大模型修炼指南:提示词工程、微调和RAG对比
摘要:本文用武侠比喻解析大模型三大技术:提示词工程(PE)如口诀点化,引导模型发挥已有能力;微调如闭关修炼,专精特定领域但耗时昂贵;检索增强生成(RAG)则似临阵查秘籍,灵活但响应较慢。三者各具优势:PE即时高效但受限于预训练知识,微调精度最高却缺乏灵活性,RAG可动态更新知识但需额外检索。文章还系统对比了三者在实现复杂度、资源成本等维度的差异,并强调学习大模型对职业发展和技术创新的重要性,最后提
若将大模型比作一位身怀深厚内力的心法高手,训练集便是其遍览过的百家武功秘籍 —— 正是这些秘籍的滋养,才让它练就了兼容并蓄的武学根基。那么,提示词工程(PE)、微调(Fine-tuning)和检索增强生成(RAG),便可这般用武侠世界的逻辑来解读:
-
提示词工程(PE)—— 口诀点化,尽显已有功力
-
这就像你面对一位深不可测的武林高手,他已经学会了各种武功,但你无法直接改变他的内功。
-
你能做的,就是用精准的语言去 引导 他施展不同的招式,比如“请用太极剑法对敌”或“施展降龙十八掌”,让他发挥出最适合当前情境的功夫。
-
这要求你的指令足够清晰,否则高手可能会发挥失误,比如你让他“以柔克刚”,但他理解成了“站着不动”……
-
2.微调(Fine-tuning)—— 闭关淬炼,专精一门绝技
-
这相当于让武林高手闭关修炼一段时间,专门学习一本新的 武功秘籍(比如《九阳真经》)。
-
经过反复训练,他的功夫发生了变化,形成了自己独特的风格,比如原本是个少林武僧,现在却精通了独孤九剑。
-
这种方法能让他在某一领域发挥出极高的战斗力,但缺点是 修炼时间长、代价大,而且一旦学成,就很难再短时间内切换到其他武功。
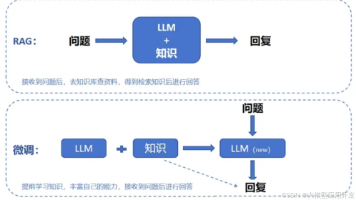
3. 检索增强生成(RAG)—— 临阵翻谱,即时破局
-
这就像是一个聪明的武者,他的脑海里没有特定的武学,但他随身携带了一本 江湖武学大全。
-
每当面对不同的对手,他就先翻阅秘籍,找到最合适的招式,比如看到对手是使剑的,他就立刻查找“剑法克制之道”,然后再根据秘籍内容施展相应的招式。
-
这样做的好处是 知识可以随时更新,但缺点是他需要额外花费时间去查找秘籍,而且如果秘籍内容不够准确,他可能会使出错误的招式。
总结:
|
方法 |
比喻 |
优势 |
劣势 |
|---|---|---|---|
| 提示词工程(PE) |
用言语指引高手施展已有武学 |
快,能即时适应新任务 |
受限于模型已有知识,无法学习新武功 |
| 微调(Fine-tuning) |
闭关修炼,习得新武学 |
精度最高,专精特定领域 |
训练时间长,适应性低 |
| 检索增强生成(RAG) |
随身携带武学秘籍,临阵查阅并施展 |
灵活,知识可随时更新 |
需要额外检索,响应速度较慢 |
正经对比
这个比喻虽然形象,但是不一完全准确,那我们就来看看三者的正经对比吧!
| 对比维度 | 提示工程(PE) | 微调(Fine-tuning) | 检索增强生成(RAG) |
|---|---|---|---|
| 核心原理 |
通过优化输入提示,引导模型生成期望输出 |
在预训练模型基础上,用领域数据更新模型参数 |
结合实时检索系统与生成模型,先检索外部知识再生成答案 |
| 实现复杂度 |
⭐️ 极低(无需训练,快速部署) |
⭐️⭐️⭐️ 高(需数据清理、训练、验证) |
⭐️⭐️ 中(需维护检索系统与知识库) |
| 资源成本 |
仅推理成本(几乎无额外计算需求) |
高昂(GPU/TPU 训练成本,长期维护消耗大) |
中等(检索系统存储+检索+推理消耗) |
| 数据依赖性 |
仅依赖提示设计,适用于通用任务 |
依赖高质量标注数据,数据质量决定精度上限 |
依赖结构化/非结构化知识库,检索质量决定效果 |
| 准确性特征 |
受限于预训练知识,无法超越模型已有认知 |
领域内精度最高,但受限于训练数据覆盖范围 |
依赖实时检索,可通过更新知识库保持准确,适应新知识 |
| 任务灵活性 |
高,即时调整提示适配新任务 |
低,适应新任务需重新训练 |
高,可通过更新知识库扩展能力,无需改动模型 |
| 响应延迟 |
原生模型推理速度(低延迟) |
原生模型推理速度(低延迟) |
需额外检索步骤,增加 20-200ms 甚至更高 |
| 知识更新机制 |
需人工调整提示模板,无法自动更新 |
需重新训练才能更新知识,更新周期长(天/周级) |
可增量更新知识库,分钟级生效,支持动态知识更新 |
| 安全风险 |
易受提示注入攻击,存在 Jailbreak 可能 |
训练数据可能泄露敏感信息 |
可能因检索外部数据导致虚假信息或数据污染 |
| 可解释性 |
高(提示与输出强关联,易调整) |
低(模型权重更新后难以解释决策) |
中(可追溯检索来源,但生成仍是黑箱) |
| 模型改动 |
无,完全使用预训练模型 |
训练后权重变化,适配特定任务 |
无,模型不变,仅更新知识库 |
| 推理稳定性 |
高,输出可预测性强(但受上下文长度影响) |
适中,受微调数据质量和训练方法影响 |
低,受检索结果波动影响,可能导致相同输入不同输出 |
| 适用任务类型 |
通用任务,如开放问答、创意写作 |
专业领域生成(医疗/法律/技术文档) |
需实时信息支撑的任务,如新闻事实核查、客服系统 |
读者福利大放送:如果你对大模型感兴趣,想更加深入的学习大模型,那么这份精心整理的大模型学习资料,绝对能帮你少走弯路、快速入门
如果你是零基础小白,别担心——大模型入门真的没那么难,你完全可以学得会!
👉 不用你懂任何算法和数学知识,公式推导、复杂原理这些都不用操心; 👉 也不挑电脑配置,普通家用电脑完全能 hold 住,不用额外花钱升级设备; 👉 更不用你提前学 Python 之类的编程语言,零基础照样能上手。
你要做的特别简单:跟着我的讲解走,照着教程里的步骤一步步操作就行。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
现在这份资料免费分享给大家,有需要的小伙伴,直接VX扫描下方二维码就能领取啦😝↓↓↓ 
为什么要学习大模型?
数据显示,2023 年我国大模型相关人才缺口已突破百万,这一数字直接暴露了人才培养体系的严重滞后与供给不足。而随着人工智能技术的飞速迭代,产业对专业人才的需求将呈爆发式增长,据预测,到 2025 年这一缺口将急剧扩大至 400 万!! 
大模型学习路线汇总
整体的学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战,跟着学习路线一步步打卡,小白也能轻松学会! 
大模型实战项目&配套源码
光学理论可不够,这套学习资料还包含了丰富的实战案例,让你在实战中检验成果巩固所学知识 
大模型学习必看书籍PDF
我精选了一系列大模型技术的书籍和学习文档(电子版),它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。 
大模型超全面试题汇总
在面试过程中可能遇到的问题,我都给大家汇总好了,能让你们在面试中游刃有余 
这些资料真的有用吗?
这份资料由我和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。  👉获取方式:
👉获取方式:
😝有需要的小伙伴,可以保存图片到VX扫描下方二维码免费领取【保证100%免费】  相信我,这套大模型系统教程将会是全网最齐全 最适合零基础的!!
相信我,这套大模型系统教程将会是全网最齐全 最适合零基础的!!

为武汉地区的开发者提供学习、交流和合作的平台。社区聚集了众多技术爱好者和专业人士,涵盖了多个领域,包括人工智能、大数据、云计算、区块链等。社区定期举办技术分享、培训和活动,为开发者提供更多的学习和交流机会。
更多推荐
 14
14 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)