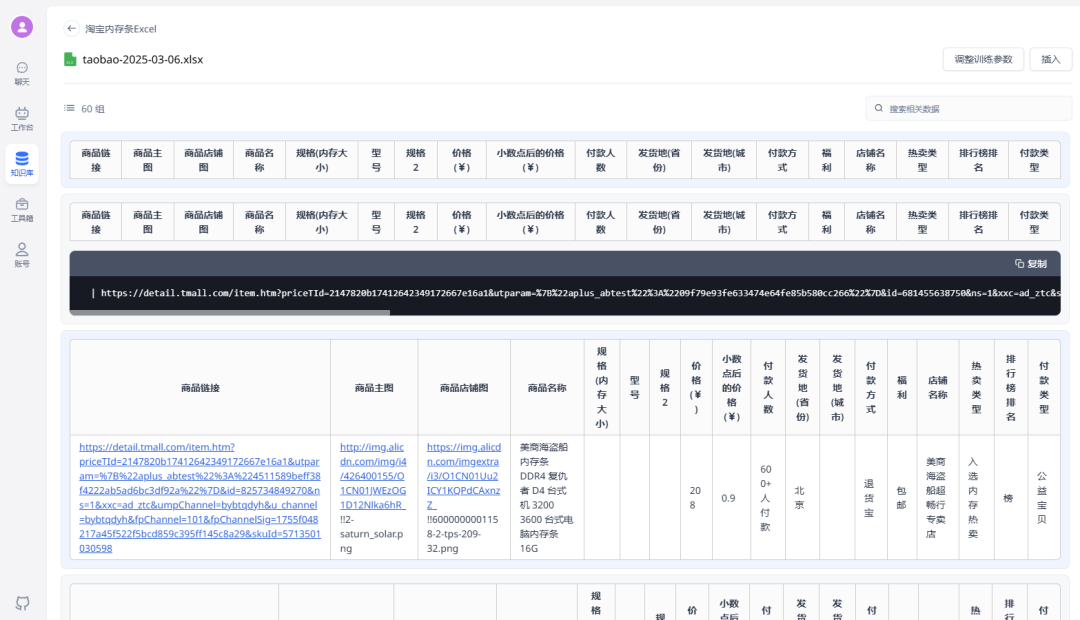
我更推荐使用表格数据集的方式来上传Excel、CSV这类表格文件
因为亲测直接通过文本数据集的方式上传表格文件,知识库内的数据如下
(有点儿乱):
使用文本数据集的方式上传Excel表格之后,具体每个chunk(块)数据格式如下(markdown格式)
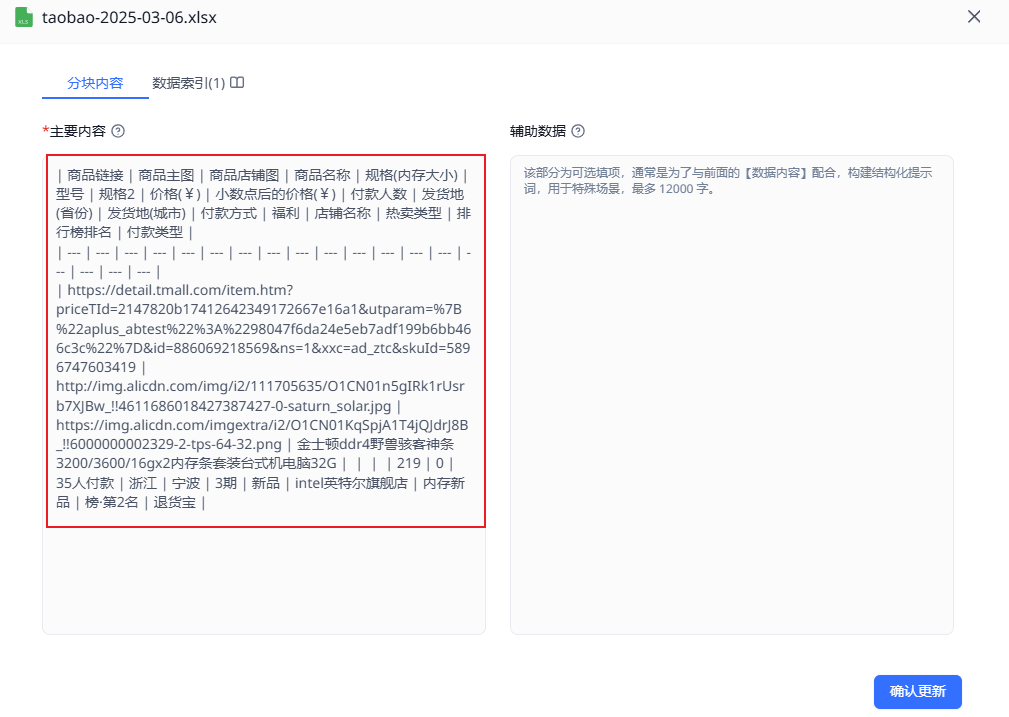
实测表格数据以这种markdown数据格式保存在知识库,后续知识库问答准确度不高(因为即便rag正确检索,大模型也很容易搞错每列对应的内容)。
下面是多次测试结果中的一个,我的问题是:“需要海盗船品牌的内存条”,但是回答结果里面乱入了海力士,,,
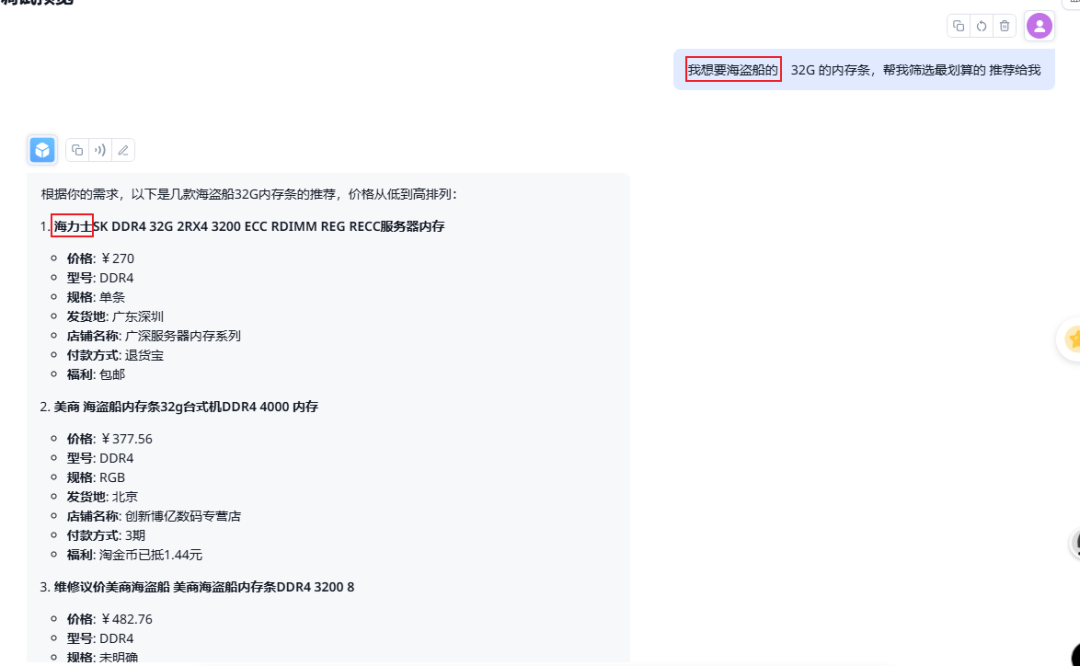
我更推荐使用表格数据集的方式来解析表格文件
不过fastgpt的表格数据集 要求按照指定的模板上传csv,而且只能有两列(模板如下图),是QA的形式,index表示问题列,content表示答案列。

所以这就导致fastgpt看起无法支持多列Excel表格文件,但fastgpt的rag效果本身是非常不错的,问题的根源还是在数据预处理上。
1.借助ragflow的预处理能力
之前写了一篇本地部署ragflow搭建知识库的文章,感兴趣的朋友可以看看
本地部署ragflow,打造企业级知识库
袋鼠帝,公众号:袋鼠帝AI客栈DeepSeek+ragflow打造企业知识库!真香警告
ragflow不管是在数据预处理的选择,还是知识库参数配置上都比fastgpt丰富不少
虽然他两的知识库效果都很棒,但是ragflow的上限应该更高,因为他支持更加精细化的参数调整。
不过对于中小企业来说,在满足需求的前提下,我觉得fastgpt够用了,因为它更简单好用,相较于ragflow更轻量,所需的服务器资源也更少。
我们可以借助ragflow丰富的数据预处理能力,通过曲线救国的方式来帮助fastgpt进行表格文件的数据预处理。
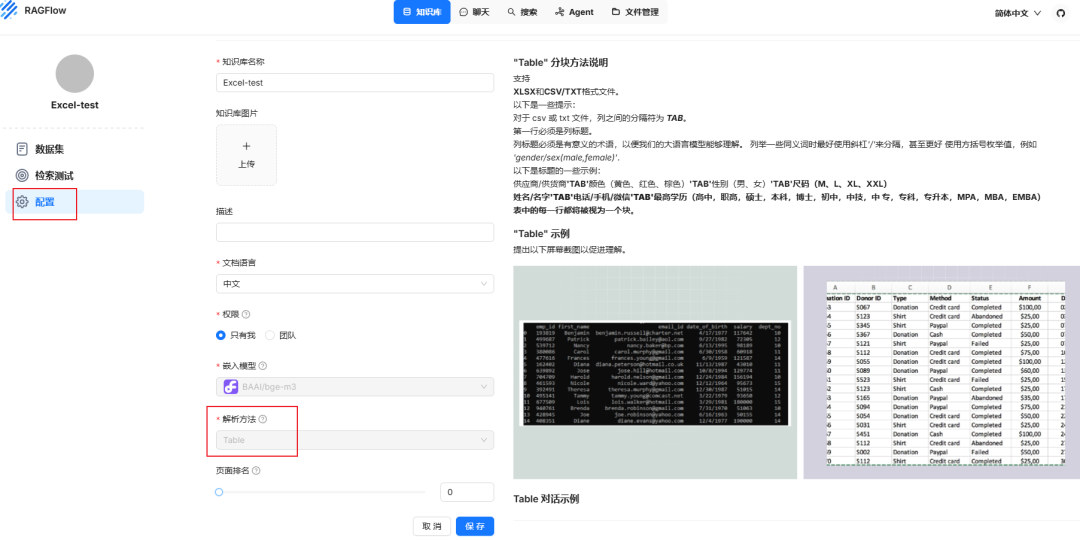
在ragflow的知识库配置这里,解析方式选择Table
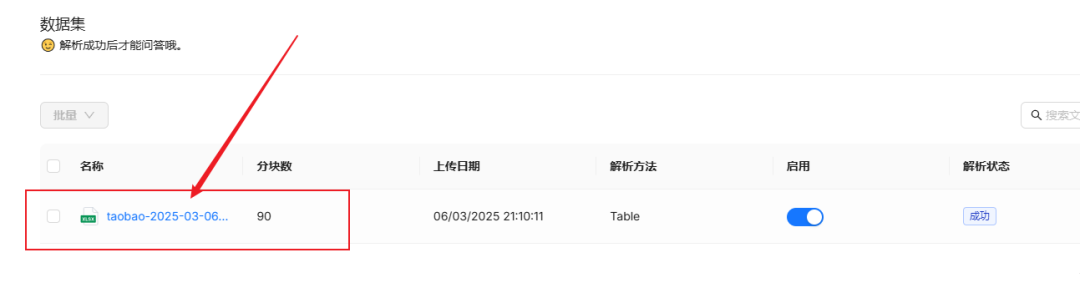
在数据集这里,上传本地原始Excel文件,点击解析按钮,直到解析状态变为成功

这时我们点击进入使用ragflow解析好的文件内部
可以看到ragflow把表格内容分了很多块(chunk),每一块代表一行数据,并且列名是在数据前面的,跟fastgpt的解析效果完全不一样,这很重要(能更加清晰明了的展示出,一行中每一列的数据对应的含义)。
并且一行数据在同一个块,使得最终通过向量检索到的数据拥有完整的关联关系。

在上传之前一定要特别重视表格中每一列的列名,不能词不达意,而是需要准确的传达每一列的含义。
不过,有点尴尬的是ragflow并不支持导出处理后的数据(希望后续官方能支持)。
所以我借助了一个叫Easy Scraper的爬虫浏览器插件(免费、简单好用)
可以把页面上展示的数据一键抓取,可选择保存为csv或者json格式
去谷歌插件商店搜索Easy Scraper,一键安装
由于该插件只能抓取页面上展示的数据,咱们先把ragflow数据集这里页面设置,改成最大的100条/页(如下图),因为我的商品是90个,所以刚好一页可以展示全。
PS:如果有几百条数据,可以点击下一页,多采集几次,如果有几千上万条的话不建议使用这个方式

点击右上角Easy Scraper插件图标,它会自动选中当前页面的所有数据,并采集,最后点击弹出的小窗口中的csv下载按钮就OK啦~
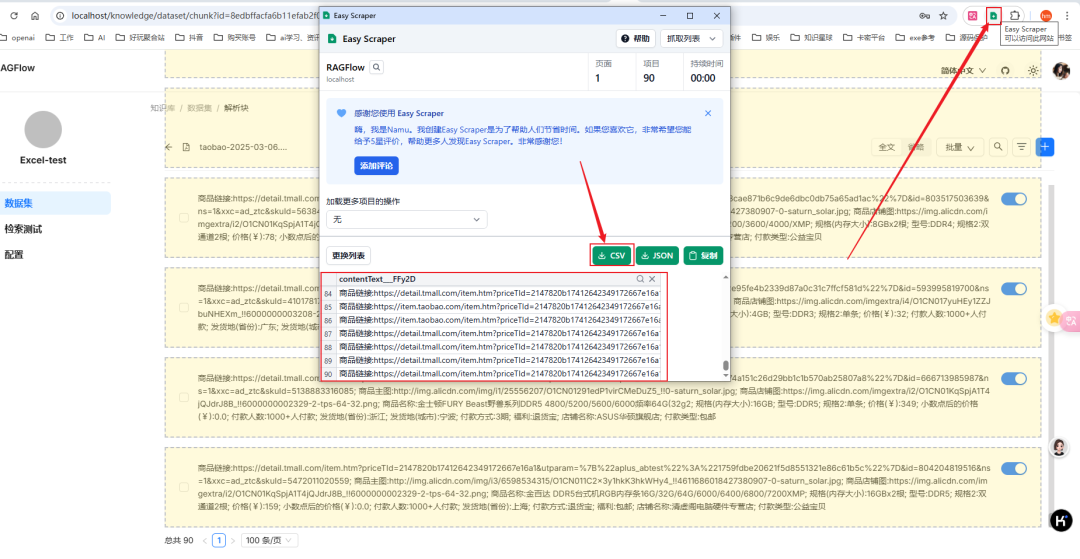
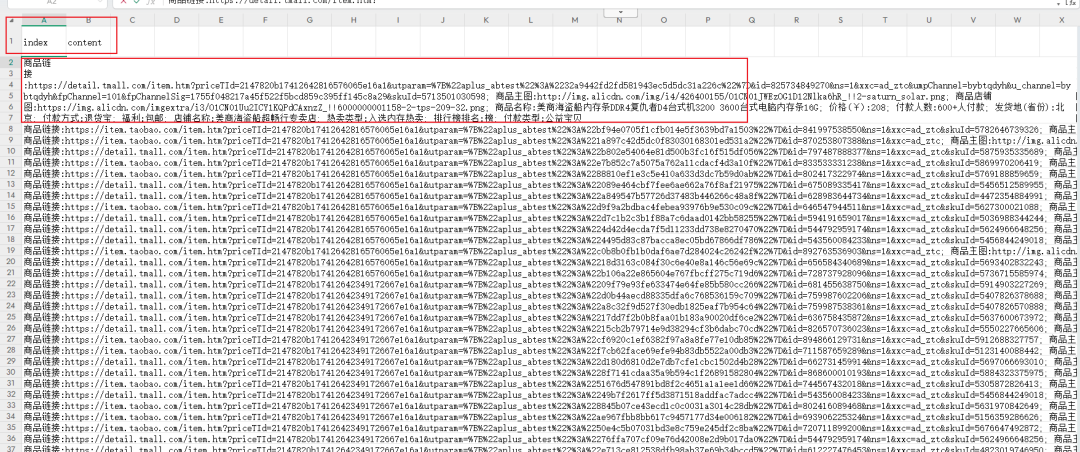
下载之后效果如下(把原本的多列数据整合到一列了),我们需要把第一行空出来,增加index,和content列,以适配fastgpt的表格模板。
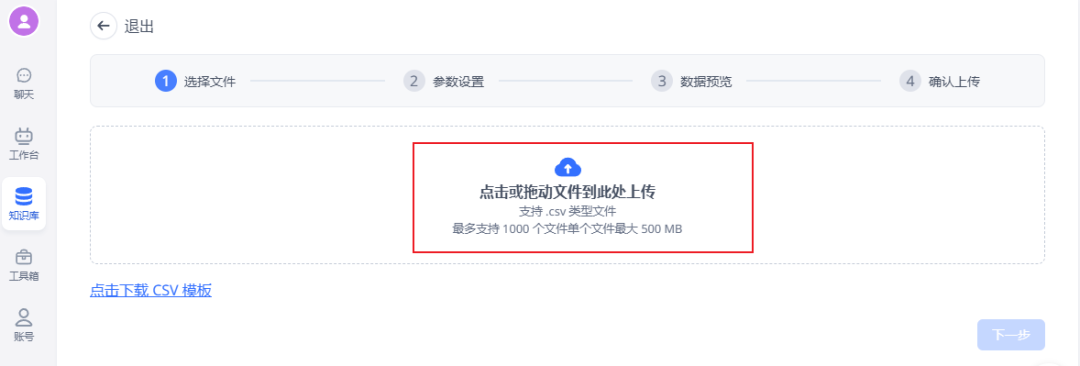
最后使用fastgpt的表格数据集方式,直接导入即可
导入之后效果如下
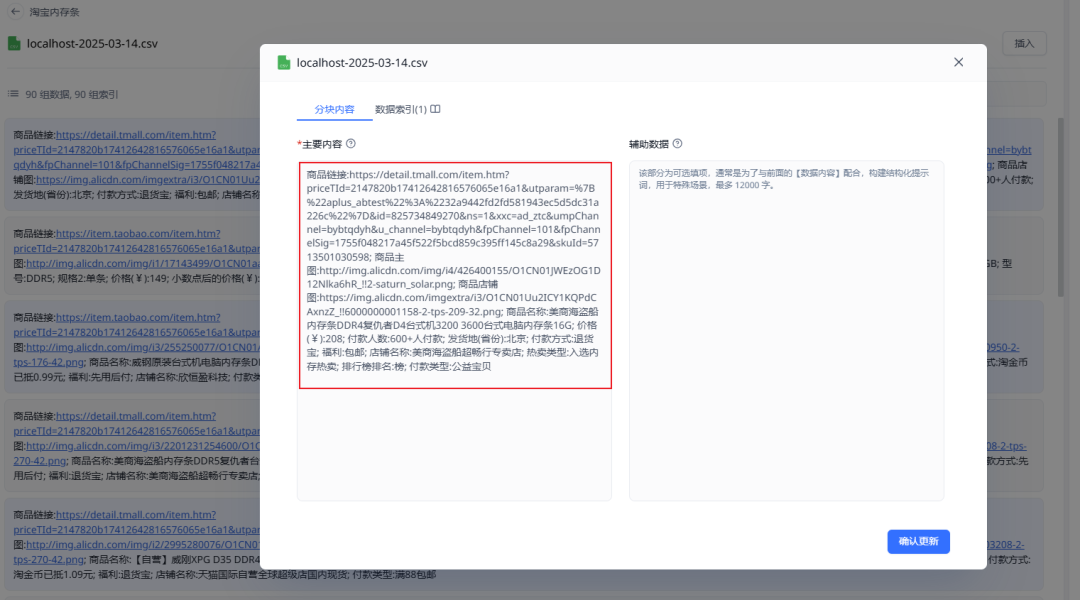
亲测表格数据以这样的形式存放到知识库中,由于每个数据都有列名做标注,并且每行数据都在同一个chunk(块)中,表格类型的知识库问答效果直接起飞~
嫌麻烦的朋友也可以使用ragflow云端版本
地址:https://ragflow.io/
还有一种情况是包含分类的表格(如下图)。
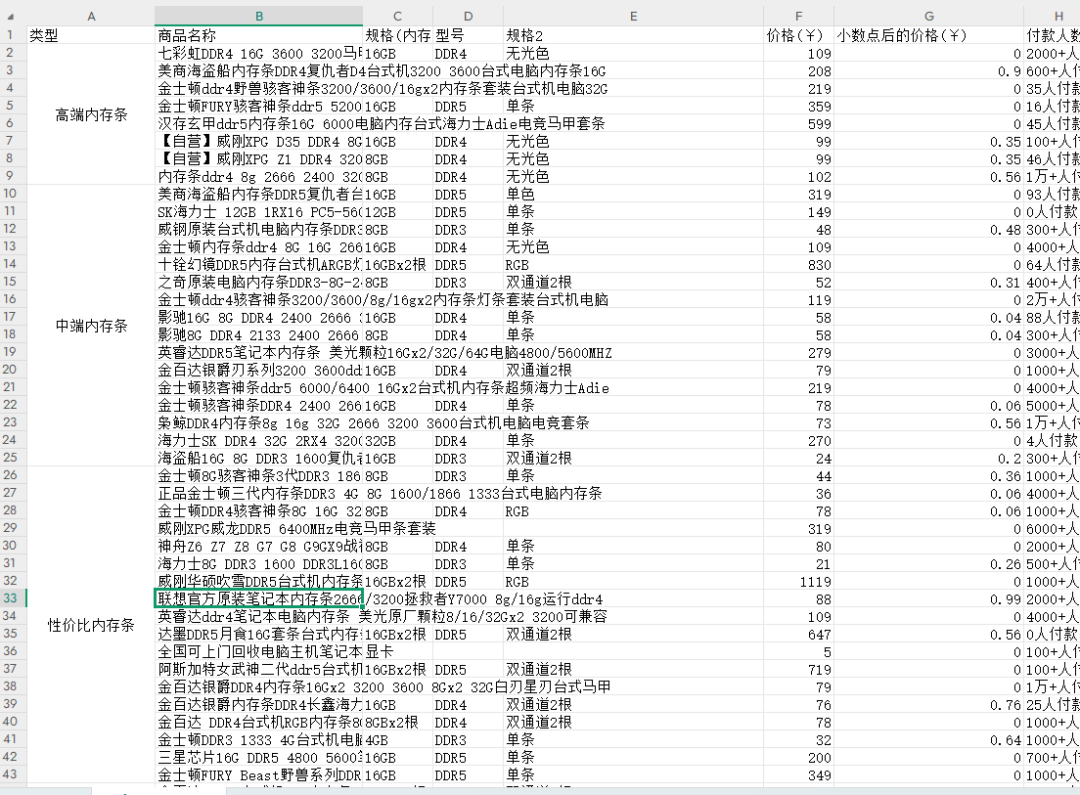
有两种方式处理
第一种:取消单元格合并,后续处理还是跟之前的处理方式一样
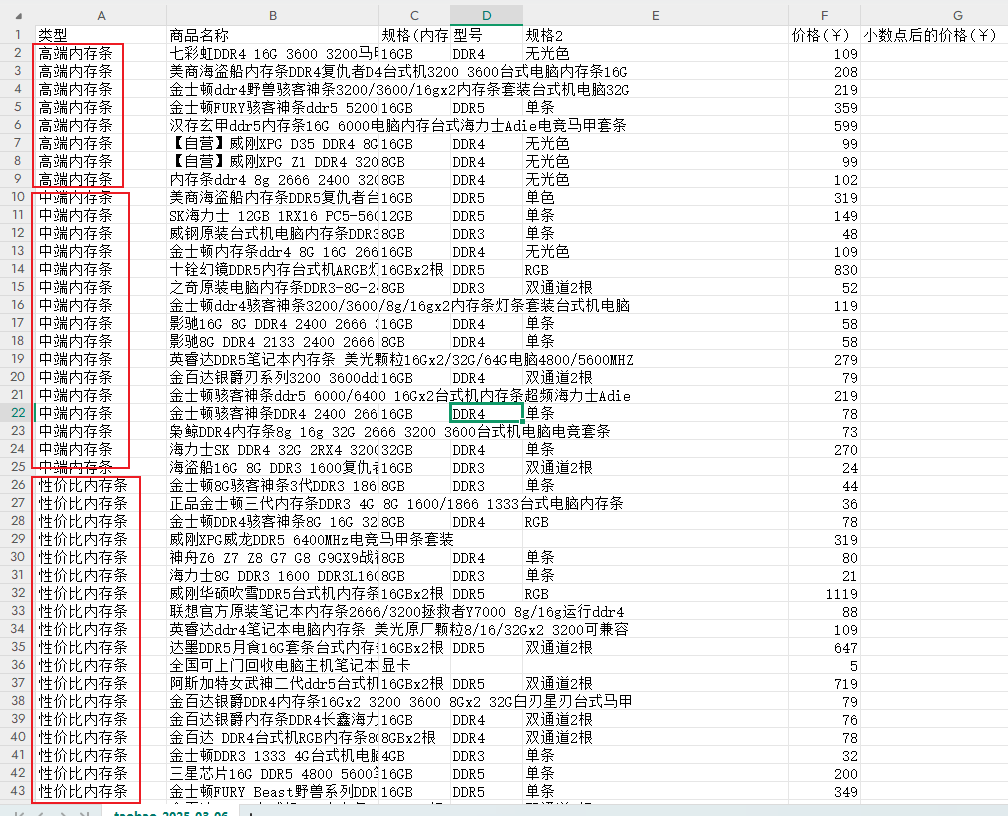
当分类不多,每个分类下的数据条数也不多的时候,可以采用第二种方式:
把同一分类下的数据放在同一个块(chunk)中,然后在顶部标明分类名称(如下图)。

避坑指南:分类数据不要像下图这样存放(index存放分类名称,content存放某个分类下的子信息),这样虽然能很方便的根据分类名称检索到该分类下所有的相关信息。但是很难从子信息反过来锁定父级分类。
比如在下图这个案例中,你问:“xxx大学,属于什么招生批次?”
就很难回答准确。
解释:因为fastgpt只对主要内容(index)创建了索引,在进行rag的时候,检索相似度也是通过index部分的语意来判断相似度,所以无法根据辅助数据回溯主要内容。
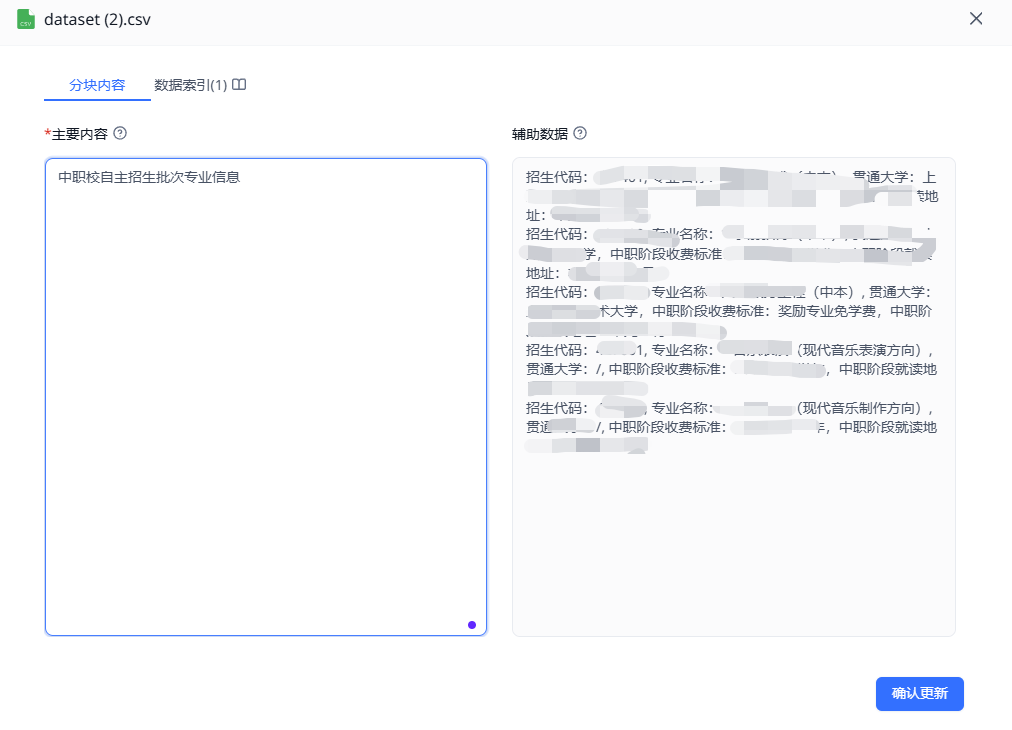
所以,对于表格数据,最好把相关信息都放到主要内容(index)中,辅助数据中留空即可。
除了表格数据外,其他像pdf、简历、论文等11种场景都可以借助ragflow来预处理~

2.借助AI编程工具进行预处理
当然,还可以借助Trae、Cursor等AI编程工具,快速的编码实现一个小工具,来帮助一键清洗、整理、优化原始数据。
3.借助带有Code Interpreter的AI应用
如果对AI编程不熟悉的朋友还可以借助 带有Code Interpreter(代码解释器)的AI应用实现(比如ChatGPT,Manus等),直接把原始文件丢给它,并描述清楚预期的输出数据格式(最好给示例),它就能快速输出处理好的文件啦。
本期就到这里啦,希望分享的这一点点小心得能够对大家有帮助。
大模型算是目前当之无愧最火的一个方向了,算是新时代的风口!有小伙伴觉得,作为新领域、新方向人才需求必然相当大,与之相应的人才缺乏、人才竞争自然也会更少,那转行去做大模型是不是一个更好的选择呢?是不是更好就业呢?是不是就暂时能抵抗35岁中年危机呢?
答案当然是这样,大模型必然是新风口!
那如何学习大模型 ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。但是具体到个人,只能说是:
最先掌握AI的人,将会比较晚掌握AI的人有竞争优势。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
但现在很多想入行大模型的人苦于现在网上的大模型老课程老教材,学也不是不学也不是,基于此我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近100余次后,终于把整个AI大模型的学习路线完善出来!

在这个版本当中:
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型路线+学习教程已经给大家整理并打包分享出来, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、大模型经典书籍(免费分享)
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套大模型报告(免费分享)
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)
三、大模型系列视频教程(免费分享)

四、2025最新大模型学习路线(免费分享)
我们把学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以微信扫描下方二维码,免费领取

为武汉地区的开发者提供学习、交流和合作的平台。社区聚集了众多技术爱好者和专业人士,涵盖了多个领域,包括人工智能、大数据、云计算、区块链等。社区定期举办技术分享、培训和活动,为开发者提供更多的学习和交流机会。
更多推荐

 10
10 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)