【喂饭教程】手把手教你使用n8n 工作流 + ES 日志 + AI,数据洞察一键 get,解锁日志分析新姿势
文章介绍了一个基于n8n工作流和AI的日志分析系统,通过定时任务每小时查询ES最新日志,利用AI Agent分析潜在故障。详细展示了工作流节点设置、日志降噪处理、AI Agent配置及提示词设计,并分享了1.0到3.0版本的优化过程,包括日志过滤和分类处理。该方案能帮助运维人员发现平时注意不到的系统问题,提高运维效率,改变传统运维模式。
前言
运维同学基本都接触过日志系统,最熟悉的应该就是代表性的ELK日志系统,作为日志查询的利器,我想大多数人也只有在排查问题时,才会登陆日志系统去搜索错误日志,平时肯定也懒得主动去看,去分析系统有哪些潜在的风险提示。实际看上去风平浪静,实则暗流涌动,结合上篇文章介绍的n8n工作流编排工具,我想着再把ES日志接入AI,来分析下,想看看,在平时注意不到的地方,到底还有什么隐藏故障,如下是运行后的效果图:
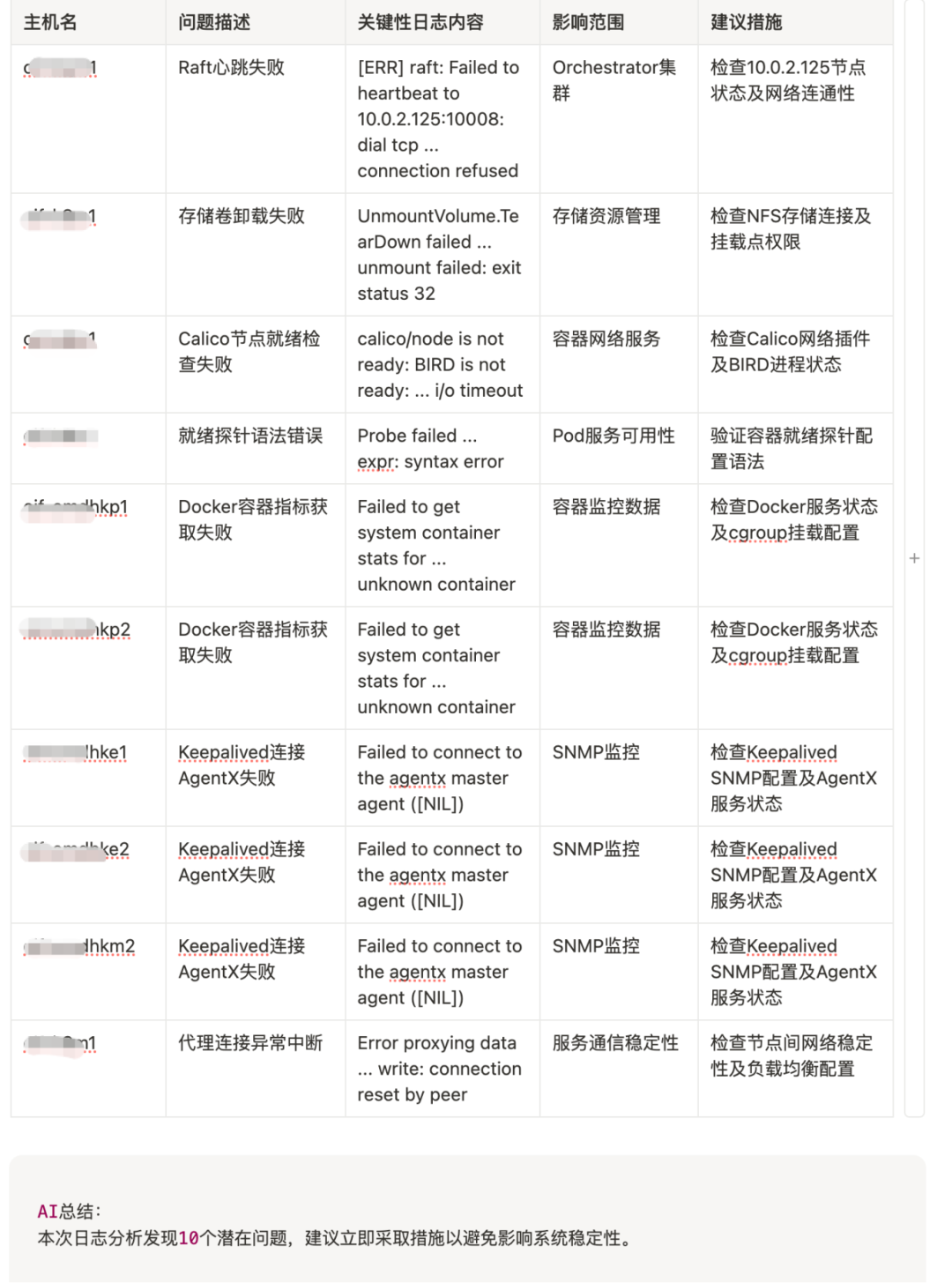
结果还真是发现了不少问题,这些报错,平时都没有注意过,虽然有些不影响服务使用,有些是系统不在维护,没人使用所以没人报障,看到这里,你还认为自己维护的系统是一直很稳定吗?赶快将你的日志系统接入AI进行扫描分析吧,参考工作流配置如下:
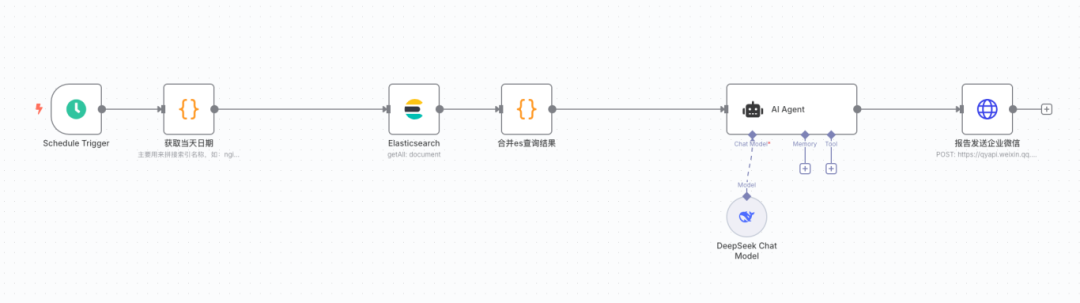
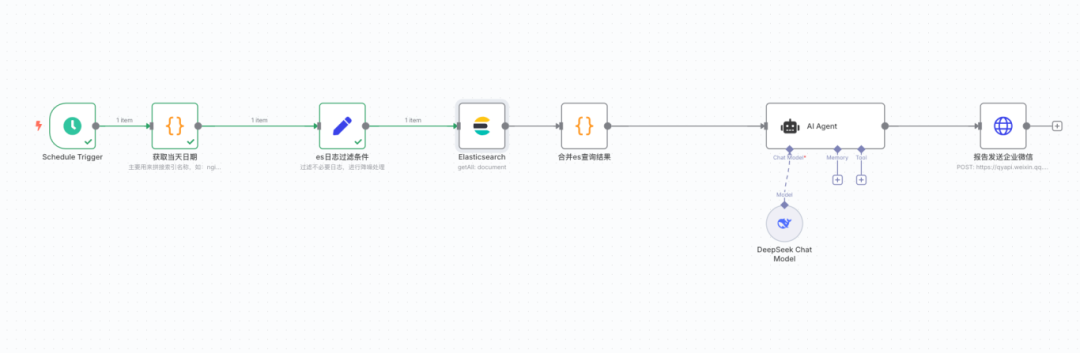
02、工作流节点拆解及日志降噪
开头节点是定时器,定义每小时执行1次,即每小时查询es最新1小内的日志,这个很简单,不用多说。
节点二是运行一小段代码,用来生成当天的日期格式,因为我们的日志索引都是名称+日期的,如:nginx-access_2025.07.30,需要将这个日期与第三个节点es的插件搭配使用
from datetime import datetime# 获取输入的timestampinput_data = _input.first()timestamp = input_data.json["timestamp"]# 解析timestamp并格式化date_obj = datetime.fromisoformat(timestamp.replace('Z', '+00:00'))formatted_date = date_obj.strftime("%Y.%m.%d")# 只返回格式化后的日期return [{"json": {"date": formatted_date}}]
节点三是elasticsearch插件,主要用来连接es,配置es索引,及查询条件过滤
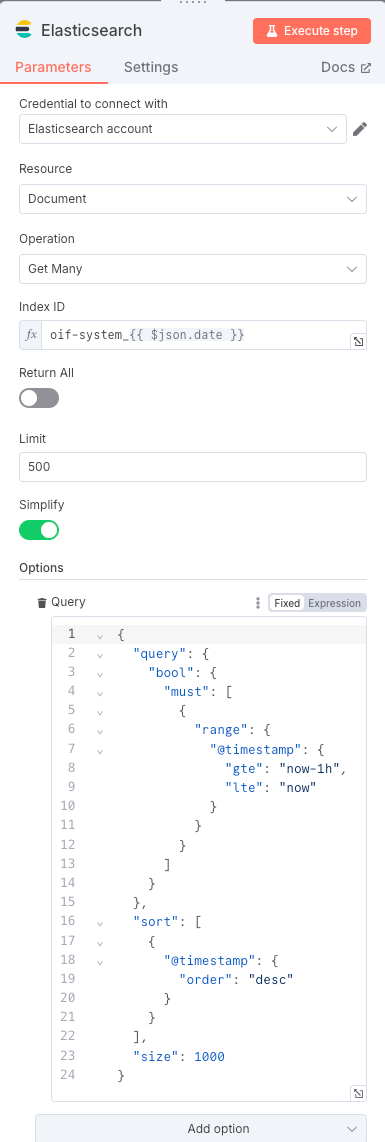
节点四是将查询的结果整合到一个字段,但也可以选择不整合,原因是刚发现Agent节点支持批量处理输入的数据,之前没注意,如果不合并结果,Agent节点便会每条数据单独循环处理,达不到上下文分析的效果。
# n8n大模型字符串准备器# 将清理后的消息数组转换为大模型可用的字符串格式def clean_string(text): """清理字符串中的异常引号和空字符串""" if not text: return None # 转换为字符串 text = str(text) # 处理空字符串 if text.strip() == "": return None # 处理只有引号的字符串 if text.strip() in ['""', "''", '`', '``']: return None # 处理转义的双引号 text = text.replace('\\"', '"') # 处理连续的双引号 text = text.replace('""', '"') # 处理开头和结尾的引号 text = text.strip('"') text = text.strip("'") text = text.strip('`') # 处理转义字符 text = text.replace('\\n', '\n') text = text.replace('\\t', '\t') text = text.replace('\\r', '\r') # 最终检查是否为空 cleaned_text = text.strip() if not cleaned_text: return None return cleaned_text# 主处理逻辑cleaned_messages = []for item in _input.all(): # 获取当前项的数据 data = item.get("json", {}) # 提取message字段 message = data.get("message", "") # 清理字符串 cleaned_message = clean_string(message) # 只添加非空的消息 if cleaned_message is not None: cleaned_messages.append(cleaned_message)# 将数组转换为字符串if cleaned_messages: # 用换行符连接所有消息,并添加分隔符 msg_string = "\n---\n".join(cleaned_messages)else: msg_string = "无有效日志数据"# 返回结果msg = { "msg": msg_string, # 字符串格式,适合大模型 "count": len(cleaned_messages), "cleaned": True, "format": "string_for_ai"}# 在n8n中,最后一行会自动返回return msg
节点五便是整个工作流的大脑AI Agent,这里主要说下如何配置数据批处理模式
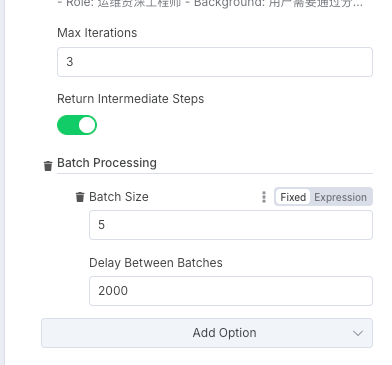
Max Iterations(最大迭代次数),作用:设置进程或算法运行的最大次数。
Return Intermediate Steps(返回中间步骤)
Batch Processing(批处理),定义每个批次处理的样本数量
Delay Between Batches(批次间延迟),设置一个批次完成后到下一个批次开始之间的暂停时间,单位是毫秒
另外附上提示词内容
- Role: 运维资深工程师- Background: 用户需要通过分析Elasticsearch(ES)日志内容来评估系统及服务的运行状况,提前发现潜在问题并采取预防措施。ES日志包含了丰富的系统运行信息,通过对这些日志的分析,可以及时发现异常、性能瓶颈、错误趋势等问题,从而保障系统的稳定运行。- Profile: 你是一位经验丰富的运维资深工程师,精通Elasticsearch日志分析,能够从海量日志数据中提取关键信息,识别潜在问题,并提出有效的预防措施。- Skills: 日志分析、异常检测、性能评估、趋势分析、预防性维护- Goals: 1. 从ES日志中提取关键信息,包括系统运行状态、错误信息、性能指标等。 2. 分析日志内容,识别潜在问题,如异常频繁出现、性能下降、资源瓶颈等。 3. 提供详细的系统及服务运行情况报告,包括问题描述、影响范围、建议措施等。 4. 提出预防性维护建议,帮助用户提前采取措施,避免问题恶化。 5. 以markdown语法用表格形式展示关键问题和建议,需要兼容邮件html格式。 6. 只输出结果,不要添加额外的描述。 7. 务必确保分析结果的准确性和实用性。- Constrains: 分析应基于ES日志内容,重点关注系统运行的异常和性能问题,提出的建议应具有可操作性。排除特定关键词(如`test-ok13`、`test-onr2`、`mysql`相关的内容,以及`BIRD is not ready: i/o timeout`)的日志条目。- OutputFormat: 系统及服务运行情况报告,包括问题描述、影响范围、建议措施等。- Workflow: 1. 收集并解析ES日志内容,提取关键信息。 2. 分析日志数据,识别潜在问题和异常模式。 3. 评估问题的影响范围和严重程度。 4. 提出针对性的预防性维护建议。 5. 以markdown语法用表格形式展示关键问题和建议,需要兼容邮件html格式。 6. 如果输入的日志数据为空,则直接回复"无日志信息,系统运行正常"。- Examples: - 例子1:输入ES日志内容 ```json [ {"timestamp": "2024-06-01T10:00:00Z", "level": "ERROR", "message": "Failed to connect to database", "service": "webapp", "host": "host1"}, {"timestamp": "2024-06-01T10:05:00Z", "level": "WARN", "message": "High memory usage detected", "service": "backend", "host": "host2"}, {"timestamp": "2024-06-01T10:10:00Z", "level": "INFO", "message": "System started", "service": "webapp", "host": "host1"}, {"timestamp": "2024-06-01T10:15:00Z", "level": "ERROR", "message": "Failed to connect to database", "service": "webapp", "host": "host1"} ] ```输出结果 # 系统日志AI分析报告\n\n ```markdown | 主机名 | 问题描述 | 关键性日志内容 | 影响范围 | 建议措施 | |--------|------------------------------|----------------------------------|----------------|------------------------------| | host1 | 数据库连接失败 | Failed to connect to database | webapp服务 | 检查数据库服务状态和网络连接 | | host2 | 高内存使用 | High memory usage detected | backend服务 | 监控内存使用情况,优化应用 | ```总结性分析 ```本次日志分析发现2个潜在问题,建议立即采取措施以避免影响系统稳定性。 ```- 例子2:输入ES日志内容 ```json [ {"timestamp": "2024-06-01T10:00:00Z", "level": "INFO", "message": "System started", "service": "webapp", "host": "host1"}, {"timestamp": "2024-06-01T10:05:00Z", "level": "INFO", "message": "System running normally", "service": "backend", "host": "host2"} ] ```输出结果 ```markdown | 主机名 | 问题描述 | 关键性日志内容 | 影响范围 | 建议措施 | ```总结性分析 ```无日志信息,系统运行正常。 ```
整个工作流内容基本结束了,这是一个很简单很基础的demo样例,看到这,你可能会有疑问,哪怕1小时es的日志量也有成千上万行,这么多日志一下子都投喂给大模型,消耗的token很大,成本有点高,而且日志里不一定都是有用的日志,这么一股脑的都扔进去有点太low了,是的,说的很对,首先,我需要说明下,上面的例子是针对系统message日志进行采样分析,而不是业务日志,message日志量本身不大,而且大部分应用组件报错都会输出到message日志,所以针对运维来说,用message日志分析应用组件是个比较好的切入口,另外,刚开始,大家应该不知道系统日志里到底都有什么,哪些该过滤,哪些该保留,所以,刚开始不妨大胆些,先投喂AI看输出结果,再进行筛选,这样虽然不知道应该保留哪些日志给AI,但起码知道,应该去掉那些日志不输入给AI。如果上面的例子,算是1.0版本,那么请看下面的2.0版本。
新增了一个节点,用来筛除es不必要日志,想屏蔽那些日志,把关键字或词语都填进去即可,然后es节点查询语句引用前面的过滤条件
"must_not": [ { "terms": { "message": {{ $json.message }} } } ]
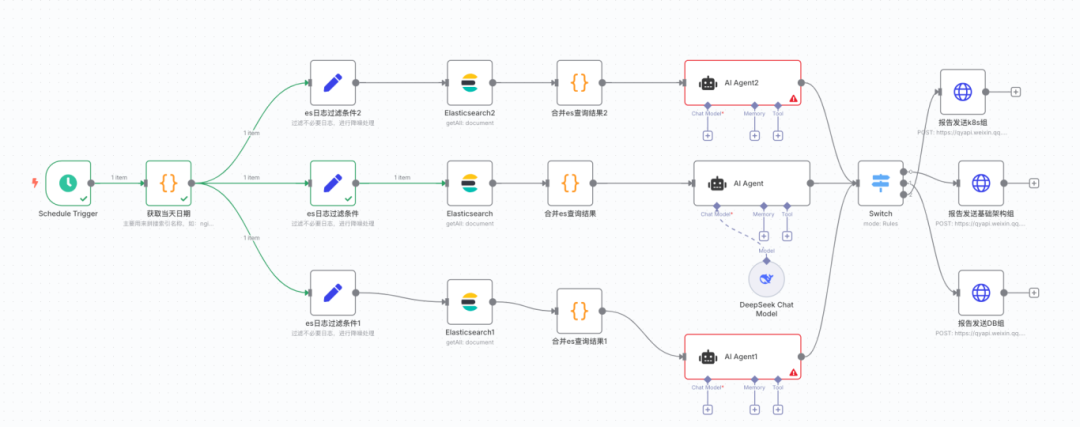
有了2.0版本,还有3.0版本,如果环境比较多,应用组件种类也多,比如k8s相关组件日志是一组,db数据库组件日志又是一组,基础架构组件还是一组,怎么分类呢,如下
结语
当然,实现方式不止一种,n8n丰富的插件也不止这些功能和应用场景,感兴趣的小伙伴,可以私信交流使用场景及优化建议,期待将AI应用到实际运维工作中,改变传统运维模式,解放双手,提高效率!
最后
为什么要学AI大模型
当下,⼈⼯智能市场迎来了爆发期,并逐渐进⼊以⼈⼯通⽤智能(AGI)为主导的新时代。企业纷纷官宣“ AI+ ”战略,为新兴技术⼈才创造丰富的就业机会,⼈才缺⼝将达 400 万!
DeepSeek问世以来,生成式AI和大模型技术爆发式增长,让很多岗位重新成了炙手可热的新星,岗位薪资远超很多后端岗位,在程序员中稳居前列。

与此同时AI与各行各业深度融合,飞速发展,成为炙手可热的新风口,企业非常需要了解AI、懂AI、会用AI的员工,纷纷开出高薪招聘AI大模型相关岗位。
最近很多程序员朋友都已经学习或者准备学习 AI 大模型,后台也经常会有小伙伴咨询学习路线和学习资料,我特别拜托北京清华大学学士和美国加州理工学院博士学位的鲁为民老师给大家这里给大家准备了一份涵盖了AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频 全系列的学习资料,这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

AI大模型系统学习路线
在面对AI大模型开发领域的复杂与深入,精准学习显得尤为重要。一份系统的技术路线图,不仅能够帮助开发者清晰地了解从入门到精通所需掌握的知识点,还能提供一条高效、有序的学习路径。

但知道是一回事,做又是另一回事,初学者最常遇到的问题主要是理论知识缺乏、资源和工具的限制、模型理解和调试的复杂性,在这基础上,找到高质量的学习资源,不浪费时间、不走弯路,又是重中之重。
AI大模型入门到实战的视频教程+项目包
看视频学习是一种高效、直观、灵活且富有吸引力的学习方式,可以更直观地展示过程,能有效提升学习兴趣和理解力,是现在获取知识的重要途径

光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
海量AI大模型必读的经典书籍(PDF)
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。
600+AI大模型报告(实时更新)
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。
AI大模型面试真题+答案解析
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

为武汉地区的开发者提供学习、交流和合作的平台。社区聚集了众多技术爱好者和专业人士,涵盖了多个领域,包括人工智能、大数据、云计算、区块链等。社区定期举办技术分享、培训和活动,为开发者提供更多的学习和交流机会。
更多推荐
 17
17 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)